源码加数据集: 文件源码
Gitee好像只收10M一下的文件类型,所以数据集就只能以链接的形式自己下了
KMeans和决策树KDD99数据集,推荐使用10%的数据集: http://kdd.ics.uci.edu/databases/kddcup99/
ALS电影推荐的Movielens数据集,推荐使用1m大小:https://files.grouplens.org/datasets/movielens/
逻辑斯蒂回归Iris数据集:https://archive.ics.uci.edu/ml/machine-learning-databases/iris/
目录
一、机器学习
机器学习是人工智能的一个分支,是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、计算复杂性理论等多门学科。机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。因为学习算法中涉及了大量的统计学理论,机器学习与推断统计学联系尤为密切,也被称为统计学习理论。算法设计方面,机器学习理论关注可以实现的,行之有效的学习算法。
机器学习可以根据有无监督分为监督式学习(supervised learning)和无监督学习(unsupervised learning),在前者中计算机会得到训练数据和目标结果,学习目的是根据反馈学习能够将输入映射到输出的规则,当不是每一个输入都有一一对应的目标结果或目标结果的形式有限时,监督式学习又可以分为半监督学习(semi-supervised learning)、主动学习(active learning)、强化学习(reinforcement learning)。在无监督学习中,训练集没有人为标注的结果,计算机需要自己发现输入数据中的结构规律。
另一种分类方法是根据学习任务的不同将其分为分类(classification),即训练一个模型根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类;回归(regression),即研究两个或多个变量间的相关关系;聚类(clustering),即将输入分成不同的组别或者更多的子集(subset),与分类学习不同的是聚类学习一半一般是无监督的;概率密度估计(density estimation)估计输入数据的分布;降维(dimensionality reduction),即将输入数据映射到维度更低的空间中从而降低学习任务的复杂度。
二、Spark机器学习库
1.Spark机器学习库介绍
传统的机器学习算法,由于技术和单机存储的限制,智能再少量数据上使用,依赖于数据抽样,是的实验的结果会与真实的结果有一定的出入。大数据技术的出现,可以支持再全量数据上进行机器学习。机器学习算法会涉及到大量迭代计算,以相对早期的Hadoop为例,基于磁盘的MapReduce不适合进行大量迭代计算。所以需要一种运行快速的,而且可以提供众多方法的技术。
Spark是基于内存运行的,天然就适应这种需要频繁迭代的计算。Spark提供了一个基于海量数据的机器学习库,它提供了常用机器学习算法的分布式实现,开发者只需要有 Spark 基础并且了解机器学习算法的原理,以及方法相关参数的含义,就可以轻松的通过调用相应的 API 来实现基于海量数据的机器学习过程。 能够了解Spark的DataFrame一些常规API操作之后,便可以尝试触及机器学习的领域,这与Python中的pandas库是类似的。也因此在Python中使用pyspark时一般都会连pandas一起使用。
在Spark的1.2版本的更新中,着重更新了关于机器学习的MLLIB的新API,支持pipeline的学习模式,k级流水线就是从组合逻辑的输入到输出恰好有k个逻辑结构,上一级的输出是下一级的输入而又无需反馈,即多个算法可以用不同参数以流水线的形式运行。在工业界的机器学习应用部署过程中,pipeline的工作模式是很常见的。新的spark.ml工具包使用Spark的SchemaRDD来表示机器学习的数据集合,提供Spark SQL直接访问的接口。
在我个人粗略学习Spark的机器学习库时,会觉得这种项目从建立到完成,最难的不是代码端,而是模型的建立和评估。因为现在大数据的发展是很迅速的,有很多好用且便利的接口或是工具,存储Hadoop一套,工具Spark,Python,Flink,Strom等等。难得是这个想法怎么出来,然后怎么落地,这期间需要用到哪些工具,等等。
2.Spark机器学习运算原理
Spark的机器学习库在1.2版本以后被分为两个包:
Spark.mllib,包含基于原始RDD的原始算法API。Spark.mllib的历史比较长,在1.2以前的版本已经包含了,提供的算法实现都是基于原始的RDD。在2.0+版本已经停止维护,即不再更新
Spark.ml,提供基于Spark SQL中的DataFrames高层次API,可以用来构建机器学习工作流(Pipeline)。ML Pipeline弥补了原始mllib库的不足,向用户提供了一个基于DataFrame的机器学习工作流式API套件。
一场机器学习过程从数据收集开始,要经历多个步骤。这非常类似于流水线式工作,即通常会包含源数据ETL(抽取、转化、加载),数据预处理,指标提取,模型训练与交叉验证,新数据预测等步骤:
- DataFrame:SparkSQL的API,是ml库的存储数据结构,可以容纳多种数据类型
- Transform:转换器,可以将一个DataFrame转换成另一种DataFrame,并且产生新的信息
- Parameter:机器算法的参数,不同的机器算法用不同的参数,种类繁多,个人建议使用setParameter(…)方法更方便
- Estimator:评估器,用于评估所训练出来的模型的好坏程度,接受一个DataFrame从而产生对应的数据结果
- Pipeline:工作流或者管道,可以将多个步骤(Transform,Estimator)合并成一项工作流程
val pipeline = new Pipeline().setStages(Array(stage1, stage2, stage3...))2.1Spark的数据处理
无论是基于原始RDD还是DataFrame,在Spark中的机器学习算法需要“消化”的数据集合是Vectors,他是一系列向量的集合,向量(也可以称作特征向量)的数据类型为Double。而我们在获取原始数据的时候,特征值可能是字符串类型,也可能是int类型等等,所以在启动机器算法前,需要对数据集做出相关处理。
特征向量还分为稀疏向量和密集向量,如下图,其特征向量用密集向量表示 [3.0, 2.0, 0.0, 5.0, 0.0, 4.0],如果用稀疏向量表示则显示为[6,(0,1,3,5),(3.0,2.0,5.0,4.0)]。可以发现,稀疏向量适合在当数据集中0出现次数较多时使用,而密集向量则相反,但两者的性质基本是一致的。
| 特征值 | 结果 |
| 3,2,0,5,0,4 | a |
| 1,0,0,0,6,3 | b |
接下来介绍几个在在数据预处理段比较常用的 transform 方法
- Binarizer 二值化器:通过设定的阈值,将一列数据转换成 0或1
- Bucketizer 特征离散化:将连续数据如年龄,分割不同分区,达到离散化
- Tokenizer 分词器:讲一句话分割各个单词组成
- StopWordRemover 停止词:删除频繁出现的词,但未携带太多意义的词(you ,i,are,all…)
- StringIndexer 标签转换索引: 将字符类型转换成索引即 String -> Double
- IndexToString 索引转字符串 : 在StringIndexer后使用,将Double还原成原来的字符串类型
- VectorAssembler 组合向量转换器:可以将多列数据(Double类型),合并成一列Vector特征集合
- StandarScaler 归一化:处理列特征,防止某列数据太大如[1.0,500.2,2.0],影响算法对各列数据的影响力判断
- MaxMinScaler 归一化:性质与相同,不同点是,它可以设定数据归一化后范围如[0,1]
三、算法实践以及解析
MLLIB目前支持4中常见的机器学习问题:分类,回归,聚类和协同过滤
| 离散数据 | 连续数据 | |
| 监督学习 | LogisticRegression,SVM,RandomForest,GBT,NaiveBayes,Classification | Regression,LinearRegression,DecisionTree,RandomFores,GBT,AFTSurvivalRegression,IsotonicRegression |
| 无监督学习 | Clustering,KMeans,GaussianMixture,LDA,PowerIterationClustering,BisectingKMeans | Dimensionality Reduction,Matrix,Factorization,PCA, SVD,ALS,WLS |
实验平台:
IDEA 2021.3.3 ,Pycharm 2021
实验工具:
Spark 3.2.1,Hadoop 3.3.1,Scala 2.13.8,JDK1.8,Python3.9
1.KMenas聚类算法检测网络数据
聚类即物以类聚,他是为了实现将数据按照某一标准(相似度)将整个数据集分为若干子集(簇),最终的分类结果要尽量保证组内相似度尽可能大,组间相似度尽可能小。聚类是典型的无监督学习(Unsupervised learning),它与分类问题最明显的区别就是分类问题有事先的标注,而聚类的分组是完全靠自己学习得来的。
聚类可以作为一个单独的学习过程,为了寻找数据的内部分布结构,也可以作为其他任务的前驱过程。KMeans算法以距离作为数据对象间相似性度量的标准,通常采用欧式距离来计算数据对象间距离,其中D表示数据对象的属性个数:
KMeans算法聚类过程中,每次迭代,对应的类簇中兴需要重新计算:对应类簇中兴所有数据对象的均值,即为更行后该类簇的类簇中心。定义第k个类簇的类簇中心为Center k,则类簇中心更行方式为:
其中,Ck表示第k个类簇,|Ck|表示第k个类簇中数据对的个数,这个库的求和是指类簇Ck中所有元素在每列属性上的和,因此CenterK也是一个含有D个属性的向量,表示为CenterK = (CenterK 1,CenterK 2, CenterK 3)
KMeans算法需要不断迭代来重新划分簇类,并更新类簇中心,迭代终止的条件常用的是设置迭代次数T,当达到第T次迭代,则种植迭代,此时所得到类簇即为最终的聚类结果;另一种方法则是采用误差平方和WSSSE准则函数,函数模型如下图:
1.1任务划分
KMeans的优点是简单易实现,但同时也存在不可忽略的缺点
- 需要事先指定类簇个数k值
- 对初始类簇中心的选取较为敏感
- 容易陷入局部最优
- 容易被噪音/异常值干扰
本次所使用的数据集时KDD99数据集,在正式训练模型前,需要对不断研究寻找数据集的最佳k值,找出异常数据并标记,最后再正式训练出最终的模型,所以整体的任务划分为
训练模型->寻找最佳k值->正式模型->预测预测集->异常检测
1.2数据预处理
本次实验使用的是KDD99数据集内容的10%数据文件:

查看类型分布可以发现,训练用的数据集一共有23钟数据类型,但根据说明显示,测试集testdata文件中含有39个数据类型,这需要考虑到所训练的模型是否具备泛化的功能,本次的主要任务有:
- 寻找最佳k值训练出最佳模型
- 23个数据类型本身并不重要,需要对预测集进行预测,找出那种判断为正常但实际上是不正常的异常数据,用于后续的异常检测。
| Normal | 正常行为 | Normal |
| Dos | 拒绝服务器攻击 | back、land、neptune、pod、smurf、teardrop |
| Probing | 监视和其他探测活动 | ipsweep、nmap、portsweep、satan |
| R2L | 来自远程机器的非法访问 | ftp_write、guess_passwd、imap、multihop、phf、spy、warezclient、warezmaster |
| U2R | 普通用户对本地超级用户特权的非法访问 | buffer overflow、loadmodule、perl、rootkit |
数据集一共有42个数值,前41个都是特征值,最后一个是数据类型。本次实验是对数据文件的前41个特征值做聚类算法,最后数值为聚类结果,训练出来的模型需要对正常行为和非正常行为做一个划分,并且这些数据集存在着异常数据和噪音,模型需要剔除噪音,找出异常数据。最终得出的模型对缺少数据类型(第42特征值)的预测集做出分类,找出正常行为和非正常行为的类簇,并挑选出异常点。

实验使用的是spark.ml包,是基于DataFrame的API,所以在实验开始时,先对数据文件转换成表格的形式,即跳过RDD的API,Spark直接将数据转换成DataFrame的形式,极大的简化的工作流程。使用spark.readcsv方法,读取文件,可以不需要给文件添加.csv后缀(csv转txt时是通过逗号“,”将数据文件分开的,所以读取文件时,类似于隐式转换),可以成功将数据摊开:
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
val spark = SparkSession.builder().appName("check K of KMeans").master("local").getOrCreate()
val sc = spark.sparkContext
import spark.implicits._
val file = "C:/Users/Lenovo/Desktop/Working/Python/data/kddcup.data_10_percent_corrected.csv"
val fileData = spark.read.csv(file)
val dataFrame = fileData
.toDF("duration", "protocol_type", "service", "flag", "src_bytes", "dst_bytes", "land",
"wrong_fragment", "urgent", "hot", "num_failed_logins", "logged_in", "num_compromised", "root_shell",
"su_attempted", "num_root", "num_file_creations", "num_shells", "num_access_files", "num_outbound_cmds",
"is_host_login", "is_guest_login", "count", "srv_count", "serror_rate", "srv_serror_rate", "rerror_rate",
"srv_rerror_rate", "same_srv_rate", "diff_srv_rate", "srv_diff_host_rate", "dst_host_count",
"dst_host_srv_count", "dst_host_same_srv_rate", "dst_host_diff_srv_rate", "dst_host_same_src_port_rate",
"dst_host_srv_diff_host_rate", "dst_host_serror_rate", "dst_host_srv_serror_rate", "dst_host_rerror_rate",
"dst_host_srv_rerror_rate", "label")
dataFrame.cache()
dataFrame
.show(5, false)Spark的机器学习的数据单位为Vector,Vector由1或多个向量组成,向量的基本单位为Double数据类型,所以我们需要将所有41个特征值转换为Double然后再合并为一个由Vector组成的特征向量。根据数据集我们发现数据集中protocol_type, service, flag均是字符类型,所以需要对该三类数据做额外处理:
//修改"protocol_type"这一列为数值型
val pretocol_indexer = new StringIndexer().setInputCol("protocol_type").setOutputCol("protocol_typeIndex").fit(dataFrame)
val indexed_0 = pretocol_indexer.transform(dataFrame)
//修改"service"这一列为数值型
val service_indexer = new StringIndexer().setInputCol("service").setOutputCol("serviceIndex").fit(indexed_0)
val indexed_1 = service_indexer.transform(indexed_0)
//修改"flag"这一列为数值型
val flag_indexer = new StringIndexer().setInputCol("flag").setOutputCol("flagIndex").fit(indexed_1)
val indexed_2 = flag_indexer.transform(indexed_1)
//修改"label"这一列为数值型
val label_indexer = new StringIndexer().setInputCol("label").setOutputCol("labelIndex").fit(indexed_2)
val indexed_df = label_indexer.transform(indexed_2)
在得到41个Int或Double的数据后,我们需要将41个特征值转换为Double类型,接着再合并成一个由41个特征向量组成的Vector数据类型。考虑到需要转换的特征列过多41列,所以采用全值转换为Double,再重新组装DataFrame,随后可以使用ML库中的VectorAssembler()方法可以完成这个要求,该方法可以将指定的多列,合并成一列由Vector组成的特征向量,代码如下:
val assembler = new VectorAssembler()
.setInputCols(Array("duration", "src_bytes", "dst_bytes", "land",
"wrong_fragment", "urgent", "hot", "num_failed_logins", "logged_in", "num_compromised",...))
.setOutputCol("features")
val cols = df_final.columns.map(f => col(f).cast(DoubleType))
val df_finalDataFrame = assembler.transform(df_final.select(cols: _*))最后做一次归一化操作,防止某列数值太大,影响聚类对各列的权重划分
val featuresDataFrame = df_finalDataFrame.select("labelIndex", "features")
val labelBack = new IndexToString().setInputCol("labelIndex")
.setOutputCol("label").setLabels(label_indexer.labels)
val scaler = new StandardScaler().
setInputCol("features").
setOutputCol("scaledFeatureVector").
setWithStd(true).
setWithMean(false))1.3最佳K值演算
KMeans的设置参数如下图
| K | k个聚类 |
| MaxIter | 最大迭代次数 |
| Tol | 收敛阈值 |
| seed | 随机种子 |
| initMode | 初始化方式 |
| initStep | KMeans||方法步数 |
寻找KMeans最佳k值常用的是手肘法(随着k增大,误差平方和会变小,并且会出现一个明显的拐点,这个拐点意味着此时的k值已经接近数据真实的k值),寻找出最佳的k值,k = [10,20,30,…..200],考虑到初始值未设定,所以本次采用8次循环求均值的方式,KMeans迭代30次。评估的参数有:
欧氏距离:[-1,1]越接近1说明各类数据越接近聚类点且远离其他聚类点
误差平方和WSSSE:越小说明各点离聚类越近
质心距离阈值:查看质心距离Top第50的变化趋势
//该方法运行时间超过3h,谨慎运行
for (k <- 10 to 200 by 10) {
var WSSSE: Double = 0
var avgThreshold: Double = 0
var avgEuclidean: Double = 0
for (n <- 1 to 8) {
val Array(trainData, testData) = trainDF.randomSplit(Array(0.7, 0.3))
val km = new KMeans()
.setFeaturesCol("scaledFeatureVector")
.setPredictionCol("prediction")
.setMaxIter(30)
.setK(k)
val pipeline = new Pipeline()
.setStages(Array(scaler, km))
val prKmeans = pipeline.fit(trainData)
val predictionKMeans = prKmeans.transform(testData)
val evaluator = new ClusteringEvaluator()
.setPredictionCol("prediction")
.setFeaturesCol("scaledFeatureVector")
val kMeansModel = prKmeans.stages.last.asInstanceOf[KMeansModel]
val centroids = kMeansModel.clusterCenters //k个中心点
// centroids.foreach(println)
//取出点向量与对应的prediction中心点的距离
val threshold = predictionKMeans.select("prediction", "scaledFeatureVector").as[(Int, Vector)].
map { case (cluster, vector) => Vectors.sqdist(centroids(cluster), vector) }.
orderBy($"value".desc)
val thresholdList = threshold.collectAsList()
val length = threshold.count()
var sum: Double = 0
val jessica = thresholdList.takeRight(length.toInt - 10)
jessica.foreach(x => {
sum = sum + x * x
})
WSSSE = WSSSE + (sum / length - 10)
avgThreshold = avgThreshold + threshold.take(100).last
avgEuclidean = avgEuclidean + evaluator.evaluate(predictionKMeans)
}
println("当k = " + k + ", 欧氏距离为" + avgEuclidean / 8 + ", 质心距离阈值为:" + avgThreshold / 8 + ", 误差平方和为:" + WSSSE / 8)
}将输出的数据,放进Python的图表中
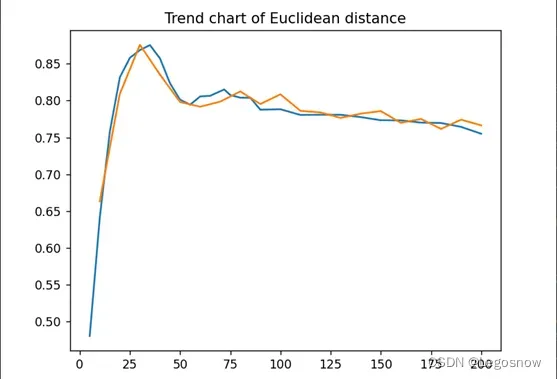


根据上图可以发现,当k = 25上下的时候,欧式距离是0.85最接近1,随后便开始下降,但总体依旧在0.8的上下,变化不是很大。反观误差平方和WSSSE,可以发现k=25的时候,WSSSE却高达4000多,根据手肘法,可以发现k=80的时候为佳k值点。
本次采用质心距离的想法是,数据集本身是存在噪点的,无论k取多少,而且总会有几个数据的质心距离超级大的离谱,所以根据求出所有点离质心的距离,根据从大到小排序,获取第50个数据为质心距离阈值,以来将其50名内的数据均视为异常点并给予后续的检测。二来当该数值变化稳定时,可以证明,测试集中的148000多的数据中,以牺牲50条数据,换取剩下的147950条数据的高可信度。
1.4训练模型,预测模型
1)所以根据以上三个评估点,采用k=80为最佳情况,并开始训练模型
println("模型训练------------------------------------------------------------------------------------------------------>")
val Array(trainData, testData) = trainDF.randomSplit(Array(0.7, 0.3))
val km = new KMeans()
.setFeaturesCol("scaledFeatureVector")
.setPredictionCol("prediction")
.setMaxIter(40)
.setK(80)
val pipeline = new Pipeline()
.setStages(Array(scaler, km))
val prKmeans = pipeline.fit(trainData)
val saveFile = "file:///C:/Users/Lenovo/Desktop/Working/Python/data/Kdd99KMeans"
prKmeans.write.overwrite().save(saveFile)
println("PipelineModel模型保存成功")
val predictionKMeans = prKmeans.transform(testData)
val evaluator = new ClusteringEvaluator()
.setPredictionCol("prediction")
.setFeaturesCol("scaledFeatureVector")
println("聚类时间花费为:" + (System.currentTimeMillis() - timeOld) / 1000 + "s")
println("模型评估------------------------------------------------------------------------------------------------------>")
println("k = 80 欧氏几何距离:" + evaluator.evaluate(predictionKMeans))
val kMeansModel = prKmeans.stages.last.asInstanceOf[KMeansModel]
val centroids = kMeansModel.clusterCenters //k个中心点
// centroids.foreach(println)
//取出100个点向量与对应的prediction中心点的距离
val threshold100 = predictionKMeans.select("prediction", "scaledFeatureVector").as[(Int, Vector)].
map { case (cluster, vector) => Vectors.sqdist(centroids(cluster), vector) }.
orderBy($"value".desc)
val threshold100List = threshold100.collectAsList()
val length = threshold100.count()
var sum: Double = 0
val jessica = threshold100List.takeRight(length.toInt - 10)
println("删除top10数值")
jessica.foreach(x => {
sum = sum + x * x
})
println("总误差为:" + sum + " 测试机数量为:" + (length) + " 误差平方和为:" + sum / (length - 10))
val threshold = threshold100.take(50).last
println("质心距离阈值为:" + threshold)
println("分类排名top50------------------------------------------------------------------------------------------------->")
val tes = predictionKMeans
.groupBy("labelIndex", "prediction")
.count()
.orderBy(-col("count"))
tes.show(50, false)
tes.groupBy("prediction")
.max("count")
.withColumnRenamed("max(count)","count")
.agg(functions.sum("count"))
.withColumnRenamed("sum(count)","preCount")
.withColumn("sumCount",lit(length))
.withColumn("Accuracy",col("preCount")/col("sumCount"))
.show(false)
2)尽管KMeans并没有交叉验证的评估器,但是求出每一个聚类的最高划分数值的和,除以测试集数量,划分的合格率达到99%。
3)预测集中只有41个特征值,没有最后一列的数据类型值,我们根据原方法将数据合并后,以训练出的模型预测数据集后,再根据求出的质心阈值,求出可能存在的异常点。
println("模型预测------------------------------------------------------------------------------------------------------>")
val predictionFile = "C:/Users/Lenovo/Desktop/Working/Python/data/kddcup.testdata.unlabeled_10_percent.csv"
val predictionData = spark.read.csv(predictionFile)
// fileData.map(_.split(',').last).countByValue().toSeq.sortBy(_._2).reverse.foreach(println)
val predictionDataFrame = predictionData
.toDF("duration", "protocol_type", "service", "flag", "src_bytes", "dst_bytes", "land",...)
predictionDataFrame.cache()
val predictionIndexed_0 = pretocol_indexer.transform(predictionDataFrame)
val predictionindexed_1 = service_indexer.transform(predictionIndexed_0)
val predictionIndexed_2 = flag_indexer.transform(predictionindexed_1)
val proserfla = predictionIndexed_2.select("protocol_type", "service", "flag")
val predictionDf_final = predictionIndexed_2.drop("protocol_type").drop("service")
.drop("flag")
val predictionCols = predictionDf_final.columns.map(f => col(f).cast(DoubleType))
val predictionDf_finalDataFrame = assembler.transform(predictionDf_final.select(predictionCols: _*))
// predictionDf_finalDataFrame.show(5,false)
val preFeaturesDataFrame = predictionDf_finalDataFrame.select("features")
val preDataFrame = prKmeans.transform(preFeaturesDataFrame)
println("预测集合个数为:" + preDataFrame.count())
preDataFrame.join(proserfla).show(20, false)
println("异常检测------------------------------------------------------------------------------------------------------>")
val abnormalDF = preDataFrame
.filter(row => {
val cluster = row.getAs[Integer]("prediction")
val vec = row.getAs[Vector]("scaledFeatureVector")
Vectors.sqdist(centroids(cluster), vec) > threshold
})
abnormalDF.show(20,false)
4)根据异常检测,最后在311029个预测集中,挑选出257个可能存在的异常数据,用于后续的检测是否为正常数据,大大缩短了检测时间。
Tips:考虑到详解篇幅可能过长,所以接下来的算法只挑代码端的讲
2.LogisticRegression回归-鸢尾花
逻辑斯蒂回归(logistic regression)是统计学习中的经典分类方法,属于对数线性模型。logistic回归的因变量可以是二分类的,也可以是多分类的。

2.1逻辑蒂斯回归实操
1)本次采用的是Iris鸢尾花数据集来实操逻辑蒂斯回归,查看数据集可以发现,只有4列特征值,并且本身是数字的字符串类型,所以可以创建函数来数据集合并成Vector
case class iris(features : Vector, label : String)
def main(args:Array[String]): Unit ={
val spark = SparkSession.builder().appName("iris").master("local").getOrCreate()
val sc = spark.sparkContext
val file = "C:/Users/Lenovo/Desktop/Working/Python/data/iris.txt"
val data = sc.textFile(file) //一定要确保txt文件没有空行,格式要保持一致
import spark.implicits._
val irisData = data
.map(_.split(","))
.map(p=>iris(Vectors.dense(p(0).toDouble,p(1).toDouble,p(2).toDouble,p(3).toDouble),p(4).toString))
.toDF()
.cache()
// irisData.show(false)2)随后转换鸢尾花字符串的索引,并创建流水线
// 将花的品种转换为index标签,易识别
val labelIndexer = new StringIndexer()
.setInputCol("label")
.setOutputCol("indexedLabel")
.fit(irisData)
val labelIris = labelIndexer.transform(irisData)
labelIris.show(false)
// 获取特征列
val featureIndexer = new VectorIndexer()
.setInputCol("features")
.setOutputCol("indexedFeatures")
.fit(labelIris)
val featuresIris = featureIndexer.transform(labelIris)
featuresIris.show(false)
// 设置逻辑斯蒂回归算法参数,循环100次,规范化为0.3,参数设置可以在explainParams()函数了解
val lr = new LogisticRegression()
.setLabelCol("indexedLabel")
.setFeaturesCol("indexedFeatures")
.setMaxIter(100)
.setRegParam(0.3)
.setElasticNetParam(0.8)
.fit(featuresIris)
// println("LogisticRegression parameters: \n"+ lr.explainParams()+"\n")
// 将测试集中的indexedLabel转换为花的品种label,属于index->String
val labelConverter = new IndexToString()
.setInputCol("prediction")
.setOutputCol("predictedLabel")
.setLabels(labelIndexer.labels)
// 构建机器学习流水线,上阶段输出为本阶段输入
val lrPipeline = new Pipeline()
.setStages(Array(labelIndexer, featureIndexer, lr, labelConverter))
3)划分训练集和测试集,并评估模型正确率
val Array(trainingData, testData) = irisData.randomSplit(Array(0.8, 0.2))
val lrPipelineModel = lrPipeline.fit(trainingData)
val lrPredictions = lrPipelineModel.transform(testData)
lrPredictions.show(false)
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
val lrAccuracy = evaluator.evaluate(lrPredictions)
println("预测的正确率为:"+lrAccuracy) //在0.8上下浮动
可以看到正确率为84%,说明本模型属于良好
3.DecisionTree分类KDD99数据集
决策树以及它们的集成都是分类和回归机器学习任务中非常流行的算法。决策树因其易解释性,能够处理类别特征,可扩展到多分类问题,不需要特征缩放,而且可以得到非线性以及特征交互(feature interaction)的优点而被广泛使用。树的集成算法,例如随机森林和提升算法,都在分类和回归问题上取得了顶尖的效果。
决策树是一种贪心算法,它将特征空间进行递归地二分。对于每个叶节点,决策树会给出一个预测。每个节点都是通过贪心地选择所有可能的切分中最好的切分进行的,从而最大化每个树节点的信息增益。
节点不纯度是节点内标签均匀度(homogeneity)的一种测量方式。目前提供两种应用于分类问题的不纯度测量方式(基尼不纯度(Gini impurity)和熵(entropy)),以及一种应用于回归问题的不纯度测量方式(方差(variance))。

Spark.mlib支持用于二分类、多分类以及回归问题的决策树,也同时支持连续和类别特征。实现方式将数据以行分隔,可以分布式地训练百万样本。
3.1决策树参数如下
| Impurity | 不纯度,”entropy”,”gini”。默认后者 |
| MaxBins | 离散化”连续特征”的最大划分数 |
| MaxDepth | 最大深度 |
| MinInfoGain | 一个节点分裂的最小信息增益,值为[0,1] |
| MinInstancesPerNode | 每个节点包含的最小样本数 |
| Seed | 随机种子 |
3.2决策树实操
1)决策树采用的是聚集跟KMeans的KDD99数据集是一样的,所以数据的预处理阶段是同性质的(看吧,机器学习的代码端确实没有想象中的那么难,还是挺方便的),但与他不同的是,决策树属于分类算法,所以数据集中有23个数据类型,那就意味着决策树会分出<=23个prediction,所以在构建决策树之前,我们需要对预测出的prediction进行IndexToString的“回溯”操作,即将Double->String:
//此featuresDataFrame与KMeans算法中的DataFrame是一样的,所以这里就不赘述了
val labelIndexer = new StringIndexer().setInputCol("label")
.setOutputCol("indexedLabel").fit(featuresDataFrame)
val featureIndexer = new VectorIndexer().setInputCol("features")
.setOutputCol("indexedFeatures").setMaxCategories(10).fit(featuresDataFrame)
val labelConverter = new IndexToString().setInputCol("prediction")
.setOutputCol("predictedLabel").setLabels(labelIndexer.labels)
val Array(trainData, testData) = featuresDataFrame.randomSplit(Array(0.7, 0.3))2) 构建决策树并验证决策树正确率以及,以及策树展示出来:
//决策树
val dtClassifier = new DecisionTreeClassifier()
.setLabelCol("indexedLabel")
.setFeaturesCol("indexedFeatures")
.setMaxBins(100).setMaxDepth(8).setMinInfoGain(0.01)
val lrPipeline = new Pipeline()
.setStages(Array(labelIndexer, featureIndexer, dtClassifier, labelConverter))
val dtPipelineModel = lrPipeline.fit(trainData)
val dtPredictions = dtPipelineModel.transform(testData)
dtPredictions.show(10, false)
val evaluator = new MulticlassClassificationEvaluator()
.setPredictionCol("prediction")
.setLabelCol("indexedLabel")
val dtAccuracy = evaluator.evaluate(dtPredictions)
println("测试机的正确率为:" + dtAccuracy)
val treeModelClassifier = dtPipelineModel.stages(2)
.asInstanceOf[DecisionTreeClassificationModel]
println("Learned classification tree model: \n" + treeModelClassifier.toDebugString) 3)可以发现正确率为99%,但实际上决策树的深度触碰到了最大深度,所以可能需要考虑到是否需要剪枝来抵制过拟合的情况,以及模型能够泛化。与KMenas的KDD99算法相比,决策树的侧重点在对新数据进行分类,其主要目的是划分各项数据对应的23个数据类型,所以与KMeans的任务目标不相同,有不同的作用,具体要看项目的目标,来决定采用何种机器算法。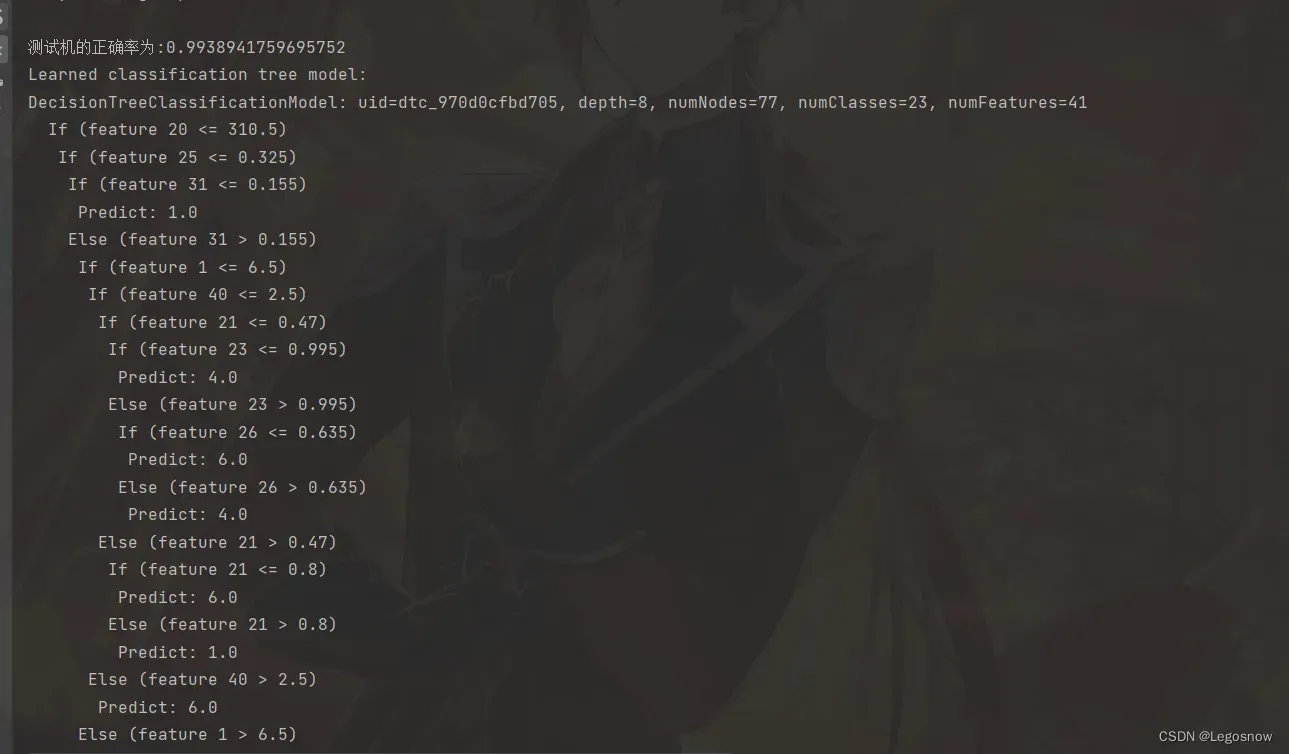
4.ALS协同过滤用户电影推荐
ALS是Alternating Least Squares的缩写,即交替最小二乘法。常用于基于矩阵分解的推荐系统中。例如将用户(User)与项目(Item)的评分矩阵分解为两个矩阵:用户对项目隐含特征的偏好矩阵、项目所包含的隐含特征的矩阵。在矩阵分解的过程中,评分缺失项得到了补充,便可以基于填充的评分来给用户推荐项目。即对于R(m*n)的矩阵可以用两个低纬矩阵P(m*k)和Q(n*k)逼近R(m*n)
其中k<<min(m,n).这相当于降维,矩阵P和Q也称为低秩矩阵,为了使低秩矩阵P和Q尽可能逼近R,可以最小化损失函数L来完成
ALS是求解L(P,Q)的组名算法,基本思想是:固定其中一类参数,使其变成单类变量,利用解析方法进行优化;再反过来,固定先前优化过的参数,再优化另一组参数….此过程迭代进行,直到收敛
4.1 显性反馈和隐形反馈
显性反馈行为属于用户能够对项目有明确的喜好评价,而隐性反馈行为指的是那些不能明确反应用户喜好的行为。再日常生活中接触的多为隐形反馈,包括购买行为,页面浏览点击,分享行为等等。ALS算法也存在着对于隐形反馈行为模型的计算,本质上,这个方法将数据作为二元偏好值和偏好强度的一个结合,而不是对评分矩阵直接进行建模。因此,评价就不是与用户对商品的显性评分,而是与所观察到的用户偏好强度关联起来。然后,这个模型将尝试找到隐语义因子来预估一个用户对一个商品的偏好。Collaborative Filtering for Implicit Feedback Datasets
4.2ALS参数选择
| numBlocks | 并行化计算分块数,默认10 |
| maxIter | 最大迭代次数,默认10 |
| rank | 隐语因子个数,默认10 |
| regParam | 正则化参数,默认1.0 |
| implicitPrefs | 是否隐形反馈,默认false |
4.3ALS实操
本次采用的是电影推荐,使用的数据集为ratings.data,通过ALS算法统计每一位用户的推荐的TOP5电影id将其存储起来。可以明显地意识到,这张数据表一般是以缓存表的形式存在,即可以尝试存储到HBase上,但为了方便,我将其存储到MYSQL即可。
1)因为数据集是通过”::”分割开的,所以无法通过csv一步到位转换为DataFrame,可通过RDD[Row]与表头结合创建成DataFrame
用户-项目-评分-时间戳
1::1193::5::978300760
val file = "C:/Users/Lenovo/Desktop/Working/Python/data/ml-1m/ratings.data"
val rddFile = sc.textFile(file)
val rddRow = rddFile.flatMap(_.split("\n"))
.map(_.split("::"))
.map(x =>Row(x(0).toInt,x(1).toInt,x(2).toDouble,x(3).toLong))
// .toDF()
println("一共有:"+rddRow.count()+"项评分")
val schema = StructType(Array(
StructField("userID", IntegerType),
StructField("movieID", IntegerType),
StructField("rating", DoubleType),
StructField("timeStamp",LongType)
))
val orgDF = spark.createDataFrame(rddRow,schema)
orgDF.show(5,false)
val Array(trainData,testData) = orgDF.randomSplit(Array(0.7,0.3))2) 创建ALS,因为有明确的评分,所以本次采用的是显性反馈ALS算法,并且为用户推荐Top5
val timeOld = System.currentTimeMillis()
//建立显性反馈模型,默认显性 最大迭代次数5,正则化参数0.01, 默认0.1(>=0)
val alsExplicit = new ALS()
.setMaxIter(5)
.setRegParam(0.01)
.setUserCol("userID")
.setItemCol("movieID")
.setRatingCol("rating")
val modelExplicit = alsExplicit.fit(trainData)
println("ALS时间花费为:" + (System.currentTimeMillis() - timeOld) / 1000 + "s")
val predictionExplicit = modelExplicit.transform(testData).na.drop()
// val predictionImplicit = modelImplicit.transform(testData).na.drop()
val evaluator = new RegressionEvaluator()
.setMetricName("rmse")
.setLabelCol("rating")
.setPredictionCol("prediction")
println("显性ALS的均方差为:"+evaluator.evaluate(predictionExplicit))
//为用户推荐电影Top n
val a = modelExplicit.recommendForAllUsers(5)
// val b = modelExplicit.recommendForAllItems(5)
a.show(false)
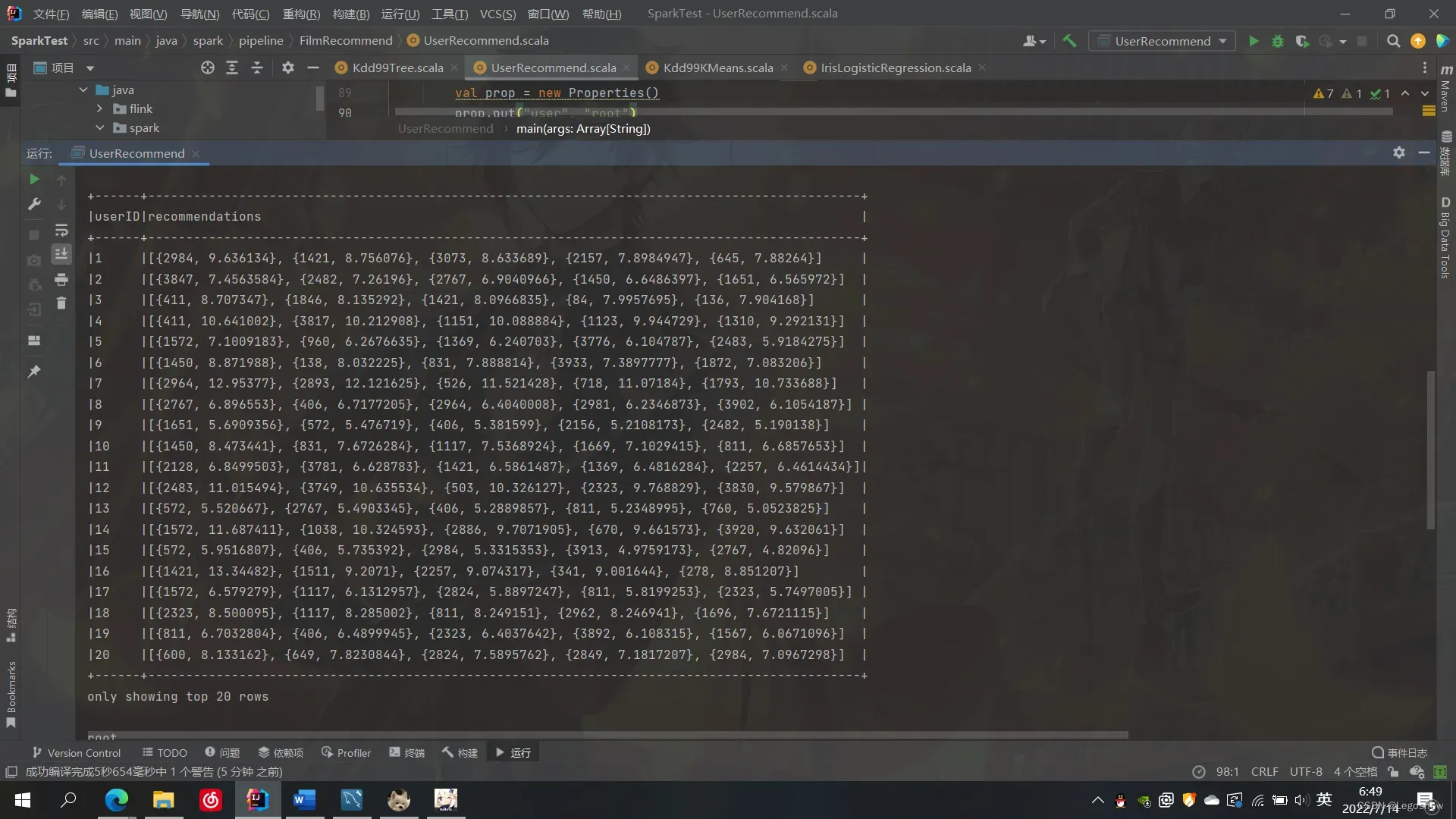
3)根据上图可以发现,虽然我们获取到了用户的推荐电影id以及对应的分数,但它不能成为我们将其存储到Mysql的数据类型,所以我们需要将recommendations的内容摊开,转换成能够存储到Mysql的二维数据表
val splitDF = a.select(col("userID"),col("recommendations").getItem(0).as("1"),
col("recommendations").getItem(1).as("2"),
col("recommendations").getItem(2).as("3"),
col("recommendations").getItem(3).as("4"),
col("recommendations").getItem(4).as("5"))
println(splitDF.printSchema)
val userRecommendDF = splitDF
.withColumn("Top1",$"1"("movieID"))
.withColumn("Top2",$"2"("movieID"))
.withColumn("Top3",$"3"("movieID"))
.withColumn("Top4",$"4"("movieID"))
.withColumn("Top5",$"5"("movieID"))
.select("userID","Top1","Top2","Top3","Top4","Top5")
userRecommendDF.show(5,false)
val prop = new Properties()
prop.put("user", "root")
prop.put("password", "******")
prop.put("driver","com.mysql.jdbc.Driver")
val url = "jdbc:mysql://localhost:3306/python_db"
println("开始写入数据库")
userRecommendDF.write.mode("overwrite").jdbc(url,"userRecommendMovieID",prop)
println("完成写入数据库")
4)上传成功
四、总结
相比较深度学习,其实Spark的机器学习库学习的整体难度并不大,因为它已经形成了一套比较完整好用的API,你只需要掌握部分知识,你便可以解决这些问题,不过本次文章可能略显粗糙,若有一些错误或者可以优化的地方,恳请指出
文章出处登录后可见!