长短时记忆网络是循环神经网络(RNNs)的一种,用于时序数据的预测或文本翻译等方面。LSTM的出现主要是用来解决传统RNN长期依赖问题。对于传统的RNN,随着序列间隔的拉长,由于梯度爆炸或梯度消失等问题,使得模型在训练过程中不稳定或根本无法进行有效学习。与RNN相比,LSTM的每个单元结构——LSTM cell增加了更多的结构,通过设计门限结构解决长期依赖问题,所以LSTM可以具有比较长的短期记忆,与RNN相比具有更好的效果。
一:基本原理
关于LSTM,其整体结构与RNN基本完全相同,都是由多个cell串联起来,并且也有双向LSTM、深层LSTM,结构与RNN也完全相同。所以兔兔在这里不在赘述,需要了解的同学可以参考兔兔的上一篇循环神经网络(Recurrent Neural Network)详解。兔兔在下面着重讲述LSTM cell结构。
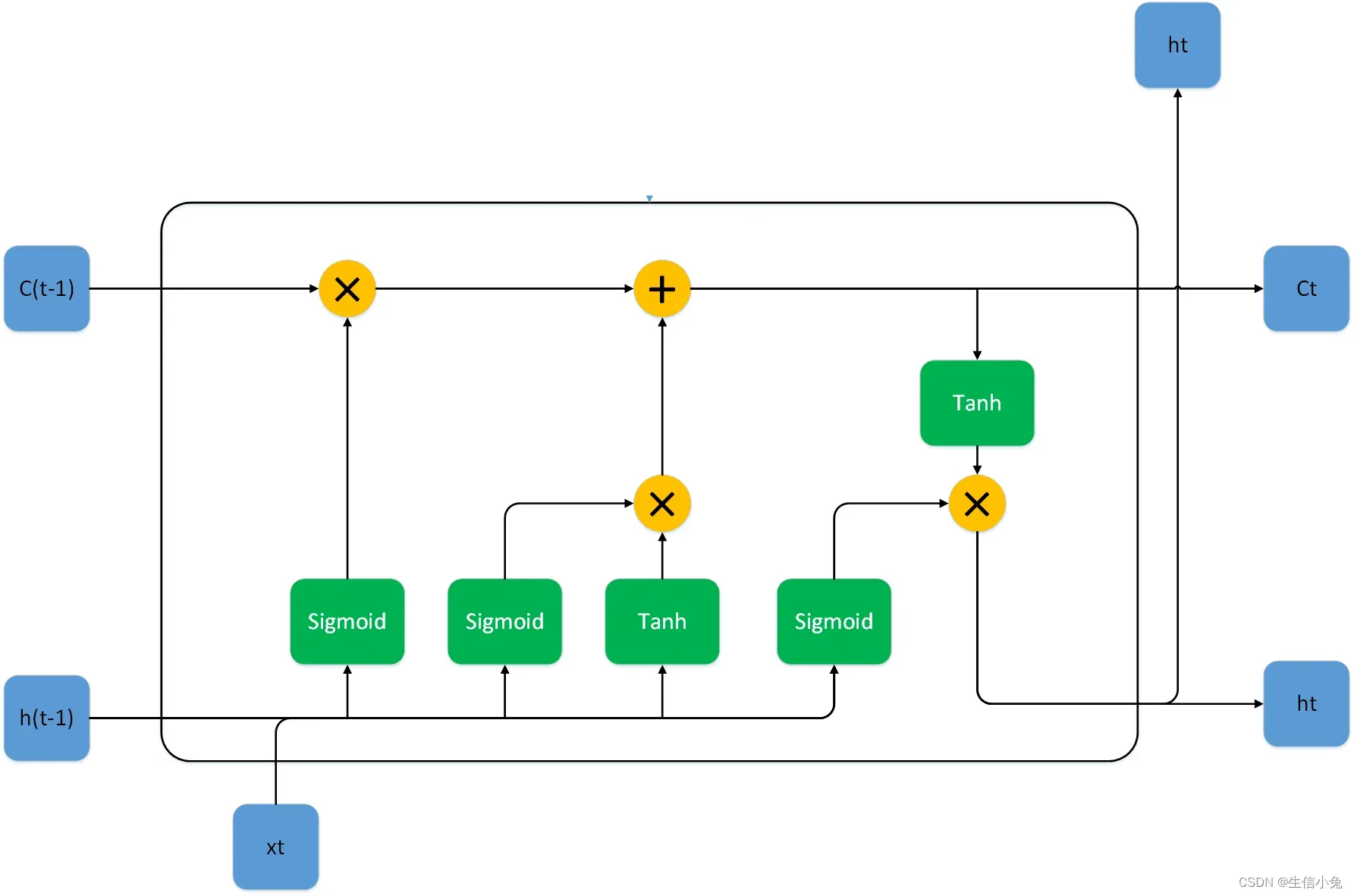
上图为一个LSTM cell的整体结构,与RNN相比,我们发现在cell直间除了之前的隐藏状态ht,还多了一个Ct,并且内部结构也相对较为复杂。对于LSTM cell,内部分为三个部分:遗忘门(也称为保持门 keep gate)、输入门(也称为更新门update gate,写入门write gate)与输出门。
(1)遗忘门(Forget Gate)
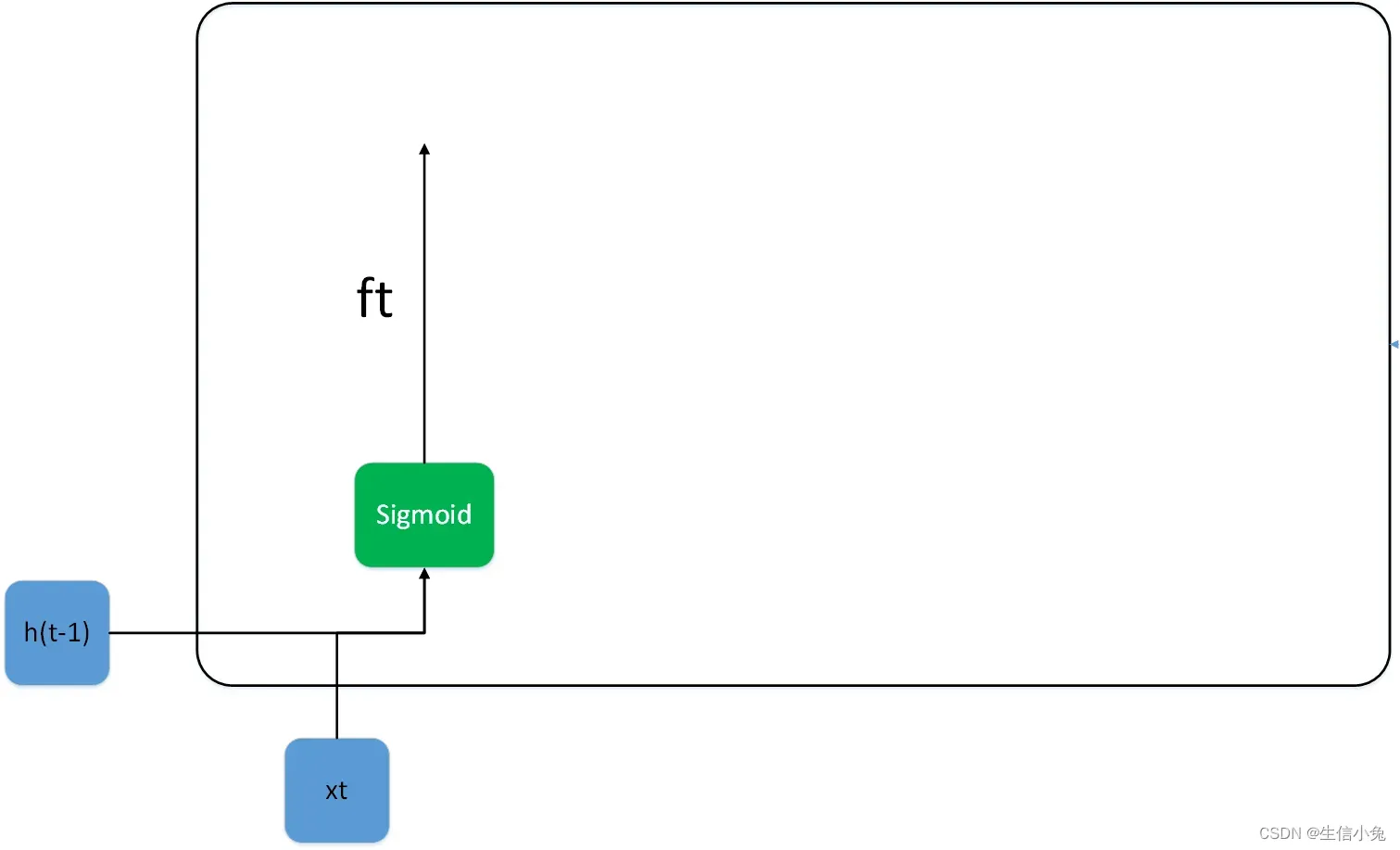
在LSTM cell中,保持门用于控制记忆单元里那些信息舍弃(遗忘)或保留。设输入数据xt特征数量为p,则dim=(p,1),h(t-1)的维度为dim=(q,1),参数矩阵的维度为dim=(q,p),偏置
:dim=(q,1),
:dim=(q,q),偏置
:dim=(q,1)。最终的输出ft为:
(2)输入门(Input Gate)
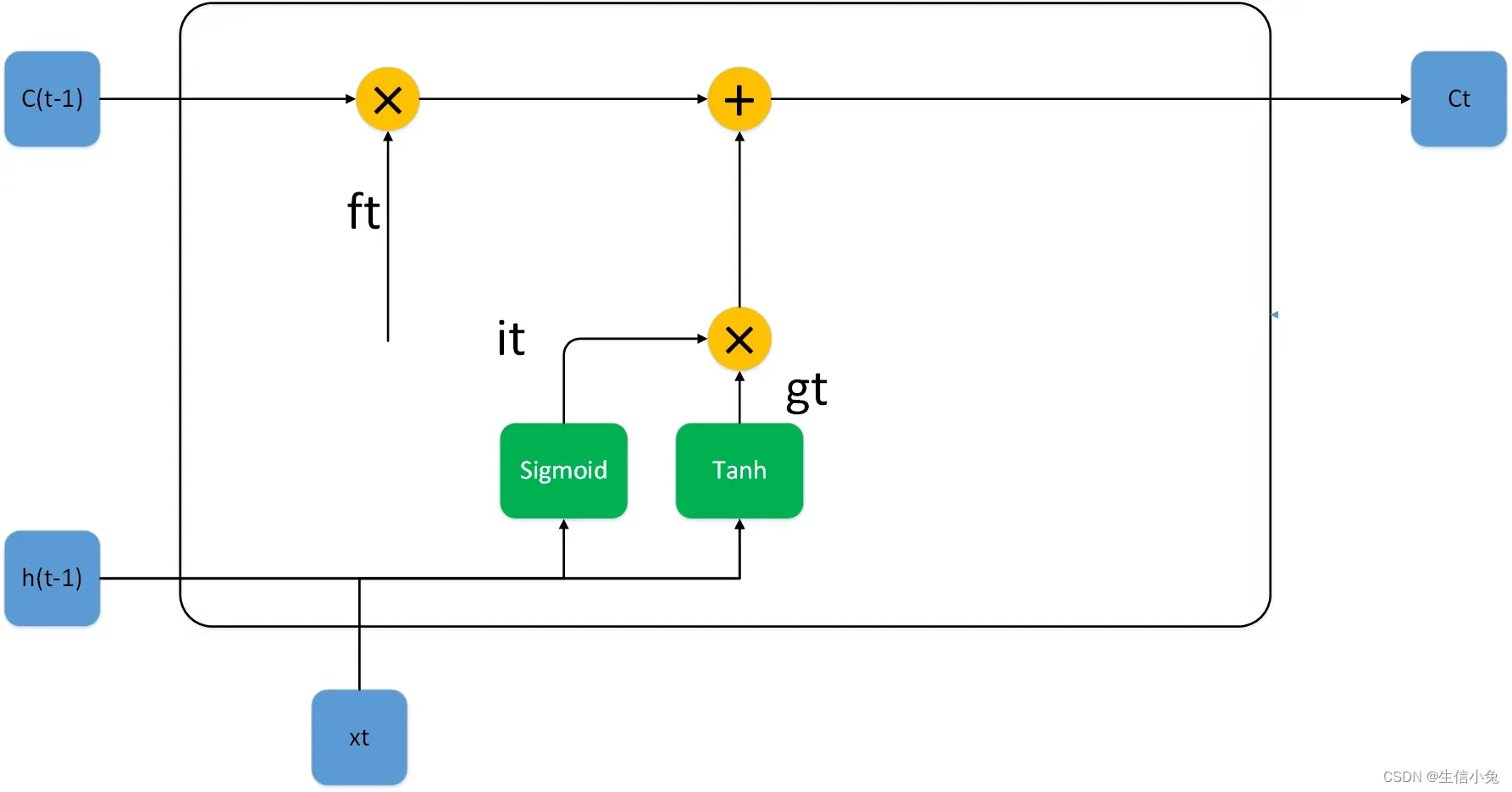
输入门决定更新记忆单元的信息,包括Sigmoid与Tanh两个部分,它们两个都包含当前时刻的输入xt与上一时刻隐藏状态h(t-1)。Sigmoid部分的参数有、
、
、
,dim分别为(q,p),(q,1),(q,q),(q,1);Tanh部分的参数
、
、
、
,dim分别为(q,p),(q,1),(q,q),(q,1)。
得到输入门的两个输出it、gt后,再由遗忘门得到的ft与上一时刻的状态C(t-1)进行计算,可以得到更新的状态Ct。
这里的乘法”*”是两个向量对应位置相乘,准确来说是哈达玛乘积,一般也可以用表示。而且这里ft、c(t-1)、it、gt、ct的维度都为(q,1)。
(3)输出门(Output Gate)
输出门的功能是读取刚刚更新过的神经网络状态,对记忆单元进行输出,而具体哪些信息可以输出受输出门的控制。
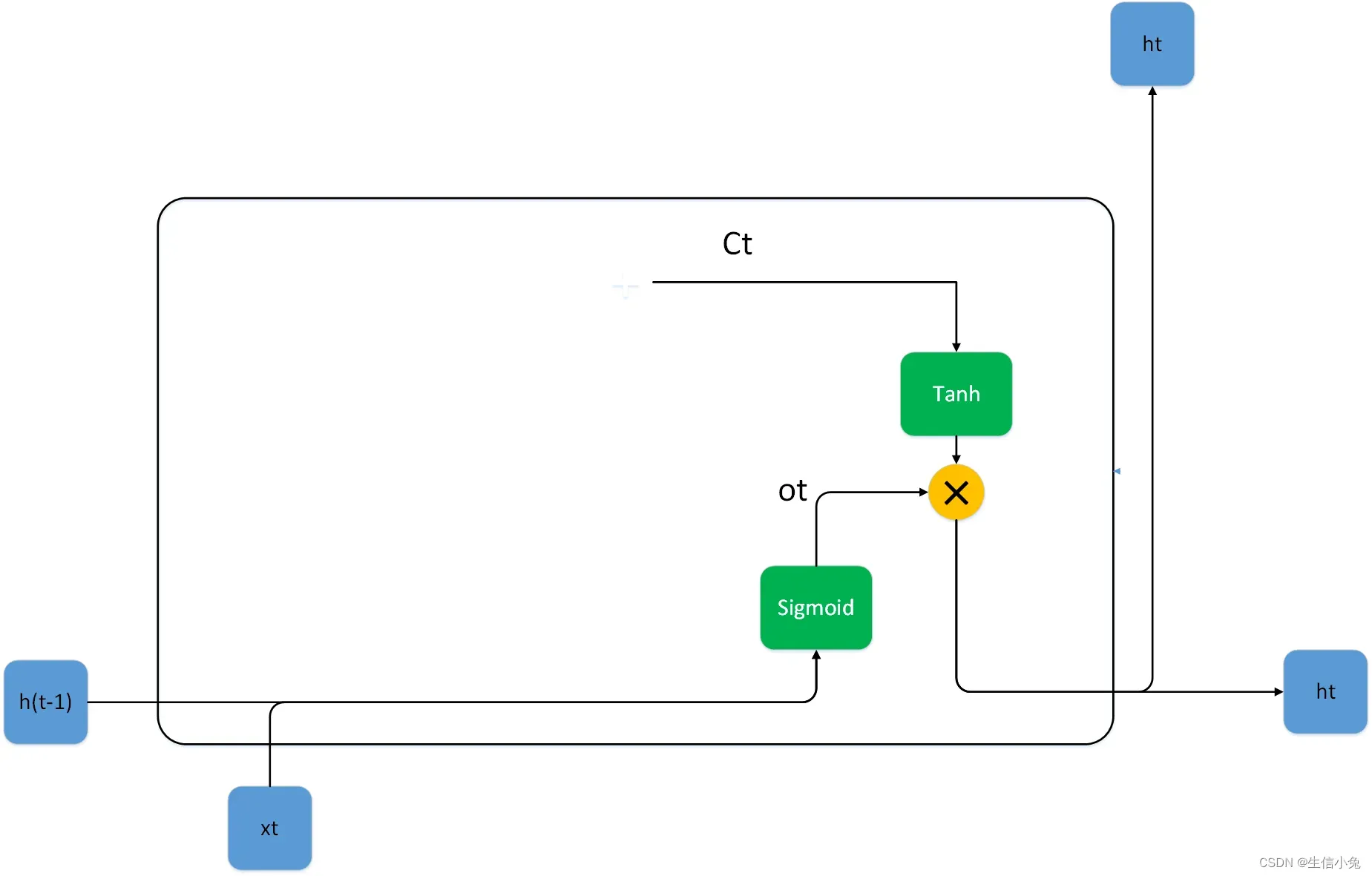
输出层的参数有、
、
、
。通过输出门得到ot,最终由ot与ct得到此时刻的输出ht,并且也可以继续传递到下一个cell。
LSTM与RNN同样权值共享,每一个LSTM cell都使用相同的参数。在这个模型中,所需要的参数有与
,有时根据需要也可以不需要偏置b。
二:方法实现
1.使用Pytorch设计LSTMCell与LSTM
import torch
from torch import nn
from torch.utils.data import DataLoader
import numpy as np
class LSTMCell(nn.Module):
def __init__(self,input_size,hidden_size):
'''
:param input_size: 输入特征个数
:param hidden_size: 隐藏层c、h的特征数
'''
super().__init__()
self.w_if=nn.Parameter(torch.randn(size=(input_size,hidden_size)))
self.w_ii=nn.Parameter(torch.randn(size=(input_size,hidden_size)))
self.w_ig=nn.Parameter(torch.randn(size=(input_size,hidden_size)))
self.w_io=nn.Parameter(torch.randn(size=(input_size,hidden_size)))
self.w_hf=nn.Parameter(torch.randn(size=(hidden_size,hidden_size)))
self.w_hi=nn.Parameter(torch.randn(size=(hidden_size,hidden_size)))
self.w_hg=nn.Parameter(torch.randn(size=(hidden_size,hidden_size)))
self.w_ho=nn.Parameter(torch.randn(size=(hidden_size,hidden_size)))
self.b_if=nn.Parameter(torch.randn(size=(1,hidden_size)))
self.b_ii=nn.Parameter(torch.randn(size=(1,hidden_size)))
self.b_ig=nn.Parameter(torch.randn(size=(1,hidden_size)))
self.b_io=nn.Parameter(torch.randn(size=(1,hidden_size)))
self.b_hf=nn.Parameter(torch.randn(size=(1,hidden_size)))
self.b_hi=nn.Parameter(torch.randn(size=(1,hidden_size)))
self.b_hg=nn.Parameter(torch.randn(size=(1,hidden_size)))
self.b_ho=nn.Parameter(torch.randn(size=(1,hidden_size)))
self.sigmoid=nn.Sigmoid()
self.tanh=nn.Tanh()
def forward(self,input,h,c):
ft=self.sigmoid(torch.matmul(input,self.w_if)+self.b_if+torch.matmul(h,self.w_hf)+self.b_hf)
it=self.sigmoid(torch.matmul(input,self.w_ii)+self.b_ii+torch.matmul(h,self.w_hi)+self.b_hi)
gt=self.tanh(torch.matmul(input,self.w_ig)+self.b_ig+torch.matmul(h,self.w_hg)+self.b_hg)
ct=torch.mul(ft,c)+torch.mul(it,gt)
ot=self.sigmoid(torch.matmul(input,self.w_io)+self.b_io+torch.matmul(h,self.w_ho)+self.b_ho)
ht=torch.mul(ot,self.tanh(ct))
return ht,ct
class LSTM(LSTMCell):
def __init__(self,input_size,hidden_size):
super().__init__(input_size,hidden_size)
self.input_size=input_size
self.hidden_size=hidden_size
self.lstmcell=LSTMCell(input_size,hidden_size)
def forward(self,input):
b,l,h=input.shape
output=[]
h0=torch.zeros(size=(1,self.hidden_size))
c0=torch.zeros(size=(1,self.hidden_size))
for i in range(l):
ht,ct=self.lstmcell(input[:,i,:],h0,c0)
output.append(ht)
h0,c0=ht,ct
return torch.stack(output).permute(1,0,2),c0
a=np.arange(0,100,0.1)
b=np.sin(a)
data=[]
label=[]
for i in range(1000-20):
data.append(b[i:i+10].reshape(-1,1))
label.append(b[i+10:i+20].reshape(-1,1))
class dataset:
def __init__(self):
self.data=torch.tensor(np.array(data),dtype=torch.float32)
self.label=torch.tensor(np.array(label),dtype=torch.float32)
self.n=len(data)
def __len__(self):
return self.n
def __getitem__(self, item):
return self.data[item],self.label[item]
if __name__=='__main__':
lstm=LSTM(input_size=1,hidden_size=1)
optim=torch.optim.Adam(params=lstm.parameters())
Loss=nn.MSELoss()
data=DataLoader(dataset(),shuffle=True,batch_size=4)
for i in range(10):
for d in data:
yp=lstm(d[0])[0]
loss=Loss(yp,d[1])
optim.zero_grad()
loss.backward()
optim.step()
print(loss)2.使用Pytorch中LSTM方法
Pytorch中LSTMCell与LSTM方法中参数与RNN方法中的参数完全一致,意义相同,并且也可以控制参数来设置双向LSTM、深层LSTM等模型,兔兔在这里不再赘述,需要的同学可以参考兔兔前面的文章。唯一不同的是,LSTMcell除了input 和h,还需要c。LSTM的输出除了所有LSTM cell的输出,还有最后一个cell的ct、ht的输出。
兔兔在这里仍以Bitcoin数据为例,利用三个月的数据进行训练,从而能够进行未来数据的预测。这部分代码与之前RNN那里的代码几乎相同,只是把nn.RNN改成了nn.LSTM。
import pandas as pd
import numpy as np
import re
import torch
from torch import nn
from torch.utils.data import DataLoader
df=pd.DataFrame(pd.read_csv('Bitcoin.csv'))
n=len(df)
opening=[]
closing=[]
transaction=[]
for i in range(n):
a = re.split(',',df['开盘'].loc[i])
a=float(a[0])*1000+float(a[1])
b = re.split(',', df['收盘'].loc[i])
b = float(b[0]) * 1000 + float(b[1])
c=re.split('K',df['交易量'].loc[i])[0]
c=float(c)
opening.append(a)
closing.append(b)
transaction.append(c)
data=np.array([opening,closing,transaction]).transpose()
seq_size=10 #RNN长度
train_num=1000#训练数据个数
epoch=100
train_data=[]
train_label=[]
for i in range(1000):
j=np.random.randint(0,n-seq_size-2)
train_data.append(data[j:j+seq_size])
train_label.append(data[j+2:j+seq_size+2])
train_data=np.float32(np.array(train_data,dtype=object))
train_label=np.float32(np.array(train_label,dtype=object))
class dataset:
def __init__(self):
self.data=torch.tensor(train_data,dtype=torch.float32)
self.label=torch.tensor(train_label,dtype=torch.float32)
def __len__(self):
return train_num
def __getitem__(self, item):
return self.data[item],self.label[item]
lstm=nn.LSTM(input_size=3,hidden_size=3,bidirectional=False,batch_first=True,num_layers=2)
optim=torch.optim.Adam(params=lstm.parameters(),lr=1e-12)
Loss=nn.MSELoss()
data=DataLoader(dataset(),batch_size=10)
for i in range(epoch):
print('the {} epoch'.format(i))
for d in data:
yp=lstm(d[0])[0]
loss=Loss(yp,d[1])
optim.zero_grad()
loss.backward()
optim.step()
print(loss.data)三:总结
长短时记忆网络作为RNN的一种改进方法,在一定程度上克服了长期依赖问题,并且成为目前循环神经网络在实际应用中的常用模型之一。当然,该模型在更为复杂的问题上仍有一定的不足,所以在RNNs中仍有其它种类的循环神经网络,用以解决不同的问题。
文章出处登录后可见!