1.pth保存模型的说明
.pth文件可以保存模型的拓扑结构和参数,也可以只保存模型的参数,取决于model.save()中的参数。
torch.save(model.state_dict(), 'mymodel.pth') # 只保存模型权重参数,不保存模型结构
torch.save(model, 'mymodel.pth') # 保存整个model的状态
#model为已经训练好的模型
使用方式1得到的.pth重构模型代码如下:
model = My_model(*args, **kwargs)
model.load_state_dict(torch.load('mymodel.pth'))
model.eval()
使用方式2得到的.pth重构模型代码如下:
model=torch.load('mymodel.pth')
model.eval()
2.pth文件load细节
以只保存模型参数的pth为例
epth_encoder = depth.ResnetEncoder(18, False) # 加载encoder模型
loaded_dict_enc = torch.load('depth/models/weights_19/encoder.pth')#数据类型:有序字典
loaded_dict_enc 的类型是:<class ‘odict_items’>(有序字典),本质还是python的字典类型,有键值对,其中键指的是每层网络结构的名字,数据类型是字符串型,值指的是每层网络结构的参数,数据类型是numpy张量。
运行下面这一行代码,可以更加细致的发现pth中含有的信息。
for k, v in loaded_dict_enc.items():
print(k)
print(v)
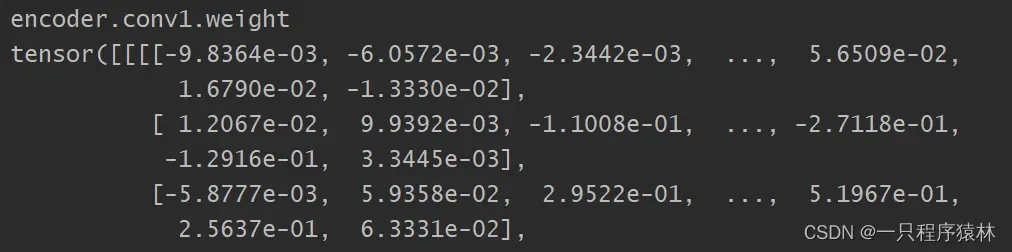
运行结果反映了,第一个键(key)为encoder.conv1.weight即表示encoder模型第一个卷积层的权重。对应的值(values)是下图的张量。这些参数张量都是pth文件中保存的,不会发生变化。
3.state_dict
state_dict是Python的字典对象,可用于保存模型参数、超参数以及优化器的状态信息。需要注意的是,只有具有可学习参数的层(如卷积层、线性层等)才有state_dict。
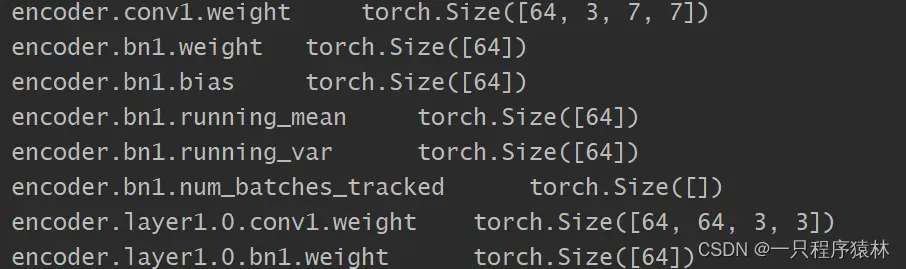
可以用state_dict非常细致的查看网络结构是否正确,能够清晰反映各层滤波器的大小。
for param_tensor in depth_encoder.state_dict():
print(param_tensor, '\t', depth_encoder.state_dict()[param_tensor].size())
4.模型参数读入
filtered_dict_enc = {k: v for k, v in loaded_dict_enc.items() if k in depth_encoder.state_dict()}
depth_encoder.load_state_dict(filtered_dict_enc)
5.eval()
eval()是PyTorch中用来将神经网络设置为评估模式的方法。在评估模式下,网络的参数不会被更新,Dropout和Batch Normalization层的行为也会有所不同。通常在测试阶段使用评估模式。
eval() 可以作为模型推理的性能提升方法,在评估模式下,计算图是不被跟踪的,这样可以节省内存使用,提升性能。还可以使用torch.no_grad()配合使用,在评估阶段关闭梯度跟踪,进一步提升性能。
depth_encoder.eval() # 切换到评估模式,使得模型BN层等失效
6.模型推理
关闭梯度流跟踪和eval()共同提升模型推理性能。
encoder_input = torch.randn(1, 3, 256, 256)
with torch.no_grad():
encoder_output = depth_encoder(encoder_input))
文章出处登录后可见!
已经登录?立即刷新