视频网站常规处理方法:
用户上传视频–>转码(处理视频)–>切片处理(把单个文件进行拆分,一般把拆分好的文件放到M3U8、txt、json的文本中),用户在拖动进度条时则进入到某个分片中。
需要一个文件记录:
1.视频播放顺序。
2.视频存放路径。
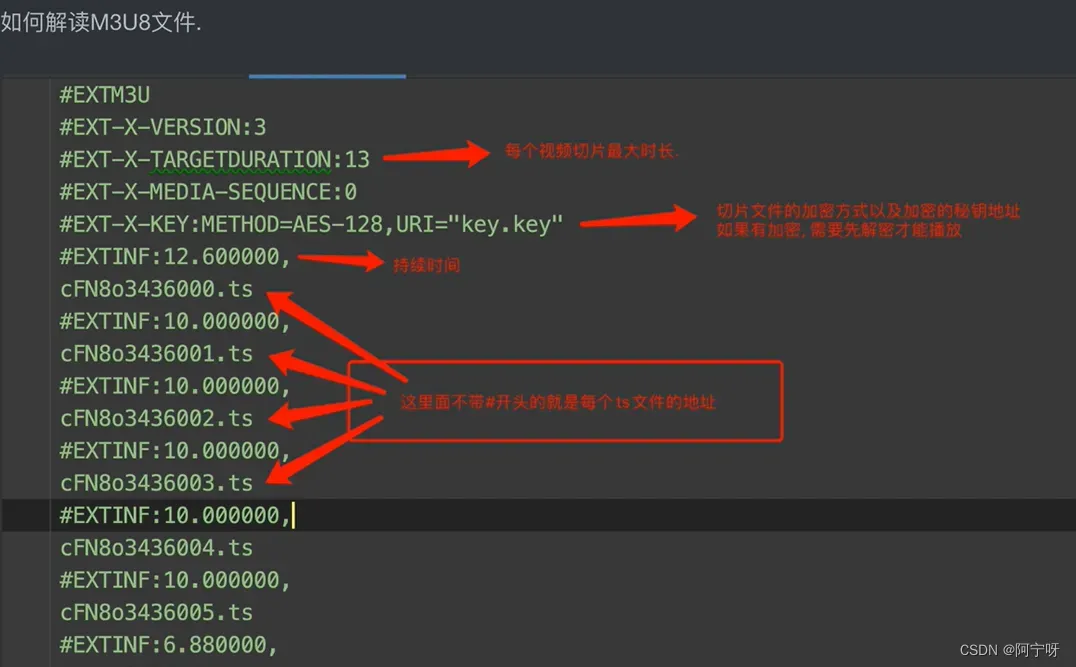
1 爬取m3u8,简单版
抓取视频的方法:
1.找到M3U8文件(可能会被隐藏)。
2.通过M3U8下载ts文件。
3.可以通过各种手段(可以为非编程手段)把ts文件合并为一个mp4文件。
#爬取影院,简单版
import requests
import re
import asyncio
import aiohttp
import aiofiles
import os
from tqdm import tqdm
#ts文件所在的地址
url = 'm3u8文件的url'
ulrMain = url.rsplit('/', 1)[0]
async def getM3U8(url):
resp = requests.get(url)
resp.encoding = "utf-8"
obj = re.compile(r',(?P<ts>.*?)#',re.S)
tsList = obj.finditer(resp.text)
resp.close()
tasks = []
for ts in tsList:
ts = ts.group("ts").strip()
tasks.append(asyncio.create_task(getTsFile(ts)))
await asyncio.wait(tasks)
async def getTsFile(ts):
tsUrl = ulrMain + '/' + ts
async with aiohttp.ClientSession() as session:
async with session.get(tsUrl) as resp:
async with aiofiles.open('attachment/kuangbiao/' + ts, mode='wb') as f:
await f.write(await resp.content.read())
print(ts," ok!")
def get_video():
files = os.listdir('attachment/kuangbiao/')
for file in tqdm(files, desc="正在转换视频格式:"):
if os.path.exists('attachment/kuangbiao/' + file):
with open('attachment/kuangbiao/' + file, 'rb') as f1:
with open('attachment/kuangbiao/' + "第一集.mp4", 'ab') as f2:
f2.write(f1.read())
else:
print("失败")
if __name__ == '__main__':
# asyncio.run(getM3U8(url))
get_video()
2 爬取m3u8,复杂版
思路:
1.拿到主页的页面源代码,找到iframe
iframe 元素会创建包含另外一个文档的内联框架(即行内框架),即在一个html中通过iframe标签可以引入另外的html。取iframe里的src可以得到视频播放的html,在sources中由页面源代码。
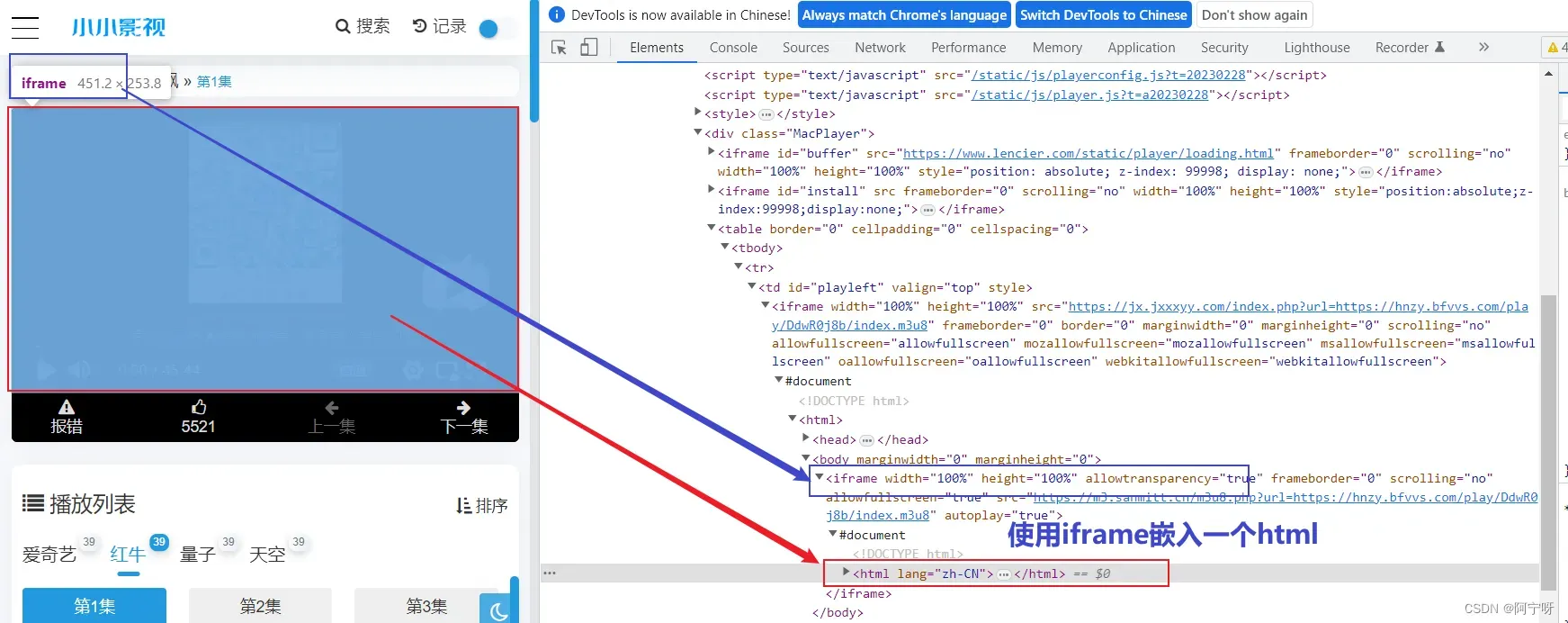
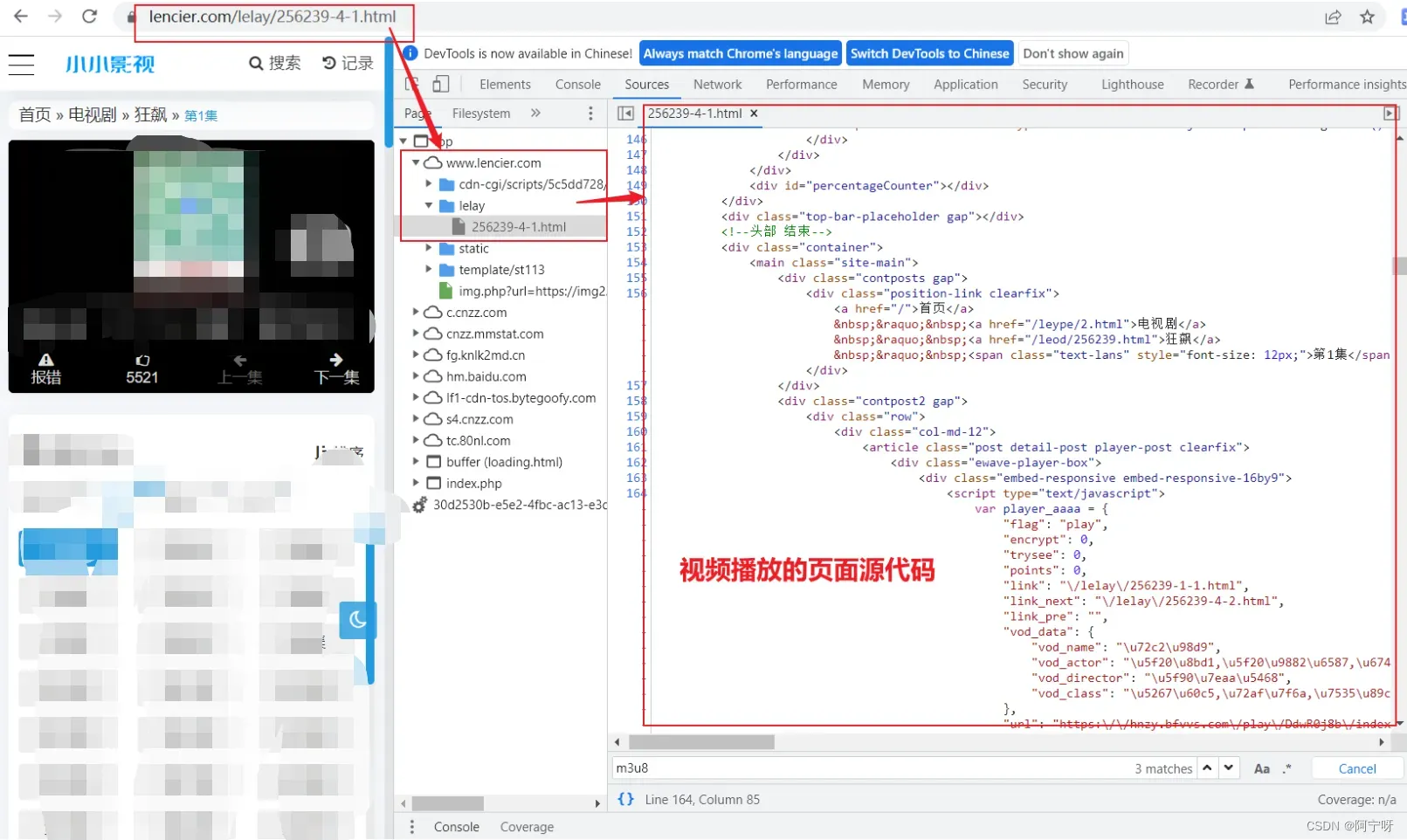
2.从iframe的页面源代码中拿到m3u8文件。
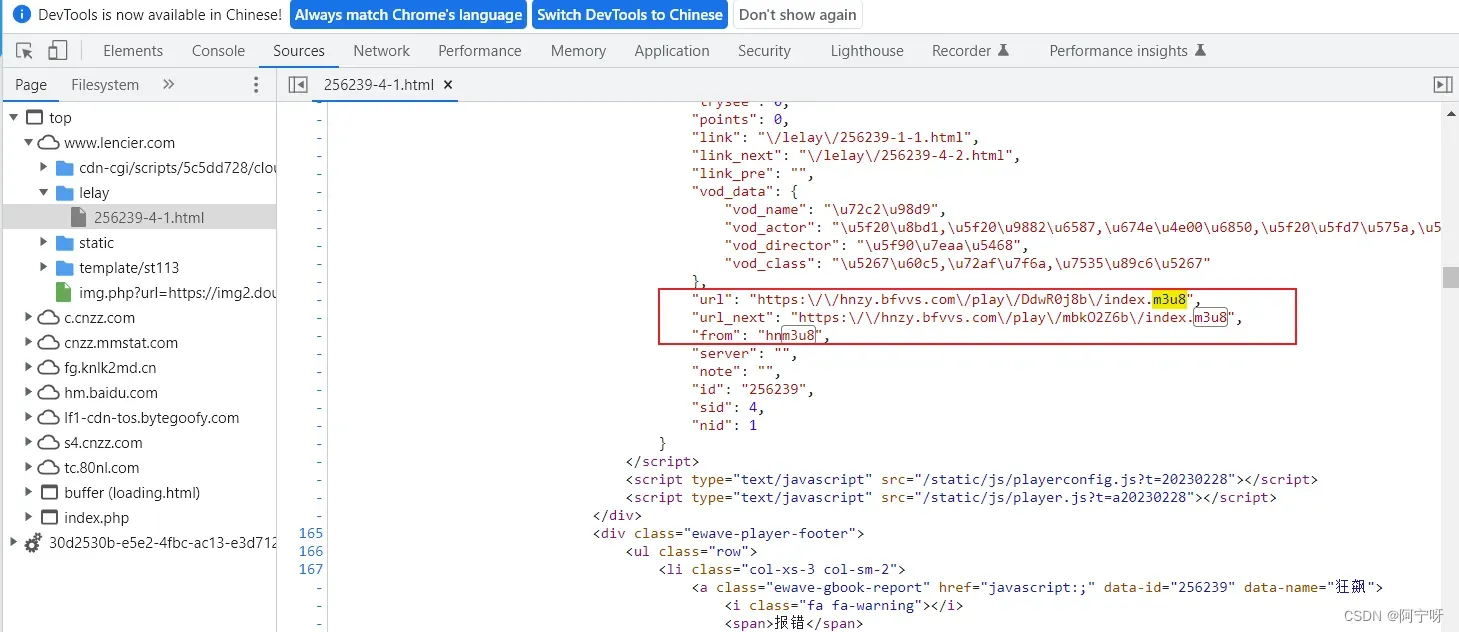
3.下载第一层m3u8文件–>下载第二层m3u8文件(视频存放路径)
4.下载视频即ts文件
5.下载密钥,进行解密
6.合并所有的ts文件为一个mp4文件
#爬取视频(复杂版)
"""
思路:
1.拿到主页的页面源代码,找到iframe
2.从iframe的页面源代码中拿到m3u8文件
3.下载第一层m3u8文件-->下载第二层m3u8文件(视频存放路径)
4.下载视频即ts文件
5.下载密钥,进行解密
6.合并所有的ts文件为一个mp4文件
"""
import requests
import re
import asyncio
import aiohttp
import aiofiles
import os
from tqdm import tqdm
from concurrent.futures import ThreadPoolExecutor
from Cryptodome.Cipher import AES
import brotli
async def getMainM3u8Url(url):
resp = requests.get(url)
with open("attachment/page.txt","wb","utf-8") as f:
f.write(resp.text)
print(resp.text)
obj = re.compile('var player_aaaa=.*?"url":"(?P<indexUrl>.*?)","url_next":"(?P<nextUrl>.*?)","from"',re.S)
urlList = obj.search(resp.text)
resp.close()
indexUrl = str(urlList.group("indexUrl")).replace("\\",'')
print(indexUrl)
return indexUrl
async def getM3u8Key(indexUrl):
async with aiofiles.open("attachment/狂飙第一集m3u8.txt", "r") as f:
async for line in f:
if line.startswith("#EXT-X-KEY:"):
keyUrl = str(line).split('"',2)[1]
print(keyUrl)
break
#'Accept - Encoding': 'gzip, deflate, br',
headers = {
'Accept': '* / *',
'Accept - Language': 'zh - CN, zh;q = 0.9',
'Cache - Control': 'no - cache',
'Connection': 'keep - alive',
'Host': 'hnzy.bfvvs.com',
'Origin': 'https: // m3.sanmitt.cn',
'Pragma': 'no - cache',
'sec - ch - ua': '"Chromium";v = "110", "Not A(Brand";v = "24", "Google Chrome";v = "110"',
'sec - ch - ua - mobile': '?0',
'sec - ch - ua - platform': '"Windows"',
'Sec - Fetch - Dest': '"empty"',
'Sec - Fetch - Mode': '"cors"',
'Sec - Fetch - Site': '"cross - site"',
'User - Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
resp = requests.get(keyUrl,headers = headers)
return resp.content
async def getM3u8File(indexUrl):
resp = requests.get(indexUrl)
resp.encoding = "utf-8"
async with aiofiles.open("attachment/狂飙第一集m3u8.txt","wb") as f1:
await f1.write(resp.content)
resp.close()
tasks = []
async with aiohttp.ClientSession() as session: #提前创建一个session,就不需要每下载一个ts文件都需要创建
async with aiofiles.open("attachment/狂飙第一集m3u8.txt","r") as f2:
async for line in f2:
if line.startswith("#"):
continue
tsUrl = line.strip()
print(tsUrl)
tasks.append(asyncio.create_task(getTsFile(tsUrl,session)))
await asyncio.wait(tasks)
async def getTsFile(tsUrl,session):
name = tsUrl.split("-",1)[1]
async with session.get(tsUrl) as resp:
async with aiofiles.open('attachment/second/' + name, mode='wb') as f:
await f.write(await resp.content.read())
print(name," ok!")
async def decodeTs(key):
tasks = []
async with aiofiles.open("attachment/狂飙第一集m3u8.txt", "r") as f2:
async for line in f2:
if line.startswith("#") or line.startswith(" "):
continue
name = (line.strip()).split("-",1)[1]
# print(name)
# 开始创建异步任务
tasks.append(asyncio.create_task(decodeByKey(name, key)))
await asyncio.wait(tasks)
async def decodeByKey(fileName, key):
#解密,在M38U文件中可以看到加密方式为AES
aes = AES.new(key=key, mode=AES.MODE_CBC, IV=b"0000000000000000")
async with aiofiles.open(f"attachment/second/{fileName}","rb") as f1:
async with aiofiles.open(f"attachment/first/temp_{fileName}","wb") as f2:
bs = await f1.read()
await f2.write(aes.decrypt(bs))
print(f"{fileName} is ok")
async def get_video():
files = os.listdir('attachment/first/')
for file in tqdm(files, desc="正在转换视频格式:"):
if os.path.exists('attachment/first/' + file):
async with aiofiles.open('attachment/first/' + file, 'rb') as f1:
async with aiofiles.open('attachment/first/' + "第二集.mp4", 'ab') as f2:
await f2.write(await f1.read())
else:
print("失败")
async def main(url):
indexUrl = 'm3u8文件的url'
# 1.拿到主页的页面源代码,找到iframe
# 2.从iframe的页面源代码中拿到m3u8文件
# indexUrl = await getMainM3u8Url(url)
# 3.下载第一层m3u8文件 -->下载第二层m3u8文件(视频存放路径)
# await getM3u8File(indexUrl)
# 4.下载视频即ts文件
# 5.下载密钥,进行解密
key = await getM3u8Key(indexUrl)
await decodeTs(key)
# 6.合并所有的ts文件为一个mp4文件
await get_video()
if __name__ == '__main__':
url = '视频网页地址'
asyncio.run(main(url))
文章出处登录后可见!
已经登录?立即刷新