文章目录
- 一、RDD#map 方法
- 1、RDD#map 方法引入
- 2、RDD#map 语法
- 3、RDD#map 用法
- 4、代码示例 – RDD#map 数值计算 ( 传入普通函数 )
- 5、代码示例 – RDD#map 数值计算 ( 传入 lambda 匿名函数 )
- 6、代码示例 – RDD#map 数值计算 ( 链式调用 )
一、RDD#map 方法
1、RDD#map 方法引入
在 PySpark 中 RDD 对象 提供了一种 数据计算方法 RDD#map 方法 ;
该 RDD#map 函数 可以对 RDD 数据中的每个元素应用一个函数 , 该 被应用的函数 ,
- 可以将每个元素转换为另一种类型 ,
- 也可以针对 RDD 数据的 原始元素进行 指定操作 ;
计算完毕后 , 会返回一个新的 RDD 对象 ;
2、RDD#map 语法
map 方法 , 又称为 map 算子 , 可以将 RDD 中的数据元素 逐个进行处理 , 处理的逻辑 需要用外部 通过 参数传入 map 函数 ;
RDD#map 语法 :
rdd.map(fun)
传入的 fun 是一个函数 , 其函数类型为 :
(T) -> U
上述 函数 类型 前面的 小括号 及其中的内容 , 表示 函数 的参数类型 ,
- () 表示不传入参数 ;
- (T) 表示传入 1 个参数 ;
同时 T 类型是 泛型 , 表示任意类型 , 也就是说 该函数的 参数 可以是任意类型的 ;
上述 函数 类型 右箭头 后面的 U , -> U 表示的是 函数 返回值类型 ,
(T) -> U表示 参数 类型为 T , 返回值类型为 U , T 和 U 类型都是任意类型 , 可以是一个类型 , 也可以是不同的类型 ;(T) -> T函数类型中 , T 可以是任意类型 , 但是如果确定了参数 , 那么返回值必须也是相同的类型 ;
U 类型也是 泛型 , 表示任意类型 , 也就是说 该函数的 参数 可以是任意类型的 ;
3、RDD#map 用法
RDD#map 方法 , 接收一个 函数 作为参数 , 计算时 , 该 函数参数 会被应用于 RDD 数据中的每个元素 ;
下面的 代码 , 传入一个 lambda 匿名函数 , 将 RDD 对象中的元素都乘以 10 ;
# 将 RDD 对象中的元素都乘以 10
rdd.map(lambda x: x * 10)
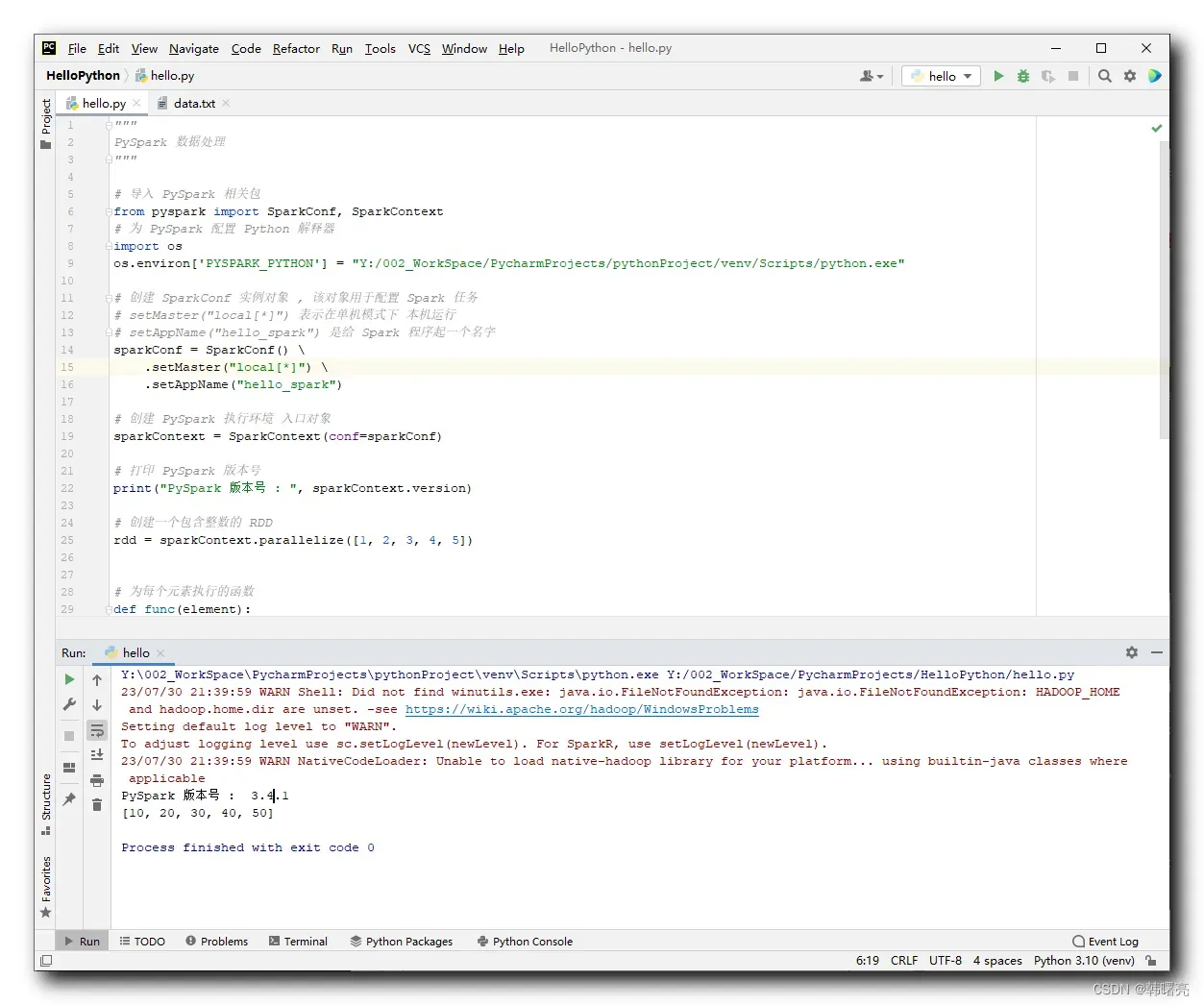
4、代码示例 – RDD#map 数值计算 ( 传入普通函数 )
在下面的代码中 ,
首先 , 创建了一个包含整数的 RDD ,
# 创建一个包含整数的 RDD
rdd = sparkContext.parallelize([1, 2, 3, 4, 5])
然后 , 使用 map() 方法将每个元素乘以 10 ;
# 为每个元素执行的函数
def func(element):
return element * 10
# 应用 map 操作,将每个元素乘以 10
rdd2 = rdd.map(func)
最后 , 打印新的 RDD 中的内容 ;
# 打印新的 RDD 中的内容
print(rdd2.collect())
代码示例 :
"""
PySpark 数据处理
"""
# 导入 PySpark 相关包
from pyspark import SparkConf, SparkContext
# 为 PySpark 配置 Python 解释器
import os
os.environ['PYSPARK_PYTHON'] = "Y:/002_WorkSpace/PycharmProjects/pythonProject/venv/Scripts/python.exe"
# 创建 SparkConf 实例对象 , 该对象用于配置 Spark 任务
# setMaster("local[*]") 表示在单机模式下 本机运行
# setAppName("hello_spark") 是给 Spark 程序起一个名字
sparkConf = SparkConf() \
.setMaster("local[*]") \
.setAppName("hello_spark")
# 创建 PySpark 执行环境 入口对象
sparkContext = SparkContext(conf=sparkConf)
# 打印 PySpark 版本号
print("PySpark 版本号 : ", sparkContext.version)
# 创建一个包含整数的 RDD
rdd = sparkContext.parallelize([1, 2, 3, 4, 5])
# 为每个元素执行的函数
def func(element):
return element * 10
# 应用 map 操作,将每个元素乘以 10
rdd2 = rdd.map(func)
# 打印新的 RDD 中的内容
print(rdd2.collect())
# 停止 PySpark 程序
sparkContext.stop()
执行结果 :
Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\Scripts\python.exe Y:/002_WorkSpace/PycharmProjects/HelloPython/hello.py
23/07/30 21:39:59 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
23/07/30 21:39:59 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
PySpark 版本号 : 3.4.1
[10, 20, 30, 40, 50]
Process finished with exit code 0
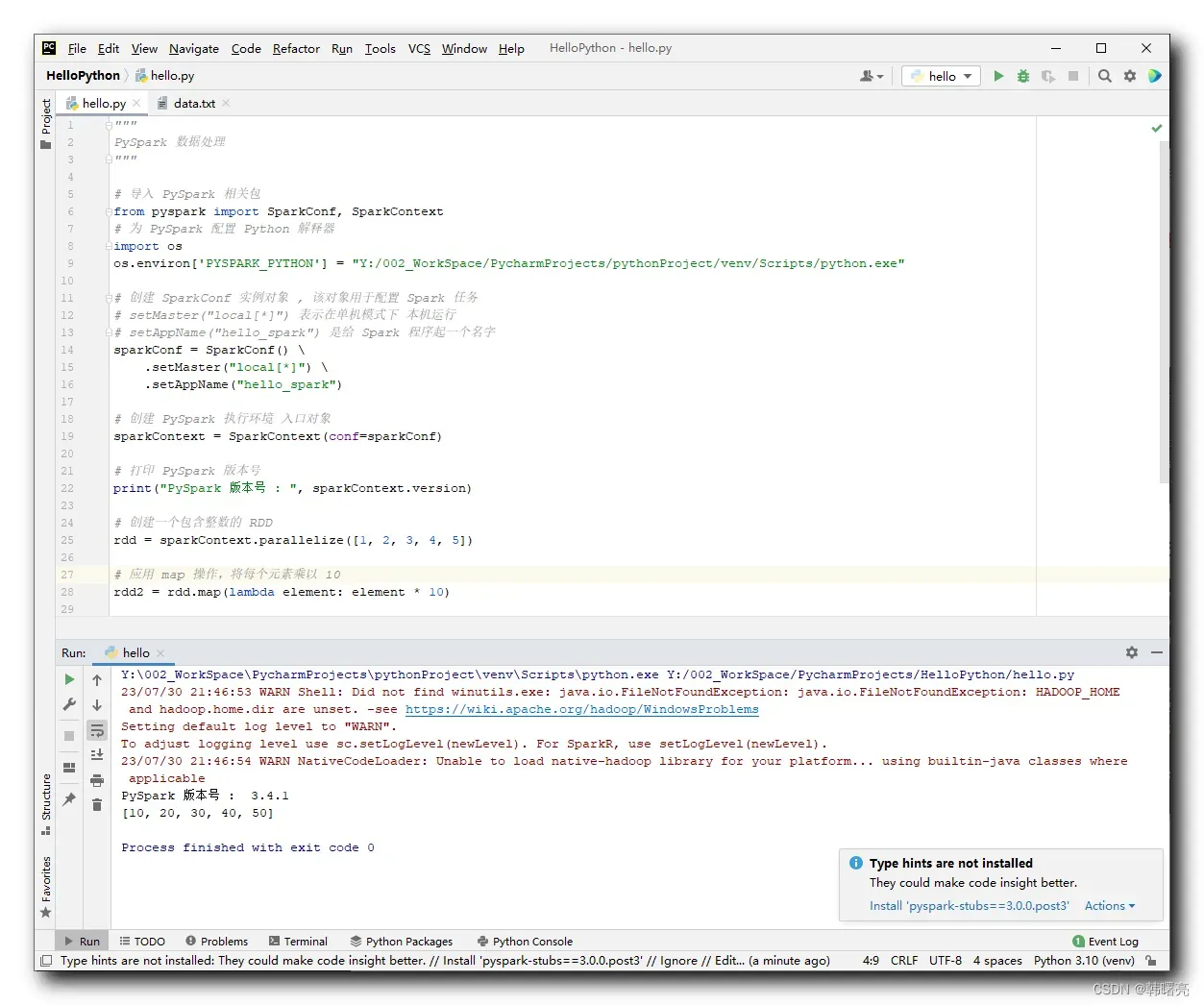
5、代码示例 – RDD#map 数值计算 ( 传入 lambda 匿名函数 )
在下面的代码中 ,
首先 , 创建了一个包含整数的 RDD ,
# 创建一个包含整数的 RDD
rdd = sparkContext.parallelize([1, 2, 3, 4, 5])
然后 , 使用 map() 方法将每个元素乘以 10 , 这里传入了 lambda 函数作为参数 , 该函数接受一个整数参数 element , 并返回 element * 10 ;
# 应用 map 操作,将每个元素乘以 10
rdd2 = rdd.map(lambda element: element * 10)
最后 , 打印新的 RDD 中的内容 ;
# 打印新的 RDD 中的内容
print(rdd2.collect())
代码示例 :
"""
PySpark 数据处理
"""
# 导入 PySpark 相关包
from pyspark import SparkConf, SparkContext
# 为 PySpark 配置 Python 解释器
import os
os.environ['PYSPARK_PYTHON'] = "Y:/002_WorkSpace/PycharmProjects/pythonProject/venv/Scripts/python.exe"
# 创建 SparkConf 实例对象 , 该对象用于配置 Spark 任务
# setMaster("local[*]") 表示在单机模式下 本机运行
# setAppName("hello_spark") 是给 Spark 程序起一个名字
sparkConf = SparkConf() \
.setMaster("local[*]") \
.setAppName("hello_spark")
# 创建 PySpark 执行环境 入口对象
sparkContext = SparkContext(conf=sparkConf)
# 打印 PySpark 版本号
print("PySpark 版本号 : ", sparkContext.version)
# 创建一个包含整数的 RDD
rdd = sparkContext.parallelize([1, 2, 3, 4, 5])
# 应用 map 操作,将每个元素乘以 10
rdd2 = rdd.map(lambda element: element * 10)
# 打印新的 RDD 中的内容
print(rdd2.collect())
# 停止 PySpark 程序
sparkContext.stop()
执行结果 :
Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\Scripts\python.exe Y:/002_WorkSpace/PycharmProjects/HelloPython/hello.py
23/07/30 21:46:53 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
23/07/30 21:46:54 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
PySpark 版本号 : 3.4.1
[10, 20, 30, 40, 50]
Process finished with exit code 0
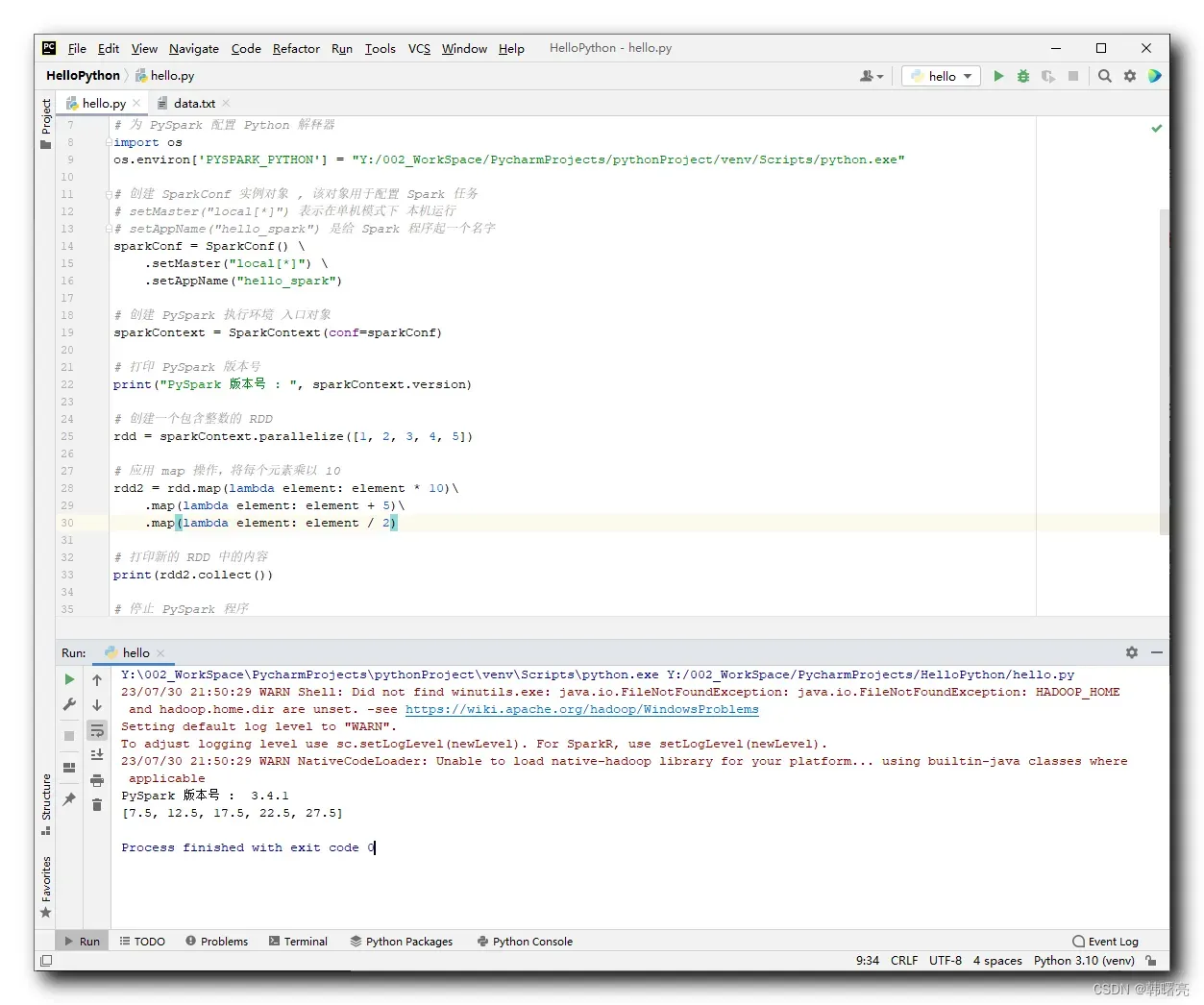
6、代码示例 – RDD#map 数值计算 ( 链式调用 )
在下面的代码中 , 先对 RDD 对象中的每个元素数据都乘以 10 , 然后再对计算后的数据每个元素加上 5 , 最后对最新的计算数据每个元素除以 2 , 整个过程通过函数式编程 , 链式调用完成 ;
核心代码如下 :
# 创建一个包含整数的 RDD
rdd = sparkContext.parallelize([1, 2, 3, 4, 5])
# 应用 map 操作,将每个元素乘以 10
rdd2 = rdd.map(lambda element: element * 10)\
.map(lambda element: element + 5)\
.map(lambda element: element / 2)
# 打印新的 RDD 中的内容
print(rdd2.collect())
代码示例 :
"""
PySpark 数据处理
"""
# 导入 PySpark 相关包
from pyspark import SparkConf, SparkContext
# 为 PySpark 配置 Python 解释器
import os
os.environ['PYSPARK_PYTHON'] = "Y:/002_WorkSpace/PycharmProjects/pythonProject/venv/Scripts/python.exe"
# 创建 SparkConf 实例对象 , 该对象用于配置 Spark 任务
# setMaster("local[*]") 表示在单机模式下 本机运行
# setAppName("hello_spark") 是给 Spark 程序起一个名字
sparkConf = SparkConf() \
.setMaster("local[*]") \
.setAppName("hello_spark")
# 创建 PySpark 执行环境 入口对象
sparkContext = SparkContext(conf=sparkConf)
# 打印 PySpark 版本号
print("PySpark 版本号 : ", sparkContext.version)
# 创建一个包含整数的 RDD
rdd = sparkContext.parallelize([1, 2, 3, 4, 5])
# 应用 map 操作,将每个元素乘以 10
rdd2 = rdd.map(lambda element: element * 10)\
.map(lambda element: element + 5)\
.map(lambda element: element / 2)
# 打印新的 RDD 中的内容
print(rdd2.collect())
# 停止 PySpark 程序
sparkContext.stop()
执行结果 :
Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\Scripts\python.exe Y:/002_WorkSpace/PycharmProjects/HelloPython/hello.py
23/07/30 21:50:29 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
23/07/30 21:50:29 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
PySpark 版本号 : 3.4.1
[7.5, 12.5, 17.5, 22.5, 27.5]
Process finished with exit code 0
文章出处登录后可见!