2023 Mask R-CNN 改进:DynaMask: Dynamic Mask Selection for Instance Segmentation 论文笔记
写在前面
本周更新的第二篇论文阅读,2023年每周一篇博文,还剩5篇未补,继续加油~
- 论文地址:DynaMask: Dynamic Mask Selection for Instance Segmentation
- 代码地址:https://github.com/lslrh/DynaMask
- 收录于:CVPR 2023
- 欢迎关注,主页更多干货,持续输出中~
一、Abstract
一般的实例分割通常采用固定分辨率大小的 mask,例如 的网格来划分不同的目标。然而,低分辨率的 mask 经常会丢失丰富的细节信息,而高分辨率的 mask 会使得计算量成平方增长。本文针对不同的目标 proposal 提出一种动态选择合适尺寸的 mask 方法。首先:一个自适应特征聚合的双端 FPN 用来逐渐地增加 mask 网格分辨率。具体来说,一个区域级别的自上而下路径被引入来整合不同阶段的图像 FPN 层的上下文和细节信息。之后提出一种 Mask Switch Module(MSM) 从每个实例中选择选择最合适的 mask 分辨率。提出的 DynaMask 效果很好。
二、引言
实例分割 Instance segmentation (IS) 的目的,进展。目前的方法大致分为双阶段的和单阶段的。双阶段精度高但是成本也高。
聊一下双阶段的方法,即先检测后分割。先对于所有的 proposal,例如 来预测一个统一分辨率的二值网格 mask,然而上采样到原始尺寸。接下来举出 Mask R-CNN 的例子,指出缺点:低分辨率的 mask 很难捕捉细节的信息,导致预测结果不满意,特别是对于过大的目标边界,而大的 mask 会使得计算量成本上升。

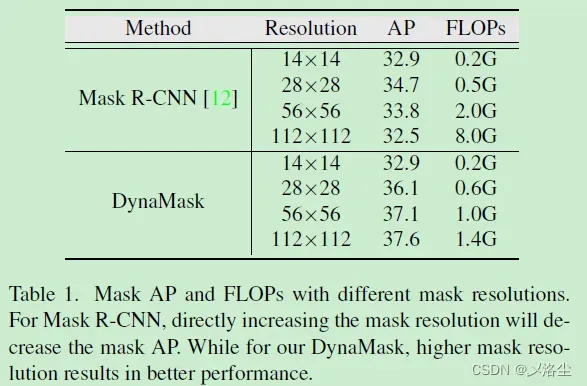
- 提出 DynaMask 来自适应地赋值给不同的实例以合适的 mask:赋值低分辨率给简单样本,而赋值高分辨率给难样本;
- 提出一种双端 FPN 框架用于 IS,构建从 i-FPN 到 r-FPN 多层的信息流动,用于促进信息互补和聚合;
- 实验结果表明 DynaMask 性能和效率很好。
三、相关工作
实例分割
目前大多数方法沿着 Mask R-CNN 的套路,接下来对 Mask Scoring R-CNN、BMask RCNN、DCT-Mask、PANet 进行简单介绍。一些工作提出通过粗糙-细腻化的精炼来提升 mask 的质量,例如 HTC、PointRend、RefineMask,缺点是增加推理时间和内存负担。本文提出动态地为每个实例选择合适的 mask,使得简单样本被赋值小的 mask(更少的精炼阶段),更难的样本被赋值大的 mask(更多的精炼阶段)。
动态网络
动态网络方法要么扔掉一些 blocks 或者修剪通道数,例如 SkipNet、DRNet 等。而在不同的分辨率采用动态 mask 来分割不同的实例还未被探索过。传统方法先预测一个固定尺寸的 mask,这一措施对简单样本很管用,但过于简化难样本的细粒度水平细节。根据分割难易,本文设计一种动态 mask 选择框架来自适应地给不同的目标分配合适尺寸的 mask。
四、动态 Mask 选择
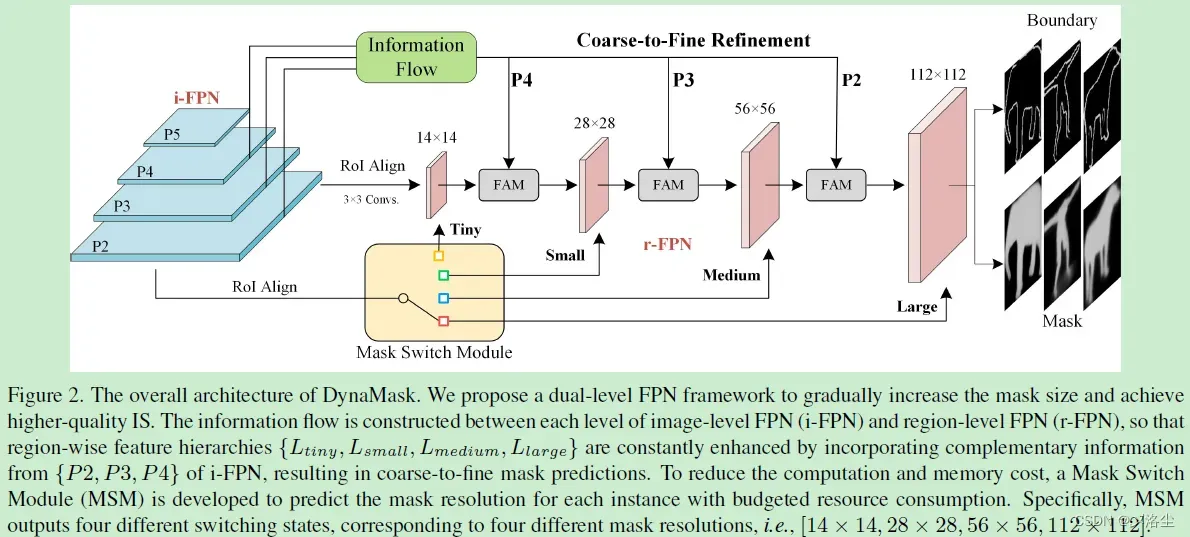
4.1 双层 FPN
原始图像层 FPN (i-FPN) 引入自上而下的路径,将高层的上下文的语义信息投影到低层中。本文提出一个区域水平的 r-FPN,将 i-FPN 中的低层整合更多的信息到区域特征层级上。从 i-FPN 到 r-FPN 的信息流动上图所示。
区域水平的 FPN
依据原始的 i-FPN 来定义层的概念,从而产生对应于原始特征图相同分辨率的层。r-FPN 起始于 RoI-Aligned 的区域特征,通过逐渐地融合
的互补信息来增强,得到一组自上而下的基于区域的特征层次,表示为
。从
到
,空间分辨率通过逐步地扩大两个尺寸因子来增加。本文设计一个特征聚合模块 Feature Aggregation Module (FAM) 来整合 r-FPN 的特征
和 i-FPN 特征
。
特征聚合模块 FAM
由于上采样和 RoI 池化操作,使得现有的 和
之间存在空间误对齐,这会降低对于边界区域的分割性能。本文提出 FAM 来自适应地聚合多尺度的特征,如下图所示:

4.2 Mask Switch Module (MSM)
不同的实例需要不同的 mask 网格来实现准确的分割,遂提出一种自适应地根据不同实例来调整 mask 网格的分辨率。确切来说,一个 MSM 用来在预算计算的假设下执行 mask 分辨率预测,从而在性能和分割准确度之间权衡。
最优的 Mask 赋值
MSM 实际上是一个轻量化的分类器,记为 ,如下图所示:
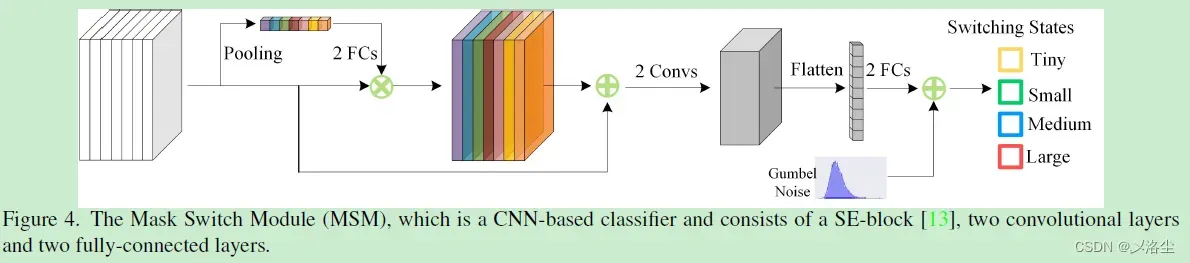
采用 Gumbel-Softmax 的重参数化
将 MSM 的软输出 转化为独热预测
,
,这一过程可以用分离采样来表示,然而不能微分,因此不支持端到端训练。
为了使得 MSM 的梯度得以更新,引入一种重参数化方法,Gumbel-Softmax。给定一个类别分布概率 ,通过规则:
其中 为
分布的样本,定义为:
之后采用 Gumbel-Softmax 函数作为一个连续的、可微分的原始 函数的近似:
其中
表示温度参数,当
接近
时,Gumbel-softmax 接近于独热状态。
4.3 目标函数
Mask 损失
给定正的样本实例 ,首先通过 MSM 来预测 mask 的 switching state:
,并将其穿过 r-FPN 的不同阶段来获得
个不同分辨率
下的 mask 预测图,定义损失函数如下:
其中
表示
的第
个 mask 预测,
表示相应的 GT mask 网格。
为是否第
个 mask 分辨率被选择作为输出分辨率的索引。
为 cross-entropy 损失。
边缘损失
Mask 损失中,假设 mask 产生非常小的损失应该有着很高的质量。因此通过最小化 mask 损失可以得到准确的 mask,然而实验结果表明 mask 损失在不同的 mask 上非常接近,很难区分 mask 质量。相比之下,由不同分辨率产生的 mask 在边缘损失上变化巨大,这能很好的揭示 mask 质量。

预算限制
通过优化边缘损失,模型倾向于收敛到次优的结果:所有的实例都采用最大的 mask 来分割,即 ,这整合了更多的细节信息且拥有最小的预测损失。而实际上,并不是所有的样本都需要最大的 mask,对于简单样本能够节省冗余的计算量。为了降本增效,提出带有预算限制的 MSM。令
表示对应于选择的 mask 分辨率损失,当前 batch 数据所产生的期望 FLOPs 记为
,而超出目标 FLOPs 的部分记为
,预算限制定义为:
进一步引入信息 entropy 损失来平衡 MSM 的分辨率预测。给定一组输出概率向量 ,其中
为当前 batch 内的实例数量,第
个分辨率的频率计算为:
。
信息 entropy 损失定义如下:
上面的 entropy 损失将每个元素
推向
,以使 MSM 能够从相似概率中选择不同的分辨率。
最后,mask 分支的总体目标函数:
其中
、
为平衡超参数,
表示结合了预算限制的正则项,即
。
五、实验
数据集:COCO、Cityscapes,评估指标:标准的 mask AP。
5.1 实施细节
Backbone:Mask R-CNN,预训练在 ImageNet 上。部署在 MMDetection 上。MSM 有四个 switching states,对应于四组分辨率 ,
。首先使用 mask 损失在所有分辨率下训练没有 MSM 的网络一个 epoch。初始学习率
,batch_size 16,8 GPUs,之后训练所有模块 12 个 epochs,SGD,相同的初始学习率及 batch_size,在第 8 和 11 个 epochs 时分别
,多尺度训练策略,短边随机从
中采样,而在推理时,短边调整至 800。消融实验中采用
训练计划,数据增强采用 MMDetection 定义的方式。
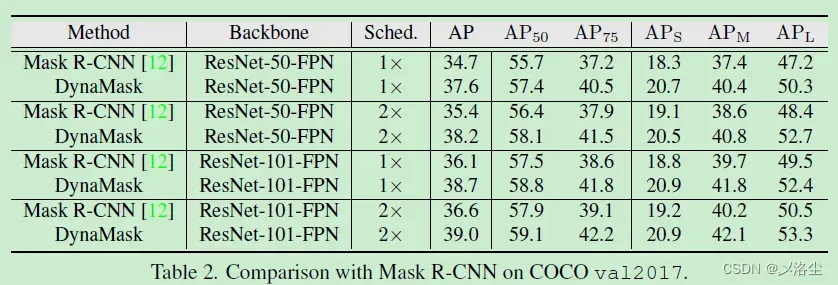
5.2 主要结果
与 Mask R-CNN 的比较
与 SOTA 的方法比较
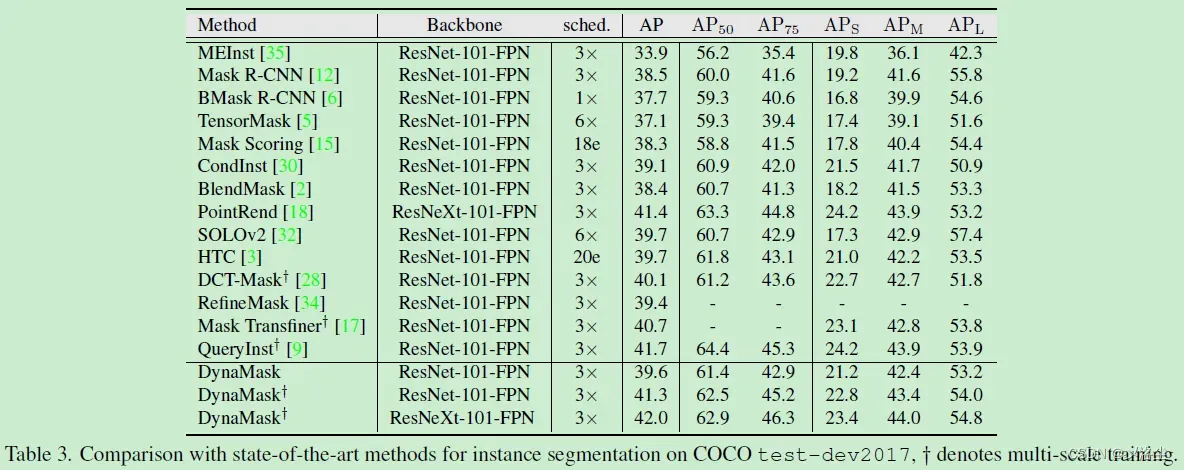
分割结果的可视化

5.3 消融实验
Mask 分辨率预测

预算限制的影响
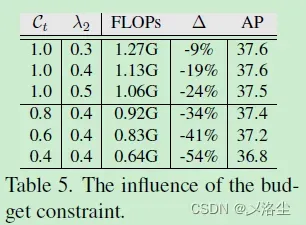
不同方法的速度比较
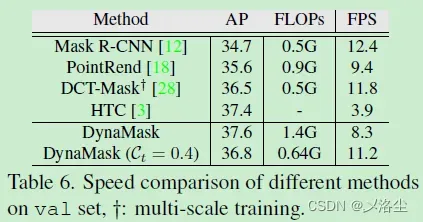
Mask 尺寸的影响
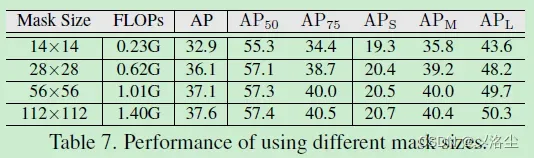
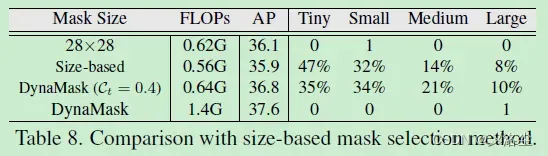
基于尺寸的 Mask 选择方法
基于尺寸的方法表示根据目标尺寸来赋值 mask,具体来说,采用下列规则赋值给宽 、高
的实例一个 mask:
其中
、
分别表示输入图像的宽、高。
表示最大的 mask 分辨率,例如
。这一式子意味着更大的目标将会赋值更大分辨率的 mask。实验结果如下表所示:
六、结论
设计了一种双层 FPN 结构来充分利用金字塔的多层中互补的上下文细节信息。具体来说,除一般的图像水平金字塔 i-FPN 外,利用一组区域水平的自上而下的路径来逐渐扩大 mask 的尺寸并整合更多的 i-FPN 细节。此外,引入了 Mask Switch Module (MSM) 来自适应地为每个 proposal 选择合适的 mask,从而减小简单样本的冗余计算量。大量的实验表明本文提出的方法很有用。
七、补充材料
7.1 关于 Mask 分辨率预测的分析
mask 分辨率和类别之间的关联
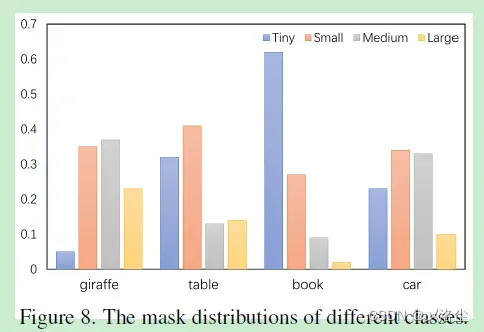
Mask 选择的结果

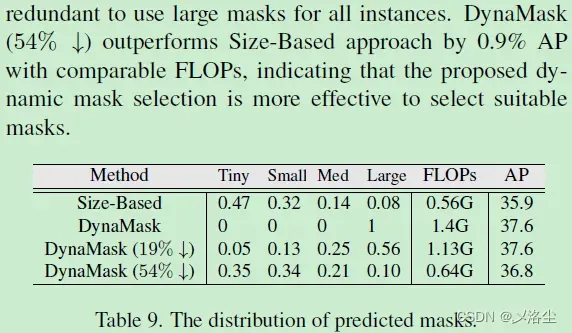
7.2 预测的 Mask 分辨率分布
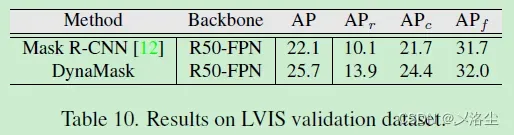
7.3 在 LVIS 数据集上的结果
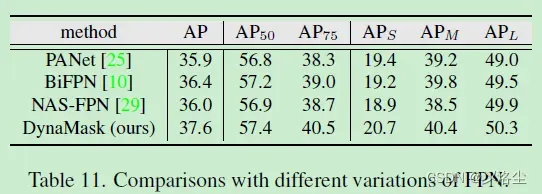
7.4 与其他 FPN 变体的比较
7.5 定性结果

本文框架以及写作手法都值得借鉴,在当今 Mask R-CNN 都快被挖的啥都没有的情况下,还能有如此创新性想法的文章属实难得一见了。
愉快的周末就要过去啦,下一周继续加油哇~
文章出处登录后可见!