写真开源AIGC推荐插播:
最新 FaceChain支持多人合照写真功能,项目信息汇总:ModelScope 魔搭社区
github开源直达(觉得有趣的点个star哈。):https://github.com/modelscope/facechain
正文:
原作者:姚远(嘉弈),清遥
简介: 换脸技术旨在将图像或者视频中的人脸替换成目标人脸,使生成的图像与目标人脸相似,且具有图像或视频中人脸的外貌特征。作为近几年计算机视觉和图形学领域较热门的应用之一,已被广泛用于互动娱乐,肖像替换,广告宣发,电影后期等场景中。本工作面向互动娱乐场景,扎根于学术前沿,聚焦于行业落地,提出了一个脸型自适应的换脸算法(SaSwap),并结合落地过程中的若干痛点难点逐一攻关,最终以高效的输出方式组成了一套完整的互娱换脸解决方案。
一、前言
1.1 简介
换脸技术旨在将图像或者视频中的人脸替换成目标人脸,使生成的图像与目标人脸相似,且具有图像或视频中人脸的外貌特征。作为近几年计算机视觉和图形学领域较热门的应用之一,已被广泛用于互动娱乐,肖像替换,广告宣发,电影后期等场景中。本工作面向互动娱乐场景,扎根于学术前沿,聚焦于行业落地,提出了一个脸型自适应的换脸算法(SaSwap),并结合落地过程中的若干痛点难点逐一攻关,最终以高效的输出方式组成了一套完整的互娱换脸解决方案。我们工作的主要创新点如下:
「更快」 支持对用户输入的任一目标人脸进行换脸,在视频换脸场景做到了视频时长:处理时长=1:0.4以内(业内领先)。
「更高」 结合客户反馈,针对换脸技术中涉及的若干典型挑战,提出了有效且实用的解决方案,将效果提升到更高的标准,保证了换脸结果的真实感,稳定性和高保真度(业内领先)。
「更强」 针对模板脸与目标脸可能存在的脸型不匹配问题,创新性地研发了脸型自适应的加强版换脸算法(业内首创),提升了生成人脸与目标脸的相似性。
1.2 术语解释
模板图像(视频):指待进行换脸操作的原始图像(视频)。
目标脸:用于替换到模板图像(视频)中的人脸,使得换脸后模板图像(视频)与目标脸相似。
生成对抗网络(GAN):由生成器和判别器构成,生成器用于生成以假乱真的图像,判别器用于判别图像真伪,两者相互博弈,从而促进生成逼近真实数据分布的样本。
1.3 相关工作
最直接的换脸可以通过2D形状拟合(贴图)方式实现,具体来说就是检测两张脸的关键点特征信息,然后计算两个人脸形状之间的变形映射并将目标脸匹配到模板脸上,最后添加图像融合等后处理技术修复边缘的痕迹,此类方法虽然实现起来快速简单,但是鲁棒性较差,只能处理较标准姿态的人脸。本部分相关研究重点关注三类典型的基于深度学习的换脸算法。
1.3.1 基于3D人脸重建的换脸算法
基于3D人脸重建的换脸算法是一类比较经典的思路,它首先对人脸进行三维重建,重建出表情姿态等系数,然后进行姿态对齐,纹理映射和融合改进,最终生成脸部替换的效果。以On face segmentation [1] 这类算法作为代表。该类方法能够处理大角度及部分遮挡条件下的换脸,但是由于引入了重建流程,导致pipeline耗时较长,效果上也易出现较生硬的合成痕迹,真实感有所欠缺。
1.3.2 基于GAN的换脸算法
换脸算法可以看作是一个人脸到人脸的图像翻译问题,研究者们很自然的想到引入生成对抗网络进行换脸应用。其中最著名的当属Deepfake[2]。
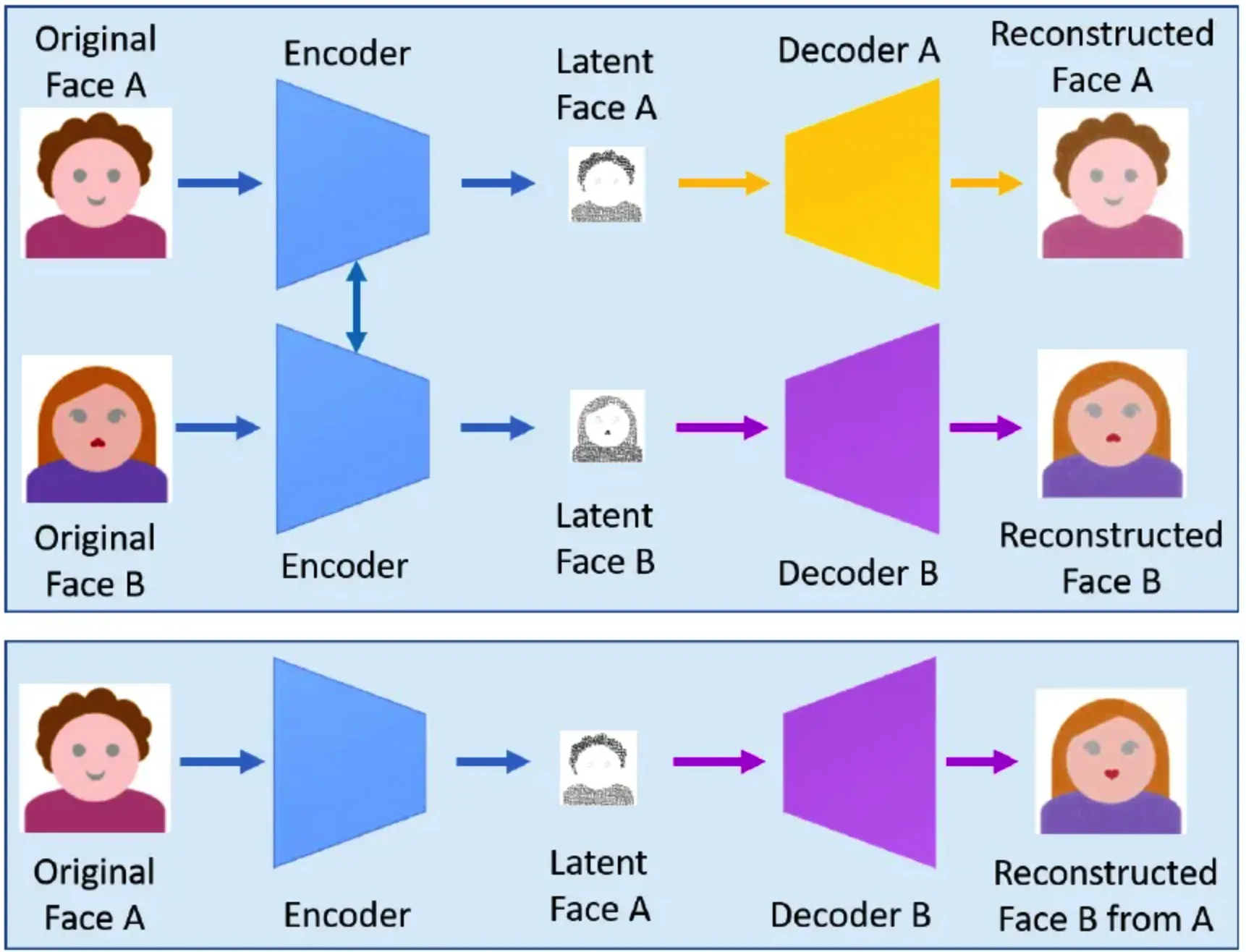
Deepfake的总体框架如上图所示,他的训练集需要两个域(人脸)的图像集A和B, 在使用同一编码器(权重共享)的约束下,在两个集合分别训练各自的编解码模型,推理的时候,对集合A的图像经过编码器提取特征,再输入集合B的解码器,完成人脸替换。Deepfake在收集到大量不同姿态、表情模板人脸和目标人脸数据时能够取得不错的效果,但是其局限性在于每次需要换不同的人脸时,都需要收集目标人脸数据并重新训练,对训练数据敏感,训练成本高,扩展性差。
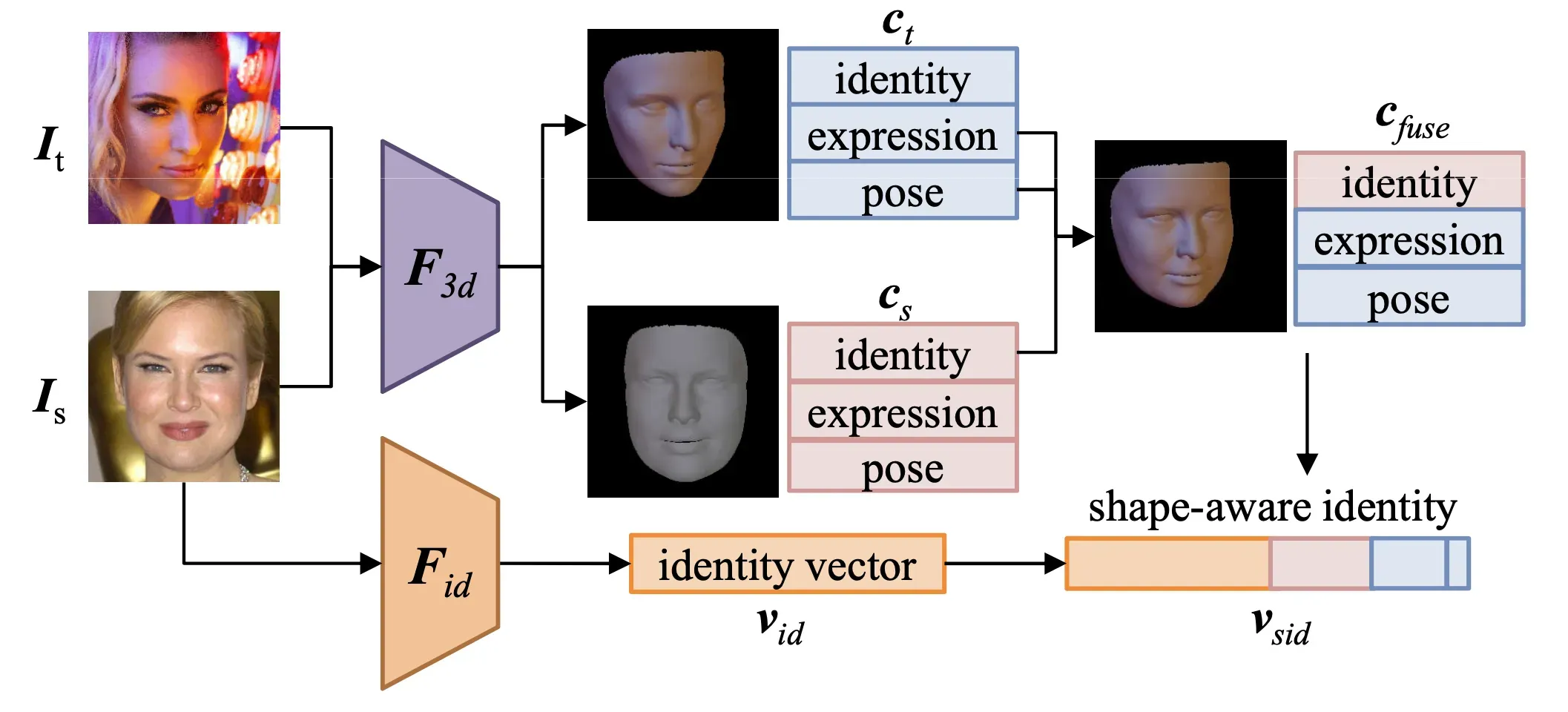
那么是否有方法能够在训练好一个通用模型后就能支持替换任意人脸呢?Faceshifter[3]的提出很好地解决了这个疑问,其将任意图像的换脸问题转换为一个特征抽取和融合的过程,通过一个身份编码器提取目标图像的特征,该特征编码了用于区分目标图像面部身份的特征,如眼睛的形状、眼睛和嘴的距离等,再通过一个多级属性编码器,提取模板图像的多个中间特征,该特征编码了不同尺度下的模板脸属性,如面部的姿势、轮廓、表情等。最终通过一个生成器将上述两类特征进行融合,直接输出换脸的结果。该网络架构使得Faceshifer能够支持推理阶段对任意的两张图像进行换脸,极大提升了换脸效率和扩展性。Simswap[4]基于类似的流程设计了一套不同的特征提取和融合网络。效率的提升不可避免的带来了效果上的妥协,Faceshifter和Simswap在实际使用中都存在诸如肤色,大角度侧脸和遮挡等问题,在第三章我们会介绍解决这些特定难点的思路。
1.3.3 3D先验 + GAN结合的换脸算法
3D方法可以重建表情姿态等系数,能够提供更为丰富的属性信息,同时对各种姿态人脸适配性更好。而生成式方法具有强大的特征提取能力,支持任意图像对的换脸。两种方法的联合也成为一个直观的优化思路,其基本思路是借助于3D可形变人脸模型(3DMM),分别提取模板脸和目标脸的ID, Color,Expression, Pose, Light等系数,进行系数替换合成后作为额外的信息输入生成式框架进行换脸。其中最新工作Facecontroller[5],HifiFace[6]就是基于此思路进行优化的换脸算法,通过更多信息的引入以及不同特征解耦模块的设计,能够提升对换脸中间态特征的控制能力,得到更高保真度的结果。
二、脸型自适应的换脸框架
2.1 网络设计
截止到今天,学术界针对任意图像的换脸算法主要集中在研究如何通过设计更好的特征解耦与融合方式,以提升最终效果的保真度、相似度和分辨率,主流的任意图像的换脸算法都默认在保留模板脸的脸型基础上,将目标脸和模板脸的特征进行融合,而我们发现,用户从主观进行评判换脸结果是否与目标脸相似时,除了五官一些特征外,脸型是另一个很重要的评判维度。特别是当模板脸和目标脸脸型相差较大时,如果换脸结果完全保留模板脸的脸型,从感观层面会觉得相似性不足,且容易在面部融合边缘出现一些合成痕迹明显的问题。
针对这一学术界和工业界公认的难点和痛点,我们结合3D先验的思路,开创性地设计了一个脸型自适应的换脸框架(Shape-aware swapping by 3D face priors, SaSwap),能够支持在换脸过程中对目标脸型的感知,在换脸的同时根据目标脸的脸型进行可控程度的变化。
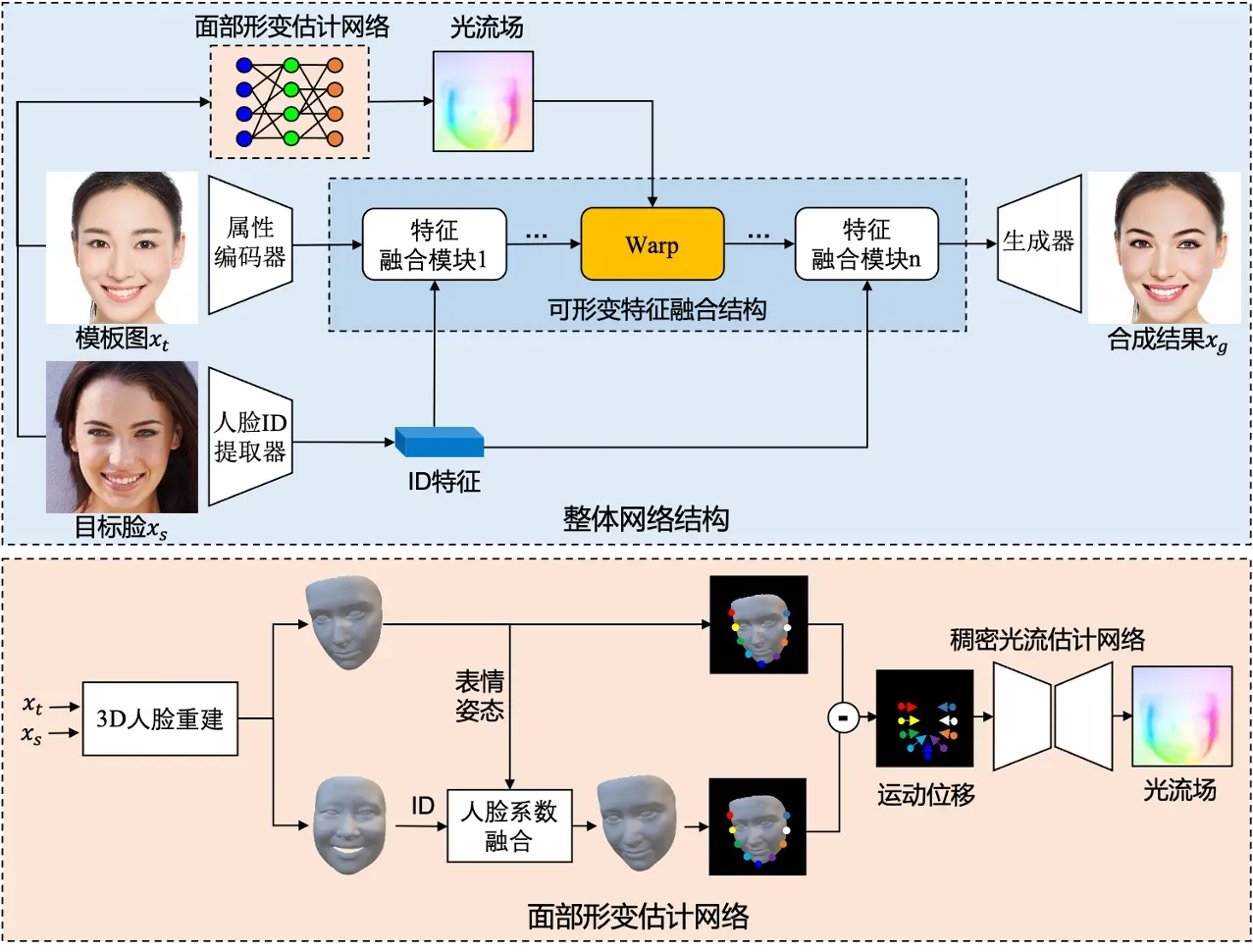
上图是我们SaSwap框架的网络结构图,主要分为多尺度人脸变换模块,基于3D先验的面部形变估计模块和可形变特征融合模块。具体流程为:首先将模板图Xt输入属性编码器获取其属性特征,目标人脸图Xs输入人脸ID提取器获取其ID特征,通过引入可形变特征融合结构,在将ID特征嵌入属性特征空间的同时,以光流场的形式实现面部的自适应变化,融合后的图像特征通过生成器得到最终合成结果。
1)多尺度人脸变换模块
多尺度人脸变换模块受启发于faceshifter AEI-Net[3]的流程,包括一个ID提取器,用于提取目标脸的ID特征,一个U-Net结构的属性编码器用于提取模板脸的多尺度信息和一个生成器用于将两个特征进行自适应融合,我们重新改良了生成器部分融合模块的结构,使得信息能更有效的结合,并生成更鲁棒的效果。
2)基于3D先验的面部形变估计模块
面部形变估计网络用于构建从输入图像到光流形成的前向通路,该模块基于3D先验信息实现。首先通过3D人脸重建模块对模板图、目标脸分别提取对应3D人脸结构并得到相关3DMM系数,通过人脸系数融合得到目标脸在指定表情姿态下的重建效果。此时依据变换后人脸mesh和原人脸mesh中的关键点信息得到运动位移,最后利用稠密光流估计网络将稀疏的关键点运动转换为稠密光流场,由于换脸任务中多为面部形态及五官形态结构的变化,因此该光流场预示了图像像素在空间位置上的运动变化。
3)可形变特征融合模块
可形变特征融合模块用于在特征融合序列模块的中间层借助网络预测的光流对深层特征施加warp形变,从而实现像素在语义空间更大范围的自由运动变换。其中光流场以无监督、自发形式生成,通过换脸相关损失约束,自发产生所需纹理形变需求,从而反馈给面部形变估计网络产生相应光流。
2.2 训练损失
整个训练过程采用端到端的形式进行学习优化,整体损失函数包括身份损失,重建损失,属性损失,语义损失,光流平滑损失和对抗损失。
-
身份损失
身份损失通过最小化换脸结果Y与目标人脸
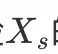
的id特征距离:
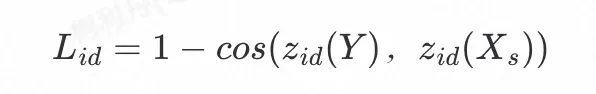
2)重建损失
重建损失分为三大块,分别是像素重建损失,3D重建损失和光流重建损失。
像素重建损失定义为换脸结果Y与模板人脸
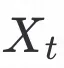
的逐像素
距离:
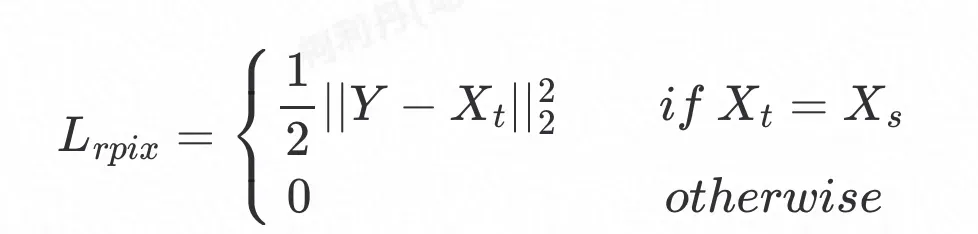
3D重建损失用于约束合成图像的3D人脸重建结果与融合后的3D人脸重建结果保持一致,定义为两个重建结果的
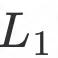
距离:
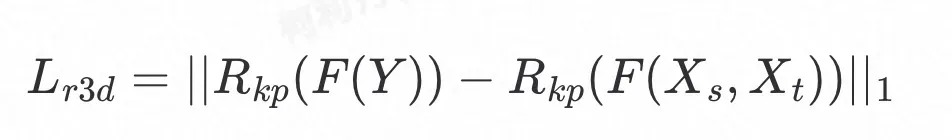
其中
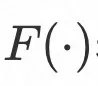
表示对图像进行3D重建,当输入两张图像时,表示分别对每张图进行3D重建,再通过参数融合转换得到新的3D模型,
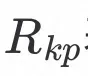
表示对图像3D重建结果提取对应的关键点。
光流重建损失定义为目标图
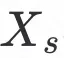
与模板图
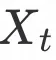
的光流预测特征的
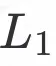
距离:
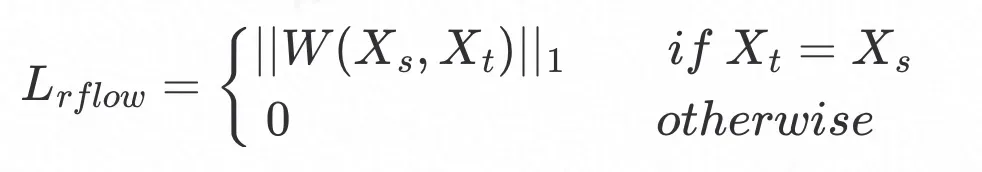
其中
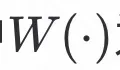
为面部形变估计网络。
最终,重建损失
![]()
可以定义为:

3)属性损失
属性损失定义为生成人脸Y与模板人脸
![]()
的多层语义属性特征的平均
![]()
距离:
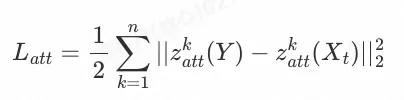
4)语义损失
我们使用Contextual loss[7]作为语义损失,它被用于约束换脸结果Y与模板人脸
![]()
在非对齐语义特征patch的相似性,借鉴风格迁移的思路,此处我们使用语义相关损失用于约束两者的肤色一致性。
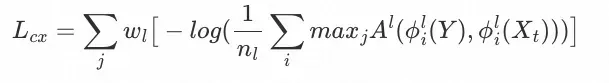
其中
![]()
代表VGG网络提取的第l层特征,i, j为对应的index,
![]()
为不同层的相对重要性权重,训练时我们使用了
![]()
和
![]()
这两层特征。
5)光流平滑损失
光流平滑损失用于减缓产生的光流�在横纵坐标(u,v)下的梯度,从而促进平滑变化。
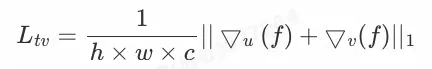
6)对抗损失
我们使用了一个多尺度的判别器来定义对抗损失。
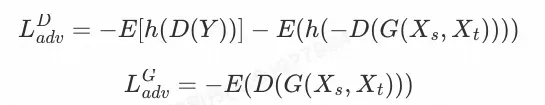
其中
![]()
为hinge函数。
最终损失函数定义为:
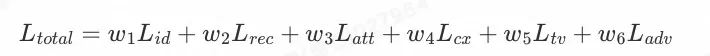
三、主要挑战及解决方案
在复现相关论文过程中,我们会发现其应用在真实场景时的泛化性往往存在不足。真实数据场景的分布具有更为复杂与多样的特点,在实际使用中容易产生各种artifacts。我们结合换脸落地过程中遇到的问题和实际需求,总结了以下痛点,并分别提出了针对性的有效改进措施。
3.1 肤色一致
效果上,换脸一个基本要求是生成的结果需要保持与模板人脸一致的肤色特征,但当目标人脸和模板人脸的肤色差距较大时,往往容易出现一些肤色偏差的问题。针对这一现象,我们引入了在图像风格迁移中应用的Contextual Loss[7], 该loss优势在于可用于非对齐(non-aligned)数据,能够较好地保留ground truth的特征,对于换脸场景两张脸五官分布非对齐的场景是十分适合的。通过引入Contextual Loss,我们的换脸算法能够准确的保持target图像的肤色信息。

3.2 大角度侧脸
大角度侧脸在视频类互娱场景中出现频率很高,是其中最容易出badcase的一类难题,侧脸图像的生成效果和稳定性对于整段视频结果的完整性起着至关重要的作用。鉴于此,我们首先优化了人脸检测的关键点算法,相较开源算法,大幅提升了对侧脸场景的检测准确性,接下来我们针对侧脸数据进行细粒度的分类,并在训练过程中结合3Dshape系数的约束,使得侧脸效果得到了极大的改善。

3.3 遮挡处理
实际场景中,输入的图像或视频帧中可能存在部分遮挡人脸的情况,比较常见的遮挡情况包括手,眼镜,口罩,装饰等,针对这些问题,我们目前采取的方式是使用数据增广,模拟频繁出现的遮挡场景,在训练时随机进行遮挡贴图。如下图是我们优化眼镜遮挡的效果,在未优化前,由于GAN生成网络的特性,容易在遮挡区域补全一些脸部纹理信息,导致遮挡信息丢失,而优化后,该遮挡信息得到了保留。

3.4 脸型适配
如第二部分介绍,我们的算法支持对用户脸进行自适应的脸型适配,脸型也是决定用户主观相似性的一个重要维度,特别是当模板脸和目标脸的脸型差距较大时,如果能够匹配上目标脸的脸型,将有助于提升换脸结果的辨识度。

3.5 人脸清晰化
由于我们网络输入的图像大小为256×256分辨率的人脸,当用户需要处理较高分辨率的图像或视频(裁剪后人脸区域的分辨率大于256×256),我们生成的换脸结果分辨率无法匹配输入的分辨率,会显得有些模糊。此时需要对生成的人脸进行增强,我们使用了一个预训练的人脸增强模型GPEN[8]作为后处理步骤,根据应用场景进行选择性的人脸增强操作。为了进一步节省这部分后处理的开销,后续我们将进一步借鉴HiFaceGAN[9]的思路,将增强直接融入训练过程中。

3.6 帧间稳定
对于视频换脸,基本流程是将视频进行拆帧,逐帧进行图像换脸后再合并所有帧,输出换脸后的视频。相较于图像换脸,除了上述的挑战,其对视频帧间的连续性具有较高的要求,其中涉及转场,模糊渐变,帧间位移等各类复杂情况,如果处理不好,结果会出现抖动,突变(上一帧换脸,下一帧未换)等不稳定的现象,严重影响换脸后的视觉效果。针对这些问题,我们从以下两个方面进行优化。
-
关键点检测稳定性优化。着重优化互娱场景的转场,模糊渐变等容易出现漏帧现象的情况,同时加入前后帧平滑逻辑,保证关键点在连续帧的五官关键区域的稳定性。
-
模拟帧间变化的数据增强策略。通过模拟帧间小幅度位移的现象,能有效提升网络鲁棒性,保证相邻两帧换脸效果的连续性和真实感。
四、视频级换脸提速框架
在互娱场景,性能是除效果之外决定产品走向落地的关键步骤。目前业界评估视频换脸的效率指标为1:N,具体指的是在类似T4算力的GPU机器上处理一段720p,25fps,长度为1秒的视频,最长处理时长为N秒。对于可支持任意图像换脸的技术方案,在推理阶段,输入一张用户图像,需要依次经过预处理(人脸关键点检测,图像对齐裁剪),模型推理,后处理(图像融合,图像变形还原)三大阶段。考虑到整个换脸的pipeline,做到1:1.5已经算是比较快的一个效率了。为了进一步降本提效,我们从推理加速和离线框架设计两个方面进行了优化,最终将视频换脸效率提升至1:1以内。下图展示了效率优化的各阶段时间开销,以上测试均在Tesla P100机器完成。

-
推理加速包括两方面,一是模型的推理加速,二是预处理和后处理的推理加速,针对模型加速,借助于模型加速团队的力量,使用Xcnn框架,将模型推理从单帧60ms提升至28ms,加速比达到2.14。进一步,我们对前后处理逻辑进行优化,最终由单帧47ms加速至27ms。
-
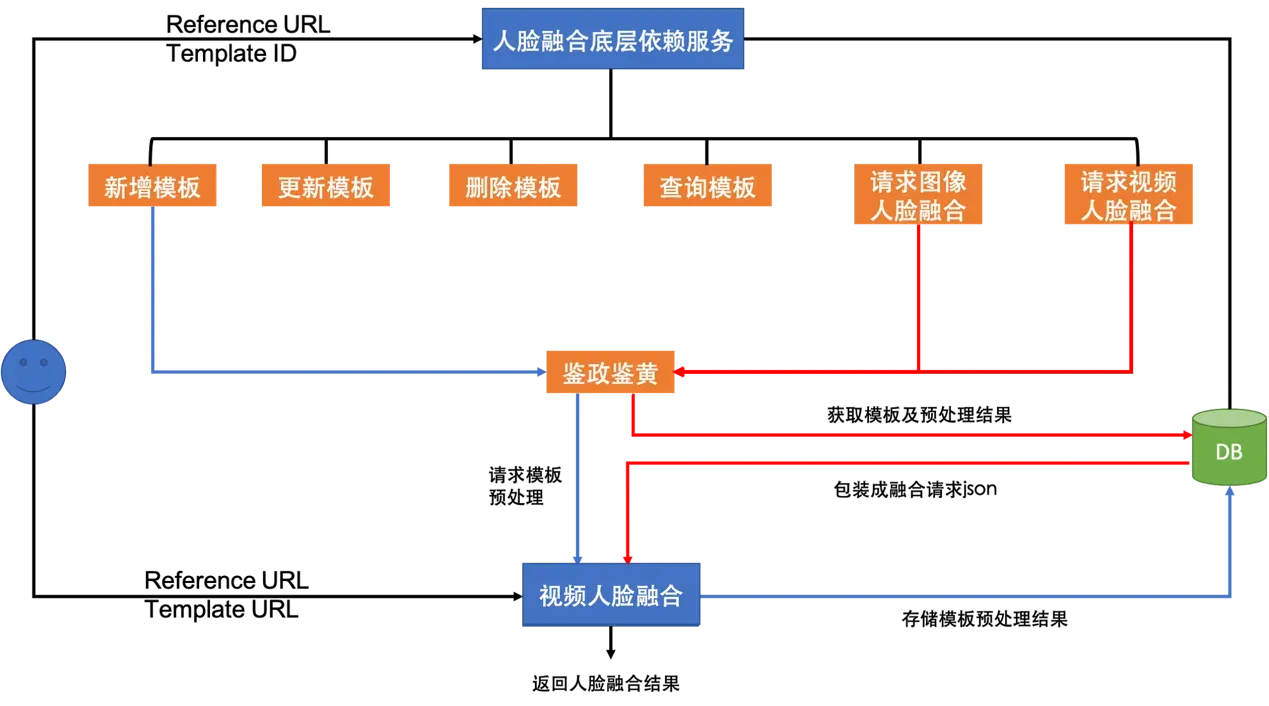
互娱场景主要面向toC客户,用户上传的图像可以频繁变化,而模板往往是固定的,因此我们可以提前将模板进行预先处理,将每次换脸需要用到的视频模板公共信息(如关键点,变形矩阵等)提前存储,省去实际换脸时该部分的额外开销。下图是我们的离线处理框架,通过提前处理模板信息,有效加速了整个视频换脸的效率。
五、效果展示及应用
5.1 竞品对比
目前业界有包括face++人工智能开放平台,火山引擎(头条),百度开放平台和腾讯开放平台提供了换脸服务,综合比较后,腾讯的效果大幅优于其他三家,由于这些竞品的视频换脸未开放测试,下面我们展示部分与竞品在图像换脸上的效果对比。



5.2 视频效果展示
5.3 应用场景
-
消防安全宣传场景下的换脸应用
-
电商模特的换脸应用
六、参考文献
[1] Nirkin Y, Masi I, Tuan A T, et al. On face segmentation, face swapping, and face perception[C]//2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018). IEEE, 2018: 98-105.
[2] GitHub – deepfakes/faceswap: Deepfakes Software For All[3] Li L, Bao J, Yang H, et al. Faceshifter: Towards high fidelity and occlusion aware face swapping[J]. arXiv preprint arXiv:1912.13457, 2019.
[4]Chen R, Chen X, Ni B, et al. Simswap: An efficient framework for high fidelity face swapping[C]//Proceedings of the 28th ACM International Conference on Multimedia. 2020: 2003-2011.
[5]Xu Z, Yu X, Hong Z, et al. Facecontroller: Controllable attribute editing for face in the wild[J]. arXiv preprint arXiv:2102.11464, 2021.
[6]Wang Y, Chen X, Zhu J, et al. HifiFace: 3D Shape and Semantic Prior Guided High Fidelity Face Swapping[J]. arXiv preprint arXiv:2106.09965, 2021.
[7]Mechrez R, Talmi I, Zelnik-Manor L. The contextual loss for image transformation with non-aligned data[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 768-783.
[8]Yang T, Ren P, Xie X, et al. GAN prior embedded network for blind face restoration in the wild[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 672-681.
[9]Yang L, Wang S, Ma S, et al. Hifacegan: Face renovation via collaborative suppression and replenishment[C]//Proceedings of the 28th ACM International Conference on Multimedia. 2020: 1551-1560.
七、结语
以下提供达摩院视觉开放平台换脸服务的试用入口:
【图像人脸融合】
能力展示-阿里云视觉智能开放平台
【视频人脸融合】
能力展示-阿里云视觉智能开放平台
以及modelscope上的图像人脸融合模型:
图像人脸融合
文章出处登录后可见!