关于轴承相关的项目之前做的大都是故障识别诊断类型的,少有涉及回归预测的,周末的时候宅家发现一个轴承寿命加速实验的数据集就想着拿来做一下寿命预测。
首先看下数据集如下:
直接百度即可搜到,这里就不再赘述了。
Learning_set为训练集
Test_set为测试集
我这里为了简单处理直接使用Learning_set作为总数据集,随机划分指定比例作为测试集。
当然了你也可以选择分别读取加载两部分的数据分别作为训练集和测试集都可以的。
每个目录下都是一堆csv文件,样例如下:
样例数据内容如下:
9,11,19,1.1879e+05,0.059,-0.372
9,11,19,1.1883e+05,0.603,-0.085
9,11,19,1.1887e+05,0.613,0.112
9,11,19,1.1891e+05,0.465,0.185
9,11,19,1.1894e+05,-0.216,-0.256
9,11,19,1.1898e+05,-0.806,0.177
9,11,19,1.1902e+05,-0.653,0.113
9,11,19,1.1906e+05,-0.007,0.398
9,11,19,1.191e+05,0.888,0.145
9,11,19,1.1914e+05,1.037,-0.542
9,11,19,1.1918e+05,0.299,-0.201
9,11,19,1.1922e+05,-0.552,-0.022
9,11,19,1.1926e+05,-1.237,0.264
9,11,19,1.193e+05,-1.059,0.155
9,11,19,1.1934e+05,-0.269,0.163
9,11,19,1.1937e+05,0.662,0.269
9,11,19,1.1941e+05,0.949,0.078
9,11,19,1.1945e+05,0.403,-0.065
9,11,19,1.1949e+05,-0.279,-0.411
9,11,19,1.1953e+05,-0.856,0.033
9,11,19,1.1957e+05,-0.736,0.201
9,11,19,1.1961e+05,0.098,0.326
9,11,19,1.1965e+05,0.718,-0.183
9,11,19,1.1969e+05,0.61,-0.038
9,11,19,1.1973e+05,0.201,0.092
9,11,19,1.1976e+05,-0.3,0.01
9,11,19,1.198e+05,-0.378,0.447
9,11,19,1.1984e+05,0.149,-0.189
9,11,19,1.1988e+05,0.499,-0.421
9,11,19,1.1992e+05,0.325,0.024
9,11,19,1.1996e+05,-0.265,0.49
9,11,19,1.2e+05,-0.708,0.487
9,11,19,1.2004e+05,-0.443,0.157
9,11,19,1.2008e+05,-0.042,-0.437
9,11,19,1.2012e+05,0.238,-0.025
9,11,19,1.2016e+05,0.46,0.193
9,11,19,1.202e+05,0.192,0.036
9,11,19,1.2023e+05,-0.093,0.118
9,11,19,1.2027e+05,-0.344,0.148
9,11,19,1.2031e+05,-0.174,0.117
9,11,19,1.2035e+05,-0.029,-0.026
9,11,19,1.2039e+05,0.026,0.469关于数据处理可以直接使用官方提供的代码:
%% 批量读取IEEE PHM 2012轴承全寿命数据
clc
clear all
close all
%% 文件夹路径
file_path = 'Learning_set/';
%% 全寿命振动信号
csv_acc_path_list = dir(strcat(file_path,'acc*.csv'));
csv_acc_num = length(csv_acc_path_list);%获取文件总数量
if csv_acc_num > 0 %有满足条件的文件
for j = 1:csv_acc_num %逐一读取文件
csv_acc_name = csv_acc_path_list(j).name;% 文件名
csv_acc = csvread(strcat(file_path,csv_acc_name));
csv_acc_data(:,:,j)=csv_acc;
fprintf('%d %d %s\n',csv_acc_num,j,strcat(file_path,csv_acc_name));% 显示正在处理的文件名
end
end
% 合并矩阵 时间*通道
channel=6; %信号的通道数
csv_acc_data_change=permute(csv_acc_data,[2 1 3]);
csv_acc_data=reshape(csv_acc_data_change,channel,prod(size(csv_acc_data))/channel)';
%% 全寿命温度信号
csv_temp_path_list = dir(strcat(file_path,'temp*.csv'));%获取该文件夹中所有csv格式的文件
csv_temp_num = length(csv_temp_path_list);%获取文件总数量
delimiter = ',';
formatSpec = '%s%s%s%s%s%s%[^\n\r]';
if csv_temp_num > 0 %有满足条件的文件
for j = 1:csv_temp_num %逐一读取文件
csv_temp_name = csv_temp_path_list(j).name;% 文件名
csv_temp_fileID = fopen(strcat(file_path,csv_temp_name),'r');
csv_temp = textscan(csv_temp_fileID, formatSpec, 'Delimiter', delimiter);
for i=1:size(csv_temp{1,1},1)
csv_temp_data(i,:,j)=str2num(csv_temp{1,1}{i,1})';
end
fprintf('%d %d %s\n',csv_temp_num,j,strcat(file_path,csv_temp_name));% 显示正在处理的文件名
fclose(csv_temp_fileID);
end
end
% 合并矩阵 时间*通道
channel=5; %信号的通道数
csv_temp_data_change=permute(csv_temp_data,[2 1 3]);
csv_temp_data=reshape(csv_temp_data_change,channel,prod(size(csv_temp_data))/channel)';
%% 全寿命振动信号和温度信号的时域图
clearvars -except csv_acc_data csv_temp_data
figure;subplot 211;plot(csv_acc_data(:,5));title('水平振动信号');
subplot 212;plot(csv_acc_data(:,6));title('竖直振动信号');
figure;plot(csv_temp_data(:,5));title('温度信号')这里我不是很懂数据背景所以就不多解释了,有懂行的可以交流一下。
为了直观分析数据这里对其进行了可视化如下:
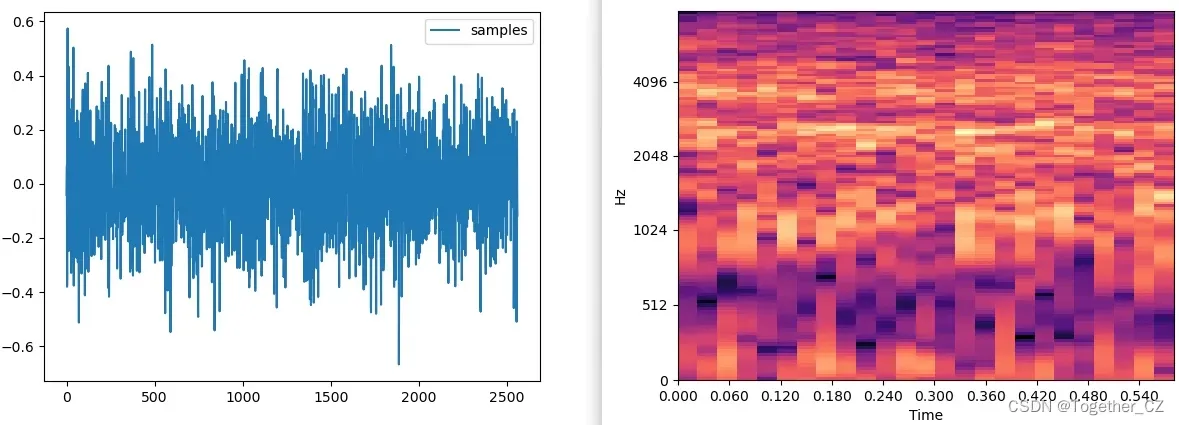
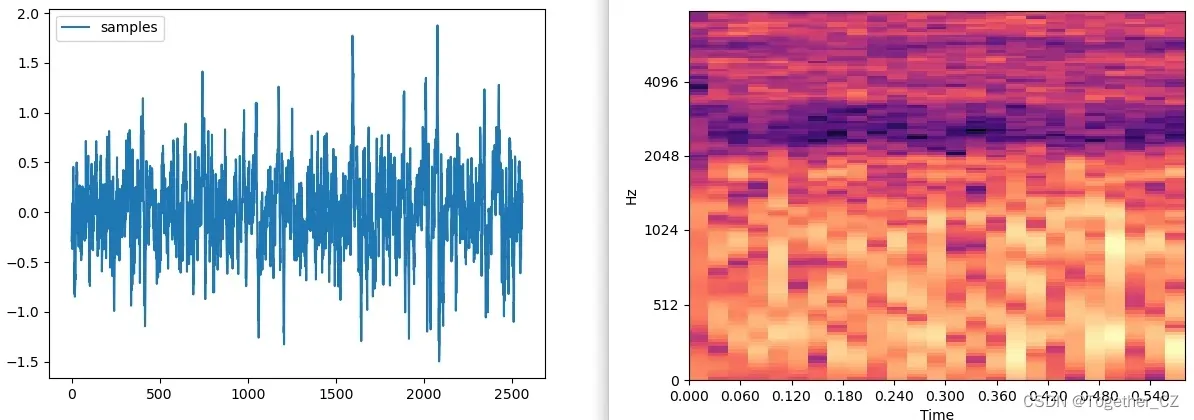
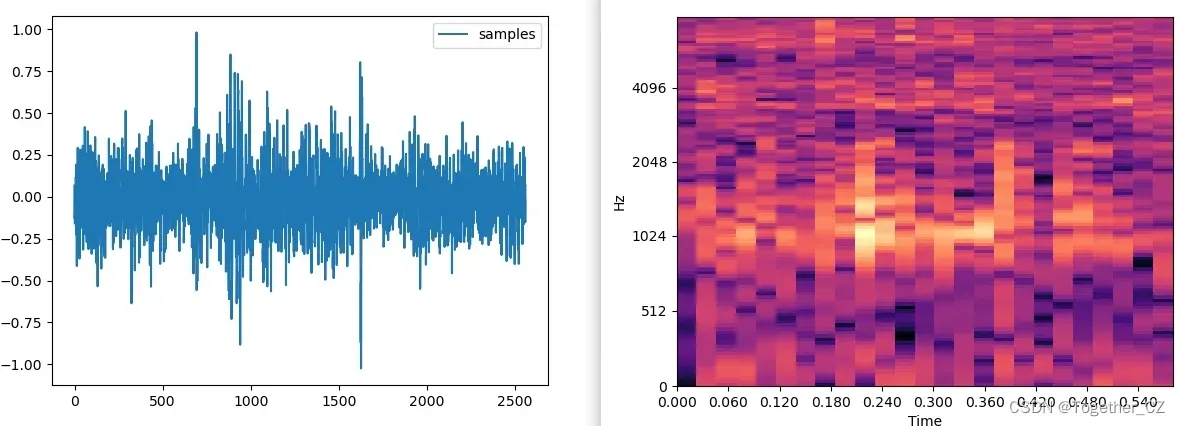
完成数据处理之后就可以搭建所需要的模型了,这里出于做实验的目的开发了很多种不同的模型:CNN、CNN-LSTM、CNN-GRU、CNN-LSTM-ATTENTION、CNN-GRU-ATTENTION等,这里以CNN为例简单看下实际的结构:

只使用了两层的卷积来实现特征提取。
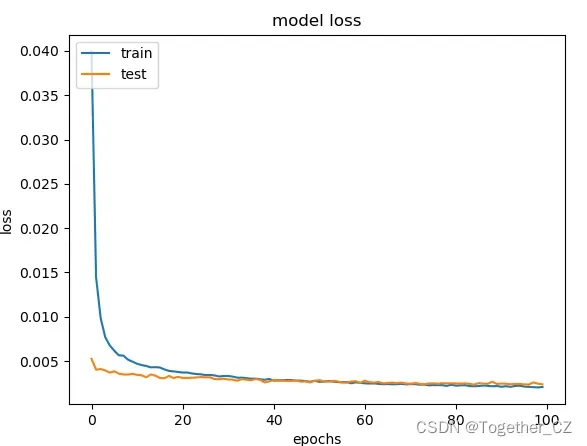
效果如下:
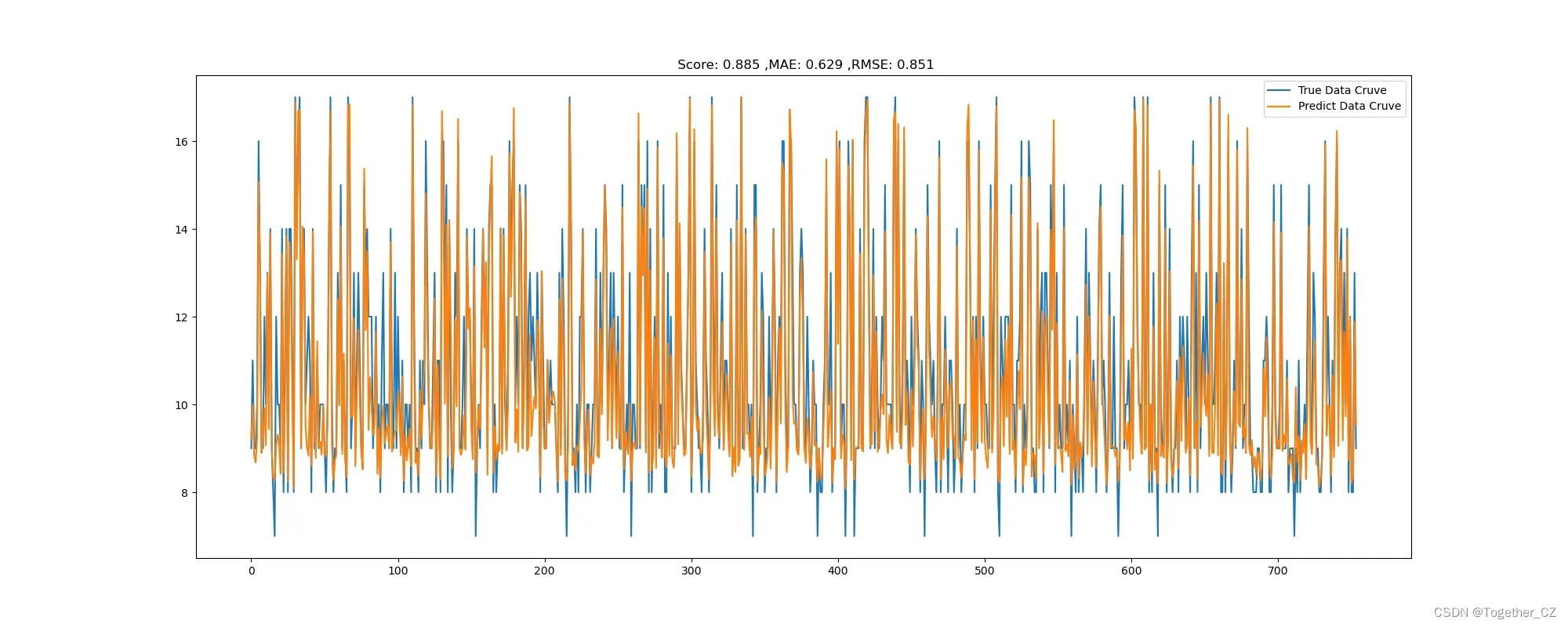
loss曲线如下所示:
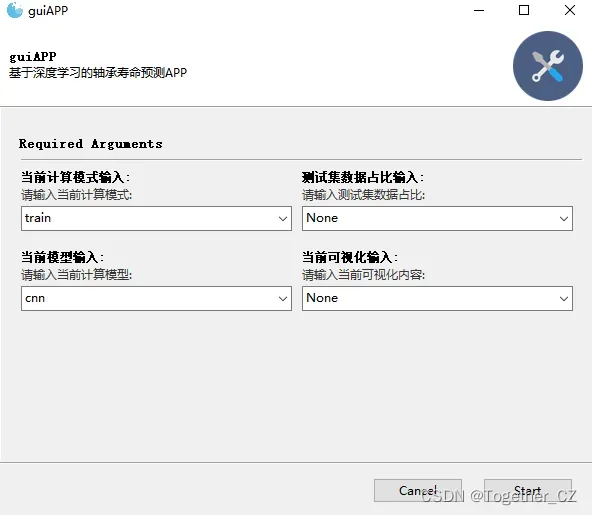
为了整体方便使用不同系列的模型这里开发了界面将所有模型整合到了一起,如下:
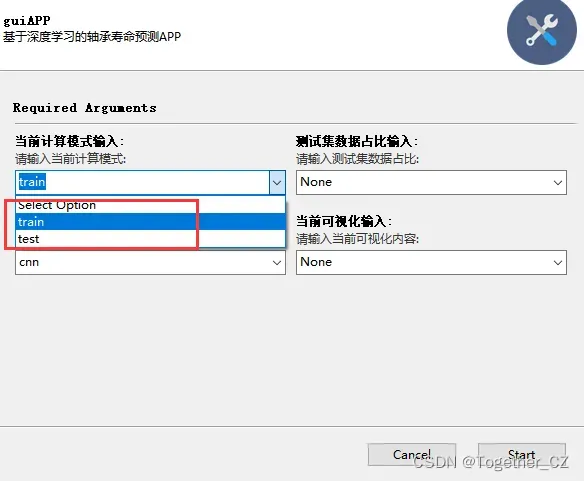
支持训练/测试两种不同的计算模式如下:
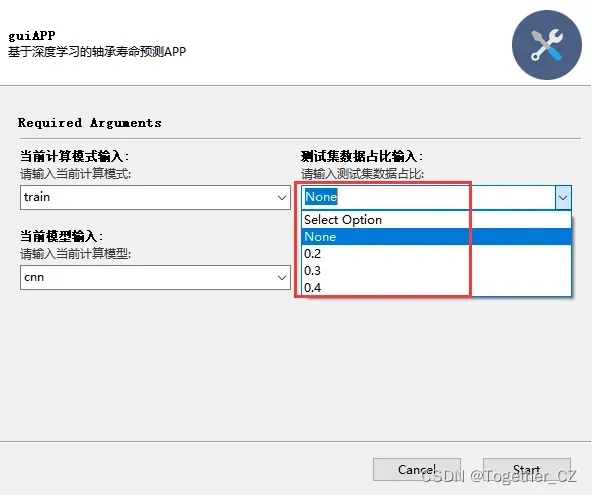
支持自定义测试数据占比计算,如下:
支持不同模型自由切换选择,如下:
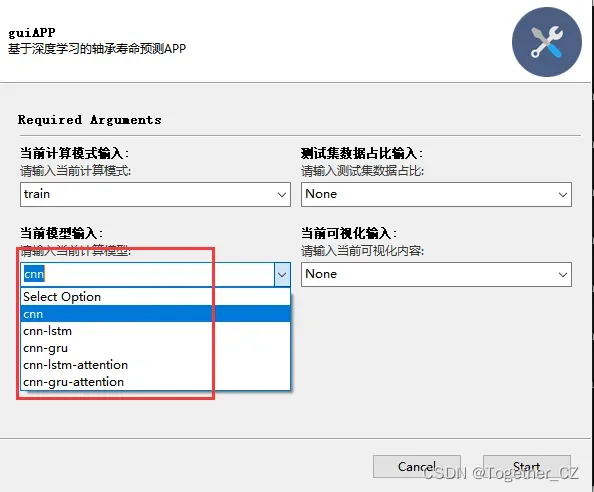
支持不同可视化选项,如下:
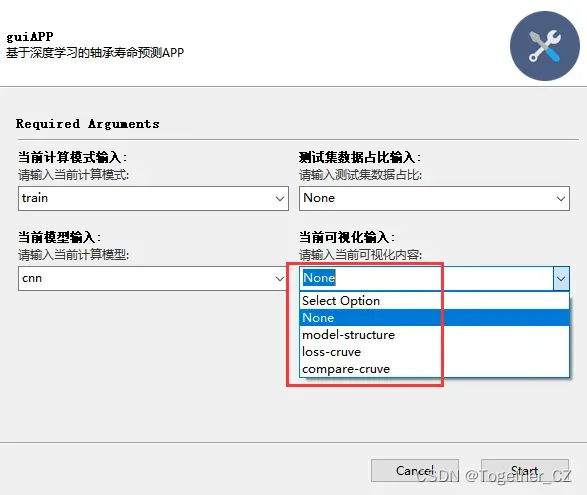
后续有时间话会考虑将一些集成测量加入进来尝试构建更加高效的模型。
文章出处登录后可见!
已经登录?立即刷新