相关背景知识
医学图像是什么?
医学图像是反映解剖区域内部结构或内部功能的图像,它是由一组图像元素——像素(2D)或立体像素(3D)组成的。医学图像是由采样或重建产生的离散图像,它能将数值映射到不同的空间位置上。像素所表达的具体数值是由成像设备、成像协议、影像重建以及后期加工所决定的。通常情况下,医学图像和医学影像所表达的含义是相同的,只是不同领域的称谓不同。
常见的医学图像(医学图像的模态)
常见的医学图像包括X射线、计算机断层扫描(CT)、单光子发射计算机断层扫描(SPECT)、超声波(US)、磁共振成像(MRI)、红外和紫外线、正电子发射断层扫描(PET)等。来自MRI、X射线、CT和超声的图像能够反映出病变的位置、大小、形态以及它在附近组织中引起的形态和结构变化。为了深入了解肿瘤的生物学过程、软组织以及功能信息,PET、功能磁共振成像(fMRI)和SPECT的使用变得越来越普遍。
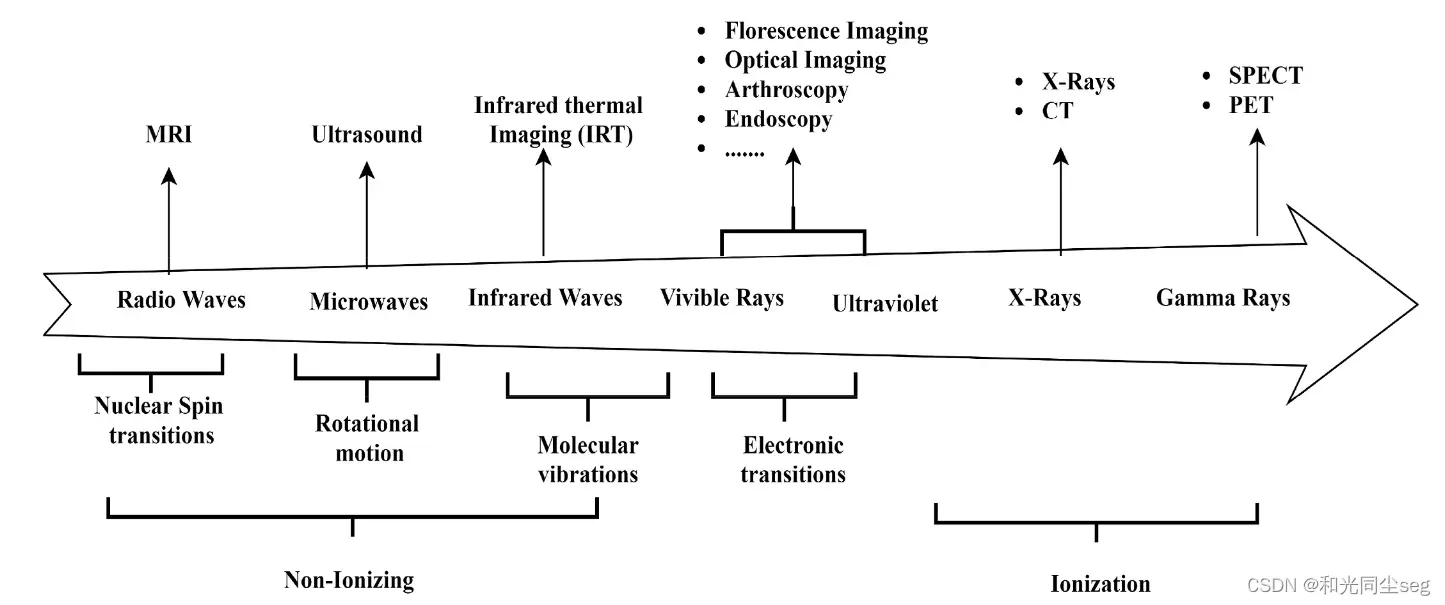
医学图像的格式
医学图像有6种主要的格式,分别为DICOM(医学数字成像和通讯)、NIFTI(神经影像信息技术)、PAR/REC(Philips磁共振扫描格式)、ANALYZE(Mayo医学成像)、NRRD(近原始栅格数据)和MNIC,目前临床应用最广的就是DICOM,比如CT、MR、X光、超声的图像都是DICOM格式的。
DICOM文件(dcm文件)一般由一个文件头和一个数据集合组成的。文件头是用于标识数据集的,最前面128字节为文件前言,4字节的DICOM前缀和不定字节的文件元信息。数据集合由若干的数据元素(数据元素由标签、值类型、数据值长度、数据域组成)组成,存储了图像的信息。其中的数据元素是根据Tag标签值(病人信息、检查信息、序列信息、图像信息)由小到大进行排列的。

医学图像与自然图像的区别
从原理上说,医学图像大多数是放射成像,功能性成像、磁共振成像、超声成像等,而自然图像大多数是自然光成像,因此存在很多的区别,比如自然成像的光谱比较复杂,其噪声可认为是高斯噪声,而医学图像中厂家去除了人体内的散射,使光谱单一,其噪声可近似于泊松噪声,因此降噪的方式不同。
从图像的内在特征来说,医学图像多是单通道灰度图像,尽管大量医学图像是3D的,但是医学图像中没有景深的概念,自然图像中目标检测发展如火如荼,大量算法针对由于景深而引起的小目标检测有非常多的设计,但是景深所造成的的影像是物体边缘模糊,物体形态变小,很多算法也是针对这个,然而在医学图像中一个很小的异常组织之所以被检测出来,不是由于它形态很小并且边缘像什么东西,而是该区域同周围区域有明显的差异,比如说DR中检测肺结核纤维化病灶,一个直观的表现就是病灶区域纹理走向同周围不同。这些都需要在设计时进行慎重考虑。
从图像所反映的信息来说,绝大多数同部位,同体态的医学图像相似度非常高,这主要是人体组织本身相似度高所致;并且医学图像中的细微结构并不能像自然图像中那样认为是无关紧要,在相似度极高的背景组织中的细微变化有可能就代表着某种病变。这就为医学图像分析处理带来难度,很多指标诸如SSIM在这里会失效,同时很多细小纹理都不得不被考虑。举例:医用显示屏的价格往往远高于工作站本身,这主要是因为为了很好的显示医学图像所包含的所有特征,不得不用具有很优化的gamma曲线的屏幕,已提供完整的,优秀的灰阶显示,而这种屏幕生产成本远高于普通屏。这又不得不影响医学图像展示以及评估。总之,一张医学图像中包含的所有信息都具有潜在利用价值,而自然图像则不然,往往一张自然图像可能就只有一部分ROI有用。
医学图像拍摄成本高,产业链复杂,入行门槛高是造成医学图像处理一系列问题的根源;一张高质量的医学图像,不仅仅是图像处理的工作,还涉及到机械加工精度、探测器材料性能是否优秀,病患身体是否配合等等非图像方面可控的因素,这些又是图像算法不得不考虑的地方。举例:CT里面去除金属伪影根本上就是一个可优化但无法根本解决的问题;而类似的自然图像中的防抖,运动伪影的处理会容易得多。很多情况下,医学图像算法并不如硬件提升来的作用大,另外,很多在自然图像领域业已势微的方向,比如图像融合技术,在医学图像研究中依然占据非常重要的地位。
医学图像分析的定义及应用
定义:医学图像分析指运用各种方法对图像中的兴趣区域和目标进行定量或定性检测,最大限度地挖掘图像内涵,为临床医师或科研人员提供信息参考。
应用场景:
- 临床辅助诊断
临床辅助诊断建立在医学图像病理形态学基础上,即是否发生病变可通过细胞、组织或器官的形态结构变化进行判断。 - 影像引导治疗
为了实现对病灶的精准治疗,在治疗前、治疗中,可使用图像分析技术对人体组织器官医学影像进行三维重建,减少由于治疗过程中发生的变化而导致的治疗效果的不佳。 - 预后
预测疾病的可能病程和结局。
医学图像分析的常见任务
医学图像分析的四大关键任务
- 疾病诊断
从医学图像中判断出患者是否患病或得了何种疾病。 - 病变、器官和异常检测
在医学图像中检测病变是许多情况下疾病诊断的重要任务和关键部分。类似地,器官检测是图像配准、器官分割和病变检测的基本预处理步骤。医学图像中的异常检测,例如脑MRI图像中的脑微出血和视网膜图像中的硬渗出物,在许多应用中也需要。 - 病变或器官的分割
医学图像分割致力于从背景中识别病变或器官的像素,通常被视为病变评估和疾病诊断的前提步骤。近年来,基于深度学习模型的分割方法已成为主流技术,并已广泛用于脑肿瘤、乳腺肿瘤以及肝脏和胰腺等器官的分割。 - 医学图像配准
配准是将两个或多个图像对齐到一个具有匹配内容的坐标系中的过程,也是许多(半)自动医学图像分析任务中的一个重要步骤。图像配准可以分为两种:刚性和可变形(非刚性)。在刚性配准中,所有图像像素均匀地经历简单变换(例如旋转),而可变形配准旨在建立图像之间的非均匀映射。
医学图像分析的其他任务
- 医学图像降噪
医学图像噪声包括原始图像的噪声和标签的噪声,这些噪声是由各种原因所导致的,对后续任务的影响程度也不同,需要采用一些方法对其处理。 - 医学图像超分辨率重建
随着临床对高分辨率图像的要求不断提高,采用低分辨率图像获得高分辨率图像的超分辨率重建方法可以在不改变成像设备的前提下获得高质量的医学图像。 - 医学图像合成
- 数据集扩展
- 模态转换
从一种模态获得另一种模态的医学图像。
- 医学图像重建
医学图像重建的目的是从大量测量(例如CT中的X射线投影或MRI中的空间频率信息)重建诊断图像。 - 医疗报告生成
应用于医学图像分析的机器学习方法
根据学习范式的不同,可以将目前应用于医学图像分析的机器学习方法分成有监督学习、无监督学习、深度学习、强化学习。
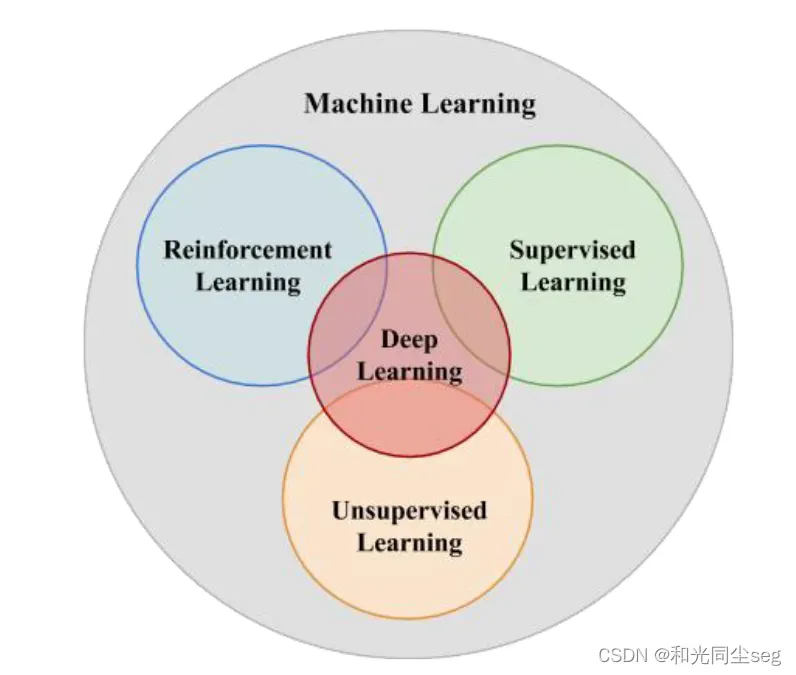
监督学习
监督学习是指训练样本有标签的一类学习方式,监督学习按照样本的标签多少可以分为两种形式:
- 全监督
- 半监督
虽然医学图像从数量上看并不少,但是对这些图像进行标注是比较困难,需要极高的专业知识和花费大量的时间。因此数据问题是医学图像分析的痛点,很多研究人员的工作都是基于此展开的。
无监督学习
深度学习
随着深度学习技术的不断发展,越来越多的人使用深度学习模型去处理相关的学习任务。由于其具有强大的特征学习与表达能力,因而在医学图像分析任务上表现出色。深度学习是通过堆叠多层神经网络以实现学习的一种方式,因此可以按照神经网络的划分方式对齐进行分类。
1.前馈神经网络
前馈神经网络(feedforward neural network)是一种简单的神经网络,也被称为多层感知机(multi-layer perceptron,简称MLP),其中不同的神经元属于不同的层,由输入层-隐藏层-输出层构成,信号从输入层往输出层单向传递,中间无反馈。前馈神经网络中包含激活函数(sigmoid函数、tanh函数等)、损失函数(均方差损失函数、交叉熵损失函数等)、优化算法(BP算法)等。常用的模型结构有:卷积神经网络、BP神经网络、RBF神经网络、感知器网络等。在医学图像分析领域,占据主导地位的无疑是卷积神经网络了,几乎所有应用于图像处理的深度学习网络都包含卷积操作。
2.反馈神经网络
反馈神经网络(feedback neural network)的输出不仅与当前输入以及网络权重有关,还和网络之前的输入有关。它是一个有向循环图或是无向图,具有很强的联想记忆能力和优化计算能力。常用的模型结构有:RNN、Hopfield网络、玻尔兹曼机、LSTM等。其中最经典的无疑是RNN了。RNN用于解决训练样本输入是连续的序列,且序列的长短不一的问题,比如基于时间序列的问题。基础的神经网络只在层与层之间建立了权连接,RNN最大的不同之处就是在层之间的神经元之间也建立的权连接。
3.图神经网络
近年来,深度学习领域关于图神经网络(GNN)的研究热情日益高涨,图神经网络已经成为各大深度学习顶会的研究热点。GNN处理非结构化数据时的出色能力使其在网络数据分析、推荐系统、物理建模、自然语言处理和图上的组合优化问题方面都取得了新的突破。图神经网络通常有以下几种网络模型:图卷积网络、图自编码器、图生成网络、图循环网络、图注意力网络。
图神经网络的计算过程总结起来就是聚合邻居。图神经网络是直接在图上进行计算,整个计算的过程,沿着图的结构进行,这样处理的好处是能够很好的保留图的结构信息。而能够对结构信息进行学习,正是图神经网络的能力所在。图数据无处不在,图神经网络的应用场景自然非常多样。比如近两年最火热的transformer就是图神经网络的一种。
强化学习
虽然强化学习近年来逐渐兴起,但是强化学习在医学图像分析中很难被理解和部署,因此该方面还需要较多的研究。强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。换句话说,强化学习是一种学习如何从状态映射到行为以使得获取的奖励最大的学习机制。这样的一个agent需要不断地在环境中进行实验,通过环境给予的反馈(奖励)来不断优化状态-行为的对应关系。因此,反复实验(trial and error)和延迟奖励(delayed reward)是强化学习最重要的两个特征。强化学习系统一般包括四个要素:策略,奖励,价值以及环境或者说是模型(model)。
强化学习在医学图像分析中的优势:
- 强化学习即使在数据样本少或者标注较差的情况下也能获得较好的效果,同时速度比较快。
- 强化学习可以从序列数据中学习,其学习过程是以目标为导向的,可以探索新的解决方案,甚至可以超过人类。
模型表现提升策略
多特征融合
多特征融合指的是在医学图像分析过程中使用多种特征,如影像组学特征、剂量组学特征或者深度学习提取的高层次特征等。
多模态融合
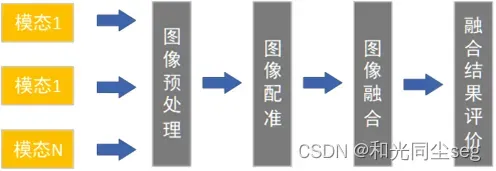
多模态图像融合方法是一种将来自一种或多种成像模态的多个图像集成在一起的过程,以提高准确性和质量,同时保留图像的补充信息。医学图像融合主要涉及MRI、PET、CT和SPECT。PET和SPECT模态提供了包含身体功能信息的图像,例如代谢、软组织运动和血流的细节,但空间分辨率较低。MRI、CT和US提供了高空间分辨率图像,提供了有关身体的解剖学信息。多模态图像通常通过将功能图像与结构图像合并来获得,以产生更好的信息,供专家诊断临床疾病。
在图像融合步骤中必须满足两点:1)输入图像中存在的所有有用的医疗信息必须存在于合成图像中,2)融合图像不应包含输入图像中不存在的任何额外信息。融合可以应用于从不同成像模态来源获得的多传感器图像、通常从同一模态获得的多聚焦图像以及广泛用于医学的多模态图像。在多模态融合过程中,研究人员首先选择感兴趣的身体器官。然后,选择两个或多个成像模态,使用适当的融合算法进行融合。为了验证融合算法,还需要一些性能指标。在最后一步中,合成的融合图像比输入图像包含更多关于身体器官扫描区域的信息。整个MMIF流程如图所示。
融合的方式主要有三种,分别是输入级融合、特征级融合、决策级融合。
- 输入级融合
在输入级融合策略中,多通道图像作为多通道输入进行逐通道融合,以学习融合的特征表示,然后训练网络。输入级融合可以最大限度地保留原始图像信息,学习图像特征。现有的多模态医学图像分析网络大多采用输入级融合策略,其结构如下所示。
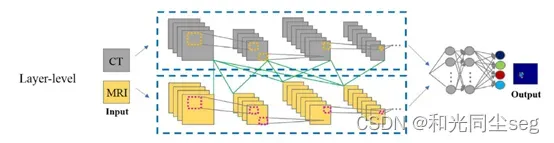
- 特征级融合
在特征级融合策略中,使用单个或两个模态图像作为单个输入来训练单个网络,然后将这些学习到的单个特征表示在网络的层中进行融合,最后将融合结果反馈给决策层以获得最终的结果。特征级融合网络可以有效地捕捉同一患者不同模态的信息,其结构如下图所示。
- 决策级融合
在决策级融合分割网络中,与特征级融合一样,每个模态图像被用作单个网络的输入。单个网络可以更好地利用相应模态的唯一信息。然后将各个网络的输出进行集成,以获得最终的分割结果。由于不同的图像采集技术,多模态图像在其原始图像空间中几乎没有直接的互补信息。决策级融合网络旨在独立学习不同模态的互补信息,决策级融合通用网络架构如图所示。
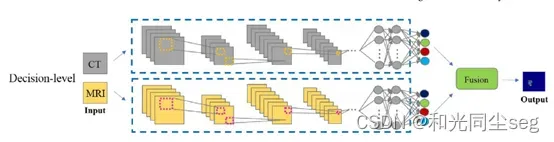
然而,这些融合策略都有不同程度的缺点。输入级融合策略难以在同一患者的不同模态之间建立内部关系,这导致模型性能下降。特征级融合的每个模态对应一个网络,这会带来巨大的计算成本,尤其是在模态数量很大的情况下。决策级融合的每个模态的输出彼此独立,因此该模型无法建立同一患者的不同模态之间的内部关系。此外,与特征级融合策略一样,决策级融合策略也是计算密集型的。因此,需要将这三种融合策略有效地结合起来,一个好的多模态融合策略应该以较低的计算复杂度实现尽可能多的不同模态之间的交互。
迁移学习
迁移学习是机器学习中一种新的学习范式,它可以克服深度学习需要大量样本的缺陷,能够解决医学图像分析中数据集较小导致模型不准确的问题,因而成为继深度学习之后在医学图像分析领域的研究热点。按照目前医学图像分析中应用的主要迁移学习方法,即基于数据的迁移学习、基于模型的迁移学习、对抗式迁移学习和混合迁移学习。
1.基于数据的迁移学习
- 基于样本的迁移学习
基于样本的迁移学习是在源域和目标域数据具有相同特征的情况下,从源域中筛选出符合目标域数据的相似分布的样本,用它们训练新模型以降低其偏差和方差。通过加入部分源域数据为辅助数据集,增大了数据集,可以减少模型的方差。但是需要计算 MMD 及 KL 等距离量度;在源域无标签的情况下无法使用样本加权方法。能够迁移的样本数量受限于源域样本数量。适用于源 域 和 目 标 域 数 据 的特征相同而分布不同的场景。 - 基于特征的迁移学习
基于特征的迁移学习要解决的是源域数据和目标域数据特征不重叠或者有部分特征重叠的问题。对于特征有重叠的情况,学习一对映射函数,将来自源域和目标域的数据映射到共同特征空间以减少域间差异性;对于不重叠的情况,找到两个特征空间可能存在的某些转换器来实现迁移学习。
目前医学图像分析领域基于特征的迁移学习属于源域和目标域有特征重叠的情况。基于特征的迁移学习适用范围较广,不管源域和目标域数据是否有标签都能使用。然而,当数据有标签时,域不变性的度量值不易计算;当数据无标签时,学习跨域通用特征也较困难。适用于源域和目标域数据的特征只有部分重叠甚至不重叠的场景。
2.基于模型的迁移学习
基于模型的迁移学习是在模型层次上源任务和目标任务共享部分通用知识,包括模型参数、模型先验知识和模型架构,分为基于共享模型成分的知识迁移和基于正则化的知识迁移两类。前者利用源域的模型成分或超参数来确定目标域模型;后者通过限制模型灵活性来防止模型过拟合。
基于模型的迁移学习可以避免再次抽取训练数据或再对复杂的数据表示进行关系推理,是更高效的学习方式。然而,模型需要进行源域的预训练和目标域的再训练,增加了训练次数和训练时间;迁移模型到目标域后,采用何种模型结构和参数调整策略对模型的精度产生重大影响,而如何快速选择合适的调整策略还缺乏有效的解决办法。适用于源域任务和目标域任务在模型层次上共享部分通用知识,即模型参数、模型先验知识和模型架构等场景。
3.对抗式迁移学习
对抗式迁移学习有两种方式,一种是基于样本的迁移学习,由 GAN 生成目标域数据;另一种是基于特征的迁移学习,这种方式还可以分成两类,一类是对抗式域适配器,使用有标签的源域数据和没有标签的目标域数据来学习一个适用于两个领域的识别分类器,另一类是对抗式特征学习,用大量无标签的源域数据构造高层抽象特征,再用少量有标签的目标域数据学习一个分类器。
对抗式迁移学习适用范围较广,无论源域和目标域数据是否有标签都能使用,使用参数化网络度量域之间的差异,无需计算 MMD 和 KL 散度等距离。然而,该迁移学习方法也有局限性,例如难以学习高维和多模态数据的内在结构;在某些区域模型无法生成样本时可能会崩溃、最小-最大博弈难以达到平衡、可能生成不切实际的样本。
4.混合迁移学习
混合知识迁移是通过使用多种迁移学习方法来迁移两种以上的知识,包括样本、特征和模型,迁移特征最终表现为迁移了样本。使用基于数据的迁移学习或对抗式迁移学习来迁移数据,使用基于模型的迁移学习来模型。
混合迁移学习可以同时迁移两种以上知识到目标域,和单一的迁移学习相比,能从多个方面提高模型的训练效果,从而提高模型精度。然而,混合迁移学习同时使用两种以上的迁移学习方法,增加了问题解决的难度和复杂性。
结合领域知识
如今,在给定医疗数据集之外引入更多信息已成为解决小型医疗数据集问题的一种更有前景的方法。引入外部信息以提高CAD深度学习模型的性能的想法并不新鲜。例如,通常的做法是首先在一些自然图像数据集(如ImageNet)上训练深度学习模型,然后在目标医学数据集上对其进行微调,这一过程被称为迁移学习,隐含地引入了来自自然图像的信息。除了自然图像外,多模态医学数据集或来自不同但相关疾病的医学图像也可用于改善深度学习模型的性能。
此外,由于经验丰富的医生(如放射科医生、眼科医生和皮肤科医生)通常可以给出相当准确的结果,因此他们的知识可以帮助深度学习模型更好地完成指定任务也就不足为奇了。医生的领域知识包括他们浏览图像的方式、他们通常关注的特定区域、他们特别关注的特征以及他们使用的解剖学先验知识。多年来,大量从业者基于大量案例积累、总结和验证了这些类型的知识,结合这些类型的知识可以提高深度学习模型的诊断性能,如下所示。
- 培训方式
可以根据医生训练的过程来去训练模型。医学生的训练过程有一个特点:他们接受越来越困难的任务训练。 - 诊断流程
有经验的医生在阅读医学图像时通常遵循一些模式。这些模式可以通过适当修改的架构集成到深度学习模型中。 - 医生通常关注的区域
当有经验的医生阅读图像时,他们通常关注几个特定区域,因为这些区域比其他地方更能提供疾病诊断的信息。因此,关于医生关注点的信息可能有助于深度学习模型产生更好的结果。上述知识通常表示为“注意力图”,这是由医生给出的注释,表明他们在阅读图像时关注的区域。 - 医生特别注意的特征(征象)
在过去的几十年中,在各个医学领域逐渐制定了许多指南和规则,以指出诊断的一些重要特征。这些特征被称为“手工特征”,因为它们是由医生指定的。 - 使用特征作为CNN的标签
在这种方法中,除了图像的原始分类标签外,医生还为一些手工制作的特征提供标签。这些额外的信息通常通过多任务学习结构并入深度学习模型中。 - 其他类别的知识
对于医学图像,除了分类标签(即正常、恶性或良性)外,放射科医师可能会给出一些额外的类别标签。例如,在乳腺癌的超声诊断中,图像通常具有BI-RADS标签,该标签将图像分类为0∼6,临床报告也是一种重要的知识,可以纳入医学图像分析中。
模型压缩
在一些移动终端或者轻量级的设备中,由于算力较低、内存较小,很难运行庞大的模型或者算法。因此对于模型的部署需要使用模型压缩的方法进行处理。
文章出处登录后可见!