82. split方法-分割字符串
文章目录
- 82. split方法-分割字符串
- 1. 什么是split( )函数
- 2. split( )方法的语法格式如下:
- 3. 实操练习
- 4. 列表索引取值知识回顾
- 5. 用split方法分解网址提取有效信息
- 6. 从地址信息中拆分省、市、区信息
1. 什么是split( )函数
split[splɪt]:使分离。
【功能】
把一个字符串按照指定的分隔符切分为字符串列表。
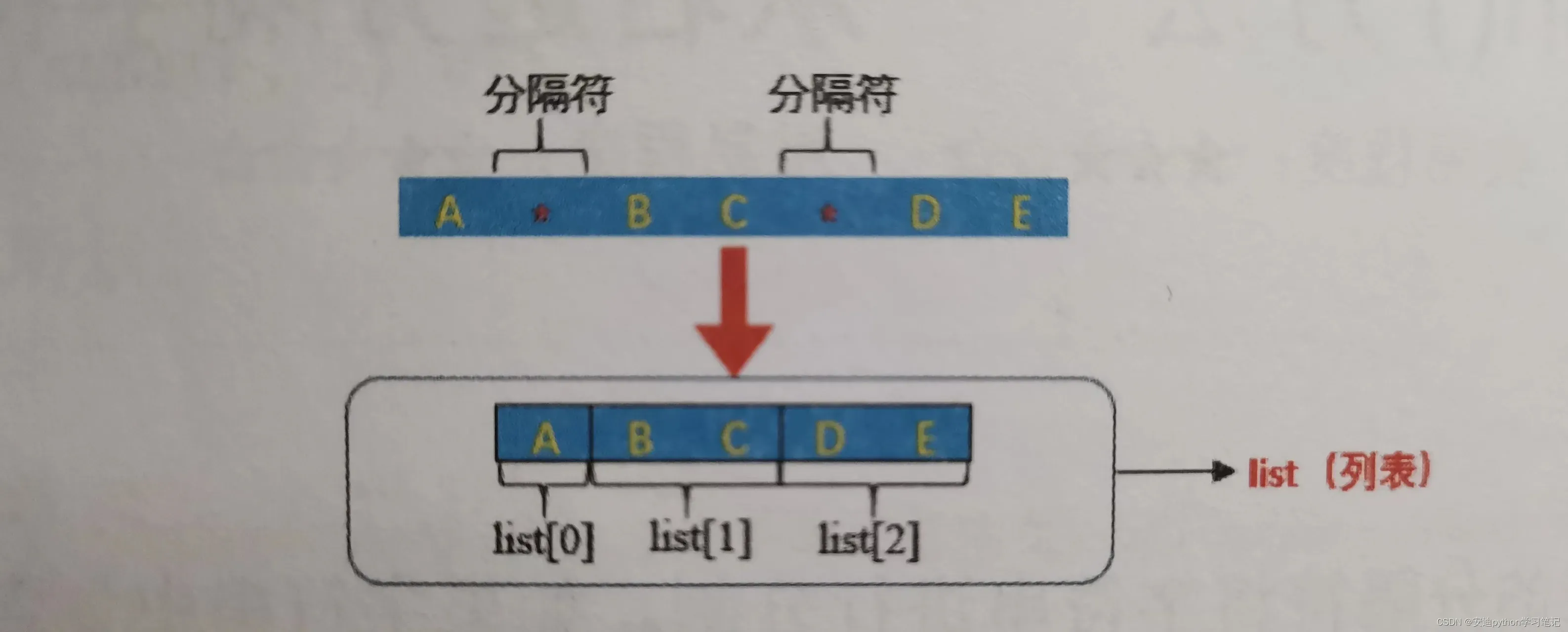
2. split( )方法的语法格式如下:
split( )方法由6部分组成:
str.split(sep=,maxsplit=)
-
str是要进行分隔的字符串。 -
英文小圆点
.。 -
方法名
split。 -
英文圆括号
( )。 -
sep是方法的第1个参数。
sep用于指定分割符。可以包含多个字符,默认为NONE,即所有空字符(包括空格、换行符\n等)。
maxsplit是方法的第2个参数。
用于指定分割的次数。如果不指定,则分割次数没有限制。
【返回值】
返回的是一个字符串列表。
【代码示例】
s = "A*BC*DE"
print("s的数据类型为:",type(s))
l = s.split("*") # split方法,作用是分割字符串
print("l的数据类型为:",type(l))
print("分割后l列表的第1个元素:",l[0])
print("分割后l列表的第2个元素:",l[1])
print("分割后l列表的第3个元素:",l[2])
【终端输出】
s的数据类型为: <class 'str'>
l的数据类型为: <class 'list'>
分割后l列表的第1个元素: A
分割后l列表的第2个元素: BC
分割后l列表的第3个元素: DE
3. 实操练习
s = "2,4,6,8"
print(type(s))
l = s.split(",")
print(l)
print(type(l))
【终端输出】
<class 'str'>
['2', '4', '6', '8']
<class 'list'>
【代码解析】
s的数据类型是字符串。
字符串中的字符都是用英文逗号进行分隔的。
l = s.split(",")
l 是变量名,数据类型为列表。
s是要进行分隔的字符串。
split是方法名。
括号中的","就是参数sep的值,即用英语逗号进行分割。
用英语逗号进行分割的意思就是遇到逗号则逗号前的即为列表的一个单独元素。
这里只有一个参数,没有maxsplit,表示可以进行无限次的分割。
字符串 “2,4,6,8”分割的结果就为[‘2’, ‘4’, ‘6’, ‘8’]。
【分隔次数为2次】
s = "2,4,6,8"
l = s.split(",",2)
print(l)
【终端输出】
['2', '4', '6,8']
这里的maxsplit=2,意思就是只分割2次。
第1次将2分割出来。
第2次将4分割出来。
分割2次后没有多余的分割次数了,因此剩下的6,8为一个单独的元素。
【分割10次】
s = "2,4,6,8"
l = s.split(",",10)
print(l)
【终端输出】
['2', '4', '6', '8']
【其他分割符示例】
str1 = "https://python123.io/student/home"
list1 = str1.split(":") # 用英文冒号进行分割
list2 = str1.split("/") # 用/进行分割
list3 = str1.split(".") # 用.进行分割
print(list1)
print(list2)
print(list3)
【终端输出】
['https', '//python123.io/student/home']
['https:', '', 'python123.io', 'student', 'home']
['https://python123', 'io/student/home']
str1中只有1个冒号,用英文冒号进行分割时,会将str1字符串分割成2个部分,冒号前的内容是列表的第1个元素,后面的内容是列表的第2个元素。
字符串分割后,分割符不会出现在列表里。
这里用英文冒号作为分割符,分割后的列表里就不会再有英文冒号了。
4. 列表索引取值知识回顾
【语法】
列表名[索引]
列表名[索引][索引]
列表本身[索引]
# 新建一个str列表
str_list = ["当归", "人参", "黄芪"]
print(str_list[0])
print(str_list[1])
print(str_list[2])
【终端输出】
当归
人参
黄芪
列表的⚠️正索引从左往右开始编号,编号从0开始!
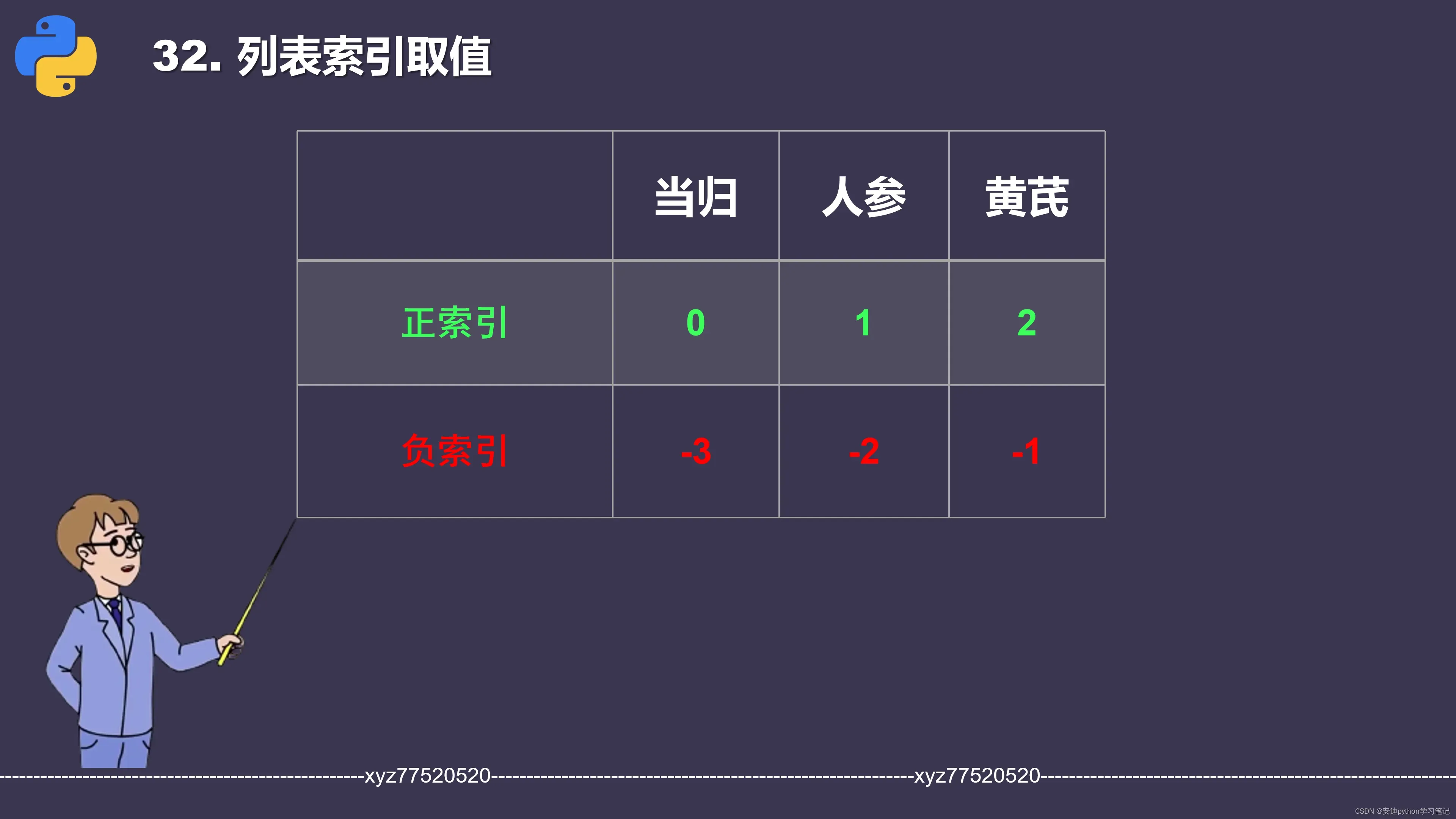
str_list[0]取到列表的第1元素当归。
str_list[1]取到列表的第2元素人参。
str_list[2]取到列表的第3元素黄芪。
原文链接如下:
27. Python 列表的索引取值
5. 用split方法分解网址提取有效信息
某网页的网址为: “https://python123.io/student/home”
任务是提取python123
【代码示例】
str1 = "https://python123.io/student/home"
print(str1.split("//"))
【终端输出】
['https:', 'python123.io/student/home']
首先用//作为分割符,将字符串分隔为2个部分。
str1 = "https://python123.io/student/home"
print(str1.split("//")[1])
【终端输出】
python123.io/student/home
split方法返回的值是一个列表。
添加[1]的作用是提取列表的第2个元素。
str1 = "https://python123.io/student/home"
print(str1.split("//")[1].split("."))
【终端输出】
['python123', 'io/student/home']
.split(".")
提取之后再添加一个.split(".")对列表的第2个元素即python123.io/student/home进行分割。
分割后得到一个新的列表。
str1 = "https://python123.io/student/home"
print(str1.split("//")[1].split(".")[0])
【终端输出】
python123
添加[0]的作用是提取列表的第1个元素,到这里就取到了我们想要的值。
6. 从地址信息中拆分省、市、区信息
【准备工作】
-
新建一个名为
82的文件夹。 -
在
82文件夹中新建一个地址.txt文件。
在地址.txt文件中写入如下内容:
江苏省 苏州市 吴江区 吴江经济技术开发区亨通路
安徽省 滁州市 明光市 三界镇中心街10000号
山东省 潍坊市 寿光市 圣城街道潍坊科技学院
吉林省 长春市 二道区 东盛街道彩虹风景
福建省 厦门市 湖里区 江头街道厦门市湖里区祥店福满园小区
-
在
82文件夹中新建一个82.py文件。 -
用VScode编辑器打开
82.py文件,在该文件中编写代码。
【体验代码】
f = open('地址.txt', 'r')
l = f.readlines()
print(l)
print(type(l))
f.close()
【终端输出】
['江苏省 苏州市 吴江区 吴江经济技术开发区亨通路\n', '安徽省 滁州市 明光市 三界镇中心街10000号\n', '山东省 潍坊市 寿光市 圣城街道潍坊科技学院\n', '吉林省 长春市 二道区 东盛街道彩虹风景\n', '福建省 厦门市 湖里区 江头街道厦门市湖里区祥店福满园小区']
<class 'list'>
用open函数打开地址.txt文件,返回文件对象f。
用readlines操作文件对象f,返回的是一个列表。
readlines方法的作用是按行读取文件内容。
f = open('地址.txt', 'r')
for i in f.readlines():
print(type(i))
print(i,end="")
f.close()
【终端输出】
<class 'str'>
江苏省 苏州市 吴江区 吴江经济技术开发区亨通路
<class 'str'>
安徽省 滁州市 明光市 三界镇中心街10000号
<class 'str'>
山东省 潍坊市 寿光市 圣城街道潍坊科技学院
<class 'str'>
吉林省 长春市 二道区 东盛街道彩虹风景
<class 'str'>
福建省 厦门市 湖里区 江头街道厦门市湖里区祥店福满园小区
for i in f.readlines():
f.readlines():是列表,用for循环从列表中依次取值。
这里的i是字符串类型。
f = open('地址.txt', 'r')
for i in f.readlines():
l = i.split()
print(l)
f.close()
【终端输出】
['江苏省', '苏州市', '吴江区', '吴江经济技术开发区亨通路']
['安徽省', '滁州市', '明光市', '三界镇中心街10000号']
['山东省', '潍坊市', '寿光市', '圣城街道潍坊科技学院']
['吉林省', '长春市', '二道区', '东盛街道彩虹风景']
['福建省', '厦门市', '湖里区', '江头街道厦门市湖里区祥店福满园小区']
i.split()
用split方法将字符串进行分割,分割符为空格即split()。
分割后的省市区就变成了单独的元素。
用列表索引的取值方法即可提取我们需要的元素。
【提取省份】
f = open('地址.txt', 'r')
for i in f.readlines():
l = i.split()
print(l[0])
f.close()
【终端输出】
江苏省
安徽省
山东省
吉林省
福建省
【提取市】
f = open('地址.txt', 'r')
for i in f.readlines():
l = i.split()
print(l[1])
f.close()
【终端输出】
苏州市
滁州市
潍坊市
长春市
厦门市
【提取区】
f = open('地址.txt', 'r')
for i in f.readlines():
l = i.split()
print(l[2])
f.close()
【终端输出】
吴江区
明光市
寿光市
二道区
湖里区
文章出处登录后可见!