第一章
关于Python的缺点以下哪个描述是错误的?
Python 2.x和Python 3.x兼容
关于Python语言的应用,以下哪个描述是错误的?
scikit-learn是Python自然语言工具包,用于诸如标记化、词形还原、词干化、解析、POS标注等任务。
Jupyter Notebook (anaconda3)中的常用快捷键中,用于表示”分割单元”的快捷键是
Ctrl+Shift±
下面关于程序注释的描述错误的是
Python中使用“#”表示多行注释。
Python 程序文件的扩展名是
.py
下面哪些属于 Python 语言的特点?
A.解释执行
B.开源
C.支持函数式编程
D.跨平台
下面能够支持 Python 开发的环境有哪些?
A.IDLE
B.Anaconda3
C.PyCharm
D.Eclipse
下面哪些是正确的 Python 标准库对象导入方式?
A. from math import *
B. from math import sin
Python 是由荷兰人Guido van Rossum开发的。
√
Python 是一种面向对象语言
√
由于 Python 不具有可移植性,因此 Python 编写的程序只能在特定平台上执行。
×
缩进是 Python 的编码规范之一,Python 每个缩进级别为 4 个空格,可使用一个Tab键代替, 但禁止其与空格混用。
√
Python 解释器安装完成后,在 Windows 或 Linux 的命令行中输入python命令,可进入 Python 解释器。
√
Python 具有丰富的第三方库。
√
Python 2 与 Python 3 中的异常处理方式相同。
×
PyCharm 是一个完全免费的 IDE 工具。
×
第二章
已知 a=3, b=5,下列计算结果错误的是( )。
a<<b 的值为 96
以下关于 Python 语句的叙述中,正确的是( )
同一层次的 Python 语句必须对齐
访问字符串中的部分字符的操作称为( )。
切片
关于 Python 中的复数,下列说法错误的是( )。
实部和虚部都必须是浮点数
关于 Python 字符串类型的说法中,下列描述错误的是( )。
Python 中单引号与双引号不可一起使用
Python 的数字类型包含整型、浮点型、复数型、布尔型。
√
布尔类型是一种特殊的整型。
√
Python 中的浮点数是由实部和虚部组成的。
×
Python 表达式1//3+1//3+1//3 的值为0.0
×
Python 中的整型可以使用二进制、八进制、十进制、十六进制表示。
√
浮点型不可与复数类型数据进行计算。
×
使用切片操作字符串其起始位置只能从 1 开始。
×
在 Python 中可以使用“<>” 表示不等于。
×
Python 运算符中用来计算整商的是//
√
Python 运算符中用来计算集合交集的是|
×
Python 3.x 语句 print(1, 2, 3, sep=‘:’)的输出结果为1:2:3:
×
表达式 len(zip([1,2,3], ‘abcdefg’))的值为 3
×
已知 x = 3,那么赋值语句 x = ‘abcedfg’是无法正常执行的。
×
0o12f 是合法的八进制数字
×
x = 9999**9999 这样的语句在 Python 中无法运行,因为数字太大了超出了整型变量的表示范围。
×
Python 变量使用前必须先声明,并且一旦声明就不能在当前作用域内改变其
类型了。
×
第三章
下列方法中,可以对列表元素排序的是()
sort()
对于列表L=[1,2,‘Python’,[1,2,3,4,5]],L[-3]指的是()
2
下列命令、方法中,默认删除列表的最后一个元素的是()
pop()
下列Python程序的运行结果是()
[4, 0, 6]
下列语句中,可以正确创建元组的语句是()
tu_three = (‘on’,)
下列方法中,可以获取字典中所有键的是()
keys()
对于字典D={‘A’:10,‘B’:20,‘C’:30,‘D’:40},对第4个字典元素的访问形式是()
D[‘D’]
下列方法中,不能删除字典中元素的是()
remove()
Python语句print(type({1:1,2:2,3:3,4:4}))的输出结果是
<class ‘dict’>
下列语句中,可以正确创建字典的是()
test_two = {‘a’: ‘A’}
已知x = list(range(10)),则表达式x[-4:]的值为[5, 6, 7, 8, 9]
×
表达式[index for index, value in enumerate([3,5,3,7]) if value==3]的值为[0, 2]。
√
表达式len(set([3,5,3,7,3,9]))的值为4。
√
列表可以作为集合的元素
×
已知x = [1, 2, 1, 2, 1],那么执行语句x.remove(1)之后,x的值为[2, 2]
×
已知 x = [1, 3, 5, 7, 9, 11],那么执行语句 x[:3] = reversed(x[:3]) 之后,x的值为 [5, 3, 1, 7, 9, 11]。
√
表达式(i**2 for i in range(100))的结果是个元组。
×
设有列表L=[1,2,3,4,5,6,7,8,9],则L[-1:-1-len(L):-1]的值是[9, 8, 7, 6, 5, 4, 3, 2, 1]。
√
在Python中,字典和集合都使用大括号作为定界符。
×
设有s1={1,2,3},s2={2,3,5},则s1.update(s2)执行后,s1的值为{1, 2, 3, 5}。
√
第四章
在 Python 中,实现多分支选择结构的较好方法是( )。
if…elif…else
关于 while 循环和 for 循环的区别,下列叙述中正确的是( )。
在很多情况下, while 语句和 for 语句可以等价使用
下列关于 for 循环的描述,说法正确的是( )。
for 循环可以遍历可迭代对象
请分析下面的程序,若输入score为74,输出的grade是( )。
x = int(input(“input scor:”))
if x >= 60:
grade = ‘D’
elif x >= 70:
grade = ‘C’
elif x >= 80:
grade = ‘B’
else:
grade = ‘A’
print(grade)
D
有如下程序段:
a, b, c = 70, 50, 30;
if(a>b):
a = b
b = c
c = a
print(a, b, c)
程序的输出结果为( )。
\newline
以下可以终结一次循环的保留字是( )。
continue
设有程序段:
k = 10
while k == 0:
k = k-1
下列说法正确的是( )。
循环不执行
下列程序可以正常结束的是( )。
i = 5
while (i>0):
i -= 1
下列程序的输出结果为( )。
s, t, u = 0, 0, 0
for I in range(1, 4):
for j in range(1, i+1):
for k in range(j, 4):
s += 1
t += 1
u += 1
print(s, t, u)
14 6 3
执行下列程序后,k的值为( )。
k = 1
n = 263
while n:
k *= n % 10
n //= 10
36
流程图是描述算法的常用工具。
√
当循环结构的循环体由多个语句构成时,必须用缩进对齐的方式组成一个语句块。
√
Python 中的循环语句有for循环和if循环。
×
Python 中使用关键字while表示条件语句。
×
当 if表达式为True会跳过执行语句。
×
Python 中 break 和 continue 语句可以单独使用。
×
if…else 语句可以处理多个分支条件。
√
if…else 语句可以处理多个分支条件。
√
if 语句最多可以嵌套两层。
×
if 语句最多可以嵌套两层。
√
第五章
下列关于函数参数的说法中,错误的是( )
*args 以字典保存不定数量的关键字参数
阅读下面程序:
num_one = 12
def sum(num_two):
global num_one
num_one = 90
return num_one + num_two
print(sum(10))
运行代码,输出结果是( )。
100
阅读下面程序:
def many_param(num_one, num_two, *args):
print(args)
many_param(11, 22, 33, 44, 55)
运行代码,输出结果是( )。
(33,44,55)
已知 f=lambda x,y:x+y,则 f([4],[1,2,3])的值是( )。
已知 f=lambda x,y:x+y,则 f([4],[1,2,3])的值是( )。
以下哪个不是定义函数的目的?( )
增加代码量
假设某个函数的函数体只有以下一行,请选择不返回None的选项。( )
return 0
向函数传递参数时,存在不可变对象和可变对象两种类型,不考虑在函数体内重新定义x的情况下,以下哪个函数内部可能会改变参数x的值?( )
x = [‘test’];func(x)
以下关于不定长参数说法错误的是( )。
+parameter类似*parameter,但是+表示至少有一个参数。
以下哪个不是函数的参数类型?( )
定长参数
关于函数作用域的说法哪个是正确的?( )
不可变对象的全局变量可以通过global定义后在函数体内赋值使用。
关于定义函数的规则以下描述错误的是( )
函数名部分以func关键字开头,后接函数标识符名称和圆括号,以冒号结尾。
函数执行语句“return [1,2,3],4” 后,返回值是[1,2,3],4;没有 return 语句的函数将返回None。
×
使用关键字global可以在一个函数中设置一个全局变量。
√
函数首部以关键字define开始,最后以冒号结束。
×
设有 f=lambda x,y:{x:y},则 f(5,10)的值是(5:10)。
×
函数可以提高代码的复用性。( )
√
全局变量在所有的函数中都可以使用。( )
√
函数的位置参数有严格的位置关系。( )
√
函数中的默认参数不能传递实参。( )
×
函数执行结束后,其内部的局部变量会被回收。( )
√
第六章
下列说法中不正确的是( )。
在 Python 中,一个子类只能有一个父类
下列选项中不是面向对象程序设计基本特征的是( )
可维护性
下列方法中,用于初始化属性的方法是( )。
init
阅读下面程序:
class Test:
count = 21
def print_num(self):
count = 20
self.count+=20
print(count)
test= Test()
test.print_num()
运行程序,输出的结果是()。
20
下列程序的执行结果是( )。
class C():
f=10
class C1(C):
pass
print(C.f,C1.f)
10 10
关于面向过程和面向对象,下列说法错误的是( )。
面向过程是基于面向对象的。
Python中定义私有属性的方法是( )。
使用__XX定义属性名
下列选项中,与class Animal()等价的是( )。
class Animal(object)
以下哪一选项是用来标识静态方法的?( )
@staticmethod
下列方法中,不可以使用类名访问的是( )。
实例方法
一个类只能创建一个实例化对象。
×
构造方法会在创建对象的时候自动调用。
√
构造方法会在创建对象的时候自动调用。
√
对象的引用计数器的值为 0 时会调用析构方法。
√
定义类时一般把数据成员定义为私有的,成员方法定义为公有的,不能把成员方法定义为私有的。
×
Python语言中没有任何方法可以在类的外部访问对象的私有成员。
×
Python语言中定义类的私有成员时需要明确使用关键字private进行说明。
×
在 Python 语言中定义类时,不论类的名字是什么,构造方法的名字总是__init__()
√
在Python语言中定义类时,特殊方法__contains__()对应的运算符是in
√
Python 语言中用来定义类的关键字是def
×
第七章
以下哪个选项属于字符串?( )
“str”
在非长字符串中,换行符就当如何表示?( )
\n
在长字符串中,如何不显示换行符?( )
行尾加\
在字符串“pYthOn”中,索引为-3的字符是什么?( )
h
对字符串stri = ”python”切片时,以下哪种写法会返回空字符串?( )
stri[-2:-3]
有用户输入了一串名字,用逗号隔开。现在需要使用Python验证其中每个姓名是否都以“张“字开头。那么以下哪种思路是正确的?( )
用split函数将字符串拆开,判断所有子串索引为0的位置是否为“张“字。
在以下格式字符串中,哪种写法不能用来格式化整数10?( )
{:#.2}
以下哪种文件打开后可能有乱码?( )
以Unicode保存,以GBK打开。
有一个列表a_list=[‘www’,’cdut’,’edu’,’cn’],如果要得到一个字符串’www.cdut.edu.cn’并输出,可以使用以下哪条语句?( )
print(“.”.jion(a_list))
有一个字符串string = “Hadoop is good”,现在需要将字符串里的Hadoop替换成hadoop,可以使用以下哪条语句来实现?( )
string.replace(‘Hadoop’,’hadoop’)
表达式 len(‘人生苦短,我用 Python’)的值为13
×
表达式’apple,peach,peach’.rindex(‘pe’)的值为6
×
表达式’abc’ in ‘abdc’的值为Flase
√
使用切片操作字符串其起始位置只能从 1 开始。( )
×
字符串是可迭代对象,可用for循环遍历每一个元素。( )
√
第八章
假设已导入正则表达式模块 re,已知:
s = '<html><head>This is head.</head><body>This is body.</body></html>' 和
pattern = r'<html><head>(.+)</head><body>(.+)</body></html>'
那么表达式 re.findall(pattern, s) 的值为( )。
[(‘This is head.’, ‘This is body.’)]
假设已导入正则表达式模块 re,那么表达式 max(re.findall(‘\d+’, ‘abc1d22e333fg’), key=len, default=‘no’) 的值为( )。
‘333’
假设已导入正则表达式模块 re,且有 example = r’one1two2three3four4five5555six6seven7eight88nine999ten’,那么表达式 len(re.split(‘\d+’, example)) 的值为( )。
10
下列关于正则表达式的说法中,错误的是( )。
只有通过预编译的字符串才能使用正则表达式
下列关于元字符功能的说法,错误的是( )。
“*”字符表示匹配 1 次或多次
下列函数中,用于文本分割的是( )。
split()
下列关于 re 模块中函数或方法的说明中,正确的是(D)。
A.split()将目标对象使用正则对象分割,成功则返回匹配对象(是一个列表),可指定最大分割次。
B.finditer()与 findall()功能相同,但返回的是迭代器对象 iterator。
C.compile()对正则表达式进行预编译,并返回一个 Pattern 对象。
> D.以上全部
使用“\d”匹配字符串“Python123”,匹配结果可能是( )。
1
以下各个选项里,哪个不全是正则表达式的特殊字符?( )
\、/
re模块的compile()方法的原型是”re.compile(pattern,flags=0)”,对于可选参数flags的各种可能取值,以下说法错误的是( )。
可使用re.D或者re.DOTALL要求特殊字符”.”可匹配换行符在内的所有字符。
正则表达式模块 re 的 match()函数是从字符串的开始匹配特定模式,而search()函数是在整个字符串中寻找模式,这两个函数如果匹配成功则返回 Match 对象,匹配失败则返回空值 None。( )
√
正则表达式’^\d{18}|\d{15}$’只能检查给定字符串是否为 18 位或 15 位数字字符,并不能保证一定是合法有效的身份证号。( )
√
正则表达式元字符’\d’用来匹配任意空白字符。( )
×
假设已导入模块 re,那么表达式 len(re.split(‘.+’, ‘alpha.beta…gamma…delta’))的值为4。( )
√
假设已导入模块 re,那么表达式 ‘’.join(re.split(‘[sd]’,‘asdssfff’)) 的值为’assfff’。( )
×
当在字符串前加上小写字母f或大写字母F时表示原始字符串,不对其中的任何字符进行转义。( )
×
已知 text = ‘111a22bb3ccc’,并且已导入正则表达式模块 re,那么表达式 len(re.split(‘[abc]+’, text))的值为3。( )
×
假设正则表达式模块 re 已导入,那么表达式 re.sub(‘\d+’, ‘1’, ‘a12345bbbb67c890d0e’)的值为’a1bbbb1c1d1e’。( )
√
split()方法分割的子项会保存到元组中。( )
×
re 模块中提供的 split()方法可使用与正则表达式模式相同的字符串分割指定文本。( )
√
第九章
在读写文件之前,用于创建文件对象的函数是( )。
open
下列关于文件读取的说法,错误的是( )。
readlines()以元组形式返回读取的数据
下列程序的输出结果是( )。
f=open('c:\\out.txt','w+')
f.write('Python')
f.seek(0)
c=f.read(2)
print(c)
f.close()
Py
下列程序的输出结果是( )。
f=open('f.txt','w')
f.writelines(['Python programming.'])
f.close()
f=open('f.txt','rb')
f.seek(10,1)
print(f.tell())
10
下列语句的作用是( )。
>>> import os
>>> os.mkdir("d:\\ppp")
在 D 盘根文件夹下建立 ppp 文件夹
以下哪种介质不能持久化保存数据?( )
CPU高速缓存
除了保存为文件,持久化的数据还可以保存成什么形式?( )
二维码
以下哪个路径是绝对路径?( )
E:\python
以下哪个操作既可以针对文件执行,也可以针对目录执行?( )
os.rename
用以下哪种方式打开的文件不能被读取?( )
w
文件打开后不需要关闭。( )
×
文件默认访问方式为可读。( )
√
使用 a+模式打开文件,文件不存在则会创建一个新文件。( )
√
read()方法可以设置读取的字符长度。( )
√
readlines()方法可以读取文件中的所有内容。( )
√
第十章
下列关于异常的说法,正确的是( )。
如果 except 子句没有指明任何异常,则可以捕获所有的异常。
下列关于 try…except 的说法,错误的是( )。
程序捕获到异常会先执行 except 语句,然后执行 try 语句
阅读下面的代码:
num_one = 9
num_two = 0
print(num_one/num_two)
运行代码,Python 解释器抛出的异常是( )。
ZeroDivisionError
如果以负数作为平方根函数 math.sqrt()的参数,将产生( )。
ValueError 异常
下列选项中,说法错误的是( )。
一个 try 语句可以对应多个 except 语句
以下哪个不是BaseException的直接子类?( )
MouseInterrupt
下面哪个是所有内置异常类的基类?( )
BaseException
关于错误和异常,以下说法错误的是( )
如果异常发生,则让程序直接退出,不需要保护程序继续运行或者恢复被占用的资源
有一个网站提供用户注册和浏览所有用户资料功能,网站内部实现了一个根据用户输入的用户名获得一个user类的实例的方法。以下说法错误的是( )。
只要根据用户名获取不到用户就认为出现了异常。
关于4种典型的异常处理结构,错误的是( )。
try…except…finally…else…
访问列表之外的索引会出现 IndexError 异常。( )
√
语言错误不会引发异常。( )
√
使用 raise 可以显式引发异常。( )
√
assert 语句用于判定一个表达式是否为真。( )
√
with 语句可以自动关闭资源。( )
√
下列关于异常的说法,正确的是( )。
如果 except 子句没有指明任何异常,则可以捕获所有的异常。
下列关于 try…except 的说法,错误的是( )。
程序捕获到异常会先执行 except 语句,然后执行 try 语句
阅读下面的代码:
num_one = 9
num_two = 0
print(num_one/num_two)
运行代码,Python 解释器抛出的异常是( )。
ZeroDivisionError
如果以负数作为平方根函数 math.sqrt()的参数,将产生( )。
ValueError 异常
下列选项中,说法错误的是( )。
一个 try 语句可以对应多个 except 语句
以下哪个不是BaseException的直接子类?( )
MouseInterrupt
下面哪个是所有内置异常类的基类?( )
BaseException
关于错误和异常,以下说法错误的是( )
如果异常发生,则让程序直接退出,不需要保护程序继续运行或者恢复被占用的资源
有一个网站提供用户注册和浏览所有用户资料功能,网站内部实现了一个根据用户输入的用户名获得一个user类的实例的方法。以下说法错误的是( )。
只要根据用户名获取不到用户就认为出现了异常。
关于4种典型的异常处理结构,错误的是( )。
try…except…finally…else…
访问列表之外的索引会出现 IndexError 异常。( )
√
语言错误不会引发异常。( )
√
使用 raise 可以显式引发异常。( )
√
assert 语句用于判定一个表达式是否为真。( )
√
with 语句可以自动关闭资源。( )
√
关于网络爬虫的描述,以下错误的是( )。
网络爬虫可以爬取任意数据,完全不需要得到数据提供方的允许。
网络爬虫的类型不包括以下哪个?( )
局域网爬虫
关于增量式网络爬虫说法,以下错误的是( )。
增量式网络爬虫爬取新增加的页面,不爬取已经爬过的页面。
下面哪个不是有效的反爬虫机制?( )
通过在页面中设置JavaScript代码来禁止右击页面。
以下哪个模块是Python自带的,无须使用pip安装,可直接通过import导入后使用?( )
urllib
关于BeautifulSoup的四大对象,以下说法错误的是( )。
Comment对象是一种特殊的NavigableString对象,输出的内容包括注释符号和注释内容。
在使用BeautifulSoup遍历一个嵌套较为复杂的文档树的时候,如果我们要一次性将所有子孙节点全部遍历一遍,需要使用下面哪个属性?( )
descendants属性,获得所有子孙节点的迭代器。
执行soup.find_all(name=’input’)会返回什么?( )
name参数可以查找所有标签名为参数值的Tag对象,所以会返回所有input标签。
在调用BeautifulSoup对象的select()方法时传入字符串参数,即可使用CSS选择器找到标签,以下说法错误的是( )。
select(‘ < title>’)表示按标签括号包裹的文本内容查找。
关于urllib、urllib2、urllib3、requests等模块,以下说法错误的是( )。
urllib是Python1的自带模块,urllib2在Python1引入,后在Python2中被大量使用,所以urllib3是Python3的自带模块。
在网页源代码中, < form>和</ form>标签用来创建供用户输入内容的表单,可以用来包含按钮、文本框、密码输入框、 单选钮、复选框、下拉列表、颜色选择框、日期选择框等组件,使用 action 属性指定用户提交数据时执行的代码文件路径,使用href属性指定用户提交数据的方式。
×
在网页源代码中,< a>标签的method属性用来定义超链接的跳转地址。
×
使用扩展库requests的get()方法成功访问指定URL后返回的response对象,可以通过response对象的content属性来查看字符串形式的网页源代码。( )
√
robots.txt协议是爬虫领域的潜规则协议,所以不用去遵守。( )
×
可以用每秒10万次请示的方式去爬取网站数据,这样可以提高工作效率。( )
×
第十一章
关于网络爬虫的描述,以下错误的是( )。
网络爬虫可以爬取任意数据,完全不需要得到数据提供方的允许。
网络爬虫的类型不包括以下哪个?( )
局域网爬虫
关于增量式网络爬虫说法,以下错误的是( )。
增量式网络爬虫爬取新增加的页面,不爬取已经爬过的页面。
下面哪个不是有效的反爬虫机制?( )
通过在页面中设置JavaScript代码来禁止右击页面。
以下哪个模块是Python自带的,无须使用pip安装,可直接通过import导入后使用?( )
urllib
关于BeautifulSoup的四大对象,以下说法错误的是( )。
Comment对象是一种特殊的NavigableString对象,输出的内容包括注释符号和注释内容。
在使用BeautifulSoup遍历一个嵌套较为复杂的文档树的时候,如果我们要一次性将所有子孙节点全部遍历一遍,需要使用下面哪个属性?( )
descendants属性,获得所有子孙节点的迭代器。
执行soup.find_all(name=’input’)会返回什么?( )
name参数可以查找所有标签名为参数值的Tag对象,所以会返回所有input标签。
在调用BeautifulSoup对象的select()方法时传入字符串参数,即可使用CSS选择器找到标签,以下说法错误的是( )。
select(‘ < title>’)表示按标签括号包裹的文本内容查找。
关于urllib、urllib2、urllib3、requests等模块,以下说法错误的是( )。
urllib是Python1的自带模块,urllib2在Python1引入,后在Python2中被大量使用,所以urllib3是Python3的自带模块。
在网页源代码中, < form>和</ form>标签用来创建供用户输入内容的表单,可以用来包含按钮、文本框、密码输入框、 单选钮、复选框、下拉列表、颜色选择框、日期选择框等组件,使用 action 属性指定用户提交数据时执行的代码文件路径,使用href属性指定用户提交数据的方式。
×
在网页源代码中,< a>标签的method属性用来定义超链接的跳转地址。
×
使用扩展库requests的get()方法成功访问指定URL后返回的response对象,可以通过response对象的content属性来查看字符串形式的网页源代码。( )
√
robots.txt协议是爬虫领域的潜规则协议,所以不用去遵守。( )
×
可以用每秒10万次请示的方式去爬取网站数据,这样可以提高工作效率。( )
×
第十二章
关于数据分析、处理、挖掘说法不正确的是。( )
数据清洗就是将数据洗干净。
pandas常用的数据结构不包括下面哪个?( )
ndarray
在pandas中,以下方法不能创建Series的语句是?( )
impor pandas as pd
pd.Series[1, ‘a’, 5.2, 7]
在pandas中,以下方法查询结果是一个dp.DatatFrame的语句是?( )
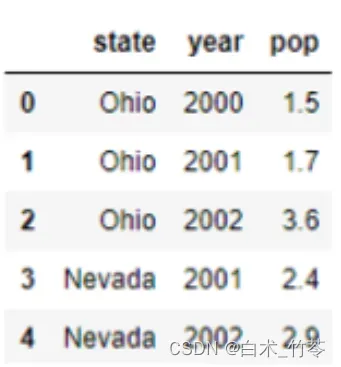
df.loc[0:2]
pandas查询数据说法正确的是。( )
df.where方法可以根据行、列进行条件查询。
pandas查询上海2016-2017年天气,能查到最高温度小于20度最低温度大于0度且天气阴有4-5级西北风且空气质量指数等级为2的天气数据的语句是。( )
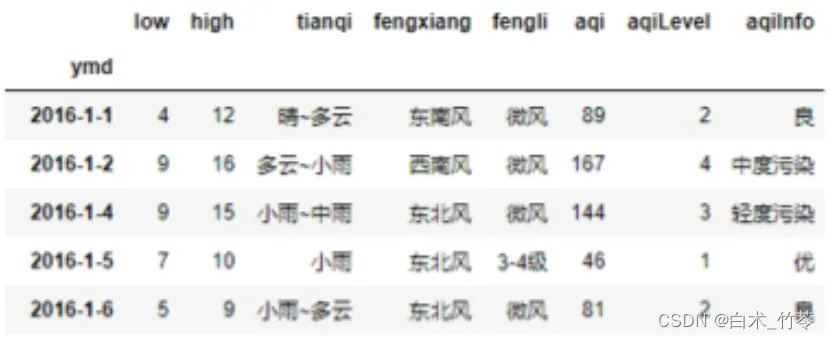
df.query(‘low>0 & high<20 & tianqi==”阴” & fengxiang==”西北风” & aqiLevel==2’)
pandas中关于相关系数和协方差概念正确的是。( )
对于两个变量x,y,如果相关系数为-1时,说明x,y反向相似度最大。
在pandas数据清洗中,能实现清洗掉第3行数据的语句是。( )
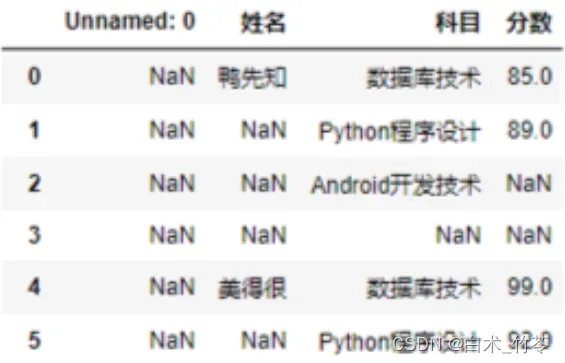
df.dropna(axis=’index’, how=’all’)
关于pandas数据排序说法不正确的是。( )
series.sor_values() 方法默认为升序排序并且默认可以修改原始Series。
在pandas的字符串处理中,不能实现删除掉ymd列中所有’-‘字符的语句是。( )
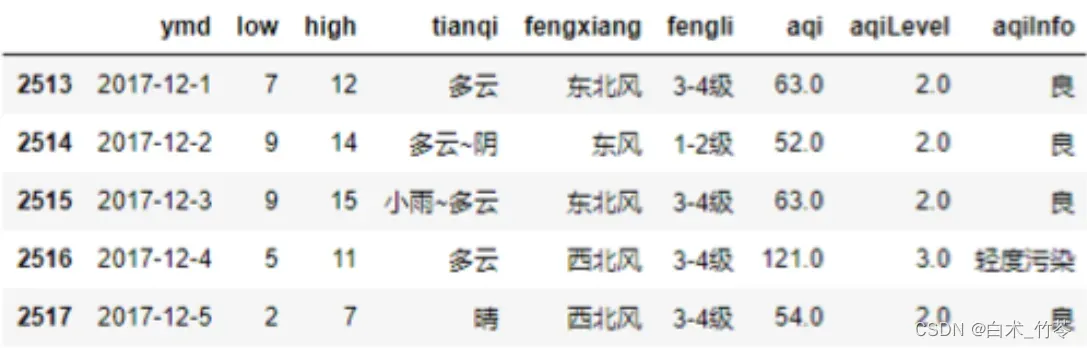
df[“ymd”].str.replace(“-“, “”).slice(0, 6)
扩展库 pandas 中 DataFrame 结构的 sort_values()方法可以用来对值进行排序,其参数axis用来指定根据哪一列或哪几列进行排序。( )
×
使用扩展库 pandas 中 DataFrame 结构的 fillna()方法填充缺失值时,可以把参数inplace设置为 False实现原地填充而不返回新的 DataFrame。( )
×
扩展库 pandas 中 DataFrame 结构的diff方法可以用来计算数据差分,其中参数axis=0 时表示纵向差分, axia=1 时表示横向差分。( )
√
使用 pandas 的 date_range()函数生产日期时间数据时,如果以 6 天为间隔可以设置参数 freq 为’6D’。( )
√
使用扩展库 pandas 的函数 read_excel()读取 Excel 文件时,可以使用参数na_values 指定哪些值被解释为缺失值。( )
√
已知 df 为 pandas 的 DataFrame 对象,那么 df[:10]表示访问 df 中前 10 列数据。( )
×
使用扩展库 pandas 中 DataFrame 对象的 iloc 方法访问数据时,可以使用DataFrame 的 index 标签,也可以使用整数序号来指定要访问的行和列。( )
×
已知 df 为 pandas 的 DataFrame 对象,那么 df.at[3, ‘姓名’]表示访问行下标为2,姓名列的值。( )
×
已知 df 为 pandas 的 DataFrame 对象,那么 df[df[‘姓名’].isin([‘张三’,‘李四’])]表示访问 df 中“姓名”列的值为“张三”或“李四”的数据。( )
√
扩展库 pandas 中 DataFrame 对象支持使用 dropnan()方法丢弃带有缺失值的数据行,或者使用 fillnan()方法对缺失值进行批量替换,也可以使用 loc()、 iloc()方法直接对符合条件的数据进行替换。( )
×
第十三章
扩展库 seaborn 中的函数 lineplot()可以用来绘制哪种图形。( )
折线图
扩展库 matplotlib.pyplot 中的函数 scatter()可以用来绘制哪种图形。( )
散点图
扩展库 pyecharts 中的函数 Funnel()可以用来绘制哪种图形。( )
漏斗图
使用可视化扩展库 matplotlib 的模块 pyplot 中的 scatter()函数绘图时,下面哪个参数可以用来设置符号。( )
c
使用可视化扩展库 matplotlib 的模块 pyplot 中的 bar()函数绘制图时,下面哪个参数可以用来设置图中形状的位置。( )
left
使用可视化扩展库 matplotlib 的模块 pyplot 中的 xlabel()函数设置 x 轴标签时,下面哪个参数可以用来设置字体。( )
fontproperties
使用可视化扩展库 matplotlib 的模块 pyplot 中的 xticks()函数设置 x 轴刻度时,下面哪个参数用来设置刻度文本的旋转角度。( )
rotation
使用可视化扩展库 matplotlib 的模块 pyplot 中的 pie()函数绘制饼状图时,下面哪个参数用来设置每个扇形区域偏离圆心的程度。( )
explode
可视化扩展库 matplotlib 的模块 pyplot 中哪个函数可以用来设置同一个画布中多个子图之间的水平间距和垂直间距。( )
subplots_adjust()
使用可视化扩展库 matplotlib 的模块 pyplot 中的 pie()函数绘制饼状图时,下面哪个参数用来设置每个扇形区域偏离圆心的程度。( )
explode
假设已使用 import matplotlib.pyplot as plt 正确导入,那么 plt.xticks([])的作用是设置当前轴域不显示 x 轴上的刻度。( )
√
假设已使用 import matplotlib.pyplot as plt 导入扩展库,那么语句 ax1 = plt.subplot(221)执行之后, ax1 表示画布左上角的子图。( )
√
假设已使用 import matplotlib.pyplot as plt 导 入可 视化 扩 展库 ,那
plt.rcParams[‘legend.fontsize’] = 10
语句的功能是设置图例的字号。( )
√
在可视化扩展库 matplotlib 的模块 pyplot 中,函数 plot(x, y, ‘r-+’)使用等长数组 x 和 y 中对应元素作为端点坐标绘制红色实心线并使用加号标记端点。( )
√
使用扩展库 matplotlib 进行可视化时,轴域坐标轴上的刻度只能是均匀分布和显示的,没有办法设置。( )
×
第十四章
计算numpy中元素个数的方法( )。
np.size()
已知c = np.arange(24).reshape(3, 4, 2)那么c.sum(axis = 0)所得的结果为( )。
array([[24, 27], [30, 33], [36, 39], [42, 45]])
有数组n = np.arange(24).reshape(2, -1, 2, 2),n.shape的返回结果是什么?
(2, 3, 2, 2)
numpy中创建全为0的矩阵使用( )。
zeros
numpy中向量转成矩阵使用( )。
reshape
numpy中矩阵转成向量使用( )。
resize
已知a = np.arange(12),c = a.view()那么c is a的结果为True,c.base is a的结果为True( )
×
np.where(condition[, x, y]),基于条件condition,返回值来自x或者y( )。
√
一个数组对象的itemsize,返回的值是由数组的大小决定的( )。
×
numpy中产生全1的数组使用方法empty。( )
×
a[::-1]可以将一个向量进行返转。( )
√
文章出处登录后可见!