报错事件发生经过
在训练百度PaddleOCR开发套件的方向识别模型时候踩了一个小坑,通过分析找到问题,文本记录了分析过程,需要解决问题的可以直接看3.1。
1.下载PaddleOCR开发套件。 首先按照Github中PaddleOCR官方文档关于文字方向识别的文档进行准备工作及参数配置。
2.准备数据。 项目中需要识别图片的角度(0、90、180、270度),故准备了数张方向全为0度的图片,通过Pillow库进行随机反转,代码如下:
r = [Image.ROTATE_90, Image.ROTATE_180, Image.ROTATE_270]
degs = ['90', '180', '270']
for fn in tqdm(os.listdir('photo')):
im = Image.open('photo/'+fn).convert('RGB')
i = random.randint(0, 3)
if i > 2:
im.save('photo_rand_rot/'+fn)
with open('label.txt', 'a') as f:
f.write('{}\t{}\n'.format(fn, '0'))
else:
im = im.transpose(r[i])
im.save('photo_rand_rot/'+fn)
with open('label.txt', 'a') as f:
f.write('{}\t{}\n'.format(fn, degs[i]))
3.配置YAML文件并运行。 运行命令如下:
python tools/train.py -c .\configs\cls\cls_mv3.yml
在加载数据步骤时,提示报错:RecursionError: maximum recursion depth exceeded while calling a Python object
[2022/08/07 23:38:59] ppocr INFO: train dataloader has 234 iters
[2022/08/07 23:38:59] ppocr INFO: valid dataloader has 19 iters
[2022/08/07 23:38:59] ppocr INFO: During the training process, after the 0th iteration, an evaluation is run every 400 iterations
Exception in thread Thread-3:
Traceback (most recent call last):
File "D:\XXX\cls\PaddleOCR-release-2.5\ppocr\data\simple_dataset.py", line 138, in __getitem__
data['image'] = img
RecursionError: maximum recursion depth exceeded while calling a Python object
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\zhy\anaconda3\lib\threading.py", line 973, in _bootstrap_inner
File "C:\Users\zhy\anaconda3\lib\threading.py", line 910, in run
self._target(*self._args, **self._kwargs)
File "C:\Users\zhy\anaconda3\lib\site-packages\paddle\fluid\dataloader\dataloader_iter.py", line 217, in _thread_loop
batch = self._dataset_fetcher.fetch(indices,
File "C:\Users\zhy\anaconda3\lib\site-packages\paddle\fluid\dataloader\fetcher.py", line 121, in fetch
data.append(self.dataset[idx])
File "D:\XXX\cls\PaddleOCR-release-2.5\ppocr\data\simple_dataset.py", line 150, in __getitem__
return self.__getitem__(rnd_idx)
File "D:\XXX\cls\PaddleOCR-release-2.5\ppocr\data\simple_dataset.py", line 150, in __getitem__
return self.__getitem__(rnd_idx)
File "D:\XXX\cls\PaddleOCR-release-2.5\ppocr\data\simple_dataset.py", line 150, in __getitem__
return self.__getitem__(rnd_idx)
[Previous line repeated 987 more times]
File "D:\XXX\cls\PaddleOCR-release-2.5\ppocr\data\simple_dataset.py", line 144, in __getitem__
data_line, traceback.format_exc()))
File "C:\Users\zhy\anaconda3\lib\traceback.py", line 167, in format_exc
return "".join(format_exception(*sys.exc_info(), limit=limit, chain=chain))
File "C:\Users\zhy\anaconda3\lib\traceback.py", line 120, in format_exception
return list(TracebackException(
File "C:\Users\zhy\anaconda3\lib\traceback.py", line 476, in __init__
_seen.add(id(exc_value))
RecursionError: maximum recursion depth exceeded while calling a Python object
查找问题
1.经常解决递归达到最大问题。
直观的问题在于报错信息:maximum recursion depth exceeded,也就是字面意思,递归达到最深,这个问题百度上有很多解决方案,大致的意思相同:Python默认的最大递归深度是1000,通过下面的方式可以设置最大递归深度。
打开PaddleOCR下的ppocr\data\simple_dataset.py,头部增加:
import sys
sys.setrecursionlimit(3000) #设置递归深度
暂时设置为3000,问题依然存在,考虑项目数据共计12w张图像(压缩后22GB大小),将深度调整为一个巨大的数,10000000,但在程序在本地PC上因内存溢出直接崩溃,本地Windows PC的RAM为48G,理论来说即便所有数据放在内存中也是足够的,抱着试一试的心态,尝试在服务器上使用128G内存依然溢出崩溃,附一个Linux上的报错信息:
[2022/08/08 00:46:45] ppocr INFO: During the training process, after the 0th iteration, an evaluation is run every 400 iterations
Traceback (most recent call last):
File "tools/train.py", line 188, in <module>
Exception in thread Thread-1:
Traceback (most recent call last):
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py", line 620, in _get_data
data = self._data_queue.get(timeout=self._timeout)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/multiprocessing/queues.py", line 105, in get
raise Empty
_queue.Empty
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/threading.py", line 926, in _bootstrap_inner
self.run()
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py", line 534, in _thread_loop
batch = self._get_data()
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py", line 636, in _get_data
"pids: {}".format(len(failed_workers), pids))
RuntimeError: DataLoader 1 workers exit unexpectedly, pids: 5503
main(config, device, logger, vdl_writer)
File "tools/train.py", line 163, in main
eval_class, pre_best_model_dict, logger, vdl_writer, scaler)
File "/home/aistudio/PaddleOCR/tools/program.py", line 238, in train
for idx, batch in enumerate(train_dataloader):
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py", line 746, in __next__
data = self._reader.read_next_var_list()
SystemError: (Fatal) Blocking queue is killed because the data reader raises an exception.
[Hint: Expected killed_ != true, but received killed_:1 == true:1.] (at /paddle/paddle/fluid/operators/reader/blocking_queue.h:166)
2.对PaddleOCR相关源码进行分析。
已知问题出在某处递归上,初步分析,可能是源码中的某处代码或者错误触发了死循环,导致不停的调用“自己”导致内存溢出,根据错误信息,问题出现在ppocr\data\simple_dataset.py下的特殊方法__getitem__中,分析该方法的代码,果然发现了一处递归。
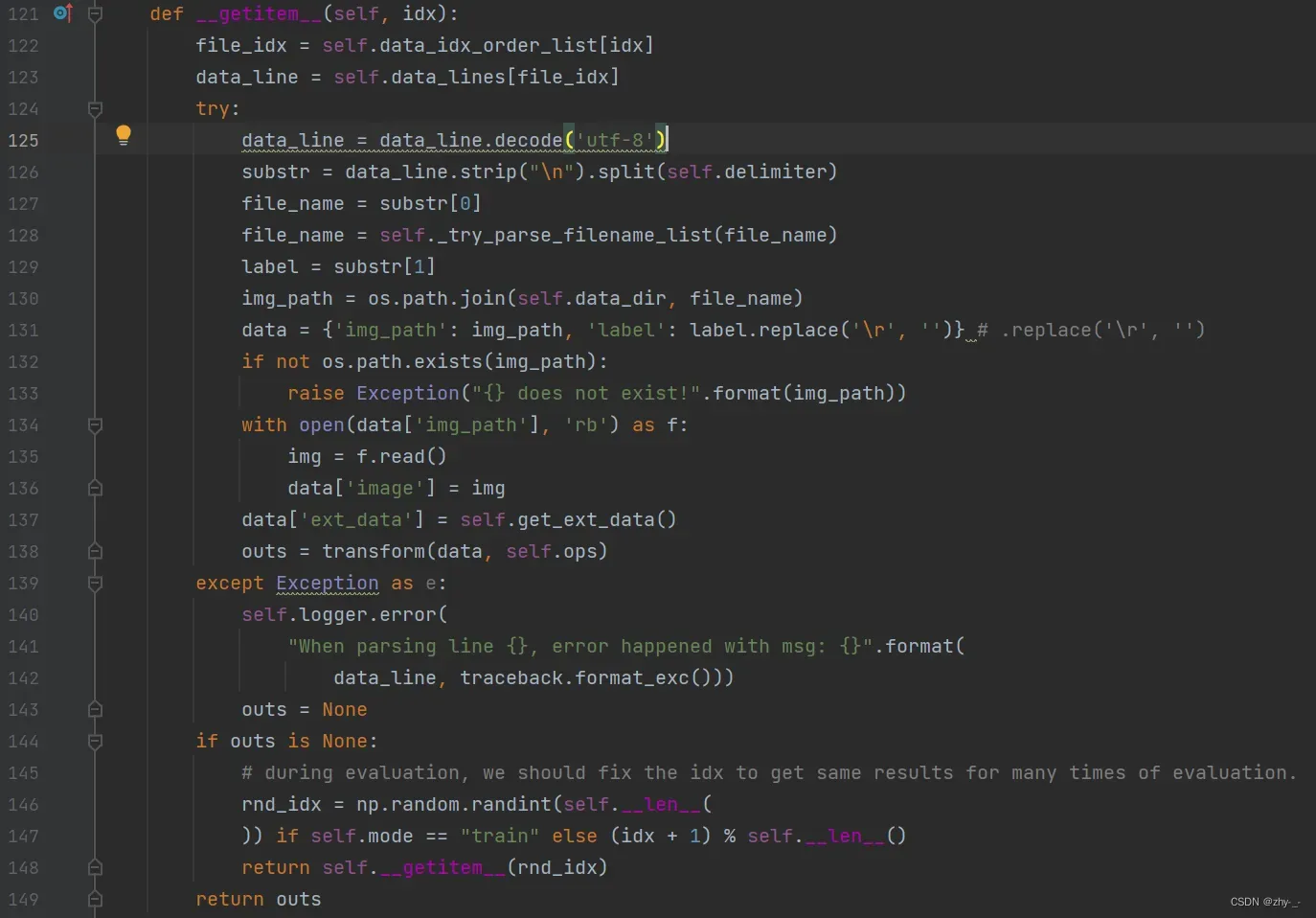
try…except…中是根据txt文件对每个图片数据进行处理的代码,若一切无误则返回一个outs字典,若捕捉到错误则outs为None,且outs为None时,会随机拿一个数据补上这个数据,若随机拿的数据一直是错误,这个递归就会陷入死循环,以抵达最大深度或内存溢出结束。
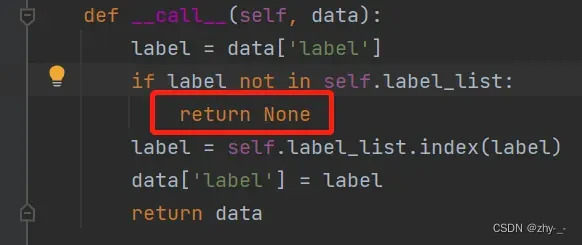
通过追踪data变量可以发现,发现错误出现在标注文本中,原本的0、90、180、270都莫名其妙的多了一个\r,导致ops中的ClsLabelEncode无法进行检索,ClsLabelEncode代码在ppocr\data\imaug\label_ops.py的ClsLabelEncode类中,无法检索到则返回None,导致所有的图片的类型都匹配失败。
解决问题
1.解决方案
如果你的标签里没有\r,你又不想动数据,则直接简单粗暴的把\r替换为空。代码在ppocr\data\simple_dataset.py的130行:
data = {'img_path': img_path, 'label': label} # 修改前
data = {'img_path': img_path, 'label': label.replace('\r', '')} # 修改后
2.\r哪里来的,为什么会这样呢?
源码中,ppocr\data\simple_dataset.py下的get_image_info_list方法是读取txt文件的代码:
with open(file, "rb") as f:
lines = f.readlines()
因为源码中以rb方式打开了txt文件,导致读取时多了一个\r,具体的解释在这里可以找到。
3.为什么训练检测模型和识别模型时候不会报错?
对于标签的处理代码,在ppocr\data\imaug\label_ops.py中,分析可知:
检测模型是DetLabelEncode类,检测图像的标签是json数据,而代码中的json.loads()方法会自动忽略结尾的\r。
识别模型是CTCLabelEncode类,类中存在一个encode方法来检查字符是否在规定的字典中,\r一般不会在字典中所以被忽略了。
爆雷的只有没有经过处理的方向识别模型了。
总结
1.这并不算PaddleOCR的BUG,只能说没有考虑到所有情况。
2.个人不了解open函数r和rb的基础知识(也可能选择性忘记了)。
文章出处登录后可见!