Hierarchical Task Network 层次任务网络


World State是一个主观的对世界的认知,并不是一个真实世界的描述
Sensors负责从游戏环境中抓取各种状态

HTN Domain 存放层次化的树状结构Task和之间的关联关系1
Planner 根据World State从 Domain 里规划 task
Plan Runner 根据 Planner 设定的计划执行 Task,当 Task 执行过程中发生了很多其他问题,Plan Runner 会监控所有的状态并且告知Planner规划另一系列Task (Re-plan)

primitive:单个动作
compound:复合任务


preconditions:检测world state中哪些state条件符合,才会执行,否则返回false,
检查task执行中间是否失败 (对世界的读操作)
effects:task执行完后修改world state (对世界的写操作)

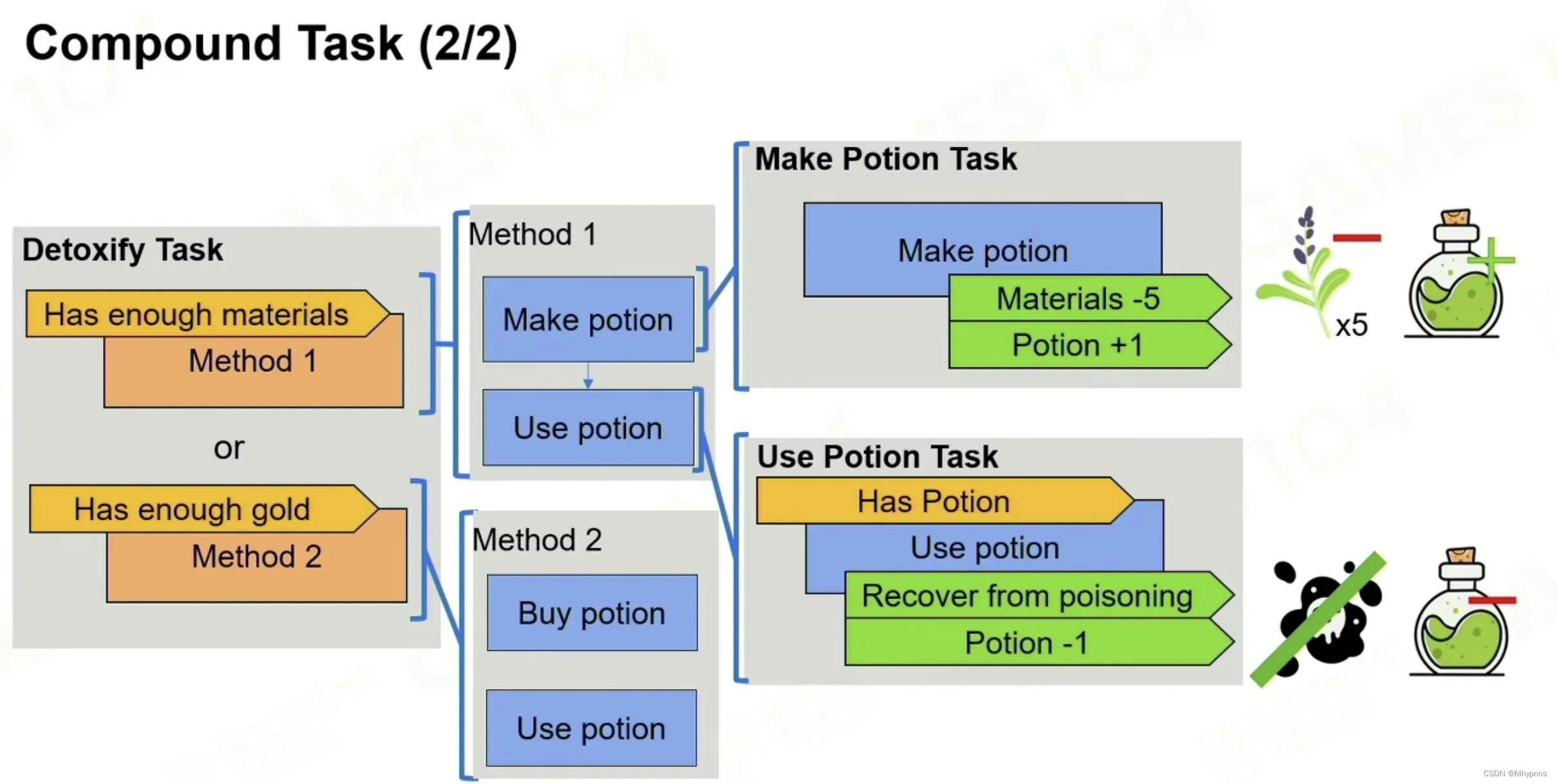
task由一堆Method构成,每个method都有一组属于自己的Precondition, Method自上而下就是优先级 Priority,类似于BT selector功能,
每个method都要执行一系列task、,全部完成,类似于BT selector的Sequence。

Goal-Oriented Action Planning

Goal set目标集:所有可以达成的目标,Htn里并没有显示的定义出目标,是从task树里看出来目标(写在注释里的)。GOAL里的目标都是用数学方式可以表达的
Planning:规划问题

每个goal是由一系列的动作完成后期望世界达成的状态来定量表达的。每个goal在动作完成后需要满足一些World State(一般是bool值),并非单一状态,而是一个目标状态的组合(Collection of States)


相比于Primitive Task,增加了Cost。有设计者定义cost,用来进行动态规划

倒着计划每个action




比较当前目标的world state和外部world state,找出未满足的state,加入到Unsatisfied State的堆栈里,
比较第一个未满足的state,以此在action set里寻找,哪个action输出的effect可改写未满足的state,移除堆栈里可改写的state
如果aciton的precondition是不满足的,把不满足的state提出,反向加入到Unsatisfied state的堆栈,action加入plan stack
最终目标清空Unsatisfied state堆栈,并且期望plan stack里的action cost最少

node:state的一个组合
egde:所有可能的action
distance:action所需的消耗

a*启发函数:选择更接近当前state组合的路径

优点:
1.相比于HTN,GOAP更加的动态
2.将目标和行为真正意义上分开(FSM,BT,HTN,行为和目标是一一锁死的,GOAP同一个目标,可能有多种行为路线,可以超出设计师的想象)
3.可以规避HTN的配置上的死锁等问题
缺点:
1.非常的复杂,计算量大于HTN和BT和FSM
2.GOAP需要对于Game World进行一个定量的表达,复杂的游戏很难通过bool变量去表达World State
通常用于传统的单机的,1V1或者少量AI博弈比较合适
Monte CarloTree Search



蒙特卡洛是一种基于随机采样的算法
State 和 Action 是用于将围棋问题抽象成数学问题的方法
State:世界的现在状态,比如这个时刻所有子的位置
Action:可执行的动作,也就是落子

判断所有的可能性,选择最有利的做法


Q 模拟赢的次数
N 模拟次数
Q / N 判断State的好坏

模拟结果要反向传导更新父节点
 1.选择一个最有可能的且所有可能性未被完全展开的子节点
1.选择一个最有可能的且所有可能性未被完全展开的子节点
2.展开加一次新的探索
3.做一次simulation,对结果进行胜负模拟,确定探索方向的好坏
4.得出结果后,把数值反向传导回父节点


Expandable Node这个node的所有可能性并没有被穷尽

Exploitation 开发:优先寻找胜率高的点,也就是选择N, Q/N值都很大的Node
Exploration 探索 :优先寻找探索 N值较小的

UCB算法:用于平衡开发和探索的算法
优先选择Q/N较高的,然后于父节点N比较,
C用于调整策略平衡,C值越大则越激进(趋向于探索),C值越小越保守(趋向于开发)

从root开始,比较第一圈所有子节点UCB的值,最大值节点作为下一个探索方向,一直往下走到第一个Expandable Node节点(未被完全展开过),作为当前 select node展开
类似BFS,但每次都从root开始往下走

根据性能可模拟一种或多种可能性

每个节点模拟胜负结果并反向更新父节点(每个Node的Q,N依次叠加)

设定一个搜索次数或者内存大小或者计算时间等作为停止条件

停止后得到一个Tree
在第一个子节点里,根据不同的策略方式来选择:
Max Child :选择Q值最大的,也就是胜的最多的
Robust Child :选择最多被访问子节点的,N值最大的,不是 Q/N
Max-Robust Child :最大的 Q 和 N 的,如果没有则继续跑直到出现
Secure Child :LCB Lower Confidence Bound,(考虑下执行区间)主要是对采样次数不多的选择进行一个惩罚,还是C的设置问题

优点:
1.会让AI更灵活(有随机数)
2.AI的决策是自我行为不是被动行为,超出设计师想象
缺点:
1.复杂游戏难以定义胜负,以及决策对胜负的影响
2.计算的复杂度很高
MCTS不适用于所有游戏,适用于Turn-base(你一下我一下)以及每个动作有明确输出结果(回合制战斗游戏,输出一个技能,可以精准计算对方会被打掉的血,会改变什么状态)的游戏,也可以结合其他方法作为子系统存在
Machine Learning Basic


本质是分类器,如图像识别

本质是聚类 Clustering,如用户画像构建

减少了案例 unlabeled data 的输入,主要是小样本学习的方向

没有监督也没有判断机制告诉对错。通过奖励让ai自我优化迭代形成自己的策略

本质是一个尝试+搜索 Trial-and-error search,比较难的一件事是奖励是Delay的 Delayed Reward。老鼠走到终点获得奖励不是延迟的,不是每走一步就触发奖惩机制
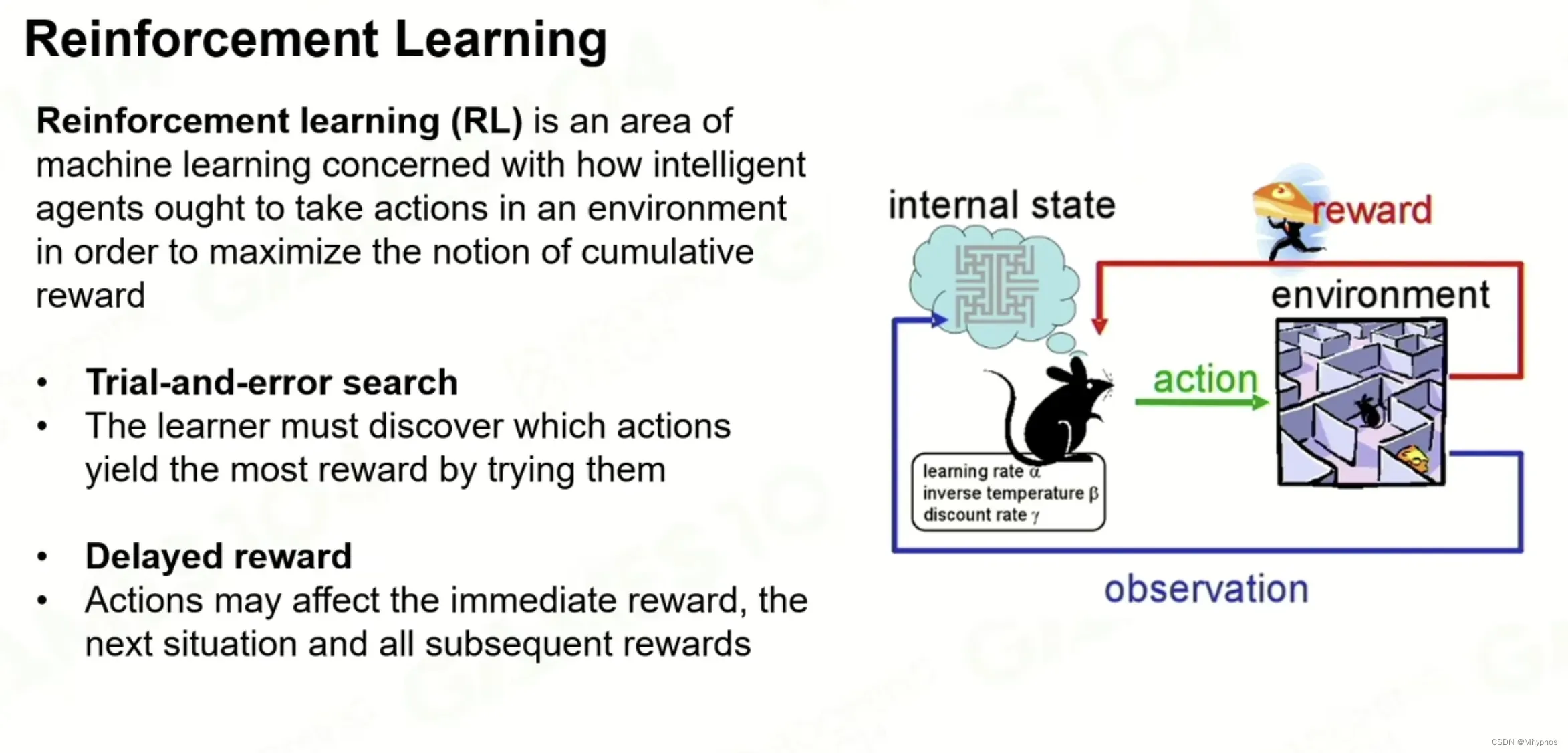





马尔科夫决策过程
当我在当前策略的State s的情况下,我去take一个Action a,到达一个新的状态的 possibility的多少,是一个随机变量
Pollcy:策略黑箱, 也是AI系统的核心,输入一个状态时,输出所有可能动作的概率,也是各种模型优化的核心
Total reward:γ用来平衡短期收益和长期收益,往后的每一步操作之后的状态获得的奖励通过与γ相乘来调整概率

Build Advanced Game AI

过去的算法都是有人类设计的,不会超过人类的预期,机器学习让游戏的行为有无限的可能

重点是对于游戏 Observation 的构建,也就是定量化的描述游戏状态,然后反复优化Policy

state:对世界状态的描述
action:电脑ai要指挥游戏做什么
reward:设置动作的奖励,最简单就是胜负的判断
NN design:构建神经网络的拓扑结构
Training Strategy:训练策略







从下往上看
1.通过各种游戏内的数据输入,Scalar Features, Entities, Minimap等
2.通过不同的神经网络类型,MLP, Transformer和ResNet
3.把所有结果再整合到LSTM里
4.结果是Unreadable的,完成Encode
5.Decode就是把encode的结果翻译成人类可以理解的

多层神经网络:处理定长数据

卷积神经网络:处理各种图像

处理大量时间上不定长的数据

模拟反馈和记忆,多次使用的策略会被记忆,同时有记忆在遗失

对于复杂游戏来说不能直接从零开始训练,因为收敛的速度会非常慢,首先使用人类的数据训练一个基础,相对较好的模型,通过Supervised learning开始
KL Divergence 数值差熵(两个分布之间的差会形成一个熵),用于衡量两个概率分布的距离,差距熵越小代表着两个概率分布越相似,用于衡量AI学习人类操作到了什么地步


MA Main Agents :每天自己和自己打35%,然后和LE和ME打50%,最后和过去的MA打15%
LE League Exploiters :专门寻找所有Agent的弱点 Weakness
ME Main Exploiters :专门寻找主分支MA的缺点
一直独自Training的AI虽然会越来越强,但是会使得能力专一化(过度拟合)
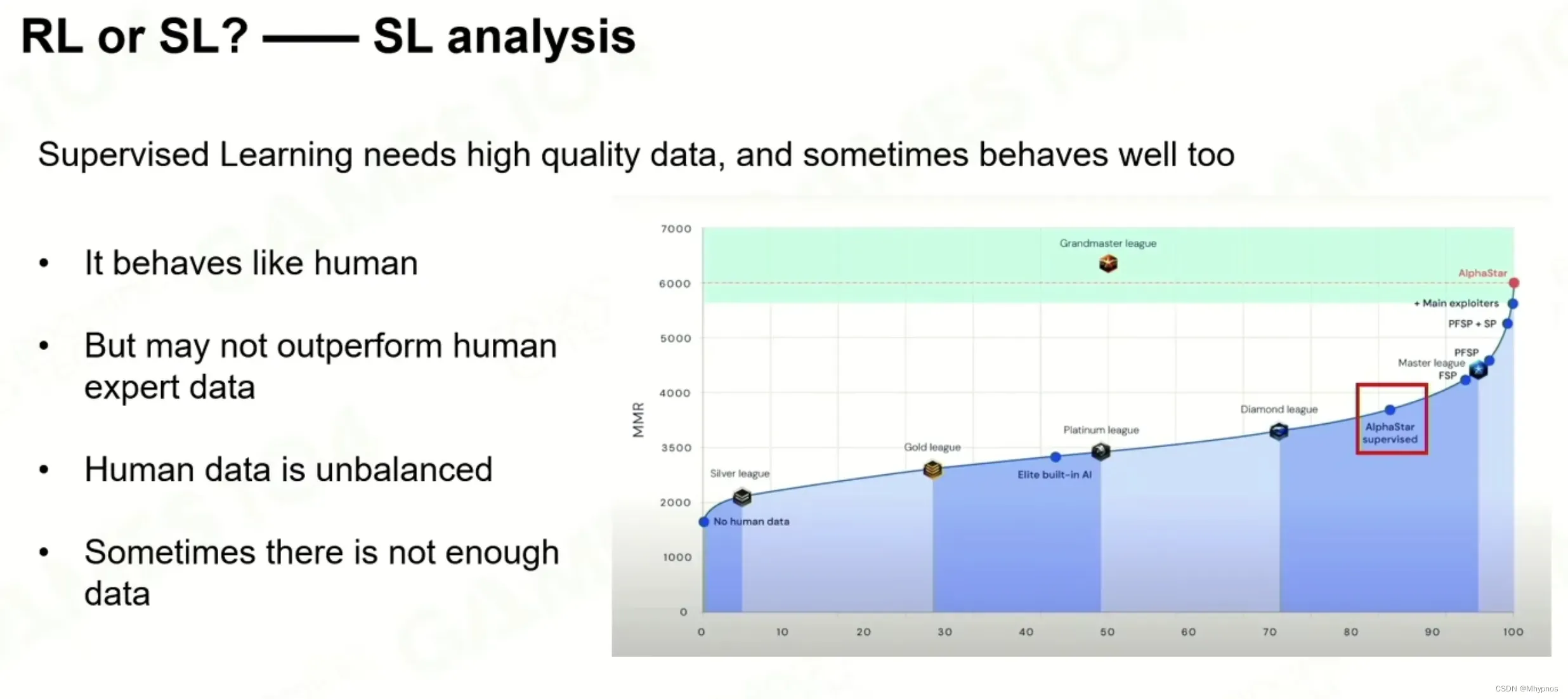
有大量玩家数据的情况下建议首先SL(监督学习),因为可以快速收敛,如果数据量足够大并且足够好,ai可以达到一个不错的水平

增强学习上限非常高,但是训练非常复杂,成本非常高

如果奖励足够密集,每一步或没几下就能判断奖励结果,用增强学习,容易训练出一个好的ai,如果是探索解谜类,一个动作和结果非常的不关联,增强学习的效果比较难
文章出处登录后可见!