文章目录
- 一、神经网络作为生成器
- 二、Generative Adversarial Network 生成式对抗网络(GAN)
- 三、Conditional Generation 条件生成
一、神经网络作为生成器
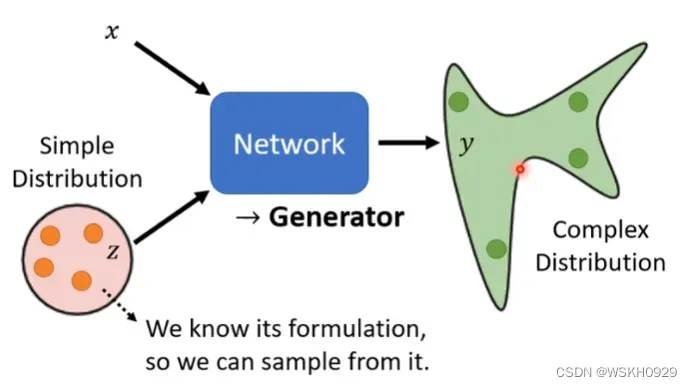
1.1 什么是生成器?
- 一个普通的输入x
- 一个随机的输入z,它要求来自同一个简单的分布(如正态分布、均匀分布等)
- 网络的输入就是x和z,可以采用拼接的方法将他们融合在一起,进行前向传播
- 网络的输出是y,它是一个复杂的分布
这样的网络就可以称是一个生成器,我们可以通过一个普通的输入x加上一个随机的输入z,生成另一个随机的复杂的输出y
1.2 为什么需要输出一个分布?
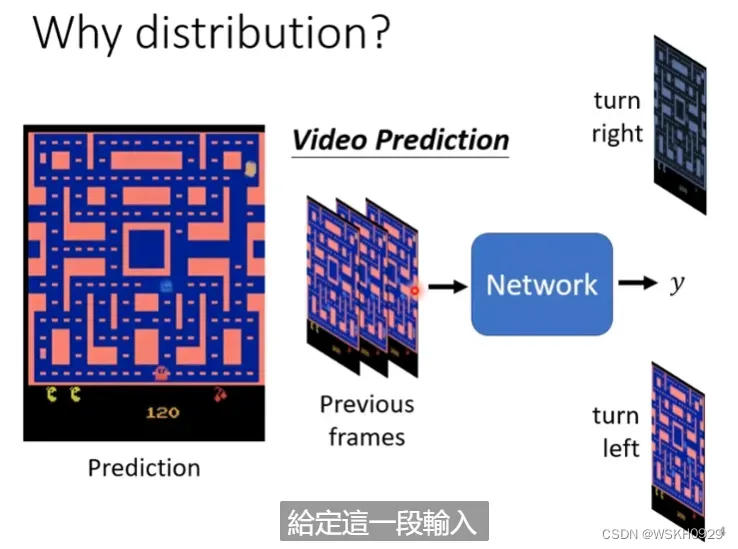
下面是小精灵游戏画面,有很多小精灵在“迷宫”里走动。现给出一个需求,需要通过当前的游戏画面,预测下一帧的画面
传统神经网络的做法是,将前面一帧或几帧的画面图片作为特征,当前画面图片作为标签进行训练,目的是使得通过历史画面,输出的画面和当前画面越接近越好。
有人按照这样的思路做了,结果出现了一个问题,小精灵在走到岔路口时,会一分为二,分裂成两个小精灵,这是为什么呢?
这是因为在岔路口时,即使是同样的历史画面,小精灵也有可能向左走或者向右走,所以在训练集里,很存在这样“矛盾”的标签,即同样的特征,但是输出不同,为了满足“矛盾”的标签,传统神经网络不得不输出同时向左和向右走的两只小精灵。
所以,这个时候,传统神经网络就不能很好地对小精灵画面进行预测了。
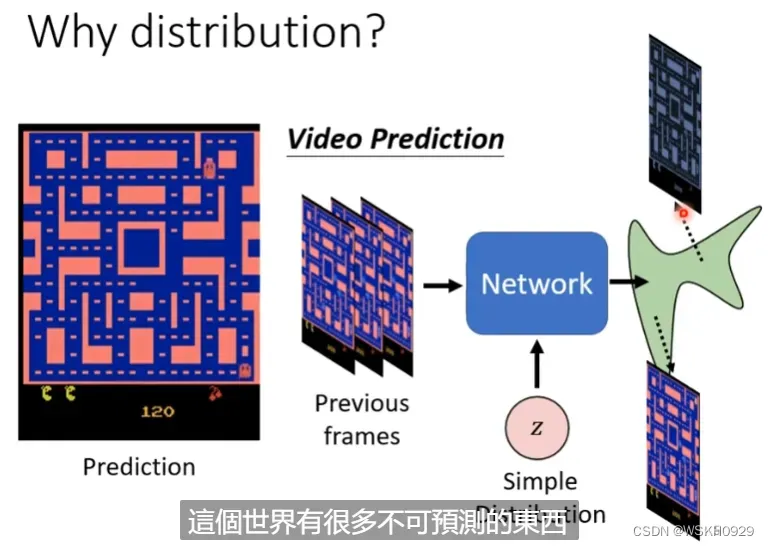
于是,生成器登场了!我们如果给网络加上一个随机的输入,这样即使在同样历史图片的情况下,网络也有可能因为随机输入的不同,导致最终的输出不同。也就相当于输出了一个分布,这个分布里包含了小精灵向左或者向右的可能。
1.3 什么时候需要生成器?
简单来说,当我们希望同样的输入,但是能得到不同的输出的时候,就可以采用生成器、即,具有创造力的事情,同一件事情,每个人做的答案都是不同的,但都是对的。
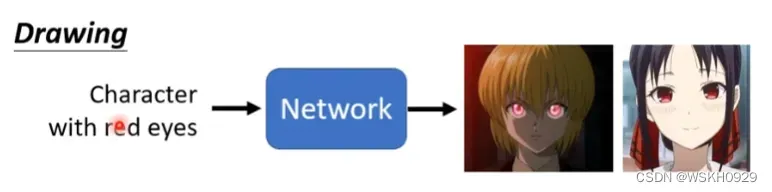
绘制红眼睛,每个人心中的红眼睛都是不同的,所以可以使用生成器
下面就来介绍生成器网络中最经典的网络:GAN 生成式对抗网络
二、Generative Adversarial Network 生成式对抗网络(GAN)
GAN存在非常多的变种,如ACGAN、BGAN、CGAN、DGAN等等,所以对抗生成网络本身也可以用来做很多创造性的事情
2.1 动漫人脸生成例子
2.1.1 例子简介
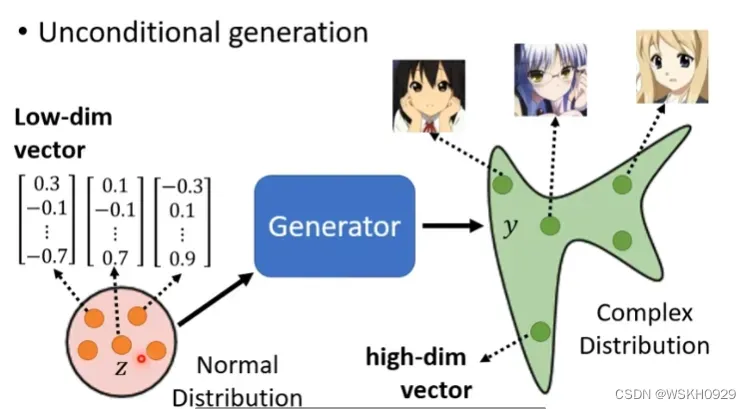
接下来,我们用一个案例来了解GAN。这是一个无条件生成(UnConditional Generation)的案例,即没有输入x,只输入一个来自简单分布的随机向量z
在这里我们使用简单的正态分布来作为随机输入的分布,其可以是一个50维或者100维的向量,输出是一个彩色图片,其维度可以是64×64×3
2.1.2 Discriminator 判别器
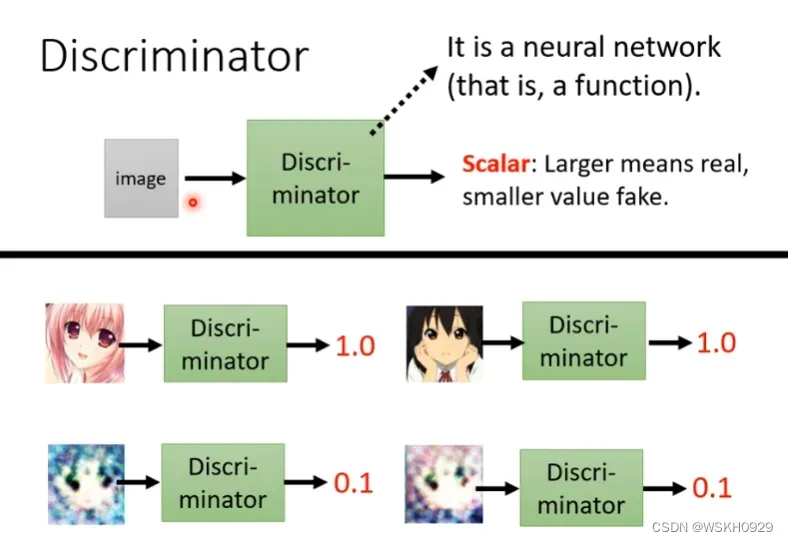
然后我们还需要一个判别器,它通常也是一个神经网络,在动漫人脸生成案例里,它的输入是生成器生成的图片,输出是0-1的实数,其代表的输入图片是动漫人脸的概率。既然涉及到图像,一般都会用到大量CNN的结构。
2.1.3 判别器和生成器的关系
假设生成器是枯叶蝶,判别器是一种鸟类(枯叶蝶的天敌),在远古时期,枯叶蝶可能还是五彩斑斓的,这也导致鸟类只需要通过颜色判断,就可以轻易捕食枯叶蝶,于是,经过长时间的自然选择,枯叶蝶褪去了五彩斑斓的外表,进化成了棕色的蝴蝶,这时候,鸟类就不能靠颜色区分枯叶蝶了,于是大部分找不到枯叶蝶的鸟类会被饿死,经过长时间自然选择,剩下的鸟类都是能够发现枯叶蝶的鸟类了,如此循环反复,鸟类和枯叶蝶一个捕食,一个逃避捕食,不断对抗不断进化,最终进化为了如今如此逼真的枯叶蝶。
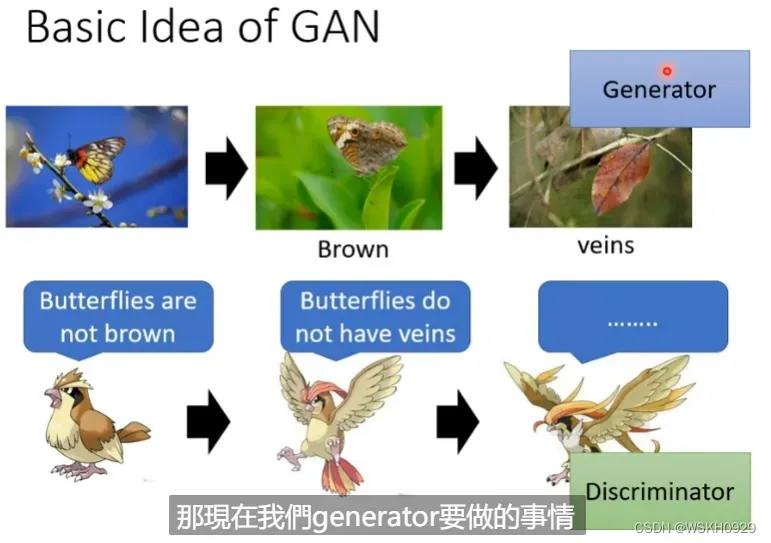
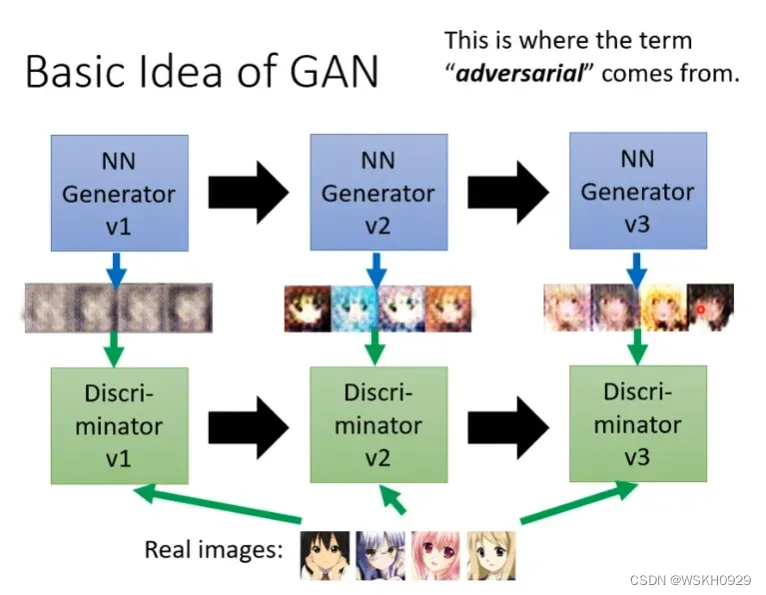
在动漫人脸生成案例中,生成器一开始就是随机生成一些杂讯图片,判别器很容易就通过生成器生成的图片是否有眼睛这个特征就判断出图片的真假,然后生成器就不断调整,直到可以生成有眼睛的图片去欺骗第一代的判别器,然后判别器被骗过后,它也会进化,它觉得不仅要有眼睛,还要有嘴巴才可以是动漫人脸。。。不断反复,判别器的要求越来越严格,生成器生成的图片也越来越逼近真实的动漫人脸。
2.1.4 算法流程
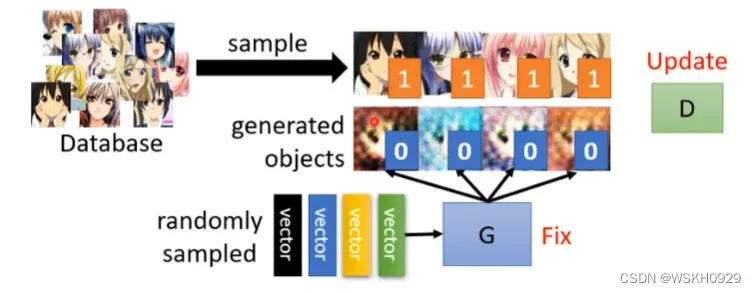
Step1:固定生成器,训练判别器
如何更新判别器呢?我们需要有一个真实动漫人脸图像的数据集,在训练判别器时,我们会用生成器生成一批虚假的动漫人脸图像,并对其标签设置为0 ,真实的动漫人脸图像标签设置为1,然后就当作一个回归问题,用将真实图片和虚假图片合并为一个训练集,对判别器进行训练,判别器的输出是0-1的实数,越接近1说明其越有可能是真实动漫人脸图片。
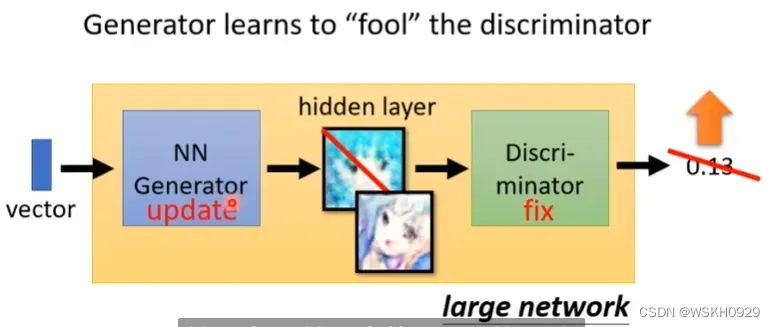
Step2:固定判别器,训练生成器
生成器生成图片,传给判别器,判别器对生成的图片进行打分,这个分值越大说明生成的图片越逼近真实的图片,所以我们希望分值越大越好,如果我们使用梯度下降法来优化生成器网络,那我们就需要用负的评分去进行反向传播,梯度下降。
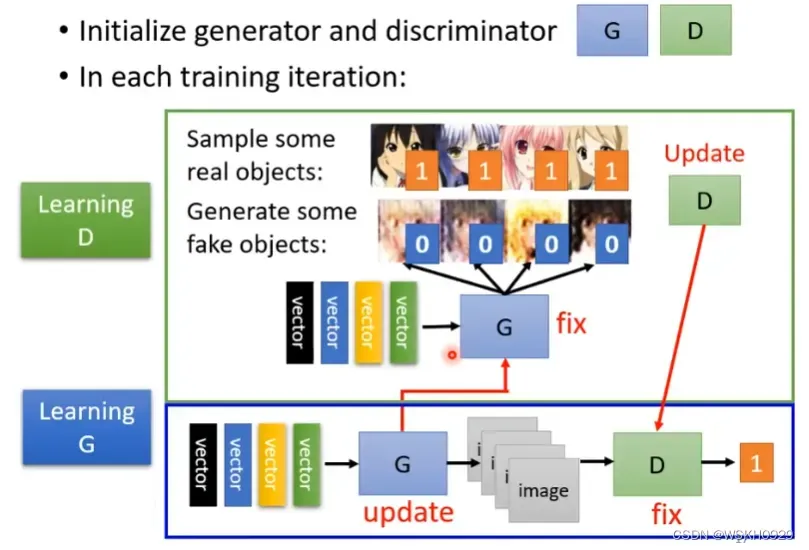
StepN:不断重复Step1和Step2
2.2 GAN 理论介绍
2.2.1 GAN所遇到的问题
我们的目标是,使得生成器输出的”虚假“分布与真实分布越接近越好,我们知道一些可以用来评价两分布之间相似度的指标,如KL散度,但我们大部分情况甚至都不知道真实分布是什么样子的。所以,如何评判两分布的相似度,这也是GAN所遇到的一个问题。
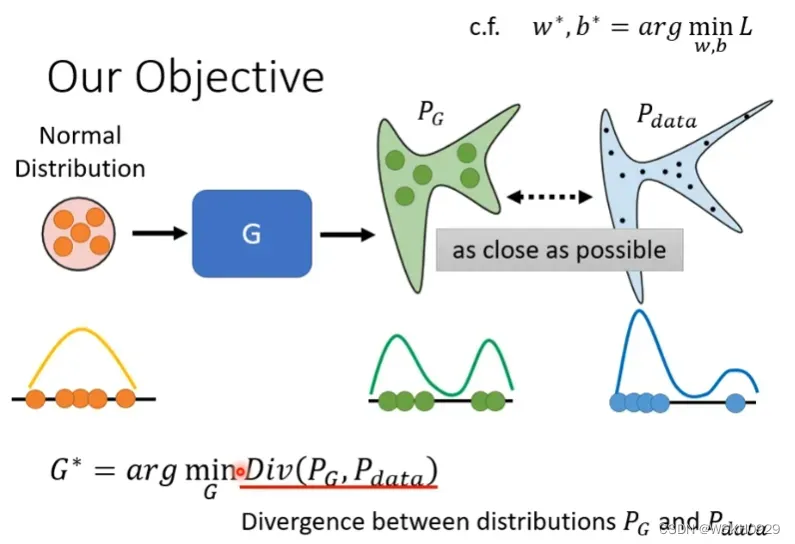
2.2.2 用抽样的方法解决问题
我们可以对真实分布和虚假分布做抽样,例如,用生成器随机生成虚假图片就是对虚假分布做抽样

在有了来自真实分布和虚假分布的数据之后,我们可以对生成器和判别器分别进行训练。
下面是对判别器进行训练,判别器的训练目标是,尽可能使得判别网络对输入真实图片时的期望输出较大,而输入虚假图片时的期望输出较小,由于一个要求较小,一个要求较大,不好统一,所以用1减去虚假图片输出,使得这个值较大,这样两个值就可以相加,使得他们相加的值较大即可。
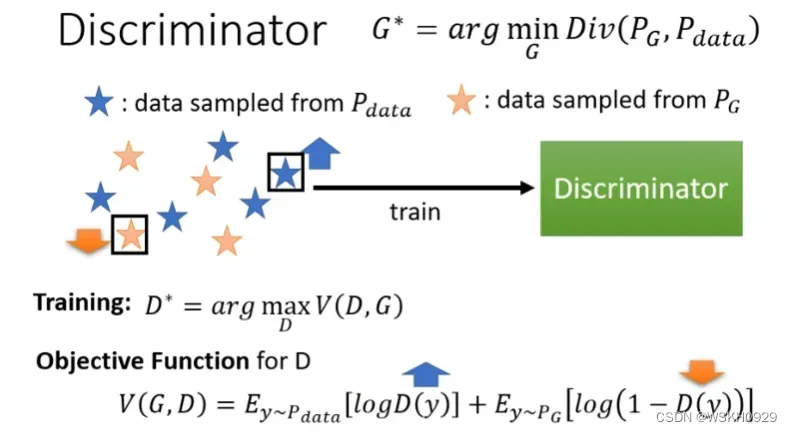
但是生成网络的训练目标就有点复杂了,他的目标是希望判别器的误差较大,即判别器的目标函数较小(判别器目标是极大化的),总的来说,生成器希望最小化判别器的最大化目标值,这样生成器才可以很好地骗过判别器。
这个最小最大化问题就是复杂的地方,在GAN中,为了处理MinMax问题,采取了之前的”轮着训练“的方式,即先固定生成器,训练判别器,再固定判别器,训练生成器,如此循环的方式进行训练。

2.3 GAN训练的小技巧
2.3.1 Wasserstein Distance
Wasserstein距离的起源是 optimal transport problem,把概率分布想象成一堆石子,如何移动一堆石子,通过最小的累积移动距离把它堆成另外一个目标形状,这就是 optimal transport 所关心的问题。
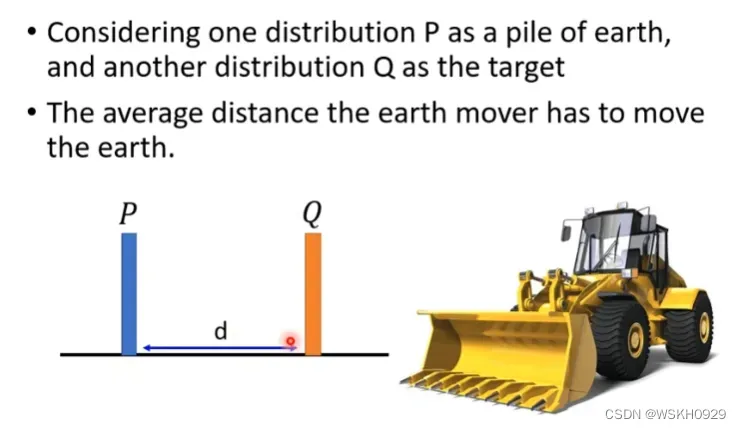
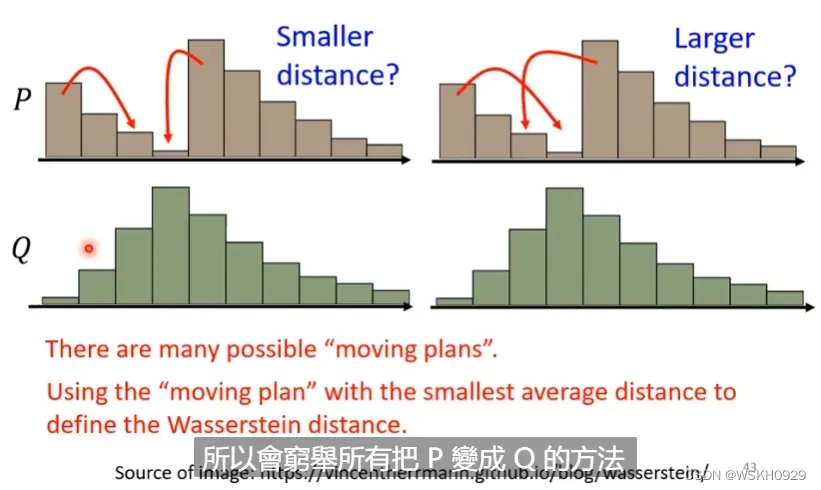
Wasserstein距离是将一个分布变为目标分布的最小的累积移动距离,我们可以通过穷举法穷举出所有移动方法,然后找到最小的累积移动距离
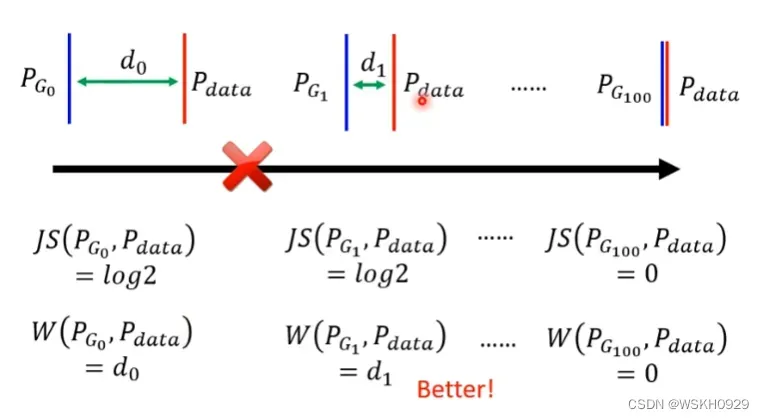
为什么要使用Wasserstein距离?因为如果使用JS散度,其有一个特性,当两个分布没有重叠时,JS散度求出的就是Log2,所以如果两分布没有重叠,无论他们距离多远或者多近,使用JS散度得出来的损失都是Log2,这样我们就无法知道两分布得真实距离了。
Wasserstein距离就可以很好解决这个问题。
2.3.2 WGAN
当我们使用Wasserstein距离取代JS散度时,这种对抗式生成网络就称为WGAN。

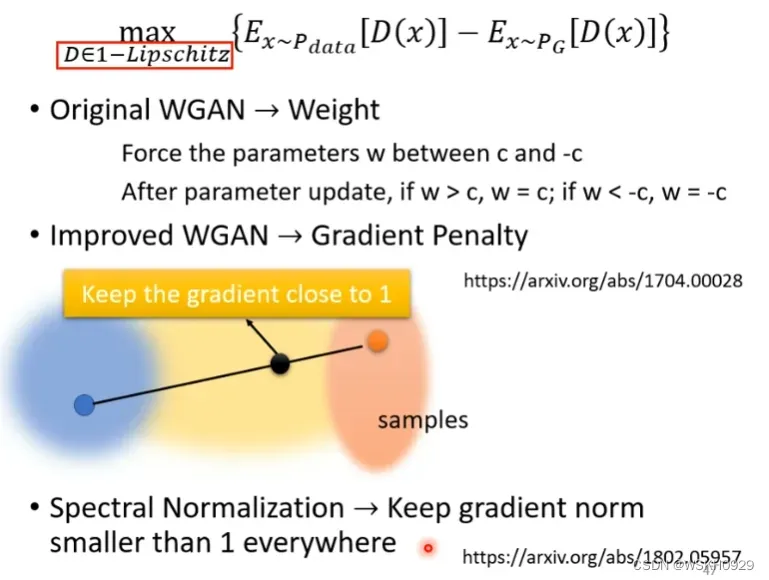
2.3.3 GAN 还是很难训练
即使有了WGAN,GAN还是很难Train起来,这是因为GAN要想收敛,需要生成者和判别者相互砥砺,只要有一方停止训练,或者训练不好,那么另一方也会训练不好。
2.3.4 More Tips

2.4 Evaluation for GAN
2.4.1 利用第三方检测器评估
如果生成动漫人脸,我们可以拿GAN生成的虚假图片,放入一个动漫人脸检测器进行检测,如果
1000张虚假人脸,被检测器检测出了900张,那说明GAN的生成虚假动漫人脸的效果还是可以的(前提是检测器要足够好)
例如:GAN+YOLO

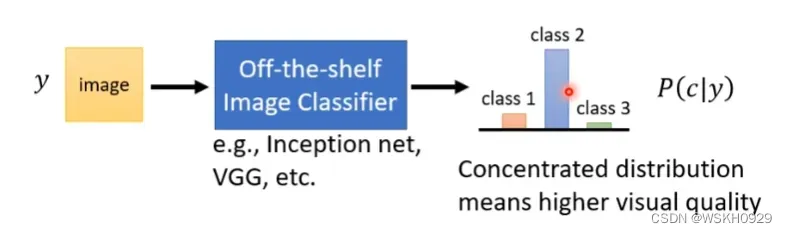
2.4.2 利用影像分类系统评估
将GAN生成的图片传入一个影像分类系统,输出一个概率分布,如果概率分布较为集中,说明分类系统有很大概率认为GAN生成的图片属于某一个类别,如果概率分布比较平均,说明GAN生成的图片四不像。
也可以输入多张图片,得到平均概率输出,如果平均概率输出较为集中,则说明生成的图片多样性不足,如果平均概率分布较为平均,则说明生成的图片具有较好的多样性。
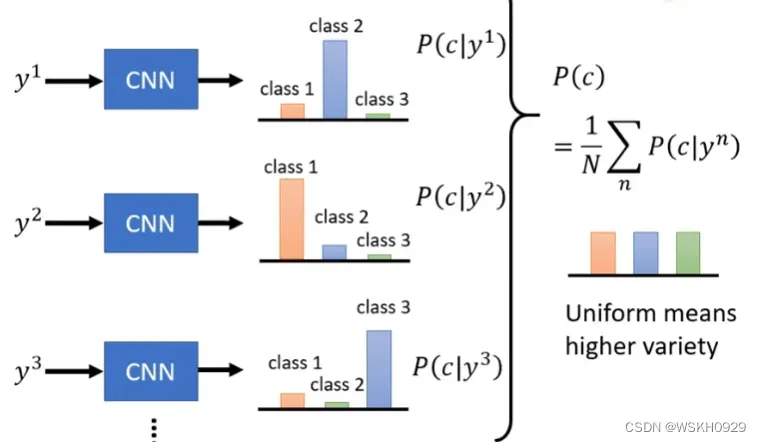
但这样会产生一些问题
2.4.2.1 Mode Collapse 模型坍塌
所谓模型坍塌,就是生成器会生成很多张很相似的动漫人脸,可以直观理解为,生成器发现了判别器的盲点后,瞄准该盲点生成了很多类似的图片。

模型坍塌暂时没有较好的解决方法,强如Google的BGAN也会产生模型坍塌问题,Google采取的做法也比较简单,就是在训练的每一步都把模型保存一下,一旦出现模型坍塌现象,就停止训练,拿之前保存的模型出来用
2.4.2.2 Mode Dropping 模型丢弃
Mode Dropping,指 GAN 能很好地生成训练集中的数据,但难以生成非训练集的数据,“缺乏想象力”。因为采样数量的局限性,现实中我们无法采集到全部可能的图像,即采集到所有可能的图像是不可能的(如果有能力采集到所有可能的图像,那么我们也就不需要 GAN 来生成图像了),所以通常我们会采样,采集一定数量的图像来代表整个图像分布。
如下图所示,generated data 分布过于与训练集 real data 分布近似,但由于 real data 无法代表整体分布,生成器无法生成没见过的图像。可以看到在 iteration t 和 iteration t+1,生成器生成的图像除了颜色以外没有其他的变化。这就像是我们考试前不理解知识点而直接背答案一般,题目一变,就直接不会了。个人感觉这种现象也更像是过拟合于训练集。

2.4.3 FID
FID是从原始图像的计算机视觉特征的统计方面,来衡量两组图像的相似度,是计算真实图像和生成图像的特征向量之间距离的一种度量。
这种视觉特征是使用 Inception v3 图像分类模型提取特征并计算得到的。FID 在最佳情况下的得分为 0.0,表示两组图像相同。分数越低代表两组图像越相似,或者说二者的统计量越相似
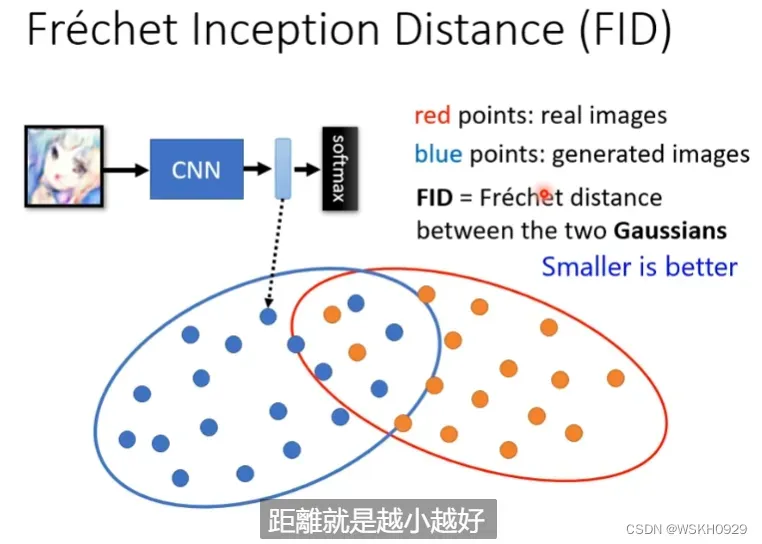
2.4.3.1 Same As Real Data
如果生成器生成的图片和真实图片集里的图片非常相似,我们使用FID的评价指标评价也会认为这是较好的结果,但实际上这是不好的,因为我们使用GAN就是希望得到一些真实图片集里没有的图片。

三、Conditional Generation 条件生成
之前讲的都是无条件生成,即没有一个普通的输入x,接下来我们要将条件生成,即有普通的输入x。
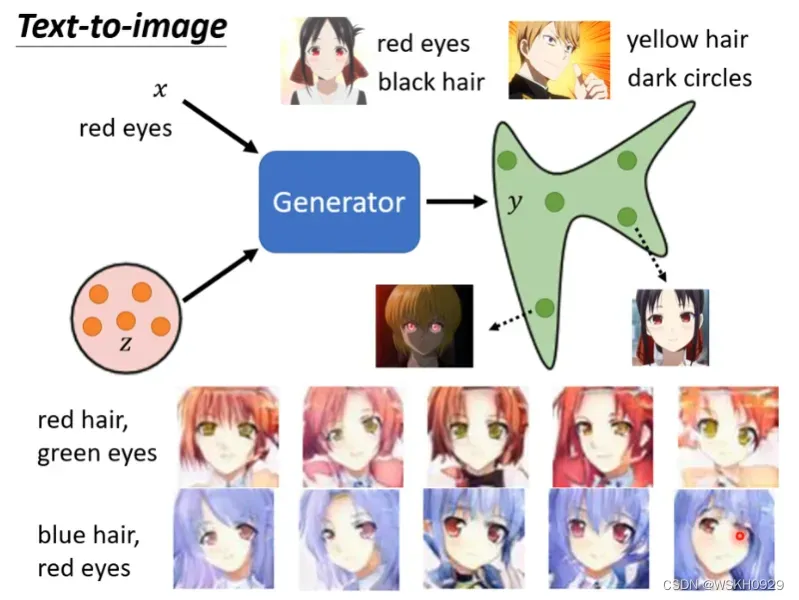
3.1 根据文字描述生成图片
最典型的条件生成例子就是”根据文字生成图片“,如下图所示,输入”red eyes“,输出就是红色眼睛的动漫人物。
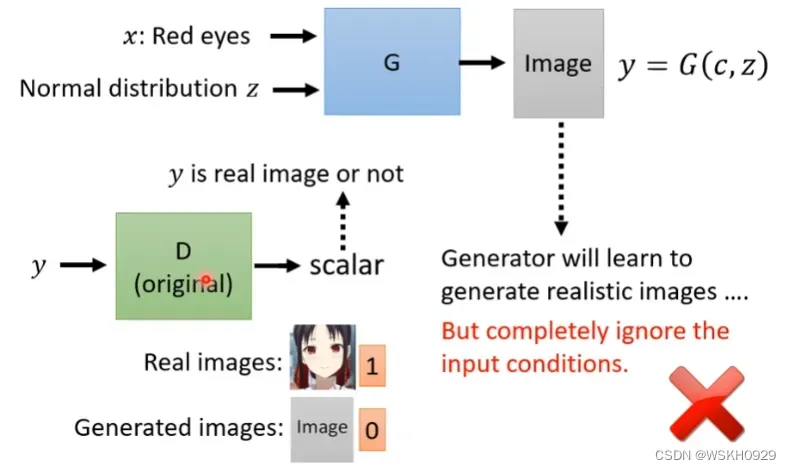
当有了普通的输入x后,我们就不能按照无条件生产的形式,只将生成器生成的虚假图片传给判别器进行判别了,因为如果这样,生成器根本不用管输入x,它只需要产生足够符合动漫人脸的图片就可以了。
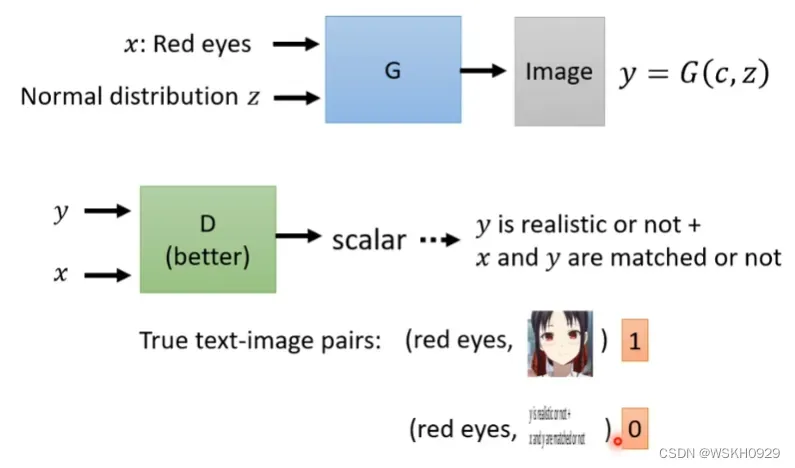
所以我们还需要将输入x也传入判别器,这样才可以让判别器也获取到文字信息。
同时,真实数据集合也必须是图片+文字描述才行,我们还可以对数据集进行增强,即对真实数据集合的图片和文字描述进行打乱重组,就可以进行数据增强啦!
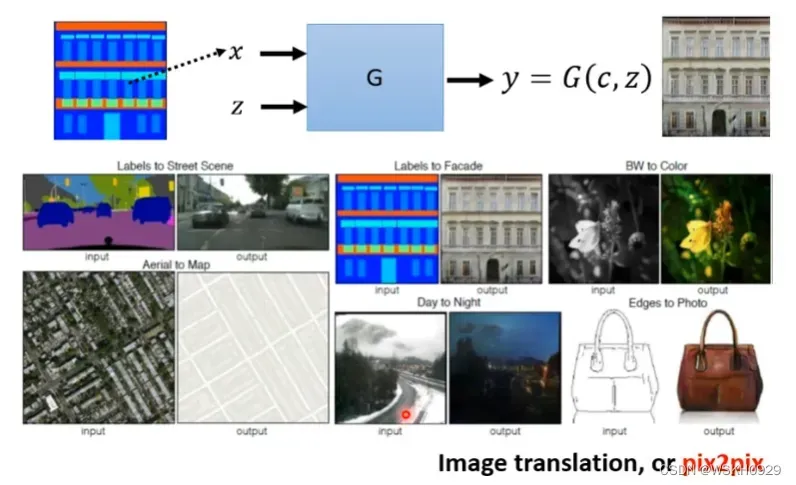
3.2 根据图片生成图片
- 给定一个房屋设计图,输出房屋实景图
- 给定灰色图,输出彩色图
- 给定素描图,输出彩色图
- …
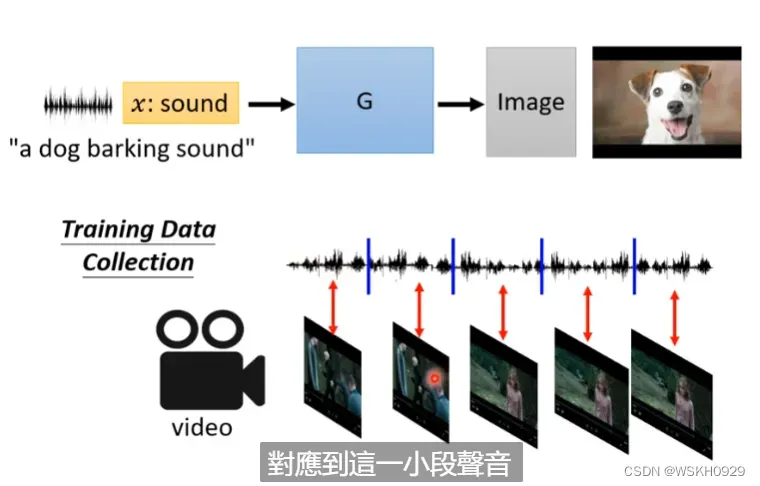
3.3 根据声音生成图片
听一段声音,让GAN想象出一个场景,并输出对应图片。
数据集可以从电影、电视剧中取。数据应当是声音-图片成对的。
3.4 生成会动的图片

文章出处登录后可见!