从UIE模型理解到UIE工业实战
- UIE: 信息抽取的大一统模型
- 原始论文
- 背景
- 信息抽取语言
- 损失函数定义
- 实验与结论
- 结论
- UIE实战
- 实战一:Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】
- 实战二:Paddlenlp之UIE模型实战实体抽取任务【产品型号、品牌、数量等信息识别】
UIE: 信息抽取的大一统模型
原始论文
uie论文链接: https://arxiv.org/abs/2203.12277
uie项目地址:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
背景
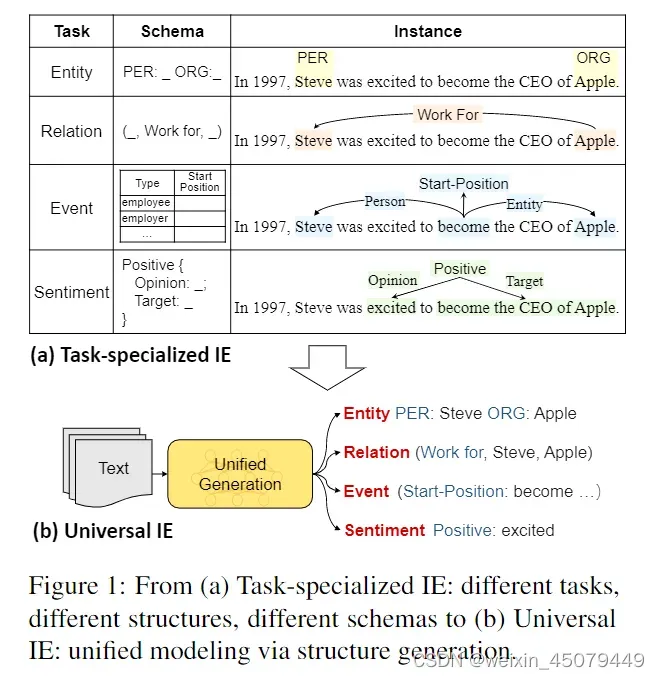
之前的信息抽取做法:子任务实体抽取、关系抽取、事件抽取和情感分析分开抽取,如a。本文要做的是联合抽取,如b
信息抽取语言
作者自定义了结构化的信息抽取语言SEL:结构如下
((定位:实体或触发等
(关系或角色:实体或触发等)
(关系或角色:实体或触发等)))

文章实例:输入句子“Steve became CEO of Apple in 1997.”,则蓝色表示关系抽取,红色表示事件抽取,剩余的是实体抽取。例如,红色部分事件的触发词是became,雇员是Steve,雇主是Apple,时间是1997年
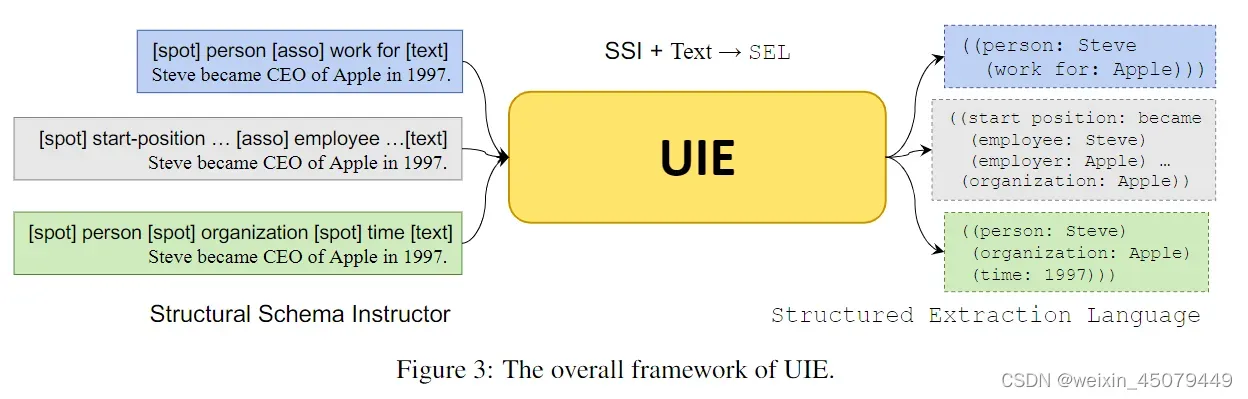
上图就是UIE模型的三大联合抽取任务,左边就是输入数据结构,右边就是预测数据结构,那么模型是如何训练和预测的呢?重点就是定义损失函数(见下小节)。
需要注意的是,这里的输入数据由SSI+Text表示,其中SSI(Structural Schema Instructor)是指结构模式指引,就是提示哪些类型的数据需要被定位和关联,例如“[spot] person [spot] company [asso] work for [text]”表示需要从句子中提取关系模式为“该人为公司工作”,此时,根据SSI提示,UIE模型会对文本test进行编码,再通过编码器-解码器式的架构生成SEL语言的目标记录y

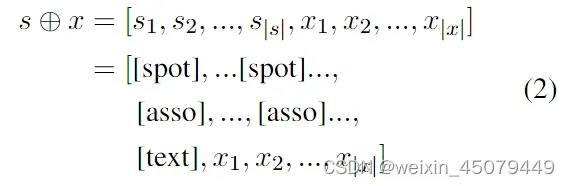
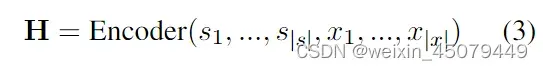
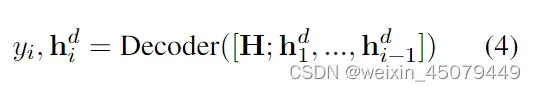
注:(4)式中的h(d)(i)是解码器状态,就是用解码器生成y
损失函数定义
作者定义了三个重要的损失函数:


介绍损失函数之前,作者介绍了他们使用的数据集是知识库(结构化数据)、文本(非结构化数据)和维基百科(并行数据)来预训练UIE模型,并按需微调使预训练的UIE模型适应特定的下游IE任务。简单讲,就是UIE的通用性比较强,可以适应大多数场景的信息抽取任务,实在厉害。
详细结构一下数据集:
数据集1:Dpair是文本x-结构y对的并行数据集,通过维基百科搜集,用于预训练UIE对文本test转换为结构structure的能力。例如 “[spot] person [asso] work for [text]Steve became CEO of Apple in 1997.-((person: Steve(work for: Apple)))”;
数据集2:Drecord是结构化数据集,每一条数据就是结构y,用于预训练UIE的结构解码能力。例如“((person: Steve(work for: Apple)))”
数据集3:Dtext是非结构化数据集,来自英语维基百科所有纯文本,用于预训练UIE的语义编码能力
了解了数据集,下面就是重要的损失函数设计了。
1、第一个损失函数是:Lpair,用于训练模型对文本到结构的映射能力。
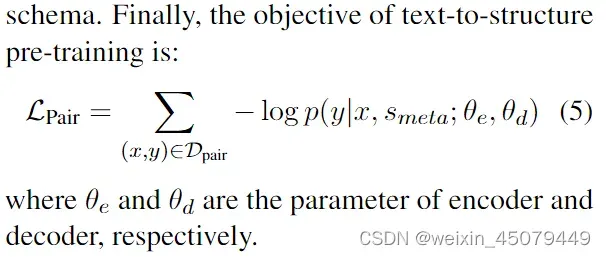
简单理解就是对生成的token加个损失。作者这里还加了一个技巧,在已有正样本的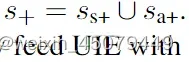
的同时构造了负样本
ss是指spots,sa是指association,负样本的添加可以让模型学习一般的映射能力。
举个例子,正样本是“((person: Steve(work for: Apple)))”,负样本是“((vehicle: Steve(located in: Apple)))”
2、第二个损失函数是:Lrecord,用于训练模型对SEL结构的生成能力。
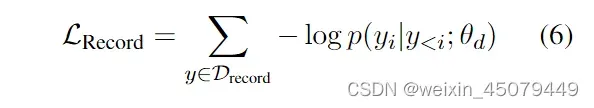
这里用了UIE的decoder解码器作为结构化语言模型,在数据集2 Drecord做预训练,相当于一个自回归损失,通过对结构生成的预训练,解码器可以捕捉到SEL的规律性和不同标签之间的相互作用。
3、第三个损失函数是:Ltext,作者把这个损失叫做改善语义表征(Retrofitting Semantic Representation)。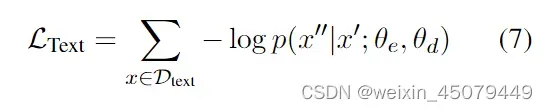
这里就是一个MLM task,一个类似于bert的语言屏蔽模型任务,如果想具体了解参考论文:Exploring the limits of transfer learning with a unified text-to-text transformer
作者认为这个损失的加入可以缓解对SPOTNAME和ASSONAME标记语义的灾难性遗忘(可以参考bert MLM任务)
至此,总损失就是上面三个损失相加:
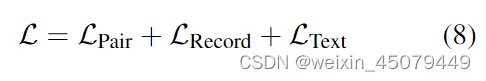
实验与结论
作者采用了13个典型的IE数据集进行了实验,涉及了4个具有代表性的IE任务(包括实体提取、关系提取、事件提取、结构化情感提取)及其组合(例如,联合实体-关系提取),实验结果很惊人(非常好了)
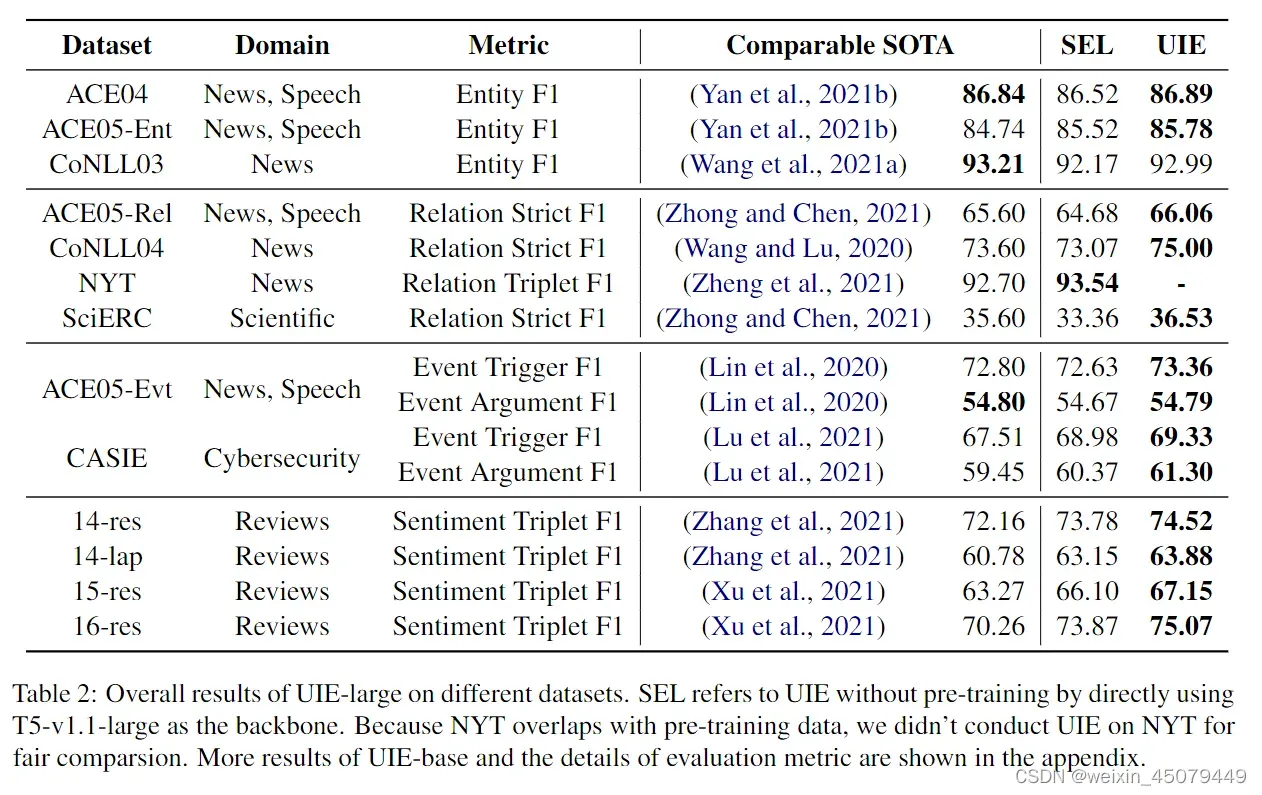
上图是UIE-base模型在13个典型数据集上达到的效果。SEL指的是没有经过预训练的UIE,直接使用T5-v1.1-large的效果,而经过预训练的UIE效果基本上都提升了。
对小样本数据集的实验(Experiments on Low-resource Settings):目的是验证UIE的快速适应能力。作者对原始训练集进行了6种采样,前三种分别是1/5/10shot(就是在少量的实验中,我们对训练集中的每个实体/关系/事件/情感类型的1/5/10句子进行抽样),后三种是直接1/5/10%的比例下采样。
用上面6种方式分别对4个任务中低资源实验,为了避免随机抽样的影响,作者对不同的样本重复每个实验10次,结果如下:
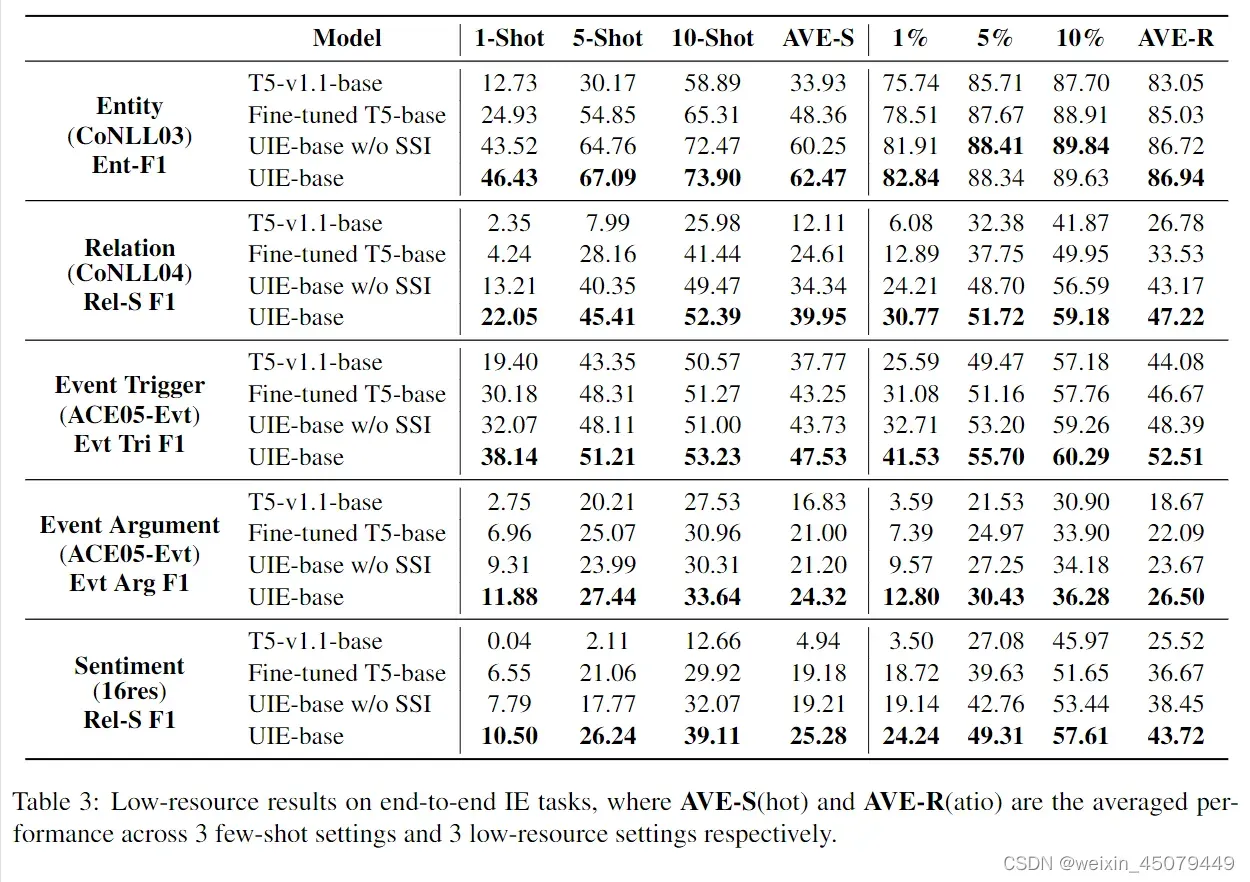
作者还比较了四种模型的效果。其中,1)T5-v1.1-base是UIE-base的初始化模型;2)Fine-tuned T5-base是微调的T5-base模型,这个模型是用与序列生成任务(如摘要)经过微调的模型,这在许多低资源的NLP任务中被证明是有效的(把它拿出来对比,说明UIE比这个通用的T5还要强);3)UIEbase w/o SSI是UIE的有监督版本,就是说在预训练阶段没有SSI(把它拿出来做对比是为了验证SSI在小样本低资源下对适应UIE的必要性)
直接看上图吧,很好的展示出了UIE-base的不错效果。
作者重点说明了UIE模型的优点:1)在与没有SSI的UIE模型相比,配备SSI的UIE在n-shot和n-ratio实验中平均取得了4.16和3.30的改进。2)我们的预训练算法可以学习一般的IE能力,而不是捕捉特定的任务信息。 与只有少量样本的baseline相比,即使UIE的预训练中没有事件和情感相关知识,UIE在这些任务上仍然取得了明显更好的性能。
表4显示了UIE-base在四个下游任务上的消融实验结果,目的是研究不同预训练任务的效果:
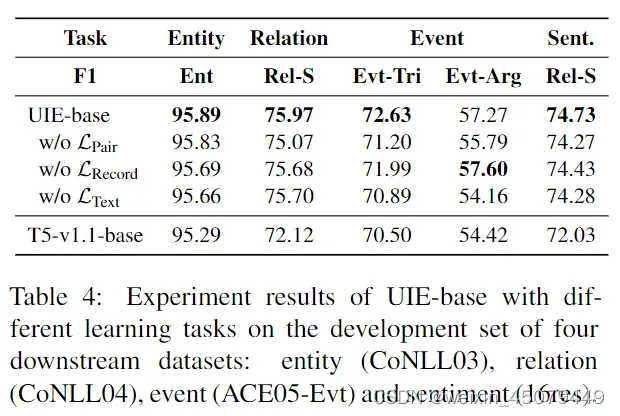
上表说明1)预训练LPair和Lrecord对于UIE-base至关重要;在小数据集CoNLL04和16res上 2)使用掩码语言模型任务LText进行语义改造对于复杂的提取任务更为重要。33种类型的事件提取在去除LText文本任务后性能从72.63下降到70.89。3)用LPair进行映射预训练使模型能够学习提取的能力。消减LPair后,UIE的提取能力明显下降。
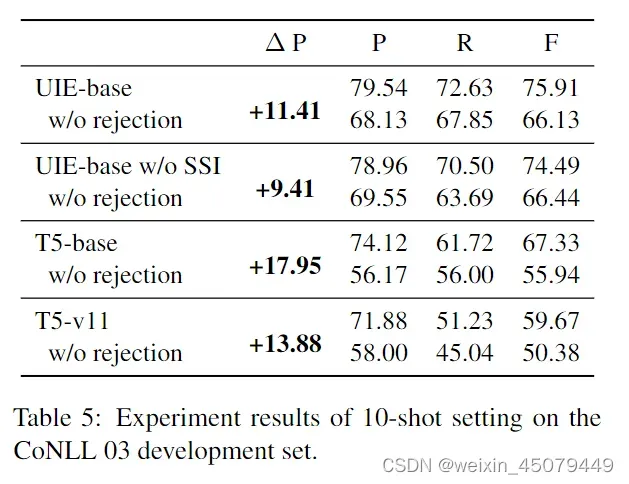
表5展示了生成错误标签与不生成错误标签(负样本)对模型的影响。
结论
作者提出了一个统一的文本到结构生成框架 , 即 UIE , 可以普遍地模拟不同的 信息抽取(IE)任务 , 自适应地生成目标结构 , 并能不厌烦得从不同的知识数据源中学习通用的 IE 能力。作者认为,UIE在有监督和低资源环境下都取得了非常有竞争力的性能,这验证了其普遍性、有效性和可转移性。一个大规模的预训练文本-结构模型的发布有利于未来的研究。对于未来的工作 , 他们希望将 UIE 扩展到 KB 感知的 IE 任务种 , 如实体链接 ( Cao 等人 , 2021 ) , 以及文档感知的 IE 任务 , 如co-reference( Lee 等人 , 2017 ; Lu 等人 , 2022 ) 。
UIE实战
实战一:Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】
本项目将演示如何通过小样本进行模型微调,快速且准确抽取快递单中的目的地、出发地、时间、打车费用等内容,形成结构化信息。辅助物流行业从业者进行有效信息的提取,从而降低客户填单的成本。其他信息抽取项目也可用此项目思想来做。
先看一下结果展示:
输入:
城市内交通费7月5日金额114广州至佛山
从百度大厦到龙泽苑东区打车费二十元
上海虹桥高铁到杭州时间是9月24日费用是73元
上周末坐动车从北京到上海花费五十块五毛
昨天北京飞上海话费一百元
输出:
{"出发地": [{"text": "广州", "start": 15, "end": 17, "probability": 0.9073772252165782}], "目的地": [{"text": "佛山", "start": 18, "end": 20, "probability": 0.9927365183877761}], "时间": [{"text": "7月5日", "start": 6, "end": 10, "probability": 0.9978010396512218}]}
{"出发地": [{"text": "百度大厦", "start": 1, "end": 5, "probability": 0.968825147409472}], "目的地": [{"text": "龙泽苑东区", "start": 6, "end": 11, "probability": 0.9877913072493669}]}
{"目的地": [{"text": "杭州", "start": 7, "end": 9, "probability": 0.9929172180094881}], "时间": [{"text": "9月24日", "start": 12, "end": 17, "probability": 0.9953342057701597}]}
{"出发地": [{"text": "北京", "start": 7, "end": 9, "probability": 0.973048366717471}], "目的地": [{"text": "上海", "start": 10, "end": 12, "probability": 0.988486130309397}], "时间": [{"text": "上周末", "start": 0, "end": 3, "probability": 0.9977407699595275}]}
{"出发地": [{"text": "北京", "start": 2, "end": 4, "probability": 0.974188953533556}], "目的地": [{"text": "上海", "start": 5, "end": 7, "probability": 0.9928200521486445}], "时间": [{"text": "昨天", "start": 0, "end": 2, "probability": 0.9731559534465504}]}
1、先升级paddlenlp
! pip install --upgrade paddlenlp
2、数据集加载(快递单数据、打车数据)
2.1 使用doccano进行数据标注,将标注好的数据放到data文件夹中
# ! wget https://paddlenlp.bj.bcebos.com/uie/datasets/waybill.jsonl
# ! mv waybill.jsonl ./data/
# ! mv doccano_ext.jsonl ./data/
# ! mv dev_test.jsonl ./data/
数据集情况:
waybill.jsonl文件是快递单信息数据集:
{"id": 57, "text": "昌胜远黑龙江省哈尔滨市南岗区宽桥街28号18618391296", "relations": [], "entities": [{"id": 111, "start_offset": 0, "end_offset": 3, "label": "姓名"}, {"id": 112, "start_offset": 3, "end_offset": 7, "label": "省份"}, {"id": 113, "start_offset": 7, "end_offset": 11, "label": "城市"}, {"id": 114, "start_offset": 11, "end_offset": 14, "label": "县区"}, {"id": 115, "start_offset": 14, "end_offset": 20, "label": "详细地址"}, {"id": 116, "start_offset": 20, "end_offset": 31, "label": "电话"}]} {"id": 58, "text": "易颖18500308469山东省烟台市莱阳市富水南路1号", "relations": [], "entities": [{"id": 118, "start_offset": 0, "end_offset": 2, "label": "姓名"}, {"id": 119, "start_offset": 2, "end_offset": 13, "label": "电话"}, {"id": 120, "start_offset": 13, "end_offset": 16, "label": "省份"}, {"id": 121, "start_offset": 16, "end_offset": 19, "label": "城市"}, {"id": 122, "start_offset": 19, "end_offset": 22, "label": "县区"}, {"id": 123, "start_offset": 22, "end_offset": 28, "label": "详细地址"}]}
doccano_ext.jsonl是打车数据集:
{"id": 1, "text": "昨天晚上十点加班打车回家58元", "relations": [], "entities": [{"id": 0, "start_offset": 0, "end_offset": 6, "label": "时间"}, {"id": 1, "start_offset": 11, "end_offset": 12, "label": "目的地"}, {"id": 2, "start_offset": 12, "end_offset": 14, "label": "费用"}]} {"id": 2, "text": "三月三号早上12点46加班,到公司54", "relations": [], "entities": [{"id": 3, "start_offset": 0, "end_offset": 11, "label": "时间"}, {"id": 4, "start_offset": 15, "end_offset": 17, "label": "目的地"}, {"id": 5, "start_offset": 17, "end_offset": 19, "label": "费用"}]} {"id": 3, "text": "8月31号十一点零四工作加班五十块钱", "relations": [], "entities": [{"id": 6, "start_offset": 0, "end_offset": 10, "label": "时间"}, {"id": 7, "start_offset": 14, "end_offset": 16, "label": "费用"}]} {"id": 4, "text": "5月17号晚上10点35分加班打车回家,36块五", "relations": [], "entities": [{"id": 8, "start_offset": 0, "end_offset": 13, "label": "时间"}, {"id": 1, "start_offset": 18, "end_offset": 19, "label": "目的地"}, {"id": 9, "start_offset": 20, "end_offset": 24, "label": "费用"}]} {"id": 5, "text": "2009年1月份通讯费一百元", "relations": [], "entities": [{"id": 10, "start_offset": 0, "end_offset": 7, "label": "时间"}, {"id": 11, "start_offset": 11, "end_offset": 13, "label": "费用"}]}
2.2 转换doccano标注数据集为uie格式的标注数据
!python doccano.py \
--doccano_file ./data/doccano_ext.jsonl \
--task_type 'ext' \
--save_dir ./data \
--splits 0.8 0.1 0.1 \
--negative_ratio 5 \
--seed 1000
参数解释:
doccano_file: 从doccano导出的数据标注文件。
save_dir: 训练数据的保存目录,默认存储在data目录下。
negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。
splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。
task_type: 选择任务类型,可选有抽取和分类两种类型的任务。
options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为[“正向”, “负向”]。
prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为”情感倾向”。
is_shuffle: 是否对数据集进行随机打散,默认为True。
seed: 随机种子,默认为1000.
*separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度级分类任务有效。默认为”##”。
3、训练UIE模型
!python finetune.py \
--train_path "./data/train.txt" \
--dev_path "./data/dev.txt" \
--save_dir "./checkpoint" \
--learning_rate 1e-5 \
--batch_size 8 \
--max_seq_len 512 \
--num_epochs 100 \
--model "uie-base" \
--seed 1000 \
--logging_steps 10 \
--valid_steps 50 \
--device "gpu"
使用标注数据进行小样本训练,模型参数保存在./checkpoint/目录。
推荐使用GPU环境,否则可能会内存溢出。CPU环境下,可以修改model为uie-tiny,适当调下batch_size。
增加准确率的话:–num_epochs 设置大点多训练训练
可配置参数说明:
train_path: 训练集文件路径。
dev_path: 验证集文件路径。
save_dir: 模型存储路径,默认为./checkpoint。
learning_rate: 学习率,默认为1e-5。
batch_size: 批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数,默认为16。
max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。
num_epochs: 训练轮数,默认为100。
model 选择模型,程序会基于选择的模型进行模型微调,可选有uie-base和uie-tiny,默认为uie-base。
seed: 随机种子,默认为1000.
logging_steps: 日志打印的间隔steps数,默认10。
valid_steps: evaluate的间隔steps数,默认100。
device: 选用什么设备进行训练,可选cpu或gpu。
4、评估UIE模型
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/test.txt \
--batch_size 16 \
--max_seq_len 512
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/test.txt \
--debug
可配置参数说明:
model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件model_state.pdparams及配置文件model_config.json。
test_path: 进行评估的测试集文件。
batch_size: 批处理大小,请结合机器情况进行调整,默认为16。
max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。
model: 选择所使用的模型,可选有uie-base, uie-medium, uie-mini, uie-micro和uie-nano,默认为uie-base。
debug: 是否开启debug模式对每个正例类别分别进行评估,该模式仅用于模型调试,默认关闭。
5、结果预测
from pprint import pprint
import json
from paddlenlp import Taskflow
def openreadtxt(file_name):
data = []
file = open(file_name,'r',encoding='UTF-8')
file_data = file.readlines()
for row in file_data:
data.append(row)
return data
data_input=openreadtxt('./input/text1.txt')
schema = ['出发地', '目的地','时间']
few_ie = Taskflow('information_extraction', schema=schema, batch_size=1, task_path='./checkpoint/model_best') #task_path为训练好的模型位置
results=few_ie(data_input)
with open("./output/test.txt", "w+",encoding='UTF-8') as f:
for result in results:
line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码,想输出真正的中文需要指定ensure_ascii=False
f.write(line + "\n")
print("数据结果已导出")
text1输入文件展示:
城市内交通费7月5日金额114广州至佛山
从百度大厦到龙泽苑东区打车费二十元
上海虹桥高铁到杭州时间是9月24日费用是73元
上周末坐动车从北京到上海花费五十块五毛
昨天北京飞上海话费一百元
输出展示:
{"出发地": [{"text": "广州", "start": 15, "end": 17, "probability": 0.9073772252165782}], "目的地": [{"text": "佛山", "start": 18, "end": 20, "probability": 0.9927365183877761}], "时间": [{"text": "7月5日", "start": 6, "end": 10, "probability": 0.9978010396512218}]}
{"出发地": [{"text": "百度大厦", "start": 1, "end": 5, "probability": 0.968825147409472}], "目的地": [{"text": "龙泽苑东区", "start": 6, "end": 11, "probability": 0.9877913072493669}]}
{"目的地": [{"text": "杭州", "start": 7, "end": 9, "probability": 0.9929172180094881}], "时间": [{"text": "9月24日", "start": 12, "end": 17, "probability": 0.9953342057701597}]}
{"出发地": [{"text": "北京", "start": 7, "end": 9, "probability": 0.973048366717471}], "目的地": [{"text": "上海", "start": 10, "end": 12, "probability": 0.988486130309397}], "时间": [{"text": "上周末", "start": 0, "end": 3, "probability": 0.9977407699595275}]}
{"出发地": [{"text": "北京", "start": 2, "end": 4, "probability": 0.974188953533556}], "目的地": [{"text": "上海", "start": 5, "end": 7, "probability": 0.9928200521486445}], "时间": [{"text": "昨天", "start": 0, "end": 2, "probability": 0.9731559534465504}]}
实战二:Paddlenlp之UIE模型实战实体抽取任务【产品型号、品牌、数量等信息识别】
1、需求背景
信息抽取类任务是近几年工业上应用比较广泛的技术。电商行业中电子商城会根据客户订单信息来查询和匹配客户的具体需求,例如服装类电商会匹配客户需求的服装品类、颜色、尺寸、数量等。原始的做法是用人工识别、或者简单的正则匹配来去提取特征,再到数据库中查询符合客户需求的产品型号等信息,人工智能席卷工业界后,电商逐渐引进深度学习技术来替代传统的人工、机器学习等方法。本实战的背景是为解决电子元器件领域电商平台对用户提交的订单进行产品型号等信息识别的需求。用到的模型有:ERNIE\UIE、SBERT对比学习等。
2、结果展示
输入:
['LTC4425IDD#TRPBF ADI 44', 'LTC4380HDD-4#TRPBF ADI 2500', 'LT8652SEV#PBF ADI;LINEAR 105']
输出:
[{'品牌': [{'end': 20, 'probability': 0.9998956, 'start': 17, 'text': 'ADI'}],
'型号': [{'end': 16,
'probability': 0.99998116,
'start': 0,
'text': 'LTC4425IDD#TRPBF'}],
'数量': [{'end': 23, 'probability': 0.9997663, 'start': 21, 'text': '44'}]},
{'品牌': [{'end': 22, 'probability': 0.99987614, 'start': 19, 'text': 'ADI'}],
'型号': [{'end': 18,
'probability': 0.9999769,
'start': 0,
'text': 'LTC4380HDD-4#TRPBF'}],
'数量': [{'end': 27, 'probability': 0.9997887, 'start': 23, 'text': '2500'}]},
{'品牌': [{'end': 24,
'probability': 0.99944764,
'start': 14,
'text': 'ADI;LINEAR'}],
'型号': [{'end': 13,
'probability': 0.99997973,
'start': 0,
'text': 'LT8652SEV#PBF'}],
'数量': [{'end': 28, 'probability': 0.9996749, 'start': 25, 'text': '105'}]}]
3、训练环境配置(需升级paddlenlp,否则报错)
# 升级paddlenlp。如果报错还需卸载和重新安装paddlepaddle:pip install paddlepaddle==2.4.0rc0
!pip install --upgrade paddlenlp
4、数据集加载
步骤一:用doccano标注平台进行标注数据(本项目共标注了3万条数据)
doccano标注后下载数据文件:doccano_3w_1.json
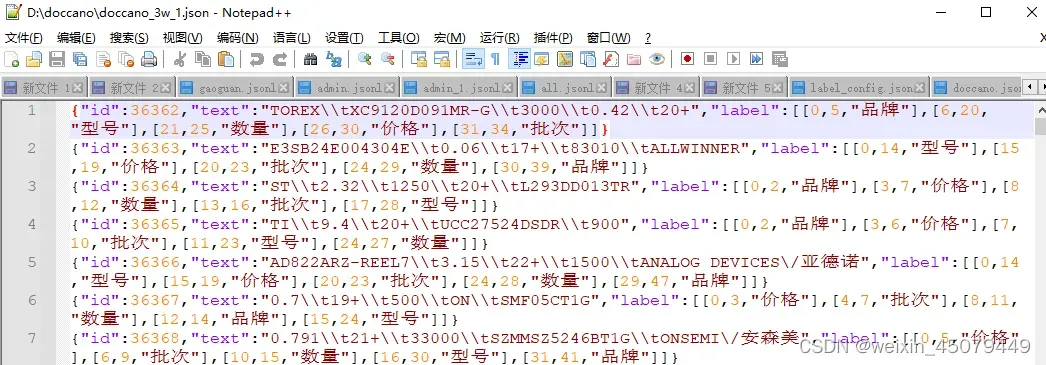
步骤二:转换标注数据集为uie训练的数据格式
python doccano.py --doccano_file ./work/doccano_3w_1.json --task_type ext --save_dir ./work/data3w_1 --splits 0.8 0.2 0
建议将数据保存在work文件夹,如果放在data文件夹下,飞桨会定期删除;可直接用于训练的标准数据集下载地址:https://aistudio.baidu.com/bj-cpu-01/user/4707772/6147417/lab/tree/work/data3w(建议用doccano平台标注或用脚本生成所需的数据集,以便熟悉整个流程)
5、训练模型
# 设定训练好的最佳模型存储路径
export finetuned_model=./checkpoint/model_best
# 训练模型
python finetune.py \
--device gpu \
--logging_steps 10 \
--save_steps 100 \
--eval_steps 100 \
--seed 42 \
--model_name_or_path uie-base \
--output_dir $finetuned_model \
--train_path work/data3w_1/train.txt \
--dev_path work/data3w_1/dev.txt \
--max_seq_length 128 \
--per_device_eval_batch_size 4 \
--per_device_train_batch_size 4 \
--num_train_epochs 10 \
--learning_rate 1e-5 \
--label_names 'start_positions' 'end_positions' \
--do_train \
--export_model_dir $finetuned_model \
--overwrite_output_dir \
--disable_tqdm True \
--metric_for_best_model eval_f1 \
--save_total_limit 1
调参说明:
1)微调时间:3w多条数据,V100 32G GPU环境大概需要6个多小时执行完成
2)num_train_epochs 为1效果不好,10还可以(型号识别率70%),硬件条件好的话设置30以上
3)batch_size = 16效果不好。改小batch_size =4后,效果型号提升到21%,品牌提升到32%,数量下降到72%,总体提升10%
4)epochs为20轮出现过拟合,效果不如10轮好
5)改动学习率lr 效果不明显,建议默认1e-5
6)改用改用uie-nano、uie-m-base后均出现效果下降现象
7)默认max_seq_length为512,改小max_seq_length =128后,效果有明显提升,一些识别不出的品牌、数量可以识别出。建议根据需要识别的单条文本长度调整,即按项目实际情况调整
6、模型评估
直接在notebook上或用脚本调用模型来进行预测,代码如下:
# 模型预测
from pprint import pprint
from paddlenlp import Taskflow
import time
import pandas as pd
# 时间1
old_time = time.time()
f = pd.read_csv('./work/test.csv', encoding='gbk') #70条测试数据
texts = f['输入'][:70].values.tolist()
print(texts)
schema1 = ['型号','品牌','数量','价格','批次','封装','分类','尺寸','阻值','精度','功率','温度系数','容值','电压','等效串联电阻','电感值','电流','直流电阻','Q值','等级','主频','IO数量','电压范围','温度范围','内核','直流反向耐压','平均整流电流','正向压降','反向电流','替代型号','替代品牌']
ie = Taskflow('information_extraction', schema=schema1, task_path='./checkpoint/model_best')
current_time = time.time()
print("数据模型载入运行时间为" + str(current_time - old_time) + "s")
#时间2
old_time1 = time.time()
results=ie(texts)
current_time1 = time.time()
print("模型计算运行时间为" + str(current_time1 - old_time1) + "s")
#时间3
old_time2 = time.time()
with open('./test_result.txt', 'w+', encoding='utf-8') as f:
f.write(str(results))
pprint(results)
current_time2 = time.time()
print("数据导出运行时间为" + str(current_time2 - old_time2) + "s")
预测结果展示(部分):
总耗时2783.4346766471863s
[{'IO数量': [{'end': 19,
'probability': 0.9993238283852008,
'start': 14,
'text': '50000'}],
'功率': [{'end': 13,
'probability': 0.440991799711405,
'start': 11,
'text': 'TI'}],
'反向电流': [{'end': 13,
'probability': 0.35759727639392835,
'start': 11,
'text': 'TI'}],
'品牌': [{'end': 13,
'probability': 0.9997595669970032,
'start': 11,
'text': 'TI'}],
'型号': [{'end': 10,
'probability': 0.9998958115887291,
'start': 0,
'text': 'TXB0108PWR'}],
'容值': [{'end': 13,
'probability': 0.6812789449635943,
'start': 11,
'text': 'TI'}],
'平均整流电流': [{'end': 13,
'probability': 0.5963570205261135,
'start': 11,
'text': 'TI'}],
'数量': [{'end': 19,
'probability': 0.9996966930740641,
'start': 14,
'text': '50000'}],
'替代品牌': [{'end': 13,
'probability': 0.9278777681837767,
'start': 11,
'text': 'TI'}],
'温度范围': [{'end': 13,
'probability': 0.426431107305703,
'start': 11,
'text': 'TI'}],
'直流电阻': [{'end': 13,
'probability': 0.37594026631118993,
'start': 11,
'text': 'TI'}],
'等效串联电阻': [{'end': 13,
'probability': 0.49062035507806456,
'start': 11,
'text': 'TI'}],
'精度': [{'end': 13,
'probability': 0.3204111132783609,
'start': 11,
'text': 'TI'}],
'阻值': [{'end': 13,
'probability': 0.3574524486612276,
'start': 11,
'text': 'TI'}]},...]
7*、模型蒸馏(该部分取决于硬件条件,条件不好的建议阅读,有足够GPU资源的不用做此步骤,直接进行部署即可)
核心思想是采用离线蒸馏方式,首先获取大规模无监督数据(需同源保证分布与训练模型用的数据集一致),再用前面训练好的模型对这些无监督数据进行预测,最后使用标注数据以及对无监督数据的预测数据训练出封闭域Student Model。
步骤一:构造离线蒸馏数据集
共需三个文件,第一个是无监督文本unlabeled_data.txt,如下
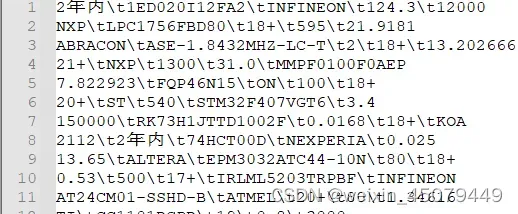 无监督文本构造很简单,直接将用于模型训练的同源数据(原始未标注)取出一些即可,注意要根据硬件条件来确定无监督文本条数,建议给2000条以内。本项目用的是飞桨AI Studio的V100 32G GPU,但为了减少耗时,还是只用了100条无监督文本数据;第二个文件是标注数据doccano_ext.json,如下
无监督文本构造很简单,直接将用于模型训练的同源数据(原始未标注)取出一些即可,注意要根据硬件条件来确定无监督文本条数,建议给2000条以内。本项目用的是飞桨AI Studio的V100 32G GPU,但为了减少耗时,还是只用了100条无监督文本数据;第二个文件是标注数据doccano_ext.json,如下
 注意标注数据需要更改格式,变成离线蒸馏所需的格式(使用简单脚本对doccano标注后的数据集doccano_3w_1.json进行修改即可,提供代码:
注意标注数据需要更改格式,变成离线蒸馏所需的格式(使用简单脚本对doccano标注后的数据集doccano_3w_1.json进行修改即可,提供代码:
# 将只标注实体转换为实体+关系格式。格式转换代码仅供参考。
import re
import json
doccano_label = ['型号', '品牌', '数量', '价格', '批次']
entities2id = {}
with open(r'./doccano_ext.json', 'r', encoding='utf-8') as f:
content = f.readlines()
count = 0
entities_id = 70000
relations_id = 100
while count != len(content):
for line in content:
count += 1
outpath = r'./doccano_r_6w.json'
with open(outpath, 'a', encoding='utf-8') as f:
if eval(line)['text'] != '' and eval(line)['label'] != '':
line_b = line.split('label')[0]
line_l = {}
label_list = eval(line)['label']
entities_val = []
relations_val = []
ent2rel = {}
for label in label_list:
entity = {}
ent = eval(line)['text'][label[0]:label[1]]
if ent not in entities2id:
entities2id[ent] = entities_id
entities_id += 1
entity['id'] = entities2id[ent]
entity['label'] = label[2]
entity['start_offset'] = label[0]
entity['end_offset'] = label[1]
entities_val.append(entity)
if label[2] == '型号':
ent2rel['型号'] = entities2id[ent]
elif label[2] == '品牌':
ent2rel['品牌'] = entities2id[ent]
# # 创建关系
# if len(ent2rel) == 2: #只有一种关系:主动件。多种关系需调整
# relation = {}
# relation['id'] = relations_id
# relation['from_id'] = ent2rel['型号']
# relation['to_id'] = ent2rel['品牌']
# relation['type'] = '主动件'
# relations_val.append(relation)
# relations_id += 1
line_l['entities'] = entities_val
line_l['relations'] = relations_val
line_json = json.dumps(line_l, ensure_ascii=False)
line_l = re.sub(' ', '', str(line_json))
f.write(line_b[:-1] + line_l[1:])
f.write('\n')
#f.write('\n')
);第三个文件是训练采样参数sample_index.json,记录了训练和验证数据的编号,此文件由前面数据集加载时产生,如下
步骤二:通过训练好的UIE定制模型预测无监督数据的标签
# 注意:无监督文本unlabeled_data.txt不要太多,否则耗时太长,建议1000条以内
cd /home/aistudio/data_distill
python data_distill.py \
--data_path /home/aistudio/work/data_distill_unlabel \
--save_dir student_data \
--task_type entity_extraction \
--synthetic_ratio 10 \
--model_path /home/aistudio/checkpoint_3w/model_best
可配置参数说明:
data_path: 标注数据(doccano_ext.json)及无监督文本(unlabeled_data.txt)路径。model_path: 训练好的UIE定制模型路径。save_dir: 学生模型训练数据保存路径。synthetic_ratio: 控制合成数据的比例。最大合成数据数量=synthetic_ratio*标注数据数量。task_type: 选择任务类型,可选有entity_extraction,relation_extraction,event_extraction和opinion_extraction。因为是封闭域信息抽取,需指定任务类型。seed: 随机种子,默认为1000。
步骤三:老师模型评估
UIE微调阶段针对UIE训练格式数据评估模型效果(该评估方式非端到端评估,不适合关系、事件等任务),可通过以下评估脚本针对原始标注格式数据评估模型效果
cd /home/aistudio/data_distill
python evaluate_teacher.py \
--task_type entity_extraction \
--test_path ./student_data/dev_data.json \
--label_maps_path ./student_data/label_maps.json \
--model_path /home/aistudio/checkpoint_3w/model_best \
--max_seq_len 128 #可以尝试不加,查看256是否可以
可配置参数说明:
model_path: 训练好的UIE定制模型路径。
test_path: 测试数据集路径。
label_maps_path: 学生模型标签字典。
batch_size: 批处理大小,默认为8。
max_seq_len: 最大文本长度,默认为256。
task_type: 选择任务类型,可选有entity_extraction,relation_extraction,event_extraction和opinion_extraction。因为是封闭域信息抽取的评估,需指定任务类型。
结果展示:
aistudio@jupyter-3723932-5602938:~/data_distill$ python evaluate_teacher.py --task_type entity_extraction --test_path ./student_data/dev_data.json --label_maps_path ./student_data/label_maps.json --model_path /home/aistudio/checkpoint_3w/model_best --max_seq_len 128
[2023-04-03 10:28:41,140] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/checkpoint_3w_1/model_best'.
[2023-04-03 10:28:41,164] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'ernie-3.0-base-zh'.
[2023-04-03 10:28:41,165] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-3.0-base-zh/ernie_3.0_base_zh_vocab.txt
[2023-04-03 10:28:41,187] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/ernie-3.0-base-zh/tokenizer_config.json
[2023-04-03 10:28:41,187] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/ernie-3.0-base-zh/special_tokens_map.json
[2023-04-03 10:37:01,468] [ INFO] - Evaluation precision: {'entity_f1': 0.4, 'entity_precision': 0.29412, 'entity_recall': 0.625}
步骤四:学生模型训练
# cd /home/aistudio/data_distill
# 可以改大epochs和batch_size尝试效果
# 可以改encoder\warmup策略
# 注意先安装python -m pip install paddlepaddle-gpu==2.4.2.post117 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
python train.py \
--task_type entity_extraction \
--train_path student_data/train_data.json \
--dev_path student_data/dev_data.json \
--label_maps_path student_data/label_maps.json \
--num_epochs 10 \
--encoder ernie-3.0-mini-zh\
--device "gpu"\
--valid_steps 100\
--logging_steps 10\
--save_dir './checkpoint2'\
--batch_size 4 \
--max_seq_len 128
可配置参数说明:
train_path: 训练集文件路径。
dev_path: 验证集文件路径。
batch_size: 批处理大小,默认为16。
learning_rate: 学习率,默认为3e-5。
save_dir: 模型存储路径,默认为./checkpoint。
max_seq_len: 最大文本长度,默认为256。
weight_decay: 表示AdamW优化器中使用的 weight_decay 的系数。
warmup_proportion: 学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0.0。
num_epochs: 训练轮数,默认为100。
seed: 随机种子,默认为1000。
encoder: 选择学生模型的模型底座,默认为ernie-3.0-mini-zh。
task_type: 选择任务类型,可选有entity_extraction,relation_extraction,event_extraction和opinion_extraction。因为是封闭域信息抽取,需指定任务类型。
logging_steps: 日志打印的间隔steps数,默认10。
valid_steps: evaluate的间隔steps数,默认200。
device: 选用什么设备进行训练,可选cpu或gpu。
init_from_ckpt: 可选,模型参数路径,热启动模型训练;默认为None。
注:底座模型encoder参数可以参考下面进行替换
Pretrained Weight Language Details of the model
ernie-1.0-base-zh Chinese 12-layer, 768-hidden, 12-heads, 108M parameters. Trained on Chinese text.
ernie-tiny Chinese 3-layer, 1024-hidden, 16-heads, _M parameters. Trained on Chinese text.
ernie-2.0-base-en English 12-layer, 768-hidden, 12-heads, 103M parameters. Trained on lower-cased English text.
ernie-2.0-base-en-finetuned-squad English 12-layer, 768-hidden, 12-heads, 110M parameters. Trained on finetuned squad text.
ernie-2.0-large-en English 24-layer, 1024-hidden, 16-heads, 336M parameters. Trained on lower-cased English text.
ernie-3.0-base-zh Chinese 12-layer, 768-hidden, 12-heads, 118M parameters. Trained on Chinese text.
ernie-3.0-medium-zh Chinese 6-layer, 768-hidden, 12-heads, 75M parameters. Trained on Chinese text.
ernie-3.0-mini-zh Chinese 6-layer, 384-hidden, 12-heads, 27M parameters. Trained on Chinese text.
ernie-3.0-micro-zh Chinese 4-layer, 384-hidden, 12-heads, 23M parameters. Trained on Chinese text.
ernie-3.0-nano-zh Chinese 4-layer, 312-hidden, 12-heads, 18M parameters. Trained on Chinese text.
rocketqa-base-cross-encoder Chinese 12-layer, 768-hidden, 12-heads, 118M parameters. Trained on DuReader retrieval text.
rocketqa-medium-cross-encoder Chinese 6-layer, 768-hidden, 12-heads, 75M parameters. Trained on DuReader retrieval text.
rocketqa-mini-cross-encoder Chinese 6-layer, 384-hidden, 12-heads, 27M parameters. Trained on DuReader retrieval text.
如果想用在线蒸馏技术,参考:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-3.0
8、Taskflow部署学生模型以及性能测试
通过Taskflow一键部署封闭域信息抽取模型,task_path为学生模型路径
注意:1)Schema 在闭域信息抽取中是固定的,无需再指定;2)建议将use_faster(默认为False)设定为True。可使用C++实现的高性能分词算子FasterTokenizer进行文本预处理加速。前提是安装FasterTokenizer库后方可使用(pip install faster_tokenizer)
# 蒸馏后:学生模型评估
# 优点:速度快、准确率接近教师模型
# 采用UIE FasterTokenizer 提速测试时间
from pprint import pprint
from paddlenlp import Taskflow
import time
import pandas as pd
# 时间1
old_time = time.time()
f = pd.read_csv('./work/test.csv', encoding='gbk')
texts = f['输入'][:70].values.tolist()
ie = Taskflow('information_extraction', model="uie-data-distill-gp", task_path='./data_distill/checkpoint2/model_best',use_faster=True) # Schema 在闭域信息抽取中是固定的
# 时间1
current_time = time.time()
print("数据模型载入运行时间为" + str(current_time - old_time) + "s")
#时间2
old_time1 = time.time()
results=ie(texts)
current_time1 = time.time()
print("模型计算运行时间为" + str(current_time1 - old_time1) + "s")
#时间3
old_time2 = time.time()
with open('./pre_checkpoint_distill_wendy.txt', 'w+', encoding='utf-8') as f:
f.write(str(results))
pprint(results)
current_time2 = time.time()
print("数据导出运行时间为" + str(current_time2 - old_time2) + "s")
测试结果:
[2023-04-04 15:02:11,183] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './data_distill/checkpoint2/model_best'.
数据模型载入运行时间为0.816422700881958s
模型计算运行时间为1.5694572925567627s
[{'品牌': [{'end': 20, 'probability': 0.9998956, 'start': 17, 'text': 'ADI'}],
'型号': [{'end': 16,
'probability': 0.99998116,
'start': 0,
'text': 'LTC4425IDD#TRPBF'}],
'数量': [{'end': 23, 'probability': 0.9997663, 'start': 21, 'text': '44'}]},...]
数据导出运行时间为2.251406669616699s
(下一篇介绍UIE在图片文本中的信息抽取实战,如电子税票中的信息抽取等应用)
文章出处登录后可见!