Stable Diffusion环境搭建与运行请参考上一篇博文《AI图片生成Stable Diffusion环境搭建与运行》,地址为“https://blog.csdn.net/suiyingy/article/details/128896426”。运行成功后,网页浏览器显示页面主要包括txt2img、img2img、Extras、PNG Info、Checkpoint Merger、Train、Settings和Extensions等八个部分,下面将分别进行介绍。另外,本专栏具体更新可关注文章下方公众号,也可关注本专栏。所有相关文章会在《Python从零开始进行AIGC大模型训练与推理》中进行更新,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。

图1 Stable Diffusion生成效果图
1 txt2img
txt2img是指文生图,即根据文字描述生成图片,其页面如下图所示。
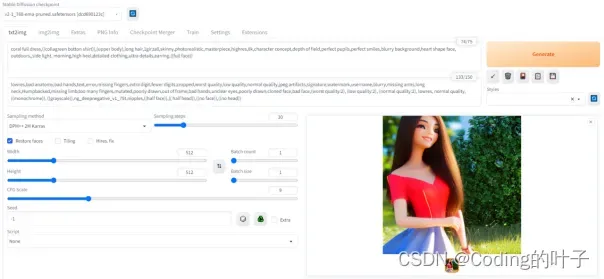
图2 txt2img
完整设置示例如下:
Prompt: coral full dress,((collagreen botton shirt)),(upper body),long hair,1gir,tall,skinny,photorealistic,masterpiece,highres,8k,character concept,depth of field,perfect pupils,perfect smiles,blurry background,heart shape face, outdoors,,side light, morning,high heel,detailed clothing,ultra details,earring,((full face))
Negative prompt: lowres,bad anatomy,bad hands,text,error,missing fingers,extra digit,fewer digits,cropped,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark,username,blurry,missing arms,long neck,Humpbacked,missing limb,too many fingers,mutated,poorly drawn,out of frame,bad hands,unclear eyes,poorly drawn,cloned face,bad face,(worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)),ng_deepnegative_v1_75t,nipples,((half face)),(( half head)),((no face)),((no head))
Steps: 30, Sampler: Euler, CFG scale: 9, Restore faces, Size: 512×512, Model hash: dcd690123c, Model: v2-1_768-ema-pruned.safetensors, Seed: 4171216357, Script: X/Y/Z plot, X Type: Steps, X Values: “10,20,30”, Y Type: Sampler, Y Values: “Euler a, Euler”。
1.1 Stable Diffusion checkpoint
Stable Diffusion checkpoints用于选择当前加载的模型,模型设置与加载可参考上一篇博文《AI图片生成Stable Diffusion环境搭建与运行》,地址为“https://blog.csdn.net/suiyingy/article/details/128896426”。用户可根据需要在hugging face网站下载以.safetensors为后缀的模型文件。
这里需要注意,不同模型生成的图片风格也会有差别,比如漫画风格或写实风格。除Stable Diffusion官方模型之外,程序还支持chilloutmix_Ni、anything-v4.5-pruned、dreamshaper_33、protogenV22Anime_22、artErosAerosATribute_aerosNovae和cheeseDaddys_35等模型。
网络上有很多生成效果比较好的作品,如果用户在相同prompt下得到的效果相差较大,那么很有可能是使用不同模型所导致的。
1.2 Prompt
Prompt是对所希望生成的图片的文本描述,一般使用英文描述可以获得更好的生成结果。不同文字描述内容得到的结果也是完全不一样的,甚至大部分时候用户需要集中精力在写出一个合适的prompt。从另一方面来看,如果用户设置的prompt描述不能被模型很好地理解,那么模型给出的生成结果也会严重偏离预期,以至于部分用户认为模型本身出了问题或者模型效果不好。
如果对模型生成的图片没有额外要求,那么我们只需要在prompt输入简单的图片描述即可,例如“为AIGC小程序RdFast设计一款商标”。但是,如果我们希望得到更好的生成图片,prompt需遵循一定的设计规则。
下面的设计规则介绍来源于《AI绘画指南 stable diffusion webui (SD webui)如何设置与使用》,地址为“https://www.tjsky.net/tutorial/488”。
(1)分隔:不同的关键词tag之间,需要使用英文逗号,分隔,逗号前后有空格或者换行没有影响。例如:1girl,loli,long hair,low twintails(1个女孩,loli,长发,低双马尾)。
(2)混合:WebUi 使用 | 分隔多个关键词,实现混合多个要素,注意混合是同等比例混合,同时混。例如: 1girl,red|blue hair, long hair(1个女孩,红色与蓝色头发混合,长发)
(3)增强/减弱:有两种写法
第一种 (提示词:权重数值):数值从0.1~100,默认状态是1,低于1就是减弱,大于1就是加强。例如: (loli:1.21),(one girl:1.21),(cat ears:1.1),(flower hairpin:0.9)。
第二种 (((提示词))),每套一层()括号增强1.1倍,每套一层[]减弱1.1倍。也就是套两层是1.1*1.1=1.21倍,套三层是1.331倍,套4层是1.4641倍。例如: ((loli)),((one girl)),(cat ears),[flower hairpin]和第一种写法等价。
(4)渐变:比较简单的理解时,先按某种关键词生成,然后再此基础上向某个方向变化。[关键词1:关键词2:数字],数字大于1理解为第X步前为关键词1,第X步后变成关键词2,数字小于1理解为总步数的百分之X前为关键词1,之后变成关键词2。例如:a girl with very long [white:yellow:16] hair 等价为“开始 a girl with very long white hair”,16步之后“a girl with very long yellow hair”。“a girl with very long [white:yellow:0.5] hair ”等价为“开始 a girl with very long white hair”,50%步之后“a girl with very long yellow hair”。
(5)交替:轮流使用关键词。例如:[cow|horse] in a field,这就是个牛马的混合物,如果你写的更长比如[cow|horse|cat|dog] in a field就是先朝着像牛努力,再朝着像马努力,再向着猫努力,再向着狗努力,再向着马努力。
Prompt示例:
coral full dress,((collagreen botton shirt)),(upper body),long hair,1gir,tall,skinny,photorealistic,masterpiece,highres,8k,character concept,depth of field,perfect pupils,perfect smiles,blurry background,heart shape face, outdoors,,side light, morning,high heel,detailed clothing,ultra details,earring,((full face))1.3 Negative prompt
Prompt描述的是用户希望生成的图片的特征,而Negative prompt则是生成的图片中不希望含有的特征,例如低质量图片等。Stable Diffusion大致做法为:
(1)对图片进行去噪处理,使其看起来更像你的提示词。
(2)对图片进行去噪处理,使其看起来更像你的反向提示词(无条件条件)。
(3)观察这两者之间的差异,并利用它来产生一组对噪声图片的改变。
(4)尝试将最终结果移向前者而远离后者。
Negative prompt示例:
lowres,bad anatomy,bad hands,text,error,missing fingers,extra digit,fewer digits,cropped,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark,username,blurry,missing arms,long neck,Humpbacked,missing limb,too many fingers,mutated,poorly drawn,out of frame,bad hands,unclear eyes,poorly drawn,cloned face,bad face,(worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)),ng_deepnegative_v1_75t,nipples,((half face)),(( half head)),((no face)),((no head))1.4 Sampling Method
采样方法与Stable Diffusion模型工作原理直接相关,本专栏后续将会详细介绍其中原理。采样方法主要影响生成图片的时间和风格偏好。网址“https://cj.sina.com.cn/articles/view/1823348853/6cae1875020018im7”有详细的实验结果。
常用的采样方法为Euler a、Euler、DDIM、LMS、PLMS和DPM2。一般选用默认采样方式即可。
1.5 Sampling Steps
采样步骤默认设置成20。如果生成图片细节不满足要求,可适当增加采样步骤,但生成时间也会相应增加。大部分采样器超过50步后意义就不大了。
1.6 Restore faces
面部修复,使面部更像真人的人脸。一般面部修复的模型有CodeFormer和GFPGAN。
1.7 Tiling
生成可平铺的图片图案,直接效果为图片上下和左右部分是可以拼接的,类似瓷砖图案。

图3 Tiling图片
1.8 Hires. Fix
txt2img 在高分辨率下(1024X1024)会生成非常怪异的图像。而此插件这使得AI先在较低的分辨率下部分渲染你的图片,再通过算法提高图片到高分辨率,然后在高分辨率下再添加细节。
1.9 Width/Height
图像的宽高分辨率,即图像尺寸大小。尺寸越大,所需显存越大。因为常见的模型基本都是在512×512和768×768的基础上训练,分辨率过高,图片质量会随着分辨率的提高而变差。
1.10 CFG Scale
图像与Prompt内容的匹配程度。增加这个值将导致图像更接近你的描述,但过高会让图像色彩过于饱和,太高后在一定程度上降低了图像质量。可以适当增加采样步骤来抵消画质的劣化。一般在5~15之间为好,7、9、12是3个常见的设置值。
低CFG:图片糊、看起来雾蒙蒙的,色彩对比弱,构图也比较差。
高CFG:图片对比度非常强,色彩非常饱和,甚至会过饱和,颜色和结构失调。
1.11 Batch count / Batch size
这两个参数本质上都是控制输出图片的数量。Batch count是顺序生成的,而Batch size是控制并行生成的,因此后者生成速度更快,但占用显存更大。
1.12 Seed
Seed默认取值为-1,每次生成的图片差异性较大,即随机生成的。将seed设置成一个固定取值后,每次生成的图片会比较接近,这样可以调整prompt来实现对生成结果的微调。
1.13 Script
Script是相当于同时设置多个条件,便于对多个条件生成结果进行对比。例如, Script: X/Y/Z plot, X Type: Steps, X Values: “10,20,30”, Y Type: Sampler, Y Values: “Euler a, Euler”,这种设置包括三种采样次数和两种采样方式,因此会生成6张图片,如下图所示。具体使用方式可参考“https://zhuanlan.zhihu.com/p/600821549”。
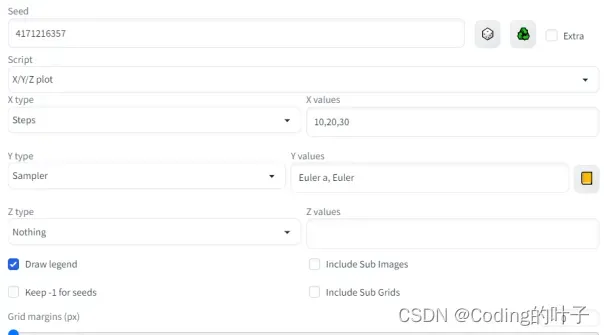
图4 多条件对比设置

图5 多条件结果对比
1.14 Styles
在“Generate”按钮下方有一个“Save style”小图标,它可以把当前prompt内容保存为一种风格样式,便于后续通过Styles进行加载复用。
2 参考资料
本文介绍参考了以下网站内容,感谢相关作者的详细解析。
(1)《AI绘画指南 stable diffusion webui (SD webui)如何设置与使用》,“https://www.tjsky.net/tutorial/488”,文中内容大部分来源于此。
(2)《stable-diffusion-webui prompt语法详解》,“https://zhuanlan.zhihu.com/p/600821549”。
(3)《扩散模型采样方法:从效果看Stable Diffusion中的采样方法》,“https://cj.sina.com.cn/articles/view/1823348853/6cae1875020018im7”。
(4)《stable-diffusion各个采样器的说明》,“http://www.codeforest.cn/article/3578”。
(5)《[Stable Diffusion 疑难杂症] CFG、采样方式、高清修复、ControlNet》,“https://zhuanlan.zhihu.com/p/610346261”。
(6)《从耗时看Stable Diffusion WebUI中的采样方式》 ,“https://post.smzdm.com/p/akk8zv5r/”。
3 其它部分
img2img、Extras、PNG Info、Checkpoint Merger、Train、Settings和Extensions等部分将在下一篇博文中进行介绍。本专栏具体更新可关注文章下方公众号,也可关注本专栏。所有相关文章会在《Python从零开始进行AIGC大模型训练与推理》中进行更新,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。
文章出处登录后可见!