一、关键概念
相比V1 移除了database 和 RP,增加了bucket。
V2具有以下几个概念:
timestamp、field key、field value、field set、tag key、tag value、tag set、measurement、series、point、bucket、bucket schema、organization
新增的概念:
bucket:所有 InfluxDB 数据都存储在一个存储桶中。一个桶结合了数据库的概念和存储周期(时间每个数据点仍然存在持续时间)。一个桶属于一个组织
bucket schema:具有明确的schema-type的存储桶需要为每个度量指定显式架构。测量包含标签、字段和时间戳。显式模式限制了可以写入该度量的数据的形状。
organization:InfluxDB组织是一组用户的工作区。所有仪表板、任务、存储桶和用户都属于一个组织。
二、系统结构
数据模式:InfluxDB数据元素存储在时间结构合并树 (TSM)和时间序列索引 (TSI)文件中,以有效压缩存储的数据。
默认路径:
| Engine path | ~/.influxdbv2/engine/ | InfluxDB 存储时序数据的位置 |
|---|---|---|
| Bolt path | ~/.influxdbv2/influxd.bolt | 非时间序列数据的基于文件的键值存储 |
| Configs path | ~/.influxdbv2/configs | 配置文件(configs) 的文件路径 |
文件目录结构:
~/.influxdbv2/
- engine/
- data/
- TSM directories and files
- wal/
- WAL directories and files
- data/
- configs
- influxd.bolt
Influxdb分片和分片组
InfluxDB在将数据存储到磁盘时将时间序列数据组织成分片。分片被分组到分片组中
表示具有4d 保留期 和1d 分片组持续时间的存储桶:
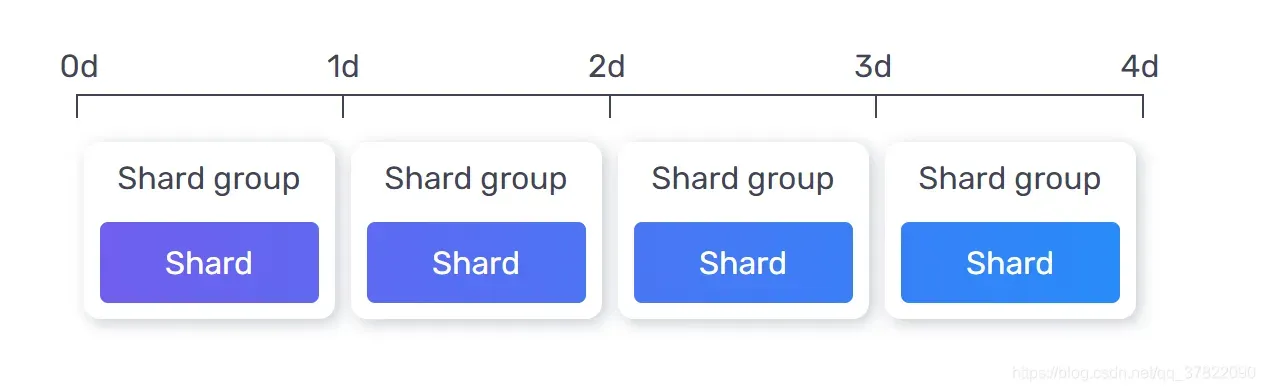
分片删除:InfluxDB保留强制执行服务会例行检查早于其存储桶保留期的分片组。一旦分片组的开始时间超过存储桶的保留期,InfluxDB 将删除该分片组以及关联的分片和 TSM 文件(在具有无限保留期的存储桶中,分片无限期地保留在磁盘上)。
系统存储桶
_monitoring system bucket : 该_monitoring系统桶存储InfluxDB数据用于 监控数据并发送警报。数据保留:7天
_tasks system bucket: 该_tasks系统桶存储与数据InfluxDB任务的执行。数据保留:1天
标签和字段描述详见:https://docs.influxdata.com/influxdb/v2.0/reference/internals/system-buckets/
三、配置文件
当influxd启动时,它会在当前工作目录检查一个名为config.*的文件。
支持以下语法:
- YAML (.yaml, .yml)
- TOML (.toml)
- JSON (.json)
配置选项(日志、并发压缩…):https://docs.influxdata.com/influxdb/v2.0/reference/config-options/
四、Flux查询语句
Flux 是 InfluxData 的功能性数据脚本语言,设计用于查询、分析和处理数据,它是InfluxQL 和其他类似 SQL 的查询语言的替代品。
设计原则:受Javascript 启发,旨在设计出可用、可读、灵活、可组合、可测试、可贡献和可共享的语言。
示例查询:近一小时存储的数据,按cpu度量和cpu=cpu-total标签过滤,以 1 分钟为间隔对数据进行窗口化,并计算每个窗口的平均值
from(bucket:"example-bucket")
|> range(start:-1h)
|> filter(fn:(r) =>
r._measurement == "cpu" and
r.cpu == "cpu-total"
)
|> aggregateWindow(every: 1m, fn: mean)
1>关键概念
Pipe-forward operator (管道转发操作符” |> “):Flux广泛使用管道转发运算符 “|>” 将操作链接在一起。在每个函数或操作之后,Flux 返回一个包含数据的表或表的集合。管道转发运算符将这些表通过管道输送到下一个函数或操作中,在那里它们将被进一步处理或操作。
Tables :Flux 构造表格中的所有数据。当数据从数据源流式传输时,Flux 将其格式化为带注释的逗号分隔值 (CSV),表示表格。然后函数操作或处理它们并输出新表。
Group keys :每个表都有一个组键(Group keys),用于描述表的内容。它是一个列列表,表中的每一行都具有相同的值。每行中具有唯一值的列不是组键的一部分。
示例 group key
Group key: [_start, _stop, _field]
_start:time _stop:time _field:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ------------------------------ ----------------------------
2019-04-25T17:33:55.196959000Z 2019-04-25T17:34:55.196959000Z used_percent 2019-04-25T17:33:56.000000000Z 65.55318832397461
2019-04-25T17:33:55.196959000Z 2019-04-25T17:34:55.196959000Z used_percent 2019-04-25T17:34:06.000000000Z 65.52391052246094
2019-04-25T17:33:55.196959000Z 2019-04-25T17:34:55.196959000Z used_percent 2019-04-25T17:34:36.000000000Z 65.536737442016
注意:_time和_value被排除在示例组键之外,它们对于每一行都是唯一的。
2>查询语法
https://docs.influxdata.com/influxdb/v2.0/query-data/get-started/query-influxdb/
指定数据源:from(bucket:"example-bucket")
指定时间范围:
使用管道转发运算符 ( |>) 将数据从数据源通过管道传输到range() 函数,该函数指定查询的时间范围。它接受两个参数:start和stop。范围可以是使用相对负持续时间 或使用绝对时间
// Relative time range with start only. Stop defaults to now.
from(bucket:"example-bucket")
|> range(start: -1h)
// Relative time range with start and stop
from(bucket:"example-bucket")
|> range(start: -1h, stop: -10m)
//使用绝对时间
from(bucket:"example-bucket")
|> range(start: 2018-11-05T23:30:00Z, stop: 2018-11-06T00:00:00Z)
//过去十五分钟的数据
from(bucket:"example-bucket")
|> range(start: -15m)
3>数据过滤:
将范围数据传递到filter()函数中,以根据数据属性或列缩小结果范围。该filter()函数有一个参数 ,fn它需要一个匿名函数,该函数具有基于列或属性过滤数据的逻
// Pattern
(r) => (r.recordProperty comparisonOperator comparisonExpression)
// Example with single filter
(r) => (r._measurement == "cpu")
// Example with multiple filters
(r) => (r._measurement == "cpu") and (r._field != "usage_system" )
//按cpu度量、usage_system字段和cpu-total标记值过滤
from(bucket:"example-bucket")
|> range(start: -15m)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system" and
r.cpu == "cpu-total"
)
4>生成指定查询数据
Flux 的yield()函数将过滤后的表作为查询结果输出。
Flux 会yield()在每个脚本的末尾自动假设一个函数,以便输出和可视化数据。yield()只有在同一个 Flux 查询中包含多个查询时,才需要显式调用。每组返回的数据都需要使用该yield()函数命
from(bucket:"example-bucket")
|> range(start: -15m)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system" and
r.cpu == "cpu-total"
)
|> yield()
5>数据转换
使用函数,将数据聚合为平均值、下采样数据等
//更新范围从最后一小时拉取数据
from(bucket:"example-bucket")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system" and
r.cpu == "cpu-total"
)
//以五分钟为间隔的窗口化数据
from(bucket:"example-bucket")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system" and
r.cpu == "cpu-total"
)
|> window(every: 5m)
//聚合窗口数据
from(bucket:"example-bucket")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system" and
r.cpu == "cpu-total"
)
|> window(every: 5m)
|> mean()
//添加时间列到聚合函数
from(bucket:"example-bucket")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system" and
r.cpu == "cpu-total"
)
|> window(every: 5m)
|> mean()
|> duplicate(column: "_stop", as: "_time")
//取消窗口聚合表,将所有点收集到一个无限的窗口中
from(bucket:"example-bucket")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system" and
r.cpu == "cpu-total"
)
|> window(every: 5m)
|> mean()
|> duplicate(column: "_stop", as: "_time")
|> window(every: inf)
//辅助函数(将聚合或选择器函数应用于固定的时间窗口,通过every指定窗口的持续时间)
from(bucket:"example-bucket")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system" and
r.cpu == "cpu-total"
)
|> aggregateWindow(every: 5m, fn: mean)
6>语法基础与通量函数
语法基础:https://docs.influxdata.com/influxdb/v2.0/query-data/get-started/syntax-basics/
通量函数包:https://docs.influxdata.com/influxdb/v2.0/reference/flux/stdlib/
比如:mean()函数对每个时间窗口内的值求平均值(https://docs.influxdata.com/influxdb/v2.0/reference/flux/stdlib/built-in/transformations/aggregates/mean/)
五、可视化数据
https://docs.influxdata.com/influxdb/v2.0/visualize-data/visualization-types/
支持的可视化类型:
Band (乐队):显示随时间变化的数据组的上限和下限
guage(仪表盘):仪表视图中显示时间序列的单个值最新值
graph(图形):折线图
Graph + Single Stat(图表+单一统计):以折线图显示指定的时间序列,并将最近的单个值叠加为一个大数值
heatmap(热图):显示 x 和 y 轴上的数据分布,其中颜色代表不同的数据点浓度
histogram(直方图):一种查看数据分布的方法。y 轴专用于计数,x 轴分为 bin
mosaic(马赛克):化显示时间序列数据中的状态变化
scatter(散点图):视图使用散点图来显示时间序列数据
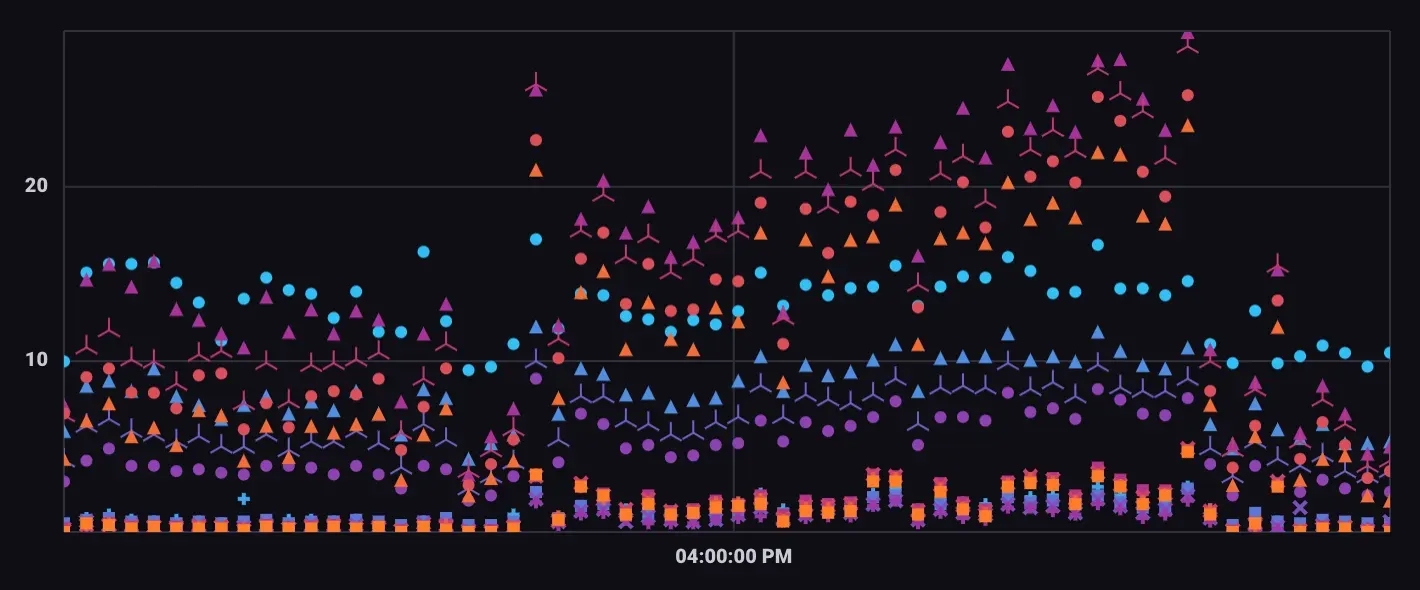
single stat(单项统计): 将指定时间序列的最新值显示为数值

table(表格视图):表格视图中显示查询结果
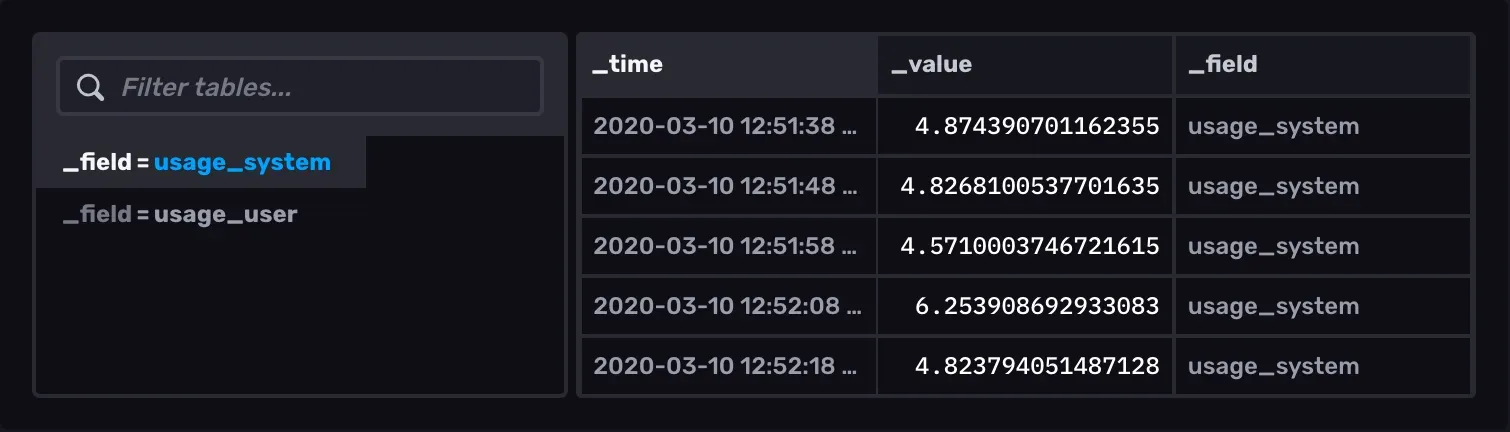
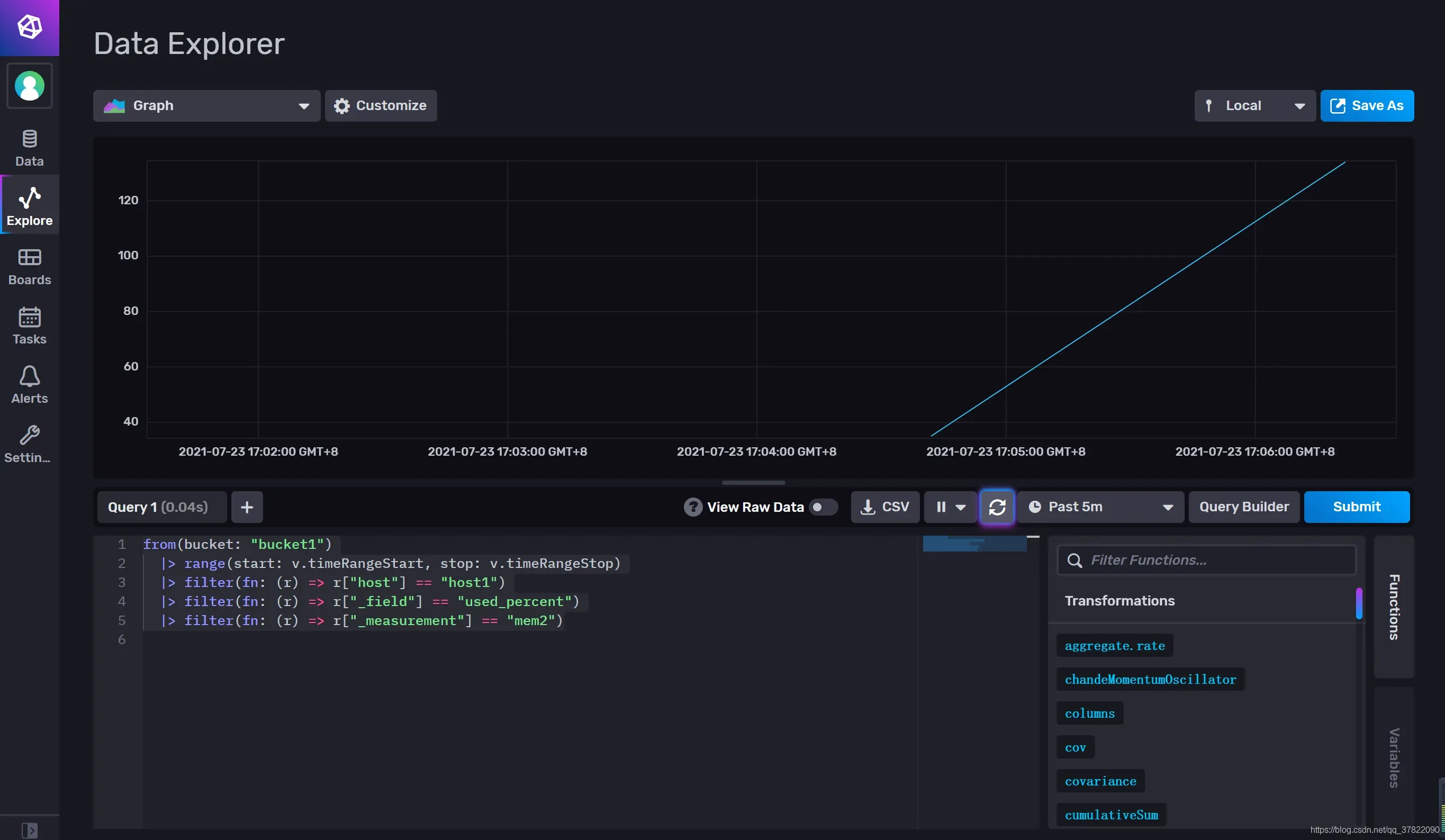
本地制造数据,通过图表数据展示案例:
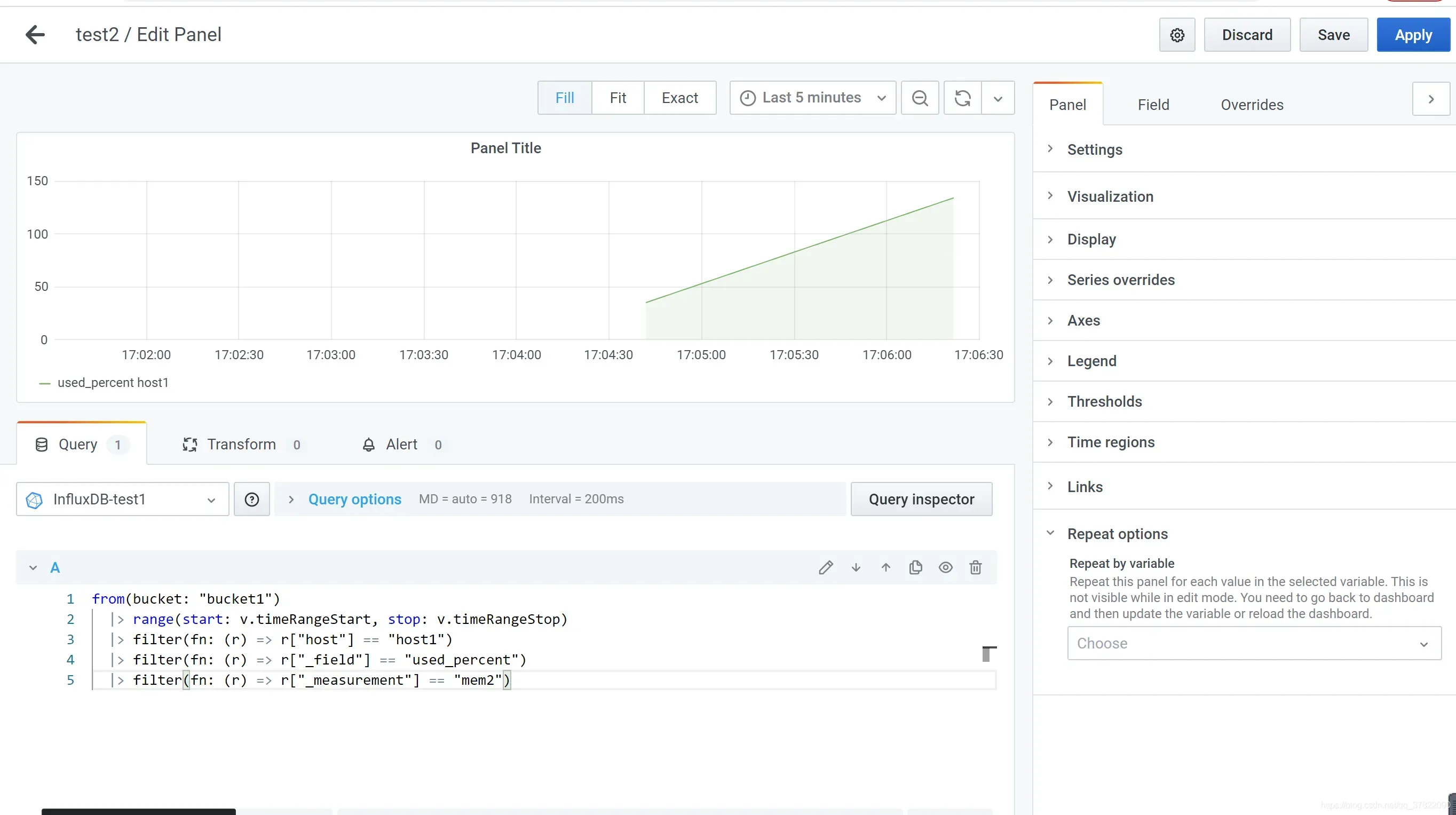
grafana集成数据展示:
结论:
- influxdb控制台提供接入sdk源码,可直接在代码中使用,其他模块可直接在界面操作influxdb,使用体验较好
- influxdb可视化图表数量有限,如果图表无法满足需求,可以选择使用grafana展示数据,总体感觉grafana使用起来更舒适,数据显示更清晰
- flux刚开始不会写,通过控制台操作图表选择属性或函数,可以生成简单的flux语句
附录
官网地址:https://docs.influxdata.com/influxdb/v2.0/
文章出处登录后可见!