🔥作者:雨晨源码🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python实战项目案例
💕💕文末获取源码
文章目录
- 个性化书籍推荐系统-系统前言简介
- 个性化书籍推荐系统-开发技术与环境
- 个性化书籍推荐系统-功能介绍
- 个性化书籍推荐系统-演示图片
- 个性化书籍推荐系统-论文参考
- 个性化书籍推荐系统-代码展示
- 个性化书籍推荐系统-结语(文末获取源码)
本次文章主要是介绍SpringBoot垃圾分类识别小程序的功能,系统分为二个角色,分别是用户和管理员
个性化书籍推荐系统-系统前言简介
- 随着信息技术的迅速发展,互联网已经成为获取信息和资源的主要途径。在互联网时代,图书和阅读仍然是知识传播和个人娱乐的重要方式之一。然而,互联网上的图书和文献数量庞大,对于用户来说,如何有效地找到适合自己的阅读材料成为了一个巨大的挑战。传统的图书馆和书店已经不再满足用户的需求,因此,个性化书籍推荐系统应运而生。
- 本研究旨在设计和实现一款基于Python、Django和网络爬虫技术的个性化书籍推荐系统。这一系统将为用户提供高度个性化的图书推荐,以满足他们的兴趣和需求。通过分析用户的阅读历史、评价和偏好,系统将能够智能地推荐适合他们的图书,从而提高阅读体验,节省时间,并促进知识的传播。此外,本研究还将利用爬虫技术来获取大量图书相关数据,包括书籍类型、价格、评分、作者评分和出版次数等信息。这些数据将有助于更好地理解图书市场的趋势,为图书爱好者提供有价值的信息,同时也为图书销售商和出版商提供市场分析的依据。
- 在国内外,个性化推荐系统已经成为信息科学领域的研究热点之一。许多著名的互联网平台,如Amazon、Netflix和Spotify,都成功地应用了个性化推荐算法,提高了用户满意度和平台的盈利能力。此外,国内的一些在线教育平台和电子商务网站也开始采用个性化推荐系统,以满足用户的不同需求。然而,尽管个性化推荐系统在各个领域取得了显著的成就,但在图书推荐领域的研究相对较少。目前存在的一些图书推荐系统主要依赖于基本的协同过滤算法,缺乏对图书内容和用户兴趣的深度分析。因此,本研究将在已有研究的基础上,结合网络爬虫技术,提供更精准、多样化的图书推荐服务。总之,本研究将致力于构建一款全面、智能的个性化书籍推荐系统,以满足用户的多样化需求,提高图书推荐的精准性和用户满意度,同时也为图书市场的发展和图书推荐领域的研究提供有价值的参考。
个性化书籍推荐系统-开发技术与环境
- 开发语言:Python
- 后端框架:Django、爬虫
- 前端:Vue
- 数据库:MySQL
- 系统架构:B/S
- 开发工具:Ppycharm
个性化书籍推荐系统-功能介绍
2个角色:用户/管理员(亮点:爬虫、echarts可视化)
用户:登录注册、系统首页、热门书籍、公告栏、小说信息、在线反馈,个人中心(我的收藏、评论)。
管理员:爬虫数据分析(书籍类型、书籍价格、书籍评分、作者评分、出版次数)、用户管理、分类管理、热门书籍管理、公告管理、小说信息管理、留言管理、系统管理。
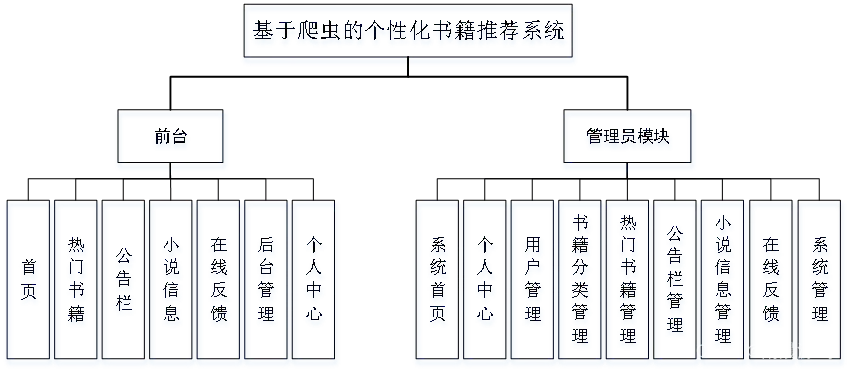
个性化书籍推荐系统-演示图片
1.用户端页面:
☀️看板☀️
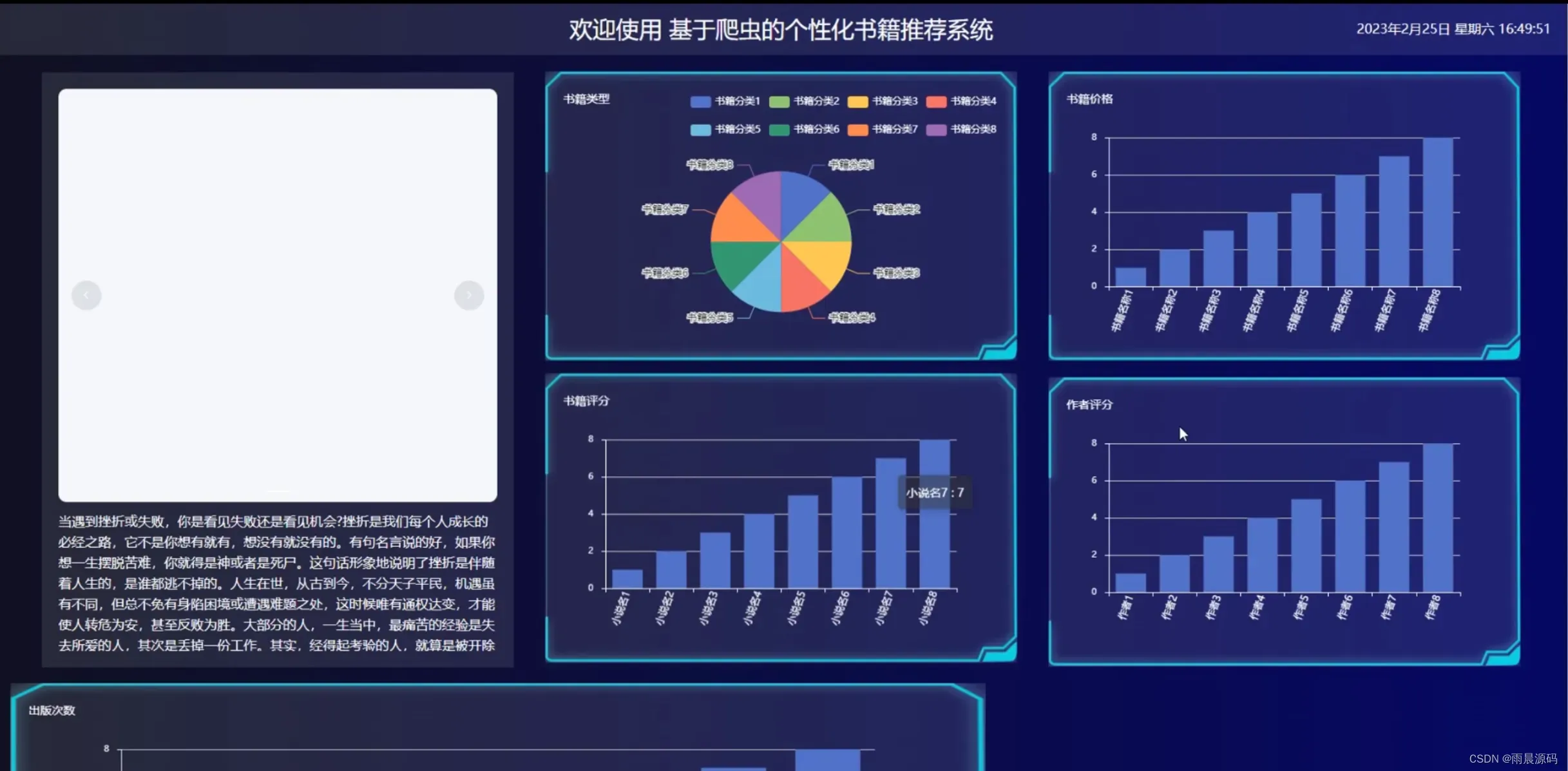
☀️热门书籍推荐☀️
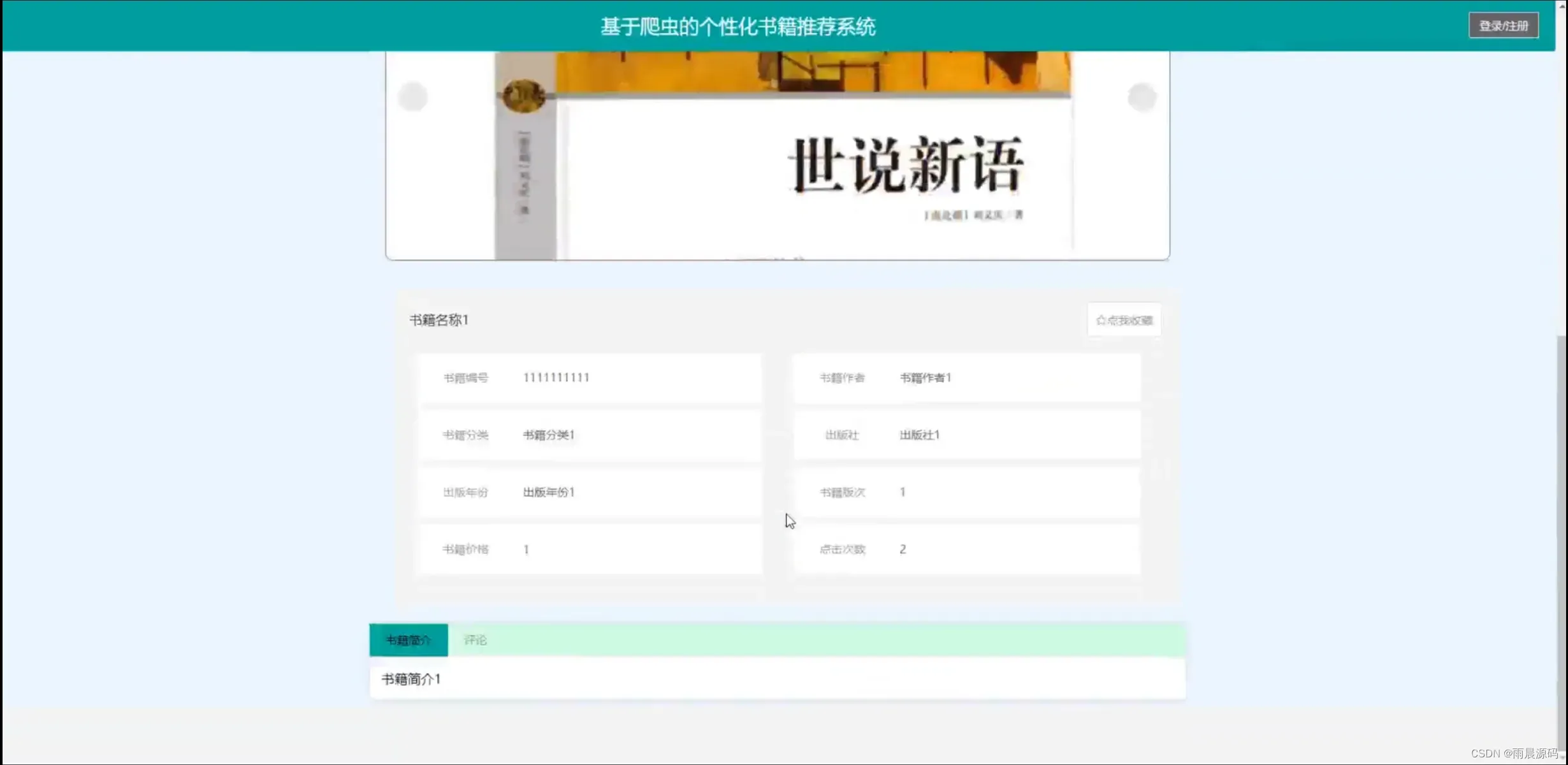
☀️书籍详情☀️
☀️小说信息☀️
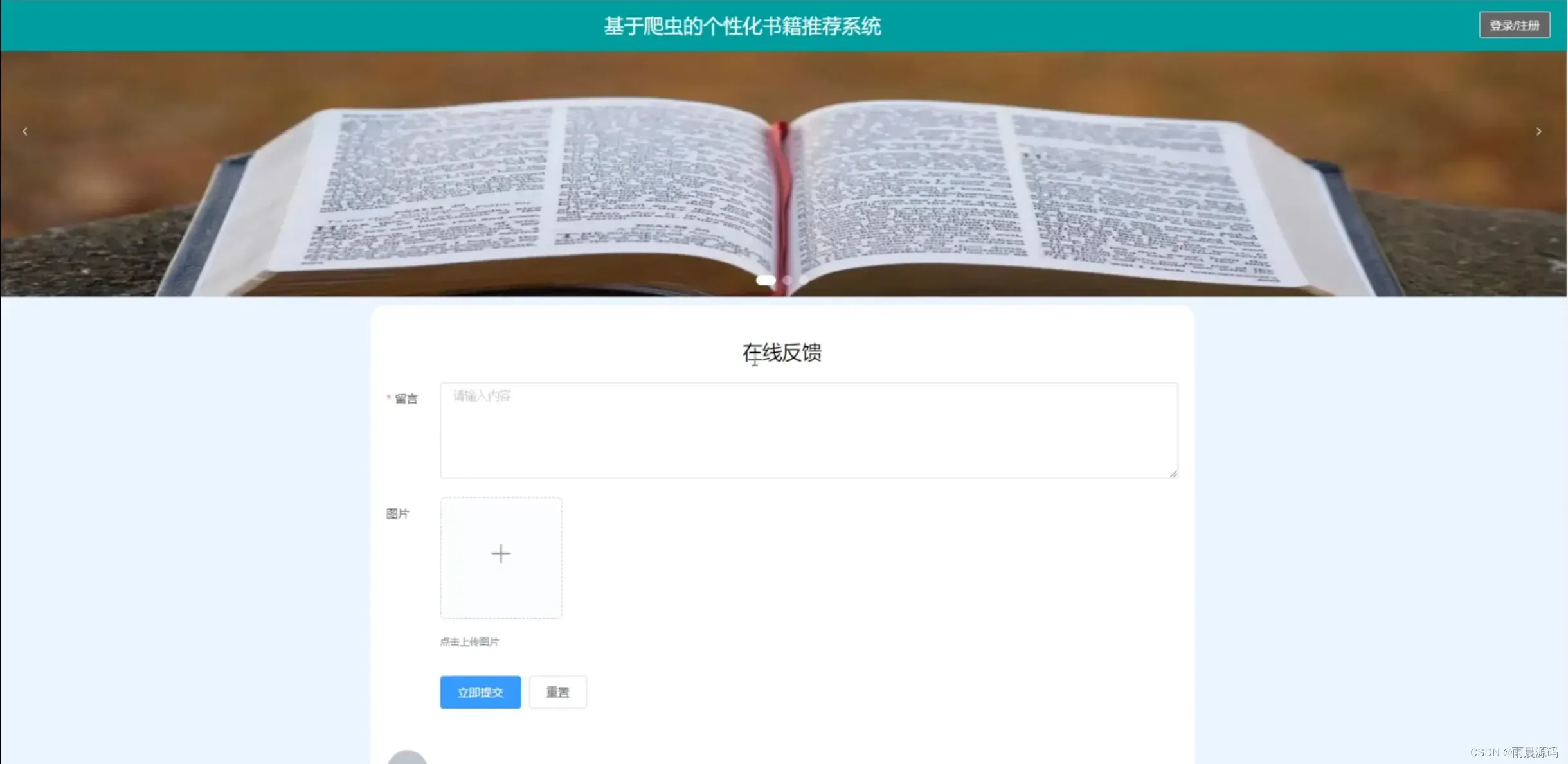
☀️ 在线反馈☀️
2.管理员端页面:
☀️公告管理☀️

☀️小说信息管理☀️
☀️用户管理☀️
☀️在线反馈管理☀️
个性化书籍推荐系统-论文参考
个性化书籍推荐系统-代码展示
1.查询房间【代码如下(示例):】
# 小说信息
class XiaoshuoxinxiSpider(scrapy.Spider):
name = 'xiaoshuoxinxiSpider'
spiderUrl = 'https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start=0&type=T'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if plat == 'windows_bak':
pass
elif plat == 'linux' or plat == 'windows':
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, '8dd17_xiaoshuoxinxi') == 1:
cursor.close()
connect.close()
self.temp_data()
return
list = response.css('ul.subject-list li.subject-item')
for item in list:
fields = XiaoshuoxinxiItem()
fields["laiyuan"] = self.remove_html(item.css('div.pic a.nbg::attr(href)').extract_first())
if fields["laiyuan"].startswith('//'):
fields["laiyuan"] = self.protocol + ':' + fields["laiyuan"]
elif fields["laiyuan"].startswith('/'):
fields["laiyuan"] = self.protocol + '://' + self.hostname + fields["laiyuan"]
fields["fengmian"] = self.remove_html(item.css('div.pic a.nbg img::attr(src)').extract_first())
fields["xiaoshuoming"] = self.remove_html(item.css('div.info h2 a::attr(title)').extract_first())
detailUrlRule = item.css('div.pic a.nbg::attr(href)').extract_first()
if self.protocol in detailUrlRule:
pass
elif detailUrlRule.startswith('//'):
detailUrlRule = self.protocol + ':' + detailUrlRule
else:
detailUrlRule = self.protocol + '://' + self.hostname + detailUrlRule
fields["laiyuan"] = detailUrlRule
yield scrapy.Request(url=detailUrlRule, meta={'fields': fields}, callback=self.detail_parse)
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
try:
if '(.*?)' in '''div#info span a::text''':
fields["zuozhe"] = re.findall(r'''div#info span a::text''', response.text, re.S)[0].strip()
else:
if 'zuozhe' != 'xiangqing' and 'zuozhe' != 'detail' and 'zuozhe' != 'pinglun' and 'zuozhe' != 'zuofa':
fields["zuozhe"] = self.remove_html(response.css('''div#info span a::text''').extract_first())
else:
fields["zuozhe"] = emoji.demojize(response.css('''div#info span a::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''a[href^="https://book.douban.com/press"]::text''':
fields["chubanshe"] = re.findall(r'''a[href^="https://book.douban.com/press"]::text''', response.text, re.S)[0].strip()
else:
if 'chubanshe' != 'xiangqing' and 'chubanshe' != 'detail' and 'chubanshe' != 'pinglun' and 'chubanshe' != 'zuofa':
fields["chubanshe"] = self.remove_html(response.css('''a[href^="https://book.douban.com/press"]::text''').extract_first())
else:
fields["chubanshe"] = emoji.demojize(response.css('''a[href^="https://book.douban.com/press"]::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''a[href^="https://book.douban.com/producers"]::text''':
fields["chupinfang"] = re.findall(r'''a[href^="https://book.douban.com/producers"]::text''', response.text, re.S)[0].strip()
else:
if 'chupinfang' != 'xiangqing' and 'chupinfang' != 'detail' and 'chupinfang' != 'pinglun' and 'chupinfang' != 'zuofa':
fields["chupinfang"] = self.remove_html(response.css('''a[href^="https://book.douban.com/producers"]::text''').extract_first())
else:
fields["chupinfang"] = emoji.demojize(response.css('''a[href^="https://book.douban.com/producers"]::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''strong[class="ll rating_num "]::text''':
fields["pingfen"] = re.findall(r'''strong[class="ll rating_num "]::text''', response.text, re.S)[0].strip()
else:
if 'pingfen' != 'xiangqing' and 'pingfen' != 'detail' and 'pingfen' != 'pinglun' and 'pingfen' != 'zuofa':
fields["pingfen"] = self.remove_html(response.css('''strong[class="ll rating_num "]::text''').extract_first())
else:
fields["pingfen"] = emoji.demojize(response.css('''strong[class="ll rating_num "]::text''').extract_first())
except:
pass
2.推荐算法【代码如下(示例):】
# 推荐算法接口
@main_bp.route("/python7bf5u/remenshuji/autoSort2", methods=['GET'])
def python7bf5u_remenshuji_autoSort2():
if request.method == 'GET':
leixing = set()
req_dict = session.get("req_dict")
userinfo = session.get("params")
sql = "select inteltype from storeup where userid = "+userinfo.get("id")+" and tablename = 'remenshuji' order by addtime desc"
try:
data = db.session.execute(sql)
rows = data.fetchall()
for row in rows:
for item in row:
if item != None:
leixing.add(item)
except:
leixing = set()
L = []
sql ="select * from remenshuji where shujifenlei in ('%s"%("','").join(leixing)+"') union all select * from remenshuji where shujifenlei not in('%s"%("','").join(leixing)+"')"
data = db.session.execute(sql)
data_dict = [dict(zip(result.keys(), result)) for result in data.fetchall()]
for online_dict in data_dict:
for key in online_dict:
if 'datetime.datetime' in str(type(online_dict[key])):
online_dict[key] = online_dict[key].strftime(
"%Y-%m-%d %H:%M:%S")
else:
pass
L.append(online_dict)
return jsonify({"code": 0, "msg": '', "data":{"currPage":1,"totalPage":1,"total":1,"pageSize":5,"list": L[0:int(req_dict['limit'])]}})
个性化书籍推荐系统-结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python实战项目集
💟💟如果大家有任何疑虑,欢迎在下方位置详细交流。
文章出处登录后可见!
已经登录?立即刷新