金融数据分析赛题2:保险反欺诈预测baseline
好久没写baseline了,最近逛比赛的时候突然看到阿里新人赛又出新题目了,索性写个baseline给初学者,昨天晚上把比赛数据下载了,然后随便跑了个模型,AUC就达到了0.95,排在了第二名,下图是我排名的截图,所以题目还是比较简单的,适合初学者入手。
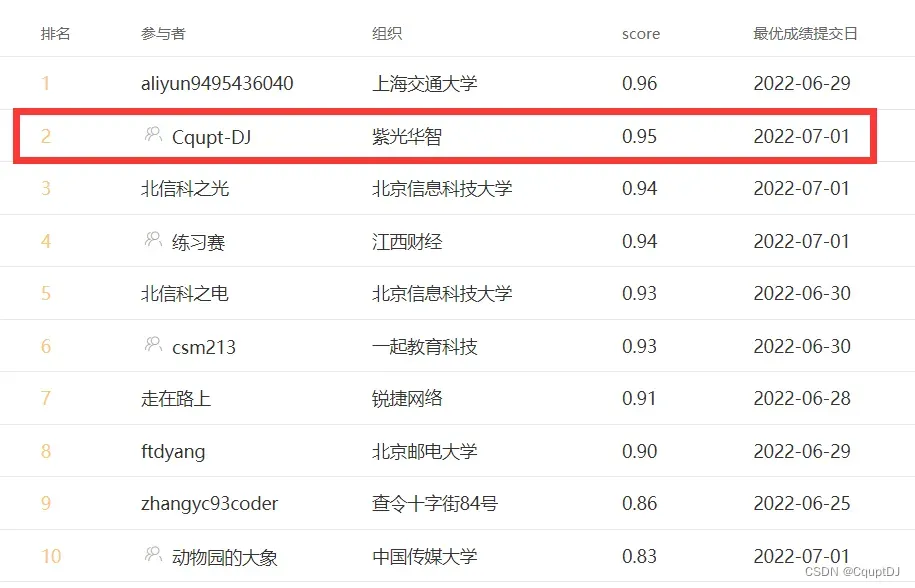
比赛地址:https://tianchi.aliyun.com/competition/entrance/531994/introduction?spm=5176.12281973.1005.21.3dd52448vSKXI0
我比较喜欢做开源,因为分享也是一种快乐,如果大家对baseline代码有任何疑问,都可以提出来,我会详细解答的,也欢迎大家关注,有任何问题我都会解答!
话不多说,直接上代码吧!
baseline代码如下:
import pandas as pd
import datetime
import warnings
warnings.filterwarnings('ignore')
from sklearn.model_selection import StratifiedKFold
#warnings.filterwarnings('ignore')
#%matplotlib inline
from sklearn.metrics import roc_auc_score
## 数据降维处理的
from sklearn.model_selection import train_test_split
from catboost import CatBoostClassifier
from sklearn.preprocessing import LabelEncoder
train=pd.read_csv("E:/金融2/train.csv")
test=pd.read_csv("E:/金融2/test.csv")
sub=pd.read_csv("E:/金融2/submission.csv")
data=pd.concat([train,test])
data['incident_date'] = pd.to_datetime(data['incident_date'],format='%Y-%m-%d')
startdate = datetime.datetime.strptime('2022-06-30', '%Y-%m-%d')
data['time'] = data['incident_date'].apply(lambda x: startdate-x).dt.days
#Encoder
numerical_fea = list(data.select_dtypes(include=['object']).columns)
division_le = LabelEncoder()
for fea in numerical_fea:
division_le.fit(data[fea].values)
data[fea] = division_le.transform(data[fea].values)
print("数据预处理完成!")
testA=data[data['fraud'].isnull()].drop(['policy_id','incident_date','fraud'],axis=1)
trainA=data[data['fraud'].notnull()]
data_x=trainA.drop(['policy_id','incident_date','fraud'],axis=1)
data_y=train[['fraud']].copy()
col=['policy_state','insured_sex','insured_education_level','incident_type','collision_type','incident_severity','authorities_contacted','incident_state',
'incident_city','police_report_available','auto_make','auto_model']
for i in data_x.columns:
if i in col:
data_x[i] = data_x[i].astype('str')
for i in testA.columns:
if i in col:
testA[i] = testA[i].astype('str')
model=CatBoostClassifier(
loss_function="Logloss",
eval_metric="AUC",
task_type="CPU",
learning_rate=0.1,
iterations=10000,
random_seed=2020,
od_type="Iter",
depth=7,
early_stopping_rounds=300)
answers = []
mean_score = 0
n_folds = 10
sk = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=2019)
for train, test in sk.split(data_x, data_y):
x_train = data_x.iloc[train]
y_train = data_y.iloc[train]
x_test = data_x.iloc[test]
y_test = data_y.iloc[test]
clf = model.fit(x_train,y_train, eval_set=(x_test,y_test),verbose=500,cat_features=col)
yy_pred_valid=clf.predict(x_test)
print('cat验证的auc:{}'.format(roc_auc_score(y_test, yy_pred_valid)))
mean_score += roc_auc_score(y_test, yy_pred_valid) / n_folds
y_pred_valid = clf.predict(testA,prediction_type='Probability')[:,-1]
answers.append(y_pred_valid)
print('10折平均Auc:{}'.format(mean_score))
lgb_pre=sum(answers)/n_folds
sub['fraud']=lgb_pre
sub.to_csv('金融2预测.csv',index=False)
以上就是baseline的全部代码,线上提交分数是0.9463,排名显示0.95,非常简单,因为数据量也不大,训练也非常快,就做了简单的编码操作和时间戳特征,没有进行其他复杂操作,所以提升的空间还非常大,大家可以做更加复杂的特征工程,也可以深层次地研究数据业务逻辑构建有效特征,或者模型融合,这些都可以提升分数。
写在最后
本人才疏学浅,如果有写得不对或者理解错误的地方欢迎评论指正,有任何问题也可以提问,我都会一一解答!
文章出处登录后可见!
已经登录?立即刷新