简介
随着AI孙燕姿的爆火出圈,各大视频平台的AI人声投稿量激增,B站首页频频给我推送相关视频,正好我对AIGC方面也挺感兴趣,心动不如行动,于是我用自己的声音训练了一个模型,发现整个过程异常的简单,并且最终出来的效果也不错,真的是有手就行,所以这次将我自己训练推理的过程经验分享给大家
Sovits
首先介绍一下今天要讲的Sovits,So-vits-svc(也称Sovits)是由是中国民间歌声合成爱好者Rcell基于VITS、soft-vc、VISinger2等一系列项目开发的一款开源免费AI语音转换软件,通过SoftVC内容编码器提取源音频语音特征,与F0同时输入VITS替换原本的文本输入达到歌声转换的效果。
由于某些原因,原作者Rcell删除了原代码仓库,现由svc-develop-team接手进行后续维护,现仓库地址:https://github.com/svc-develop-team/so-vits-svc
配置要求
- 一张支持 CUDA 的,拥有至少 6G 以上显存的 NVIDIA 显卡
- 推荐使用
Windows系统,教程后续的素材处理、训练、推理均在Windows平台上完成,同时使用整合包GUI也可以帮助新手将注意力集中在训练/推理本身上,避免了繁杂的环境配置等工作
环境配置
本次的环境使用的是 bilibili@羽毛布団 大佬提供的整合包:https://www.yuque.com/umoubuton/ueupp5/sdahi7m5m6r0ur1r ,在这里能找到下载地址和一些说明
下载完后,你会得到一个Sovits的压缩包和一些工具软件,将其中的so-vits-svc解压缩后,打开里面的启动webui.bat文件,它会自动准备环境,然后弹出一个网页
在网页中将Tab页切换至训练页,可以看到我们的显卡信息
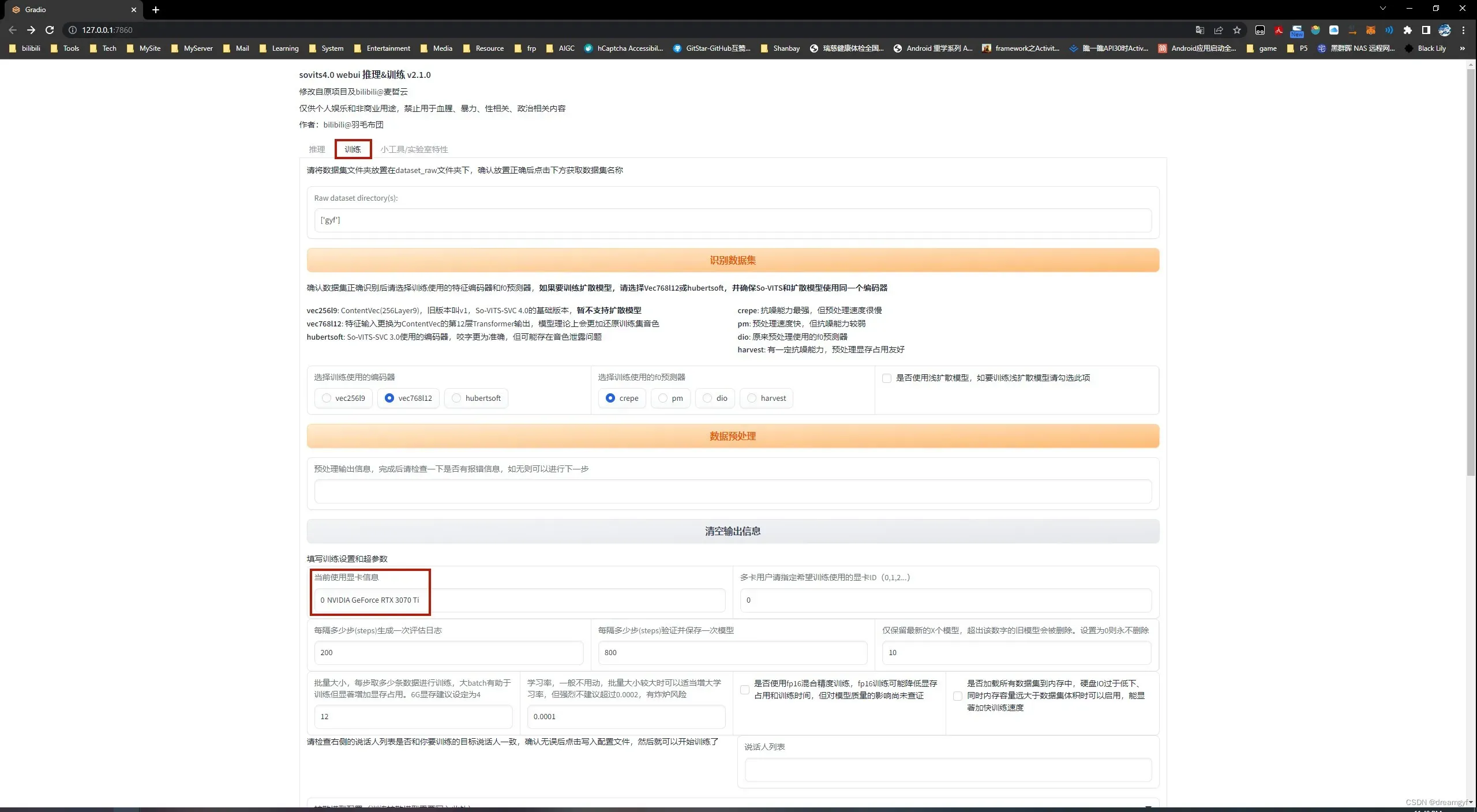
确认无误后我们就可以开始训练了
准备数据集
数据集的质量及多少决定了训练模型质量的上下限,质量差的数据集无论你训练多久,训练了多少万个step,都不可能达到一个理想的效果
准备干声
Sovits的训练我们需要找一些想训练的声线所对应的干声素材,不可混杂多种声线,时长最好在2个小时以上,最低不要少于30分钟,否则无法保证训练出来的模型的质量,可以是说话、读书或唱歌的声音(有的人说加入一些哭闹、大笑等各种各样的声音有奇效,我没尝试过,大家可以试试看),如果想让你的模型唱歌的话,唱歌的素材需要覆盖低中高音多个频率
干声素材中不能有伴奏、混响、和声(避免转换后的声音自带BGM),不要有换气声、颤音、转音等,尽量将背景噪音去除干净
降噪
如果你本来的素材就是不带伴奏混响的干声文件,但是有一些嘈杂的背景噪音,可以使用Adobe Audition(以下简称AU)进行降噪处理
教程:https://helpx.adobe.com/cn/audition/using/noise-reduction-restoration-effects.html
去伴奏混响
如果你的素材是之前录好的歌曲,那么需要对它进行去伴奏去混响处理,这里推荐使用 Ultimate Vocal Remover v5(简称UVR5)
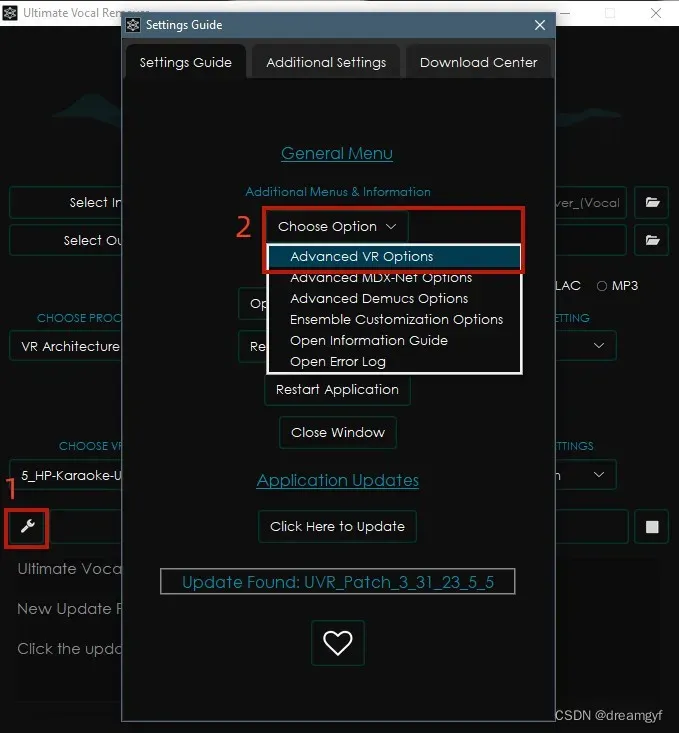
下载完UVR5,在处理音频前建议先去Advanced VR Options中将Post-Process选项打开,这样去混响的效果可能更好(玄学)
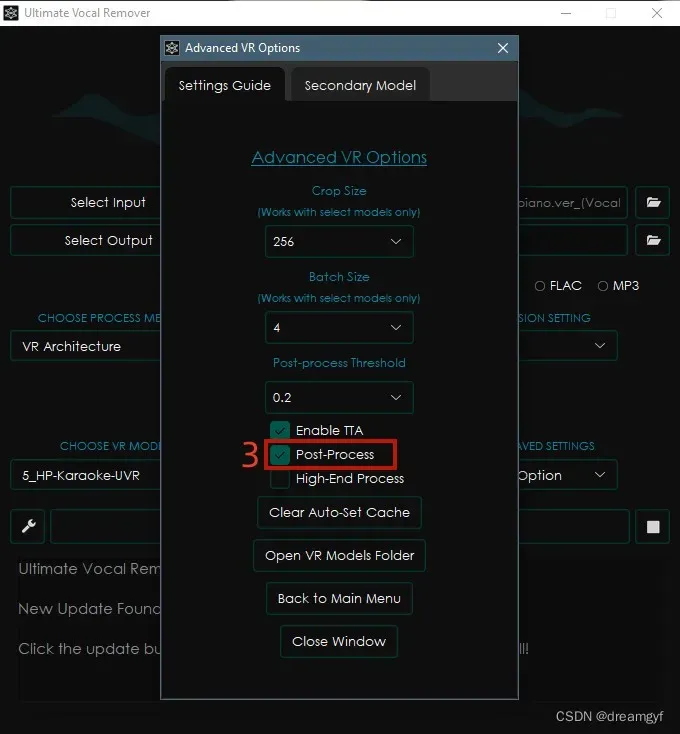
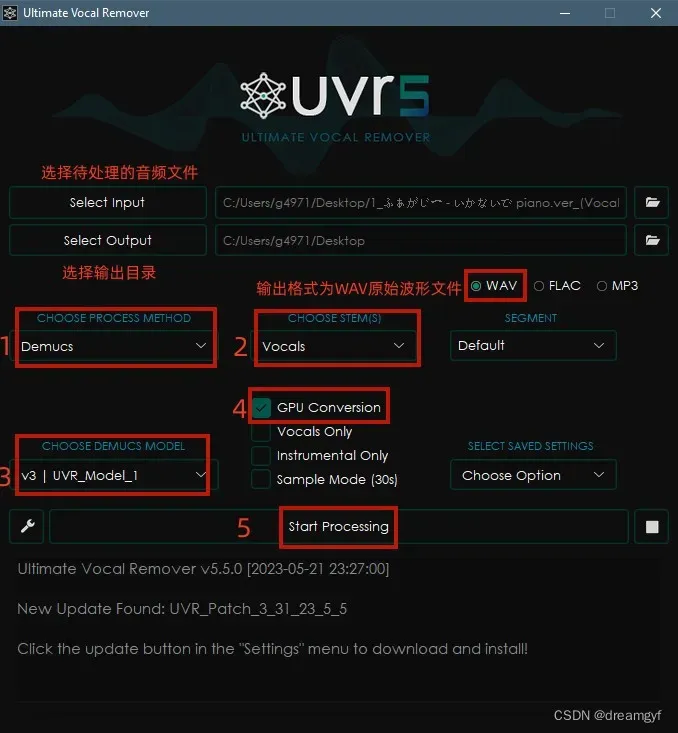
接着开始去伴奏,推荐采用以下配置:
- Process Method: Demucs
- Stems: Vocals
- Demucs Model: v3 | UVR_Model_1 注:找不到对应模型的可以在下拉框中选择Download在软件内下载相应模型
- 勾选GPU Conversion
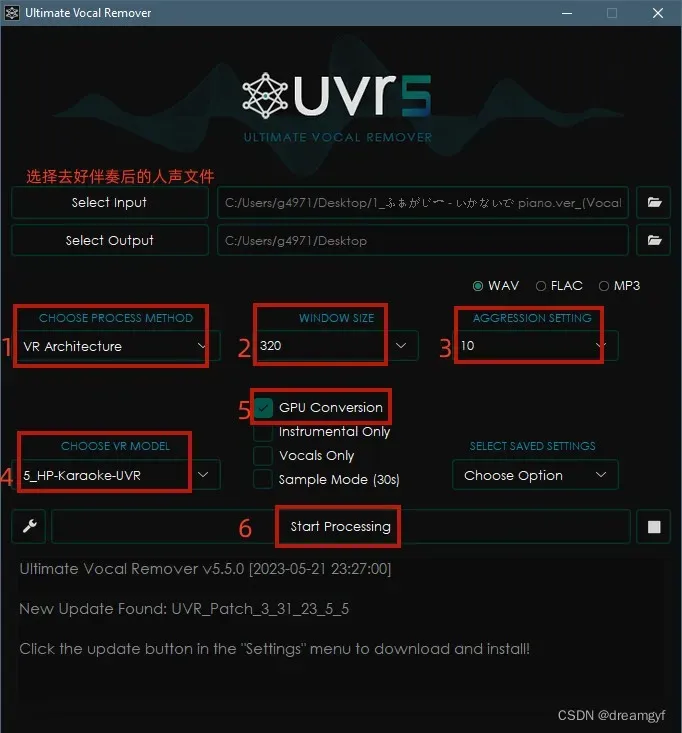
然后对处理完后的人声文件再做一次去混响处理,推荐采用以下配置:
- Process Method: VR Architecture
- Window Size: 320
- Aggression Setting: 10
- VR Model: 5_HP-Karaoke_UVR
- 勾选GPU Conversion
- 勾选Voacls Only
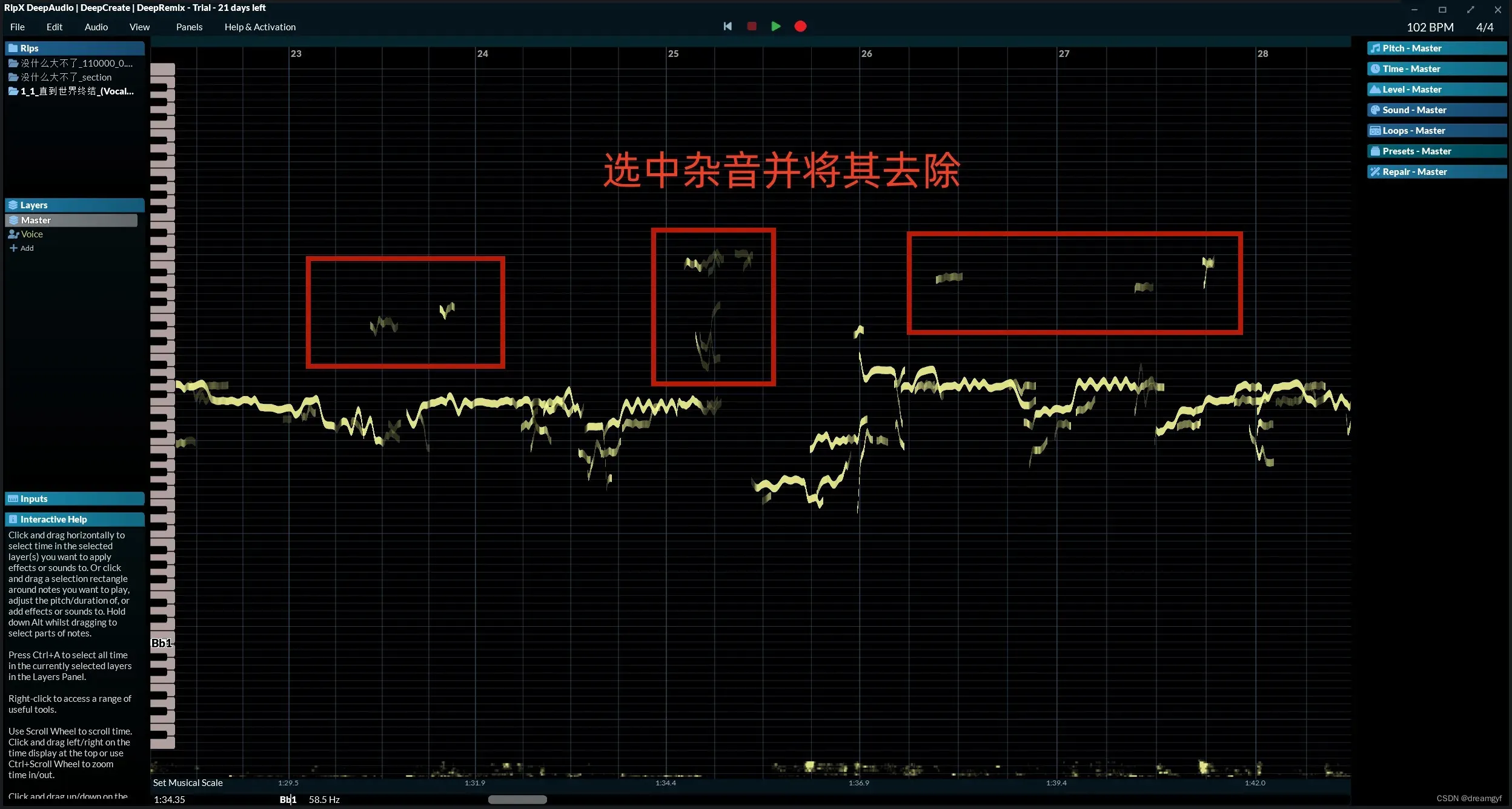
这样简单的几步,我们就将干声从歌曲文件中提取出来了,如果你觉得提取出来的效果差强人意,也可以使用 RipX DeepAudio 做一些精修
将文件导入RipX中,会产生如下图一样的一段曲线
点击其中的某段黄色曲线可以播放这段音频,我们可以一段段听过去,遇到杂音部分可以将其手动删除
匹配响度
如果你的干声素材的来源不同,很可能会有素材响度大小不一的情况,这种情况下需要使用AU对所有音频去做匹配响度,使所有素材的分贝值在一个统一的范围内
教程:https://helpx.adobe.com/cn/audition/using/match-loudness.html
压限
干声的响度不宜超过-6db,建议使用Adobe Audition中的压限器将声音的分贝限制在-6db以内
教程:https://helpx.adobe.com/cn/audition/using/amplitude-compression-effects.html
切片
干声素材都处理完后,下一步就是将这些素材切成一个个2-15s的小片段(片段太长容易爆显存,最好不要超过20s),这里推荐使用 Audio Slicer ,可以根据响度阈值和间隔时间等自动将音频切片
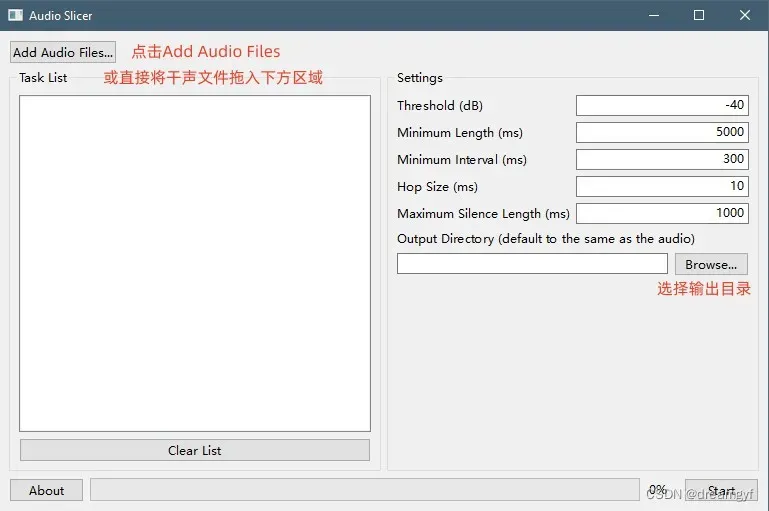
将干声文件拖进去后可以先使用默认参数切一遍,然后去输出目录,将文件按文件大小由大到小排列,查看是否还有大于15s的音频切片,如有的话,将这些音频重新拖入软件中,按照以下参数重新切片一次:
- Threshold(db): -20
- Minimum Interval: 100
- Maximum Silence Length(ms): 500
一般这样就不会有大于15s的音频了,如果还有的话,我将这些参数的含义列在下面,大家可以自己调整参数尝试,大家也可以使用其他的一些音频处理工具(如:AU)手动切片
- Threshold(阈值)
以 dB 表示的 RMS 阈值。所有 RMS 值都低于此阈值的区域将被视为静音。如果音频有噪音,请增加此值。默认值为 -40。
- Minimum Length(最小长度)
每个切片音频剪辑所需的最小长度,以毫秒为单位。默认值为 5000。
- Minimum Interval(最小间距)
要切片的静音部分的最小长度,以毫秒为单位。如果音频仅包含短暂的中断,请将此值设置得更小。此值越小,此应用程序可能生成的切片音频剪辑就越多。请注意,此值必须小于 min length 且大于 hop size。默认值为 300。
- Hop Size(跳跃步长)
每个 RMS 帧的长度,以毫秒为单位。增加此值将提高切片的精度,但会降低处理速度。默认值为 10。
- Maximum Silence Length(最大静音长度)
在切片音频周围保持的最大静音长度,以毫秒为单位。根据需要调整此值。请注意,设置此值并不意味着切片音频中的静音部分具有完全给定的长度。如上所述,该算法将搜索要切片的最佳位置。默认值为 1000。
最后,记得把过短的音频切片删除掉
格式转换
数据集的格式必须是wav原始波形格式,大家检查一下,如果如果有非wav格式的文件,需要做一下格式转换,推荐使用Foobar2000,或者直接使用FFmepg进行转换
重命名
数据集中不能出现中文等非英文字符,特殊字符推荐只使用下划线,Windows下直接将文件全选后重命名,文件名会变成以下这种格式:
- xxx (1).wav
- xxx (2).wav
- …
本人亲测这样命名虽然会报Warning,但不影响训练,是可行的
预训练
接着我们就开始准备训练了
放置数据集
首先将处理好的干声全部放到一个文件夹下,然后再将这个文件夹放到so-vits-svc目录下的dataset_raw文件夹下
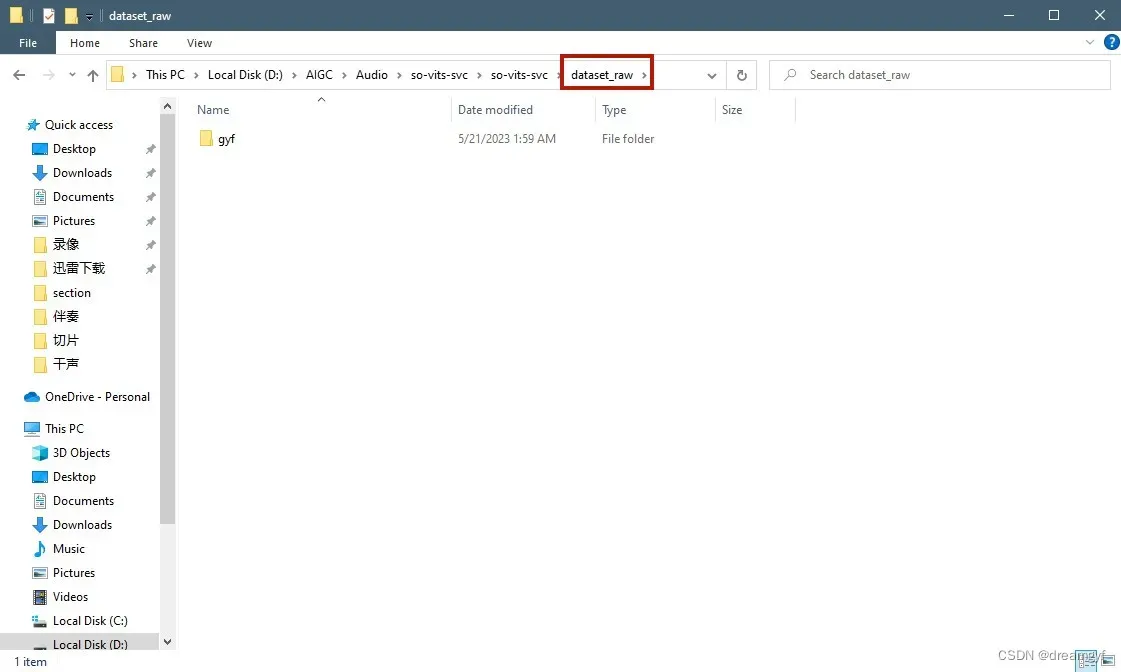
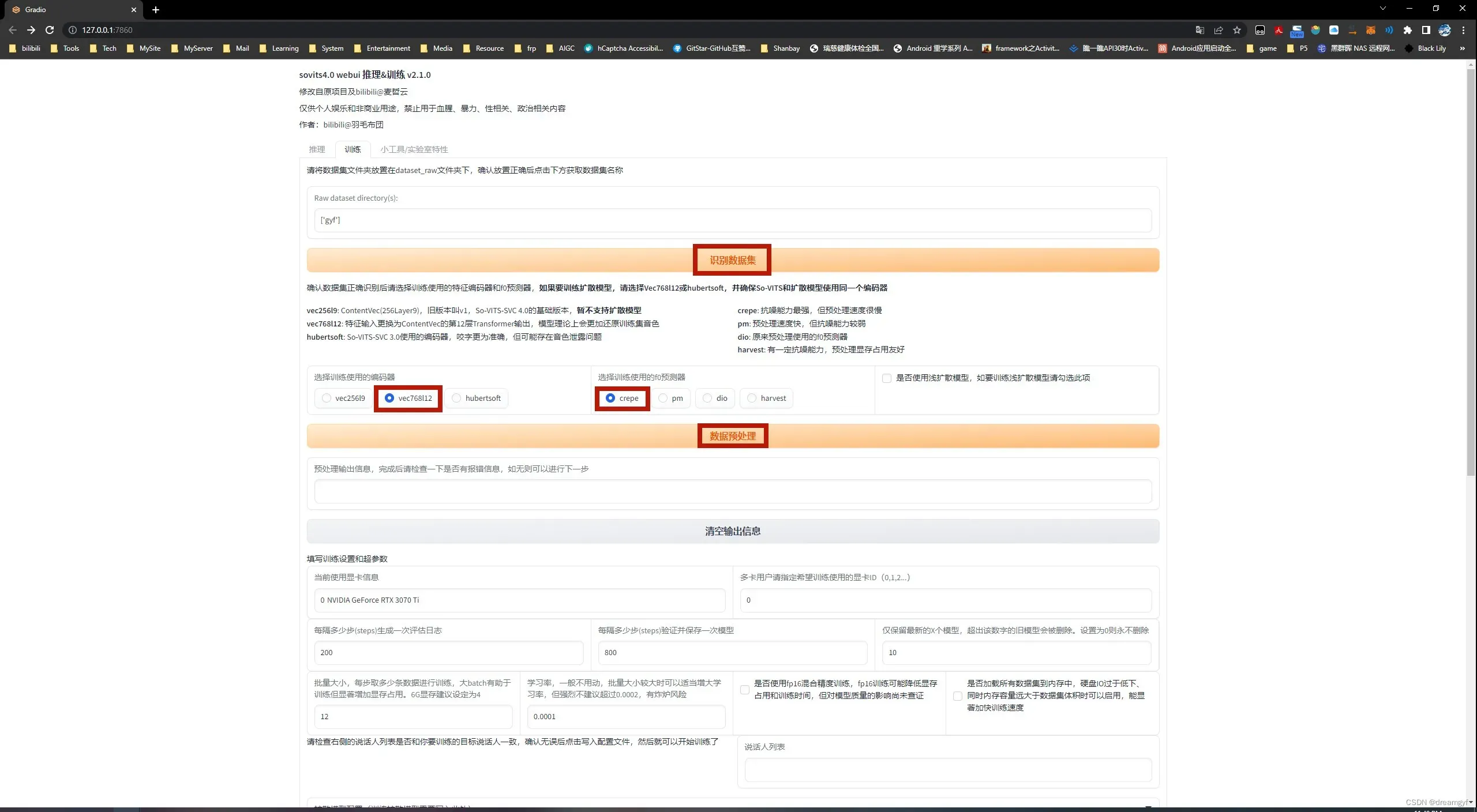
数据预处理
打开webui界面,切换到训练选项卡,首先点击识别数据集,上面的文本框中便会显示出我们准备好的数据集名,然后选择训练使用的编码器和f0预测器,这里选择我图中标出的两个选项,是目前效果比较好的选项,接着点击数据预处理,在预处理输出信息那一栏会打印进度,耐心等待它跑完
训练配置
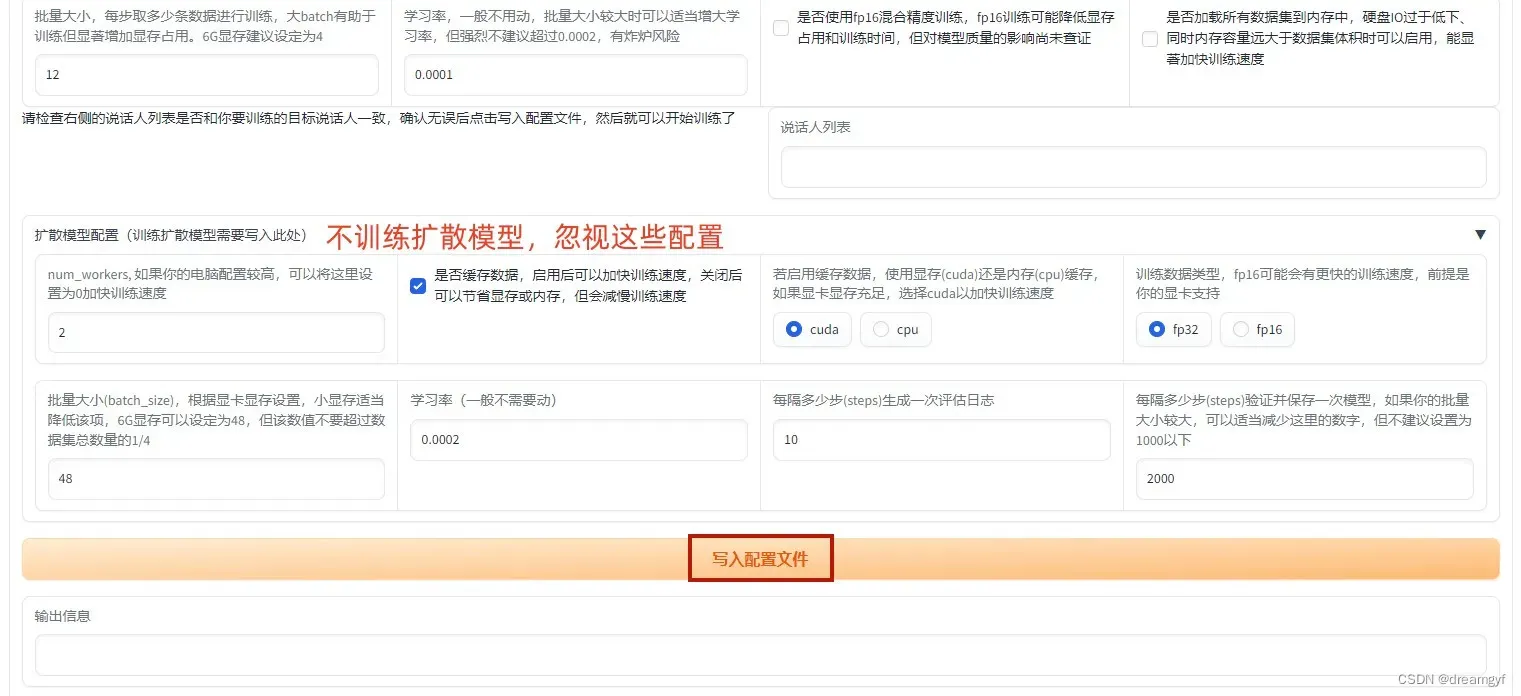
等待数据预处理完成后,我们要将训练的设置和参数写入到配置文件中
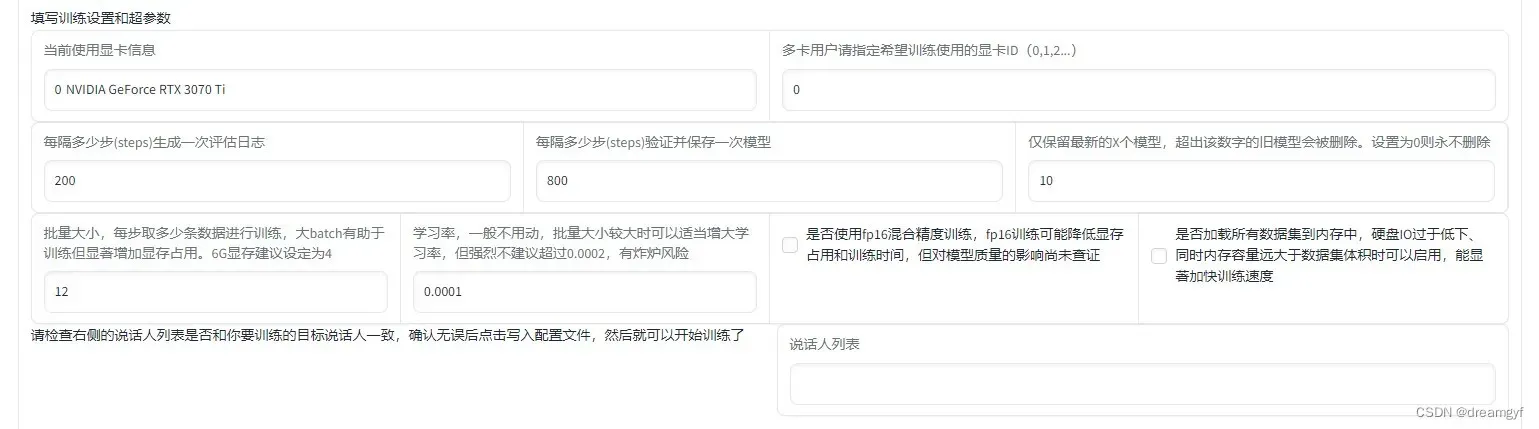
介绍一下这里参数的含义和推荐设置:
- 每隔多少步(steps)生成一次评估日志:每隔一定步数输出一下当前步数下的学习率,loss值等信息,根据个人偏好自己填写即可
- 每隔多少步(steps)验证并保存一次模型:字面意思,根据个人偏好自己填写即可
- 仅保留最新的X个模型:我训练到11万步时一个模型接近600MB,大家根据自己的硬盘大小和个人偏好填写即可
- 批量大小:大的batch size可以减少训练时间,提高稳定性,但同时也会导致模型泛化能力下降,所以,就算你的显存很大也不建议将本参数设置的过大,推荐使用4
- 学习率:初始学习率过大会导致模型无法收敛,过小则会导致模型收敛特别慢或无法学习,建议使用默认值0.0001
- 使用fp16混合精度训练:混合精度训练是在尽可能减少精度损失的情况下利用半精度浮点数加速训练,它使用FP16即半精度浮点数存储权重和梯度,在减少占用内存的同时起到了加速训练的效果,理论上来说使用混合精度几乎不会造成精度损失,但目前没对模型质量的影响尚未查证,在显卡性能足够的情况下建议还是先不要勾选
- 加载数据集到内存中:在内存足够的情况下建议勾选,可以加快训练速度
所有训练参数设置好后,点击下面的写入配置文件按钮,在下面的输出信息那里会显示配置文件写入完成,接下来就可以开始正式训练了
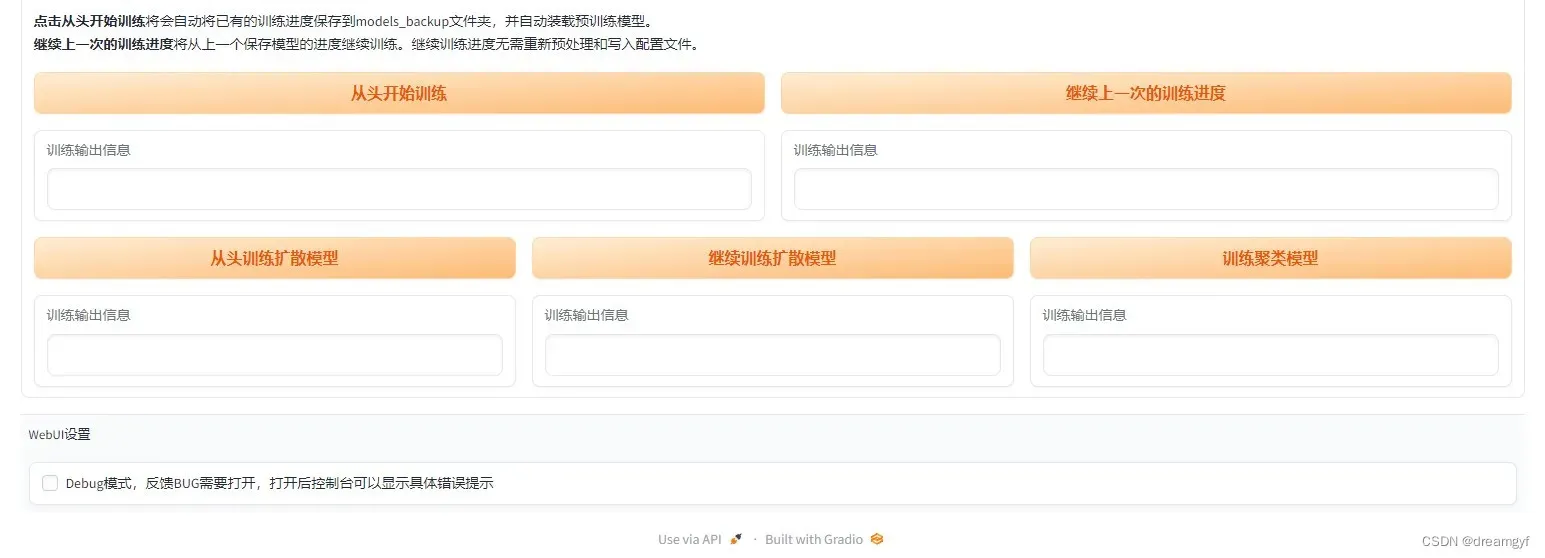
正式训练
点击下面的从头开始训练,会弹出一个新的终端窗口,在这个终端窗口中,会不断的输出当前训练的日志
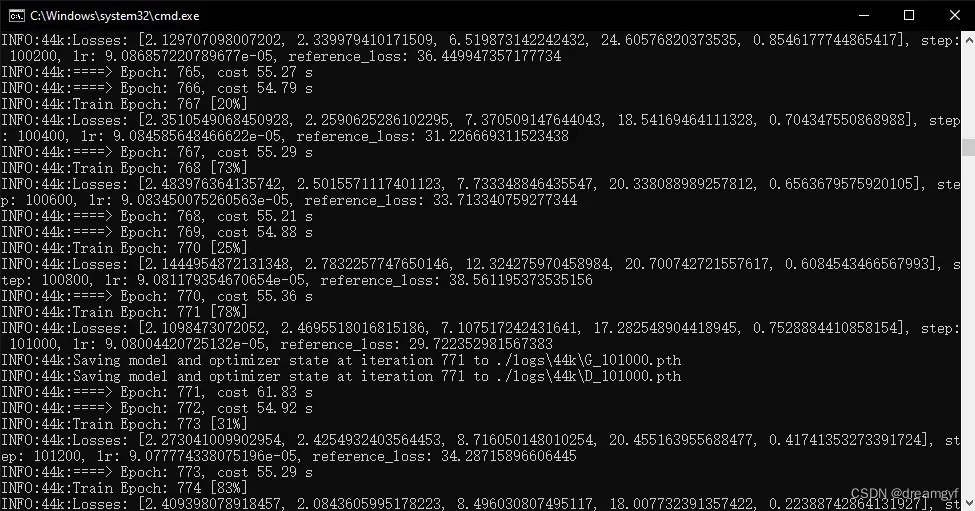
我的训练参数设置的是每隔200步生成一次评估日志,每隔1000步保存一次模型,日志中输出的reference_loss值代表了模型的输出与真实值之间的差距,理论来说,这个值越低越好,越低,模型输出的声音就和真人的声音越像,但从经验来说未必如此,过低的loss值也可能代表了模型过拟合,我们只能将这个参数作为一个参考,实际效果要使用测试了这个模型后才能得知,我们可以参考这个值初步选择模型进行推理测试
训练是不会自动终止的,当我们感觉训练的差不多了,想试一下模型的实际效果时,可以在训练终端窗口中键盘键入Ctrl + C停止训练,如果对本次训练出来的模型还不满意,想要继续训练,则可以点击继续上一次的训练进度,程序会从上一个自动保存的模型的进度开始继续训练
推理
加载模型
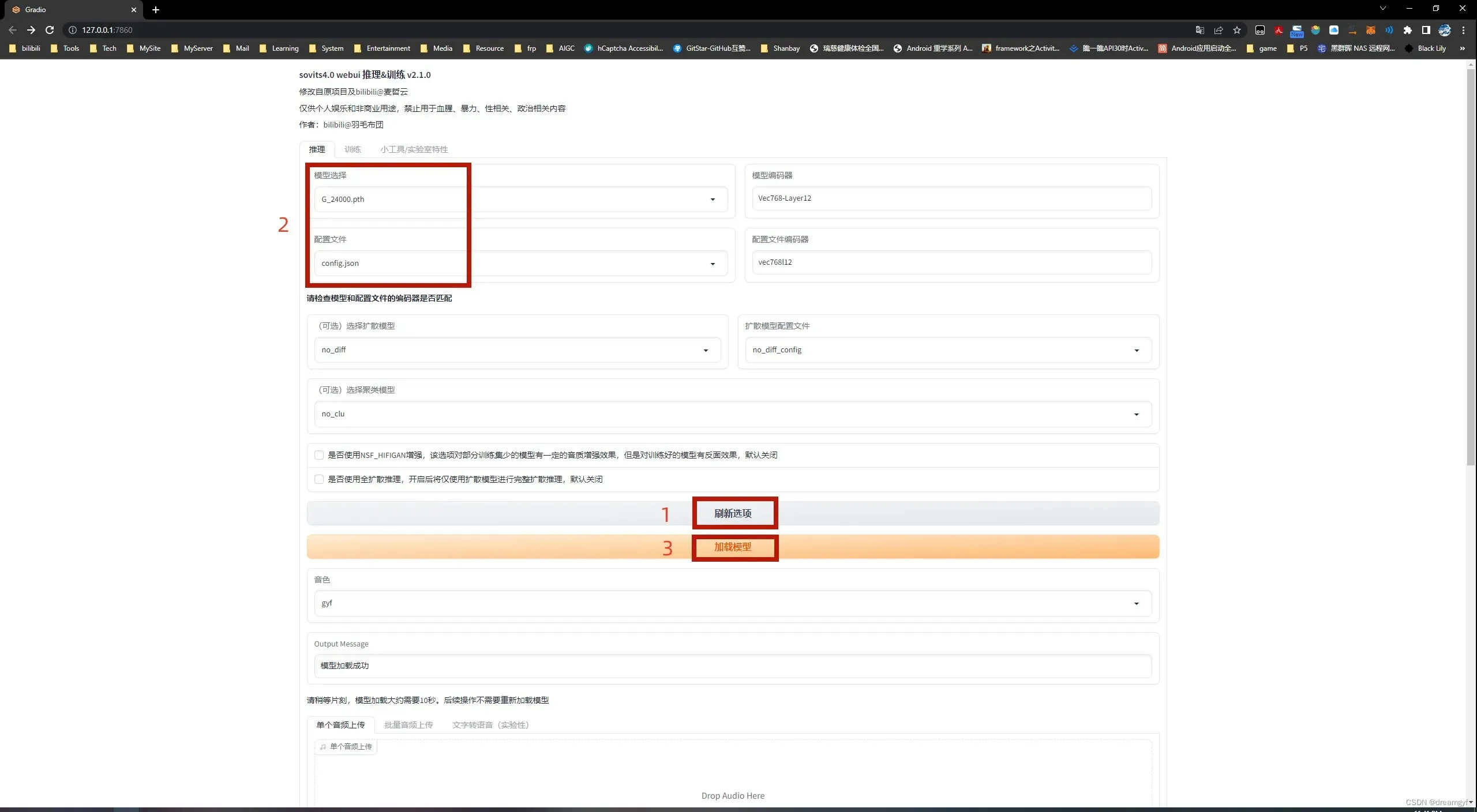
模型训练完后我们就可以将选项卡切换到推理来测试模型的实际效果了
我们先点击刷新选项,此时在模型选择和配置文件的下拉菜单中就出现了我们之前训练好的模型,参考之前的reference_loss值我们选取一个模型(G开头),并且选择训练所使用的配置文件,点击加载模型,等待下面的Output Message文本框出现模型加载成功字样,就可以正式开始我们的推理了
开始推理
Sovits是一个声音转换工具,我们首先需要找一段想要转换的原声音频,和准备数据集那一章的要求一样,我们需要一段干声,不能有伴奏、混响、和声。如果想让模型唱歌的话,我们可以采用前面准备数据集所用的方法,直接将原曲去伴奏混响,处理好后将其拖入音频上传区域中
默认的 pm f0预测器推理出来的音质效果最好,所以建议先使用默认参数推理一遍,出现问题再针对性的对参数进行调整
我们点击下面的音频转换按钮,稍等一会儿,在Output Audio那里便会生成一段推理后的音频
我们试听后根据具体的问题设置转换参数:
- 出现哑音
哑音是因为原声音频中的和声部分没有去处干净,导致f0预测器对音高的预测出现了错误,预测成了一个极高的音高,模型唱不上去导致的
有两种办法解决这个问题,一种就是从源头解决问题,想办法将原声音频的和声混响去除,获得更纯净的干声重新推理,另一种方法可以将f0预测器换成crepe,适度调节F0过滤阈值(一般使用默认值就行,改大改小没什么区别),然后重新进行推理基本就可以解决这个问题,但是音质不如f0预测器pm,电流音等杂音会变多,两种方法大家可以自行判断选取
- 音域差距过大
如果训练的模型是男声,但推理使用的原声是女声,或者反过来,碰到这种音域差距过大的情况会导致推理出来的音频不堪入耳
我们可以打开f0自动预测选项来解决这个问题,但正如选项里描述的那样,此选择仅限于转换语音时才可用,转换歌声时打开此选项会导致灾难性的跑调
如果是歌声并且实在是想要唱这首歌的话,建议去找一个和自己音域比较契合的翻唱音频,用这个音频处理后作为原声进行推理
- 部分音调唱不上(下)去
训练时喂的数据集没有覆盖到部分音域
这里的变调选项似乎是先推理再变调?所以对这种情况不起作用,建议使用AU先将原声音频升降调到合适的音域,再进行推理
- 爆显存
在推理的过程中有可能会出现爆显存的情况,因为推理也是将原音频按照响度阈值切成一段段小切片分别进行推理,最后再合成,如果其中有一段切片时常过长就可能会导致爆显存
我们可以将切片阈值调高,使得原声音频可以切的更加细碎,甚至你也可以直接调整音频自动切片的值开启强制切片,比如输入10,音频就会被切成每10s一段,确保音频时常不会爆显存
合成
如果转换的是歌声,最后可以将转换出来的干声和伴奏合并成一个音频文件,可以使用AU等软件,在合成之前还可以对干声进行一些EQ、混响的调整等,关于音乐方面的知识这里就不多说了
结尾
最后贴一下我自己练的模型所推理出来的歌声,使用了30分钟质量较好的干声素材和30分钟质量较差的素材(噪音和混响比较多),训练了11万步,使用crepef0预测器推理得出
链接:https://www.bilibili.com/audio/au3907000
这是我第一次尝试训练Sovits模型,如果有什么疏漏或错误欢迎大家指出
文章出处登录后可见!