1.制作数据集
1.1标注数据集
本人采用的是电力标识牌(200张图片)作为数据集,首先在电脑终端cmd输入labelimg,回车,打开标注软件


左侧open dir选择数据集图片路径,change save dir是标签路径,文件格式选择yolo,也可以选择voc,然后通过脚本转换成yolo。本文直接采用yolo格式。连续打200张图片标注。
数据集文件dianlibiaoshipaiA的结构

1.2划分数据集
接下来划分训练集和验证集,创建python脚本,路径为dianlibiaoshipaiA/split_train_val.py
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='dianlibiaoshipaiA/Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='dianlibiaoshipaiA/ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.9 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
读者可修改其中的两个路径即可,一个输入,一个输出
划分比例也可修改,本人采用0.9,也即训练集:验证集=9:1
运行脚本,可得
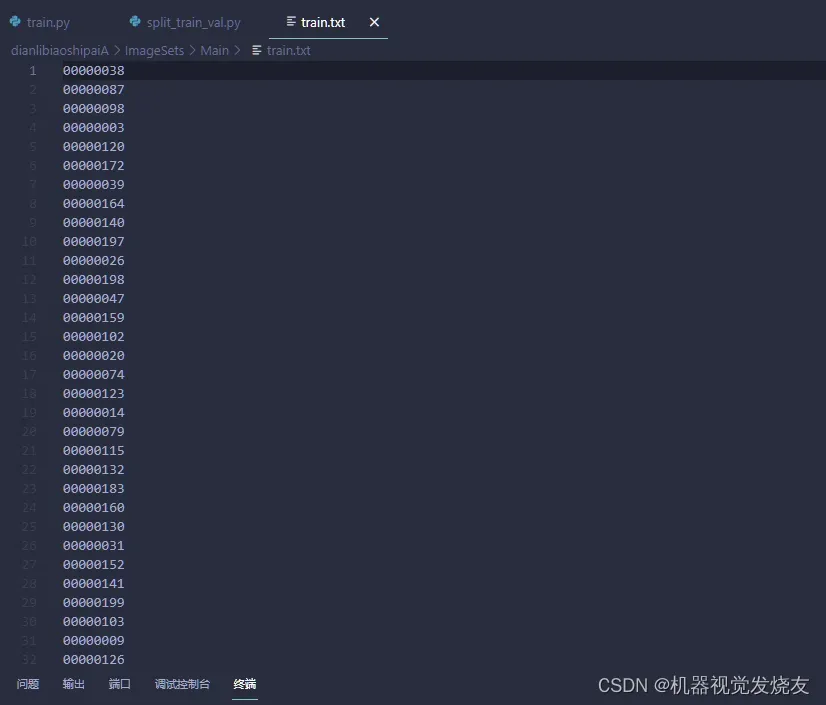
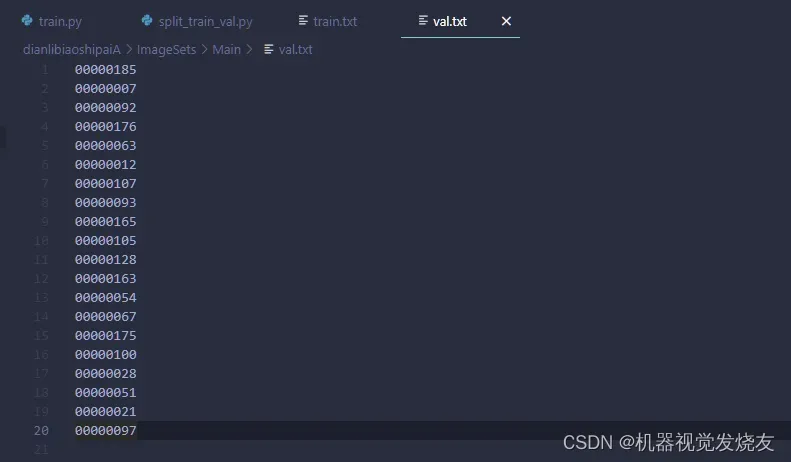
表明数据集划分好了,接下来生成训练集和验证集路径,创建脚本,路径如下dianlibiaoshipaiA/hualujin.py
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["signboard"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
wd = getcwd()
for image_set in sets:
if not os.path.exists('dianlibiaoshipaiA/Annotations'):
os.makedirs('dianlibiaoshipaiA/Annotations')
image_ids = open('dianlibiaoshipaiA/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
if not os.path.exists('dianlibiaoshipaiA/dataSet_path/'):
os.makedirs('dianlibiaoshipaiA/dataSet_path/')
list_file = open('dianlibiaoshipaiA/dataSet_path/%s.txt' % (image_set), 'w')
# 这行路径不需更改,这是相对路径
for image_id in image_ids:
list_file.write('dianlibiaoshipaiA/images/%s.jpg\n' % (image_id))
list_file.close()读者可修改绿色部分,运行结果
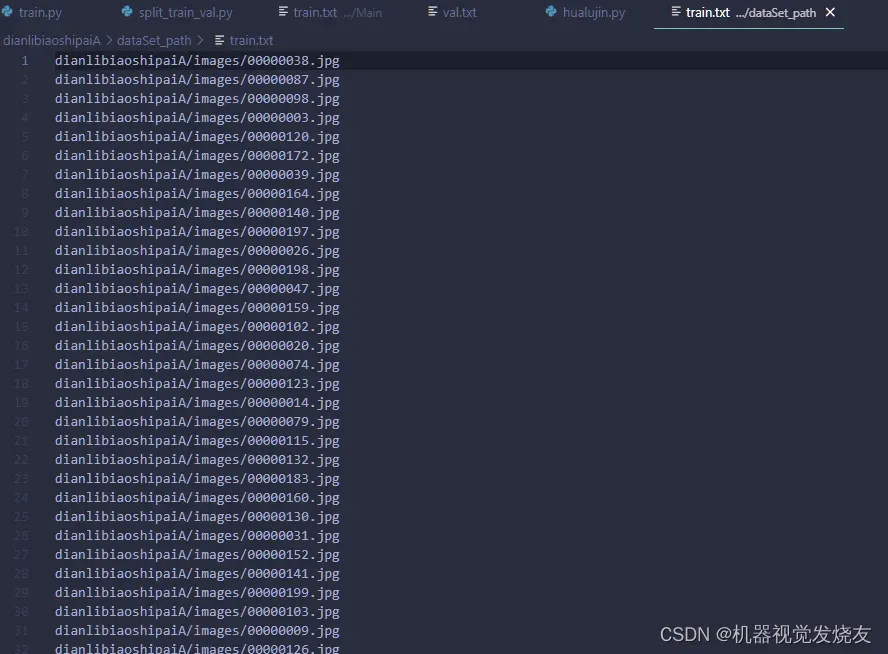
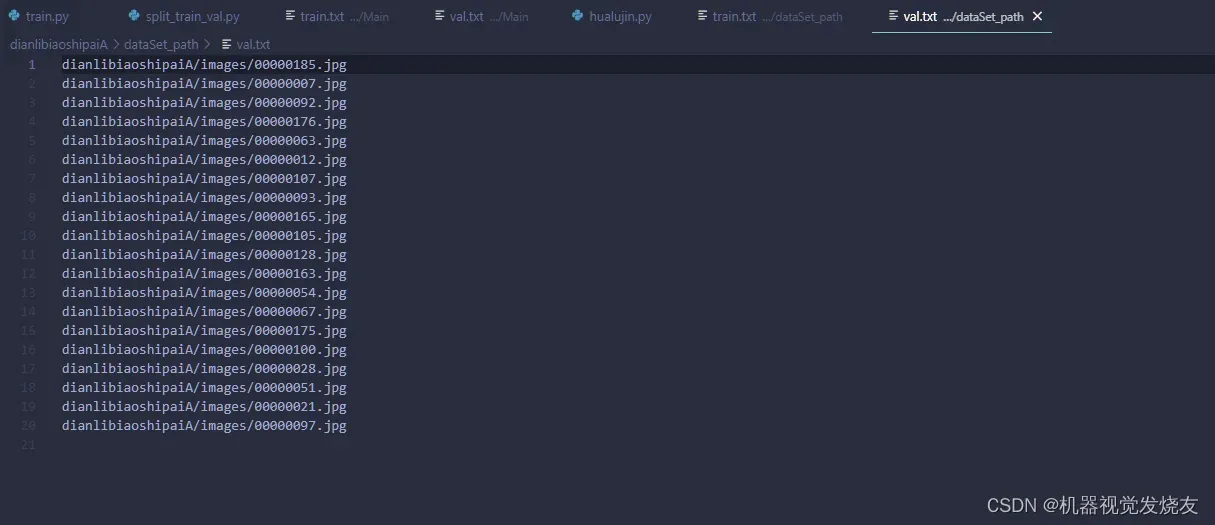
1.3 配置yaml文件
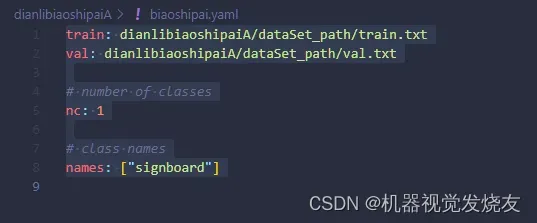
最后,创建yaml文件,路径为dianlibiaoshipaiA/biaoshipai.yaml
train: dianlibiaoshipaiA/dataSet_path/train.txt
val: dianlibiaoshipaiA/dataSet_path/val.txt
# number of classes
nc: 1
# class names
names: ["signboard"]
最后检查utils/datasets.py文件
快捷键输入ctr+F,搜索框内输入如下

修改训练图片和标签的文件名,与自己用的文件夹一一对应,笔者训练的图片文件名和标签名分别是train_images和 labels
否则在训练时会报如下错误

2. 训练
2.1 修改train.py
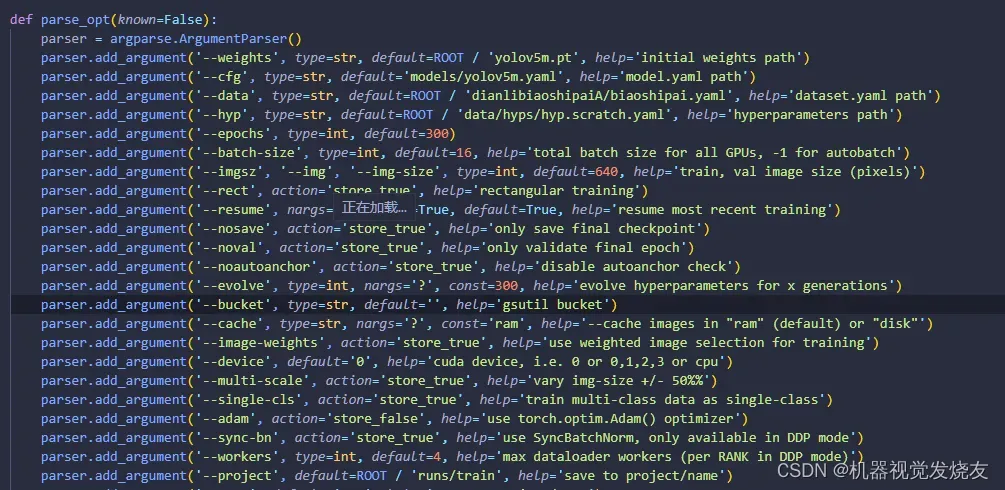
weights:预训练权重地址
data:数据集配置yaml地址
hyp:超参数配置yaml文件地址
adam:修改成store_false,采用adam优化器
其他参数可以自行调节
2.2 运行train.py
nohup python3 -u train.py > log_file.txt &
输出权重,训练配置文件如下4幅图

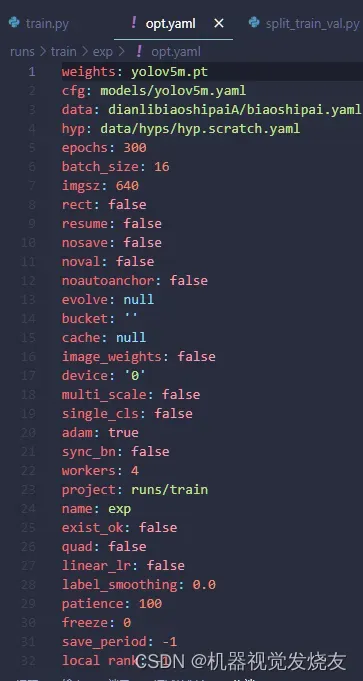
可视化训练过程
tensorboard --logdir=runs/train/exp 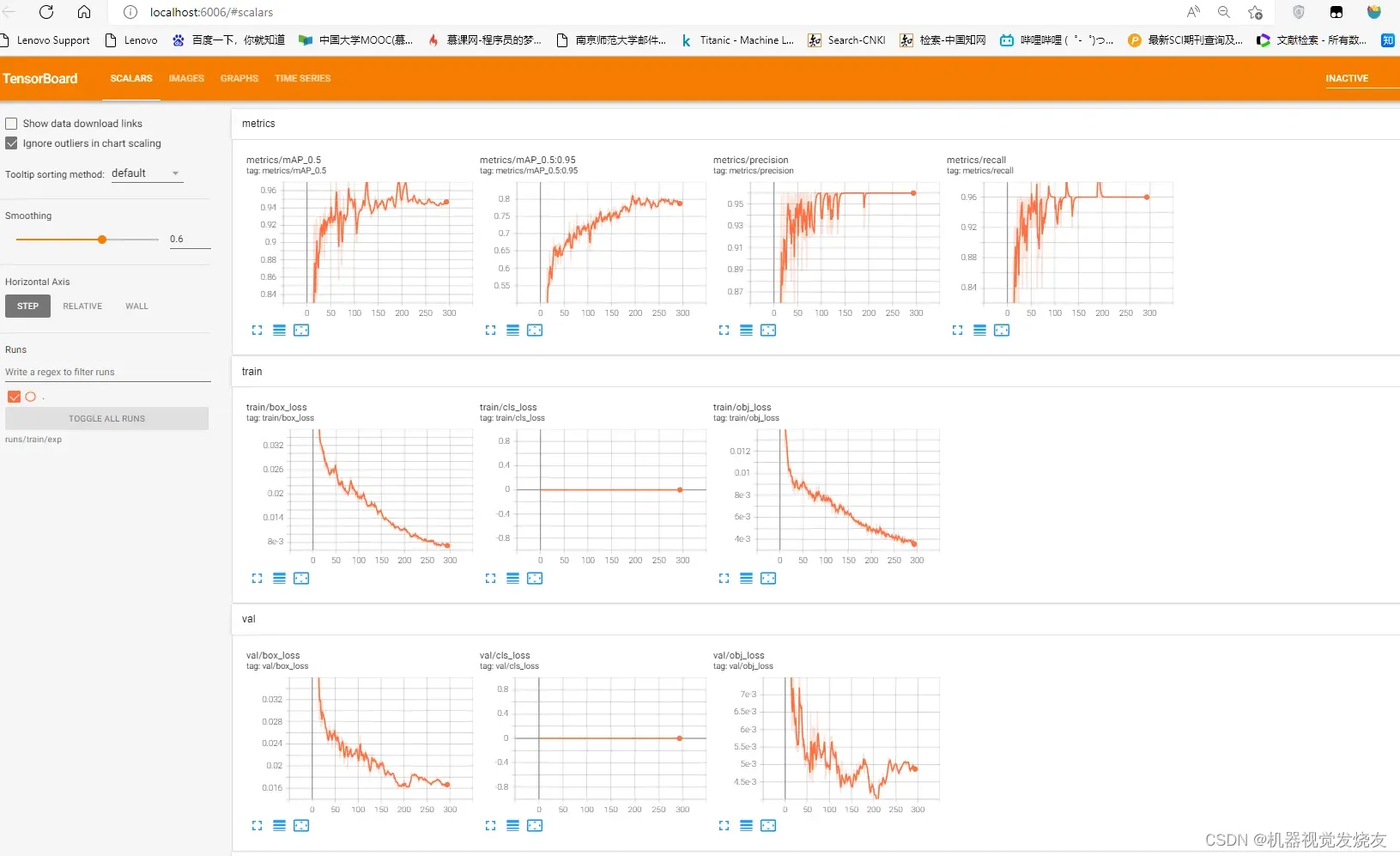
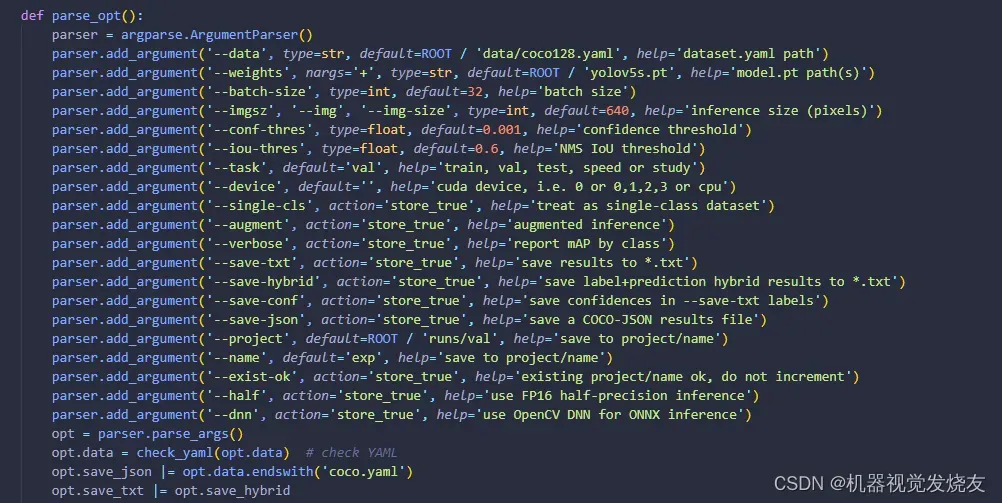
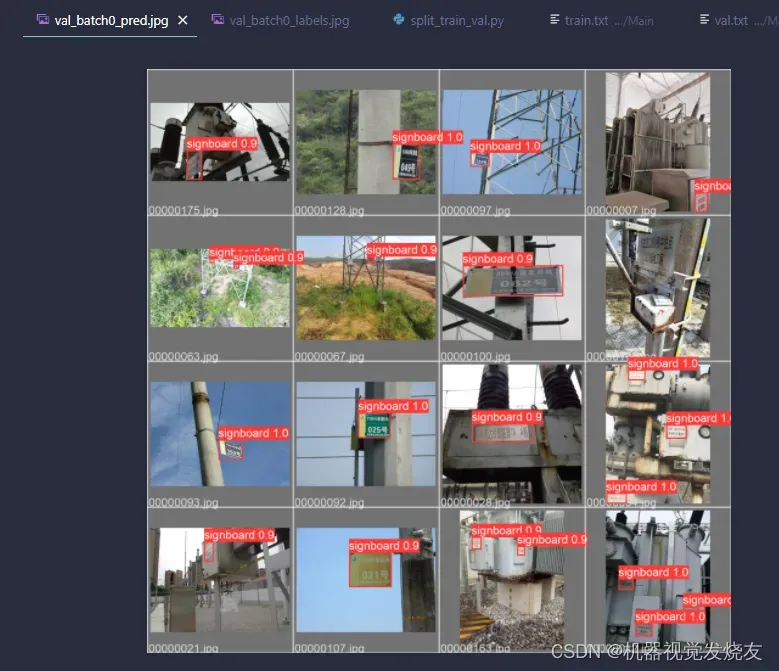
3 验证
修改val.py,改data ,weights,运行python val.py
4 预测
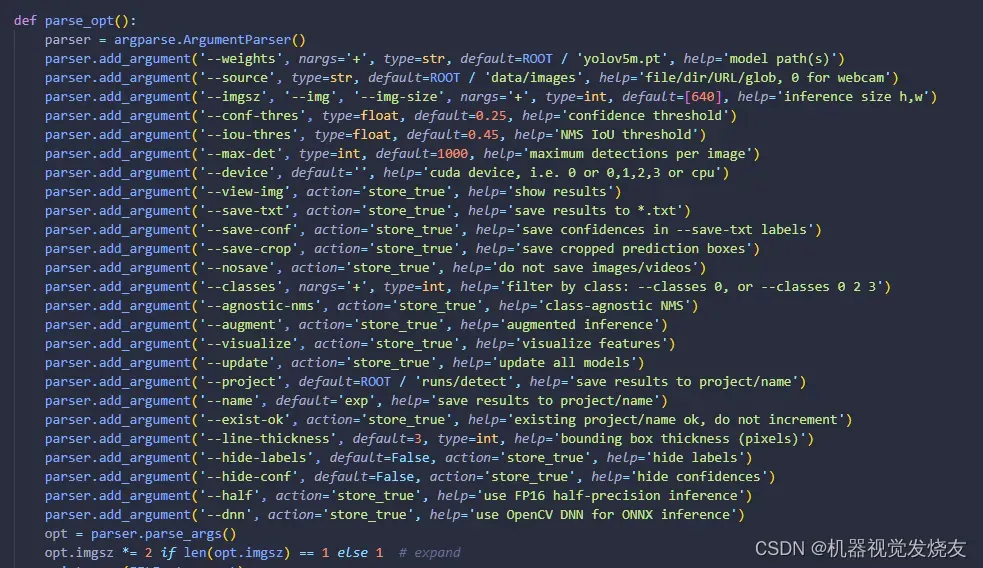
修改detect.py,改weights,source,运行detect.py

文章出处登录后可见!