LSTM—长短期记忆递归神经网络是一个非常常用的神经网络,其特点在于该网络引入了长时记忆和短时记忆的概念,因而适用于一些有着上下文语境的回归和分类,诸如温度预测或是语义理解。从利用pytorch来构造模型的角度来看,该模型相比于一般的模型会有一些不同的地方,尤其是在参数的设置上,本文尝试以一个相对通俗的方式来解释本人的一些理解。
本文主要参考:全面理解LSTM网络及输入,输出,hidden_size等参数_豆豆小朋友小笔记的博客-CSDN博客
LSTM与一般递归神经网络
如下图,h[t]理解为传递到t时刻的状态,是短时的,改变较快,c[t]是LSTM独有的,理解为长时记忆。相比之下,一般的网络就是把这个状态传递到下一个状态,也就是从h[t-1]到h[t]—短时记忆的传递,而LSTM除了h[t-1]到h[t]的传递,还有一个相对变化缓慢的c[t]的传递,而这个节点主要用于保存信息,因此一般网络在当前点只能看到前面几个接近的点的信息,而LSTM则可以看到前面较长一段时间的记忆,这也就是上下文理解。
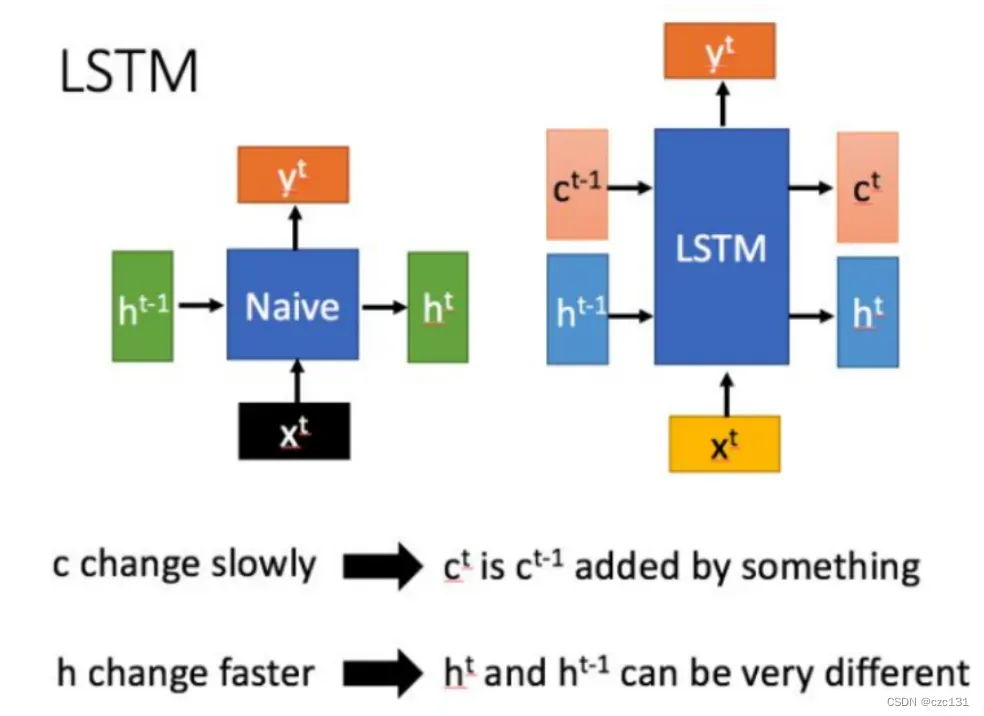
怎样实现传递
那么如何实现长期和短期记忆,LSTM引入了门的概念,一般的网络输入x,经过一些变化,输出结果,结束了,但是LSTM对于x要进行多种处理。
如下图,有两根线横着的贯穿时间序列的线 , 上面的一根是长时记忆c,下面是短时记忆h,其中![]() 代表的是门控状态值,是一个比例,每次经过这个都需要进行遗忘,σ代表sigmoid激活函数,经过这个可以得到一个数字∈[0,1],也就是遗忘比例。输入x进来先和上一个时刻短时记忆混合,然后经过三个门控操作。先看左上的第一个,长期记忆c经过,因此长期记忆遗忘部分;再看中间的,表示的是短时记忆要遗忘部分,此时再上去和长时记忆求和,形成了新的长时记忆;最后是右下角的,这个是当前长时记忆和短时记忆进行tanh激活运算,这样之后我们就得到了当下新的短时记忆,然后长时记忆和短时记忆继续往下影响下面的,形成一个递归网络。
代表的是门控状态值,是一个比例,每次经过这个都需要进行遗忘,σ代表sigmoid激活函数,经过这个可以得到一个数字∈[0,1],也就是遗忘比例。输入x进来先和上一个时刻短时记忆混合,然后经过三个门控操作。先看左上的第一个,长期记忆c经过,因此长期记忆遗忘部分;再看中间的,表示的是短时记忆要遗忘部分,此时再上去和长时记忆求和,形成了新的长时记忆;最后是右下角的,这个是当前长时记忆和短时记忆进行tanh激活运算,这样之后我们就得到了当下新的短时记忆,然后长时记忆和短时记忆继续往下影响下面的,形成一个递归网络。
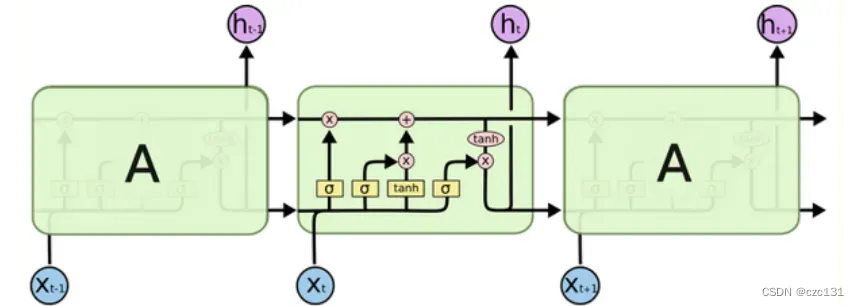
这个过程实际上非常生动,从阅读一本书的角度来理解,我们看到的一段文字其实就是当前时间输入x,长期记忆包括前面阅读的内容,而短期记忆就是刚刚阅读的内容。我们阅读了一段内容,首先会结合刚刚阅读过的内容,这就是x和上一个时刻的短时记忆混合,左上的门控表示长期记忆遗忘,就是我们记忆的遗忘;中间的tanh运算就是对当前的字和前一个字的组合进行理解,当然不可能全部记住,因此经过中间的门控遗忘部分进入长期记忆;然后我要结合长期记忆和当前的内容上下文对当前阅读的内容进行理解,产生新的理解,那么就是tanh激活;最后遗忘一部分成为下一个时刻的“刚刚阅读”。宏观来看,越长时间前阅读的内容,忘记的也越多,这也符合传递过程中,相距越远的记忆影响越小的特点。
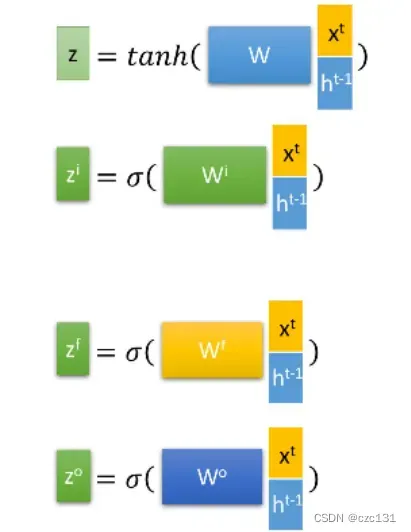
具体到实现,那么就是以下几个运算,就不多进行展开。
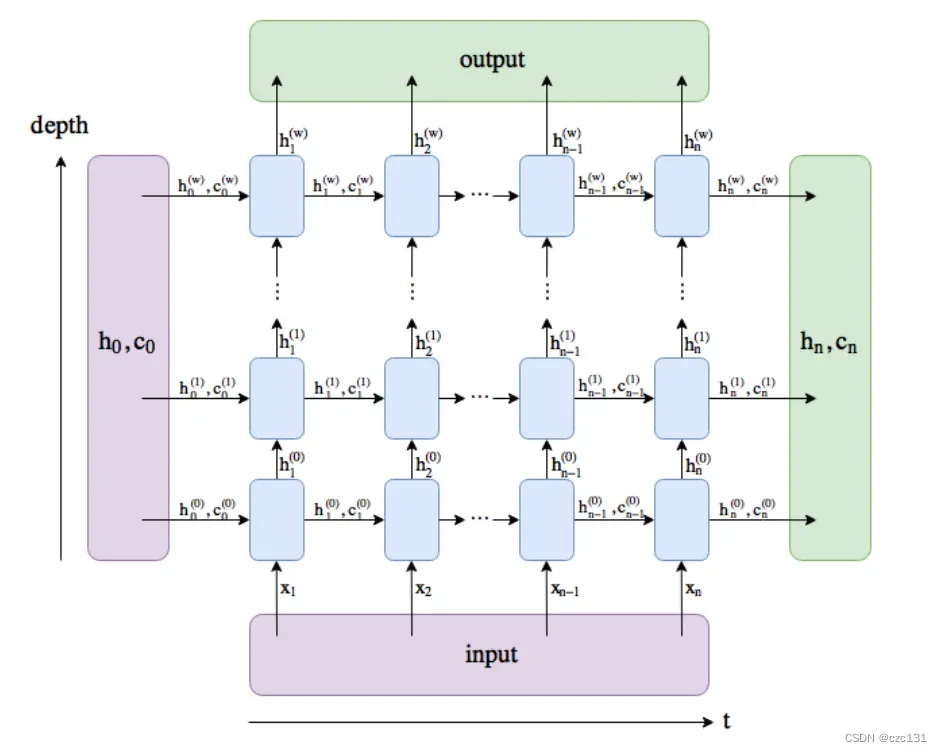
下图是一个整体的LSTM网络的结构,也就是一个序列输入和输出所经历的变化,对于后面参数的理解非常有帮助。整体输入是所有数据的其中一个时间序列,一个序列包含了若干单元,横向分布,类似于从文章中选出的一句话,包含了若干个字;纵向分布是网络层的不断深入,也就是一般网络的多层神经结构。每个蓝色方框就是一个神经元,观察其中一个神经元,其接收前一个序列的同层的长时和短时影响,同时接收此此序列上一层的短时影响,同时继续影响下一层和下面的序列(直接影响下一个,间接影响下一个后面的所有)。最终的output包含了每个序列的输出特征,本质上就是在记录每一个序列的短时记忆,最后拼接起来。而hn和cn则是记录了第n个序列短时记忆和长时记忆。
LSTM网络参数理解
下面就来到利用pytorch构造LSTM网络的时间,代码是不难找到,但是往往难以理解里面的参数含义,我自己也没有找到非常让我满意的解析,下面从我的角度详细解析几个难以理解的参数。
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size, seq_length) -> None:
super(Net, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.batch_size = batch_size
self.seq_length = seq_length
self.num_directions = 1 # 单向LSTM
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers,
batch_first=True) # LSTM层假设构造一个了以上的一个简单的LSTM模型,下面给出所有参数的解释。
seq_length = 3 # 时间步长,可以自己设置
input_size = 3 # 输入维度大小
num_layers = 6 # 网络层数
hidden_size = 12 # 隐藏层大小
batch_size = 64 # 批数量
output_size = 1 # 输出维度num_directions=1 # 表示单向LSTM,等于2就是双向LSTM
input_size和output_size是很好理解的,也就是x和y的维度数,不多做解释,num_directions表示LSTM的方向数,这个我倒没研究过,可能双向就是正反都进行?
seq_length就是每个时间序列包含多少个单元,或者说包含多少条数据,如果是3的话那么每次把3个时刻的数据包装成一条,并且打上一个相应的y标签作为一条数据,也就是一个序列seq。
num_layers就是网络的层数,上面那张整体结构体就的深度就是这里的层数。
batch-size表示的是一次送入多少批数据进行训练,我个人喜欢理解成叠加的层数,在一般网络中,如图像识别,就是一次对多张图片进行训练,相当于把batch-size张图片叠加在一起,然后优化参数,在LSTM中类似,也就是一次送入多批时间序列进行训练。
最后是hidden-size,hidden-size是开始比较困扰我的,这是隐藏层hn大小,也就是短期记忆的大小(列数)。这里就需要结合前面的图进行理解,每次的x数据进来,并不是直接进入网络的,而是要和隐藏层进行混合,也就是x[n]和要h[n]进行叠加,把列数相加,然后送入模型训练,因此这真正网络模型的权重参数的列数一定是hidden_size+input_size,经过网络然后形成新的短时记忆h[n+1],这时的列数为就是hidden_size,最后再和x[n+1]进行混合,再形成新的短时记忆向下传播。
下面的两个参数矩阵大小结合整体图进行理解:
(h[n], c[n])
h[n] shape:(num_layers * num_directions, batch_size, hidden_size)
c[n] shape:(num_layers * num_directions, batch_size, hidden_size)如上,这就是整个隐藏层状态的具体大小,分别是长期记忆和短期记忆,大体一致。以h[n]也就是第n层整体的短期记忆为例,整体记忆实际上就是这一个时间序列的所有时刻在每一层的短期记忆的集合,结合图,一列有num_layers层,每一层都有一个大小为hidden_size的输出,那么叠加就变成了num_layers个hidden_size长度,而每个hidden_size都有一个batch_size层的叠加,双向LSTM要再*2。
output
output.shape: (seq_length, batch_size, hidden_size * num_directions) 再看输出output,结合图,我们可以看到output是一个时间序列内每个节点在最后一层的短期记忆的输出集合,可以理解为每个节点的短期记忆的集合,长度就是序列内的时刻个数seq_length,每个时刻都是大小为hidden_size,batch_size层的叠加。要注意区分,这个只是训练过程中一个其中一个序列的输出,相当于一组x-y关系中的x输出,不是最终输出,最终的输出还要进行特征映射。
整体来看的话,output是每个时刻的最终短时记忆的集合,反映了这一段时间序列的整体特征,隐藏层h[n]和c[n]都是某一时刻的所有层的长短时记忆,反映的是这一个时刻的特征,往往被用作预测或分类。
文章出处登录后可见!