文章目录
- 前言
- 一、使用 re 模块的前期准备工作
- 二、使用 re 模块匹配字符串
- 1. 使用 match() 方法进行匹配
- 2. 使用 search() 方法进行匹配
- 3. 使用 findall() 方法进行匹配
- 三、使用 re 模块替换字符串
- 四、使用 re 模块分割字符串
- 总结
前言
在之前的博客中我们学习了【正则表达式】的诸多用法,但是还没有真正在Python代码中使用过。其实Python语言专门提供了 re 模块,用于实现正则表达式的操作。在实现时,可以使用 re 模块提供的方法(如 search()、match()、findall()等)进行字符串处理,也可以先使用 re 模块的 compile() 方法将模式字符串转换为正则表达式对象,然后再使用该正则表达式对象的相关方法来操作字符串,接下来就跟大家介绍一下 re 模块的详细用法。
一、使用 re 模块的前期准备工作
首先我们要知道 re 模块是Python语言内置的,不用额外安装。但在使用时需要先用 import 语句引入该模块,代码如下:
import re
注意:在使用 re 模块时,一定要先 import 语句引入,否则会报错如下图所示。

二、使用 re 模块匹配字符串
re 模块中提供了 match()、search() 和 findall() 等方法专门用来匹配字符串,可以从海量数据中精确筛选出需要的对象,我们逐一来看看每种方法的具体实现。
1. 使用 match() 方法进行匹配
match() 方法用于从字符串的开始处进行匹配,如果在起始位置匹配成功,则返回 Match 对象,否则返回 None。其语法格式如下:
re.match(pattern, string, [flags])
参数说明:
- pattern:表示模式字符串,由要匹配的正则表达式转换而来。
- string:表示要匹配的字符串。
- flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写、是否包括换行等等。常用的标志如下表所示。
| 标志 | 说明 |
|---|---|
| A 或 ASCII | 对于 \w、\W、\b、\B、\d、\D、\s 和 \S 只进行 ASCII 匹配(仅适用于Python3.x) |
| I 或 IGNORECASE | 执行不区分字母大小写的匹配 |
| M 或 MULTILINE | 将 ^ 和 $ 用于包括整个字符串的开始和结尾的每一行(默认情况下,仅适用于整个字符串的开始和结尾处) |
| S 或 DOTALL | 使用(.)字符匹配所有字符,包括换行符 |
| X 或 VERBOSE | 忽略模式字符串中未转义的空格和注释 |
看到表中这么多标志位,有的小伙伴应该已经懵了,这都是啥?

没关系,先通过下图的代码案例给大家细细道来。
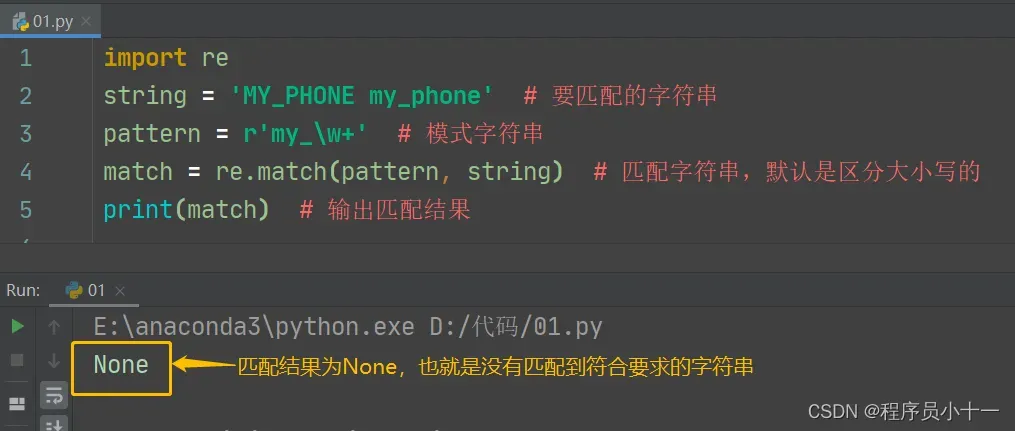
上面代码实现的功能是从给定的字符串 string 中按照指定的 pattern 模式来匹配有没有我们要的结果,pattern 语句中的代码意思是:该语句要以字符串 my_ 开头,\w+ 在之前的博客【Python之正则表达式细讲】中有讲过,是匹配字母、数字、下划线或汉字一次或多次,默认是贪婪匹配,也就是所有符合条件的都会匹配出来。但是结果为 None,也就是没有匹配到,因为待匹配字符串中是以大写字母开头的,而使用正则表达式匹配字符串时,默认是严格区分大小写的。所以如果要不区分字母大小写,就要加上可选参数 flags 来控制匹配方式,使用到标志位 I 或 IGNORECASE。如下图所示:

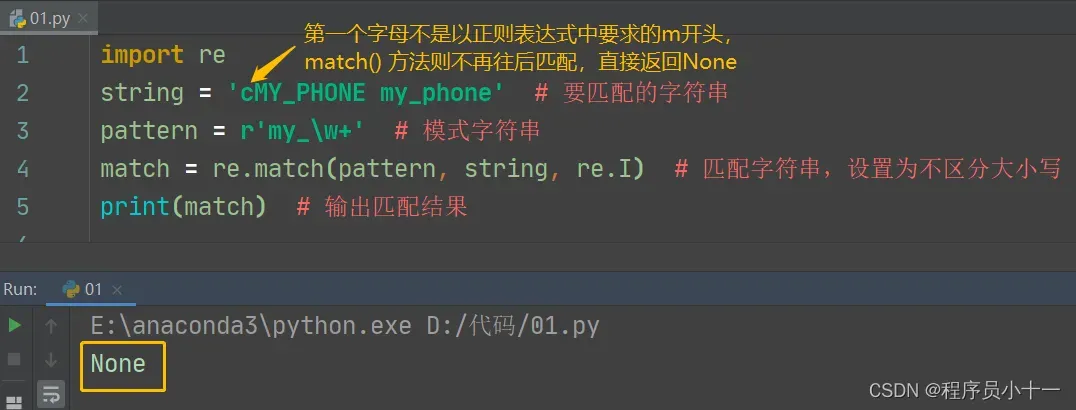
说明:match() 方法从字符串的开始位置开始匹配,一旦当第一个字母不符合条件时,则不再进行匹配,直接返回 None,如下图代码所示。
Match 对象中包含了匹配值的位置和匹配数据。其中,要获取匹配值的起始位置可以使用 Match 对象的 start() 方法;要获取匹配值的结束位置可以使用 end() 方法;通过 span() 方法可以返回匹配位置的元组;通过 string 属性可以获取要匹配的字符串;通过 group() 方法可以返回匹配到的结果。比如如下代码所示:
import re
string = 'MY_PHONE my_phone' # 要匹配的字符串
pattern = r'my_\w+' # 模式字符串
match = re.match(pattern, string, re.I) # 匹配字符串,设置为不区分大小写
print('匹配值的起始位置:', match.start())
print('匹配值的结束位置:', match.end())
print('匹配位置的元组:', match.span())
print('要匹配的字符串:', match.string)
print('匹配数据:', match.group())
代码运行之后结果如下:
匹配值的起始位置: 0
匹配值的结束位置: 8
匹配位置的元组: (0, 8)
要匹配的字符串: MY_PHONE my_phone
匹配数据: MY_PHONE
运行结果中匹配值的结束位置之所以是 8,是因为match() 方法匹配时,如果待匹配字符串中有多个符合规则的结果,也只返回第一个。 而匹配规则中 \w 是匹配字母、数字、下划线和汉字,所以匹配到中间空格那里第一个符合规则的结果就匹配结束了,即使后面有别的符合规则的结果,也不再进行匹配。
2. 使用 search() 方法进行匹配
search() 方法用于在整个字符串中搜索第一个匹配的值,如果匹配成功,则返回 Match 对象,否则返回 None。search() 方法的语法格式如下:
re.search(pattern, string, [flags])
参数说明:
- pattern:表示模式字符串,由要匹配的正则表达式转换而来。
- string:表示要匹配的字符串。
- flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写、是否包括换行等等。
代码示例如下图所示:
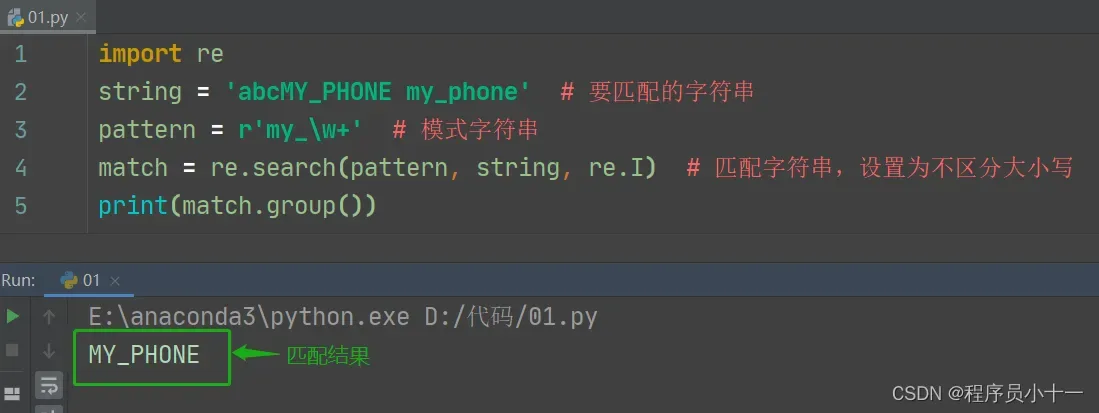
说明:search() 方法不仅是在字符串的起始位置搜索,其他位置上有符合的匹配也可以进行搜索,但是最终不论待匹配字符串中有多少个符合的结果,也只会返回一个。
3. 使用 findall() 方法进行匹配
findall() 方法用于在整个字符串中搜索所有符合正则表达式的字符串,并以列表的形式返回所有符合条件的结果。如果匹配不成功,返回空列表。findall() 方法的语法格式如下:
re.findall(pattern, string, [flags])
参数说明:
- pattern:表示模式字符串,由要匹配的正则表达式转换而来。
- string:表示要匹配的字符串。
- flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写、是否包括换行等等。
代码示例如下图所示:
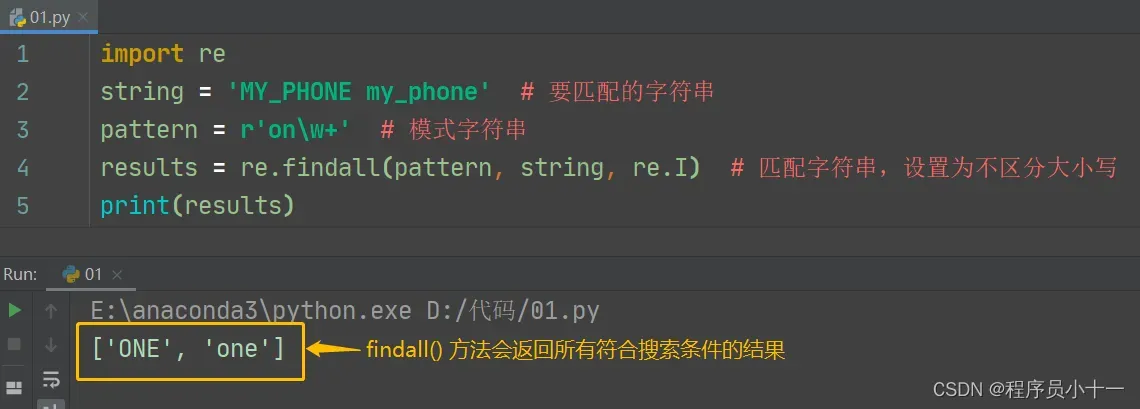
说明:以上三种匹配方法,最常用的还是 findall() 方法,因为 match() 和 search() 均只能返回一个符合的结果。
三、使用 re 模块替换字符串
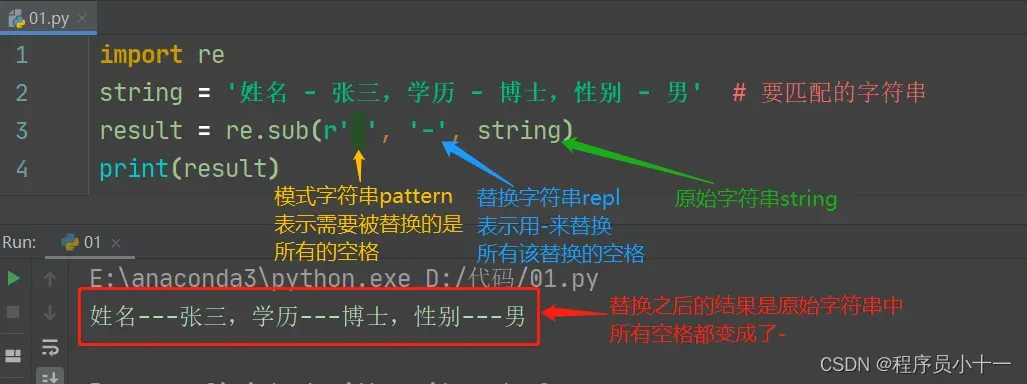
re 模块中的 sub() 方法用于实现字符串替换,语法格式如下:
re.sub(pattern, repl, string, count, flags)
参数说明:
- pattern:表示模式字符串,由要匹配的正则表达式转换而来。
- repl:表示要替换的字符串。
- string:表示要被查找替换的原始字符串。
- count:可选参数,表示模式匹配后替换的最大次数,默认值为 0,表示替换所有的匹配。
- flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写、是否包括换行等等。
代码示例如下图所示:
四、使用 re 模块分割字符串
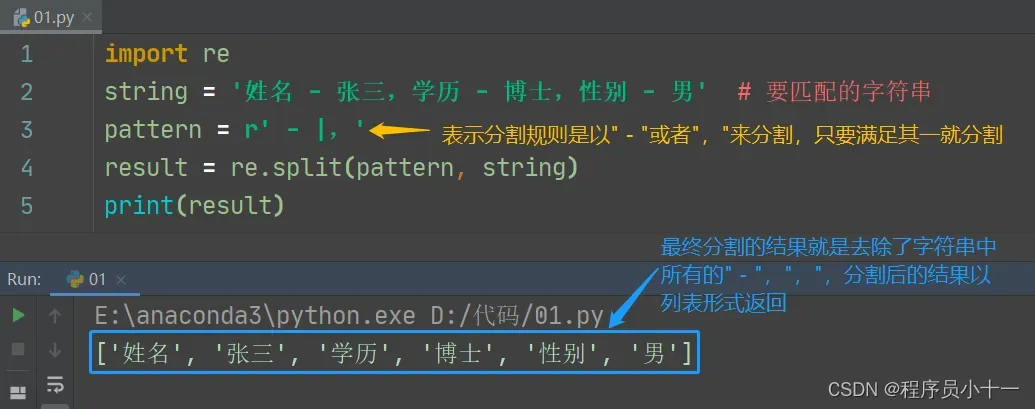
re 模块中的 split() 方法用于实现根据正则表达式分割字符串,并以列表的形式返回。其作用同字符串对象的 split() 方法类似,所不同的就是分割字符由模式字符串指定。split() 方法的语法格式如下:
re.split(pattern, string, [maxsplit], [flags])
参数说明:
- pattern:表示模式字符串,由要匹配的正则表达式转换而来。
- string:表示要匹配的字符串。
- maxsplit:可选参数,表示最大的拆分次数。
- flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写、是否包括换行等等。
代码示例如下图所示:
总结
博客中主要讲解了Python语言中 re 库的各种方法,在之后开发中最常用的就是匹配方法和替换方法,其中匹配方法主要使用 findall()。其实这些用法不难,难的还是其中的模式字符串需要用到的正则表达式搭配,这些正则表达式中各种特殊字符的含义大家要牢记。如果这些还不明白的可以回头看看博主之前的博客【Python之正则表达式细讲】。
文章出处登录后可见!