Residual Net论文笔记
- 1. 传统深度网络的问题
- 2. 残差结构和残差网络
- 2.1 残差是什么
- 2.2 残差模块 Residual Block
- 2.3 基本模块BasicBlock和BottleNeck
- 2.4 残差网络ResNet设计
- 2.4.1 恒等映射与残差的连接
- 3. Forward/Backward Propagation
- 3.1 Forward propogation
- 3.2 Back Propogation
- 4. 代码分析
- 5. 恒等映射
- 6. 分析残差连接
- 7. 不同结构的残差模块
残差网络(Residual Net, ResNet)自从2015年面世以来,凭借其优异的性能在ILSVRC中以绝对优势获得第一名,并成功应用于许多领域。
1. 传统深度网络的问题
在深度学习或者神经领域的研究中,一般认为,网络越深(层数越多),网络的性能应该会更好,因为更深的网络倾向于有更强大的表示能力,即网络容量越大。
但是在实际过程中,我们发现过深的网络反而会导致性能的下降。在网络结构的设计中似乎存在一种“阈值”,在到达一定的层数之后,训练误差和测试误差都会加大。下图为一个24层网络和一个56层网络在CIFAR10数据集的训练表现。
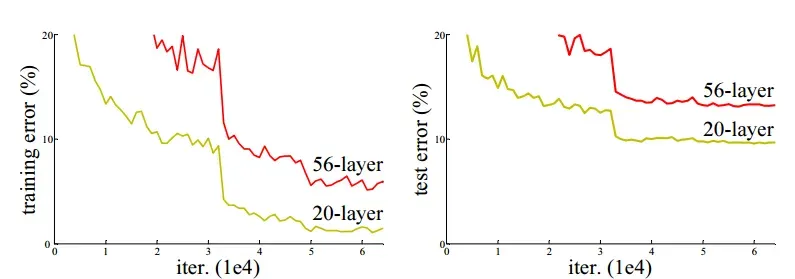
显然,这种性能的下降并不是因为过拟合引起的。因为过拟合意味着训练误差正常减小,而测试误差显著增大。
对这种现象的一种解释是,在网络深度过深的时候,低层参数的细微变动都会引起高层参数的剧烈变化,优化算法没有能力去得到一个最优解。
做这样一个假设,假设有一个50层的网络,但在其优化过程中,最容易优化出最佳解的层数是25,那么这个网络的后25层应当作为一个恒等映射。
由于神经网络由非线性层组合而成,学习一个恒等映射是比较困难的。优化算法的局限性使得“冗余”的网络层学习到了不适合恒等映射的参数。
2. 残差结构和残差网络
2.1 残差是什么
残差的统计学定义:实际观测值和估计值(拟合值)之间的差值。
如果存在某个k层的网络是当前最优的网络,那么可以构造一个更深的网络,其最后几层仅是网络f第k层输出的恒等映射,就可以取得与
一致的结果
如果k还不是最佳层数,那么更深的网络就可以取得更好的结果。所以,如果深层网络的效果不如浅层网络,那么则说明新加入层不好学。
如果不好学,则可以使用类似“分治法”,分开求解恒等映射和非恒等映射。
x代表之前浅层网络已经学到的东西
F(x)代表已经学到的东西和要学的东西的之间的残差
现在只学F(x)就能与x组合起来。
令成为恒等映射,那么只需要学习残差
作为非恒等映射。
残差在这里,指的是直接的映射H(x)与快捷连接x的差值,也就是。
2.2 残差模块 Residual Block
据此,我们设计一个残差模块(Residual Block)的结构如下:
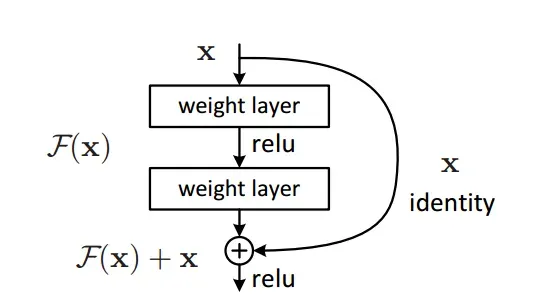
在网络实现中:
最后得到的残差模块表达式如下:
2.3 基本模块BasicBlock和BottleNeck
在残差网络中,基本的残差模块由两个3×3的卷积层和ReLU激活函数、BatchNorm层组成。其结构如下(以64个channel的输入为例):
BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
在网络层数过深的时候,考虑到训练成本,作者提出了一种新的结构设计BottleNeck。将原来的两个3×3的卷积层变为两个1×1的卷积层和一个3×3的卷积层。其中,两个1×1的卷积层负责降低/恢复通道维度,3×3的卷积层负责“真正”的卷积运算。其结构如下图右图所示,BottleNeck的运算具有更小的时间复杂度。
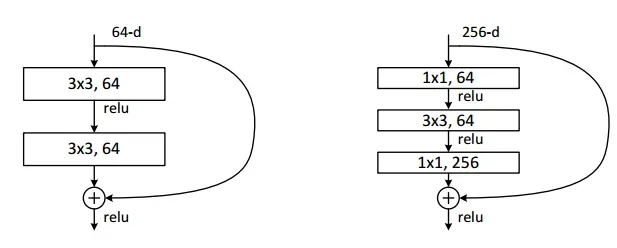
2.4 残差网络ResNet设计
在文中,作者给出了ResNet18、ResNet34、ResNet50、ResNet101、ResNet152等网络设计,分别对应不同层数的卷积运算层。在50层及以上的网络中,都使用BottleNeck结构进行网络构建。
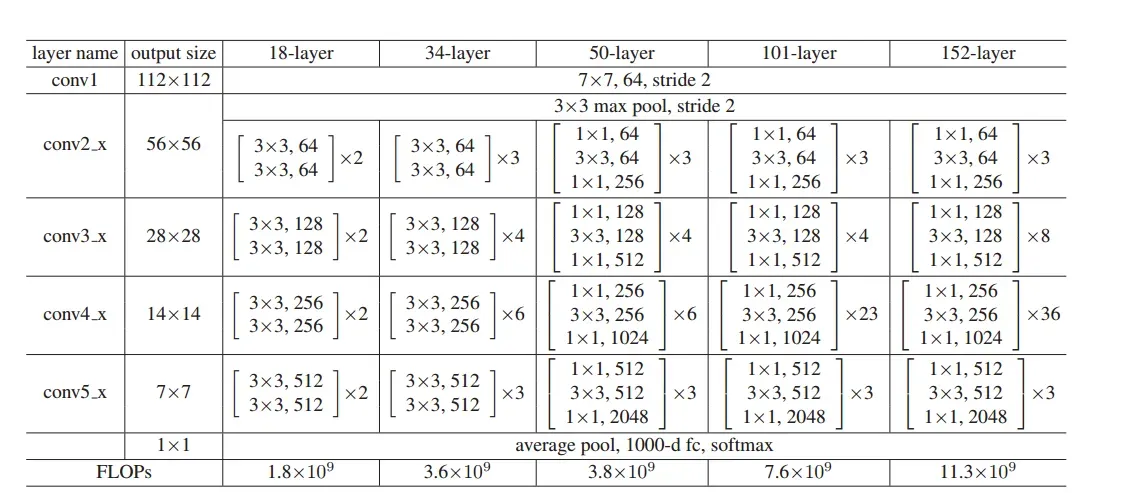
2.4.1 恒等映射与残差的连接
在网络设计中,特别需要注意的是在不同layer之间,例如conv2_x和conv3_x间,输出和输入的尺寸是不一样的,如下图虚线所示。
对于残差运算,这可以很简单的通过卷积进行尺寸的变换,对于恒等映射,作者考虑了如下几个方法进行变换:
- 给恒等映射
添加0,扩充其维度
- 用一个1×1的卷积进行下采样
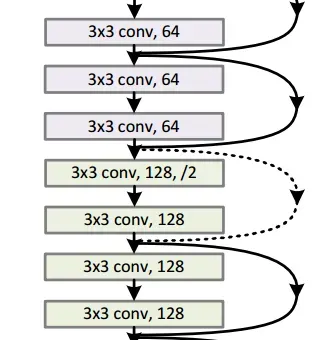
在代码实现中,采用下采样的方法对恒等映射进行变换。
3. Forward/Backward Propagation
3.1 Forward propogation
传统网络
残差网络
3.2 Back Propogation
传统网络
浅层网络是,加入层以后变成
残差网络
可以看到,在求梯度的过程中,残差网络相比传统网络多加了一项,这有利于解决梯度消失,是网络训练的更快
损失函数对网络的第求梯度:
传统网络
残差网络
可以看到,在残差网络中,梯度由乘法变加法,这可以有效缓解梯度消失和梯度爆炸。
4. 代码分析
PyTorch现已将ResNet整合为python库,可以直接调用。源码的地址如下:
https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
基本的卷积层:
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
其中,对输入进行下采样在卷积层中有两种实现方式:
- 第一种采用stride,在下采样是,设置stride=2,即卷积核每次移动的步长是2,使得输出的尺寸变小。
- 第二种采用dilation,即在每次采样的时候,卷积核各一个像素进行一次采样。https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md中有很生动的直观演示。
Basic Block
其中,expension代表了经过一个Block之后,channel数量的变化。这里输出channel维度与预设一样,expension为1。
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
BottleNeck
BottleNeck输出的channel输出是对应BasicBlock的4倍,所以expension=4
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
ResNet
在构造每个层的时候,要注意在输出通道和输入通道数量不一致的时候,要添加一个下采样层对恒等映射进行下采样
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x):
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
return self._forward_impl(x)
5. 恒等映射
对残差做一个简单的改进:
则有:
求梯度,有:
可以看到,大于1的时候,累乘会造成梯度爆炸;在小于1的时候,累乘会造成梯度消失。
6. 分析残差连接
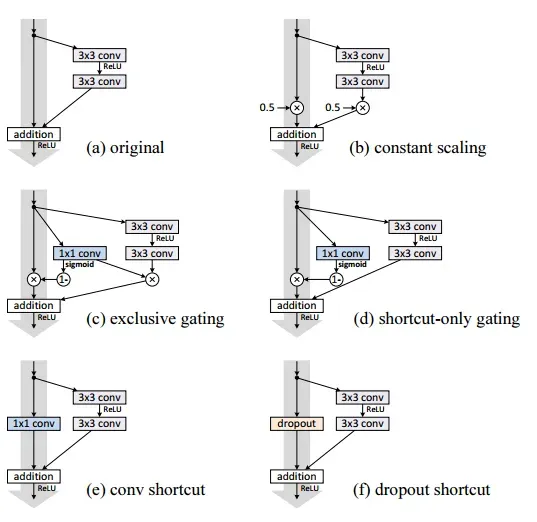
作者给出了一下几种残差连接的变体:
Original
constant
exclusive gating
shortcut-only gating
其余还包括1×1 conv shortcut和dropout shortcut
这几种残差连接的示意图如下所示:
7. 不同结构的残差模块
作者接下来分析了不同残差模块的设计带来的影响。
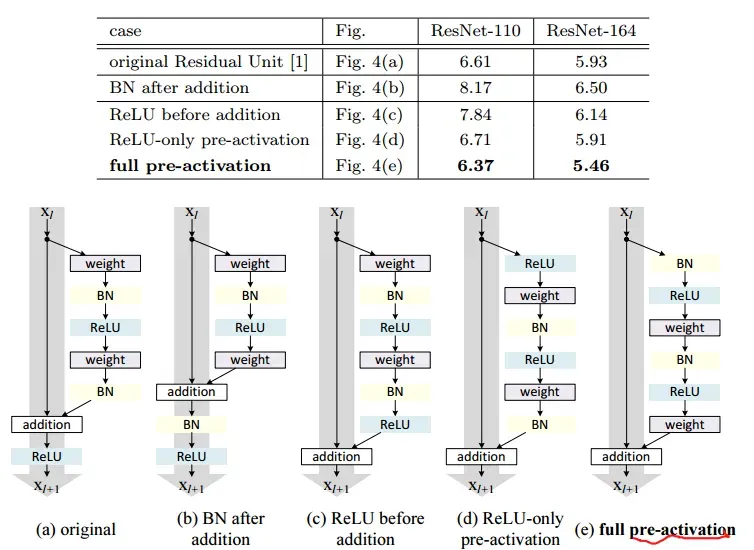
- 在(b)中,由于BN层的存在,使得
不再是一个线性映射,这会影响残差网络的性能
- 在(c)中,残差目标最后的ReLU激活层使得残差的输出范围是非负的。然而,无论是数学定义上还是经验上,残差的范围应该是
,非负的残差影响模型性能
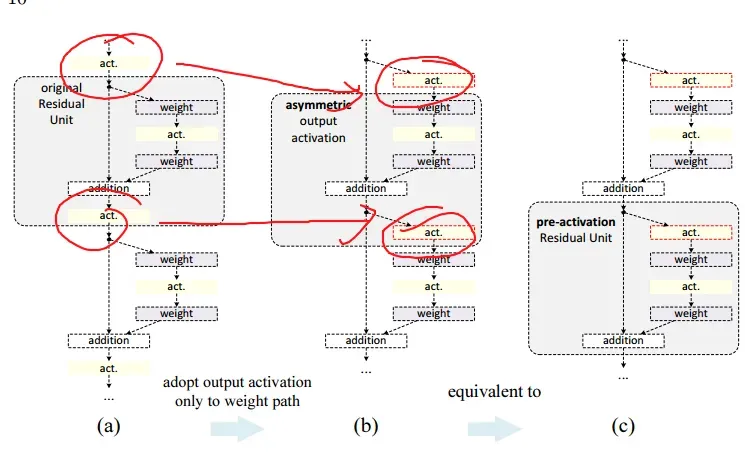
- zai(d)和(e)中,作者采用了一种pre-activation的想法。
在原版设计中,会影响到残差模块的两个部分:
pre-activation使得
在网络设计中,结构如下:
文章出处登录后可见!