文章目录
- 1. 人体姿态估计的介绍和应用
- 2-1. 2D姿态估计概述
- 2-2. 2D姿态估计详细说明
- 3. 3D姿态估计
- 4. 人体姿态估计的评估方法/指标
- 5. DensePose(人体表面参数化)
- 6. 人体参数化模型
- 7. 课程总结
视频链接:B站-人体关键点检测与MMPose
1. 人体姿态估计的介绍和应用

关键点提取,属于模式识别

人体姿态估计的下游任务:行为识别(比如:拥抱。。)
下游任务:CG和动画,这个是最常见的应用

下游任务:人机交互(手势识别,依据收拾做出不同的响应,比如:HoloLens会对五指手势(3D)做出不同的反应)
2-1. 2D姿态估计概述
包括:
- 自顶向下方法
- 自底向上方法
- 单阶段方法
- 基于Transformer的方法
2.1 任务描述

2D人体姿态估计的任务:
- 输入:一张包含人体的图像
- 输出:人体关键点(主要关节)的坐标(2D的)
注意,这里的输出是固定对应(预定义的)18个关节的坐标,就是要找这18个位置的坐标
2.2 基于回归
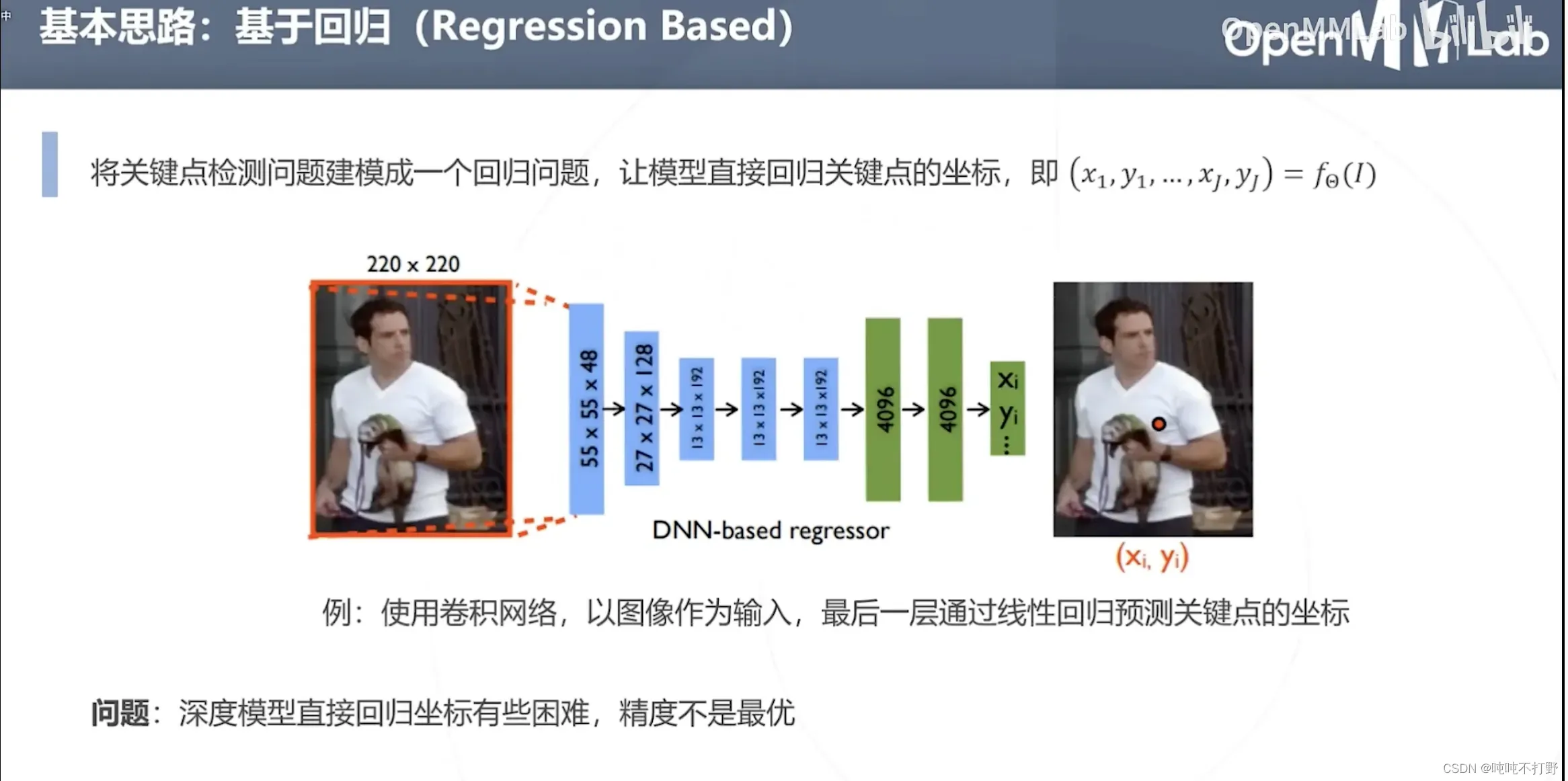
使用深度学习的模型直接回归坐标有些困难,精度不是最优(效果不好)
2.3 基于热力图
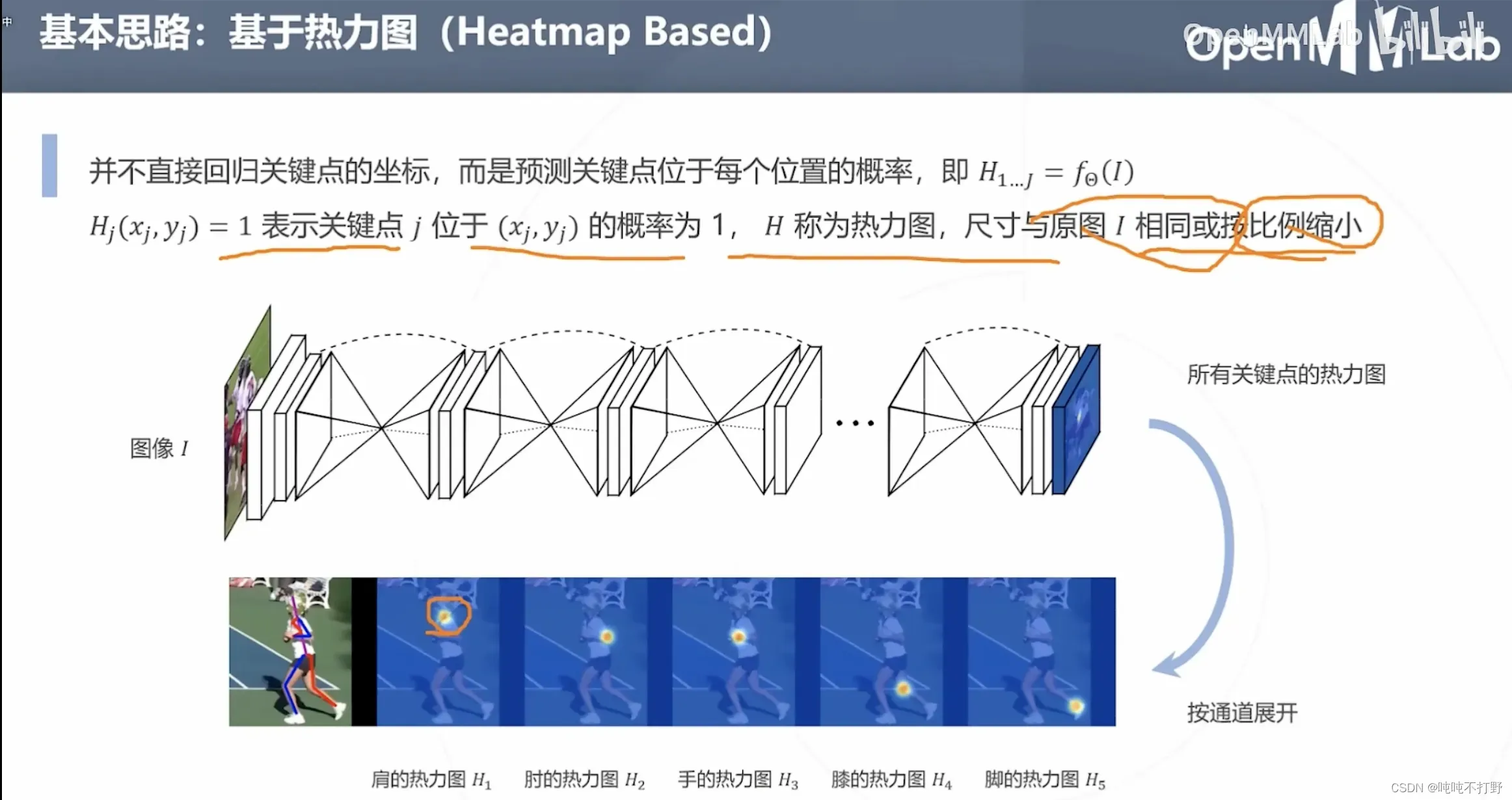
另一种思路是:不直接回归关键点的坐标,而是预测关键点位于每个位置的概率。
- 比如肩的热力图(越靠近肩膀的预定义的关键点,概率越高,颜色逐渐从黄色变成红色)
- 18个关键点,对应18个热力图

基于热力图天然符合神经网络的卷积算子(对每个像素都进行计算,得到每个像素的概率)
2.3.1 从数据标注生成热力图(高斯函数)
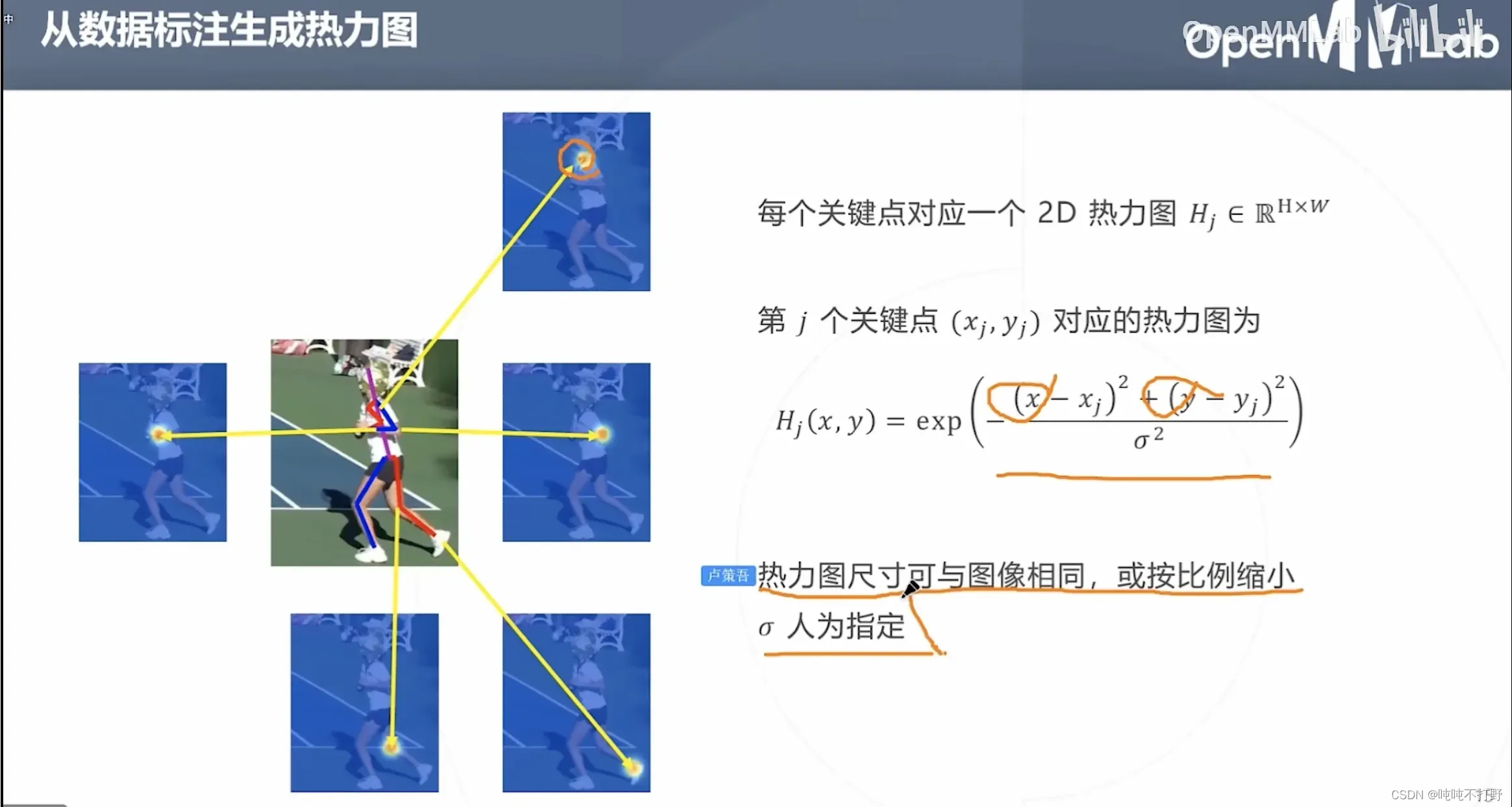
如果想要使用基于热力图的方式,那么首先要根据已有的标注数据生成热力图。
- 预定义的关键点附近区域的概率其实符合这一事实:
- 越靠近预定义的关键点,概率越高,如上图,颜色逐渐从黄色变成红色
- 假设上面这个热力图区域是个圆形,那么任意一个直径作为
轴(距离预定义关键点的距离作为自变量),是关键点的概率作为
轴(因变量),则可以用高斯函数来描述
- 所以这里是假设关键点区域的热力图符合高斯分布,来生成热力图(概率图),来进行训练。
- 所以这里说热力图的尺寸,即作为控制高斯函数图像钟的宽度的
参数,也就是控制热力图区域大小
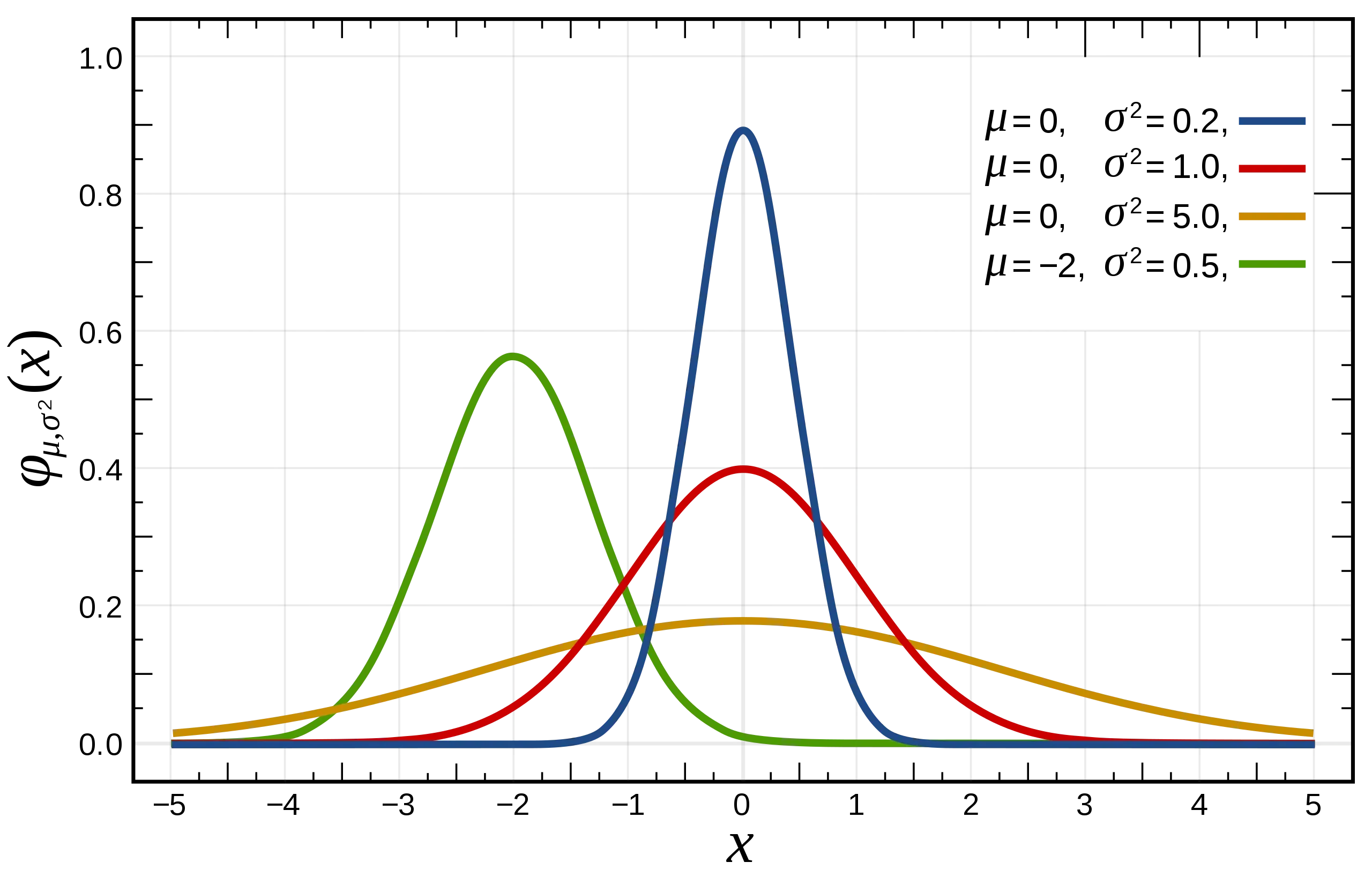
复习一下高斯函数(红色线代表标准正态分布):

高斯函数是正态分布的密度函数,下图的红色是标准正态分布
可以直接看:
- 中文wiki百科-高斯函数
- 中文wiki百科-正态分布
- 打不开上面这个看下面转载的这个,旧了点,但是意思差不多:高斯分布(Gaussian distribution)/正态分布(Normal distribution)
2.3.2 使用热力图训练模型
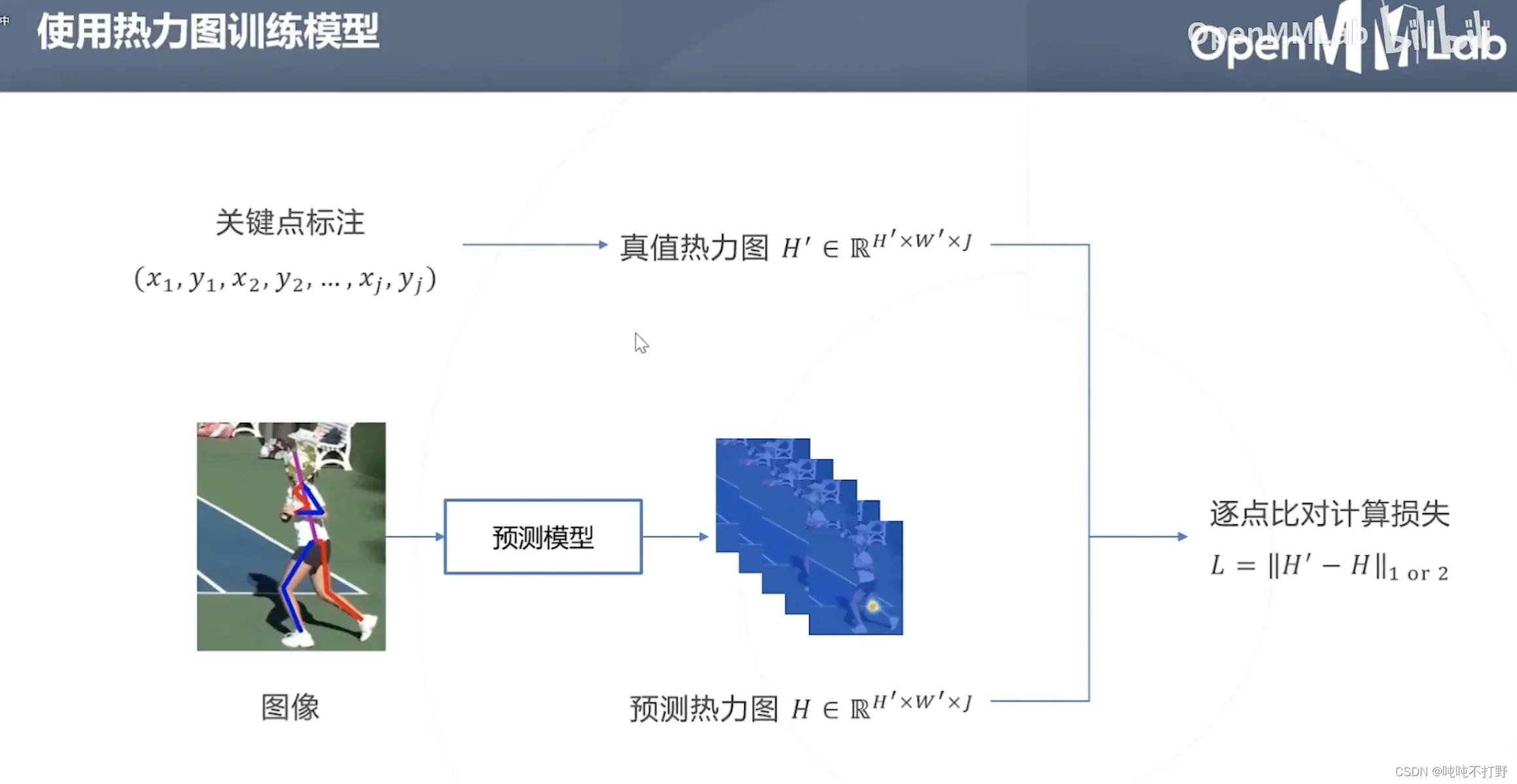
- 这里其实是一个2D的高斯函数,
其实就对应上面高斯函数图像的最高点
- 即,真值热力图的构建函数需要满足:距离关键点越近,概率越大,所以高斯函数天然满足这个性质
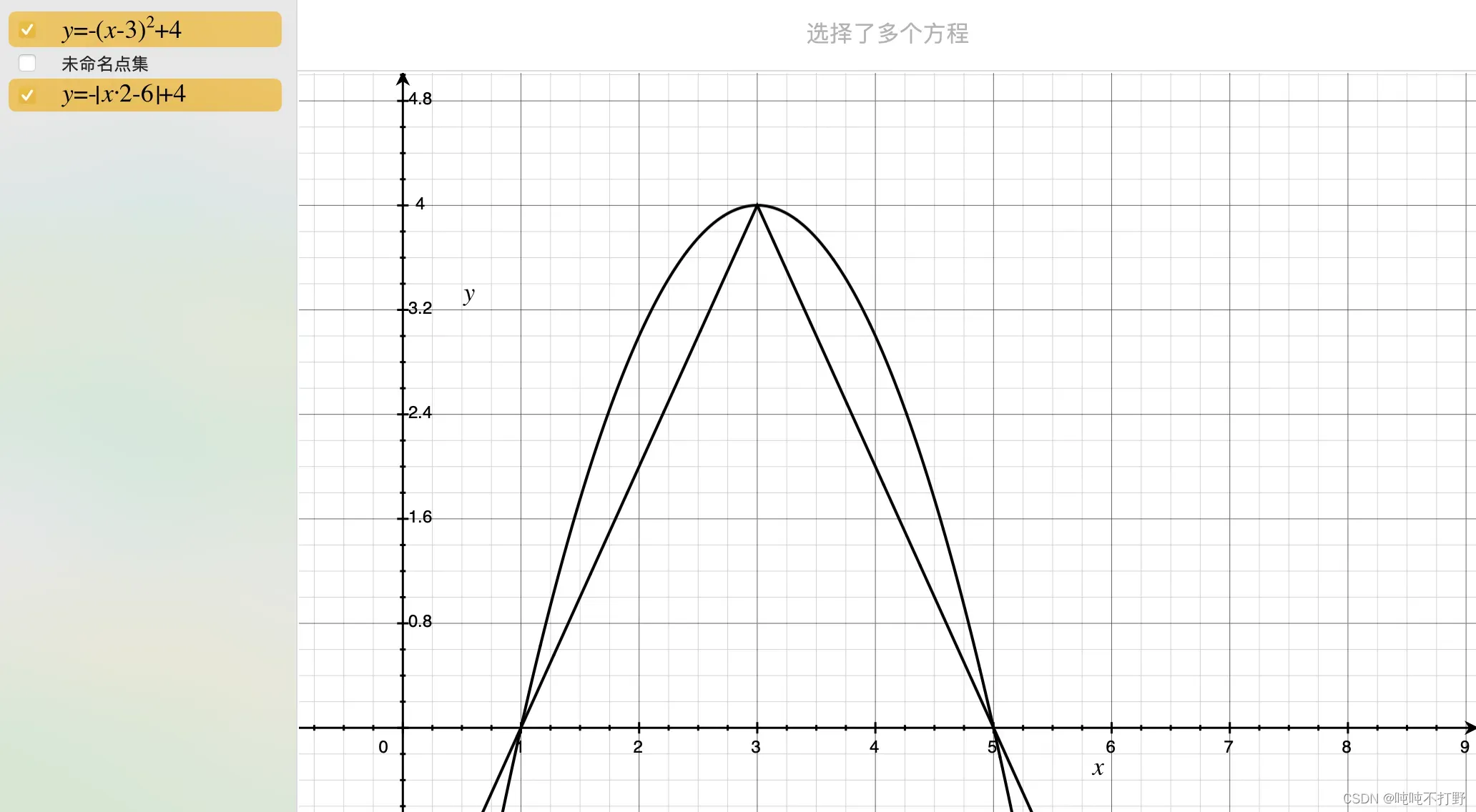
- 除此之外,其实只要是类似钟形都可以,下面这个抛物线函数,还有我随便造的一个绝对值函数,其实都满足这个条件(但是概率取值范围[0,1]需要进一步处理一下才行)
2.3.3 从热力图还原关键点

- 最直接的办法就是求最大概率(热力图最大值)对应的位置的坐标,
- 按照生成真值热力图的方式来倒推,是很合理的方式
- 但这是基于:预测的热力图符合高斯函数,这一假设下的推论
- 实际上,可能预测的热力图形状不会那么规整,可能会有多个最大值,所以直接求1个最大值这种方式不够鲁棒

- 先对热力图的概率进行归一化(对概率用softmax,输出的还是概率),用归一化后的概率计算位置的期望
- 期望就是平均值,在1D的高斯函数图像中,高斯函数的最高点,对应的
- 可能不一定能取到最高点,但是能取到”重心”,这样利用了整个热力图的概率,相对于上面只看热力图的最大概率,就会比较鲁棒,
这种计算方式还有很好的一个性质:
- 可以进行端到端的训练,还原关键点的方式的公式,是可以求导的,所以能和整个训练过程串起来。
- 比如,一开始训练的时候,网络初始化时,使用的是随机数作为关键点来生成初始预测热力图,第一轮训练完成后,得到生成的热力图,就可以得到一个矫正过的关键点,以此来作为第二轮使用的热力图的初始值,继续迭代。
- ❓❓❓但是上面优化的时候只使用热力图的loss, 但是真实关键点和预测关键点也都可以拿到,关键点的loss其实也可以加上去。两种损失一起会更好吗??
2.4 自顶向下

最直观的一种方式(自顶向下):
- 先目标检测,得到每个人(检测器的精度需要保证)
- 再对每个人进行 单人姿态估计
模型串联的坏处,
- 姿态估计结果会过分依赖人体目标检测的结果
- 速度和计算量和画面中的人数成正比
2.5 自底向上

优点:
- 推理速度和画面中的人数无关
- 关键点多,则检测速度肯定也会慢一些。但不会像自顶向下方法一样与人数成正比,人数越多的时候,自底向上比自顶向下方法快的越明显)
- 聚类耗时肯定是和人数成正比的
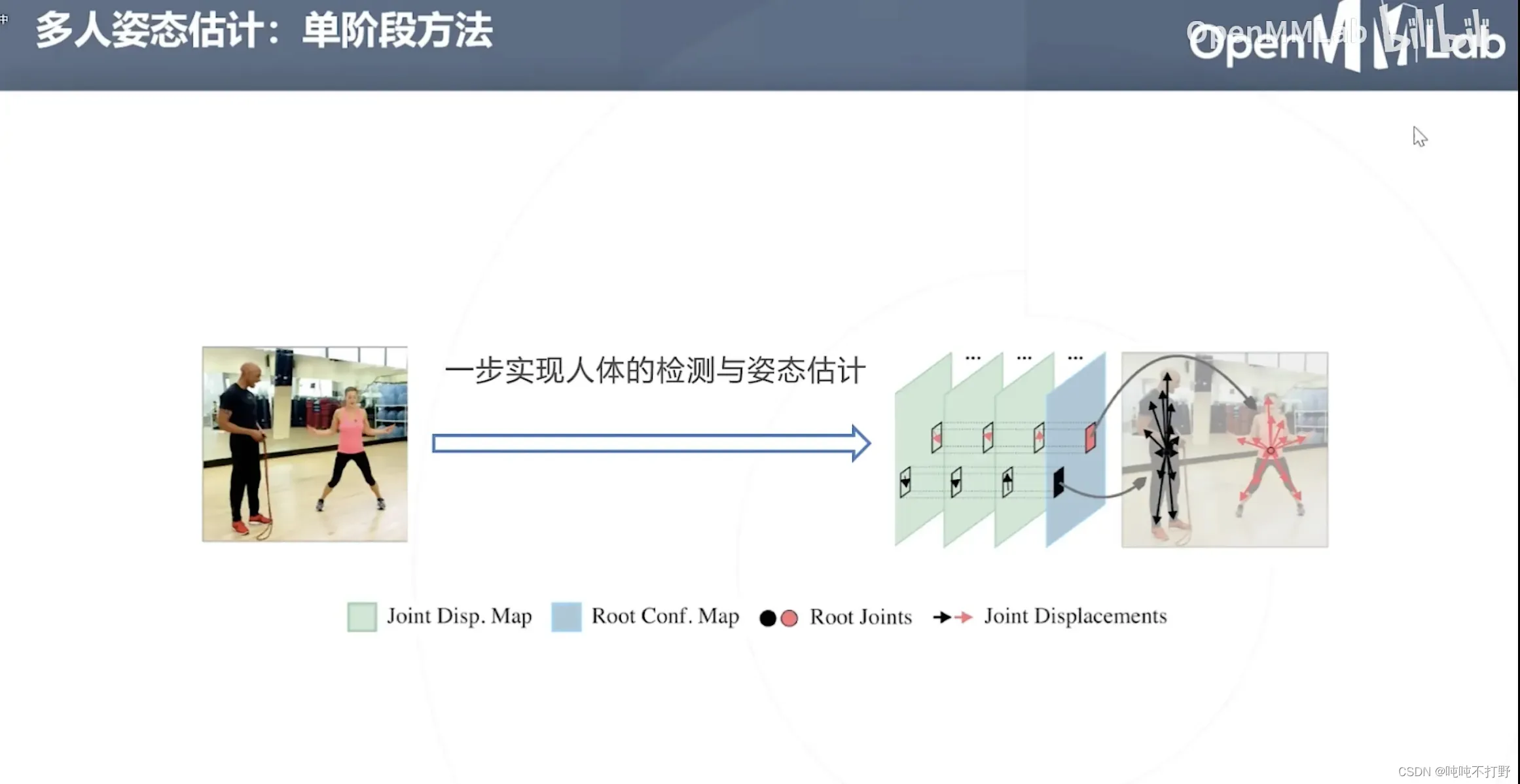
2.6 单阶段方法
2-2. 2D姿态估计详细说明
2.1 基于回归的自顶向下方法
2.1.1 经典方法

- 如果是人体姿态估计的话,就是18个关键点的坐标,在2D场景下,也就是要预测36个数字。。。(回归36个数字,可比分类36个类要难,目标检测里也有回归box四个坐标的方法)
- 原始论文是用AlexNet主干+回归头做的,主干(backbone)也可以换成ResNet等结构
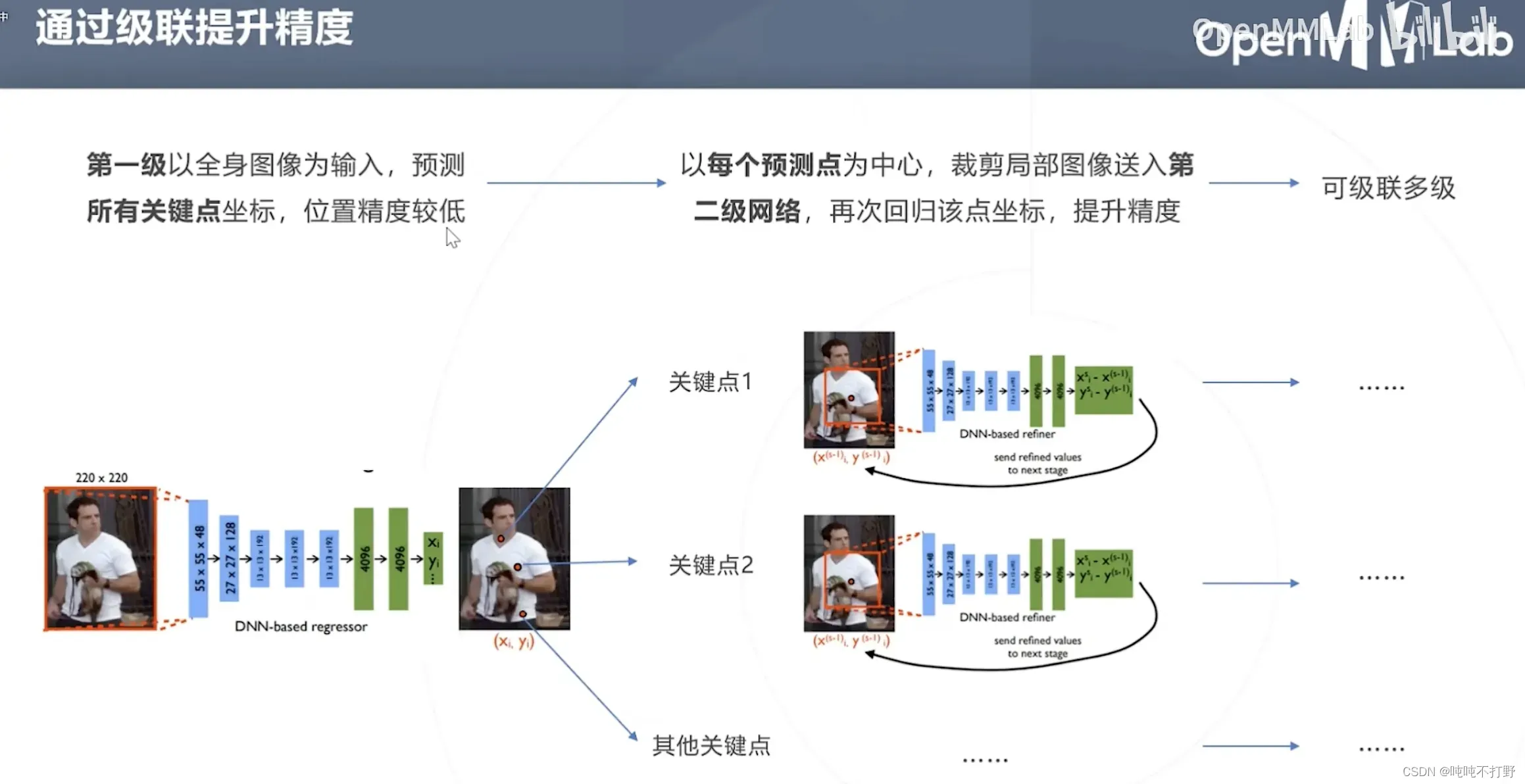
- 第一级,输入:全身图像
- 第二级,输入:第一步预测点为中心的裁剪后的局部区域
类似医疗影像分割里的级联:
- 第一级,输入:医疗影像
- 第二级,输入:医疗影像+第一级得到的概率图

优势:
- 回归模型理论上可以达到无限精度,热力图方法的精度受限于特征图的空间分辨率(也不一定,加个期望上去有时候也可以突破这个限制)
- 回归模型不需要维持高分辨率特征图,计算更高效。相比之下,热力图方法的特征图的size不能低于热力图的size,所以热力图方法确实要计算和存储高分辨率特征图,计算成本(硬件要求)更高
劣势:
- 图像到关键点坐标的映射是高度非线性的,导致直接回归坐标,比通过热力图(概率)得到坐标更难,同时回归方法的精度也低于热力图,因此DeepPose提出之后很长一段时间,2D关键点预测算法主要都是基于热力图的。
2.1.2 基于最大似然估计的改进(RLE)

之前的基于回归方法的姿态估计,
- 损失函数为:真实关键点位置
与模型预测关键点位置
的误差作为损失
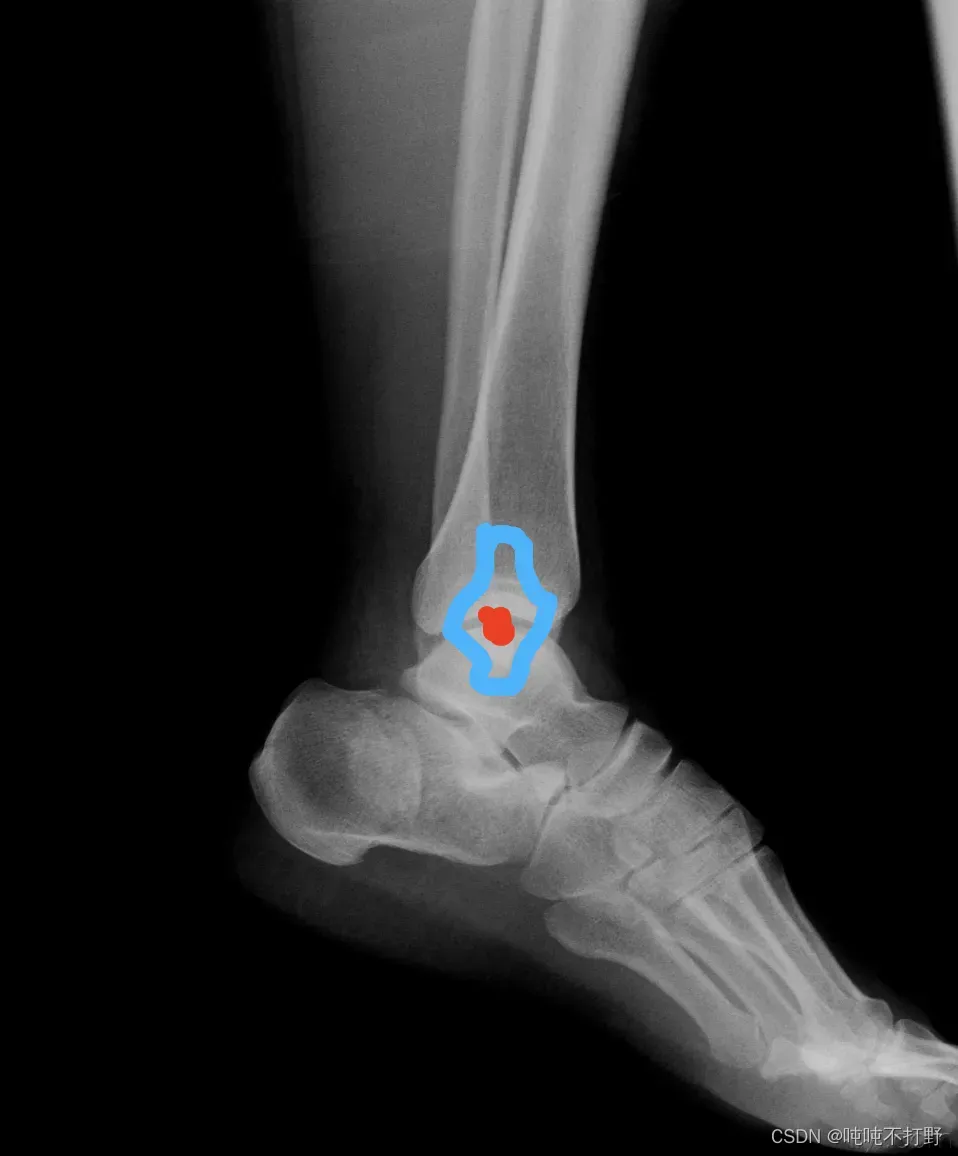
- 这背后隐含了高斯分布的假设,即:预测点距离关键点越近,就越好,因此以关键点为圆心,相同半径圆周上的点作为预测点,其误差都是一样的。即:认为预测点分布在真实点形成的一个圆形里。
- 但是实际上,人体的关节有不同的形状如下图:踝关节,红色是关键点,蓝色围成的区域就是分布,不是个圆形,不是只靠一个方向的距离就可以衡量误差的(每个方向距离引起的误差在损失函数中权重应该是不同的):
另外,下面这篇文章创新点的部分,要先去看下面的背景知识,看完就基本就懂这个创新点了。

- 模型给出基础分布的参数
- RLE模块基于标准化流,给出位置的分布
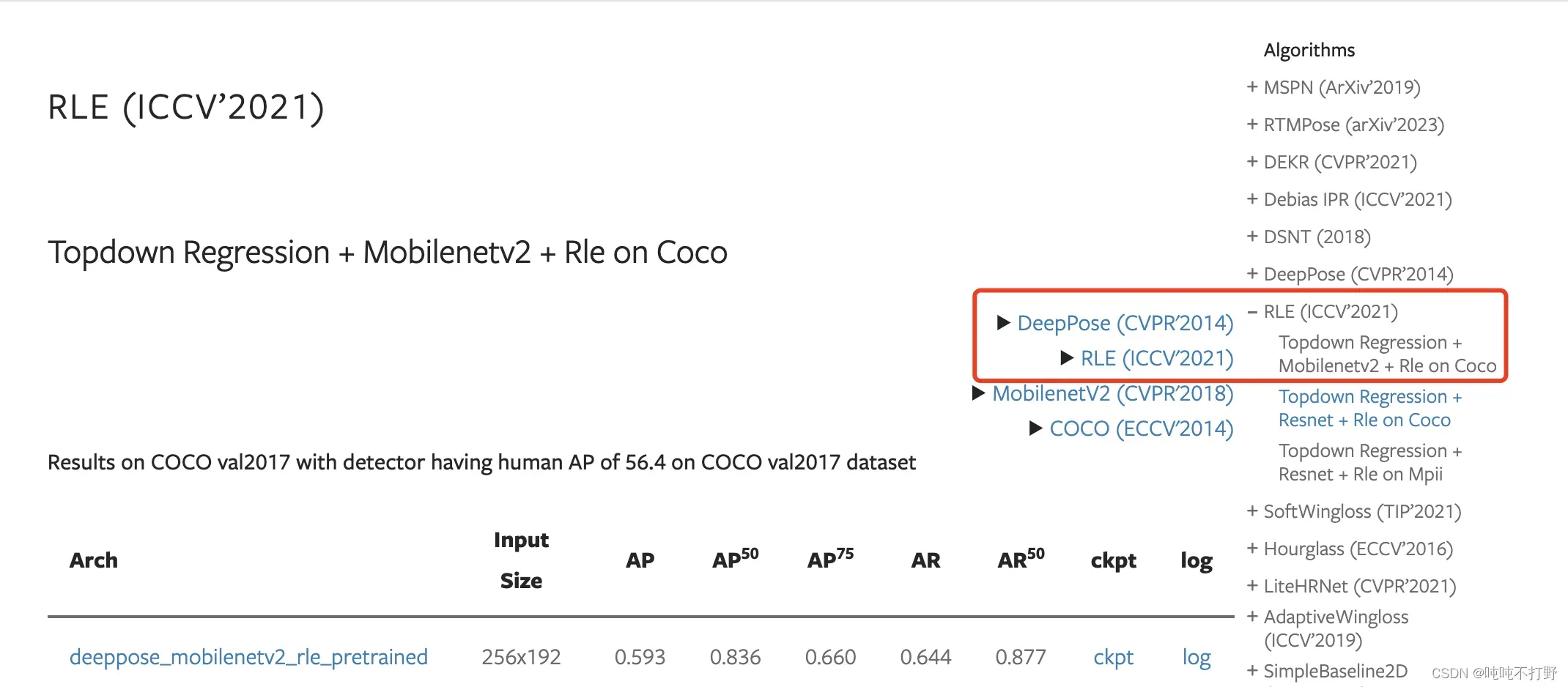
论文就直接在MMPose里找了,这里Topdown Regression + Mobilenetv2 + Rle on Coco
论文arxiv链接:Human Pose Regression with Residual Log-likelihood Estimation
2.1.2 背景知识-回归和最大似然估计的联系

- 关于二范数(L2-norm损失函数)这个名词,可以看看:区分混淆概念之L2范数,L2范数损失,L2损失,均方误差
- 如上面的右图,使用二范数(最小二乘误差/最小平方误差)进行回归
- 其实隐含了 关键点位置 符合 固定方差的各向同性的高斯分布 的假设,但是实际上,在真实的人体关节,关键点的位置并不一定符合高斯分布
- 因此RLE的关键在于:
- 将简单的高斯分布替换为一个可学习的、表达能力更强的分布(用在损失函数上),来更好指导模型学习真实的关键点位置分布。
- 因为基于高斯分布假设的回归误差,和高斯似然下的最大似然估计是等价的
- 注意,这里的二范数误差回归的各向同性高斯分布,是基于回归的方法用在损失函数上的;但是原理和基于热力图的方法里,使用标注关键点生成热力图的思想是类似的。
2.1.2 背景知识-标准化流Normalizing Flow
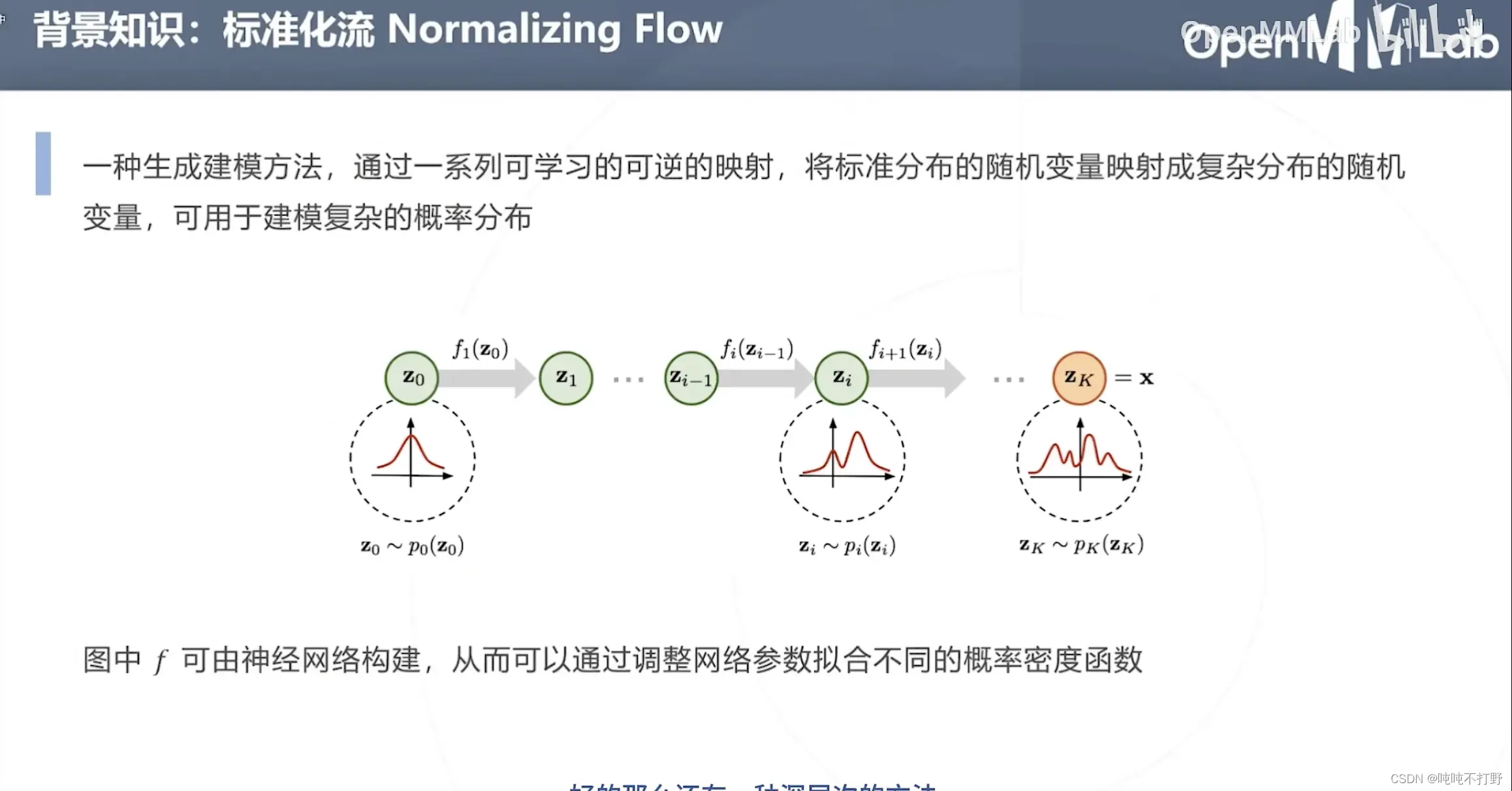
标准化流Normalizing Flow:
- 一种生成建模方法,通过一系列可学习的可逆的映射(
是学习出来的,同时要满足是可逆的),将标准分布的随机变量映射成复杂分布的随机变量,可用于建模复杂的概率分布
是标准分布,解析式已知,可以计算其导数等性质
- 后面所有对
进行的变换

- 由于
- det:是行列式(Determinant)的缩写,表示计算一个矩阵的行列式,不记得的可以看看:

- 这样乘法
就变成了加法
(这个latex语法是’\prod’,product是乘积的意思),
- 注意,后面的det外面还套了个
-1,因此就变成了
- 全体参数
,latex-
\Phi
概率分布受到构建该分布的神经网络
的全体参数
控制
- 可以通过梯度下降优化
映射的函数形式,让这个计算变简单。
- RLE论文使用的标准化流模型是RealNVP
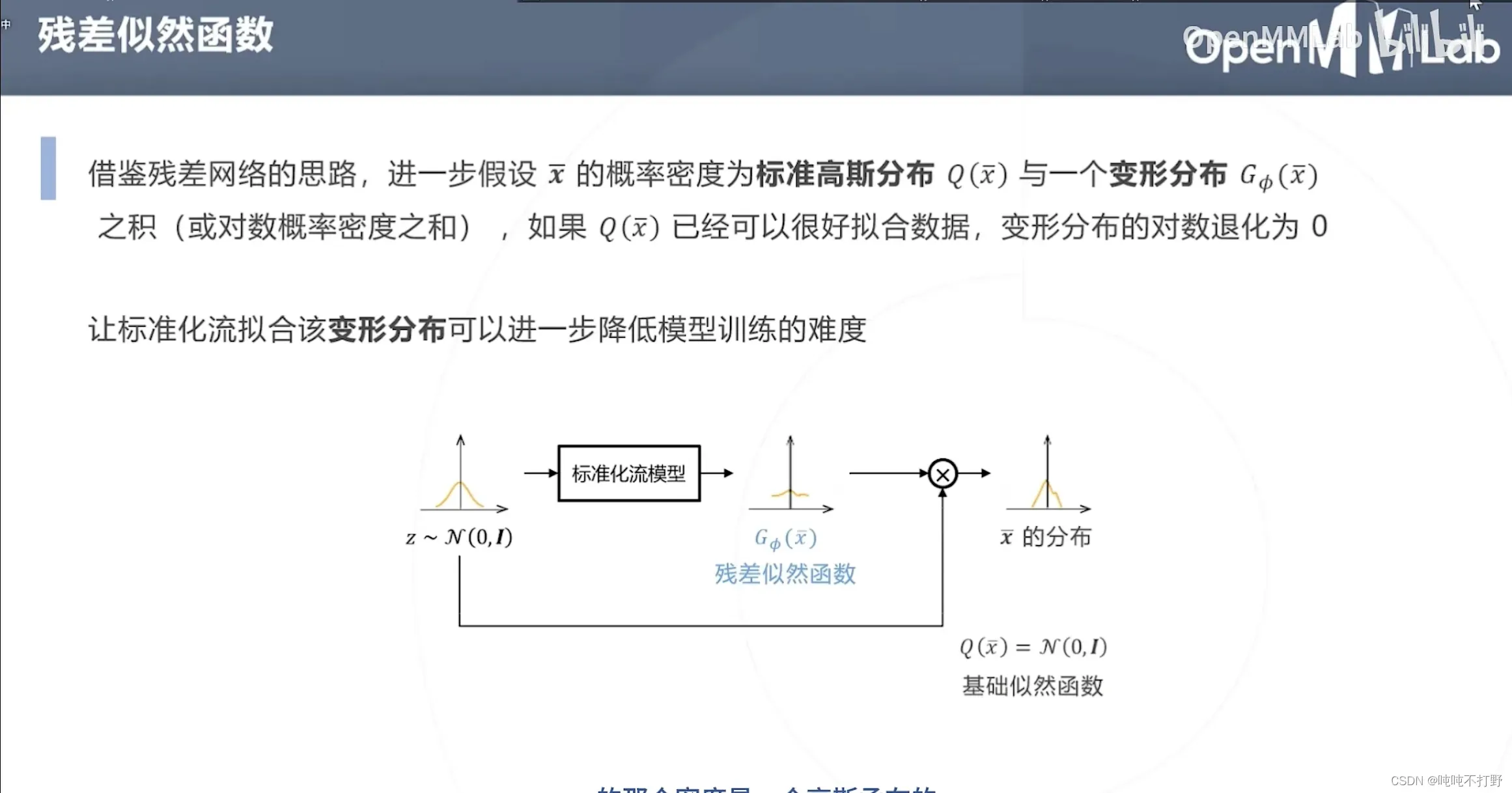
2.1.2 RLE的整体设计

- 重(chong)参数化
- 残差似然函数

- 例如:所有一元正态分布
构成位置尺度族,基础分布为标准正态分布。
对标准正态分布进行平移缩放,就可以得到任意其他的一元正态分布。 - 重参数化的思想,有点像,卷积层的参数共享(卷积核/模板参数共享),都是为了减少参数,所以公用了一部分参数
所以整体就是:
- 标准化流拟合基础分布
- 卷积网络预测平移缩放参数
- 即上图右下侧的示意图
❓❓❓
推理阶段,则只需要卷积网络预测的平移(❓为什么不考虑缩放)参数,❓不用推理标准化流
2.2 基于热力图的自顶向下方法
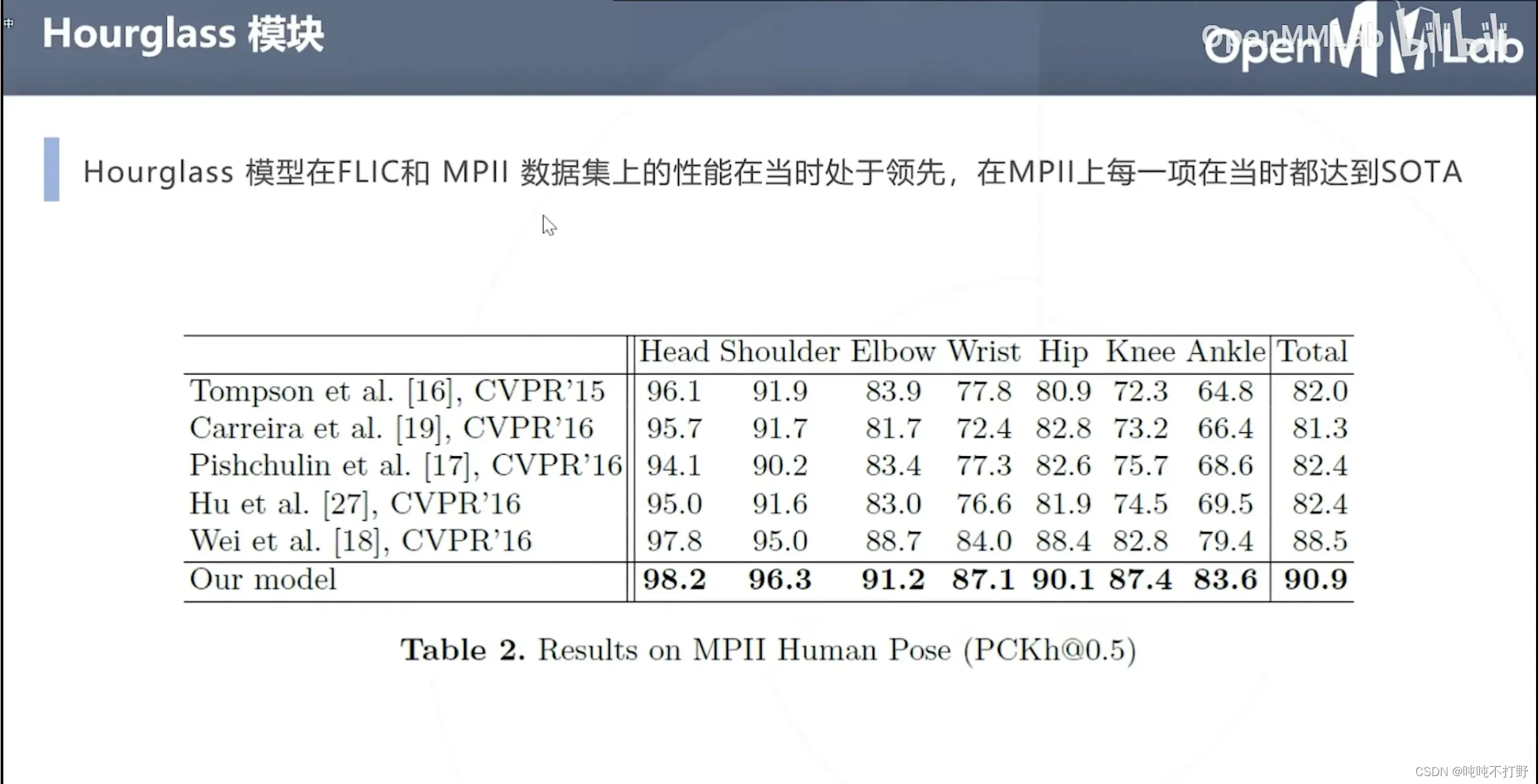
2.2.1 Hourglass论文地址(2016年)
MMPose中这个网络的位置:
2.2.2 Hourglass模型
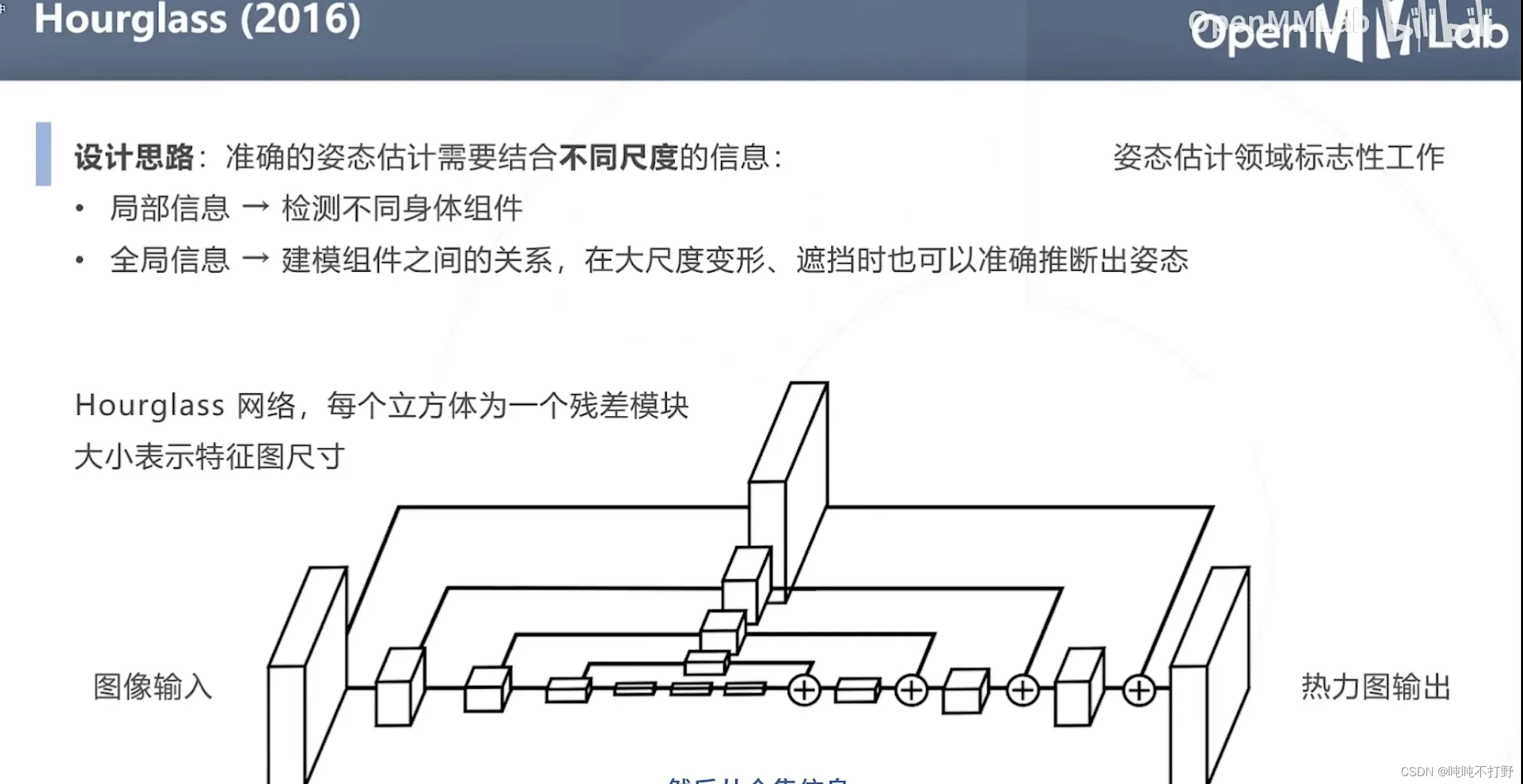
- 设计思路:准确的姿态估计需要结合不同尺度的信息
- 局部信息→检测不同的身体组件(不同部位的关键点)
- 全局信息→建模组件之间的关系,在大尺度变形、遮挡时也可以准确推断出姿态
上图的网络结构中,
- 每个立方体都是一个残差模块,大小表示特征图的尺寸
- 每个尺度,都有自己的残差
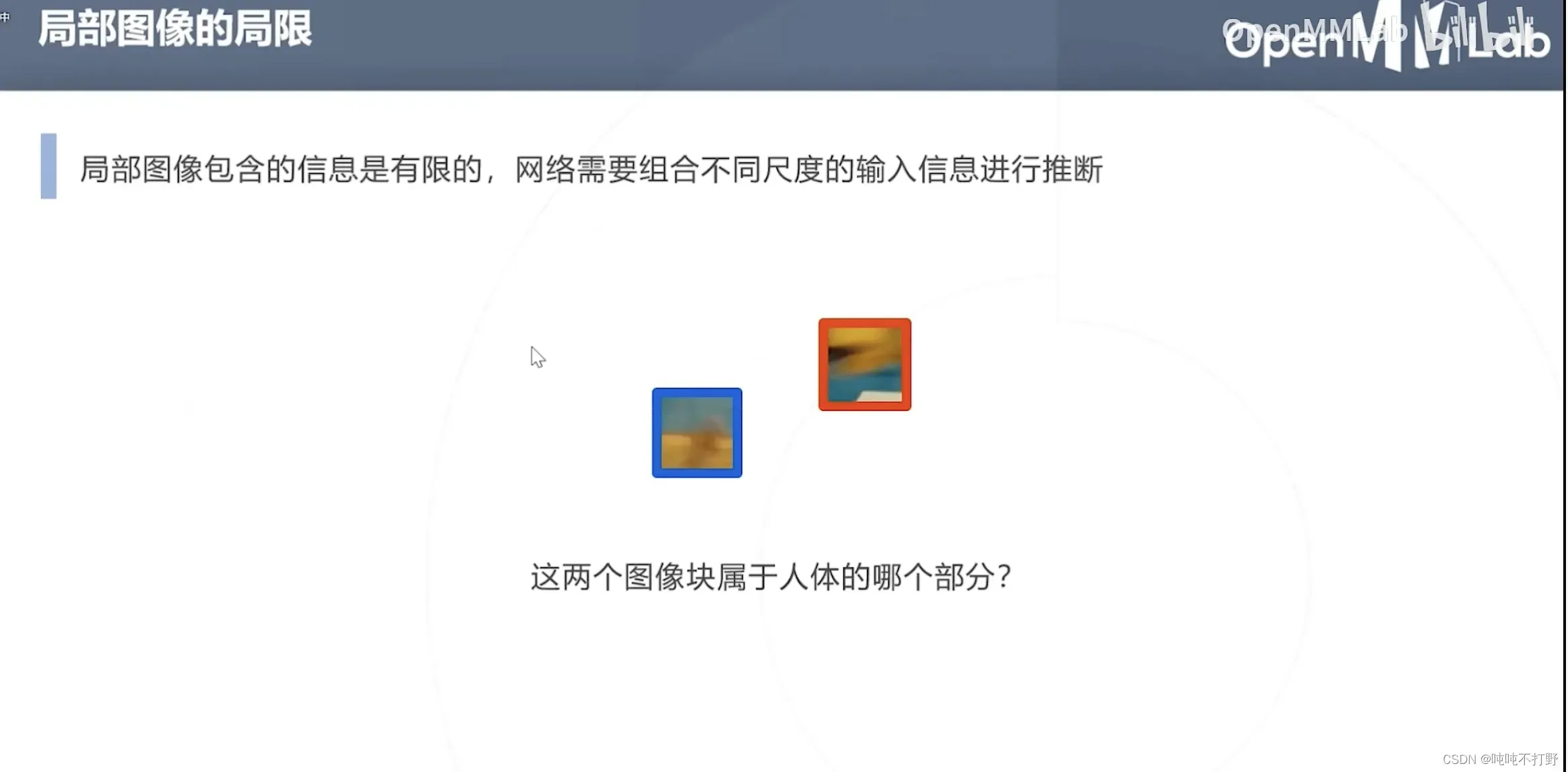
- 对于上图蓝色框的小尺度局部,其实只要给一个输入包含手臂的一个尺度的局部,其实就可以判断出来是什么,黄色框同理,
- 不同尺度,看到的信息不一样,不同的尺度就可以得出不同的结论(甚至有些小尺度没有效的结论,或者某些特定尺度才能看到有效信息)
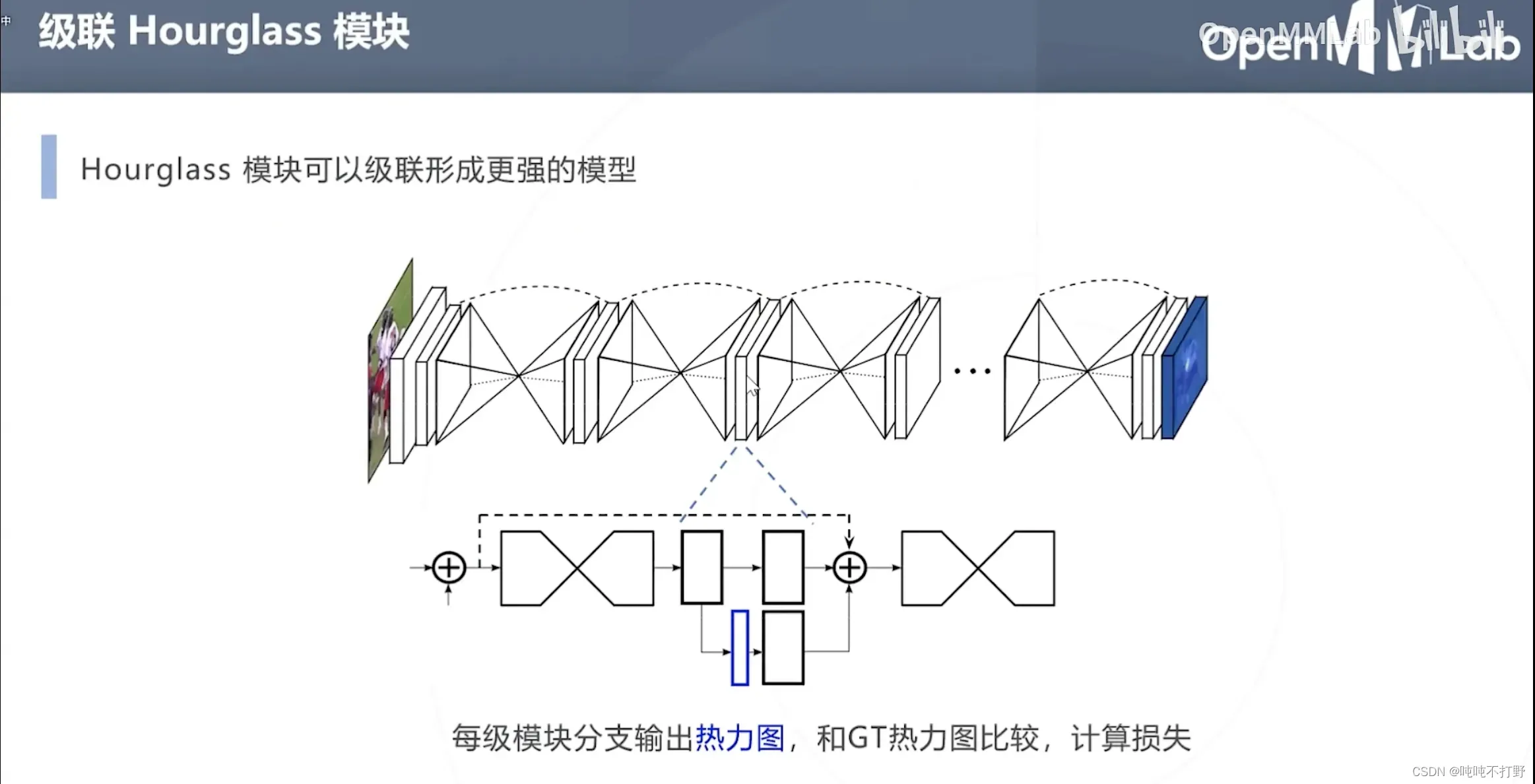
- 上图蓝色部分就是这个模块输出的热力图,蓝色右边的就是真值
- 虚线的曲线括住的部分就是一层Hourglass模块,一般会有8层。。
也就是:每一级模块都可以分别进行损失函数的优化。
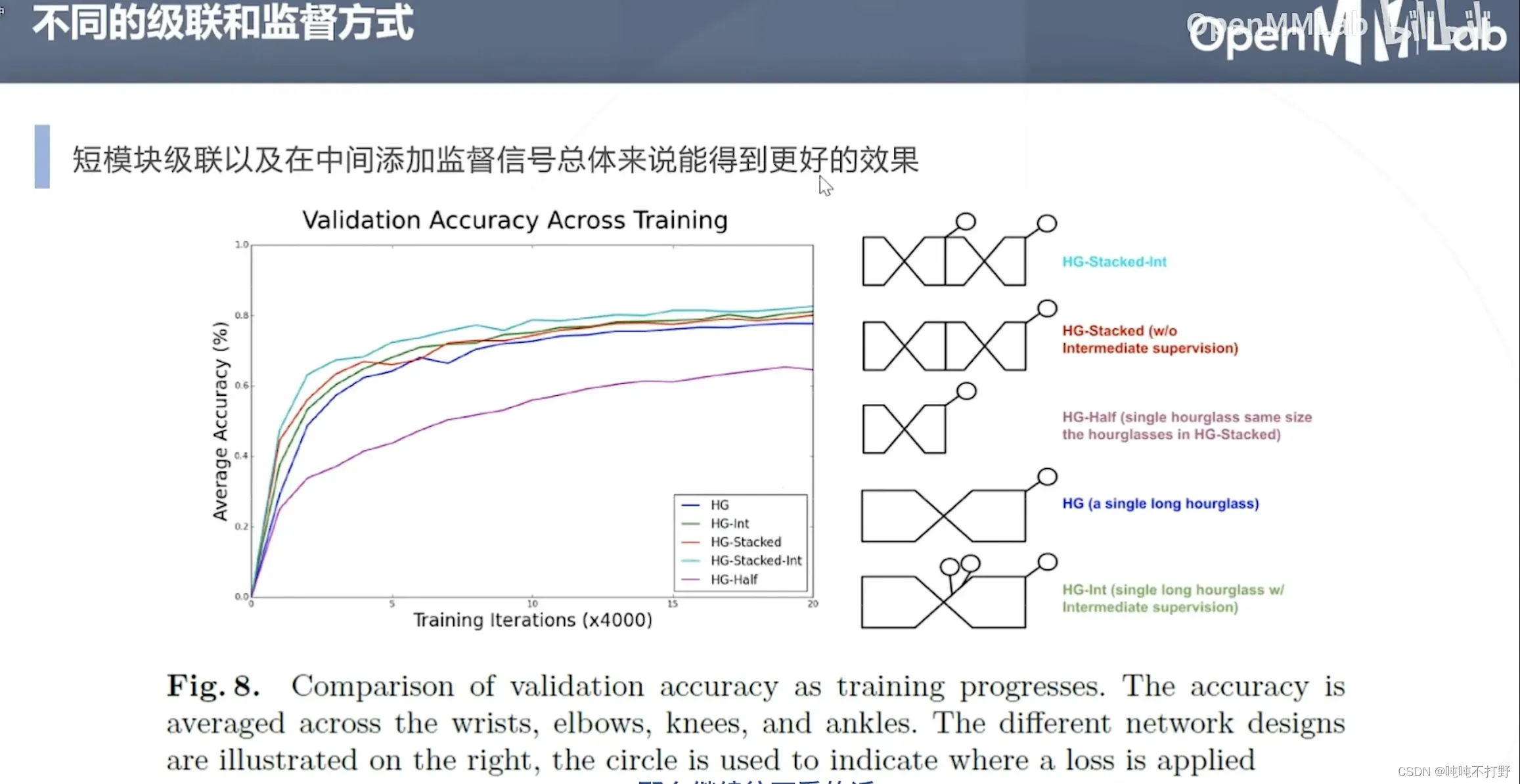
- HG堆叠,也就是这个论文主推的方法,8个Hourglass模块堆在一起,每个模块输出的热力图都和真值比较(短模块级联+每层模块都添加监督信号)
- HG堆叠,但是只对最后输出的热力图和真值比较
- 不进行级联,只有HG堆叠中一层Hourglass模块
- Hourglass特征提取部分变大了(long hourglass),这个要去论文里看具体的
- 类似4,在中间添加了监督
蓝色和绿色最好,说明在中间添加监督信号是更有效的,但是级联和long hourglass的效果最后看起来似乎没有差很多
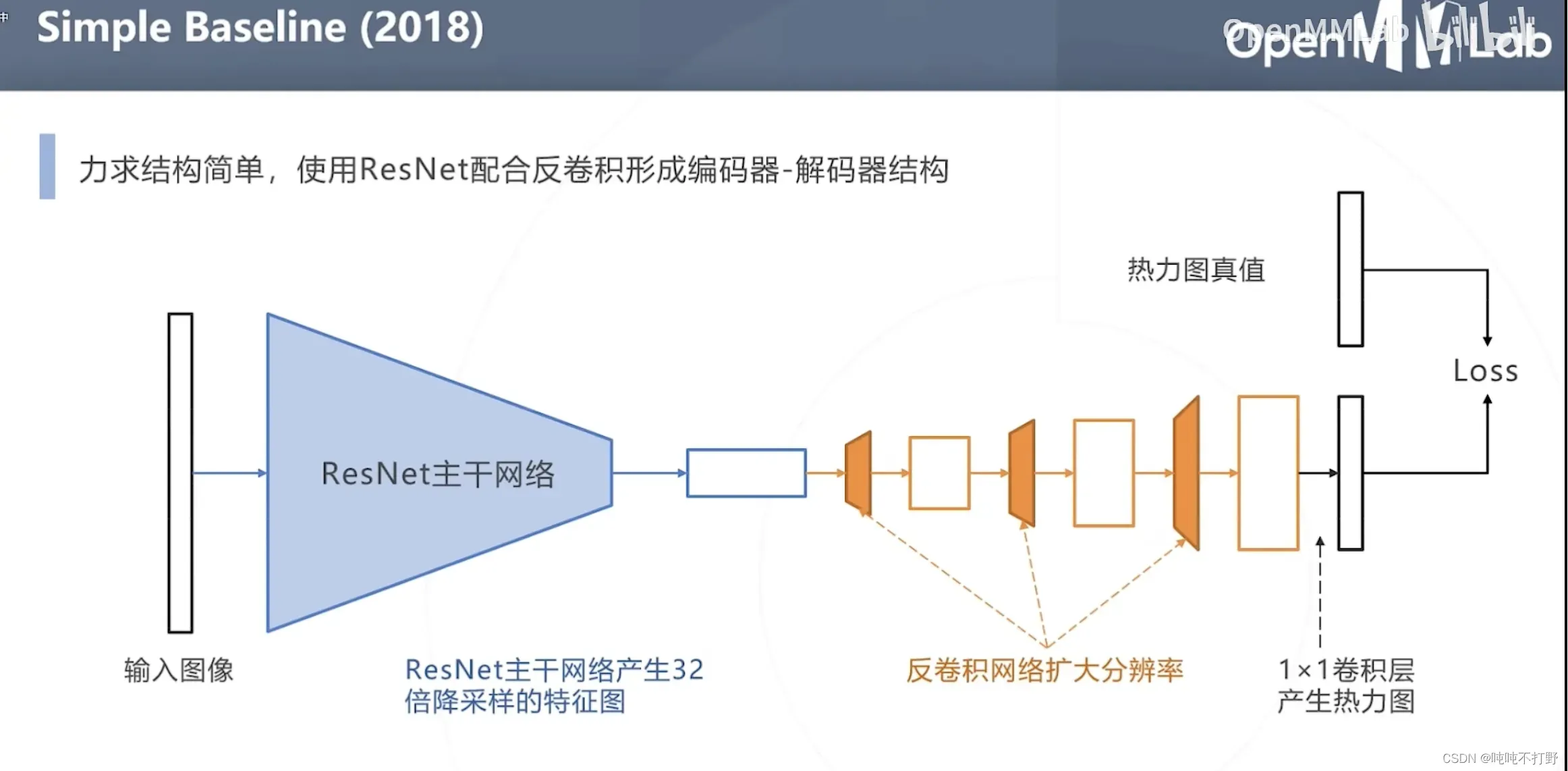
2.2.3 Simple Baseline(2018年)
MMPose中这个网络的位置
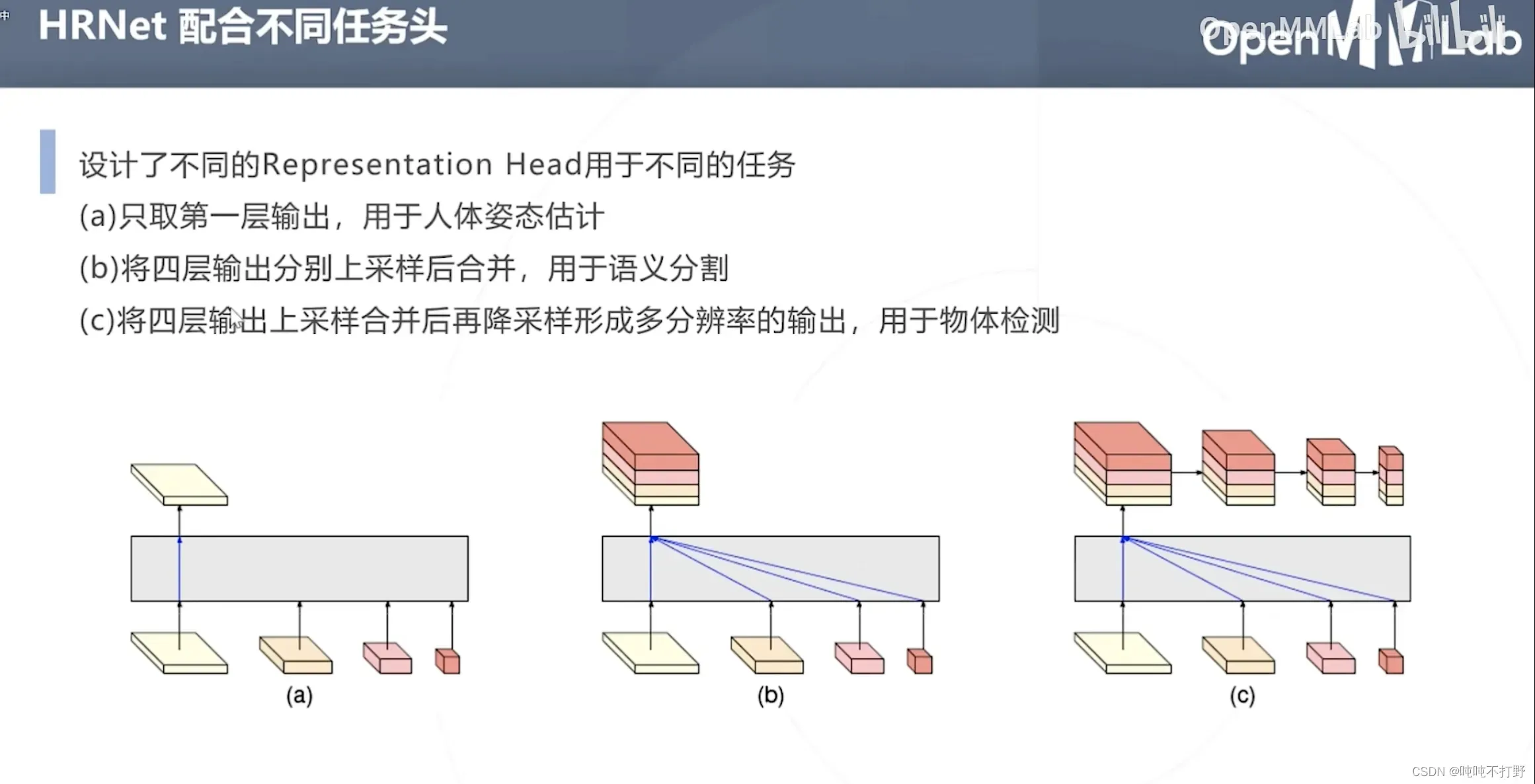
2.2.4 HRNet(2019)
位于MMPose的这里,链接
论文链接:Deep High-Resolution Representation Learning for Human Pose Estimation
可以看看这个讲解:陀飞轮-一文读懂HRNet

- 下采样时通过保留原分辨率分支,来保持网络全过程特征图的高分辨率与空间信息位置
- 设计了独特的网络结构实现不同分辨率的多尺度特征融合

- 对于右图,第二列最下面最小的橙红色分辨率特征图,其实是来自前一层三种不同尺度的分辨率(三个虚线箭头),同理,其实第二层的所有不同尺度的分辨率特征图,都是从前一层的三个尺度里得到的。
- 橙红色就是上面说的跨层的额外融合输出,其余三个都是对应各自那个级别的分辨率
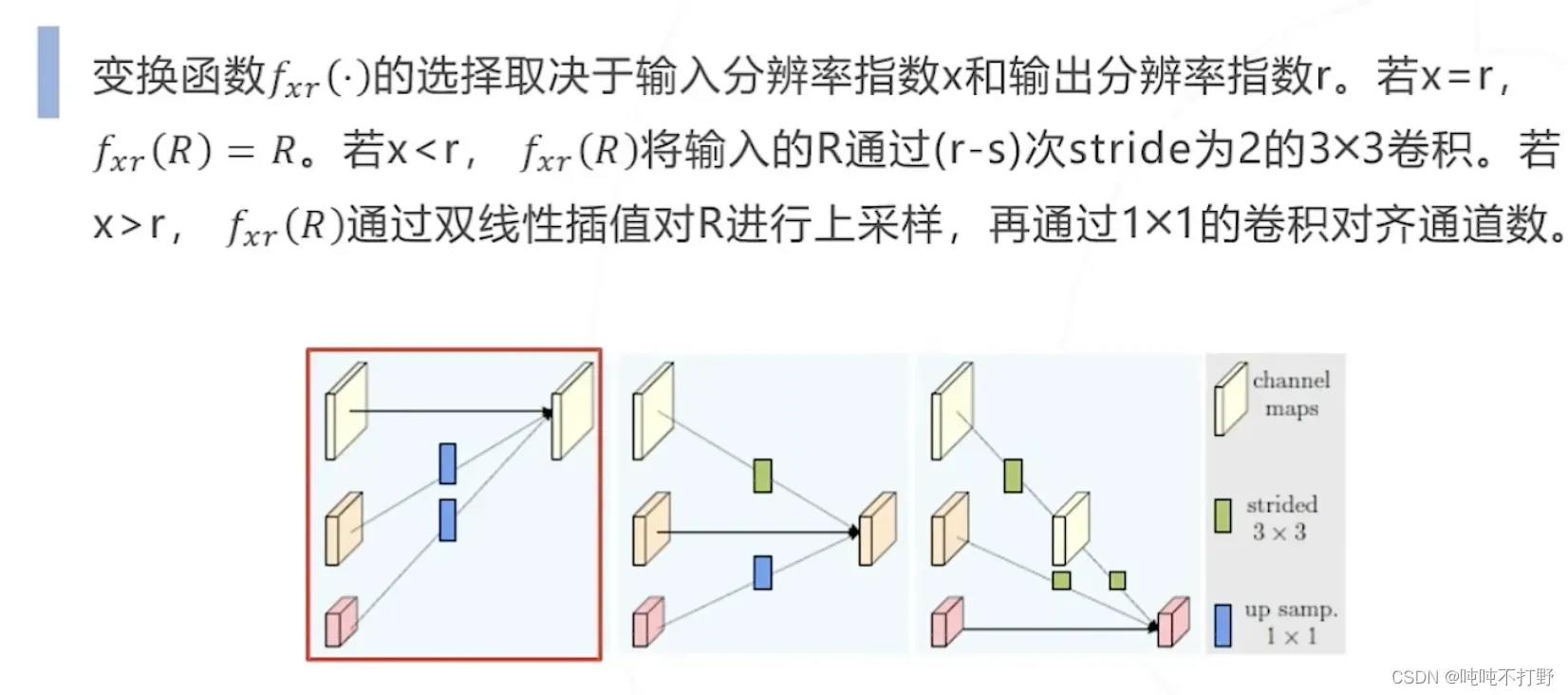
- 第一列分辨率(x) = 第二列分辨率( r) 的特征图,直接相等。
- 第一列分辨率(x) > 第二列分辨率( r) 的特征图,
将输入的
经过
次stride为2的
卷积。
,stride为2,也就是每次卷积特征图size小1,经过r-x次,就刚好可以得到输出特征图为x的尺寸了
- 第一列分辨率(x) < 第二列分辨率( r) 的特征图,使用双线性插值进行上采样,再用1X1卷积对齐通道数。
2.3 基于热力图的自底向上的方法
2.3.1 Part Affinity Fields & OpenPose(2016)
MMPose中这个网络的位置,没有找到这个文章

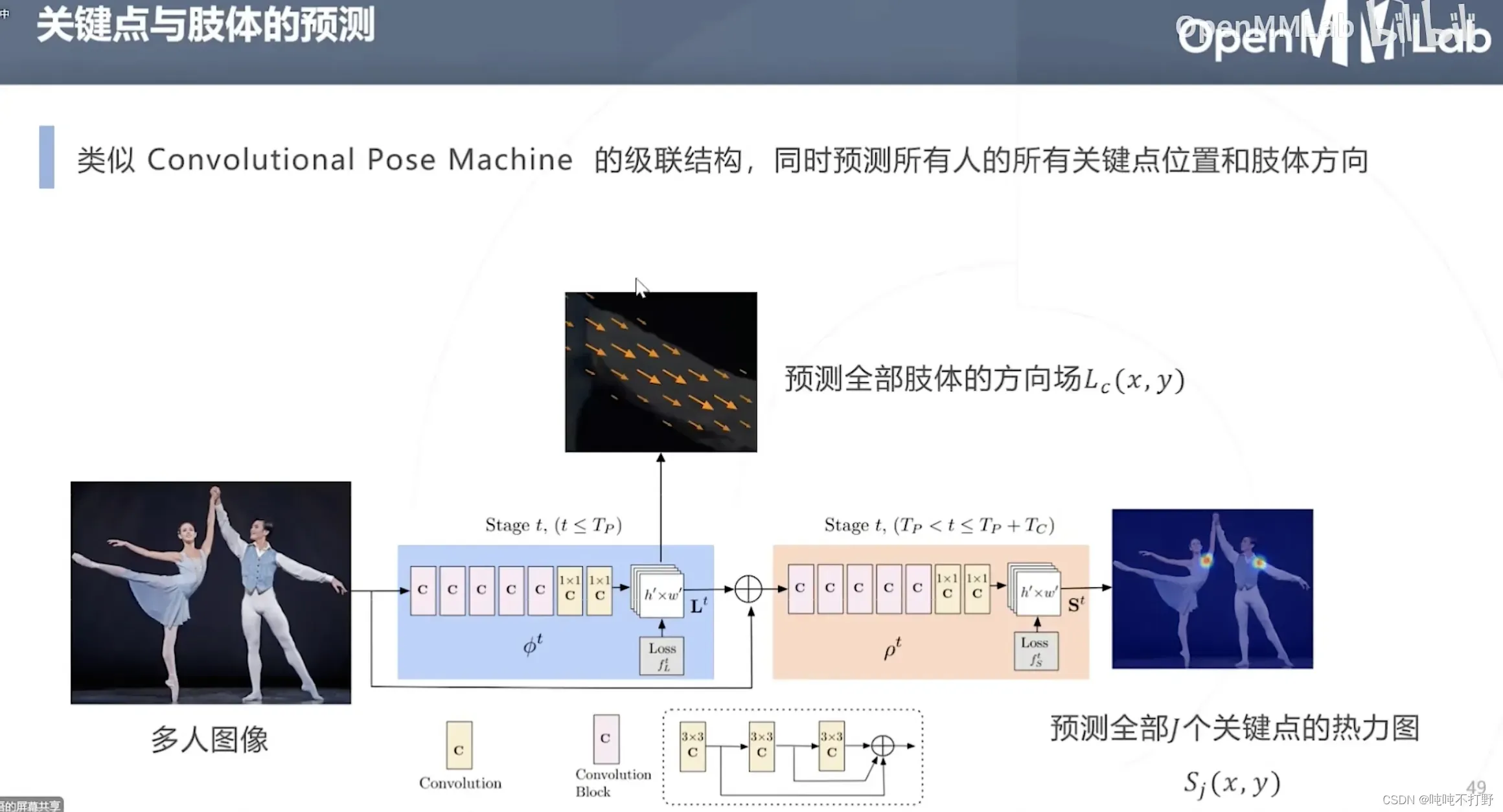
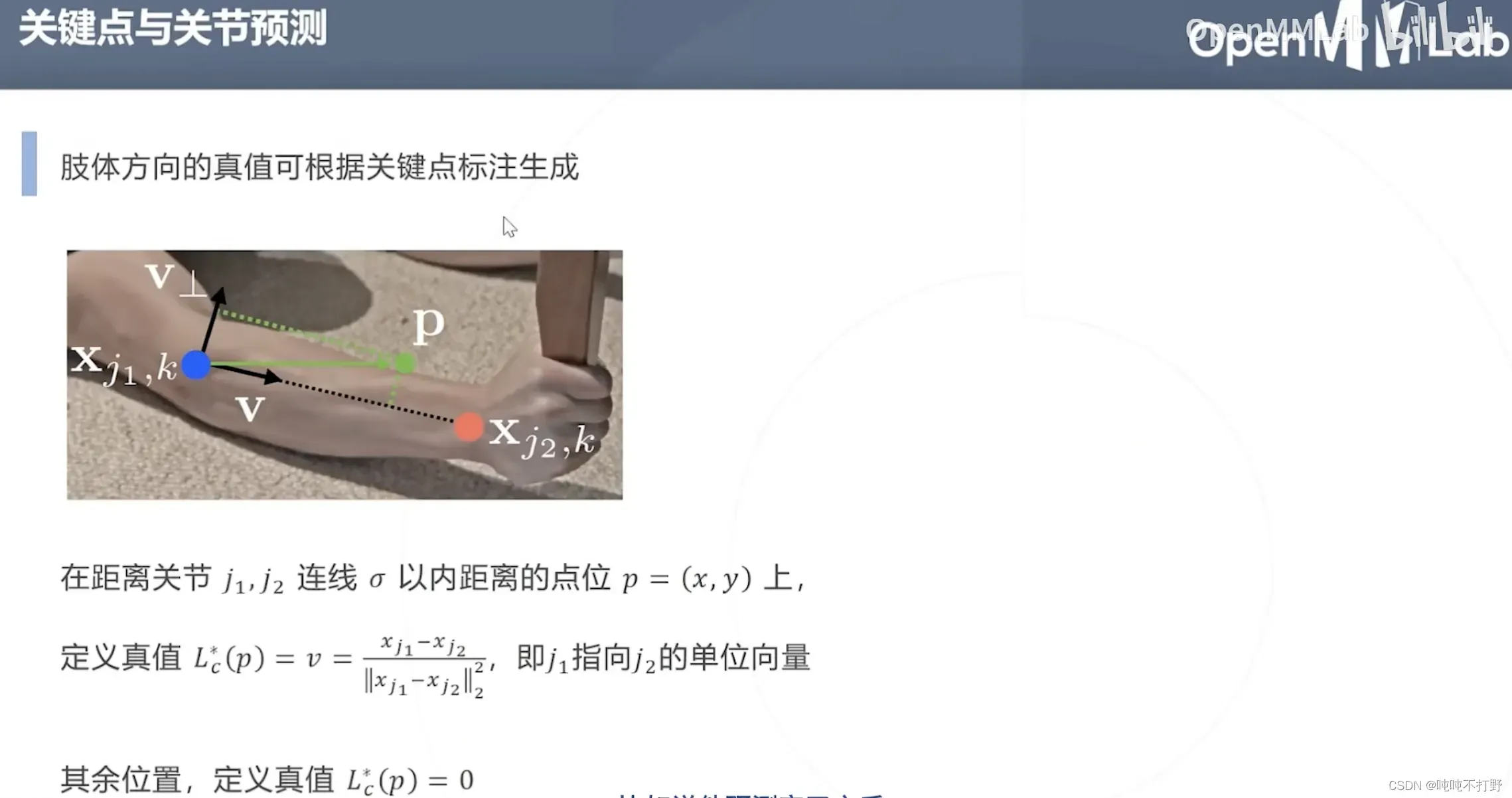

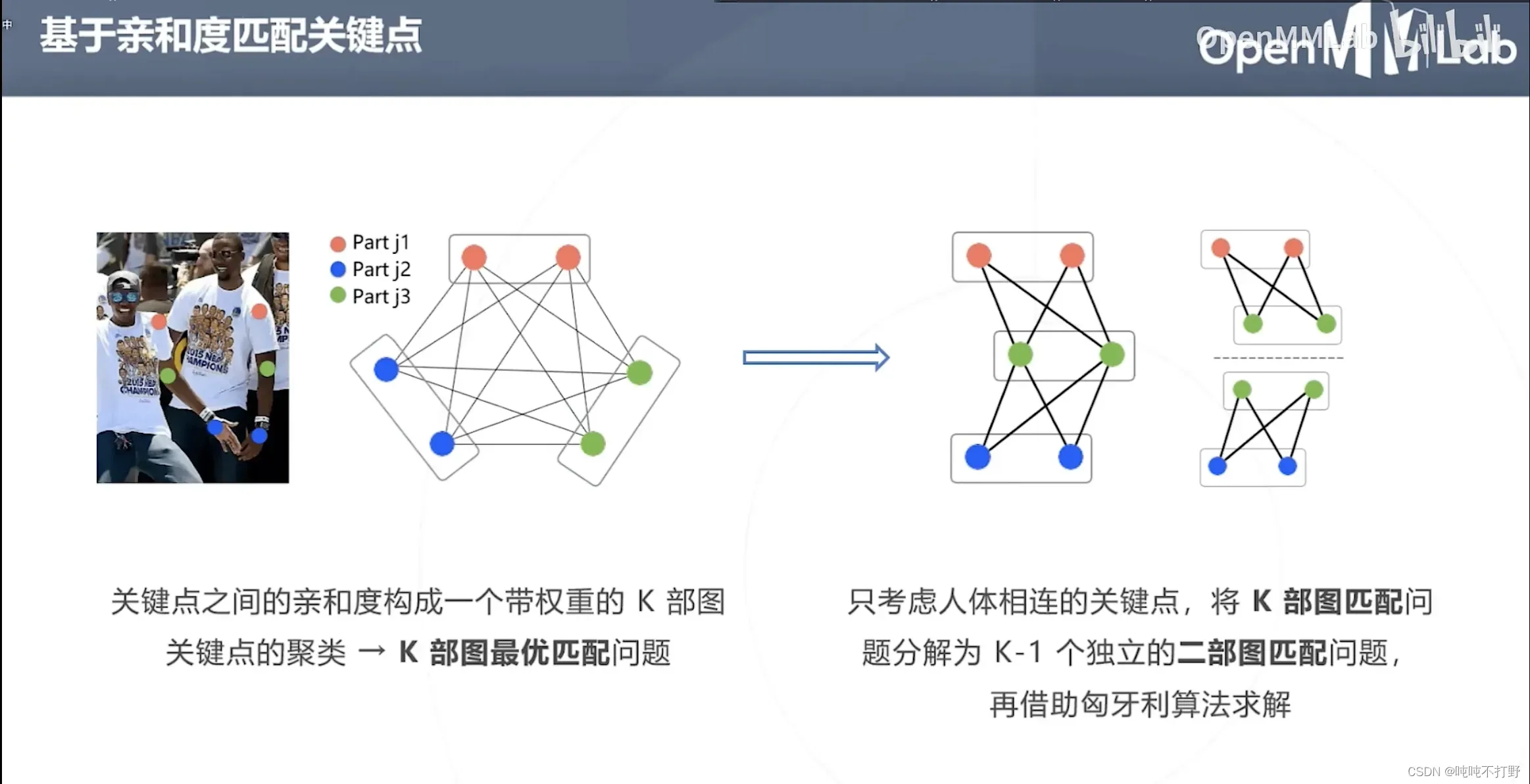
- 关键点就是图里的顶点,关键点之间的亲和度就是顶点连线的权重,构建出了一个带权的图(特殊的图,是K部图)
- 通过对图进行建模,就把关键点的聚类问题转换成K部图最优匹配的问题
2.4 单阶段方法
2.4.1 SPM(2019)
目前在MMPose中也没看到这个网络
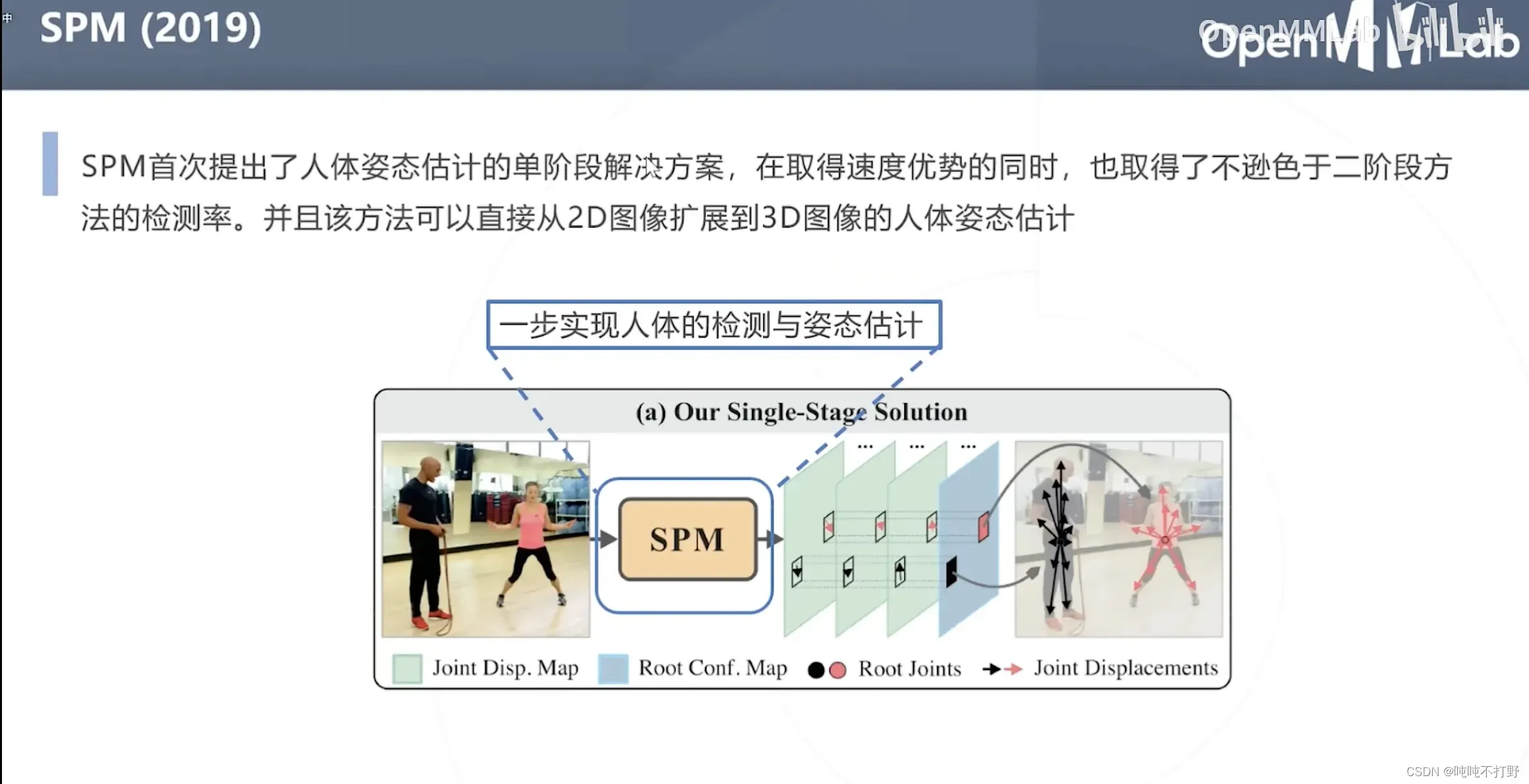
- 目标检测是回归中心点和一个向量(主对角线)
- 这里是回归关键点,以及多个方向向量
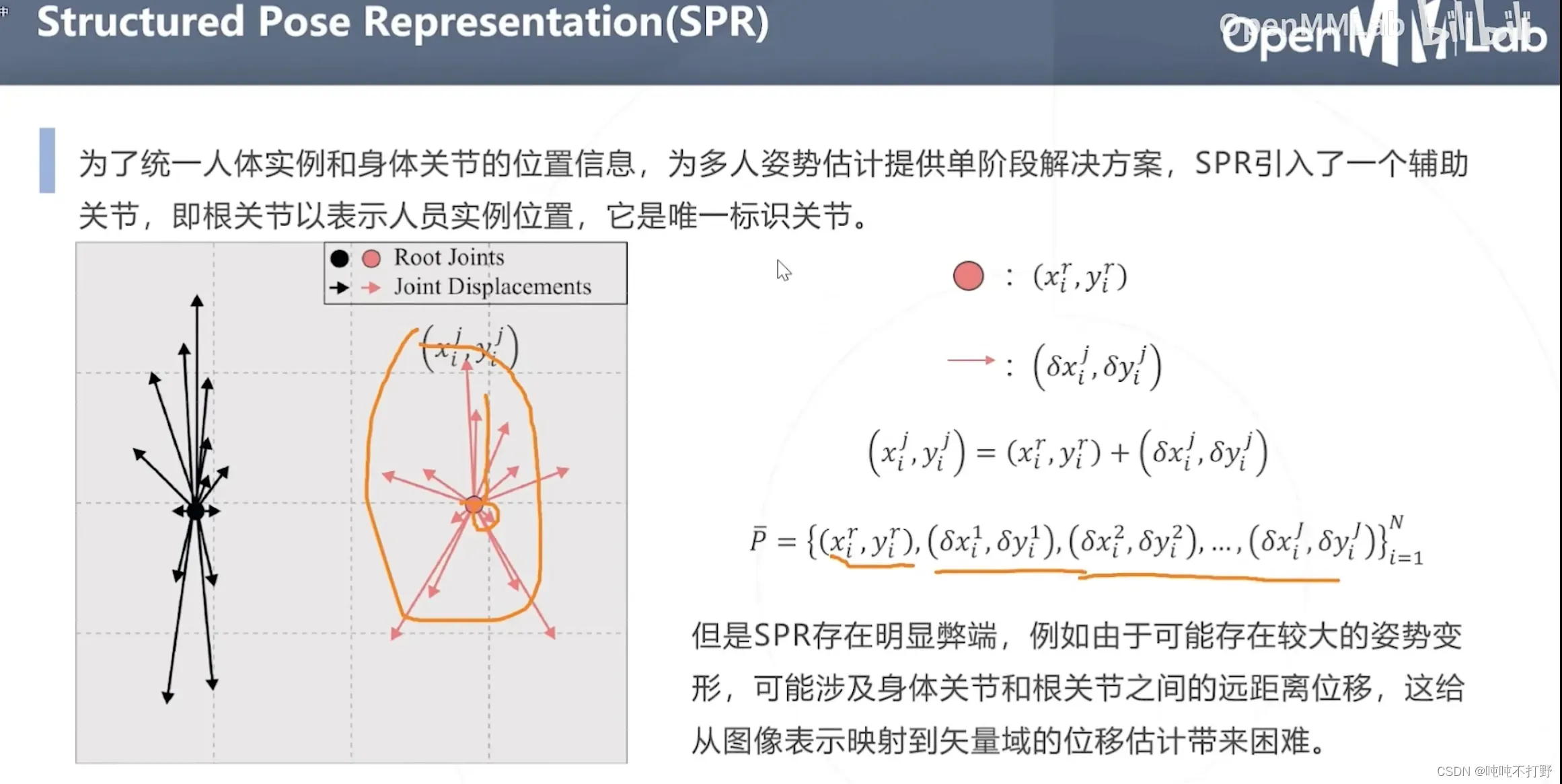
- SPR会学习根关节的位置,其他关键点相对于根关键点的方向(
)
- 这样的弊端就是:如果有较大的姿势变形,涉及身体关节和根关节之间的远距离位移,就会给从图像表示映射到矢量域的位移估计带来困难
- (和上面的那个亲和度差不多),只要是单纯只使用方向向量的,都会产生这个问题
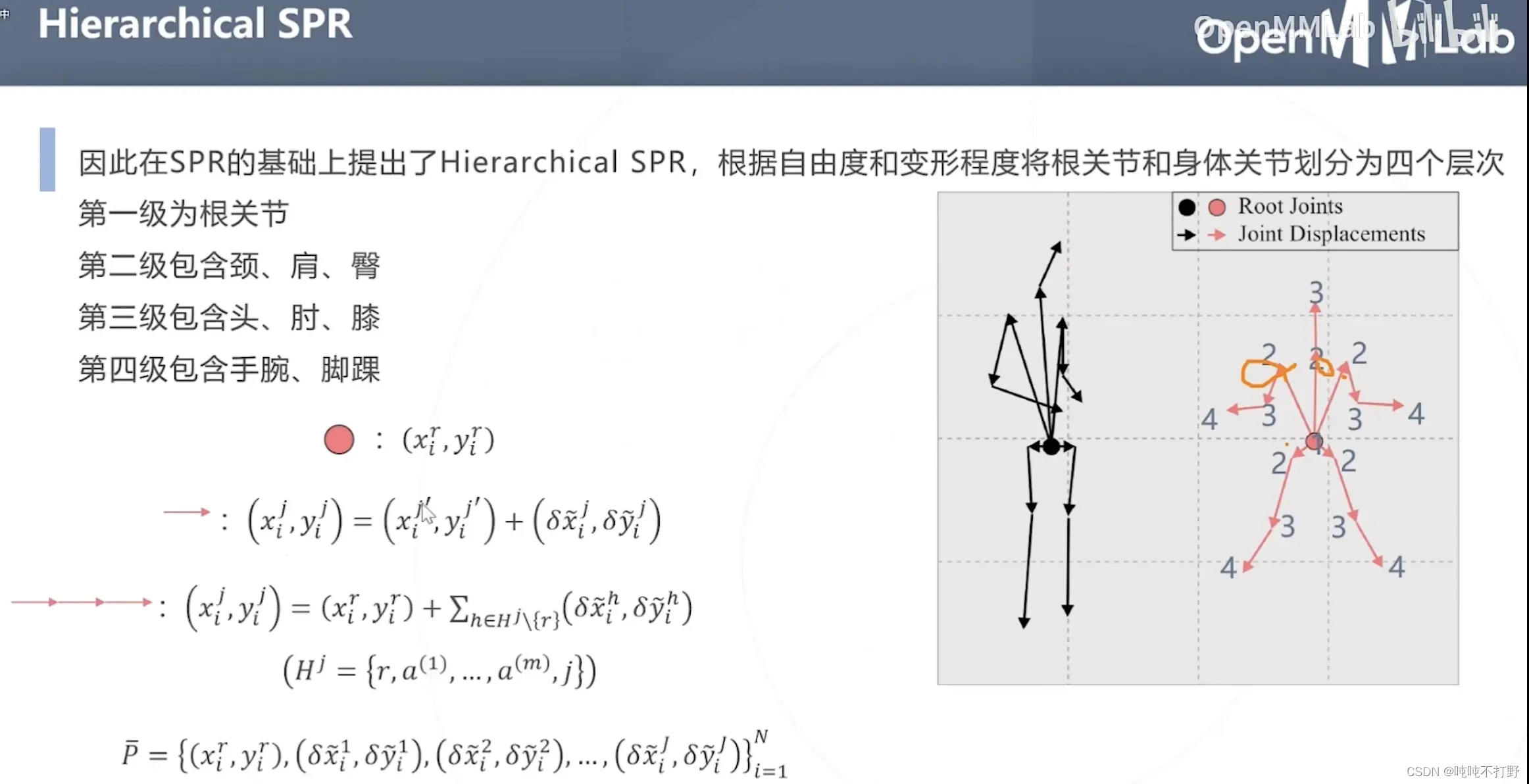
- 第一级:根关节(自由度最低,基本不会变形)
- 第二级:颈、肩、臀(这些关节由于在人体的位置和构造,肩颈的活动范围有限。基本也不会有太大的位移)
- 第三级:手、肘、膝(会有些大的位移和形变)
- 第四级:手腕、脚踝(距离根关节最远,四肢还最灵活,形变程度和位移都最大)

- 置信回归分支,回归关节的热力图
- 额外延伸的一个位移回归分治,估计身体关节位移图(相对于根节点的其他18个关键点的位移)

- 根节点以热力图形式,进行概率回归
- 身体节点位移(方向向量)回归,通过对每个节点构建稠密的位移图,并规定位移量在一定的范围内(亲和度根据真值生成肢体方向的真值时,也是会规定关节之间的范围)后,对所有非零量取平均得到

是根关节置信度的L1 loss,
是位移图的L2 loss
说明确定根关节的位置更重要。。。根关节确定后,位移图才有正确的可能
- 这个值的取法是有技巧的,可以思考一下
2.5 基于Transformer的方法
2.5.1 PRTR(2021)-两阶段算法(基于回归的)
MMPose的网络里没有
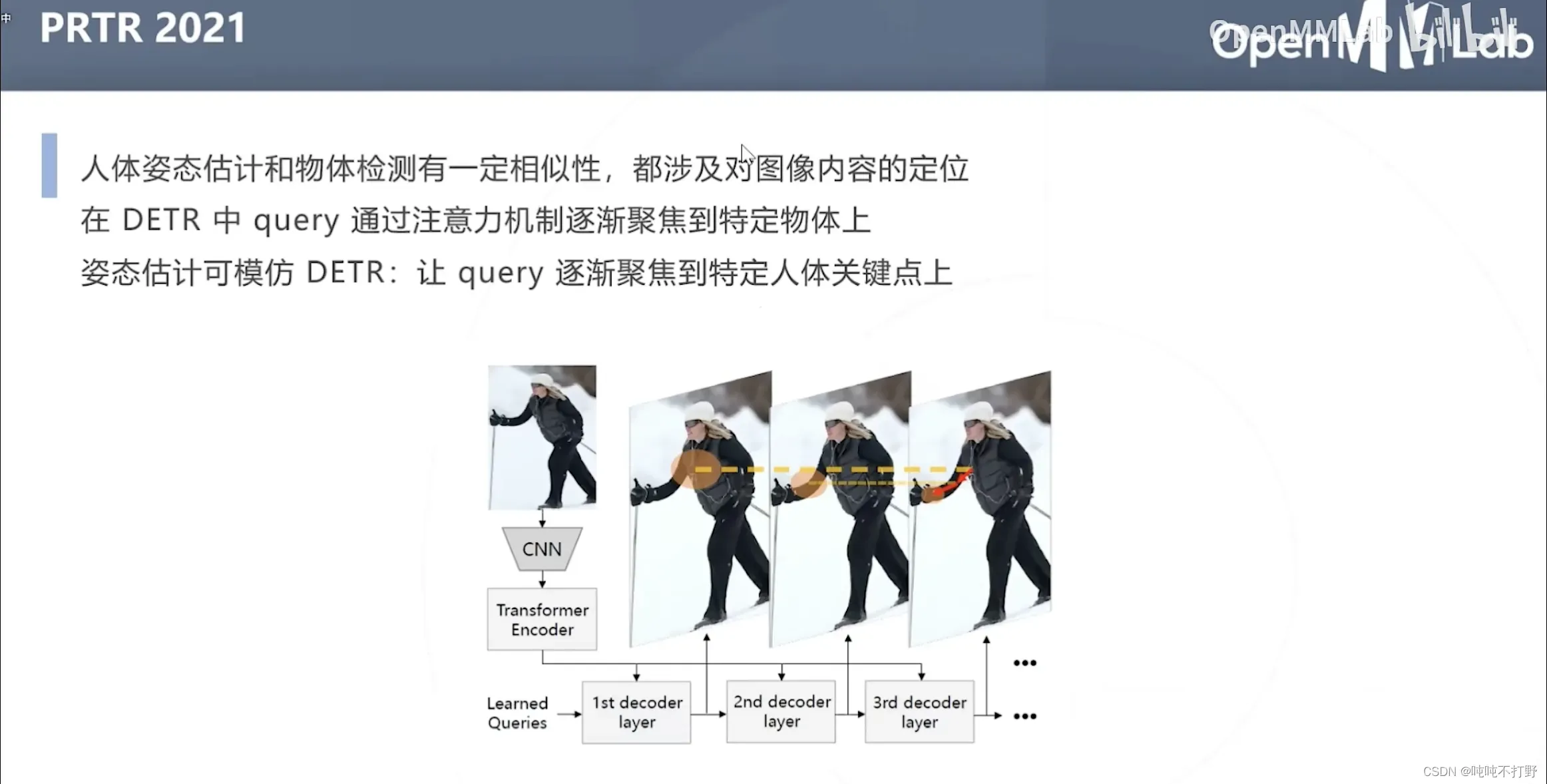
- DETR中query通过注意力机制逐渐聚焦到特定物体上
- 类似的,姿态估计中也可以让query逐渐聚焦到特定人体关键点上
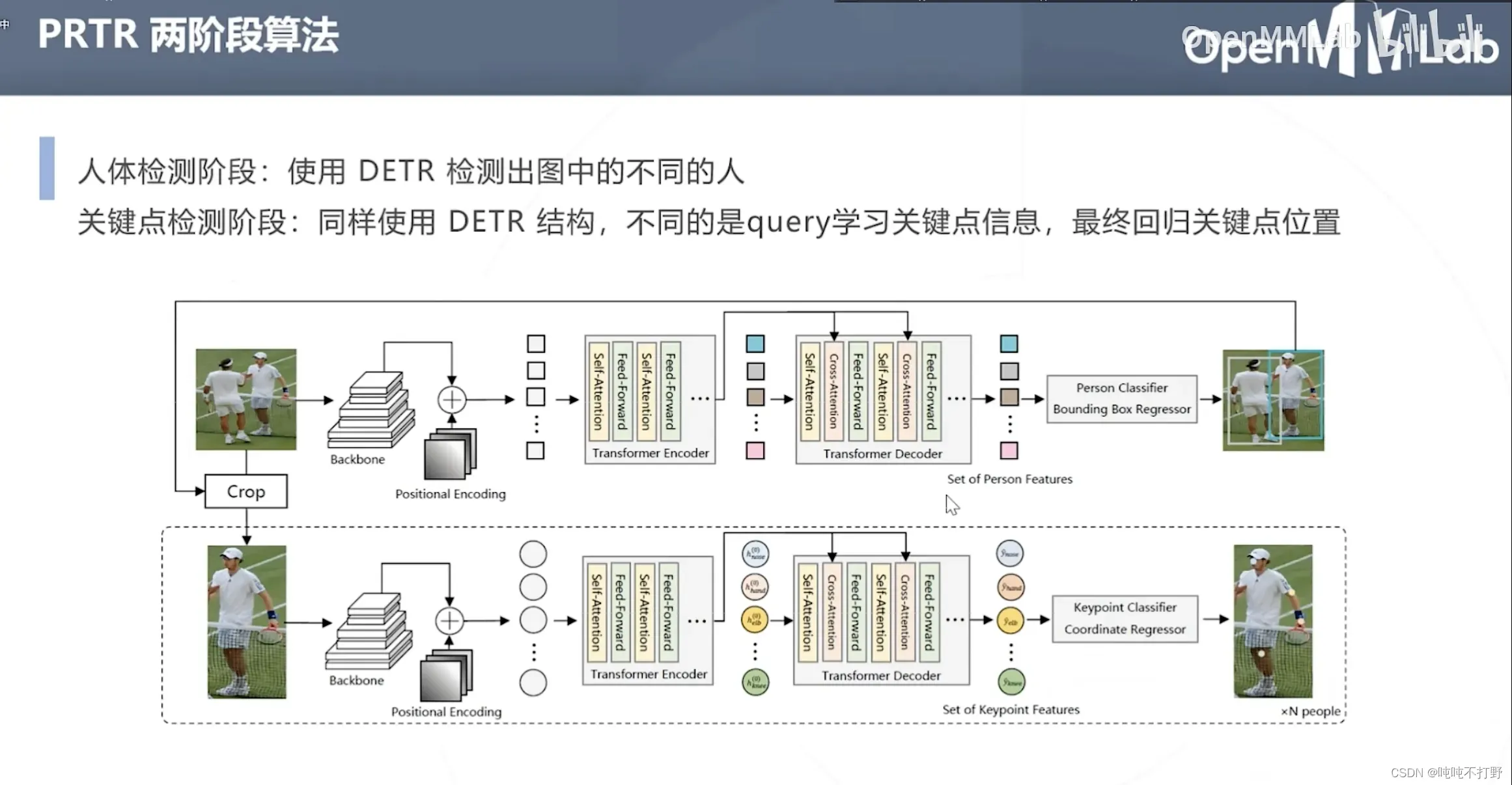
- DETR先检测出人体
- 同样使用DETR结构,只是此时query的不是人体的位置,而是关键点的信息,并最终回归关键点的位置
- 结构是是类似的,都是有个backbone+位置嵌入,然后Transformer的Encoder和decoder,
- 上面人体检测得到的是人体特征,是bounding box回归(中心点+方向,或者左上点坐标+高宽),
- 下面是关键点特征,是关键点回归
- 另外,这里有个Crop,就是从完整特征图中裁剪出单人对应的图像特征,用于后续关键点检测
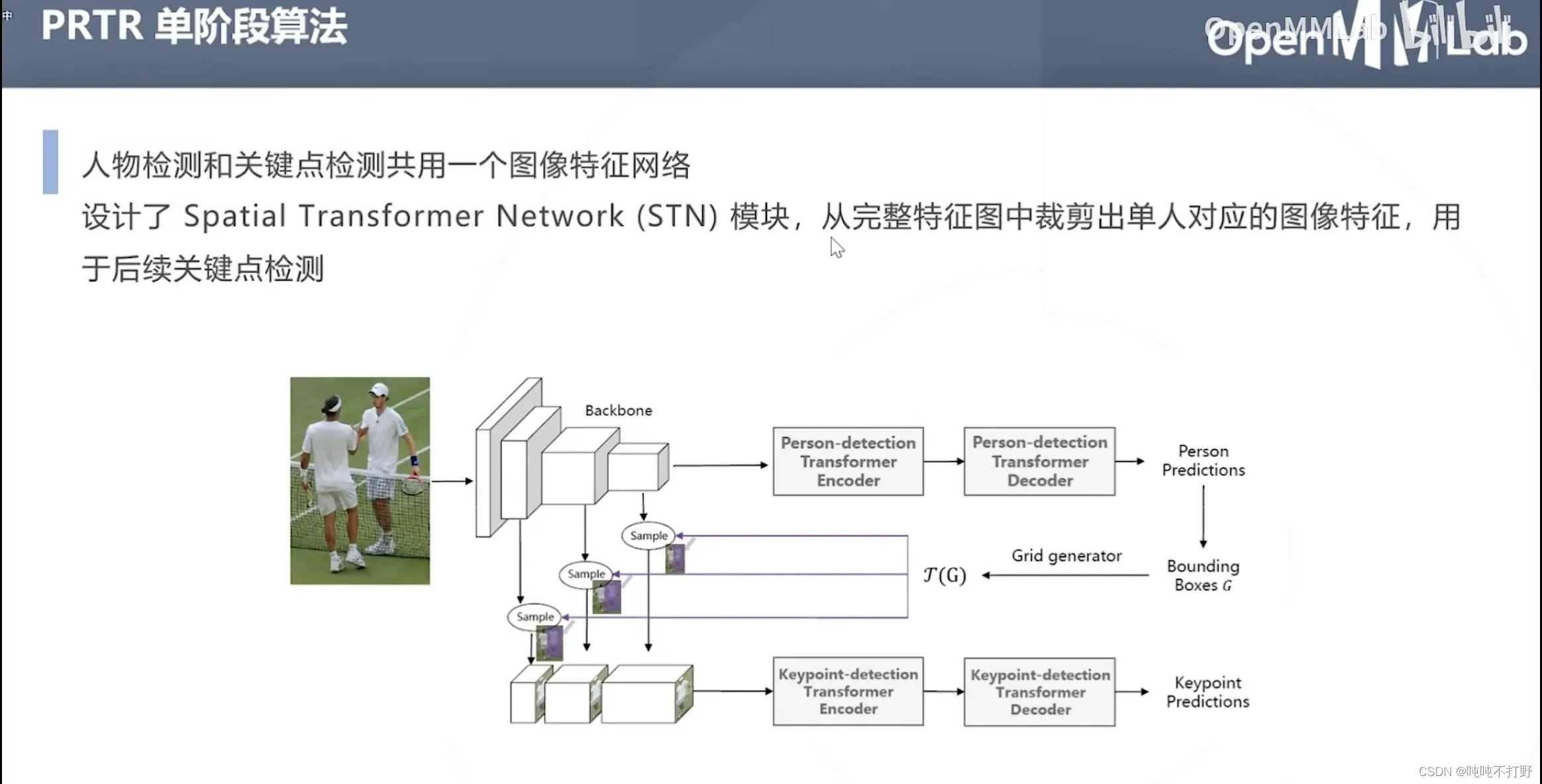
- 设计了Spatial Transformer Network(STN)模块,从完整特征图中裁剪出单人对应的图像特征,用于后续关键点检测
- 则关键点检测部分的backbone网络,就不用做重复训练了。
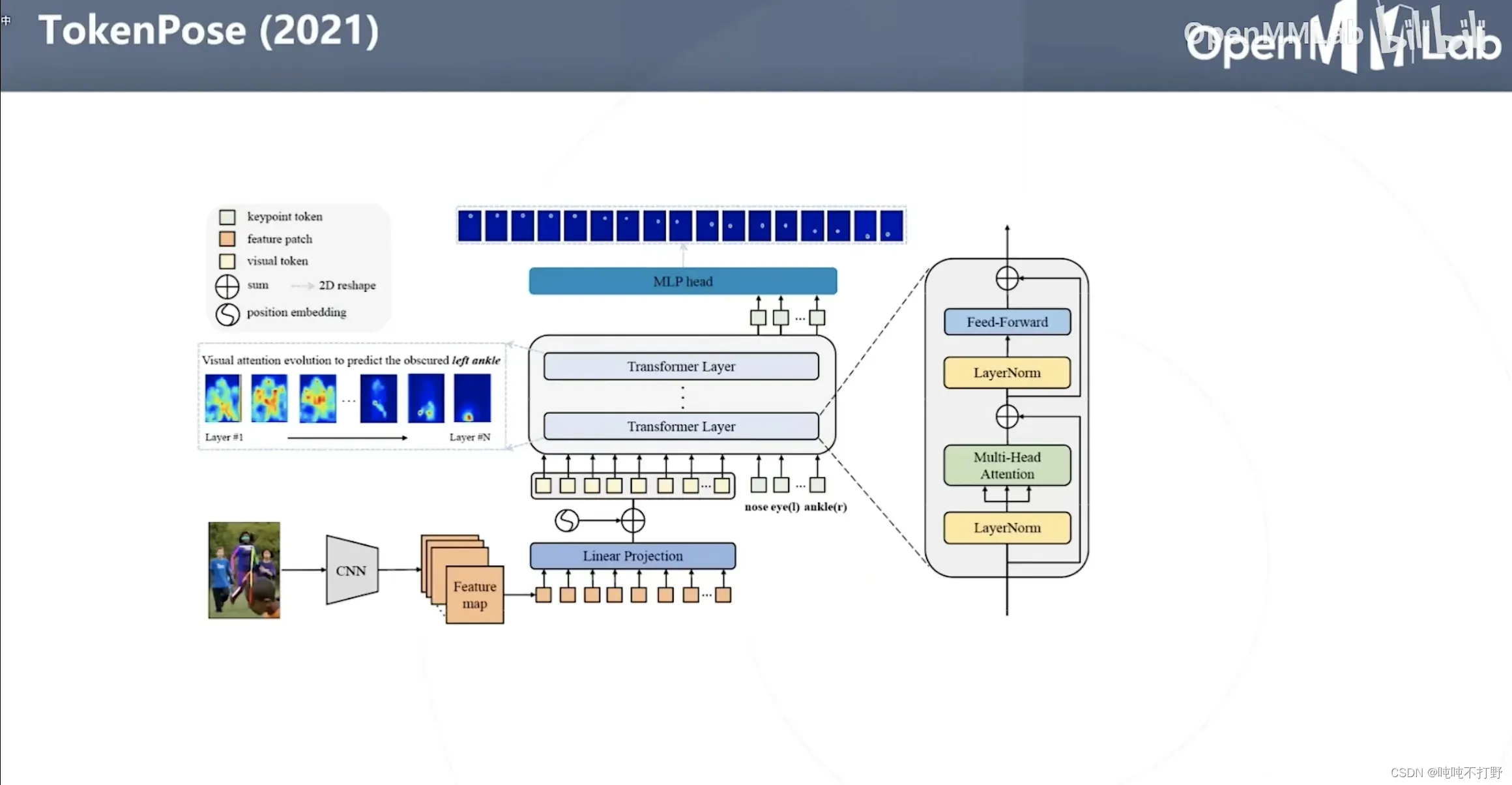
2.5.2 TokenPose(2021)(基于热力图的)
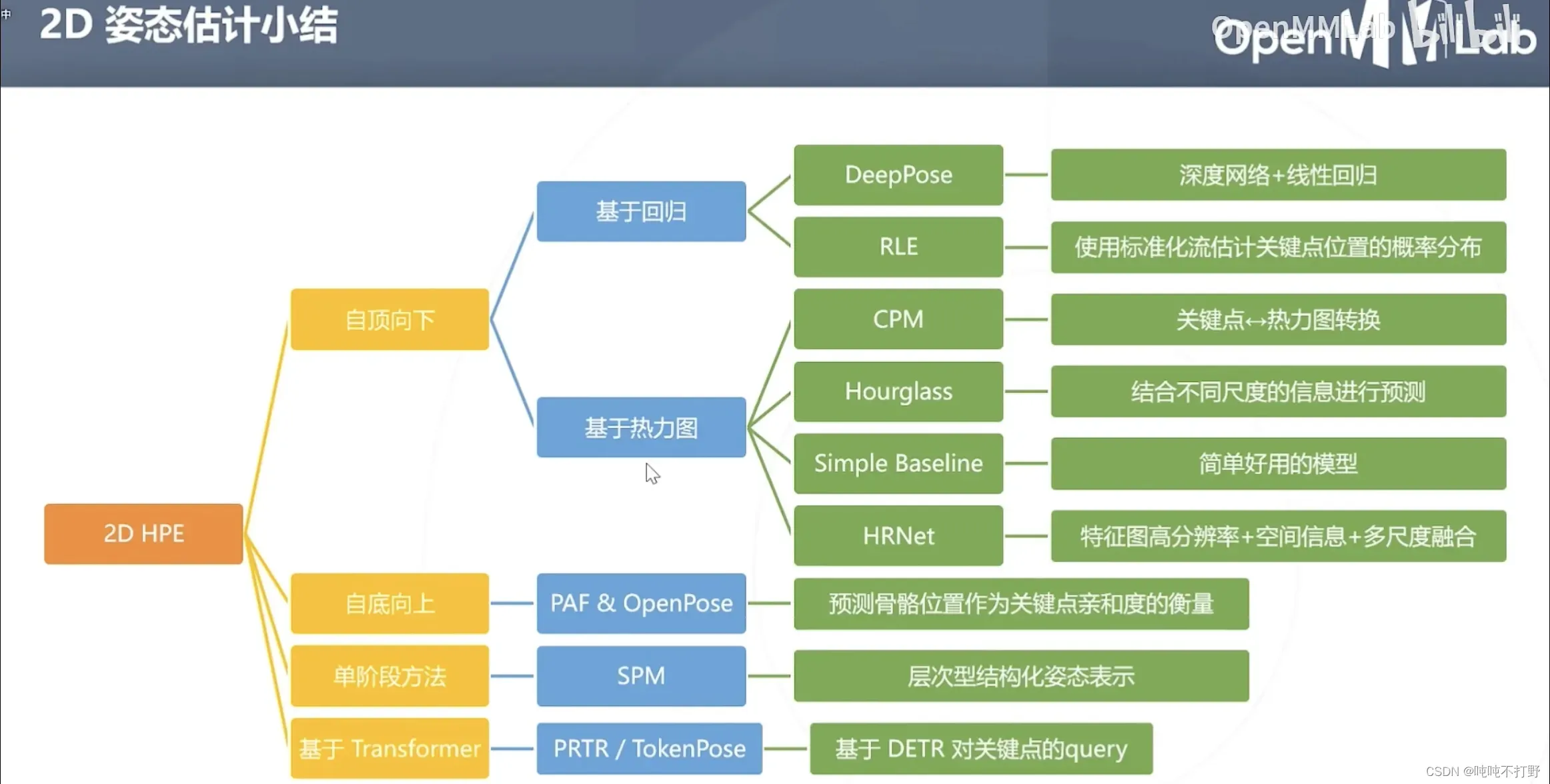
2.6 2D姿态估计小结
3. 3D姿态估计
3.1 任务描述

- 这里对3D的描述是相对的,给的如果是2D图,去生成3D本来也不太合适。。
- 并没有准确的深度信息
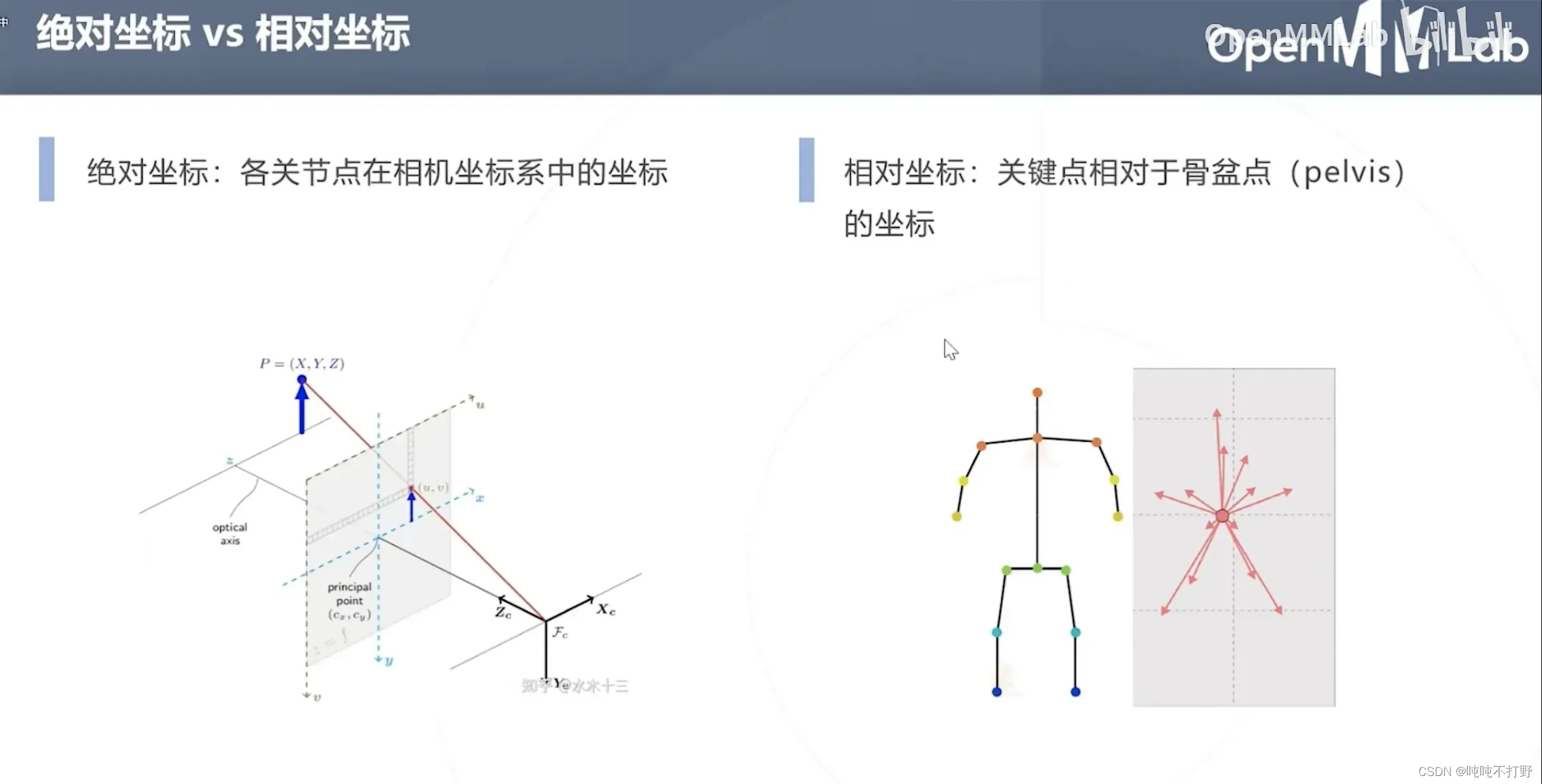

难点,如何从2D恢复3D信息
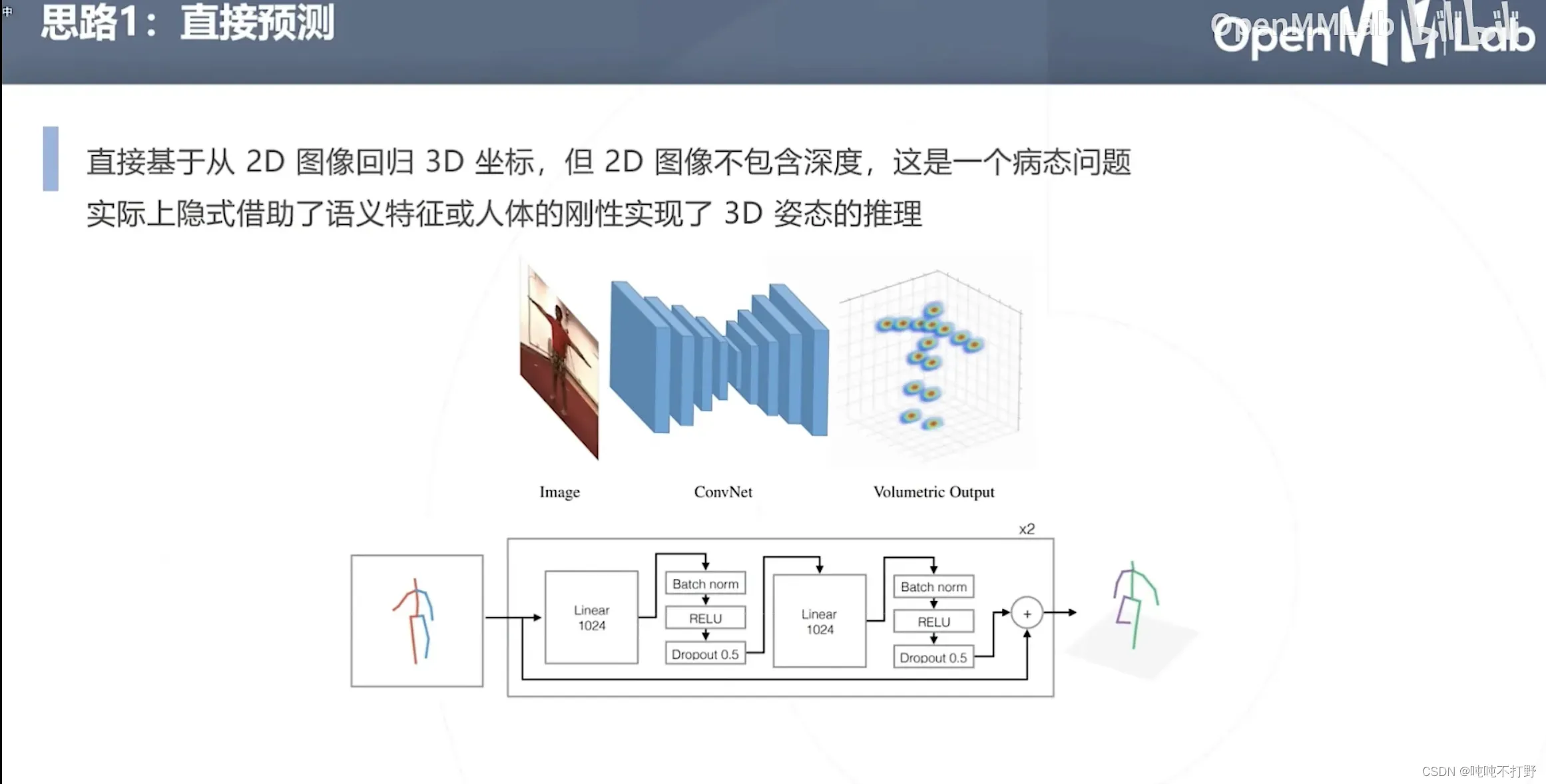
方式1:直接预测
- 直接从2D图像回归3D坐标,但是2D图像不包含深度,这是一个病态问题。
- 实际上可以借助语义特征(人体是有一个先验知识的),并且人体是刚性的来实现3D姿态的推理
- 对于一张2D图像,由于人体是先验且刚性的(可以理解为有个模板,同时这个模板不会发生太大的改变),人体的厚度/深度其实是一个可以推断的信息
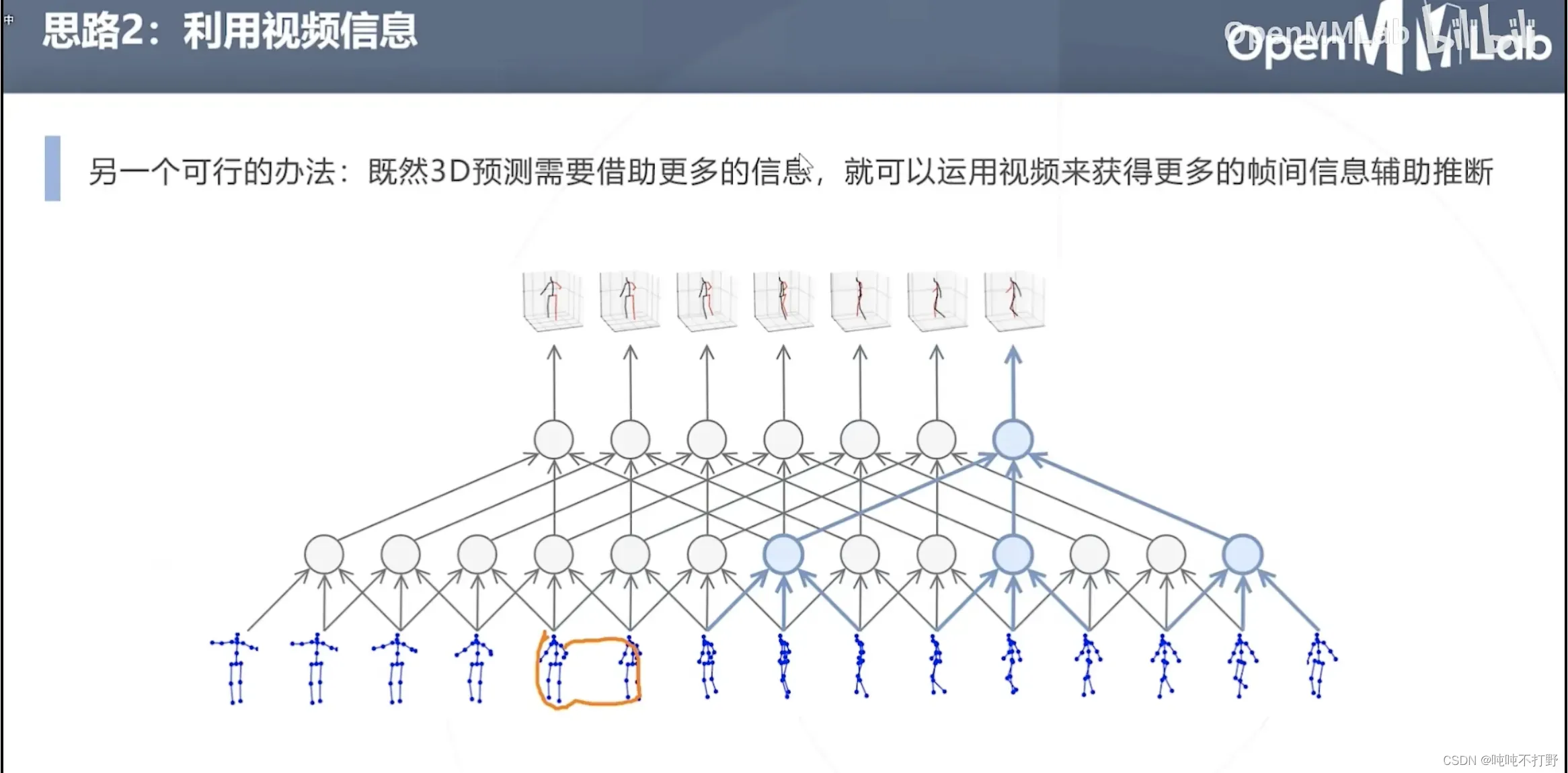
方式2,利用视频信息
- 直接从2D推理到3D,可能会有病态的问题(生成的结果看起来不符合人体结构)
- 借助视频的帧间信息辅助判断,两帧视频之间,人体姿态并不会发生特别大的变化,
- 上面的原图(动态图)来自:https://dariopavllo.github.io/VideoPose3D/#demo

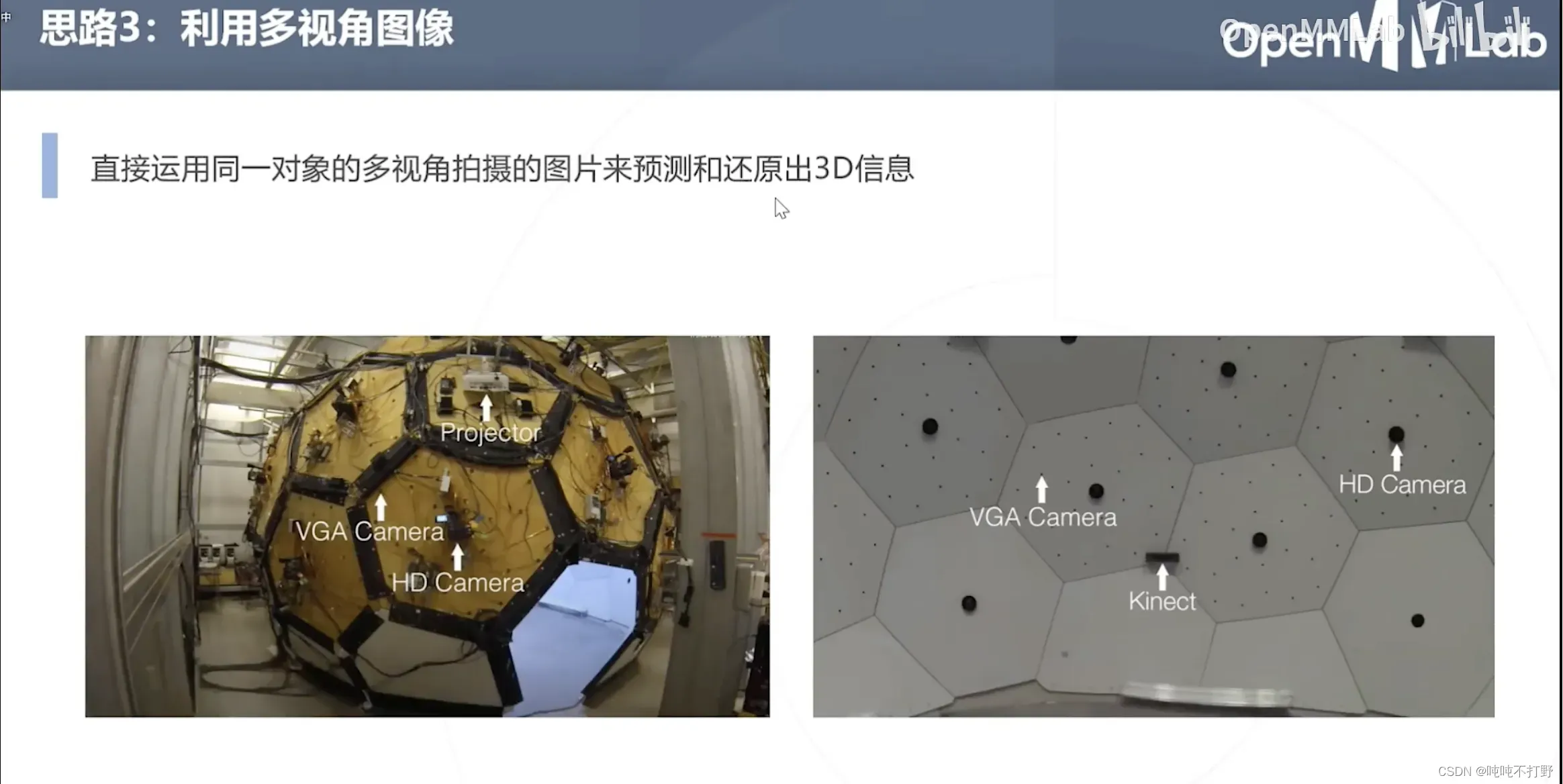
方式3:利用多视角图像
直接运用同一对象的多视角拍摄的图像来预测和还原出3D信息(2D图像生成3D模型)
3.2 方法介绍
3.2.1 Coarse-to-Fine Volumetric Prediction 2017
粗粒度到细粒度,体数据预测??
论文地址:Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose
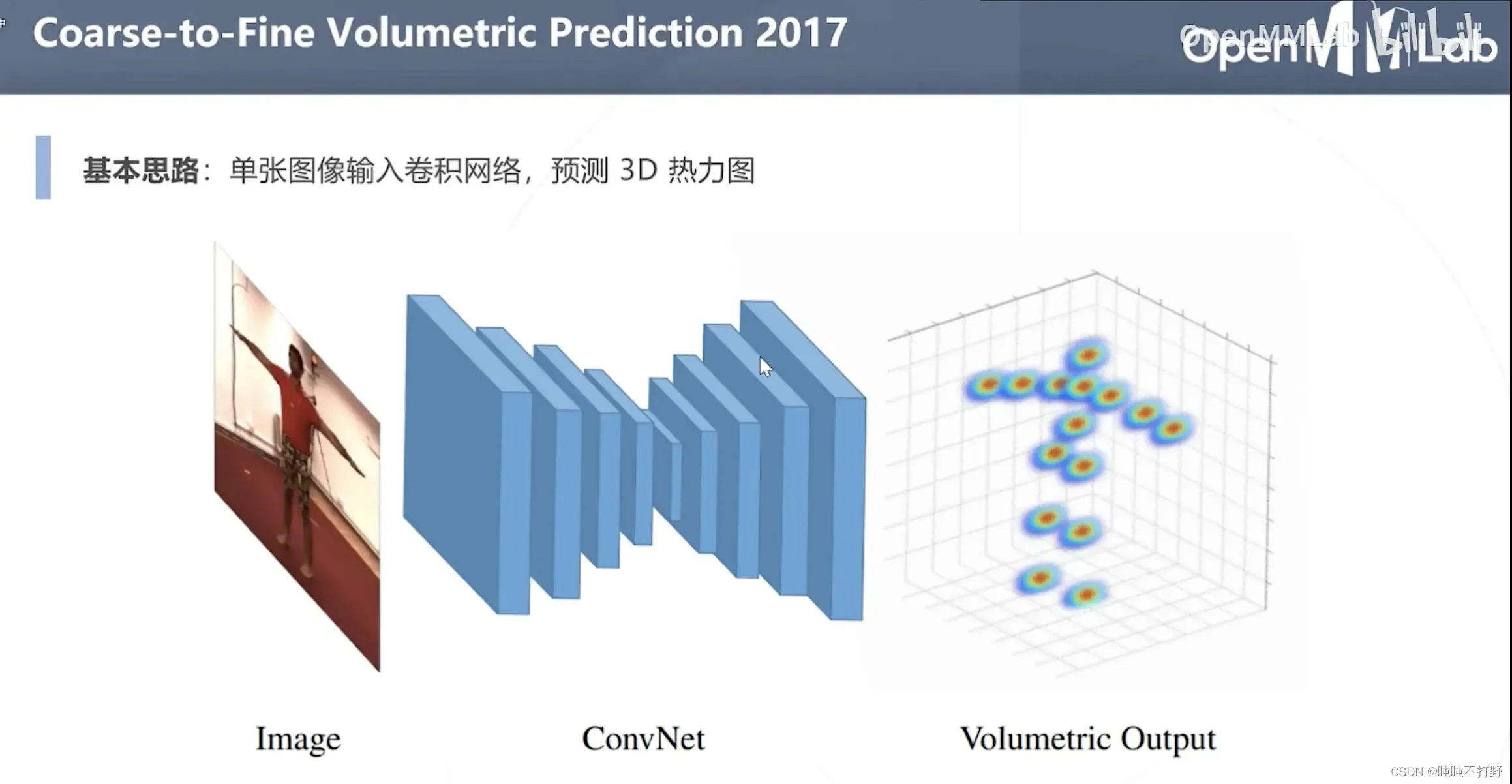
注意,这里输出的就是一个3D的热力图了(Volume 一般指体数据,3D数据)
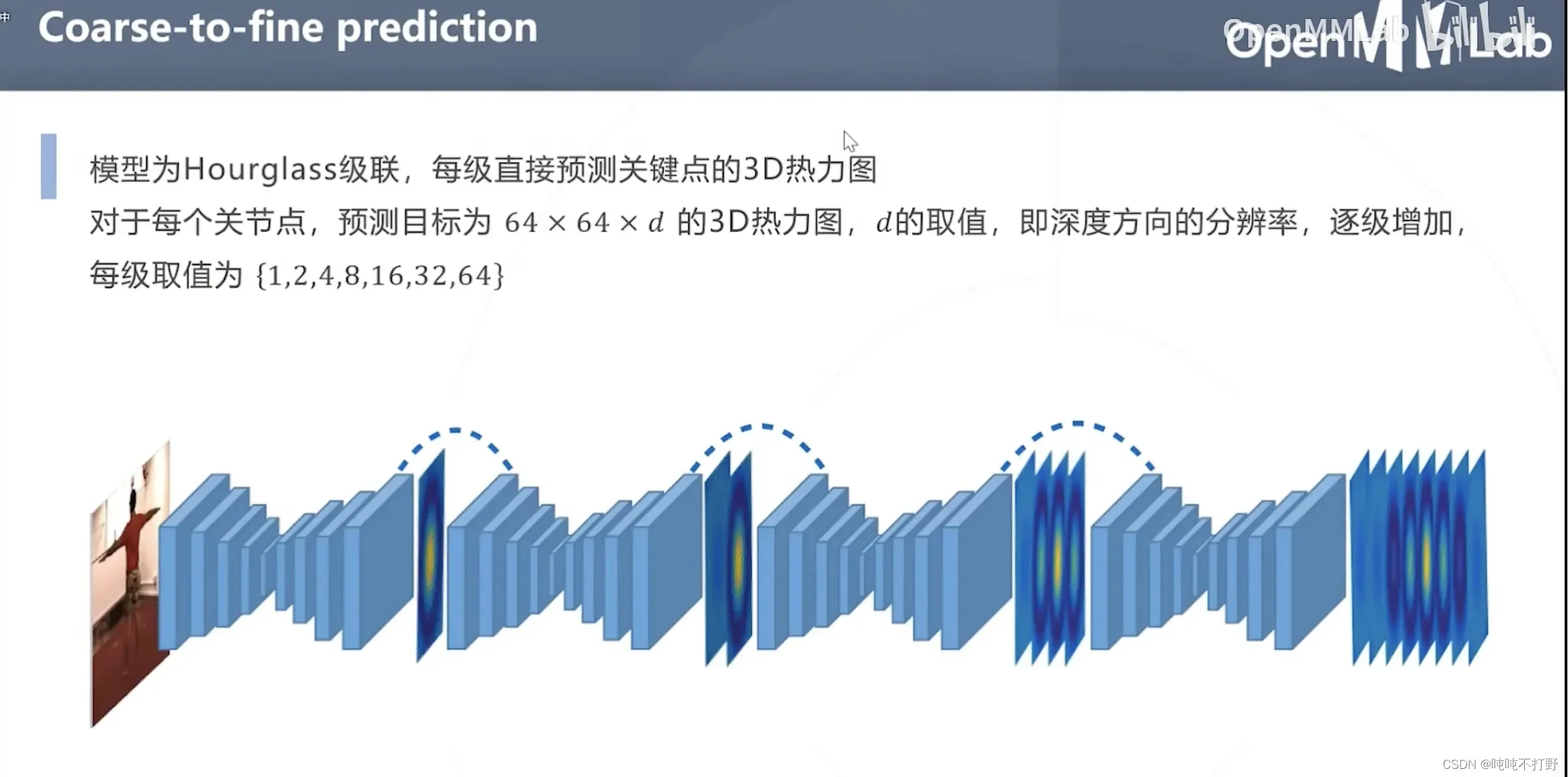
采用的是Hourglass级联,深度信息每次逐渐加深,8个Hourglass对应的输出的3D热力图的级联部分的深度大小依次为:{1,2,4,8,16,32,64},(,7个输出),最后一个Hourglass没有级联了,就是自己最后的输出,也是64
3.2.2 Simple Baseline 3D(2017)
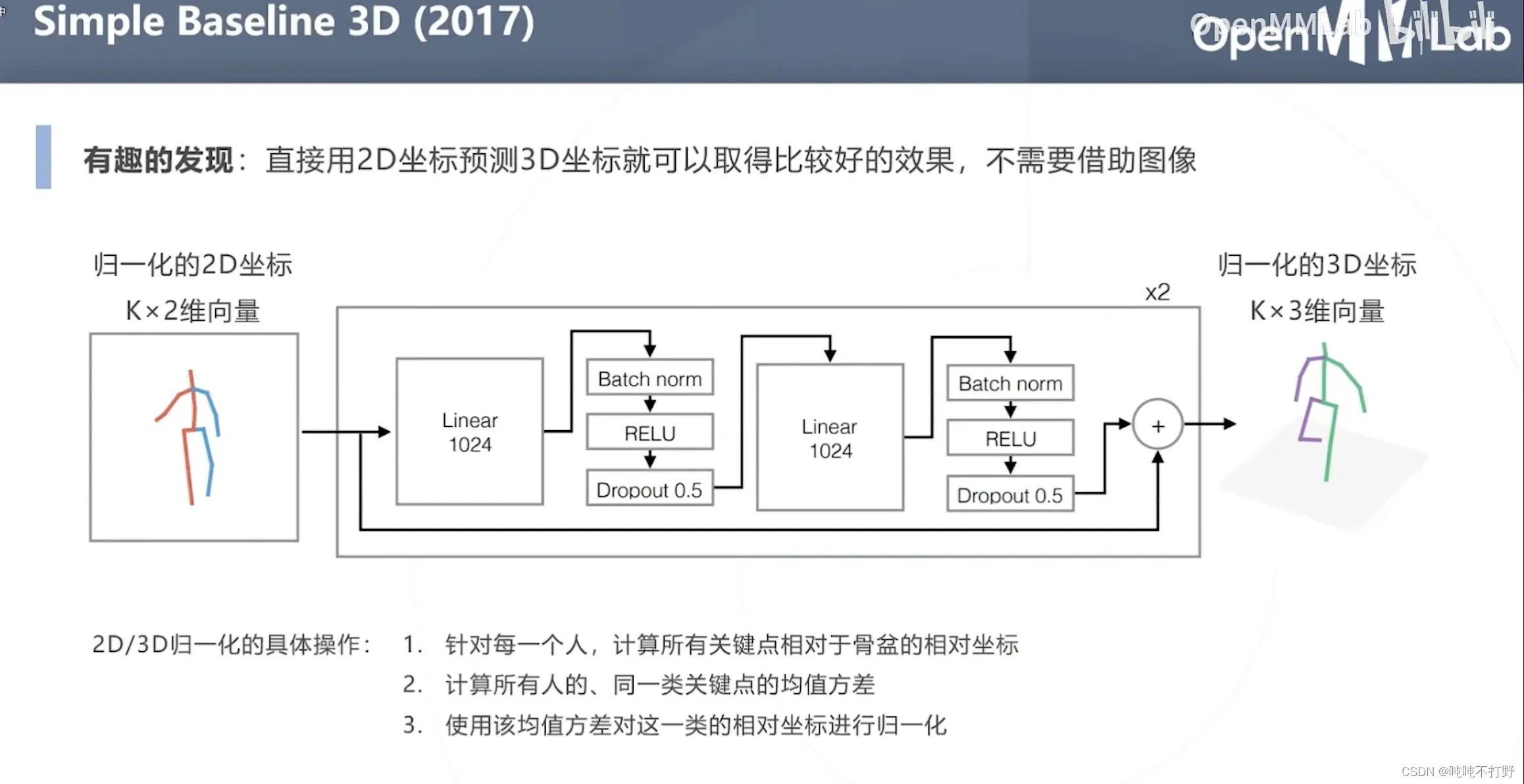
直接用2D坐标预测3D坐标就可以取得比较好的效果,不需要借助图像
- 输入就是归一化的2D坐标,输出就是归一化的3D坐标,不需要使用图像信息。。用的网络也很简单,基本都是全连接层,用了一些防止过拟合的手段。。
- Amazing😗😗😗!
- 单纯依靠2D坐标去得出3D姿态估计,其实这里面肯定会存在一些病态问题,比如右脚是前翘还是后翘,
- 病态问题:指输出结果对输入数据非常敏感的数值分析问题. 对一个数值分析问题, 如果输入数据有微小误差,引起问题解的相对误差很大, 那么称这个问题为病态问题. 一般而言, 病态问题是指条件数很大的数值分析问题.
3.2.3 VideoPose3D
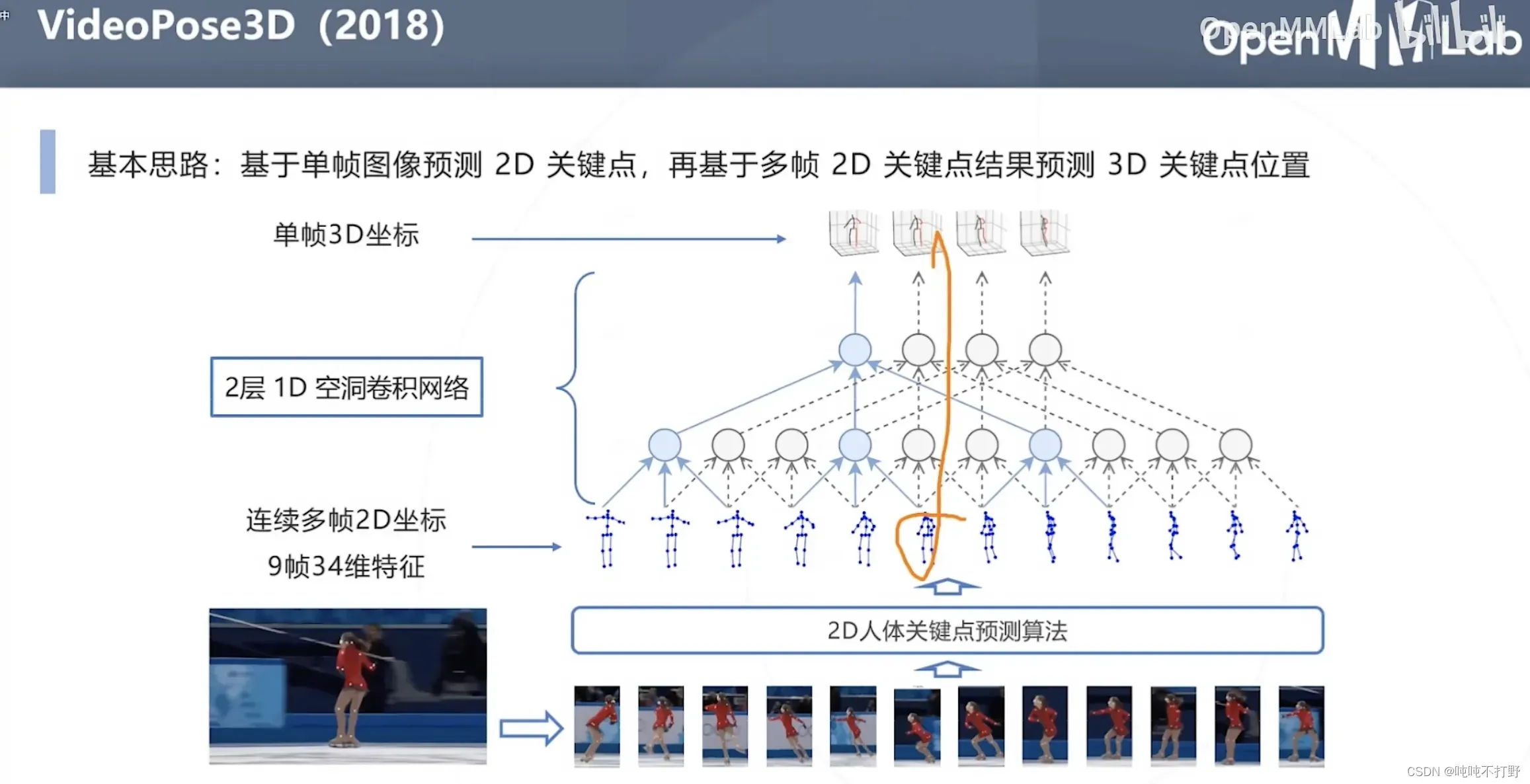
- 上面的原图(动态图)来自:https://dariopavllo.github.io/VideoPose3D/#demo
基本思路:
- 单帧图像预测2D关键点,再基于多帧的2D关键点的结果预测3D关键点的位置
- 单帧算3D可能会有病态(直接从2D图预测3D坐标会有病态问题),但是帧数多了之后,就会一定程度上消除病态性
3.2.4 VoxelPose(2020)
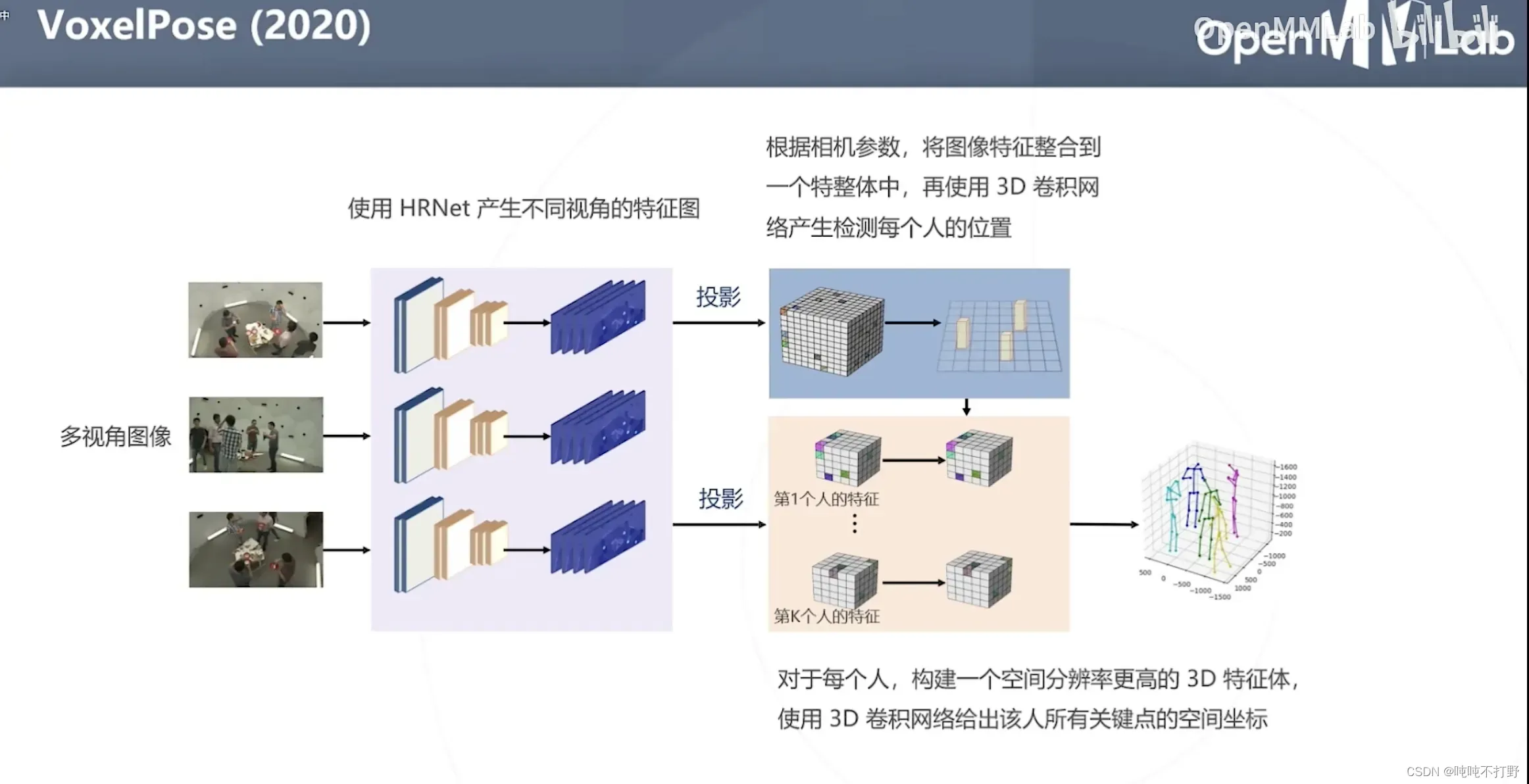
输入是多视角图像,中间就会利用多视角所来源的相机,根据相机参数来进行3D模型的建立。
4. 人体姿态估计的评估方法/指标

PCP-以肢体检出率为评价指标,算上头其实一共是9个肢体
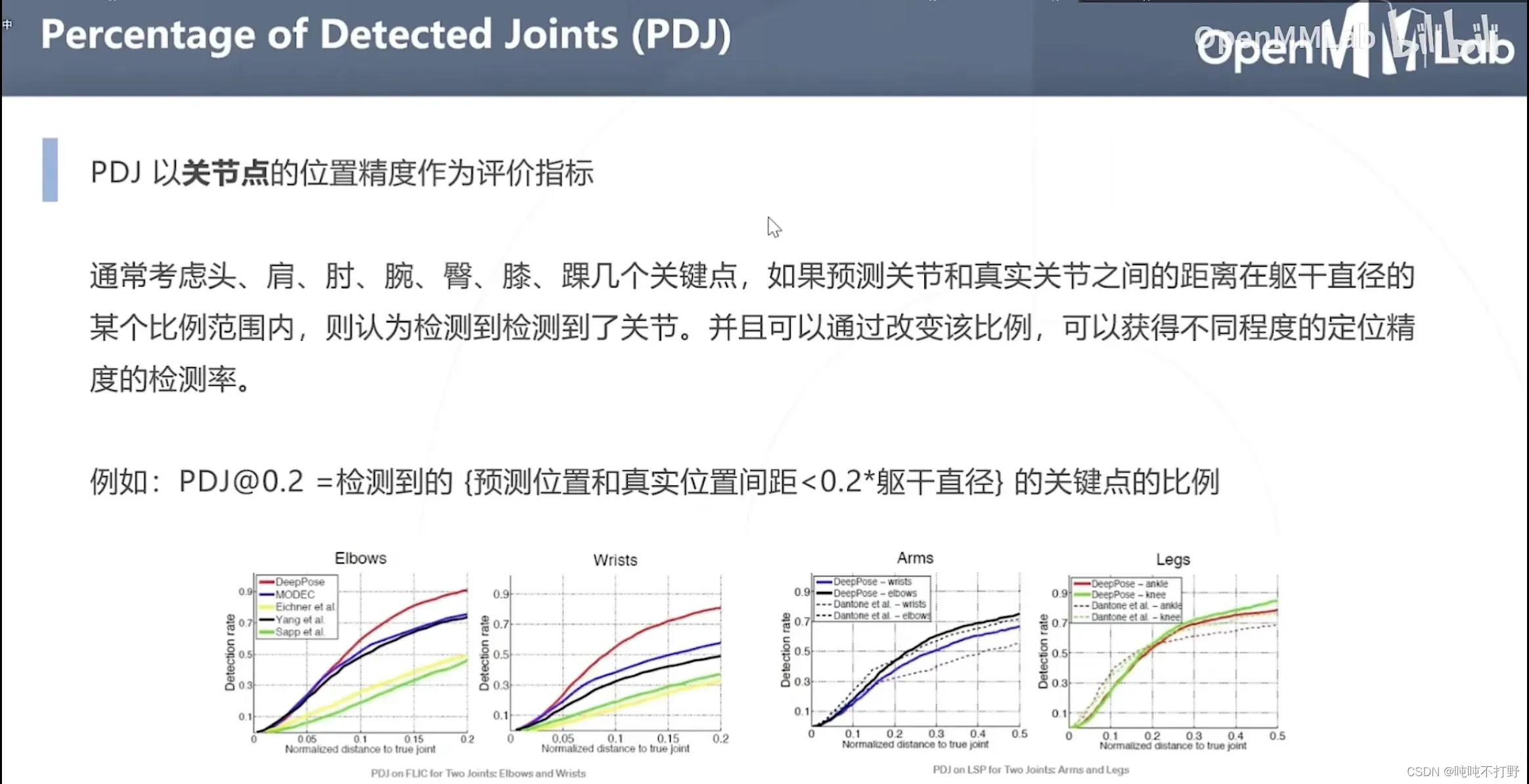
PDJ-以关节点的位置精度作为评价指标,可以获得不同级别的定位精度的检测率,用比例定义距离
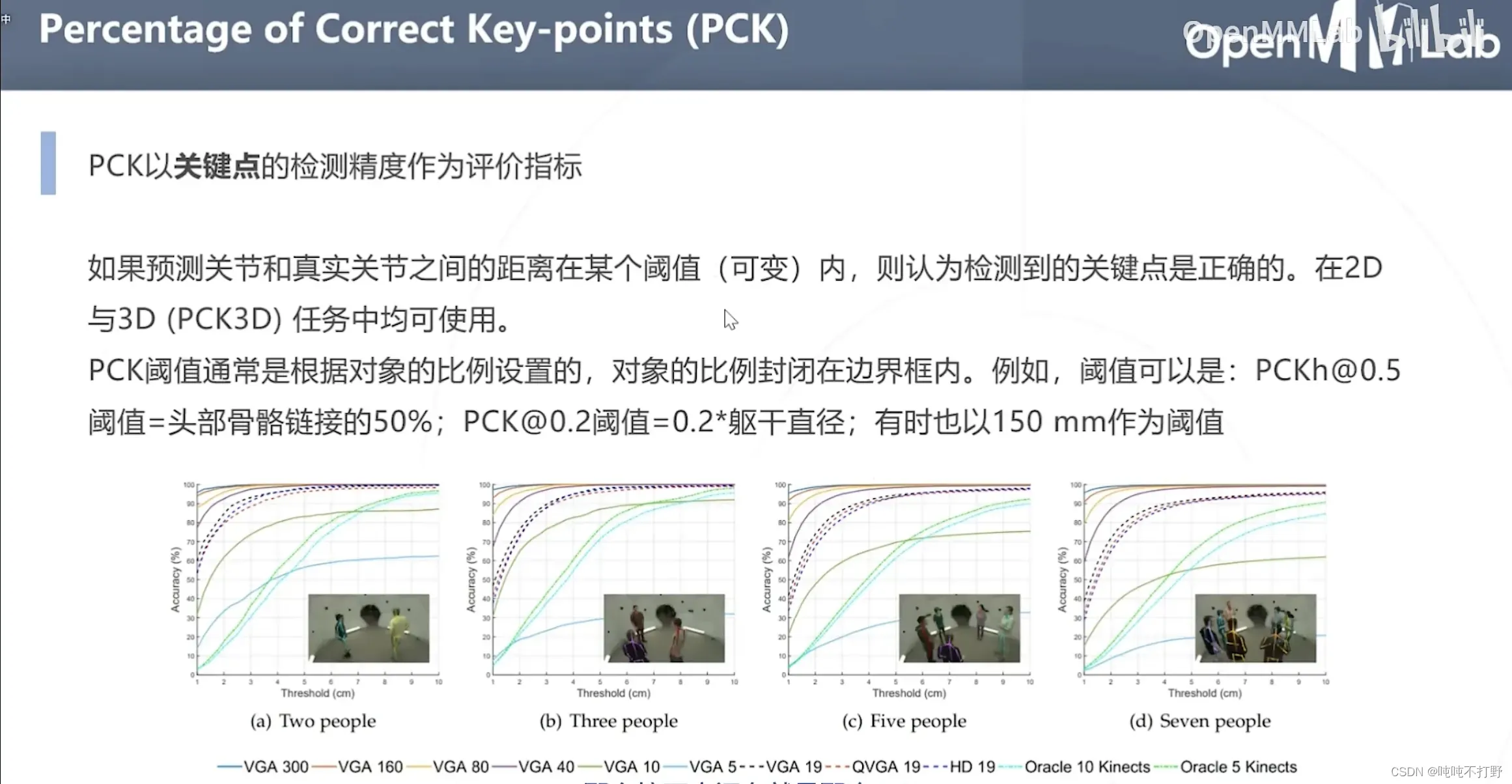
PCK-以关键点的检测精度作为评价指标,不是靠距离比例,直接设定一个距离阈值(设定的时候也可以根据比例去设置,这样设置最简单,没有什么特殊缘由),2D和3D里都可以用这个指标

略微有些复杂,如果想要这页ppt的文字表述,可以看看这位兄弟的MMPose学习笔记1,我真的懒得打字了。
5. DensePose(人体表面参数化)
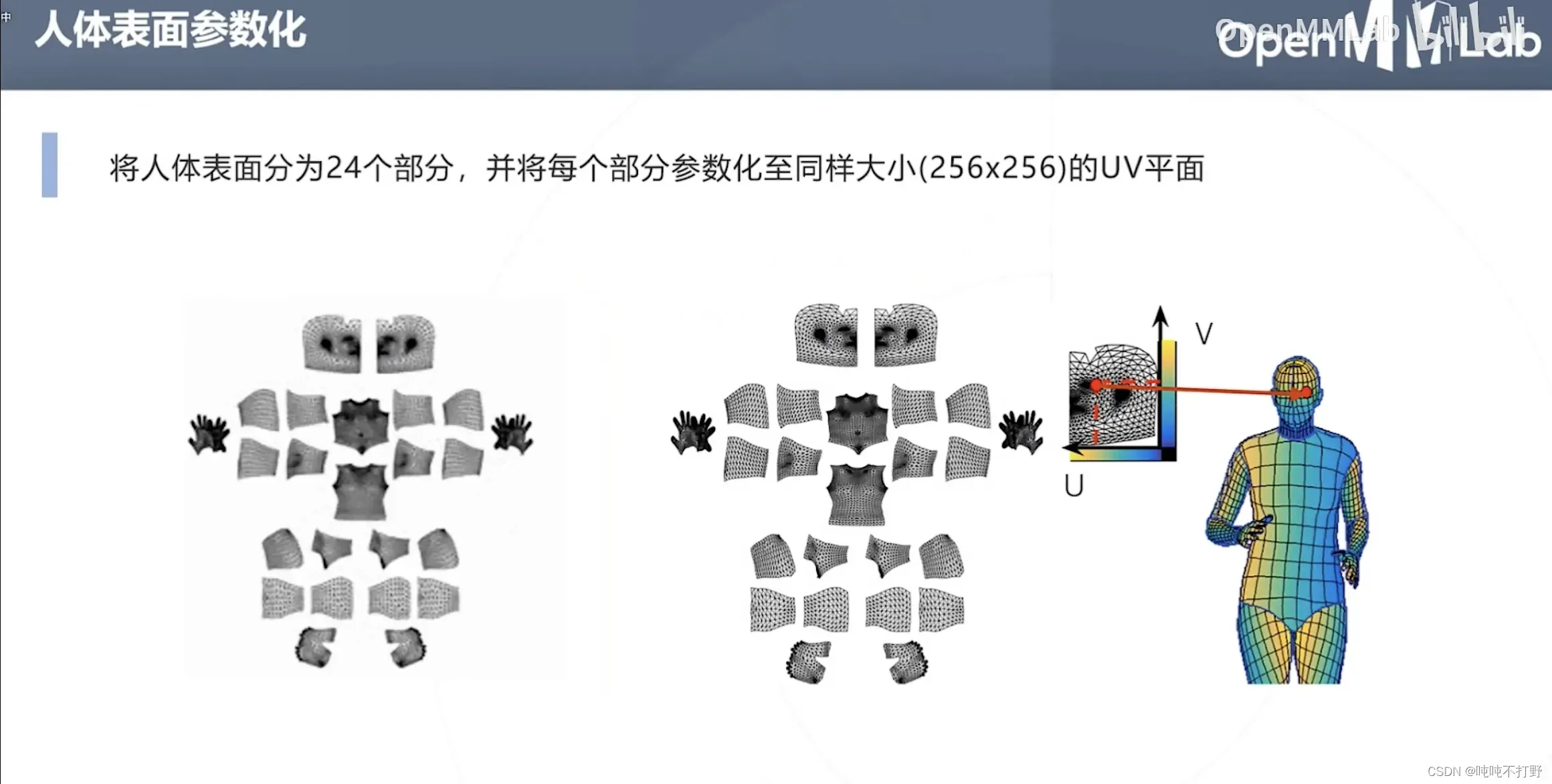
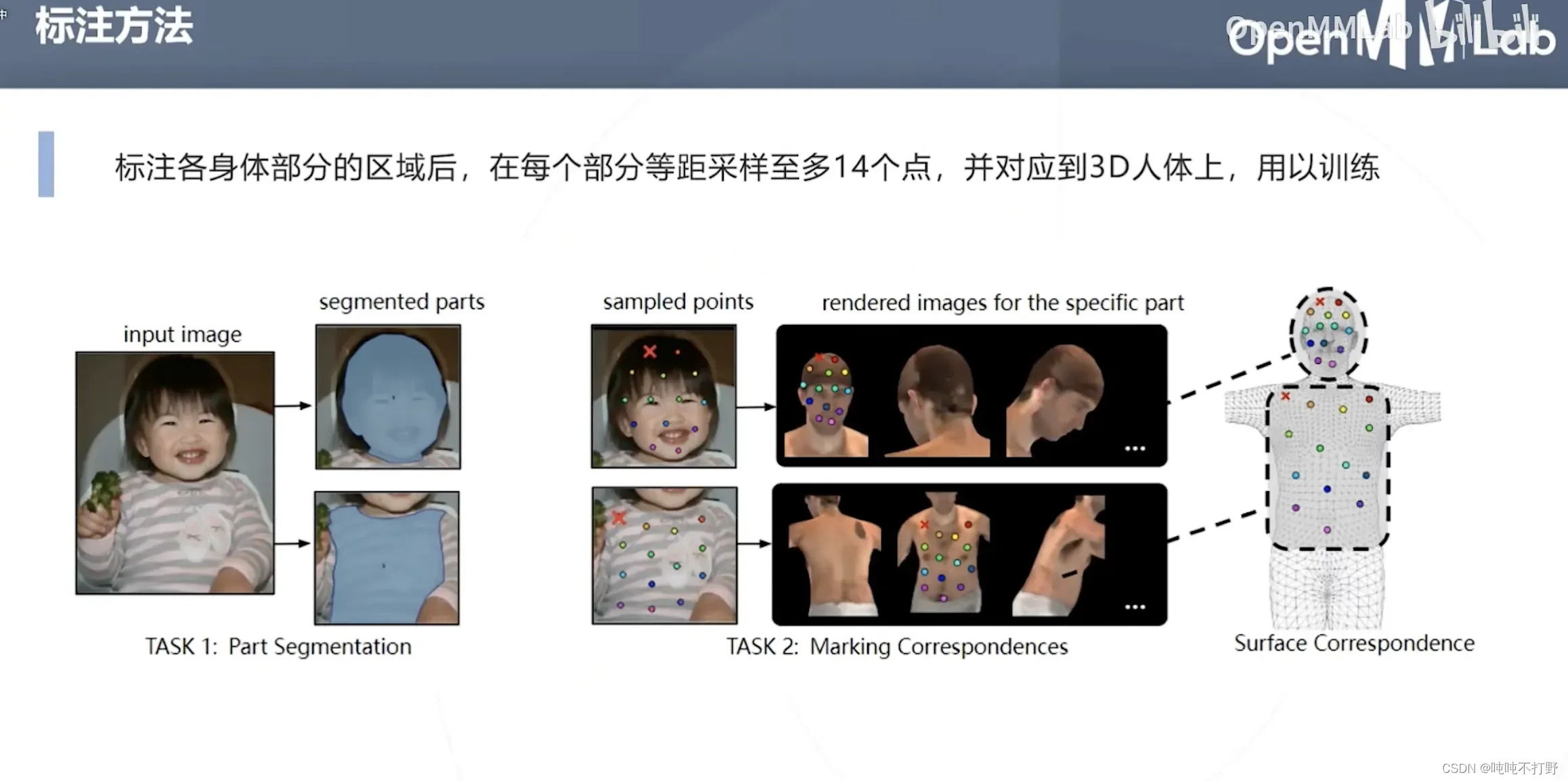
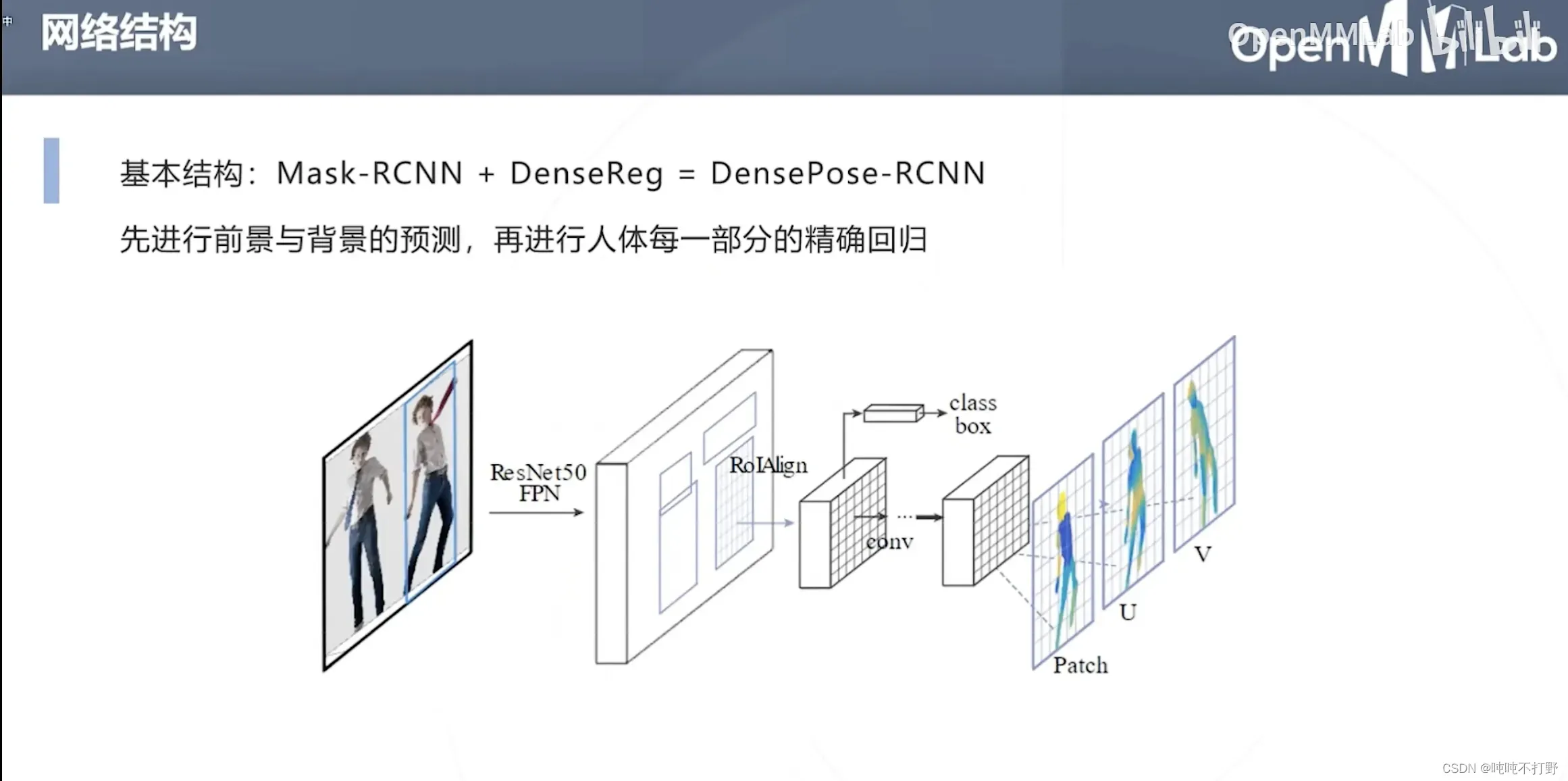
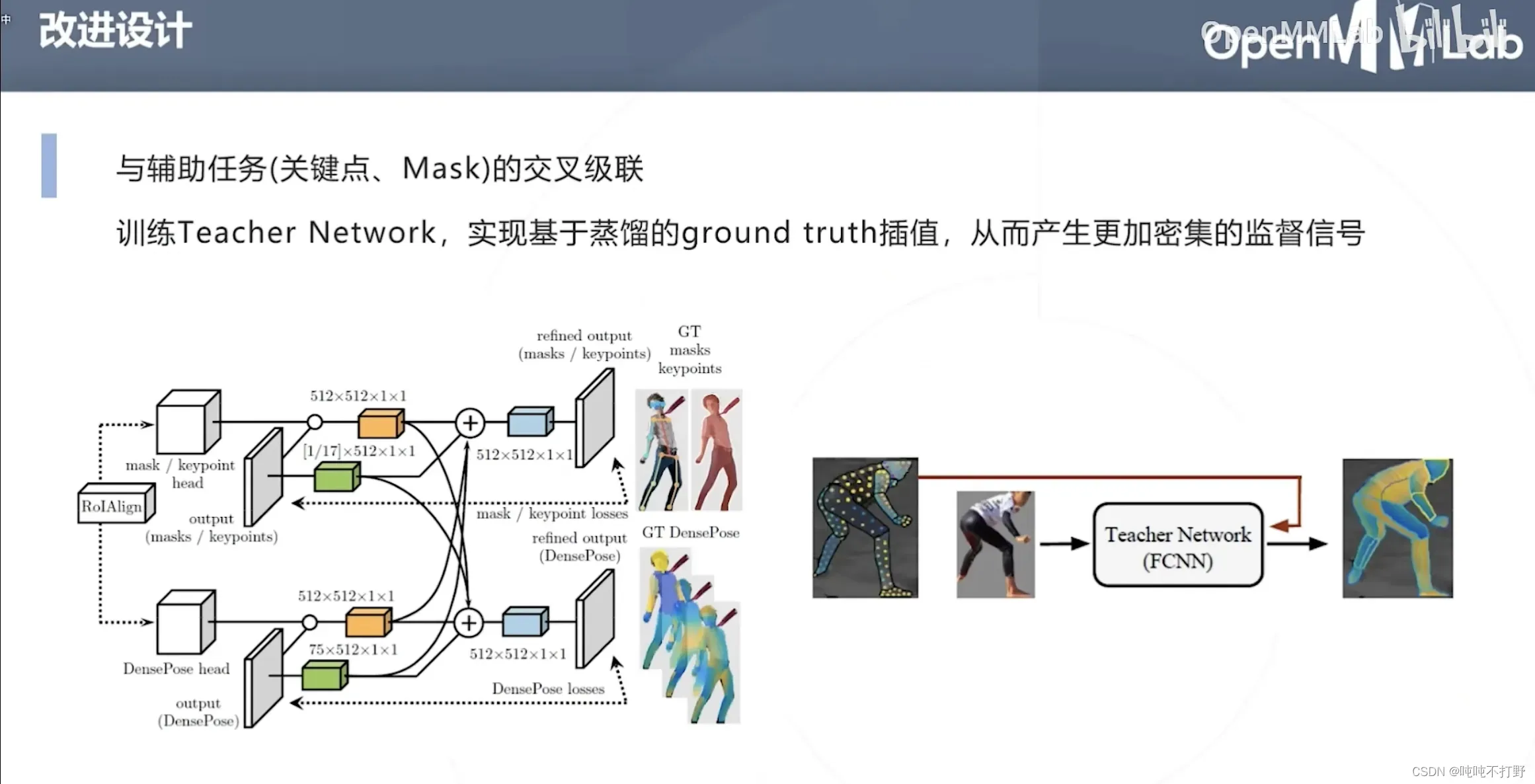
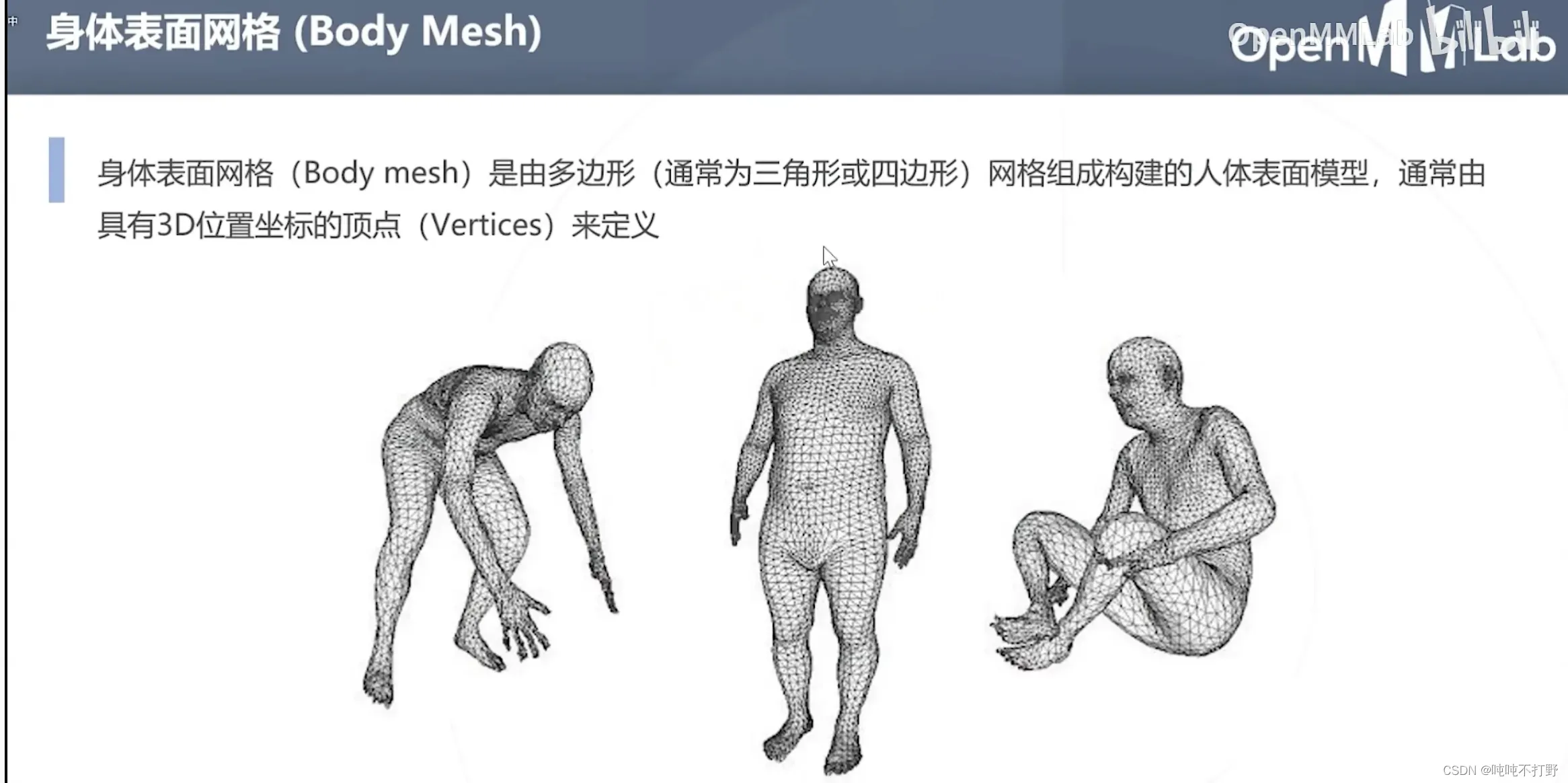
3D网格构建,属于渲染的内容了(使用计算机图形学的传统表示+深度学习的优化方法,挺好)

上面的两个肩膀是动图,来自:blender.stackexchange.com-Shoulder deformations

6. 人体参数化模型
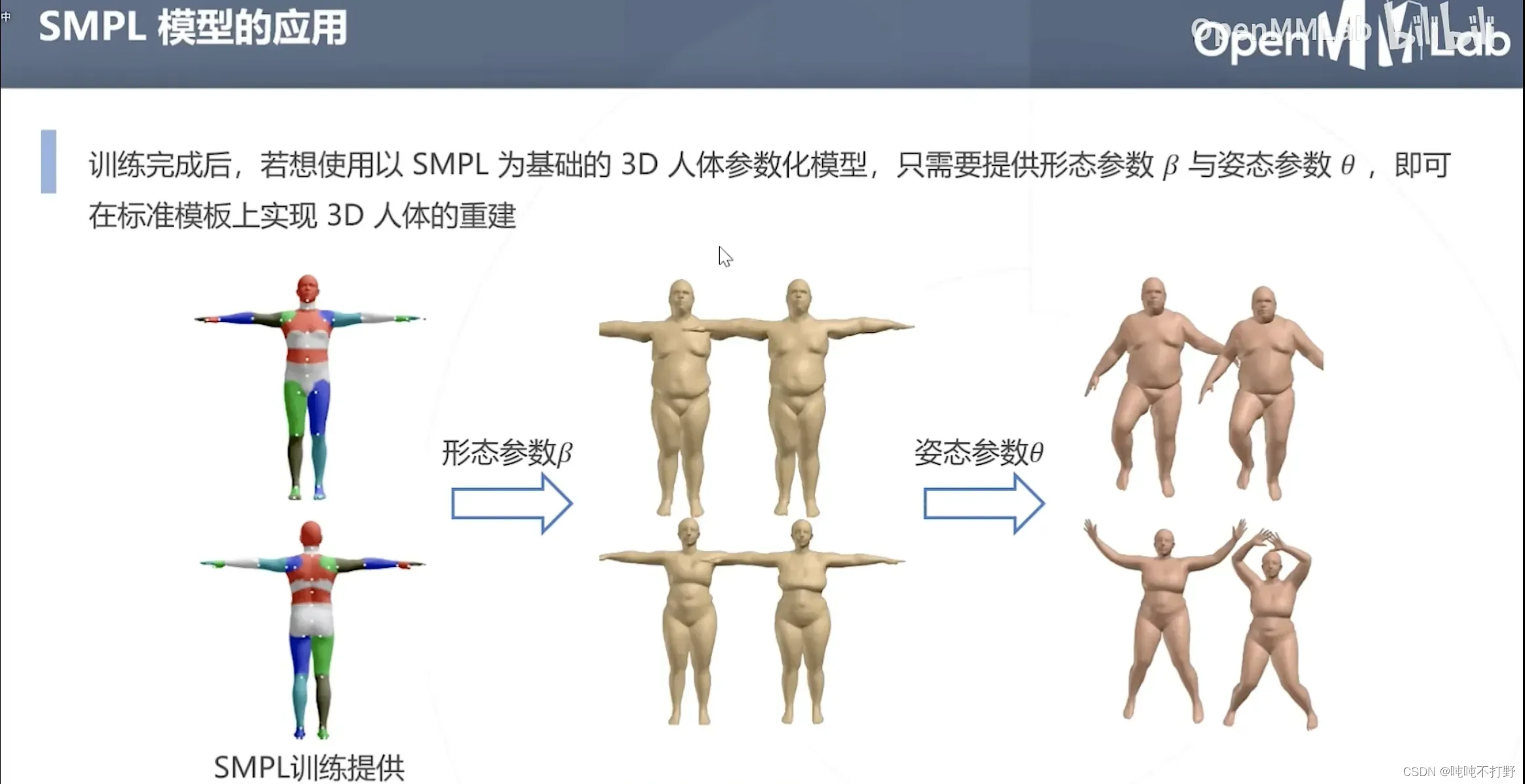
6.1 SMPL(人体参数化模型)-2015
论文:SMPL: A Skinned Multi-Person Linear Model
主页:https://smpl.is.tue.mpg.de/



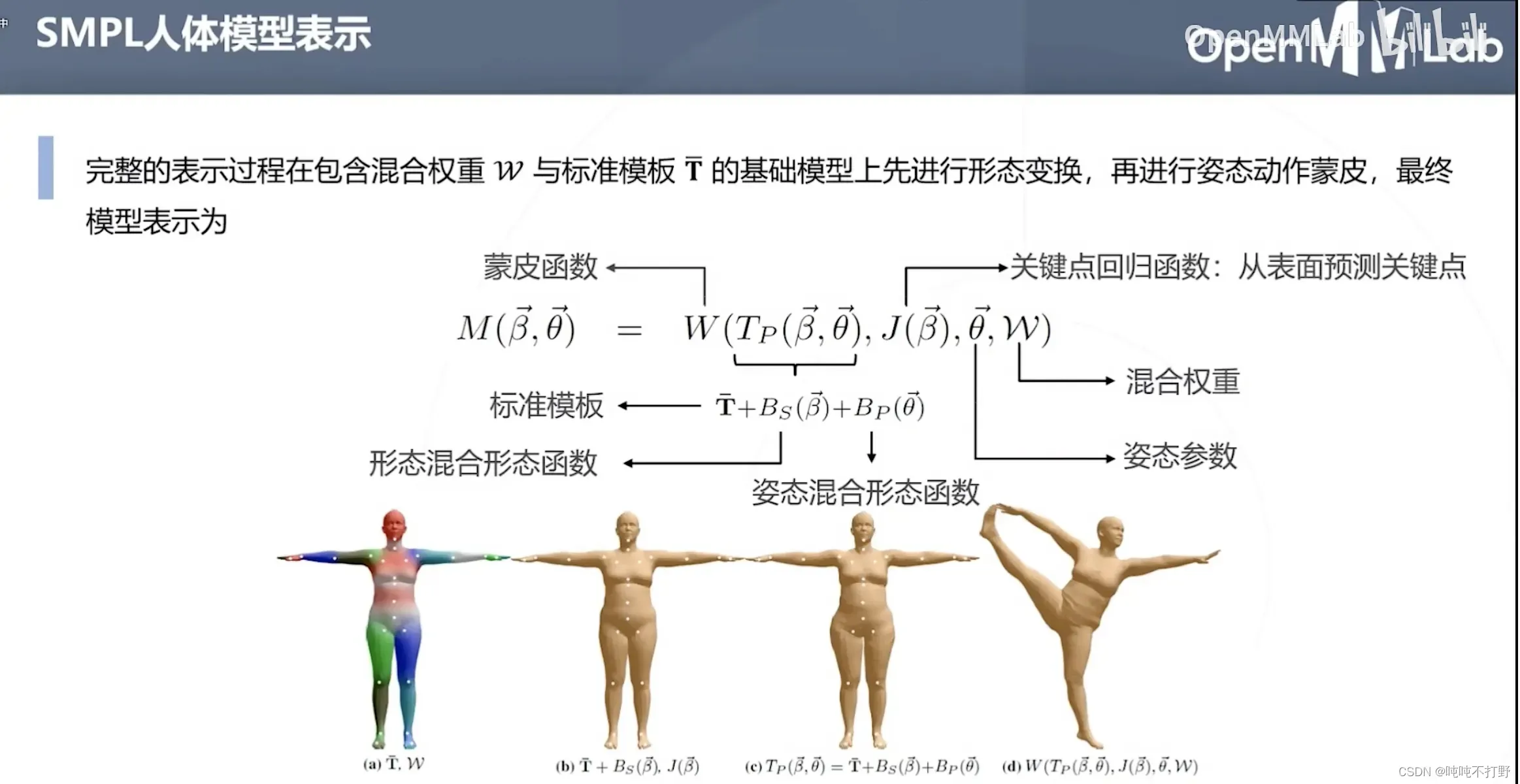
人体生成3D动画,人穿着特定设备,做动作,生成相应动作的3D动画人物模型,电影动画感觉用得到很多。
课件里的视频来源是这里:https://smpl.is.tue.mpg.de/

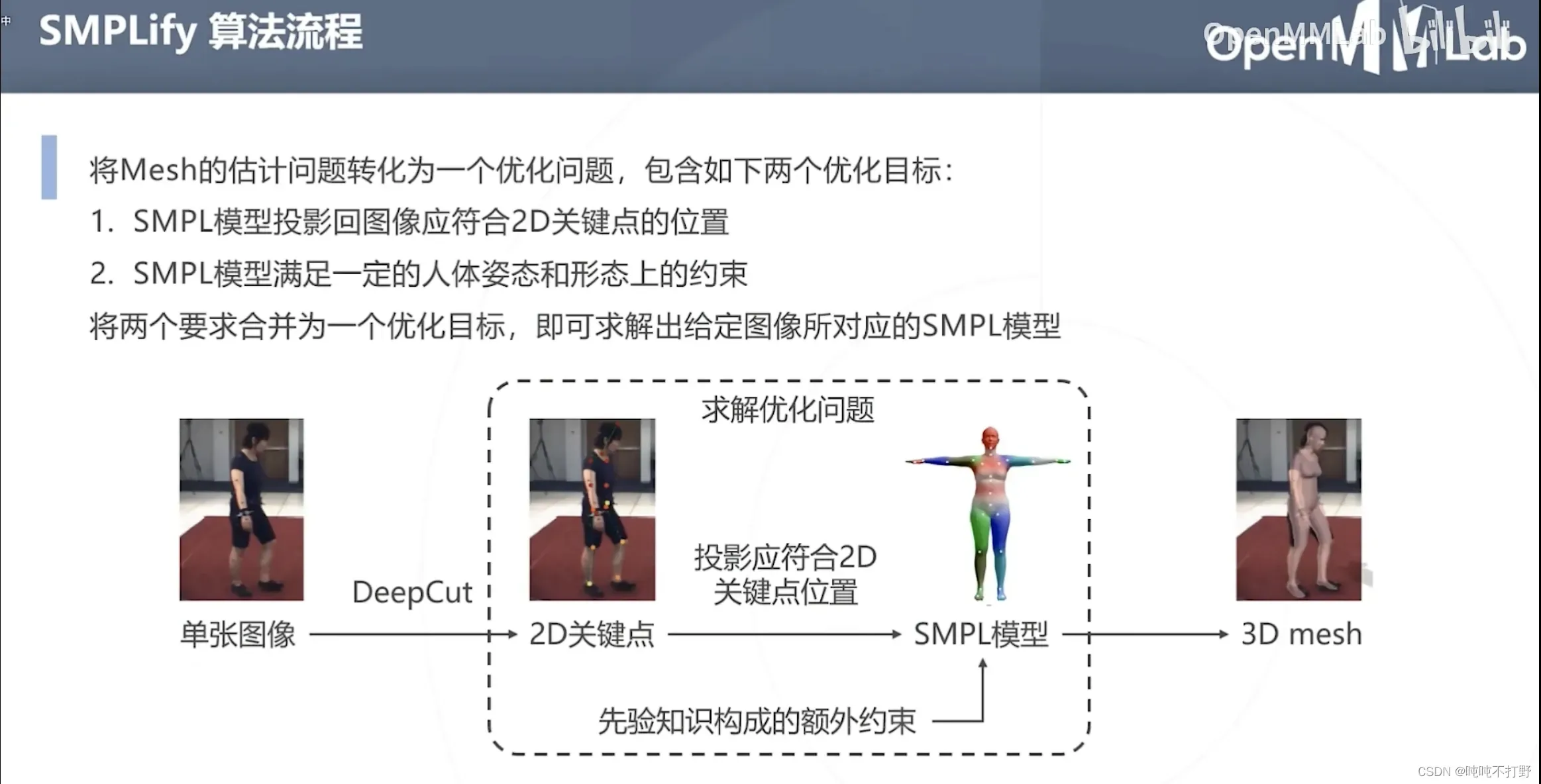
6.2 SMPLify
论文:Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image,和上面那个论文有一个共同的作者:Michael J. Black

人体参数化模型可以得到关键点(人体姿态估计),但是更进一步,它的目标其实是直接生成人体的3D mesh,人体姿态估计是这个模型的中间产物,不是最终目的。
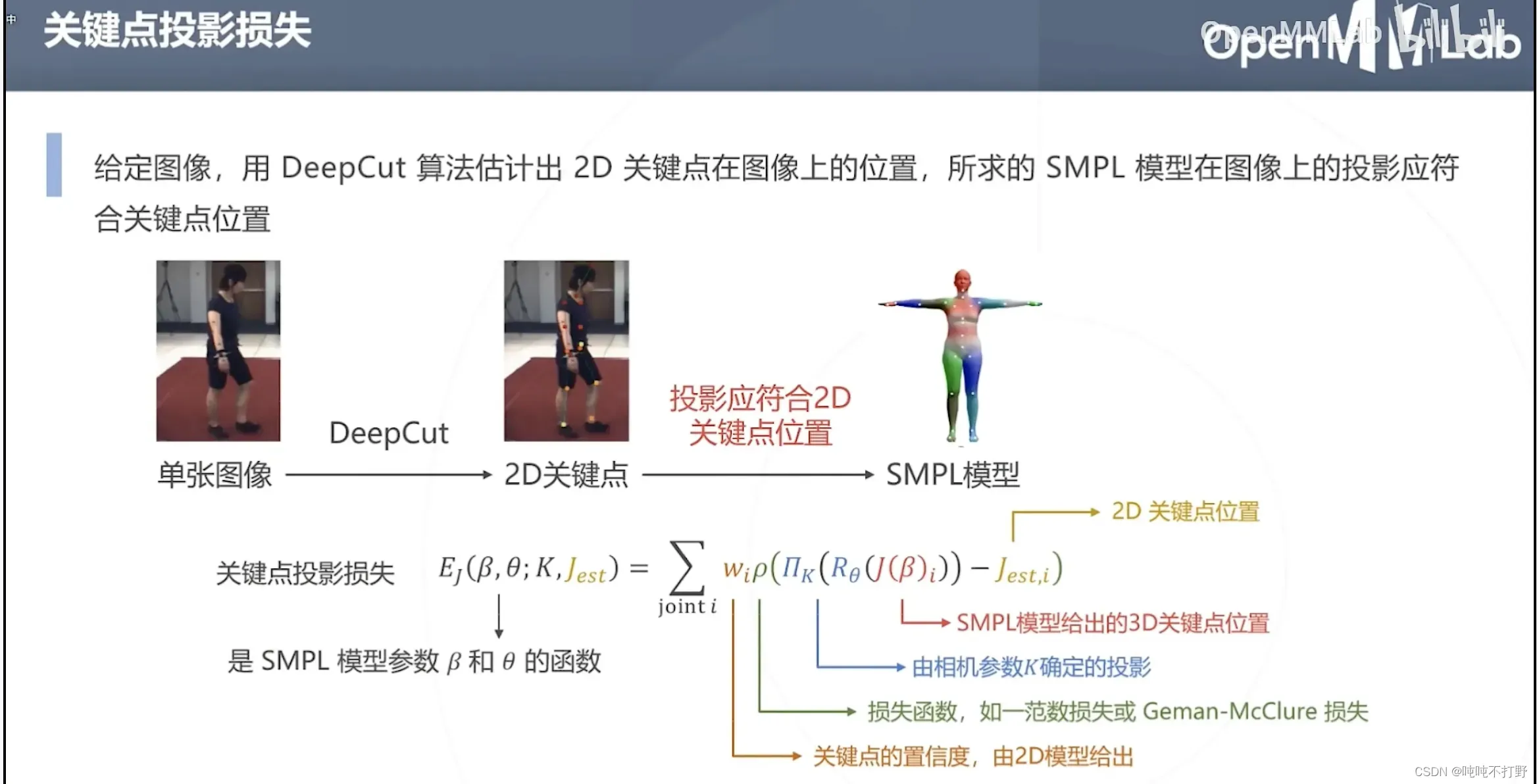



穿模,比如:手本来应该插兜,结果插到肚子里了

把人体建模成类似胶囊组合的形状

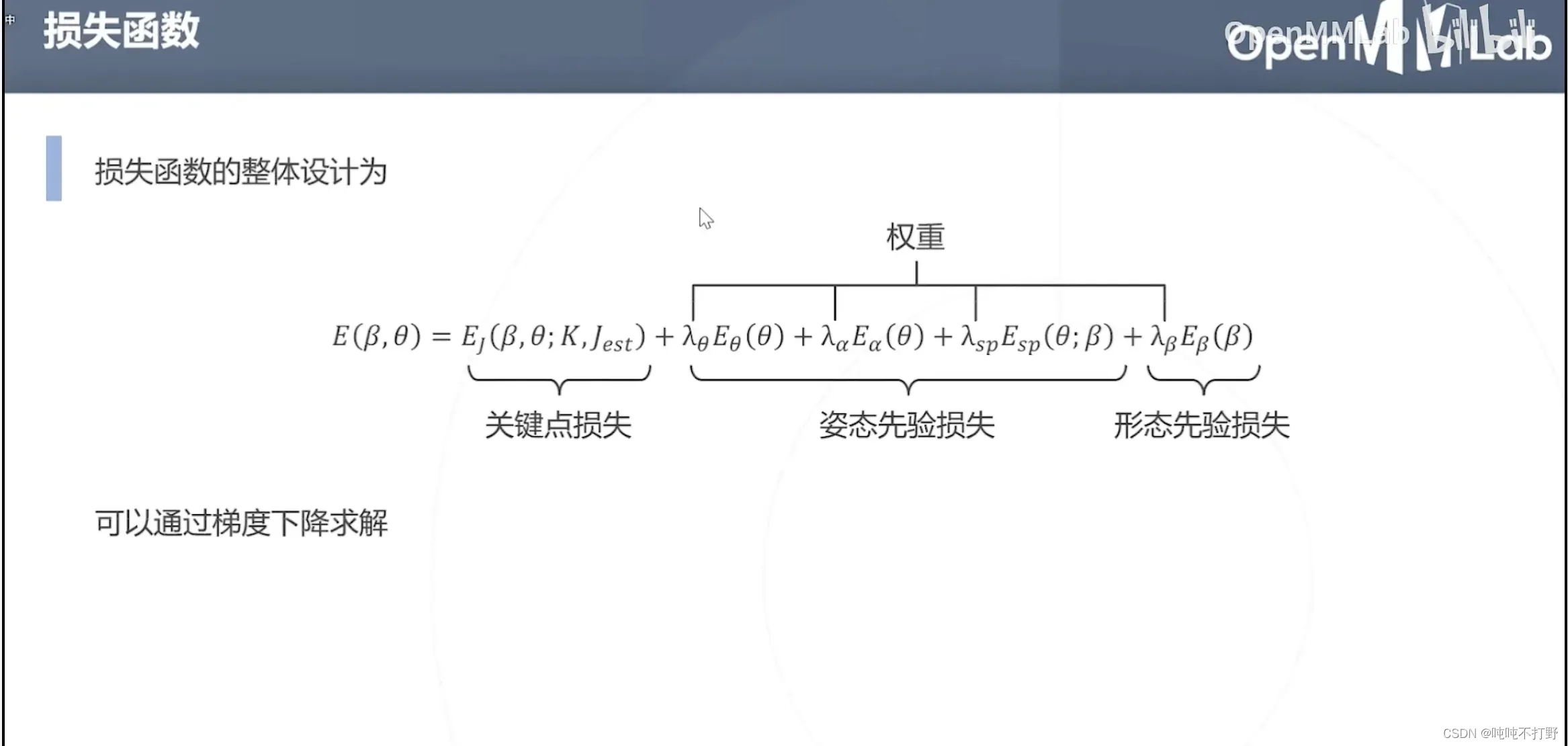
上面说的三种约束,等的进一步数学推导,
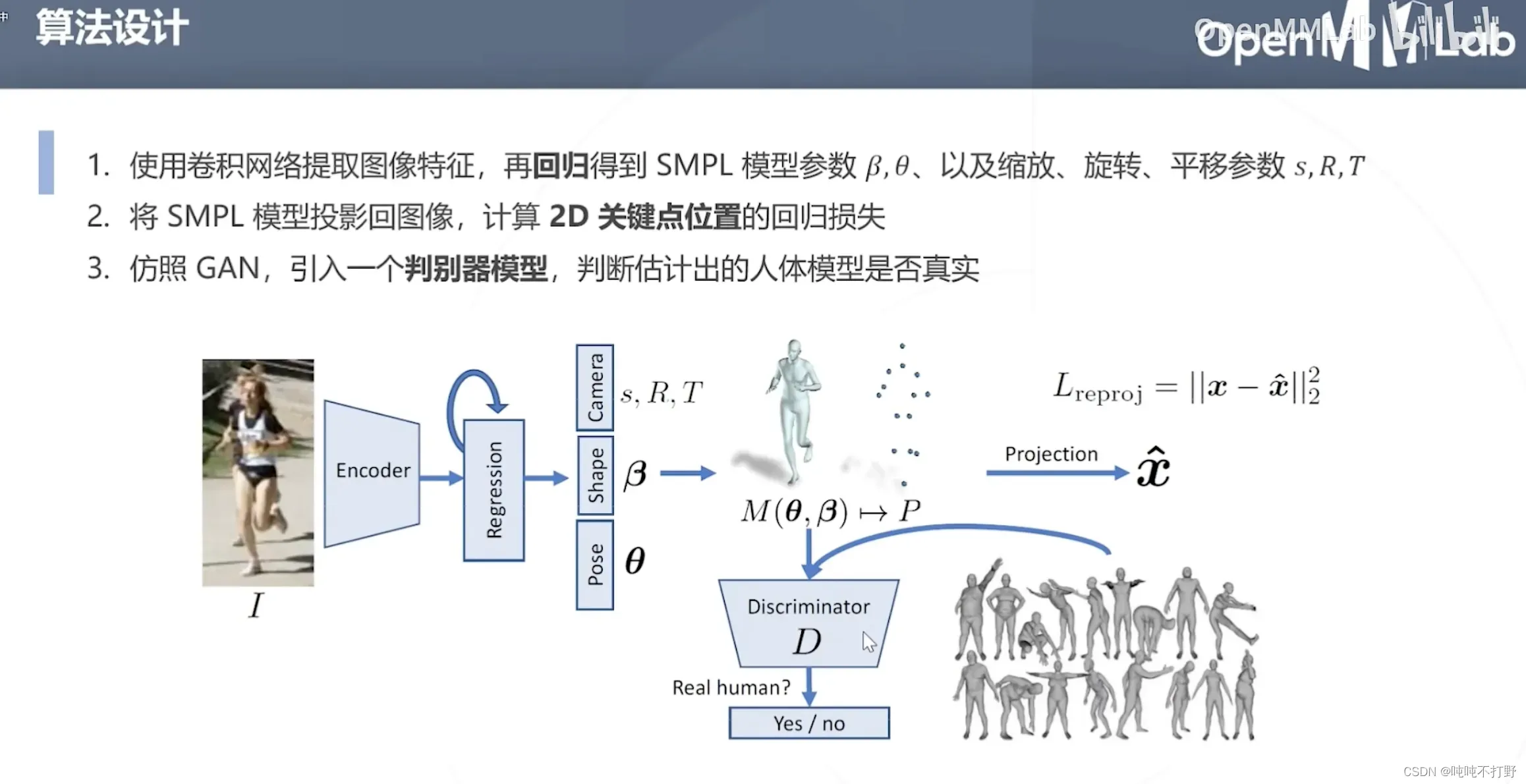
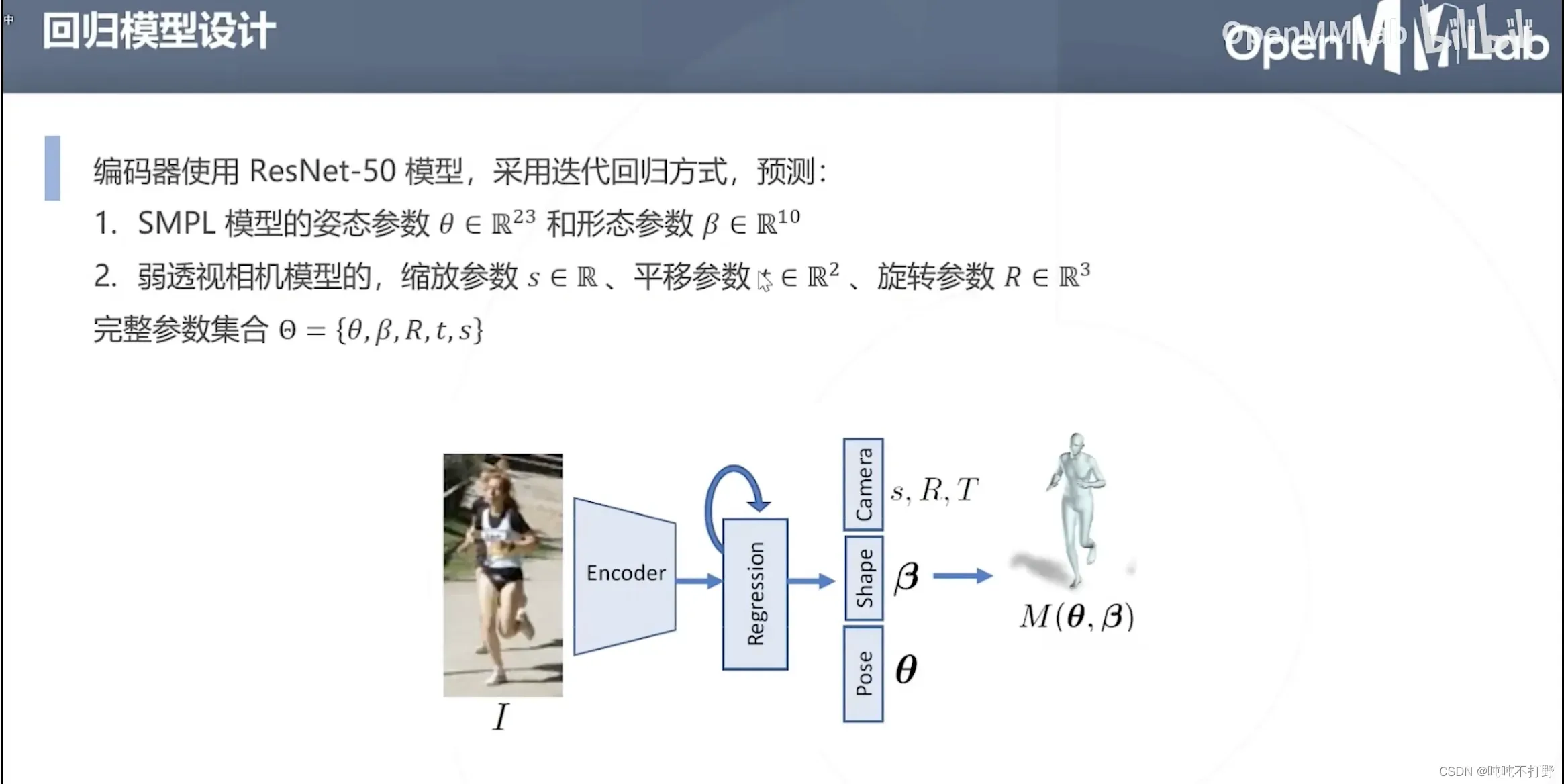
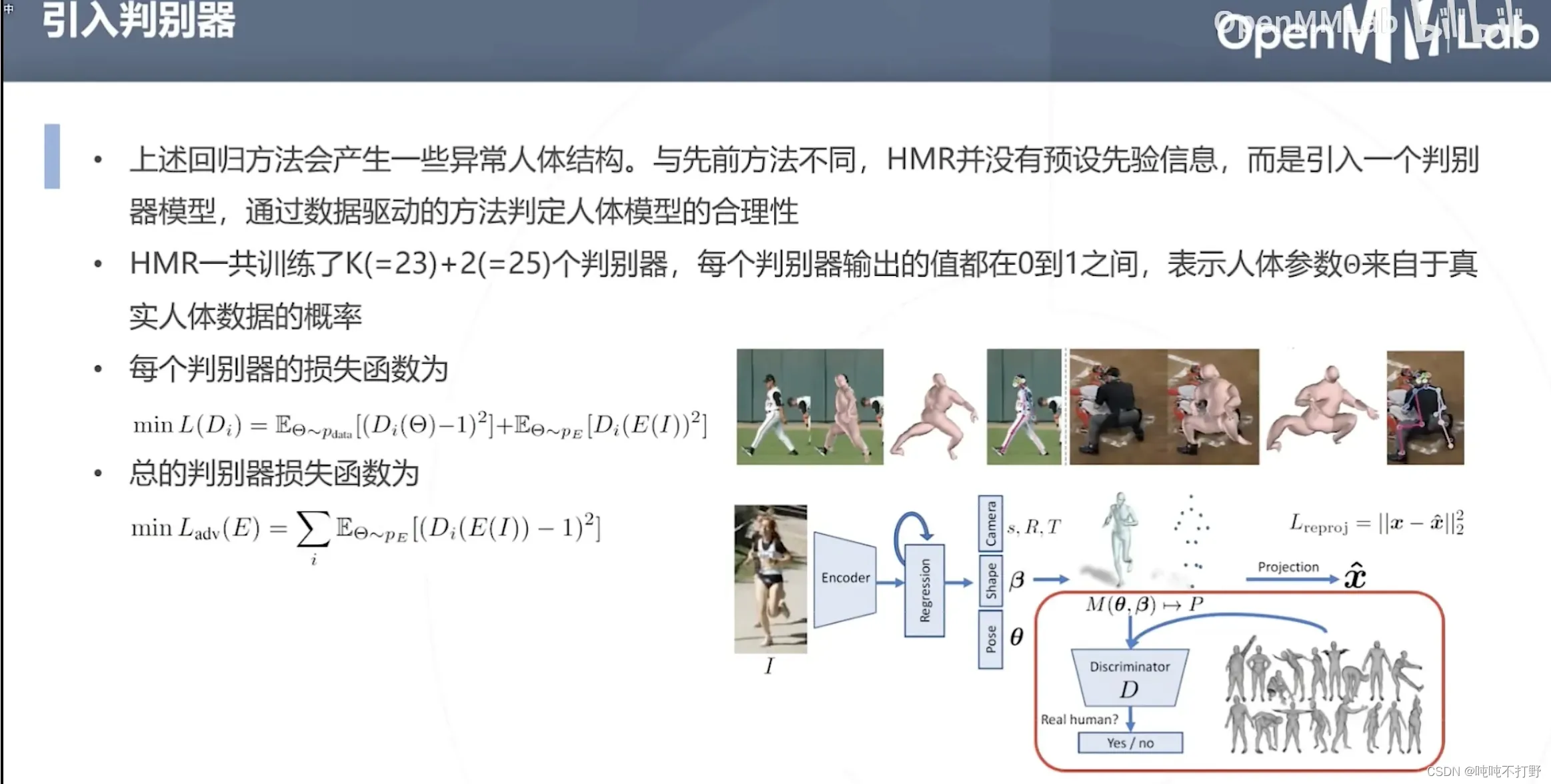
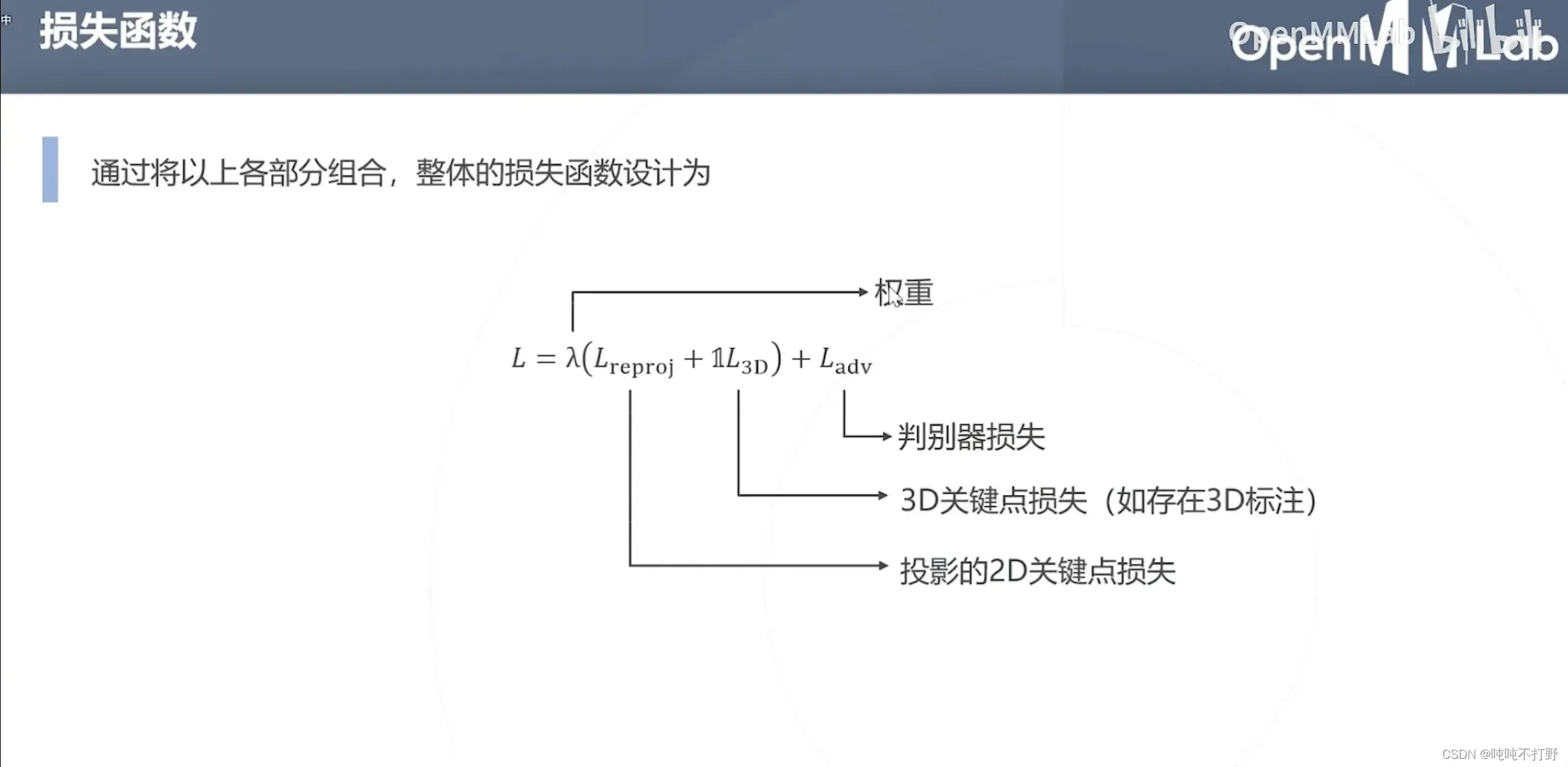
6.3 HMR
论文:End-to-end Recovery of Human Shape and Pose
和上面两篇一样,都有共同的作者(应该是一个实验室的成果)

这种求解方式可以适用于,只有2D标注的情况,如果有3D点云数据肯定更好

7. 课程总结

文章出处登录后可见!