大家好,我是微学AI,今天给大家介绍一下人工智能任务1-【NLP系列】句子嵌入的应用与多模型实现方式。句子嵌入是将句子映射到一个固定维度的向量表示形式,它在自然语言处理(NLP)中有着广泛的应用。通过将句子转化为向量表示,可以使得计算机能够更好地理解和处理文本数据。
本文采用多模型实现方式词嵌入,包括:Word2Vec 、Doc2Vec、BERT模型,将其应用于句子嵌入任务。这些预训练模型通过大规模的无监督学习从海量文本数据中学习到了丰富的语义信息,并能够产生高质量的句子嵌入。
目录
- 引言
- 项目背景与意义
- 句子嵌入基础
- 实现方式
- Word2Vec
- Doc2Vec
- BERT
- 项目实践与代码
- 数据预处理
- 句子嵌入实现
- 总结
- 参考资料
引言
随着人工智能和大数据的发展,自然语言处理(NLP)在许多领域得到了广泛应用,如搜索引擎,推荐系统,自动翻译等。其中,句子嵌入是NLP的关键技术之一,它可以将自然语言的句子转化为计算机可以理解的向量,从而使机器可以处理和理解自然语言。本文将详细介绍句子嵌入在NLP中的应用项目,以及几种常见的中文文本句子嵌入的实现方式。
项目背景与意义
在自然语言处理中,将句子转化为向量的过程称为句子嵌入。这是因为计算机不能直接理解自然语言,而是通过处理数值数据(例如向量)来实现。句子嵌入可以捕捉句子的语义信息,帮助机器理解和处理自然语言。
句子嵌入的应用项目广泛,如情感分析,文本分类,语义搜索,机器翻译等。例如,在情感分析中,句子嵌入可以将文本转化为向量,然后通过机器学习模型来预测文本的情感。在机器翻译中,句子嵌入可以帮助机器理解源语言的句子,并将其转化为目标语言的句子。
句子嵌入的应用主要包括以下几个方面:
文本分类/情感分析:句子嵌入可以用于文本分类任务,如将电影评论分为正面和负面情感。基于句子嵌入的模型能够学习到句子的语义信息,并将其应用于情感分类。
语义相似度:通过计算句子嵌入之间的相似度,可以衡量句子之间的语义相似性。这在问答系统、推荐系统等任务中非常有用,可以帮助找到与输入句子最相关的其他句子。
机器翻译:句子嵌入可以用于机器翻译任务中的句子对齐和翻译建模。通过将源语言句子和目标语言句子编码成嵌入向量,可以捕捉句子之间的对应关系和语义信息,从而提高翻译质量。
句子生成:利用预训练的语言模型和句子嵌入,可以生成连贯、语义正确的句子。句子嵌入可以作为生成任务的输入,保证生成的句子与输入的上下文相关。
信息检索/相似句子查找:通过将句子转换为嵌入向量,可以建立索引并进行快速的相似句子查找。这在搜索引擎、知识图谱等领域具有重要应用价值。
句子嵌入基础
句子嵌入是一种将自然语言句子转化为固定长度的实数向量的技术。这个向量能够捕获句子的语义信息,例如句子的主题,情感,语气等。句子嵌入通常是通过神经网络模型学习得到的。这些模型可以是无监督的,如Word2Vec,Doc2Vec,或者是有监督的,如BERT。
实现方式
接下来,我们将介绍三种常见的中文文本句子嵌入的实现方式。
方法一:Word2Vec
Word2Vec是一种常见的词嵌入方法,它可以将词语转化为向量。这种方法的思想是,将一个句子中的所有词向量取平均,得到句子的向量。
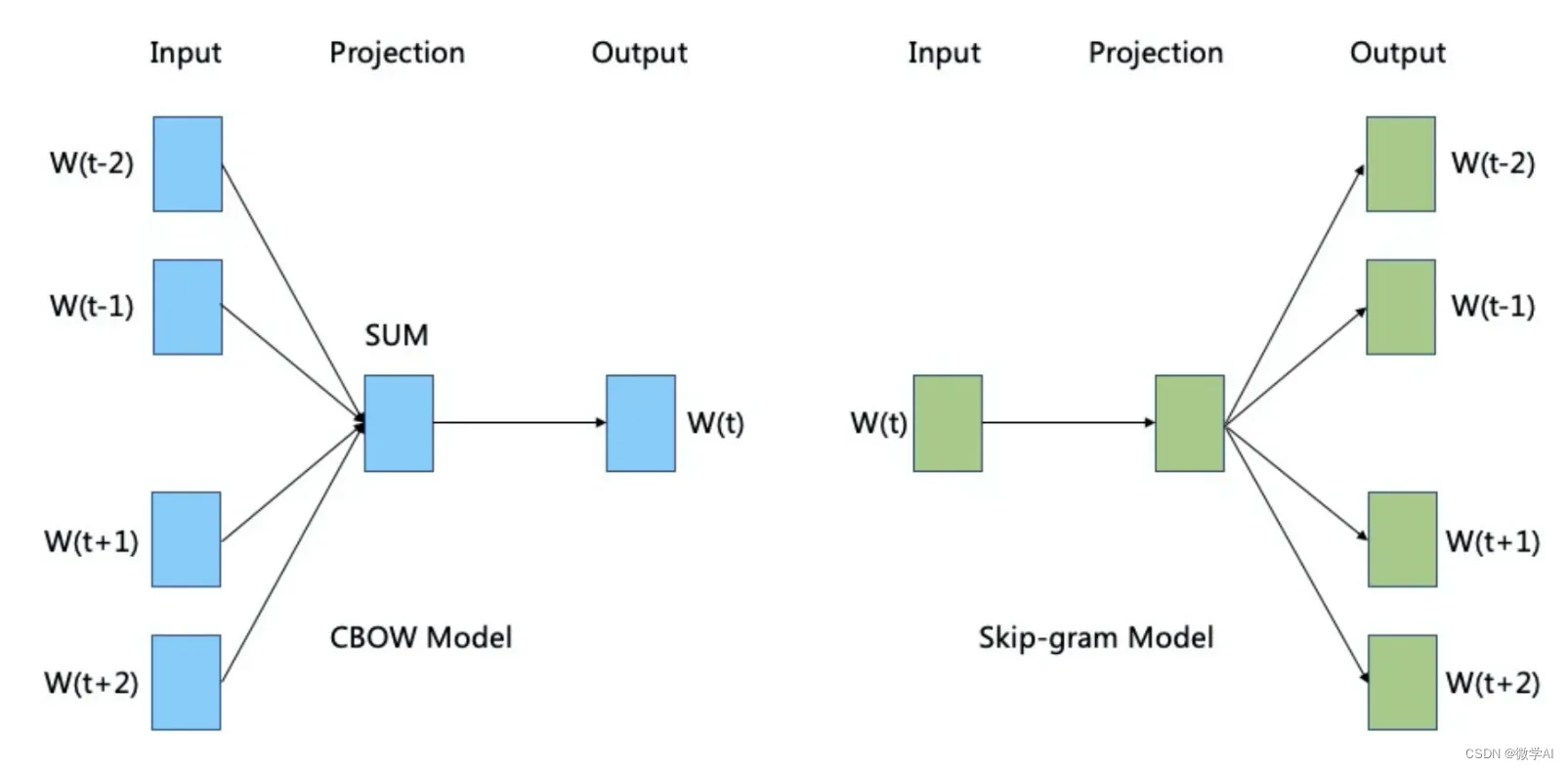
Word2Vec 有两种实现方式:CBOW(Continuous Bag-of-Words)和Skip-gram。
CBOW 模型旨在根据上下文预测中心词,而 Skip-gram 模型则是根据中心词预测上下文。以下是这两种模型的基本数学原理:
CBOW 模型:
假设我们有一个中心词 ,并且上下文窗口大小为
,则上下文词可以表示为
。
CBOW 模型试图根据上下文词来预测中心词,其目标是最大化给定上下文条件下中心词的条件概率。
具体而言,CBOW 模型通过将上下文词的词向量进行平均或求和,得到上下文表示 。然后,将上下文表示
输入到一个隐藏层中,并通过一个非线性函数(通常是 sigmoid 函数)得到隐藏层的输出
。最后,将隐藏层的输出与中心词
相关的 one-hot 编码表示进行比较,并使用 softmax 函数得到每个词的概率分布
。模型的目标是最大化实际中心词的对数概率:
。
Skip-gram 模型:
Skip-gram 模型与 CBOW 模型相反,它试图根据中心词预测上下文词。
具体而言,Skip-gram 模型将中心词 的词向量
输入到隐藏层,并通过一个非线性函数得到隐藏层的输出
。然后,将隐藏层的输出与上下文词
相关的 one-hot 编码表示依次比较,并使用 softmax 函数得到每个词的概率分布
。模型的目标是最大化实际上下文词的对数概率:
。
在实际训练过程中,Word2Vec 使用负采样(negative sampling)来近似 softmax 函数的计算,加快模型的训练速度,并取得更好的性能。
希望上述使用 LaTeX 输出的数学表示对您有所帮助!
方法二:Doc2Vec
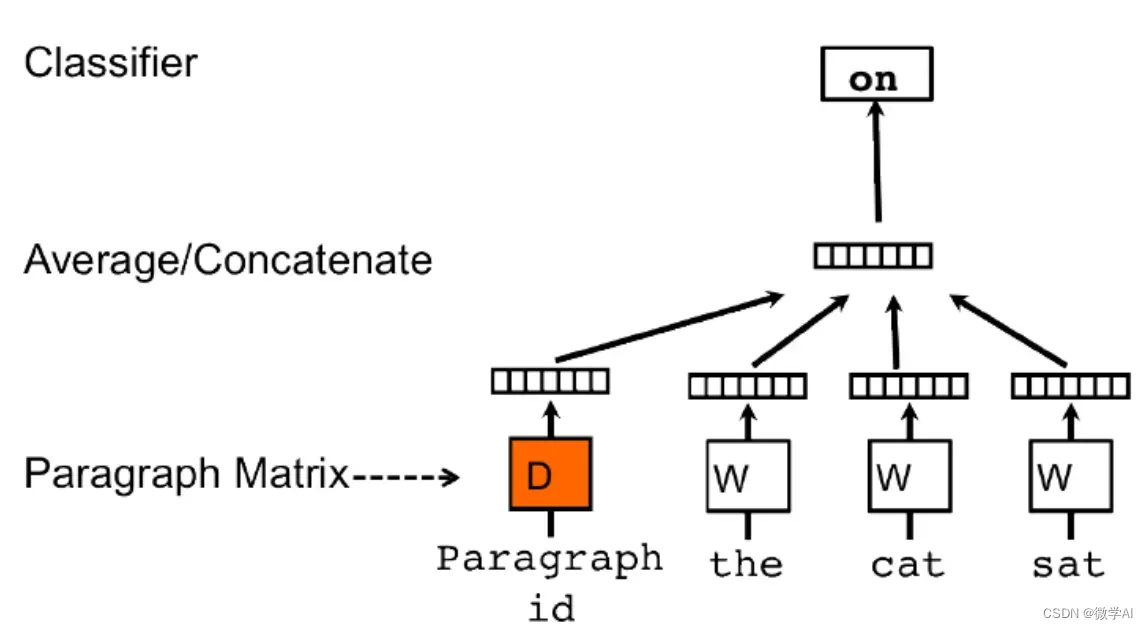
Doc2Vec是一种直接获取句子向量的方法,它是Word2Vec的扩展。Doc2Vec不仅考虑词语的上下文关系,还考虑了文档的全局信息。
假设我们有一个包含N个文档的语料库,每个文档由一系列单词组成。Doc2Vec的目标是为每个文档生成一个固定长度的向量表示。
Doc2Vec使用了两种不同的模型来实现这一目标:分别是PV-DM和PV-DBOW。
对于PV-DM模型,在训练过程中,每个文档被映射到一个唯一的向量(paragraph vector),同时也将每个单词映射到一个向量。在预测阶段,模型输入一部分文本(可能是一个或多个单词)并尝试预测缺失部分文本(通常是一个单词)。模型的损失函数基于预测和真实值之间的差异进行计算,然后通过反向传播来更新文档和单词的向量表示。
对于PV-DBOW模型,它忽略了文档内单词的顺序,只关注文档的整体表示。在该模型中,一个文档被映射到一个向量,并且模型的目标是通过上下文单词的信息预测该文档。同样地,模型使用损失函数和反向传播来更新文档和单词的向量表示。
总体而言,Doc2Vec通过将每个文档表示为固定长度的向量来捕捉文档的语义信息。这些向量可以用于度量文档之间的相似性、聚类文档或作为其他任务的输入。
使用数学符号描述Doc2Vec的具体细节,可以参考以下公式:
PV-DM模型:
- 输入:一个文档d,由单词序列
组成,其中
是文档中的单词数。
- 文档向量:
,表示文档d的向量表示。
- 单词向量:每个单词
都有一个对应的向量表示
- 预测:给定输入部分文本
,模型尝试预测缺失文本
。
- 损失函数:使用交叉熵或其他适当的损失函数计算预测值与真实值之间的差异。
- 训练:通过反向传播和梯度下降算法更新文档向量和单词向量。
PV-DBOW模型:
- 输入:一个文档d,由单词序列
- 文档向量:
,表示文档d的向量表示。
- 单词向量:每个单词
- 预测:给定一个文档d,模型尝试预测与该文档相关的上下文单词。
- 损失函数:使用交叉熵或其他适当的损失函数计算预测值与真实值之间的差异。
- 训练:通过反向传播和梯度下降算法更新文档向量和单词向量。
方法三:BERT
BERT是一种基于Transformer的深度学习模型,它可以获取到句子的深层次语义信息。
BERT模型的数学原理基于两个关键概念:MLM和NSP。
首先,我们将输入文本序列表示为一系列的词向量,并且为每个词向量添加相对位置编码。然后,通过多次堆叠的Transformer层来进行特征抽取。
在MLM阶段,BERT会对输入序列中的一部分词进行随机掩码操作,即将这些词的嵌入向量替换为一个特殊的标记 “[MASK]”。然后,模型通过上下文上下文预测这些被掩码的词。
在NSP阶段,BERT会将两个句子作为输入,并判断它们是否是原始文本中的连续句子。这个任务旨在帮助模型学习到句子级别的语义信息。
具体而言,BERT模型的数学原理包括以下几个步骤:
- 输入嵌入层:输入是一系列的词语索引,将其映射为词向量表示。
- 位置编码:为每个输入添加相对位置编码,以便模型能够理解词语之间的顺序关系。
- Transformer层:通过多次堆叠的Transformer层进行特征抽取,每层由多头自注意力机制和前馈神经网络组成。
- Masked Language Model(MLM):对输入序列中的一部分词进行掩码,并通过上下文预测这些被掩码的词。
- Next Sentence Prediction(NSP):将两个句子作为输入,判断它们是否是原始文本中的连续句子。
项目实践与代码
接下来,我们将通过一个例子来展示如何实现中文文本的句子嵌入。我们将使用Python语言和相关的NLP库(如gensim,torch,transformers等)来完成。
数据预处理
首先,我们需要对数据进行预处理,包括分词,去除停用词等。以下是一个简单的数据预处理代码示例:
import jieba
def preprocess_text(text):
# 使用jieba进行分词
words = jieba.cut(text)
# 去除停用词
stop_words = set(line.strip() for line in open('stop_words.txt', 'r', encoding='utf-8'))
words = [word for word in words if word not in stop_words]
return words
句子嵌入实现
接下来,我们将展示如何使用上述的三种方法来实现句子嵌入。
方法一:Word2Vec + 文本向量平均
from gensim.models import Word2Vec
def sentence_embedding_word2vec(sentences, size=100, window=5, min_count=5):
# 训练Word2Vec模型
model = Word2Vec(sentences, size=size, window=window, min_count=min_count)
# 对每个句子的词向量进行平均
sentence_vectors = []
for sentence in sentences:
vectors = [model.wv[word] for word in sentence if word in model.wv]
sentence_vectors.append(np.mean(vectors, axis=0))
return sentence_vectors
方法二:Doc2Vec
from gensim.models import Doc2Vec
from gensim.models.doc2vec import TaggedDocument
def sentence_embedding_doc2vec(sentences, vector_size=100, window=5, min_count=5):
# 将句子转化为TaggedDocument对象
documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(sentences)]
# 训练Doc2Vec模型
model = Doc2Vec(documents, vector_size=vector_size, window=window, min_count=min_count)
# 获取句子向量
sentence_vectors = [model.docvecs[i] for i in range(len(sentences))]
return sentence_vectors
方法三:BERT
import torch
from transformers import BertTokenizer, BertModel
# 加载预训练的BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
# 输入待转换的句子
sentence = "这是一个示例句子。"
# 使用分词器将句子分成tokens
tokens = tokenizer.tokenize(sentence)
# 添加特殊标记 [CLS] 和 [SEP]
tokens = ['[CLS]'] + tokens + ['[SEP]']
# 将tokens转换为对应的id
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# 创建输入tensor
input_tensor = torch.tensor([input_ids])
# 使用BERT模型获取句子的嵌入向量
with torch.no_grad():
outputs = model(input_tensor)
sentence_embedding = outputs[0][0][0] # 取第一个句子的第一个token的输出作为句子的嵌入向量
# 输出句子的嵌入向量
print(sentence_embedding)
print(sentence_embedding.shape)
总结
本文详细介绍了句子嵌入在NLP中的应用项目,以及几种常见的中文文本句子嵌入的实现方式。我们通过实践和代码示例展示了如何使用Word2Vec + 文本向量平均,Doc2Vec,和BERT来实现句子嵌入。希望本文能够帮助读者更好地理解句子嵌入,并在实际项目中应用句子嵌入技术。
文章出处登录后可见!