文章及代码来源:中国工业经济《税收征管数字化与企业内部薪酬差距》
目录
随机抽取对照组和实验组
随机设定政策时点
先po完整代码
*随机抽取对照组和控制组
forvalue i=1/500{
sysuse 数据1.dta, clear
g obs_id= _n //初始样本序号
gen random_digit= runiform() //生成随机数
sort random_digit //按新生成的随机数排序
g random_id= _n //产生随机序号
preserve
keep random_id gtp //保留虚拟的gtp
rename gtp random_gtp
rename random_id id //重命名为id,以备与其他变量合并(merge)
label var id 原数据与虚拟处理变量的唯一匹配码
save random_gtp, replace
restore
drop random_digit random_id gtp //删除原来的gtp
rename obs_id id //重命名为id,以备与random_rd合并(merge)
label var id 原数据与虚拟处理变量的唯一匹配码
save rawdata, replace
*- 合并,回归,提取系数
use rawdata, clear
merge 1:1 id using random_gtp,nogen
xtreg gap random_gtp size lev roa labor age cash indratio top1 soe olddep avgwage lnpgdp i.year i.ind i.prov,fe vce(cluster code)
g _b_random_gtp= _b[random_gtp] //提取x的回归系数
g _se_random_gtp= _se[random_gtp] //提取x的标准误
gen pvalue=2*ttail(e(df_r), abs(_b[random_gtp]/_se[random_gtp]))
keep _b_random_gtp _se_random_gtp pvalue
duplicates drop _b_random_gtp, force
drop if pvalue ==.
save placebo`i', replace //把第i次placebo检验的系数和标准误存起来
}
*- 纵向合并500次的系数和标准误
use placebo1, clear
forvalue i=2/500{
append using placebo`i' //纵向合并500次回归的系数及标准误
}
rename _b_random_gtp coef1
twoway (kdensity coef1,yaxis(1)) (scatter pvalue coef1, msymbol(smcircle_hollow) yaxis(2) mcolor(blue)), ///
title(Placebo Test) ///
xlabel(-0.13(0.05)0.06) ylabel(,axis(1) angle(0)) ylabel(0(1)5,axis(2)) ///
xline(-0.1152, lwidth(vthin) lp(shortdash)) xtitle(估计系数) ///
xline(0,lwidth(vthin) lp(shortdash)) ///
yline(0.1,lwidth(vthin) lp(dash)) ytitle(p value) ///
legend(label(1 'kdensity of estimates') label( 2 'p value')) ///
plotregion(style(none)) ///无边框
graphregion(color(white)) //白底
*-删除临时文件
forvalue i=1/500{
erase placebo`i'.dta
}
*随机设定政策时点
mat b = J(500,1,0)
mat se = J(500,1,0)
mat p = J(500,1,0)
forvalues i = 1/500{
use 数据1.dta, clear
xtset code year
bsample 1, strata(province) //根据**id**分组,每组随机抽取一个年份
keep year
save matchyear.dta, replace
mkmat year, matrix(sampleyear)
use 数据1.dta, clear
xtset code year
gen DID = 0
foreach j of numlist 1/36 {
replace DID = 1 if (province== `j' & year >= sampleyear[`j',1])
}
qui xtreg gap DID size lev roa labor age cash indratio top1 soe olddep avgwage lnpgdp i.year i.ind i.prov,fe vce(cluster code)
mat b[`i',1] = _b[DID]
mat se[`i',1] = _se[DID]
scalar df_r = e(N) - e(df_m) -1
mat p[`i',1] = 2*ttail(df_r,abs(_b[DID]/_se[DID]))
}
svmat b, names(coef)
svmat se, names(se)
svmat p, names(pvalue)
drop if pvalue1 == .
label var pvalue1 p值
label var coef1 估计系数
twoway (kdensity coef1,yaxis(1)) (scatter pvalue1 coef1, msymbol(smcircle_hollow) yaxis(2) mcolor(blue)), ///
title(Placebo Test) ///
xlabel(-0.2(0.05)0.2) ylabel(,axis(1) angle(0)) ylabel(0(1)5,axis(2)) ///
xline(-0.1152, lwidth(vthin) lp(shortdash)) xtitle(估计系数) ///
xline(0,lwidth(vthin) lp(shortdash)) ///
yline(0.1,lwidth(vthin) lp(dash)) ytitle(p value) ///
legend(label(1 'kdensity of estimates') label( 2 'p value')) ///
plotregion(style(none)) ///无边框
graphregion(color(white)) //白底随机抽取对照组和实验组
接下来逐一解读:
forvalue表示循环
sysuse表示使用xx数据,和use区别参考stata中 sysuse和use区别 – 知乎
简单来说use调用数据时,需要加上路径,而sysuse不用。
g obs_id= _n //初始样本序号表示生成序号,按照列表依次递增,如图:

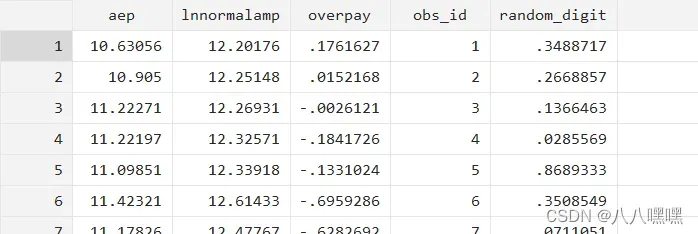
gen random_digit= runiform() //生成随机数每一列随机生成,如图
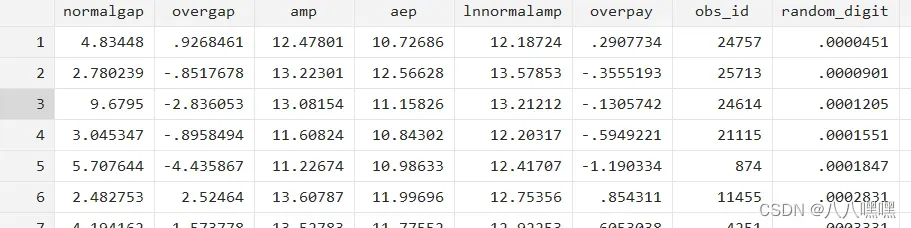
sort random_digit //按新生成的随机数排序结果如图:
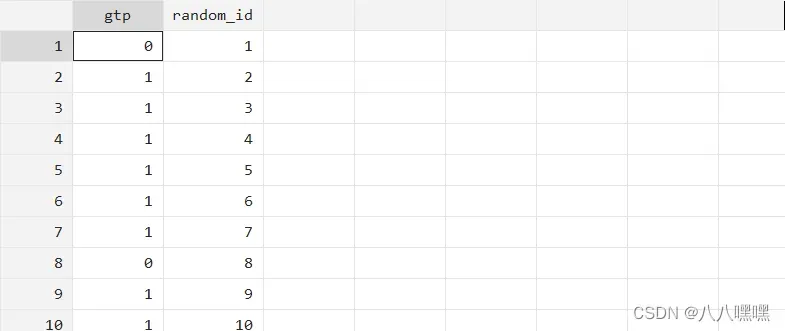
g random_id= _n //产生随机序号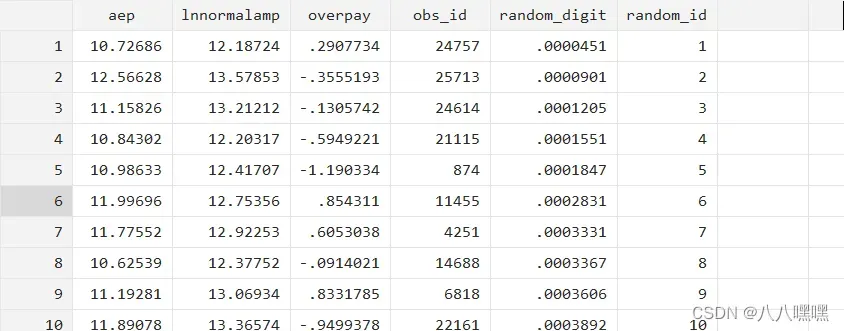
preserve
keep random_id gtp //保留虚拟的gtp
rename gtp random_gtp
rename random_id id //重命名为id,以备与其他变量合并(merge)
label var id 原数据与虚拟处理变量的唯一匹配码
save random_gtp, replace
restorepreserve……restore
详细可参考:preserve restore——stata的起死回生之术
preserve 命令可以把之前的内容保存在一个临时内存空间中,这样保存的文件,无论 preserve 以后我们对文件进行什么操作,都可以随时通过restore将preserve命令之前的文件恢复到内存中,继续使用。
keep random_id gtp //保留虚拟的gtpkeep表示保留变量
merge 1:1 id using random_gtp,nogenmerge1:1(merge1:m或merge m:1或merge m:n) 变量 using 数据集2
如果两个数据中的某变量的数据都是唯一的,则用1:1,;
如果数据1中某变量的数据有多个,而数据2中某变量的数据是唯一的,则用merge m:1;
如果数据1中某变量的数据是唯一的,而数据2中某变量的数据有多个,则用merge 1:m;
如果数据1和2中某变量的数据均有多个,则用merge m:n
nogen的含义就是不生成 _merge这个变量
twoway (kdensity coef1,yaxis(1)) (scatter pvalue coef1, msymbol(smcircle_hollow) yaxis(2) mcolor(blue)), ///
title("安慰剂检验") ///
xlabel(-0.13(0.05)0.06) ylabel(,axis(1) angle(0)) ylabel(0(1)5,axis(2)) ///
xline(-0.1152, lwidth(vthin) lp(shortdash)) xtitle(估计系数) ///
xline(0,lwidth(vthin) lp(shortdash)) ///
yline(0.1,lwidth(vthin) lp(dash)) ytitle(估计系数密度分布) ///
legend(label(1 "核密度") label( 2 "P值")) ///
plotregion(style(none)) ///无边框
graphregion(color(white)) //白底Kdensity命令是对变量未知密度函数分布时的一种估计,不是一种标准的密度分布函数(比如t分布、正态分布)
msymbol() 调整标记符号的形状。msymbol(S)中的 S 是 square 的缩写,表示方块。msymbol(t) 对应的标记符号为小三角形;msymbol(sh) 对应的标记符号为小的空心方块,括号的的 h 对应 hollow,表示空心的意思;msymbol(X) 对应的标记符号为大的叉号;msymbol(+) 对应的标记符号为十字号;msymbol(p) 对应的标记符号为小点。
随机设定政策时点
mat b = J(500,1,0)//系数矩阵
mat se = J(500,1,0)//标准误矩阵
mat p = J(500,1,0)//P值矩阵生成备用矩阵
使用mat list b可以查看矩阵,可以看出生成500行,一列,值为0的矩阵

bsample 1, strata(province) 这里首先将数据按照省份分组,然后在每个省份组内的 year 变量中随机抽取一个年份作为其政策时间
bsample [exp] [if] [in] [, options]其中,if代表条件语句,in代表范围语句,options代表其他选项。exp为表达式,用于指定抽取的样本个数。
需要说明的是,对于样本容量exp,如果进行简单分层抽样,就要求样本规模小于等于数据的观测值个数;如果进行分层抽样,exp就不能超过各层中的观测值个数;如果设定选项cluster(),exp就不能超过组的个数;如果同时设定选项cluster()和strata(),exp就不能超过各层内组的个数。
mkmat:将数值型变量中的观测值转变为矩阵
foreach j of numlist 3/30 {
replace DID = 1 if (prov== `j' & year >= sampleyear[`j',1])
}foreach详细参考:foreach的五个小秘密
文章出处登录后可见!