这里是redis系列文章之《redis集群》,上一篇文章链接:【redis基础】哨兵_努力努力再努力mlx的博客-CSDN博客
目录
概念
作用
集群算法-分片-槽位slot
槽位与分配的概念及两者的优势
官网介绍分析
槽位
分片
两者的优势
slot槽位映射的三种解决方案
哈希取余分区
一致性哈希算法分区
哈希槽分区
经典面试题
集群环境案例步骤
3主3从redis集群配置
找三台虚拟机,各自新建
新建6个独立的redis服务实例
通过redis-dir命名为六台机器构建集群关系
链接进入6381作为切入点,查看并检验集群状态
3主3从redis集群读写
主从容错切换前移案例
主从扩容案例
主从缩容案例
集群常用操作命令和CRC算法分析
概念
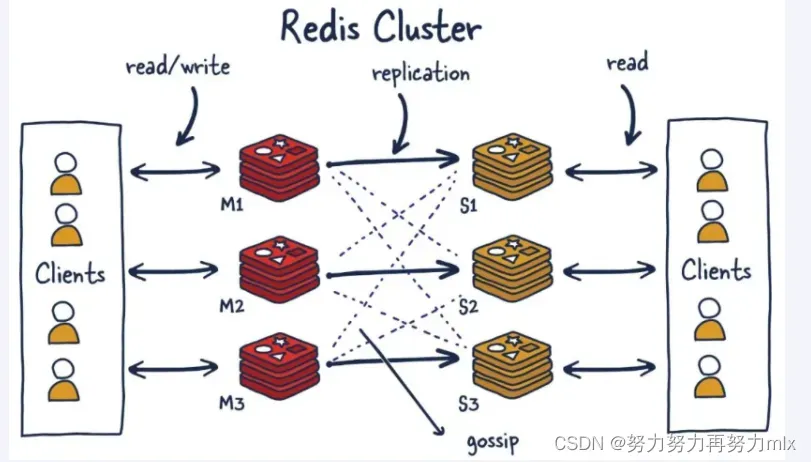
由于数据量过大,单个Master复制集难以承担,因此需要对多个复制集进行集群,形成水平扩展每个复制集只负责存储整个数据集的一部分,这就是Redis的集群,其作用是提供在多个Redis节点间共享数据的程序集。
使用一句话来总结即为:Redis集群是一个提供多个Redis节点间共享数据的程序集,Redis集群可以支持多个master
作用
1.Redis集群支持多个Master,每个Master又可以挂载多个Slave
- 读写分离:master slave模型支持数据的读写分离
- 支持海量数据的高可用:一个master下跟随多个slave,当一个master挂掉之后由其对应的slave上位,保证数据的高可用性
- 支持海量数据的读写存储操作:由一个master拓展为多个master,在支持数据量的方面也得到了很大的优化, 因此redis集群支持海量数据的读写存储操作
2.由于Cluster自带Sentinel的故障转移机制,内置了高可用的支持,无需再去使用哨兵功能
- 客户端和Redis的节点连接,不再需要连接集群中所有节点,只需连接集群中的任意一个可用节点即可
3.槽位slot负责分配到各个物理服务节点,由对应的集群来负责维护节点、插槽和数据之间的关系
集群算法-分片-槽位slot
槽位与分配的概念及两者的优势
官网介绍分析
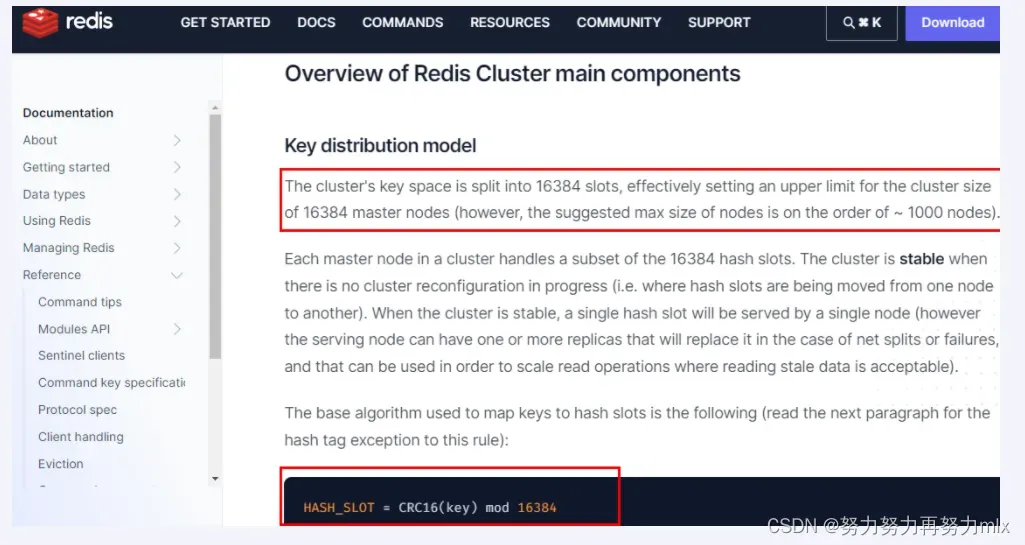
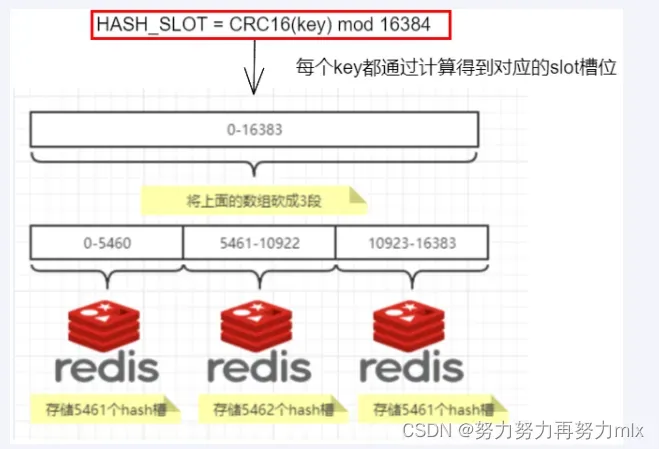
集群的密钥空间被分成16384个槽,有效地设置了16384个主节点的集群大小上限(但是,建议的最大节点大小约为1000个节点)。
集群中的每个主节点处理16384个哈希槽的一个子集。当没有集群重新配置正在进行时(即哈希槽从一个节点移动到另一个节点),集群是稳定的。当集群稳定时,单个哈希槽将由单个节点提供服务(但是,服务节点可以有一个或多个副本,在网络分裂或故障的情况下替换它,并且可以用于扩展读取陈旧数据是可接受的操作)。
槽位
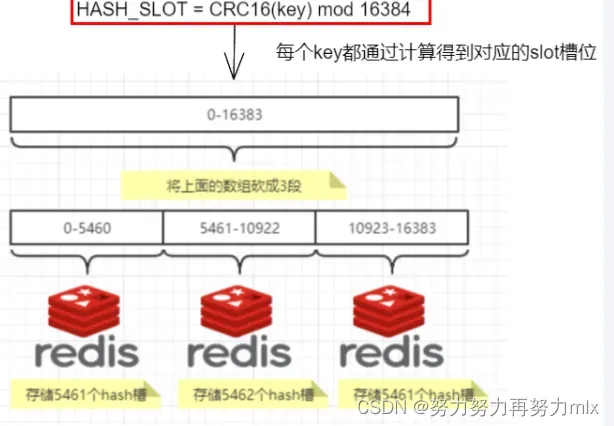
Redis集群没有使用一致性hash,而是引入了hash槽的概念,Redis集群有16384个hash槽,每个key通过CRC16校验后取模来决定放置在哪个槽位,集群中的每个节点负责一部分的hash槽,举例而言,如下图有三个节点,则:
分片
| 分片是什么 | 使用Redis集群时我们会将存储的数据分散到多台redis机器上,这称为分片。 简言之,集群中的每个Redis实例都被认为是整个数据的一个分片。 |
| 如何找到给定key的分片 | 为了找到给定key的分片,我们对key进行CRC16(key)算法处理并通过对总分片数量取模。 然后, 使用确定性哈希函数,这意味着给定的key 将多次始终映射到同一个分片, 我们可以推断将来读取特定key的位置。 |
两者的优势
最大优势在于扩缩容以及数据的分片查找
这种结构很容易添加或者删除节点.比如购果我想新添加个节点D,我需要从节点A,B,C中得部分槽到D上.如果我想移除节点A.需要将A中的槽移到B和C节点上然后将没有任何槽的A节点从集群中移除即可.由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
slot槽位映射的三种解决方案
哈希取余分区
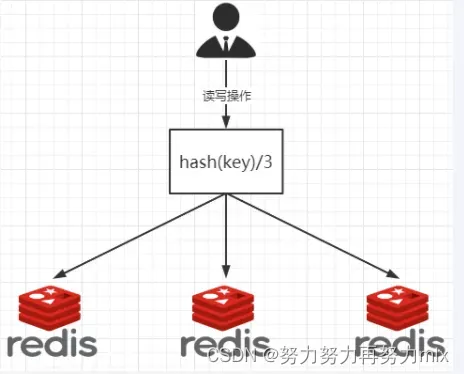
| 2亿条记录就是2亿个k,v,我们单机不行必须要分布式多机,假设有3台机器构成一个集群, 用户每次读写操作都是根据公式: hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。 |
| 优点: 简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息), 起到负载均衡+分而治之的作用。 |
| 缺点: 原来规划好的节点,进行扩容或者缩容就比较麻烦了额,不管扩缩,每次数据变动导致节点有变动, 映射关系需要重新进行计算,在服务器个数固定不变时没有问题,如果需要弹性扩容或故障停机的情况下, 原来的取模公式就会发生变化:Hash(key)/3会变成Hash(key) /?。 此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。 某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。 |
一致性哈希算法分区
三大步骤:
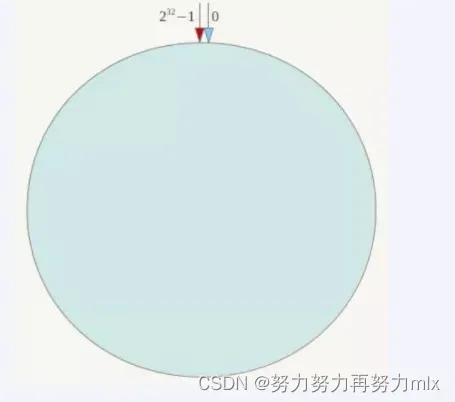
1.算法构建一致性哈希环
一致性哈希环
一致性哈希算法必然有个hash函数并按照算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间[0,2^32-1],这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0 = 2^32),这样让它逻辑上形成了一个环形空间。
它也是按照使用取模的方法,前面笔记介绍的节点取模法是对节点(服务器)的数量进行取模。而一致性Hash算法是对2^32取模,简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希环如下图:整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1, 0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。
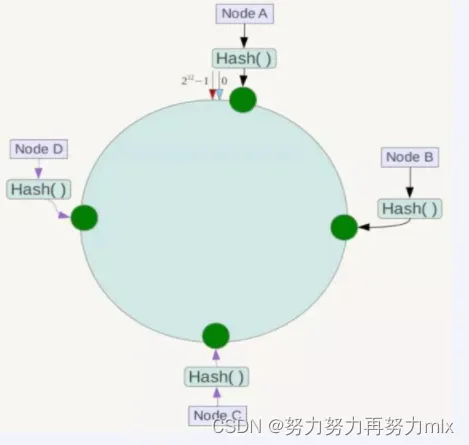
2.redis服务器ip节点映射
节点映射
将集群中各个IP节点映射到环上的某一个位置。
将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:
3.key落到服务器的落键规则
当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
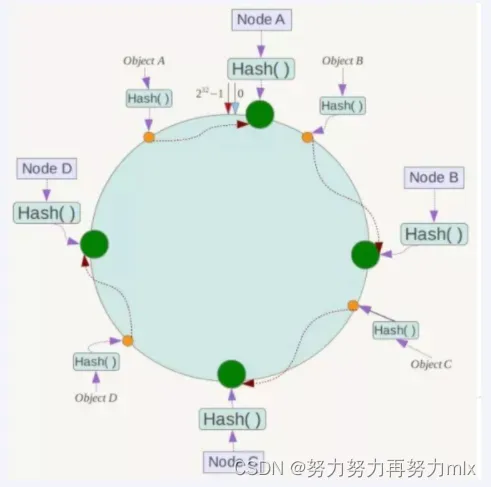
优点:
容错性
假设Node C宕机,可以看到此时对象A、B、D不会受到影响。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据且这些数据会转移到D进行存储。
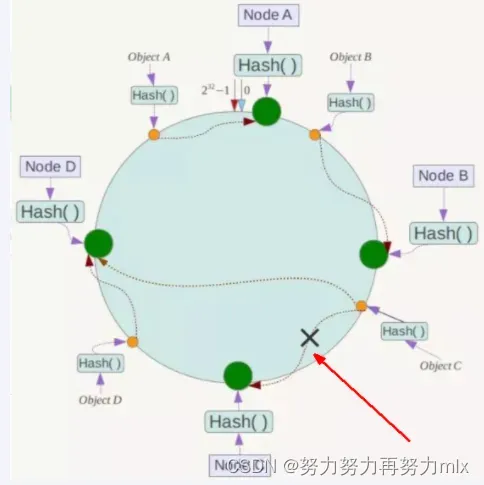
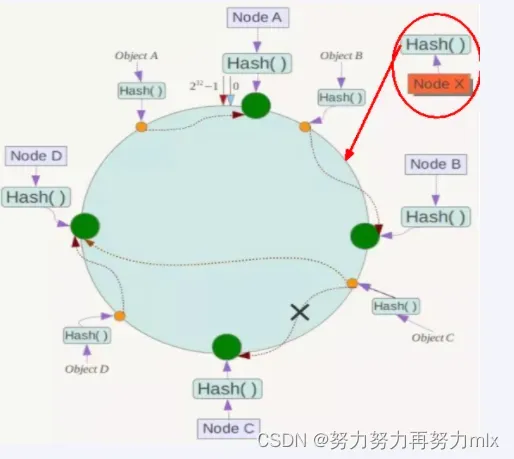
扩展性
数据量增加了,需要增加一台节点NodeX,X的位置在A和B之间,那收到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,
不会导致hash取余全部数据重新洗牌。
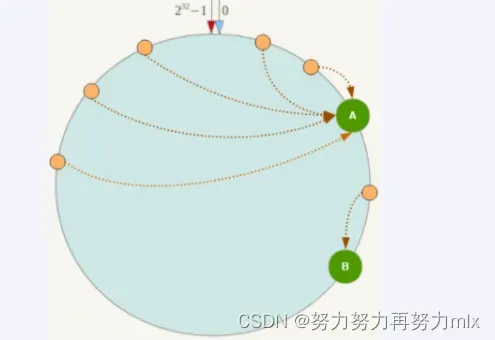
缺点:
Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,
例如系统中只有两台服务器:
总结:
为了在节点数目发生改变时尽可能少的迁移数据
将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储节点存放。
而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点。
优点
加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。
缺点
数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。
哈希槽分区
概念: 为解决一致性哈希算法的数据倾斜问题,哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。
作用:解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
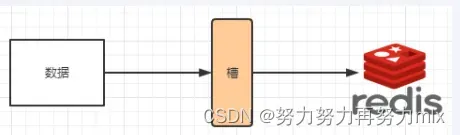
槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配
多少个hash槽:
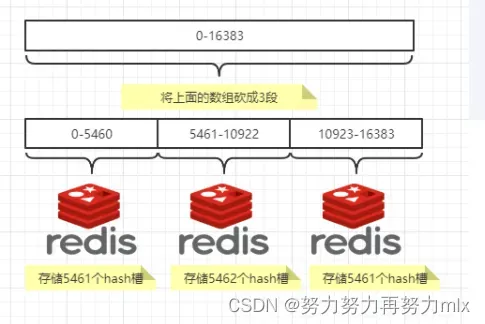
一个集群只能有16384个槽,编号0-16383(0-2^14-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。
集群会记录节点和槽的对应关系,解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取模,余数是几key就落入对应的槽里。HASH_SLOT = CRC16(key) mod 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
哈希槽计算:
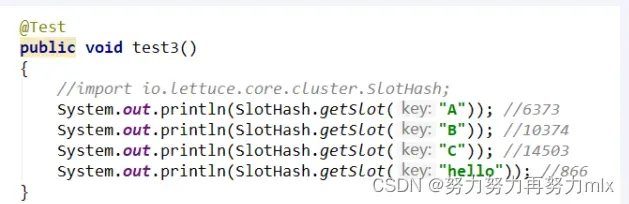
Redis 集群中内置了 16384 个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在 Redis 集群中放置一个 key-value时,redis先对key使用crc16算法算出一个结果然后用结果对16384求余数[ CRC16(key) % 16384],这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,也就是映射到某个节点上。如下代码,key之A 、B在Node2, key之C落在Node3上
经典面试题
为什么redis集群的最大槽数是16384个?
(1)如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大。
在消息头中最占空间的是myslots[CLUSTER_SLOTS/8]。 当槽位为65536时,这块的大小是: 65536÷8÷1024=8kb 在消息头中最占空间的是myslots[CLUSTER_SLOTS/8]。 当槽位为16384时,这块的大小是: 16384÷8÷1024=2kb 因为每秒钟,redis节点需要发送一定数量的ping消息作为心跳包,如果槽位为65536,这个ping消息的消息头太大了,浪费带宽。
(2)redis的集群主节点数量基本不可能超过1000个。
集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者不建议redis cluster节点数量超过1000个。 那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。
(3)槽位越小,节点少的情况下,压缩比高,容易传输。
Redis主节点的配置信息中它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中会对bitmap进行压缩,但是如果bitmap的填充率slots / N很高的话(N表示节点数),bitmap的压缩率就很低。 如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低。
集群环境案例步骤
3主3从redis集群配置
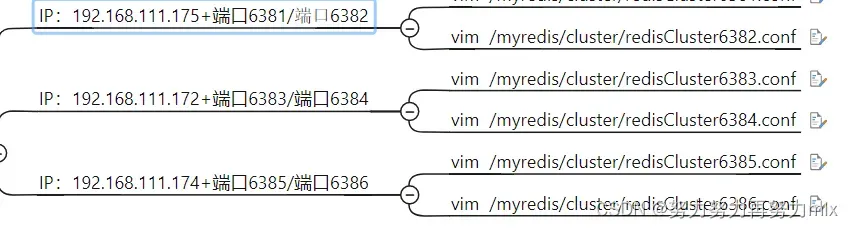
找三台虚拟机,各自新建
mkdir -p/myredis/cluster
新建6个独立的redis服务实例
每个配置文件中的内容均大同小异,自己调节即可,我们给出一个配置文件的配置信息:
bind 0.0.0.0
daemonize yes
protected-mode no
port 6381
logfile "/myredis/cluster/cluster6381.log"
pidfile /myredis/cluster6381.pid
dir /myredis/cluster
dbfilename dump6381.rdb
appendonly yes
appendfilename "appendonly6381.aof"
requirepass 111111
masterauth 111111
cluster-enabled yes
cluster-config-file nodes-6381.conf
cluster-node-timeout 5000启动六台redis实例:
redis-server/myredis/cluster/redisCluster6381.conf
........
redis-server/myredis/cluster/redisCluster6386.conf
通过redis-dir命名为六台机器构建集群关系
/注意,注意,注意自己的真实IP地址 //注意,注意,注意自己的真实IP地址
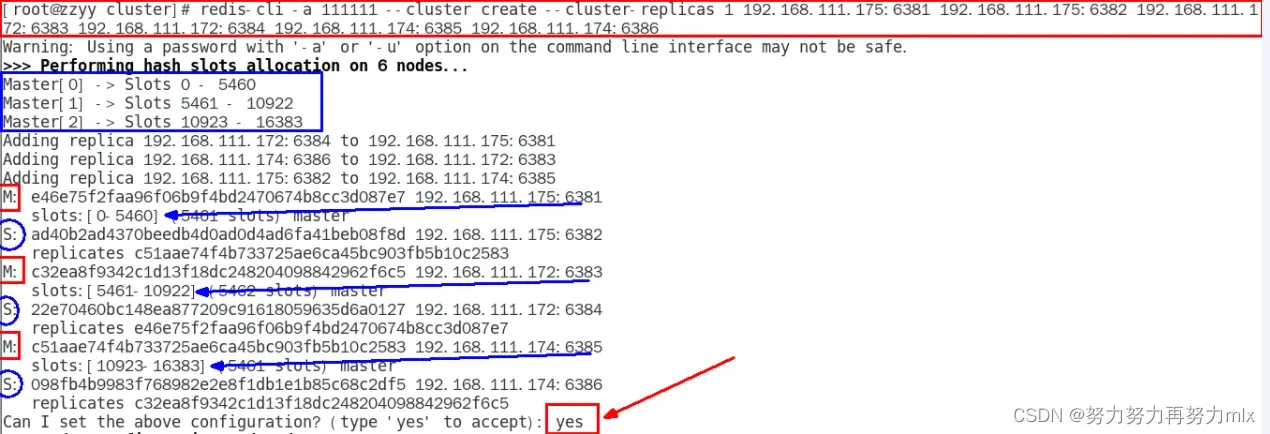
| redis-cli -a 111111 –cluster create –cluster-replicas 1 192.168.111.175:6381 192.168.111.175:6382 192.168.111.172:6383 192.168.111.172:6384 192.168.111.174:6385 192.168.111.174:6386 |
–cluster-replicas 1 表示为每个master创建一个slave节点
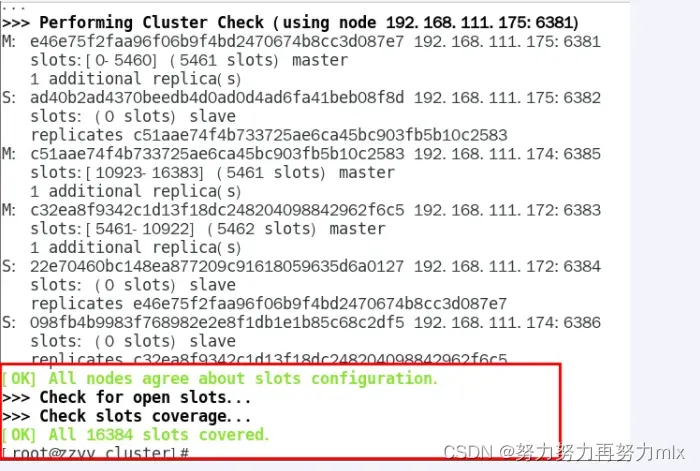
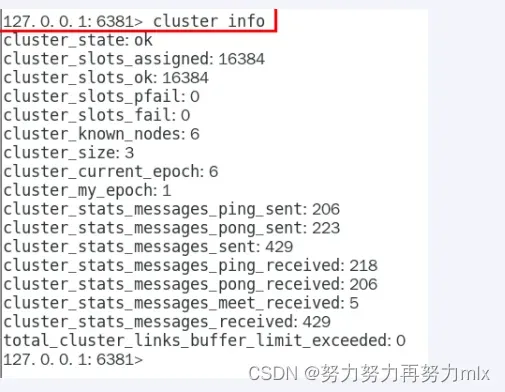
链接进入6381作为切入点,查看并检验集群状态
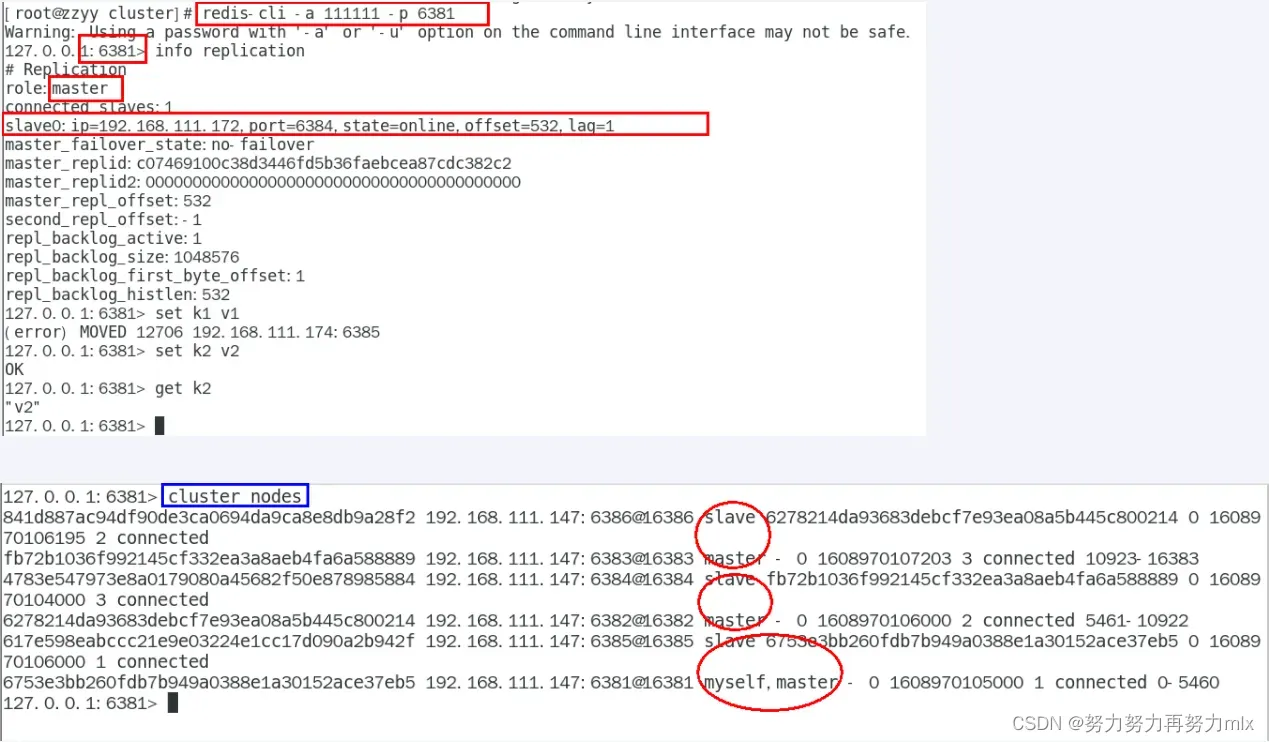
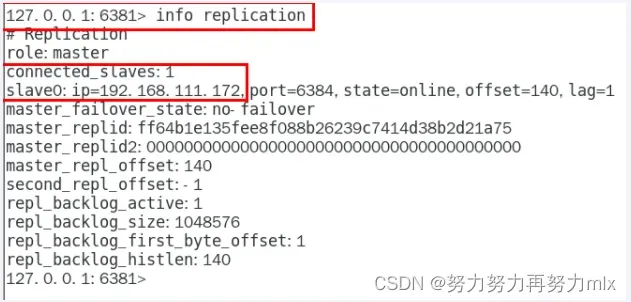
info replication
cluster info
cluster nodes

3主3从redis集群读写
对6381新增两个key,查看效果:

我们可以发现:我们在加入新的key时可能会报错,我们分析其原因:我们在设置k1这个新键时,在经过crc16算法和取模运算后,这个key被分配到了一个不属于当前的分片,就会报这个错误,我们想要解决这个错误,我们可以使用以下的指令:
redis- cli – a – 111111 p 6381 -c
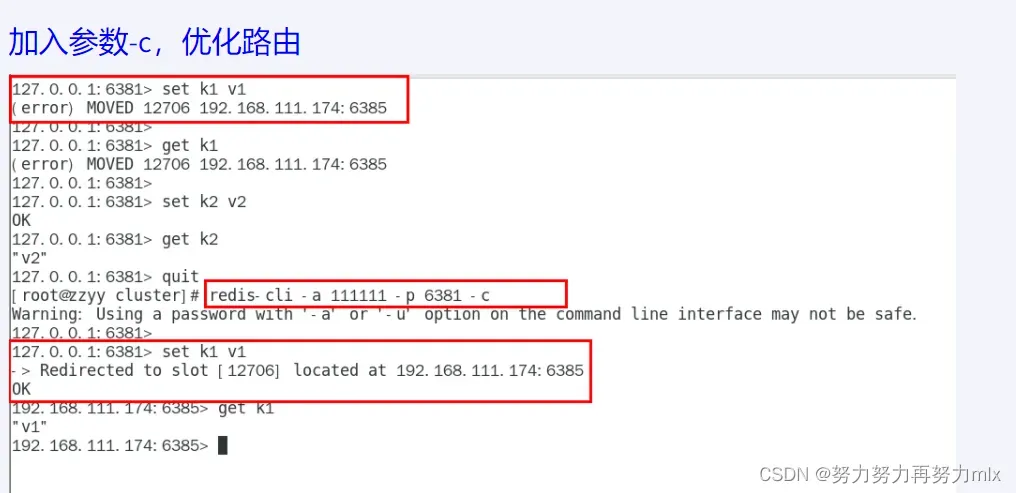
使用 -c指令后,当前的键在经过计算之后,会直接分配到对应的分片和槽位
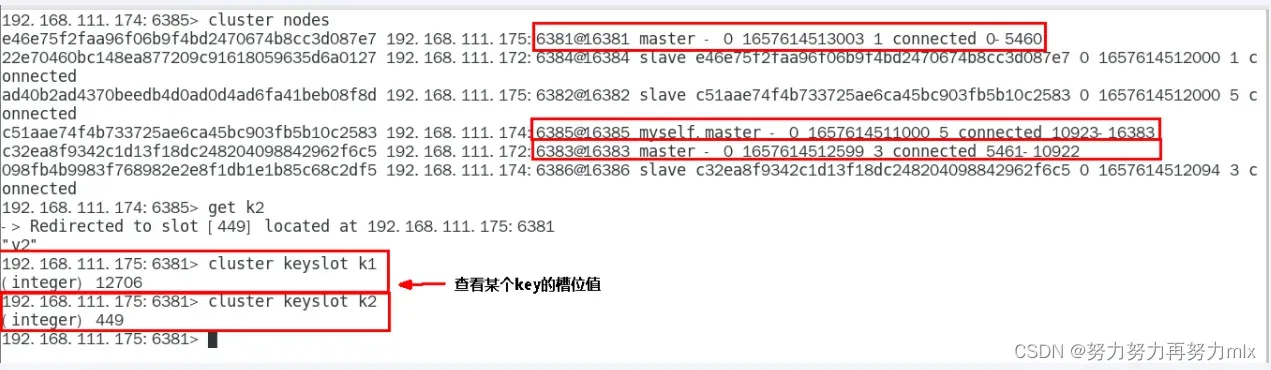
使用cluster keyslot查看key对应的槽位值
主从容错切换前移案例
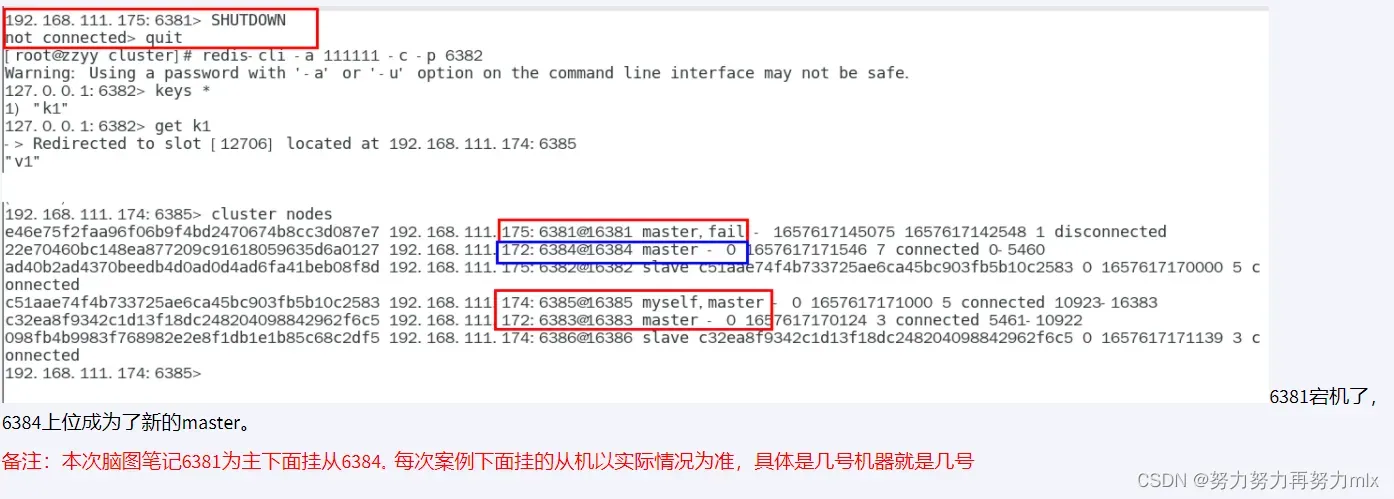
案例分析:
6381(主)-6384(从)
把6381停了,6384会成为master
启动6381,6384还是master,并不会让位
Redis集群不保证强一致性,意味着在特定的条件下,Redis集群可能会丢掉一些被系统收到的写入请求命令
因为本质还是发送心跳包,需要一些时间判断是否down机,如果down机,对应的slave直接成为master
如果想要原先的master继续做master的话,执行以下指令:CLUSTER FAILOVER // 让谁上位 就在谁的端口号下执行这个命令

主从扩容案例
新建6387、6388 两个服务实例配置文件+启动 (又加了个虚拟机 或者 直接在三个虚拟机里选一个)
启动87/88两个新的节点实例,此时他们自己都是master

以其中一个为例说明配置文件中的配置信息:
bind 0.0.0.0
daemonize yes
protected-mode no
port 6387
logfile "/myredis/cluster/cluster6387.log"
pidfile /myredis/cluster6387.pid
dir /myredis/cluster
dbfilename dump6387.rdb
appendonly yes
appendfilename "appendonly6387.aof"
requirepass 111111
masterauth 111111
cluster-enabled yes
cluster-config-file nodes-6387.conf
cluster-node-timeout 5000将新增的6387节点作为master加入原集群
redis-cli -a 123456 –cluster add-node 192.168.230.114:6387 192.168.238.111:6381
检查集群情况,6381
redis-cli -a 123456 –cluster check 192.168.238.111:6381
重新分配槽号
redis-cli -a 123456 –cluster reshard 192.168.238.111:6381
重新分配成本太高,所以前3家各自匀出来一部分,从6381/6383/6385三个旧节点分别匀出1364个坑位,注意本机这里经过调整所以我是需要从6381中分出4096即可
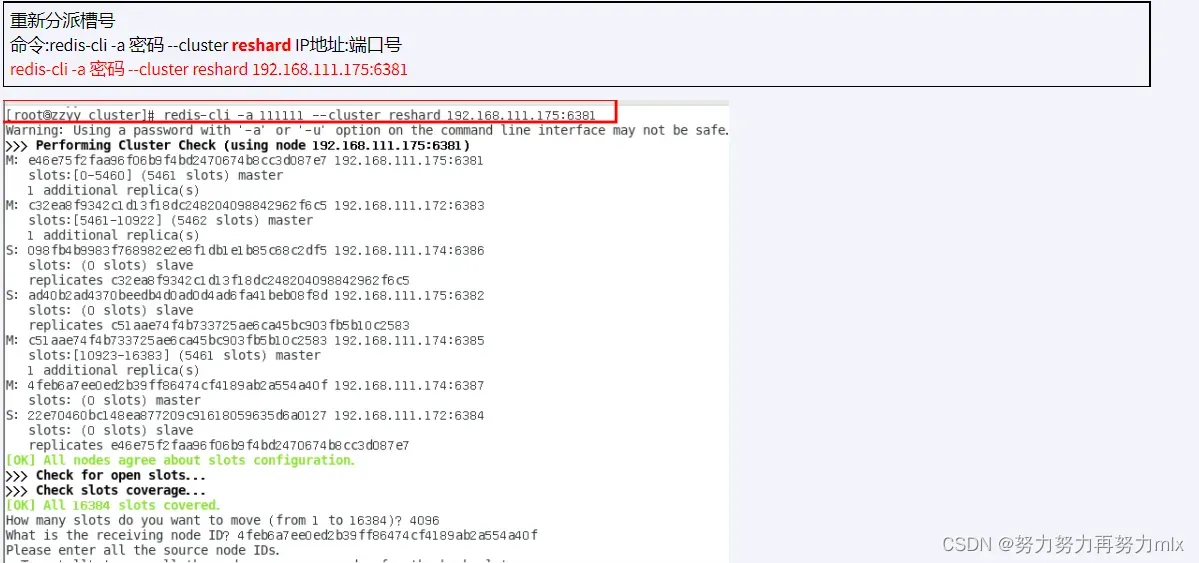
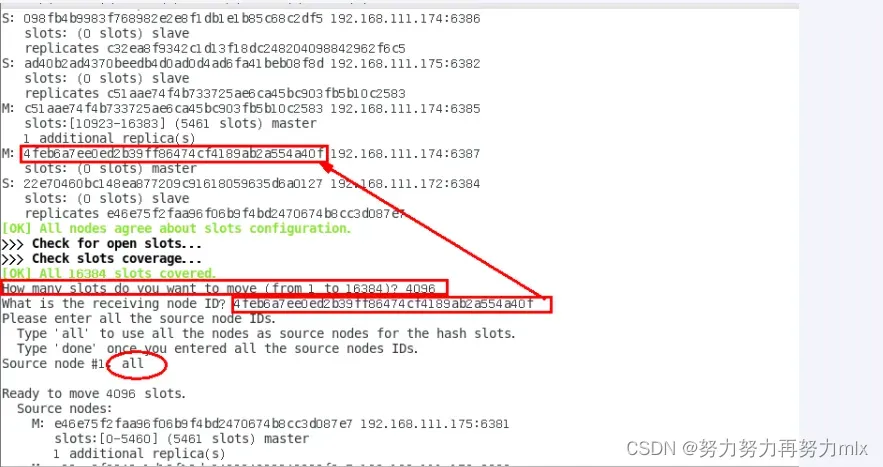
再次检查集群情况
redis-cli -a 123456 –cluster check 192.168.238.111:6381
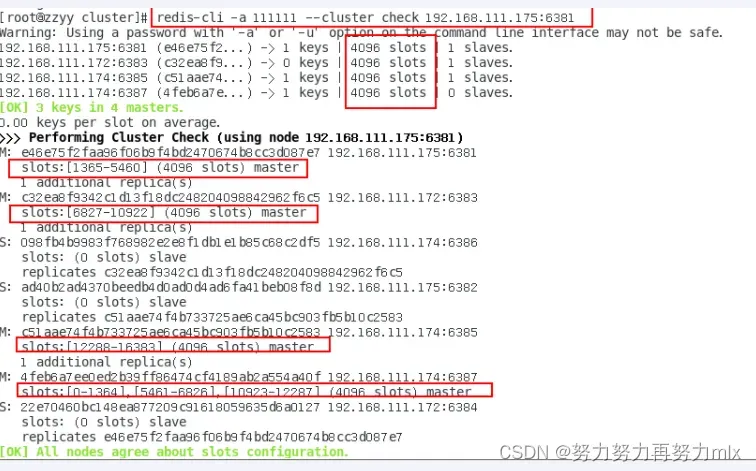
为主节点6387分配从节点6388 –cluster-master-id 后跟的是6387的id
redis-cli -a 123456 –cluster add-node 192.168.238.114:6388 192.168.238.114:6387 –cluster-slave –cluster-master-id b861764cbba16a1b21536a3182349748e56f24cc
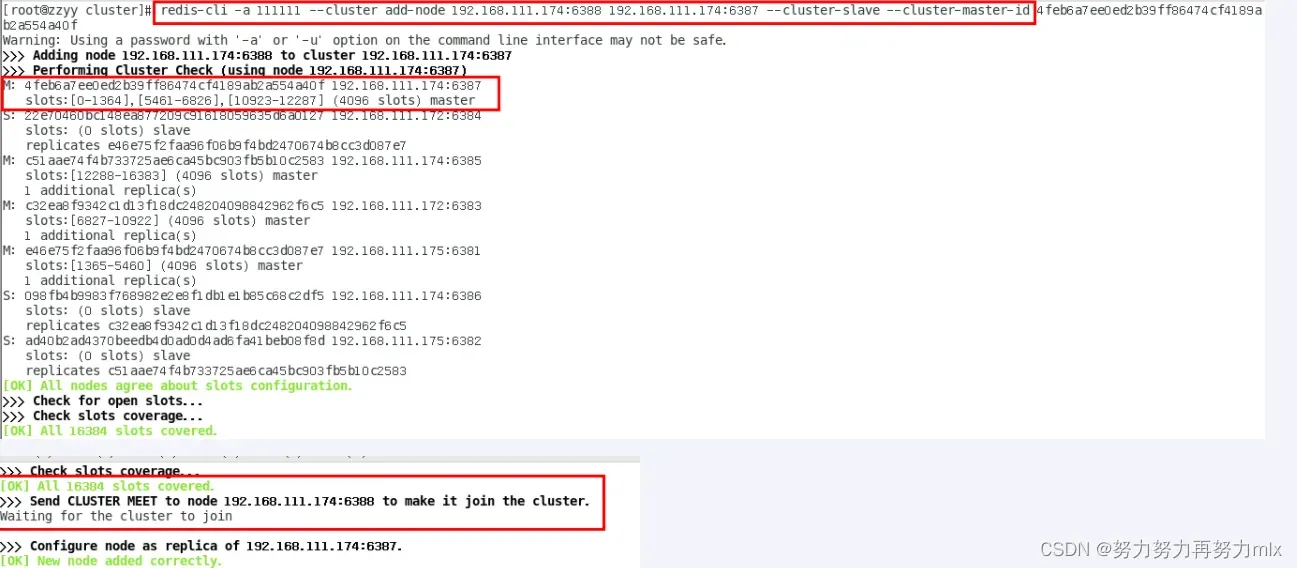
查看集群信息
redis-cli -a 123456 –cluster check 192.168.238.111:6381
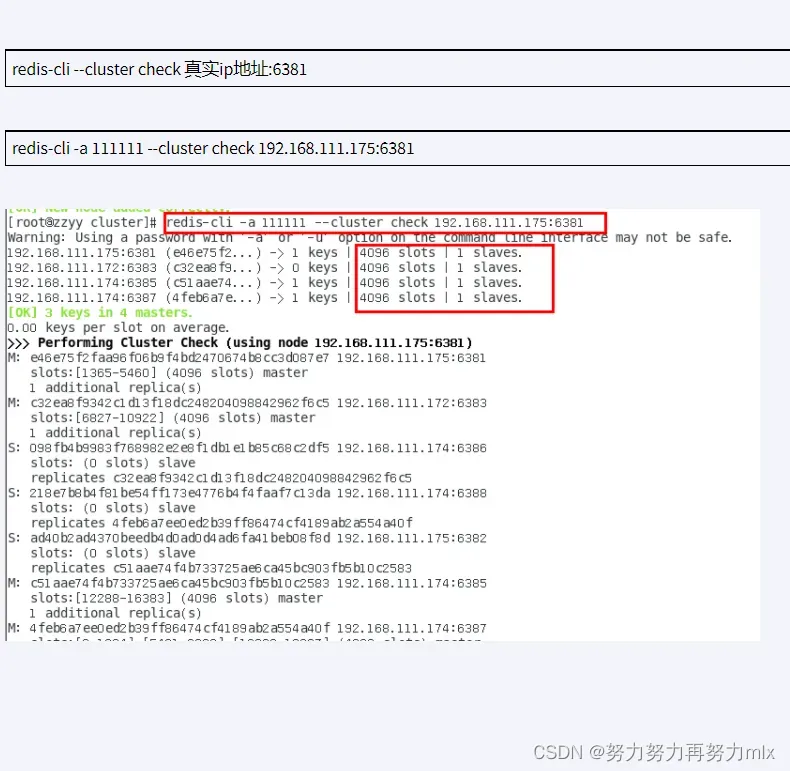
主从缩容案例
目的:将6387和6388进行下线操作
1.集群检查第一次:查看6388节点
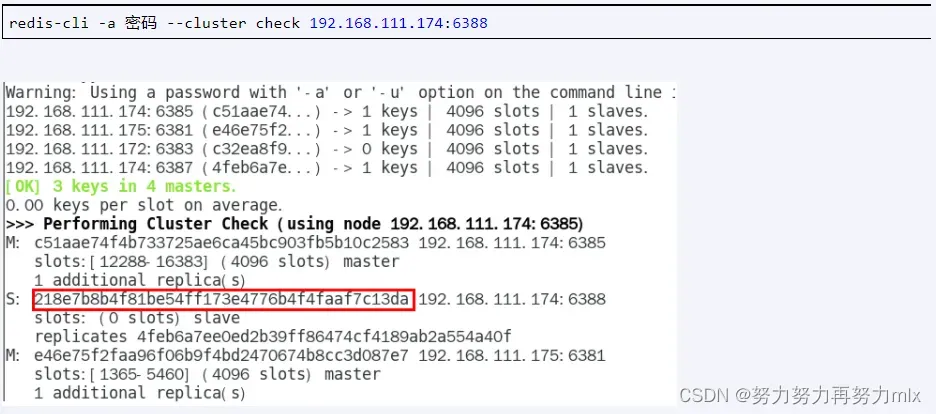
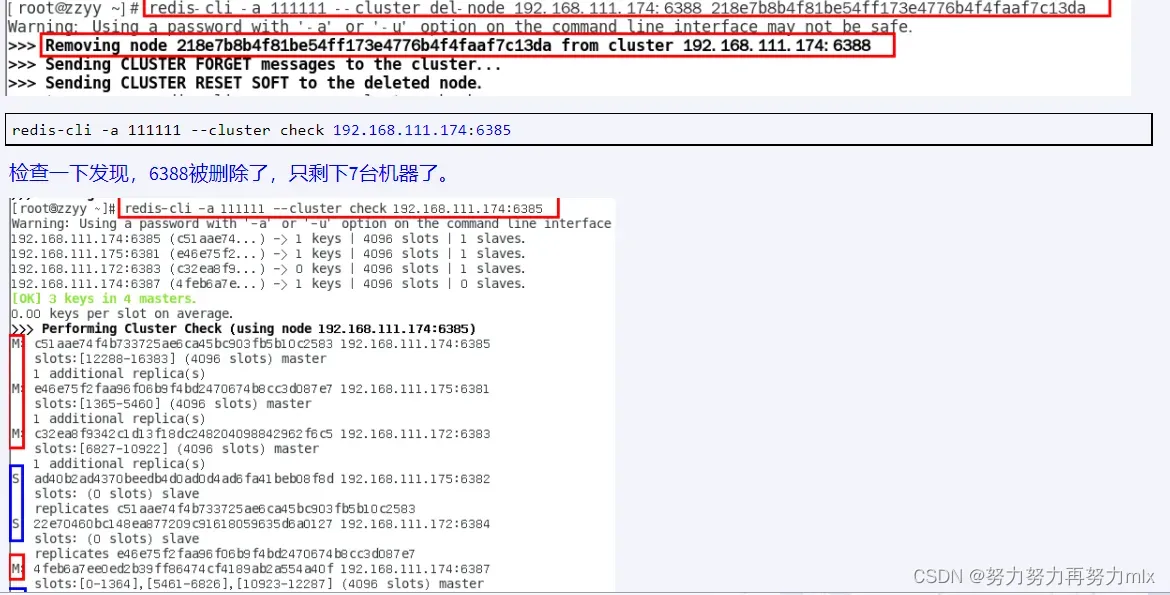
2.删除6388节点
命令:redis-cli -a 密码 –cluster del-node ip:从机端口 从机6388节点ID
redis-cli -a 111111 –cluster del-node 192.168.111.174:6388 218e7b8b4f81be54ff173e4776b4f4faaf7c13da
3.将6387节点槽位进行清除,将节点全部分配给6381
redis-cli -a 111111 –cluster reshard 192.168.111.175:6381
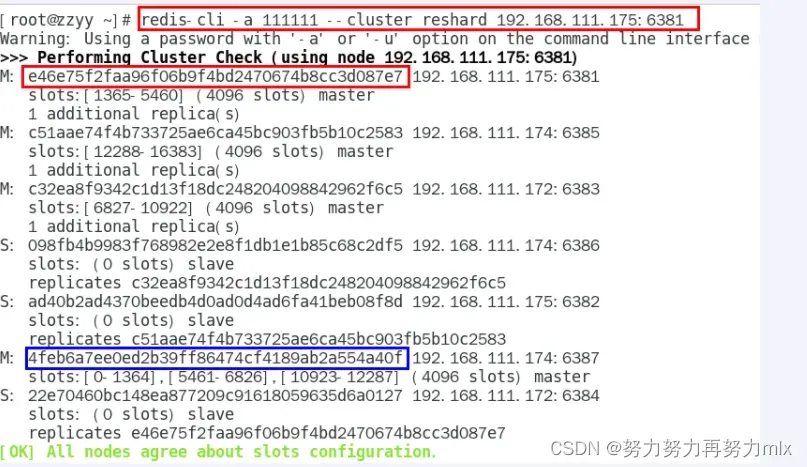
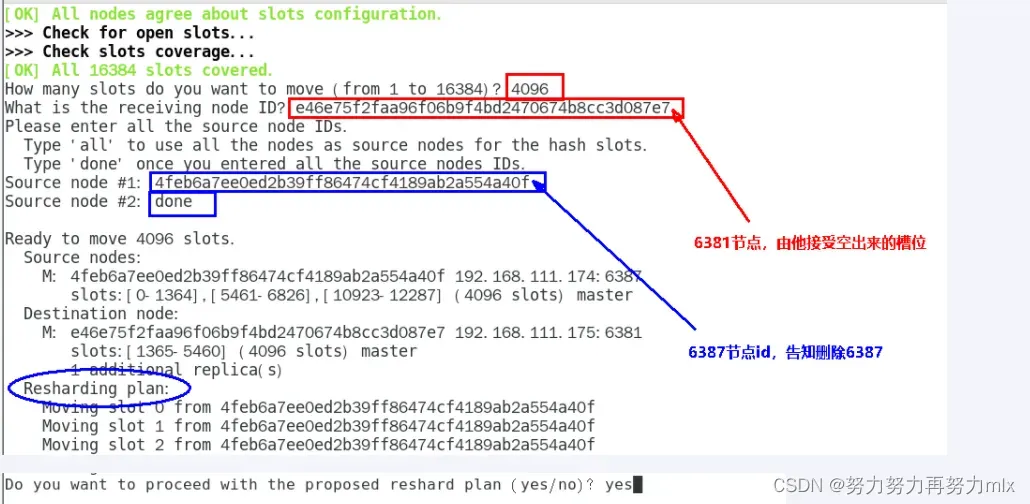
4.情况检查第二次
redis-cli -a 111111 –cluster check 192.168.111.175:6381
4096个槽位都指给6381,它变成了8192个槽位,相当于全部都给6381了,不然要输入3次,一锅端

5.将6387节点删除
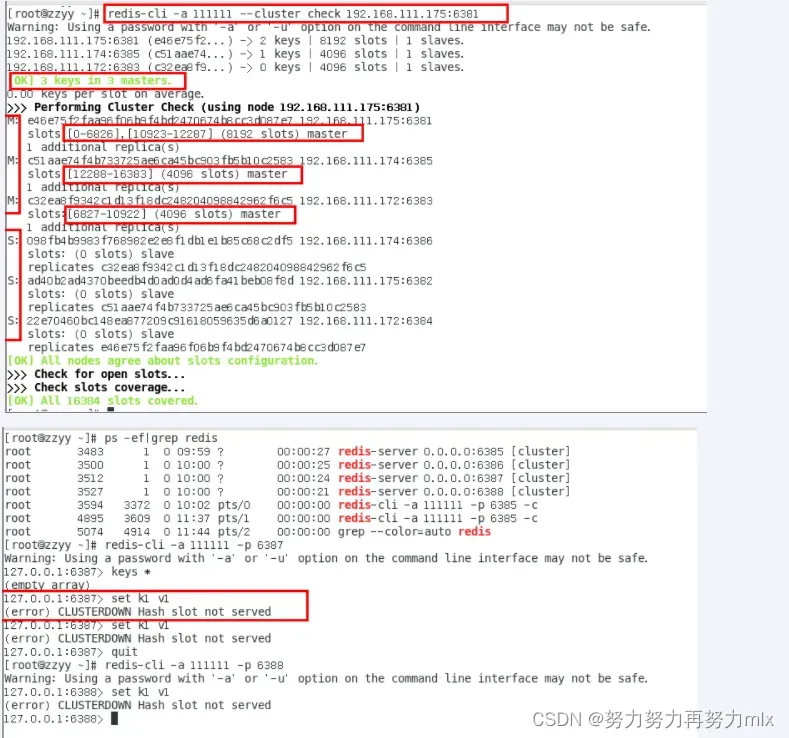
命令:redis-cli -a 密码 –cluster del-node ip:端口 6387节点ID
redis-cli -a 111111 –cluster del-node 192.168.111.174:6387 4feb6a7ee0ed2b39ff86474cf4189ab2a554a40f

6.最后一次情况检查
| redis-cli -a 111111 –cluster check 192.168.111.175:6381 |
集群常用操作命令和CRC算法分析
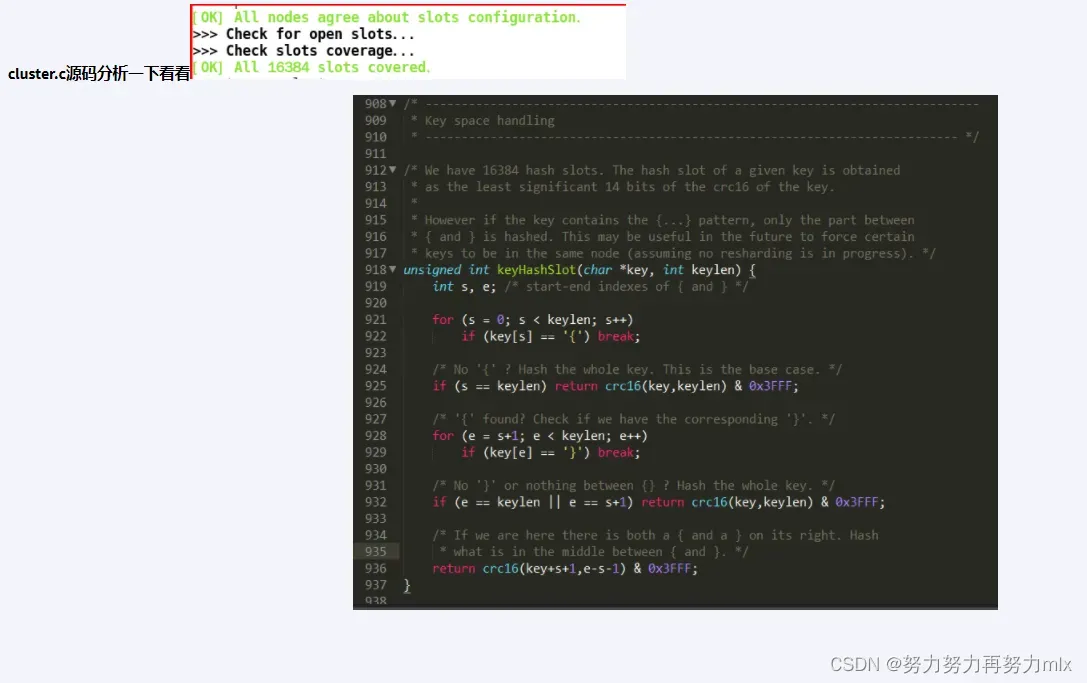
算法概述和源码浅谈:
redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置在哪个槽。捷群的每个节点负责一部分hash槽。
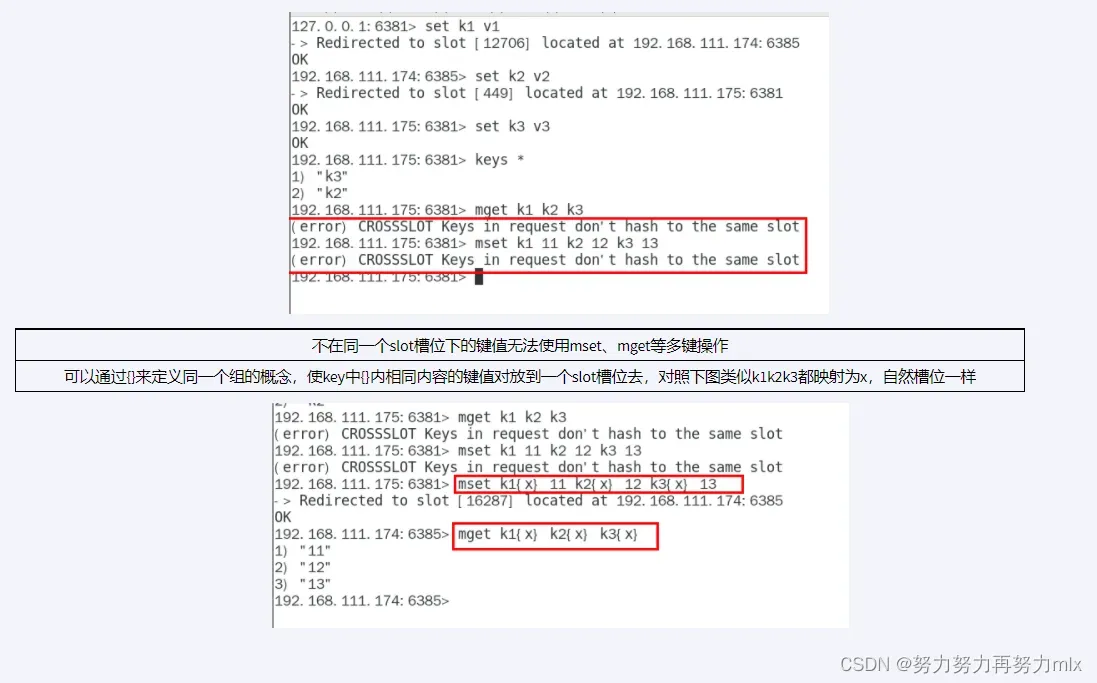
不在同一个slot槽位下的键值无法使用mset、mget等多键操作
可以通过{}来定义同一个组的概念,使key中{}内相同内容的键值对放到一个slot槽位去,对照下图类似k1k2k3都映射为x,自然槽位一样
mset k1{x} v1 k2{x} v2 K3{x} v3
mget k1{x} k2{x} K3{x}
CLUSTER COUNTKEYSINSLOT 槽位数字编号 // 1,该槽位被占用,0,该槽位没占用
CLUSTER KEYSLOT 键名称 // 该键应该存在哪个槽位上
cluster nodes // 查看集群的主从关系
cluster info // 查看集群信息
info replication // 查看主从
cluster keyslot k2 // 查看key的哈希槽位置
文章出处登录后可见!