文章目录
- 1. 导入库
- 2. 发送HTTP请求获取页面内容
- 3. 解析HTML内容
- 4. 定位和提取电影信息
- 5. 存储数据
- 6. 反爬虫策略及应对方法
- 完整代码及运行结果
网络爬虫是一种获取互联网上数据的方法,但在实际应用中,需要注意网站可能采取的反爬虫策略。本文将介绍如何使用Python爬取xx电影Top250的数据,并探讨一些常见的反爬虫策略及应对方法。
1. 导入库
首先,需要导入requests库和BeautifulSoup库,以及csv库。
requests库用于访问目标网站,获取网页数据。
BeautifulSoup库用于处理requests获得的数据进行解析和处理。
csv库用于最后数据的存储。
import requests
from bs4 import BeautifulSoup
import csv
2. 发送HTTP请求获取页面内容
我们使用requests.get()函数发送GET请求,并模拟浏览器的请求头信息,以减少被网站识别为爬虫的风险。
url = 'https://movie.douban.com/top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
response = requests.get(url, headers=headers)
3. 解析HTML内容
创建一个BeautifulSoup对象,并指定解析器和要解析的内容。
soup = BeautifulSoup(response.text, 'html.parser')
4. 定位和提取电影信息
两种方式:
4.1 select_one()
定位电影信息:根据HTML结构和标签的特点,使用BeautifulSoup提供的选择器方法定位电影信息的HTML元素。豆瓣电影Top250的每个电影都包含在一个class为’item’的div标签中,可以使用find_all方法定位所有的电影项。例如:
movie_items = soup.find_all('div', class_='item')
提取电影信息:遍历电影项列表,逐个提取电影的各个信息。可以使用find方法和CSS选择器来定位电影信息的具体元素。例如,电影的标题位于class为’title’的span标签中,可以使用select_one方法和CSS选择器提取标题。其他信息如评分、导演、演员等也可以通过类似的方式提取。例如:
for item in movie_items:
title = item.select_one('.title').text
rating = item.select_one('.rating_num').text
director = item.select('.bd p')[0].text.strip()
actors = item.select('.bd p')[1].text.strip()
# 其他信息的提取...
4.2 find()
根据网页的HTML结构,使用find_all()方法定位包含电影信息的HTML元素,并使用循环遍历提取所需的信息。
movies = soup.find_all('div', class_='item')
data = []
for movie in movies:
title = movie.find('span', class_='title').text # 电影名
rating = movie.find('span', class_='rating_num').text #
bd = (
movie.find("div", class_="bd")
.text.replace(" ", "")
.replace("\n\n\n", "\n")
.replace("\n\n", "\n")
.split("\n")
)
data.append([title, rating])
5. 存储数据
将提取的电影信息存储到CSV文件中,以便后续分析和使用。
with open(r"测试\movies.csv", "w", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["电影名", "导演", "主演", "时间/地区/类型", "评分", "评价人数", "一句话评价"])
writer.writerows(data)
遇到的问题:
1、处理数据时,正常存储显示的中文在写入到
csv文件时变成了乱码,文件的编码未能正确处理中文,需要在写入csv文件时指定编码。2、写入多出一行空白行
解决办法:
with open(filename, 'a', newline='', encoding='utf-8-sig') as f: # 数据存储
6. 反爬虫策略及应对方法
在进行网页数据爬取时,网站可能采取一些反爬虫策略,例如设置访问频率限制、使用验证码、检测请求头信息等。以下是一些常
见的反爬虫策略及应对方法:
- 访问频率限制:使用
time.sleep()函数随机延时,以避免过于频繁的请求。 - 使用代理
IP:通过使用代理IP进行请求,隐藏真实的请求来源。 - 处理验证码:如果遇到验证码,可以使用第三方库进行自动识别或手动输入验证码。
请注意,尊重网站的爬虫规则是非常重要的,不要过度请求或对网站造成过大的负载。
完整代码及运行结果
import requests
from bs4 import BeautifulSoup
import csv
url = "https://movie.douban.com/top250"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
}
response = requests.get(url=url, headers=headers)
print(response.status_code)
soup = BeautifulSoup(response.text, "html.parser")
movies = soup.find_all("div", class_="item")
# print(movies)
data = []
for movie in movies:
title = movie.find("span", class_="title").text
# rating = movie.find("span", class_="rating_num").text
# inq = movie.find("span", class_="inq").text
bd = (
movie.find("div", class_="bd")
.text.replace(" ", "")
.replace("\n\n\n", "\n")
.replace("\n\n\n", "\n")
.split("\n")
)
bd = [x for x in bd if x != ""]
bd = [x for y in bd for x in y.split(" ", 1)]
data.append([title] + bd)
with open(r"测试\movies.csv", "w", newline="", encoding="utf-8-sig") as file:
writer = csv.writer(file)
writer.writerow(["电影名", "导演", "主演", "时间/地区/类型", "评分", "评价人数", "一句话评价"])
writer.writerows(data)
print("数据爬取完成并存储到movies.csv文件中。")
以上是使用Python爬取豆瓣电影Top250的完整代码。运行代码后,将会爬取电影的标题和评分信息,并存储到名为movies.csv的CSV文件中。
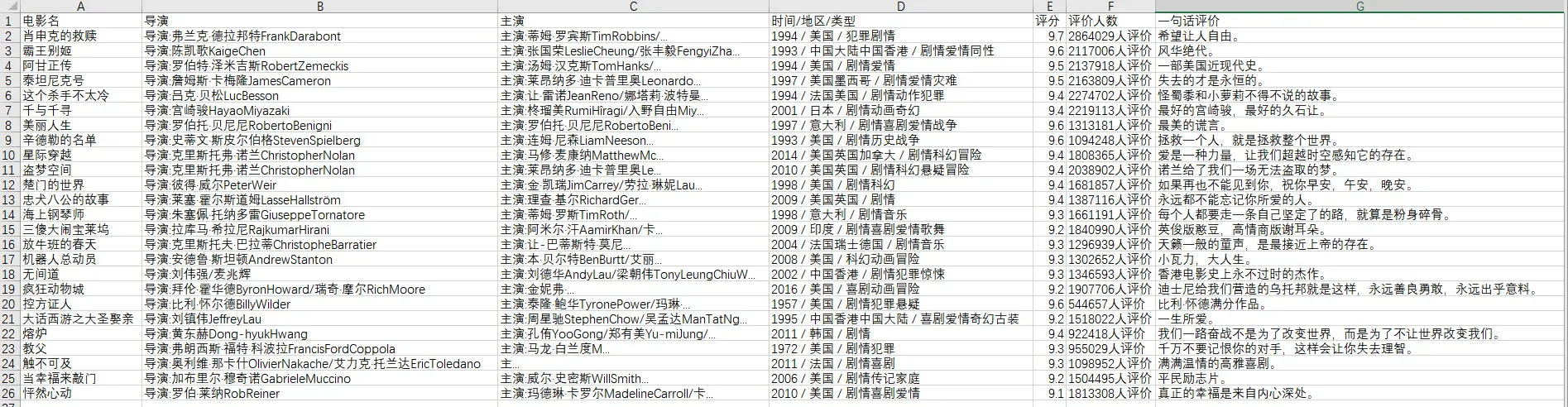
结语:
通过以上步骤,学习了如何使用Python和requests库爬取豆瓣电影Top250的数据,并介绍了一些常见的反爬虫策略及应对方法。希望本文能对您在网络爬虫项目中有所帮助,祝您成功获取所需的数据。
请记住,在进行爬虫行为时,应遵守法律法规和网站的爬虫规则,尊重网站的服务端资源。谨慎和负责任地使用爬虫技术,为网络空间的发展贡献自己的一份力量。
文章出处登录后可见!