
MMDetection是针对目标检测任务推出的一个开源项目,它基于Pytorch实现了大量的目标检测算法,把数据集构建、模型搭建、训练策略等过程都封装成了一个个模块,通过模块调用的方式,我们能够以很少的代码量实现一个新算法,大大提高了代码复用率。本文记录一下关于MMdetection的使用方法,可能比较白话,专业的可以去看下面的教程:
MMDetection框架入门教程
官方文档–config文件教程
1.文件夹结构
从github上下载mmdetection的代码,解压后得到的目录如下(这里只显示主要文件夹):
├─mmdetection-master
│ ├─build
│ ├─checkpoints # 存放断点
│ ├─configs # 存放配置文件
│ ├─data # 存放数据
│ ├─demo
│ ├─dist
│ ├─docker
│ ├─docs
│ ├─mmdet # mmdetection的主要源码,包括模型定义之类的
│ ├─requirements
│ ├─resources
│ ├─src
│ ├─tests
│ ├─tools # 训练、测试、打印config文件等等主要工具
│ └─work_dirs # 存放训练日志和训练结果
2.环境配置
- 创建环境,安装pytorch:
conda create --name envName python=3.7
conda activate envName
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=10.2 -c pytorch - 按照官方github上的教程安装mmcv:
pip install -U openmim
mim install mmcv-full - 安装mmdet:
pip install mmdet
以前安装mmcv特别容易报错,现在基本只要你按照对应版本安装pytorch,然后使用openmim来安装mmcv,基本就不会报错。上面的指令是配置python3.7的环境,如果是其他的python版本应该也行。
3.模型训练
熟练掌握使用MMdetection训练模型的关键在于理解config(配置文件)。假如你要训练faster rcnn,那么只需要配置好配置文件,然后用下面的指令训练:
python tools/train.py configs/faster_rcnn/faster_rcnn_r101_fpn_2x_towervoc.py
其中configs/faster_rcnn/faster_rcnn_r101_fpn_2x_towervoc.py就是我们训练时需要使用的配置文件。训练过程中需要的所有参数设置都定义在这个配置文件里。
使用的时候尽量注意几点:
- 尽量不要修改除了配置文件之外的参数
- 不要改动原有的配置文件,如果想要进行新的任务就新建配置文件
因为MMdetection这个项目里文件很多,如果你训练某个网络改了它原本的哪个配置文件或者哪个py文件里的参数,可能过一会儿就忘记了,下次再使用的时候如果别的网络也需要这个模块就会出问题。
ok接下来主要介绍一下config文件。
一、config文件命名规则:
{model}_[model setting]_{backbone}_{neck}_[norm setting]_[misc]_[gpu x batch_per_gpu]_{schedule}_{dataset}
其中各个字段的含义:
{model}: 模型种类,例如 faster_rcnn, mask_rcnn 等。
[model setting]: 特定的模型,例如 htc 中的without_semantic, reppoints 中的 moment 等。
{backbone}: 主干网络种类例如 r50 (ResNet-50), x101 (ResNeXt-101) 等。
{neck}: Neck 模型的种类包括 fpn, pafpn, nasfpn, c4 等。
[norm_setting]: 默认使用 bn (Batch Normalization),其他指定可以有 gn (Group Normalization), syncbn (Synchronized Batch Normalization) 等。 gn-head/gn-neck 表示 GN 仅应用于网络的 Head 或 Neck, gn-all 表示 GN 用于整个模型, 例如主干网络、Neck 和 Head。
[misc]: 模型中各式各样的设置/插件,例如 dconv、 gcb、 attention、albu、 mstrain 等。
[gpu x batch_per_gpu]:GPU 数量和每个 GPU 的样本数,默认使用 8x2。
{schedule}: 训练方案,选项是 1x、 2x、 20e 等。1x 和 2x 分别代表 12 epoch 和 24 epoch,20e 在级联模型中使用,表示 20 epoch。对于 1x/2x,初始学习率在第 8/16 和第 11/22 epoch 衰减 10 倍;对于 20e ,初始学习率在第 16 和第 19 epoch 衰减 10 倍。
{dataset}:数据集,例如 coco、 cityscapes、 voc_0712、 wider_face 等。
二、config文件内容解析
每个网络的config文件都由四个部分组成:
- model settings
- dataset settings
- schedules
- runtime
文章开头给出的官方教程中有以mask rcnn的配置文件为例子逐行写的详细注释。这里只大致记录一下我一开始的一些误区。首先应该先学会使用一个工具tools/misc/print_config.py,这个工具打印出来的参数就是最后输入网络执行训练的参数,使用语法为:
python tools/misc/print_config.py configs/yolox/yolox_l_8x8_300e_coco.py
1.从_base_中继承初始参数
![]()
这个代表着在初始化配置文件时先继承自这些base config。如果后面不重新定义的话就默认使用这些base config的参数。以configs/yolox/yolox_l_8x8_300e_coco.py为例,YOLOX中关于学习率调度的参数lr_config最开始是继承自configs/_base_/schedules/schedule_1x.py的,也就是说应该是:
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500, # 学习率“热身”,初始学习率为0.001,经过500次迭代达到optimizer中
warmup_ratio=0.001, # 定义的lr
step=[8, 11])
但是最后发现,使用print_config打印出来的学习率调度并非如此。这是因为在这个配置文件最开始从_base_文件中继承lr_config之后,又在后面对其进行了修改:
lr_config = dict(
_delete_=True,
policy='YOLOX',
warmup='exp',
by_epoch=False,
warmup_by_epoch=True,
warmup_ratio=1,
warmup_iters=5, # 5 epoch
num_last_epochs=num_last_epochs,
min_lr_ratio=0.05)
_delete_=True代表删除原来从_base_中继承的lr_config,用这里定义的新的一组键值对来代替。如果只修改部分参数,比如只修改step,那么就不需要_delete_,只用在配置文件中添加:
lr_config = dict(
step=[7, 10])
需要注意的是,config文件中的键值对是按顺序读取的,如果你多次定义同一个参数,那么写在后面的会覆盖前面的。
2.学习率自动调整

最开始我误以为这个参数是调整batch_szie的。但其实这个参数的含义是本项目中设置的学习率都是基于8 gpus*8 batch_size的情况下的,如果你的设置不同,则会基于这个来根据你的batchsize自动调整你的初始学习率,所以这个值不要改,初始学习率也不要改。
调整batch_size的地方在这里(samples_per_gpu):
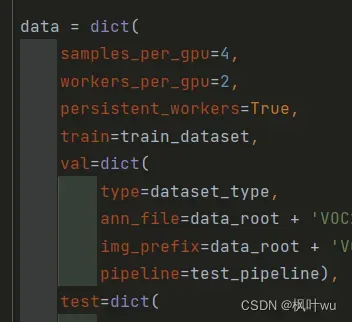
4.模型训练实战
使用MMdetection训练coco格式数据集非常简单,那么怎样在自己定义的voc数据集上面训练呢?这里我以ssd这个模型为例子来进行介绍。首先介绍一下我的数据集,voc格式,一共是有三个类别,文件夹结构如下:
├─TowerVoc
│ └─VOC2012
│ ├─Annotations
│ ├─ImageSets
│ │ └─Main
│ └─JPEGImages
这里只介绍怎么实现,具体改动哪些参数大家可以对比我这里给出的配置文件和原配置文件(我给出的代码也会标记出改动的地方)。
打开ssd对应的配置文件可以看到以下内容:
可以看到,默认都是使用coco数据集进行训练的。看看配置文件的继承关系:
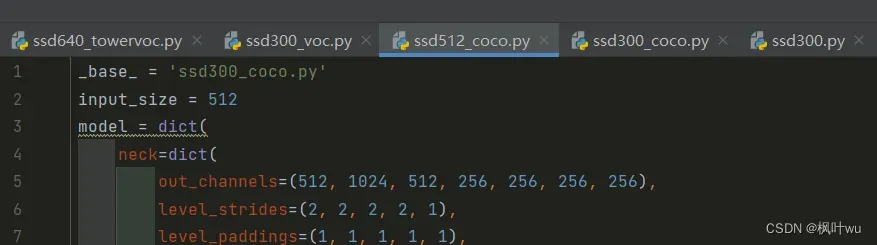
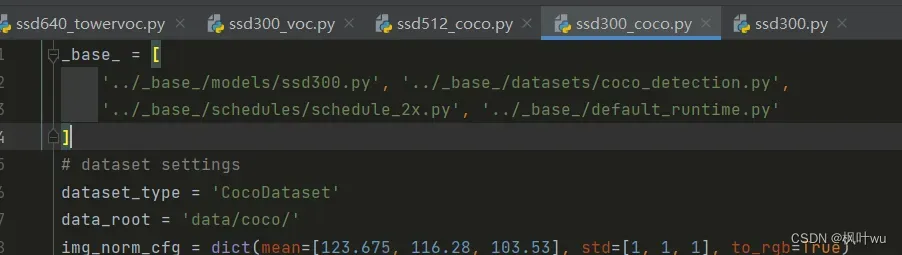
- 复制
ssd512_coco.py,将其命名为ssd512_towervoc.py。其中tower是我的数据集的名字,这里随便取。 - 复制
ssd300_coco.py,将其命名为ssd300_voc.py。 - 复制
configs/_base_/datasets/voc0712.py,命名为configs/_base_/datasets/voctower.py。
三个配置文件代码如下:
ssd512_towervoc.py
_base_ = 'ssd300_voc.py' # 改动1
input_size = 512
model = dict(
neck=dict(
out_channels=(512, 1024, 512, 256, 256, 256, 256),
level_strides=(2, 2, 2, 2, 1),
level_paddings=(1, 1, 1, 1, 1),
last_kernel_size=4),
bbox_head=dict(
in_channels=(512, 1024, 512, 256, 256, 256, 256),
anchor_generator=dict(
type='SSDAnchorGenerator',
scale_major=False,
input_size=input_size,
basesize_ratio_range=(0.1, 0.9),
strides=[8, 16, 32, 64, 128, 256, 512],
ratios=[[2], [2, 3], [2, 3], [2, 3], [2, 3], [2], [2]])))
# dataset settings
dataset_type = 'VOCDataset' # 改动3
data_root = 'data/TowerVoc/' # 改动4
img_norm_cfg = dict(mean=[123.675, 116.28, 103.53], std=[1, 1, 1], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='Expand',
mean=img_norm_cfg['mean'],
to_rgb=img_norm_cfg['to_rgb'],
ratio_range=(1, 4)),
dict(
type='MinIoURandomCrop',
min_ious=(0.1, 0.3, 0.5, 0.7, 0.9),
min_crop_size=0.3),
dict(type='Resize', img_scale=(640, 640), keep_ratio=False),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='PhotoMetricDistortion',
brightness_delta=32,
contrast_range=(0.5, 1.5),
saturation_range=(0.5, 1.5),
hue_delta=18),
dict(type='Normalize', **img_norm_cfg),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(512, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=False),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=4, # 如果有需要这里可以改成你自己的batchsize
workers_per_gpu=2,
train=dict(
_delete_=True,
type='RepeatDataset',
times=5,
dataset=dict(
type=dataset_type,
ann_file=data_root + 'VOC2012/ImageSets/Main/train.txt', # 改动5
img_prefix=data_root + 'VOC2012/',
pipeline=train_pipeline)),
val=dict(pipeline=test_pipeline),
test=dict(pipeline=test_pipeline))
# optimizer
optimizer = dict(type='SGD', lr=2e-3, momentum=0.9, weight_decay=5e-4)
optimizer_config = dict(_delete_=True)
custom_hooks = [
dict(type='NumClassCheckHook'),
dict(type='CheckInvalidLossHook', interval=50, priority='VERY_LOW')
]
# evaluation = dict(interval=1, metric='mAP')
# NOTE: `auto_scale_lr` is for automatically scaling LR,
# USER SHOULD NOT CHANGE ITS VALUES.
# base_batch_size = (8 GPUs) x (8 samples per GPU)
auto_scale_lr = dict(base_batch_size=64)
ssd300_voc.py
_base_ = [
'../_base_/models/ssd300.py', '../_base_/datasets/voctower.py', # 改动1
'../_base_/schedules/schedule_2x.py', '../_base_/default_runtime.py'
]
# model settings
input_size = 300
model = dict(
type='SingleStageDetector',
backbone=dict(
type='SSDVGG',
depth=16,
with_last_pool=False,
ceil_mode=True,
out_indices=(3, 4),
out_feature_indices=(22, 34),
init_cfg=dict(
type='Pretrained', checkpoint='open-mmlab://vgg16_caffe')),
neck=dict(
type='SSDNeck',
in_channels=(512, 1024),
out_channels=(512, 1024, 512, 256, 256, 256),
level_strides=(2, 2, 1, 1),
level_paddings=(1, 1, 0, 0),
l2_norm_scale=20),
bbox_head=dict(
type='SSDHead',
in_channels=(512, 1024, 512, 256, 256, 256),
num_classes=3, # 改动2
anchor_generator=dict(
type='SSDAnchorGenerator',
scale_major=False,
input_size=input_size,
basesize_ratio_range=(0.15, 0.9),
strides=[8, 16, 32, 64, 100, 300],
ratios=[[2], [2, 3], [2, 3], [2, 3], [2], [2]]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[0.1, 0.1, 0.2, 0.2])),
# model training and testing settings
train_cfg=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.,
ignore_iof_thr=-1,
gt_max_assign_all=False),
smoothl1_beta=1.,
allowed_border=-1,
pos_weight=-1,
neg_pos_ratio=3,
debug=False),
test_cfg=dict(
nms_pre=1000,
nms=dict(type='nms', iou_threshold=0.45),
min_bbox_size=0,
score_thr=0.02,
max_per_img=200))
cudnn_benchmark = True
# dataset settings
dataset_type = 'VOCDataset' # 改动3
data_root = 'data/TowerVoc/'
img_norm_cfg = dict(mean=[123.675, 116.28, 103.53], std=[1, 1, 1], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='Expand',
mean=img_norm_cfg['mean'],
to_rgb=img_norm_cfg['to_rgb'],
ratio_range=(1, 4)),
dict(
type='MinIoURandomCrop',
min_ious=(0.1, 0.3, 0.5, 0.7, 0.9),
min_crop_size=0.3),
dict(type='Resize', img_scale=(300, 300), keep_ratio=False),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='PhotoMetricDistortion',
brightness_delta=32,
contrast_range=(0.5, 1.5),
saturation_range=(0.5, 1.5),
hue_delta=18),
dict(type='Normalize', **img_norm_cfg),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(300, 300),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=False),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=8,
workers_per_gpu=3,
train=dict(
_delete_=True,
type='RepeatDataset',
times=5,
dataset=dict(
type=dataset_type,
ann_file=data_root + 'VOC2012/ImageSets/Main/train.txt', # 这里其实可以不改
img_prefix=data_root + 'VOC2012/', # 因为ssd300_voc.py会重写
pipeline=train_pipeline)),
val=dict(pipeline=test_pipeline),
test=dict(pipeline=test_pipeline))
# optimizer
optimizer = dict(type='SGD', lr=2e-3, momentum=0.9, weight_decay=5e-4)
optimizer_config = dict(_delete_=True)
custom_hooks = [
dict(type='NumClassCheckHook'),
dict(type='CheckInvalidLossHook', interval=50, priority='VERY_LOW')
]
# NOTE: `auto_scale_lr` is for automatically scaling LR,
# USER SHOULD NOT CHANGE ITS VALUES.
# base_batch_size = (8 GPUs) x (8 samples per GPU)
auto_scale_lr = dict(base_batch_size=64)
voctower.py
# dataset settings
dataset_type = 'VOCDataset'
data_root = 'data/TowerVoc/' # 改为自己的数据集文件夹
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(640, 640), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(640, 640),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=4, # 这里改成自己的batch_size 其实对于ssd这个网络来说改不改无所谓
workers_per_gpu=2, # 但是有些网络不会重写这个参数,所以为了方便最好还是改一下
train=dict(
type='RepeatDataset',
times=3,
dataset=dict(
type=dataset_type,
ann_file=data_root + 'VOC2012/ImageSets/Main/train.txt', # 修改路径
img_prefix=data_root + 'VOC2012/',
pipeline=train_pipeline)),
val=dict(
type=dataset_type,
ann_file=data_root + 'VOC2012/ImageSets/Main/val.txt', # 修改路径
img_prefix=data_root + 'VOC2012/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'VOC2012/ImageSets/Main/test.txt', # 修改路径
img_prefix=data_root + 'VOC2012/',
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='mAP')
大家自己改完之后,可以print_config看看参数是否符合要求。
除了上面的之外,还需要修改下面两个文件:
anaconda3\envs\conda_env_name\lib\python3.7\site-packages\mmdet\core\evaluation\class_names.pyanaconda3\envs\conda_env_name\lib\python3.7\site-packages\mmdet\datasets\voc.py
把类别改成自己的类别:
voc.py
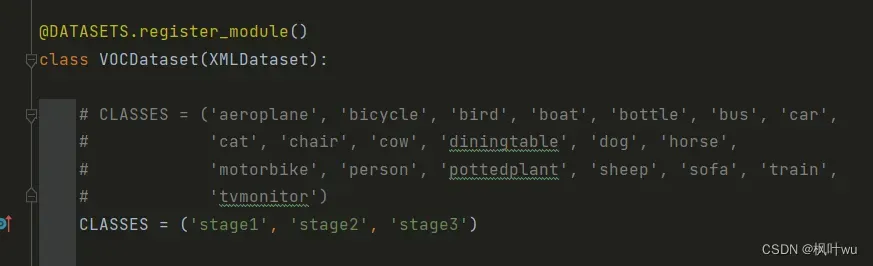
class_names.py
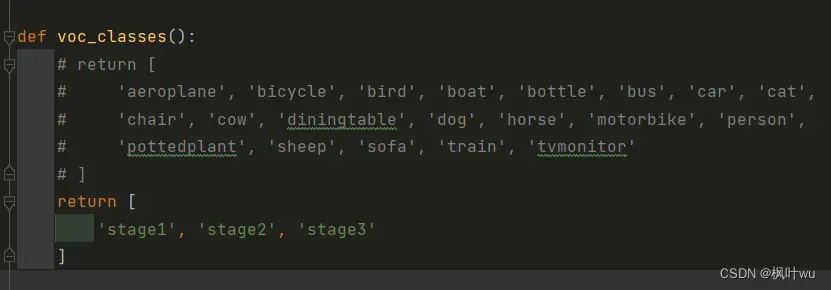
这里要注意,修改项目目录下的mmdet中的代码是没用的。上面安装环境的时候我们有一步是pip install mmdet,我们使用的mmdet实际上是python库,而不是项目下的mmdet,所以如果你要训练的数据类别与PASCAL VOC数据集不同,你需要修改上面两个文件。其实最好的方式当然是针对自己的数据集新建一个py文件,但那样会很麻烦。
码字不易,如果对你有帮助还请点个赞~
文章出处登录后可见!