导入模块
1.jieba的安装与使用
pip install jieba
conda install -c conda-forge jiebaPython2.X版
- 全自动安装:
easy_install jieba或者pip install jieba - 半自动安装:先下载http://pypi.python.org/pypi/jieba/ ,解压后运行python setup.py install
- 手动安装:将jieba目录放置于当前目录或者site-packages目录
- 通过import jieba 来引用
Python3.X版
-
目前master分支是只支持Python2.x 的
-
Python3.x 版本的分支也已经基本可用: https://github.com/fxsjy/jieba/tree/jieba3k
-
git clone https://github.com/fxsjy/jieba.git git checkout jieba3k python setup.py install
使用国人开发的jieba(结巴的拼音)库来进行智能分词,并加入空格,才能被wordcloud库所用。
中文智能分词:‘西安全城下大雨’,应该分成‘西安’,‘全城’,‘下大雨’。而不是‘西’,‘安全’,‘城下’,‘大雨’
(1)jieba分词的三种模式:精确模式、全模式、搜索引擎模式
– 精确模式:把文本精确的切分开,不存在冗余单词
– 全模式:把文本中所有可能的词语都扫描出来,有冗余
– 搜索引擎模式:在精确模式基础上,对长词再次切分
(2)jieba库常用函数
①分词
jieba.cut方法接受两个输入参数: 1) 第一个参数为需要分词的字符串 2)cut_all参数用来控制是否采用全模式jieba.cut_for_search方法接受一个参数:需要分词的字符串,该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细- 注意:待分词的字符串可以是gbk字符串、utf-8字符串或者unicode
jieba.cut以及jieba.cut_for_search返回的结构都是一个可迭代的generator,可以使用for循环来获得分词后得到的每一个词语(unicode),也可以用list(jieba.cut(…))转化为list
②词性标注
-
标注句子分词后每个词的词性,采用和ictclas兼容的标记法
-
>>> import jieba.posseg as pseg >>> words = pseg.cut("我爱北京天安门") >>> for w in words: ... print w.word, w.flag ... 我 r 爱 v 北京 ns 天安门 ns
2.词云wordcloud库的安装与使用
词云(Word Cloud)是对文本中出现频率较高的词语给予视觉化展示的图形, 是一种常见的文本挖掘的方法。wordcloud是优秀的词云展示第三方库,wordcloud能够将一段文本变成一个词云。词云在我们的生活中经常能够看到,无论是中文的词云还是英文的词云。
(1)wordcloud库的安装
pip install wordcloud
conda install -c conda-forge wordcloud(2)wordcloud库的使用
wordcloud库把词云当做一个WordCloud对象,
即wordcloud.WordCloud()是一个代表文本对应词云的对象,一个词云就是一个WordCloud对象。wordcloud库可以根据文本中词语出现的频率等一系列参数来绘制词云,在绘制词云时,词云的形状、尺寸、颜色包括字体都是可以设定的。
由文本变为词云,wordcloud库大概做了4件事:1.wordcloud库以空格为分隔符,将文本分割成单词;2.wordcloud库会在文本中统计每一个单词出现的次数,单词出现次数越多,那么单词显示的词云效果的字体越大,反之则反。并且将只有1到2个字符的单词过滤掉;3.wordcloud库会根据统计单词出现的次数,为不同的单词配置显示的字号;4.进行布局。
一.实验步骤
Step1)安装jieba库,wordcloud库
1.PyCharm环境安装
①安装jieba库
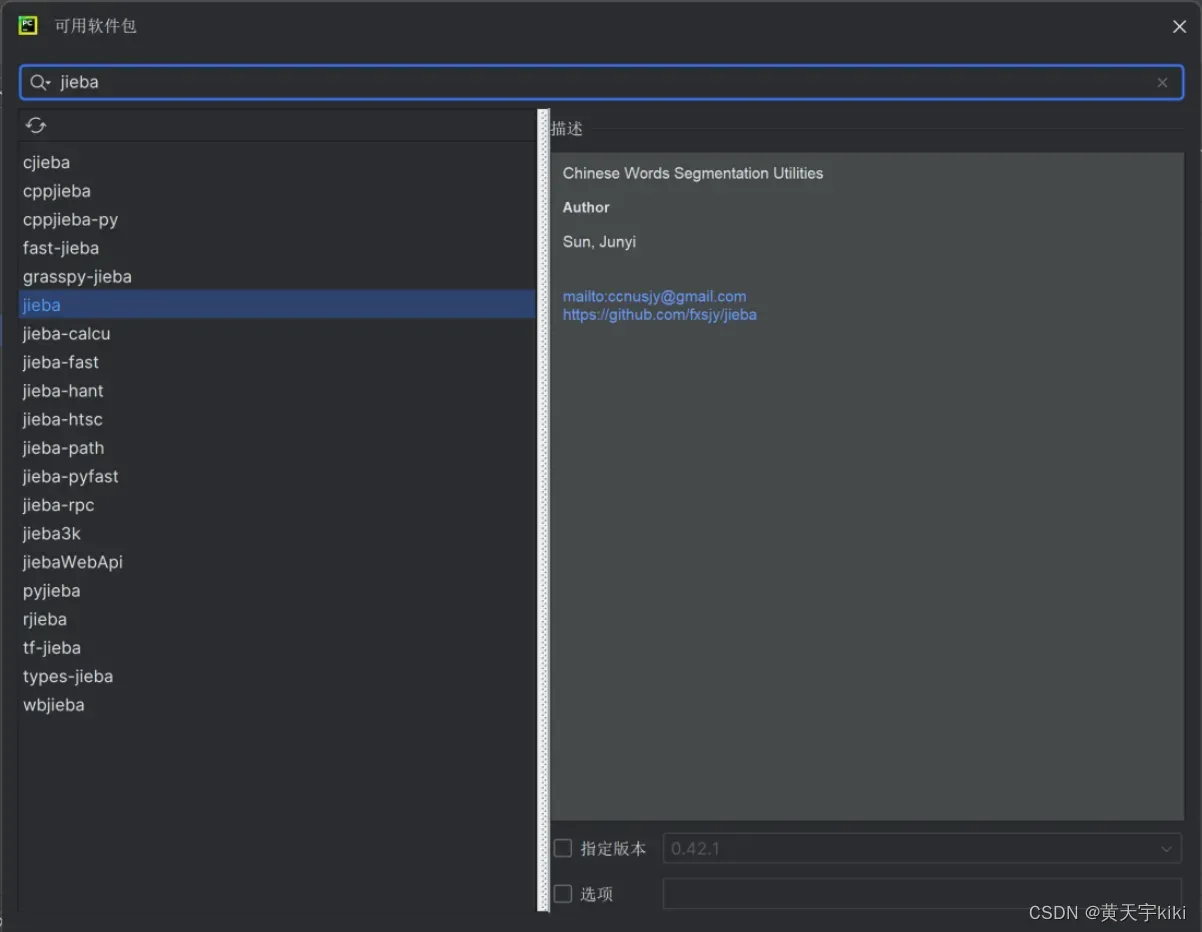
②安装wordcloud库
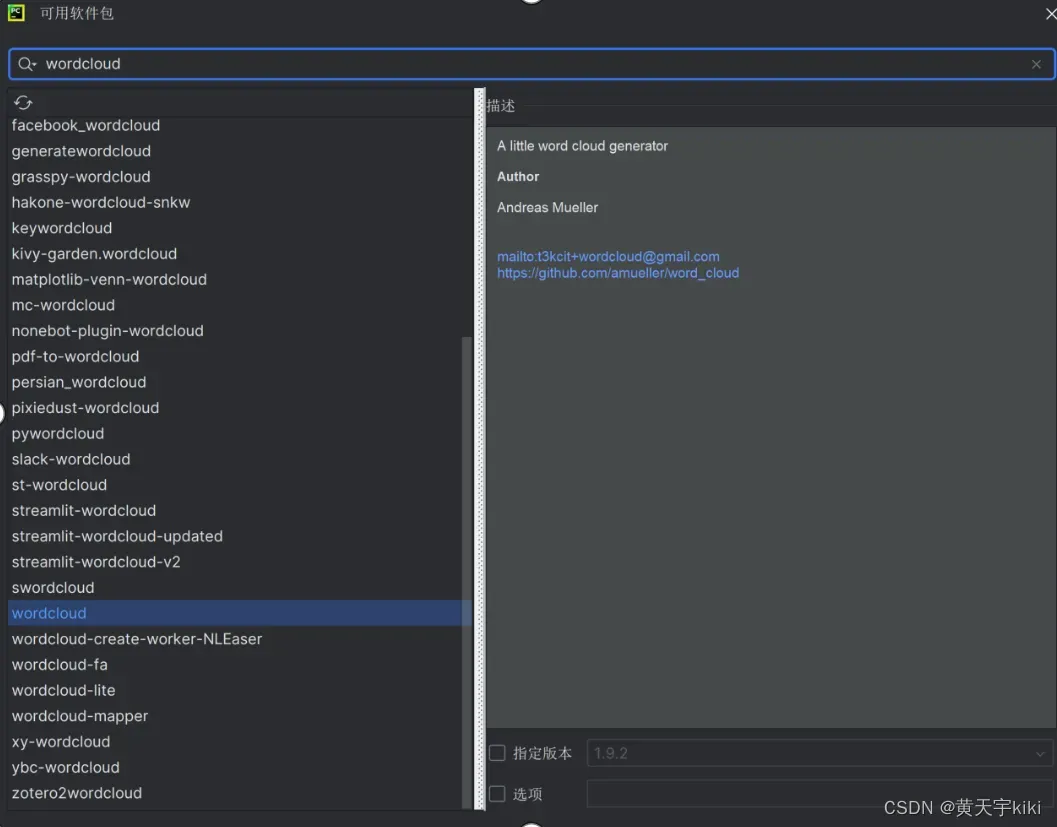
2.检查环境安装
①检查jieba库

②检查wordcloud库
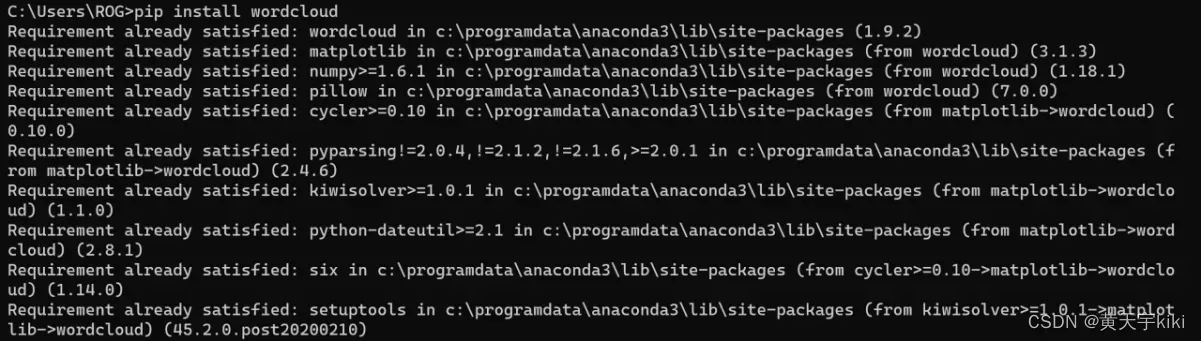
Step2)导入jieba、wordcloud模块
# 导入模块
import jieba # 分词
import wordcloud as wc # 词云
import jieba.posseg as psegStep3)导入“三国演义.txt”文件
文件操作的步骤为:
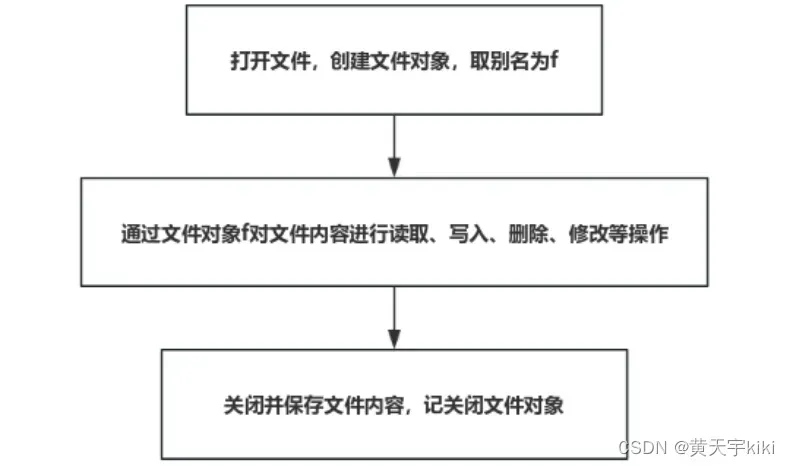
为了简便操作,本实验选用with语句导入文件。
# 导入文件“三国演义”
with open(r'C:\Users\ROG\Desktop\三国演义.txt', 'r',encoding='utf-8') as f:
tf = f.read()Step4)对文件对象精选分词和词性标注
由于jieba库中,jieba.lcut方法只能分词,不能标注词语的词性,本实验采用jieba库中pseg模块,利用pseg.lcut方法,完成分词并标注词性。
# 分词
seg_list = pseg.lcut(tf)Step5)词频统计
由于实验目的是为了将《三国演义》中常见人名进行去重后生成词云,所以,本实验对词语进行了筛选,分别进行了以下三种筛选操作:

①词语长度筛选
if len(word.word) >= 2②词语词性筛选
查询jieba词性标注表:

word.flag == 'nrfg' or word.flag == 'nr'③人名去重
if word.word in ('玄德','玄德曰','刘皇叔','皇叔'):
rword = '刘备'
elif word.word in ('乱世奸雄','治世能臣','阿瞒','乱世枭雄','孟德','丞相'):
rword = '曹操'
elif word.word in ('碧眼小儿','紫髯鼠辈','孙仲谋'):
rword = '孙权'
elif word.word in ('诸葛亮','卧龙先生','伏龙','军师','孔明曰'):
rword = '孔明'
elif word.word in ('关公','云长'):
rword = '关羽'
else:
rword = word.word统计词频本实验采用字典get()方法
counts[rword] = counts.get(rword,0) + 1词频统计完整代码:
# 词频统计
counts = {}
for word in seg_list:
if len(word.word) >= 2 and ( word.flag == 'nrfg' or word.flag == 'nr' ):
if word.word in ('玄德','玄德曰','刘皇叔','皇叔'):
rword = '刘备'
elif word.word in ('乱世奸雄','治世能臣','阿瞒','乱世枭雄','孟德','丞相'):
rword = '曹操'
elif word.word in ('碧眼小儿','紫髯鼠辈','孙仲谋'):
rword = '孙权'
elif word.word in ('诸葛亮','卧龙先生','伏龙','军师','孔明曰'):
rword = '孔明'
elif word.word in ('关公','云长'):
rword = '关羽'
else:
rword = word.word
counts[rword] = counts.get(rword,0) + 1Step6)词频排序
本实验采用列表sort()函数排序,sort() 函数用于对原列表进行排序,key参数采用匿名函数lambda x:x[1],reverse参数选择True。
# 词频排序
items = list(counts.items())
items.sort(key= lambda x:x[1],reverse=True)Step7)输出词频前20个人名
# 输出词频前20个人名
for i in range(20):
word, count = items[i]
print("{}:{}".format(word,count))Step8)绘制词云图
本实验采用wordcloud库WordCloud方法绘制词云图,参数设置如下:
图片背景颜色:background_color=’white’
图片宽:width=2000
图片高:height=1600
最多显示词语数量:max_words=1000
字体:font_path=”C:/Windows/Fonts/simhei.ttf”
采用wordcloud库generate_from_frequencies方法根据词频字典,依据词频数,绘制词云图。
将图片保存至C:/Users/ROG/Desktop,命名为:三国演义词云图.jpg
绘制词云图完整代码如下:
# 绘制词云图
w = wc.WordCloud( background_color='white',
width=2000 ,
height=1600 ,
max_words=1000 ,
font_path="C:/Windows/Fonts/simhei.ttf" )
w.generate_from_frequencies(counts)
# 保存图片
w.to_file("C:/Users/ROG/Desktop/三国演义词云图.jpg")全过程代码如下:
# 导入模块
import jieba # 分词
import wordcloud as wc # 词云
import jieba.posseg as pseg
# 导入文件“三国演义”
with open(r'C:\Users\ROG\Desktop\三国演义.txt', 'r',encoding='utf-8') as f:
tf = f.read()
# 分词
seg_list = pseg.lcut(tf)
# 词频统计
counts = {}
for word in seg_list:
if len(word.word) >= 2 and ( word.flag == 'nrfg' or word.flag == 'nr' ):
if word.word in ('玄德','玄德曰','刘皇叔','皇叔'):
rword = '刘备'
elif word.word in ('乱世奸雄','治世能臣','阿瞒','乱世枭雄','孟德','丞相'):
rword = '曹操'
elif word.word in ('碧眼小儿','紫髯鼠辈','孙仲谋'):
rword = '孙权'
elif word.word in ('诸葛亮','卧龙先生','伏龙','军师','孔明曰'):
rword = '孔明'
elif word.word in ('关公','云长'):
rword = '关羽'
else:
rword = word.word
counts[rword] = counts.get(rword,0) + 1
# 词频排序
items = list(counts.items())
items.sort(key= lambda x:x[1],reverse=True)
# 输出词频前20个人名
for i in range(20):
word, count = items[i]
print("{}:{}".format(word,count))
# 绘制词云图
w = wc.WordCloud( background_color='white',
width=2000 ,
height=1600 ,
max_words=1000 ,
font_path="C:/Windows/Fonts/simhei.ttf" )
w.generate_from_frequencies(counts)
# 保存图片
w.to_file("C:/Users/ROG/Desktop/三国演义词云图.jpg")二.数据记录与处理
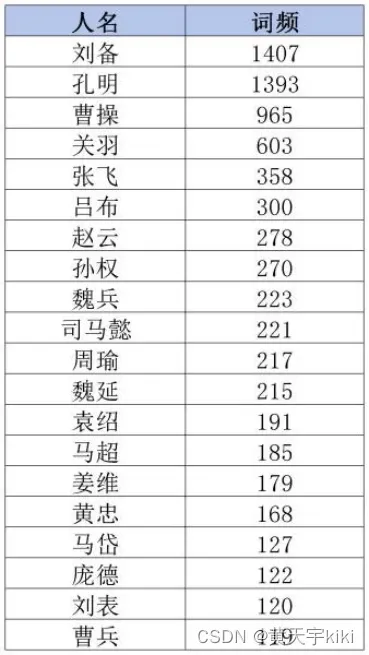
1.词频排名前20的人名
2.三国演义人名词云图

三.结果分析
根据词云图结合词频统计表分析可知:
《三国演义》中出现频率最高的人物是刘备,出乎很多资深读者意料地,刘皇叔力压「三绝」排名榜首。其次是孔明,从出山后就是演义核心看点,曹刘死后一段故事的当然主角。紧接着是曹操,乱世枭雄,天下英雄谁敌手?三国演义前半部分,讲的就是曹刘的故事。
由此也可以反映出作者罗贯中“尊刘抑曹”的态度。“尊刘”的原因是刘备代表汉朝皇室正统,反映了广大人民渴望统一,反对分裂、拥护仁政,反对暴政的根本要求;他把诸葛亮塑造为智慧的化身,极大地鼓舞了人们对自身能力的信心,促使人们在斗争实践中不断丰富和发展自己的智慧;
四.实验改进
Step1)提高分词精确度
可以发现,在词频统计时,程序把“魏兵”、“曹兵”误认为人名,程序精确度还需进一步提升。
通过建立去除词库,利用遍历的思想,去除错误识别词。
# 去除停用词
list_tf2 = tf2.split()
for i in list_tf2:
del(counts[i])
# 词频排序
items = list(counts.items())
items.sort(key= lambda x:x[1],reverse=True)去除后的词频统计结果为:
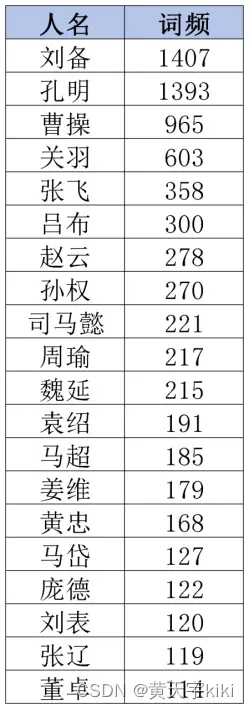

可以看出,去除后的词频统计均为人名。
Step2)改变词云图形状
导入模块
import numpy as np
from PIL import Image读取底板图形文件:
pic = np.array(Image.open('C:/Users/ROG/Desktop/图片3.png'))调整词云图参数:
w = wc.WordCloud( background_color='white',
mask=pic,
width=2000 ,
height=1600 ,
max_words=1000 ,
font_path="C:/Windows/Fonts/simhei.ttf" )
w.generate_from_frequencies(counts)改变形状后的词云图展示:




文章出处登录后可见!