目录
一、实践要求
1.从18.student_score.csv文件中读取同学的成绩册,处理好缺失值。
2.将实验报告成绩从ABCD转换成百分制,统计出实验成绩。A为90分,B为75分,C为60分,D为40分。
3.按照平时成绩20%,实验成绩30%,期末成绩50%的比例计算综合成绩,形成新的综合成绩列。
4.统计全班综合成绩[90,100],[80,89],[70,79],[60-69],[0,59]各段成绩的人数并画饼图。
5.将完整的成绩保存到score.csv文件中,打开excel检查输出是否正确。
二、测试数据
18.student_score.csv文件:(以下是分别用记事本和Excel打开的数据,可自行粘贴到记事本或Excel上保存为csv文件)
序号,姓名,平时成绩,实验成绩,期末成绩
1,张三,95,A,81
2,李四,94,B,60
3,王五,95,C,87
4,马七,97,D,75
5,梦雪,97,A,63
6,樱花,94,A,66
7,杏子,94,A,28
8,天涯,99,A,76
9,孔维,94,B,84
10,赵四,95,D,86
11,孙二,100,C,60
12,,98,,
13,太良,98,D,83
14,丁云,95,D,83
15,淑萍,98,D,80
16,溪美,98,C,53
17,泰山,96,A,67
18,梅花,,A,64
19,梅六,98,B,68
20,云霞,96,B,85
序号 姓名 平时成绩 实验成绩 期末成绩 1 张三 95 A 81 2 李四 94 B 60 3 王五 95 C 87 4 马七 97 D 75 5 梦雪 97 A 63 6 樱花 94 A 66 7 杏子 94 A 28 8 天涯 99 A 76 9 孔维 94 B 84 10 赵四 95 D 86 11 孙二 100 C 60 12 98 13 太良 98 D 83 14 丁云 95 D 83 15 淑萍 98 D 80 16 溪美 98 C 53 17 泰山 96 A 67 18 梅花 A 64 19 梅六 98 B 68 20 云霞 96 B 85
三、代码实现
1.从18.student_score.csv文件中读取同学的成绩册,处理好缺失值。
import pandas as pd
# 绘图需要使用的库
from matplotlib import pyplot as plt
# 从18.student_score.csv文件中读取同学的成绩册,处理好缺失值
df = pd.read_csv("18.student_score.csv")
df.set_index("序号", inplace=True) # 将序号作为index索引
df['姓名'].fillna('老六', inplace=True)
df = df.fillna(method="bfill") # 处理缺失值:backfill / bfill表示用后面行的值,填充当前行的空值
# print(df)输出的结果(print(df)):
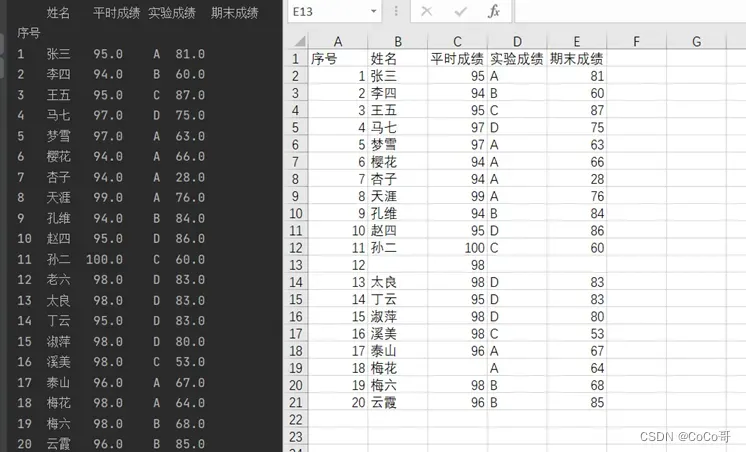
2.将实验报告成绩从ABCD转换成百分制,统计出实验成绩。A为90分,B为75分,C为60分,D为40分。
# 将实验报告成绩从ABCD转换成百分制,统计出实验成绩。A为90分,B为75分,C为60分,D为40分。
for x in df.index:
if df.loc[x, "实验成绩"] == 'A':
df.loc[x, "实验成绩"] = 90
if df.loc[x, "实验成绩"] == 'B':
df.loc[x, "实验成绩"] = 75
if df.loc[x, "实验成绩"] == 'C':
df.loc[x, "实验成绩"] = 60
if df.loc[x, "实验成绩"] == 'D':
df.loc[x, "实验成绩"] = 40
# print(df)输出的结果(print(df)):
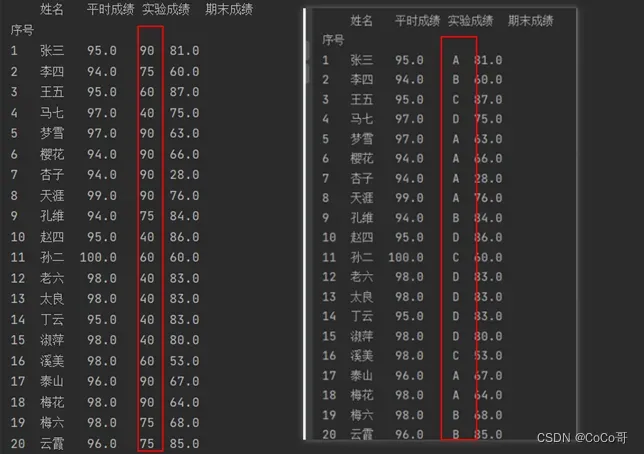
3.按照平时成绩20%,实验成绩30%,期末成绩50%的比例计算综合成绩,形成新的综合成绩列。
# 按照平时成绩20%,实验成绩30%,期末成绩50%的比例计算综合成绩,形成新的综合成绩列。
df["综合成绩"] = df["平时成绩"] * 0.2 + df["实验成绩"] * 0.3 + df["期末成绩"] * 0.5
print(df)
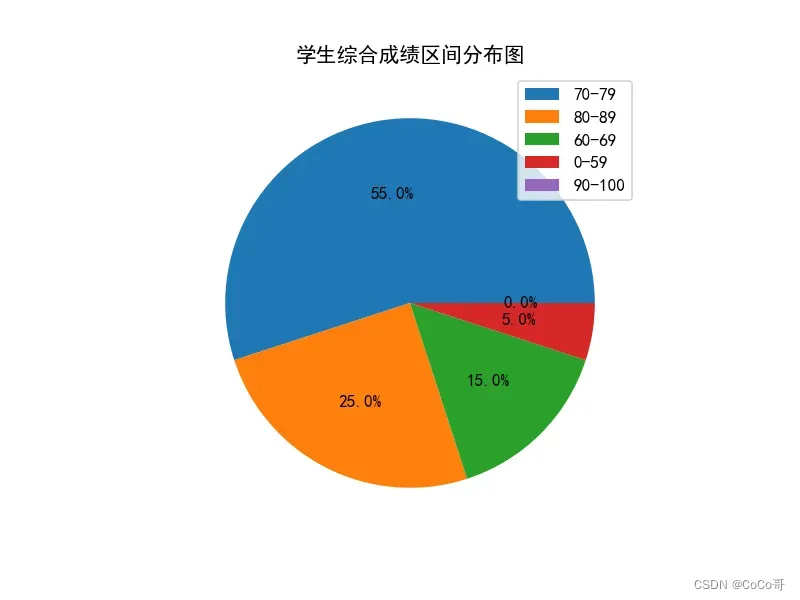
# 统计全班综合成绩[90,100],[80,89],[70,79],[60-69],[0,59]各段成绩的人数,并画饼图。
num = pd.cut(df['综合成绩'], bins=[0, 60, 70, 80, 90, 100], labels=['0-59', '60-69', '70-79', '80-89', '90-100'],
right=False) # bins为分区的分界值,labels为相应区间的标签
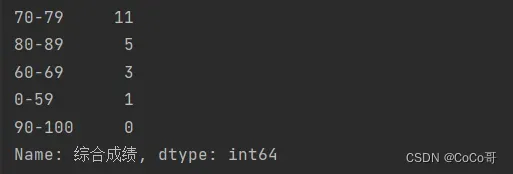
counts = num.value_counts() # 统计区间人数
# print(counts)输出的结果:print(df)
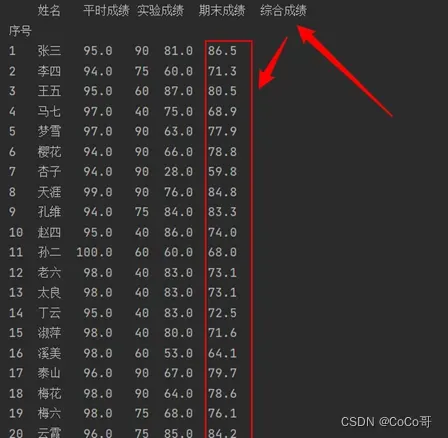
print(counts):
4.统计全班综合成绩[90,100],[80,89],[70,79],[60-69],[0,59]各段成绩的人数并画饼图。
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文字体
plt.pie(counts, autopct='%1.1f%%')# autopct后面的值1.1表示保留2位小数
plt.legend(labels=['70-79', '80-89', '60-69', '0-59', '90-100'], loc="best") # 绘制图的图例为name,位置为最佳
plt.title("学生综合成绩区间分布图") # 饼图的名称
plt.show()输出的结果:
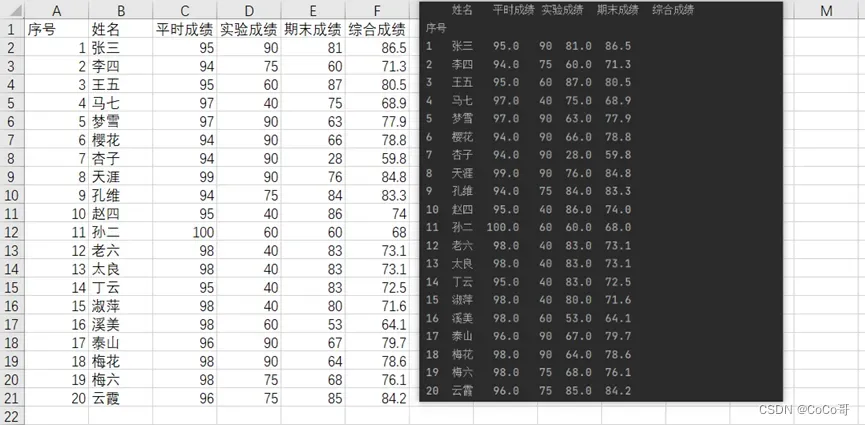
5.将完整的成绩保存到score.csv文件中,打开excel检查输出是否正确。
# 完整的成绩保存到score.csv文件中,打开excel检查输出是否正确。
df.to_csv('score.csv', encoding='utf-8-sig')
# “utf-8-sig"中sig全拼为 signature 也就是"带有签名的utf-8”,
# 因此"utf-8-sig"读取带有BOM的"utf-8文件时"会把BOM单独处理,与文本内容隔离开,也是我们期望的结果。打开excel检查输出是否正确:
四、学习资料
以下是本实践涉及到的学习资料链接:
python解决csv文件用excel打开乱码问题 – 简书 (jianshu.com)
(93条消息) python csv写文件,用Excel打开中文乱码解决_dcong9010的博客-CSDN博客
数据分箱之pd.cut() – 知乎 (zhihu.com)
Pandas 数据清洗 | 菜鸟教程 (runoob.com)
(93条消息) 菜鸟编程:python中使用matplotlib绘制饼状图_小菜鸟Zoe的博客-CSDN博客
文章出处登录后可见!
已经登录?立即刷新