说明:
本教程仅供于学习研究使用,请勿用于其他用途。
软件安装:
官网下载visual studio Visual Studio: 面向软件开发人员和 Teams 的 IDE 和代码编辑器 (microsoft.com)
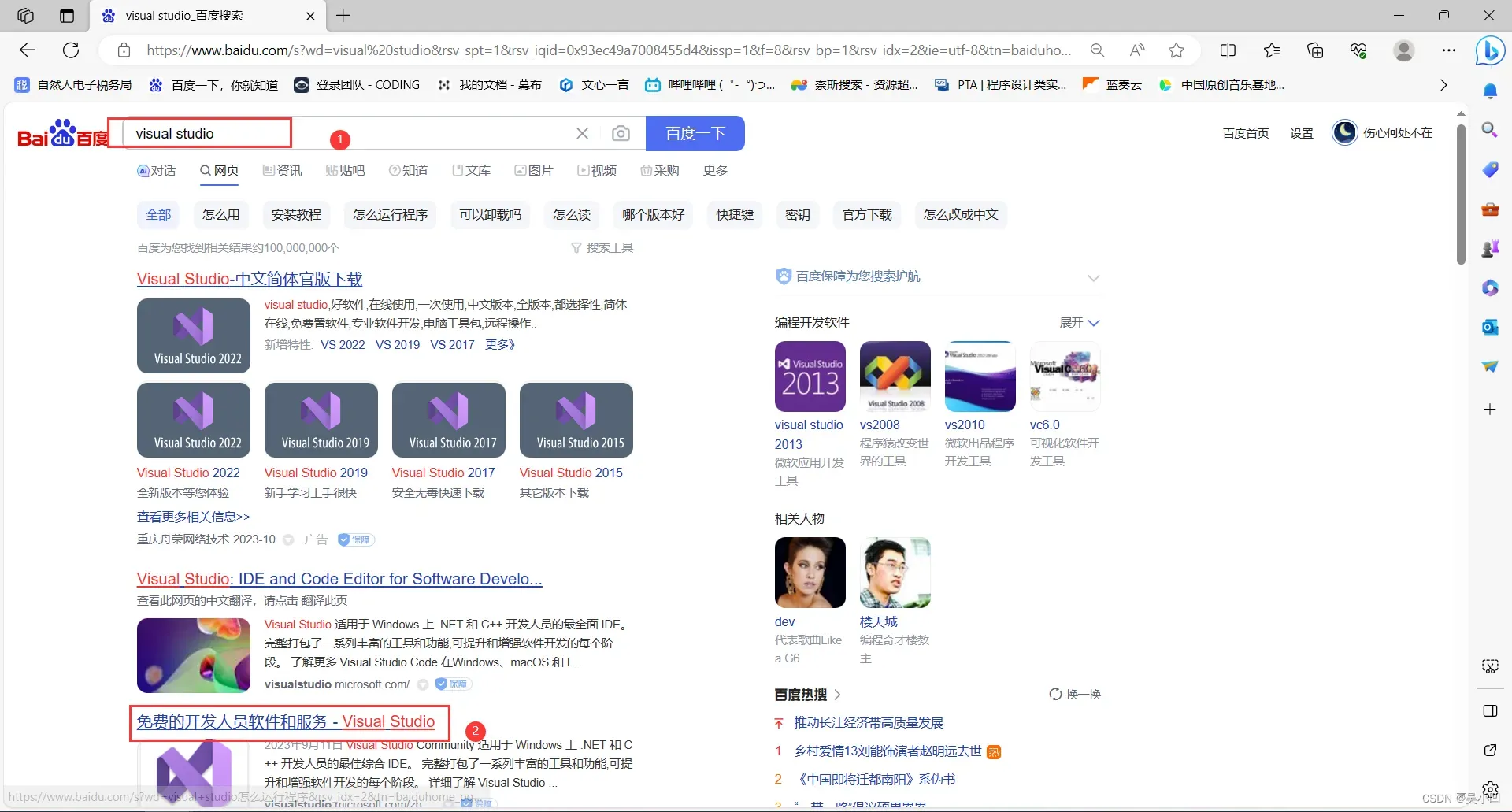
点进网页后下拉找到个人免费版本。点击下载即可。
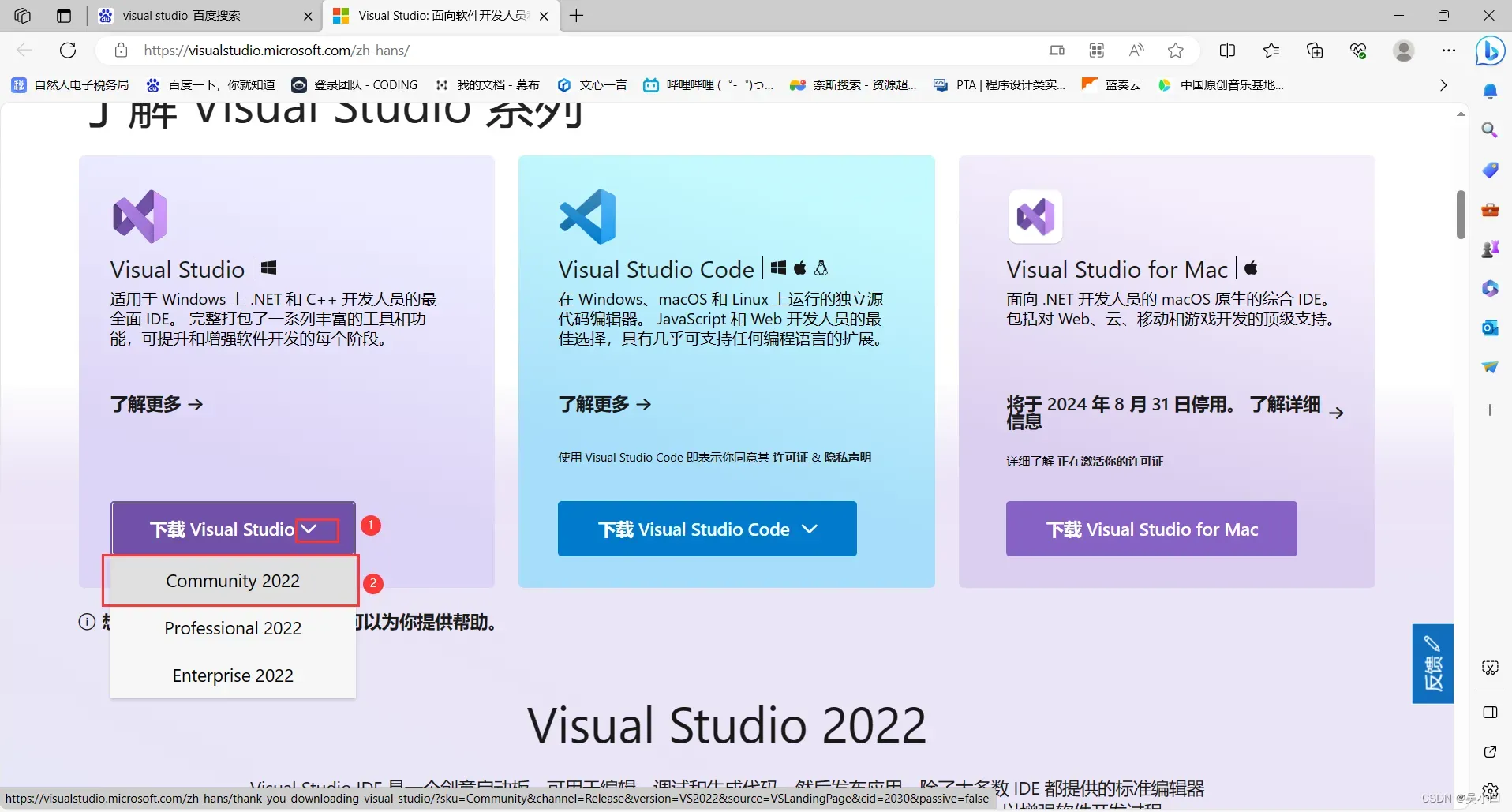
1:找到浏览器下载位置,2:选择打开下载文件位置、3:选择双击运行安装程序
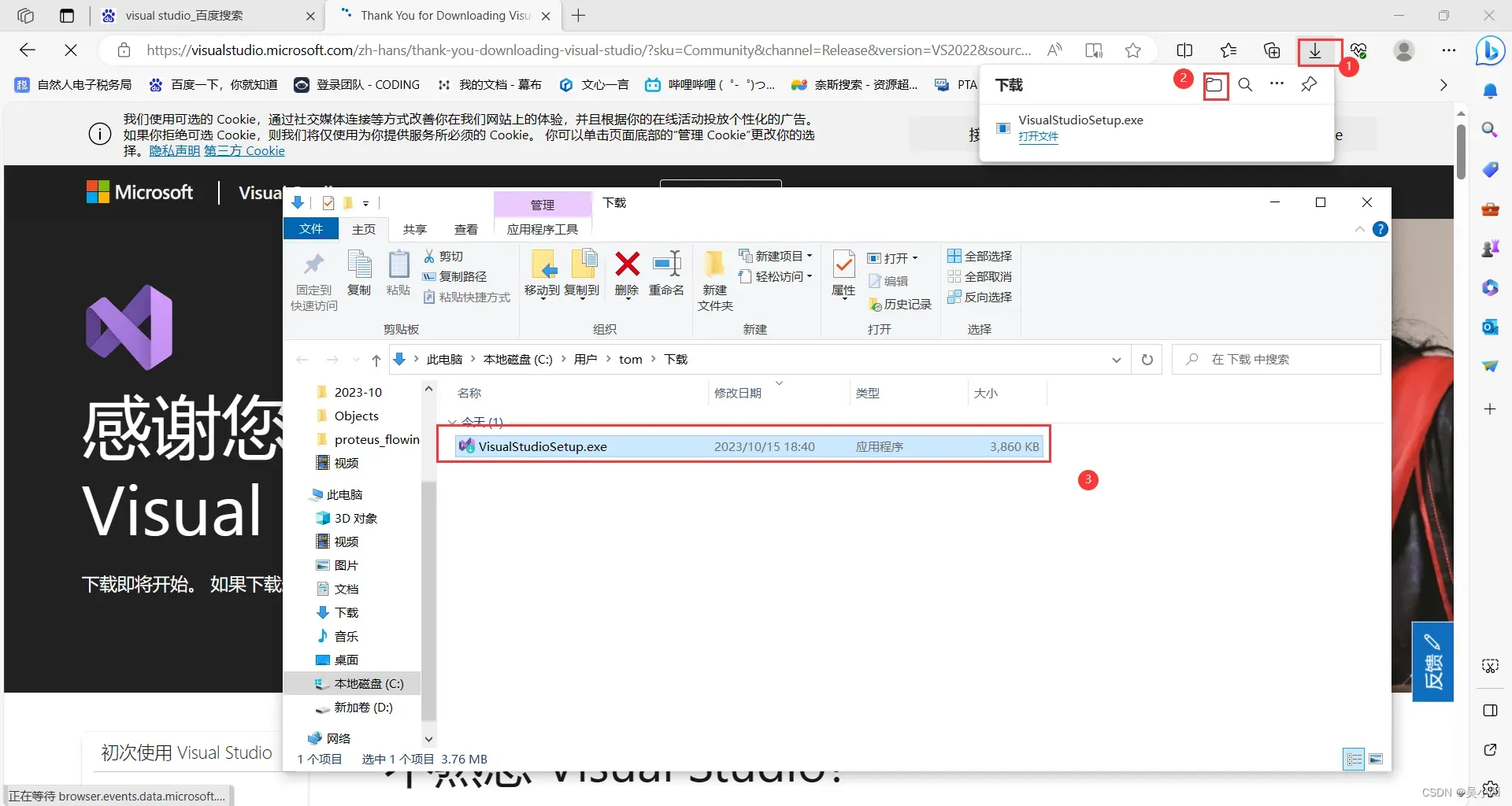
点击继续
等待下载完成后,勾选对python 的开发。
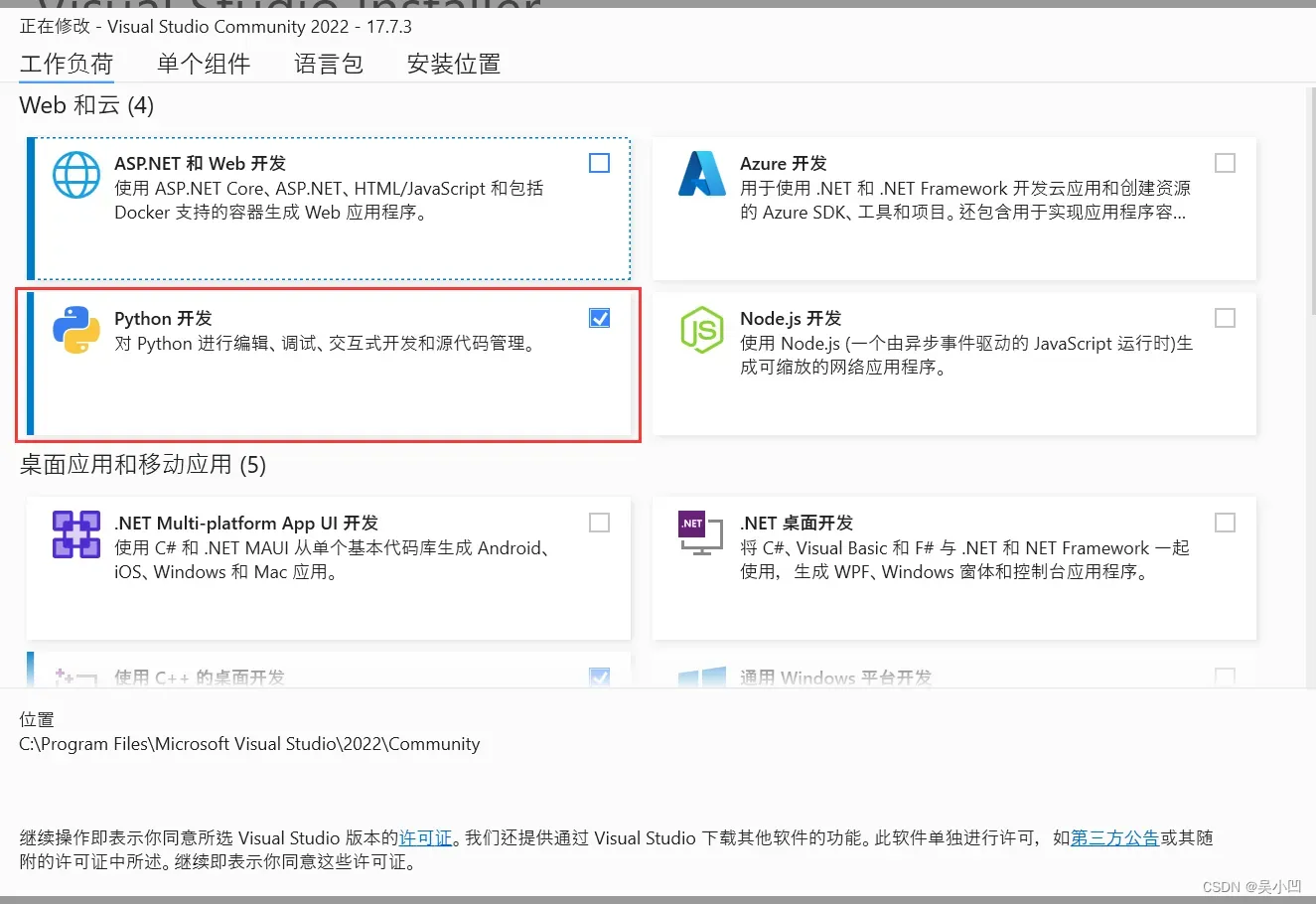
最后等待安装完毕即可。
新建工程:
一般安装完成后桌面是没有图标的的我们要去系统栏进行搜索。
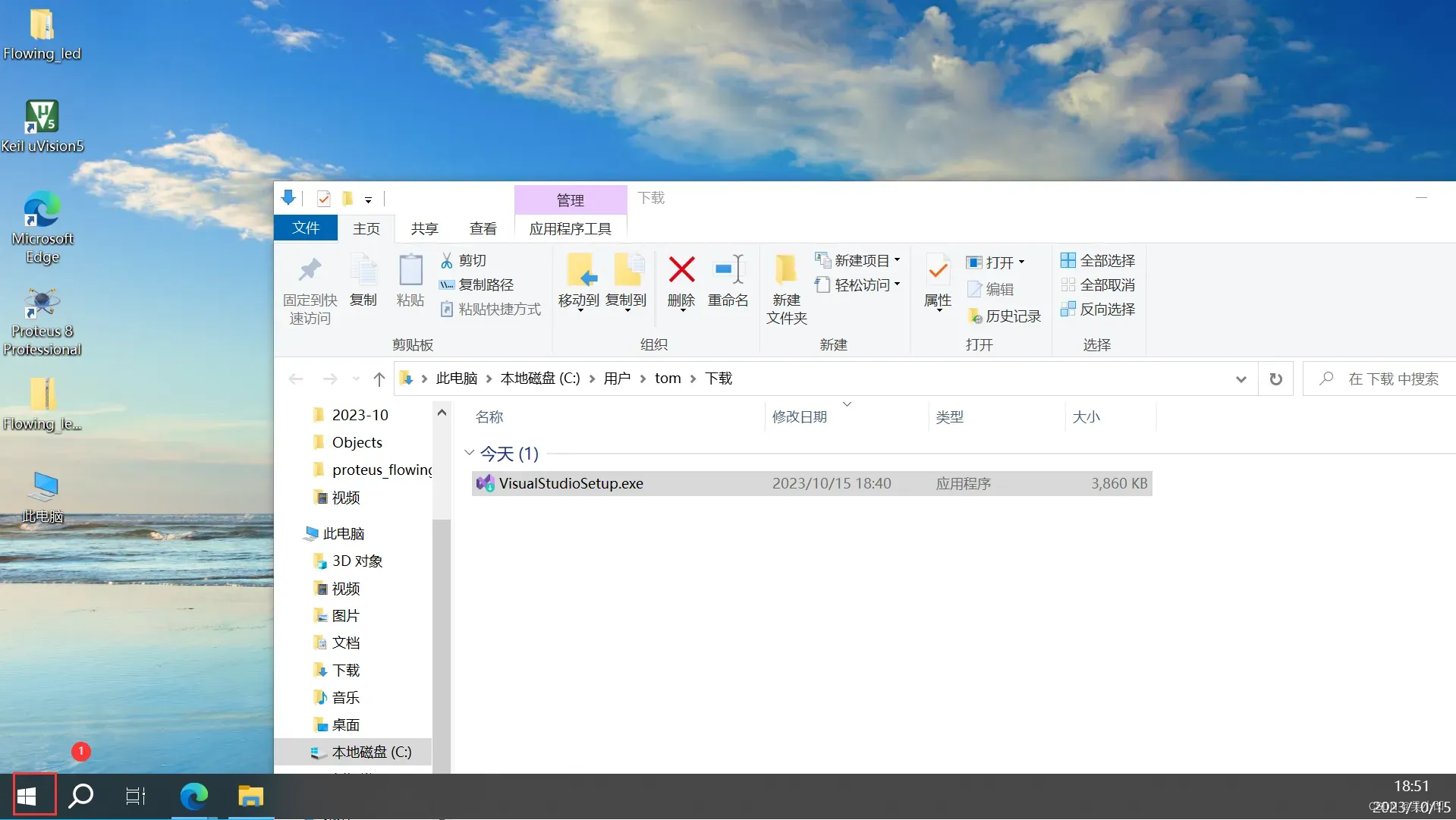
选择创建新项目。
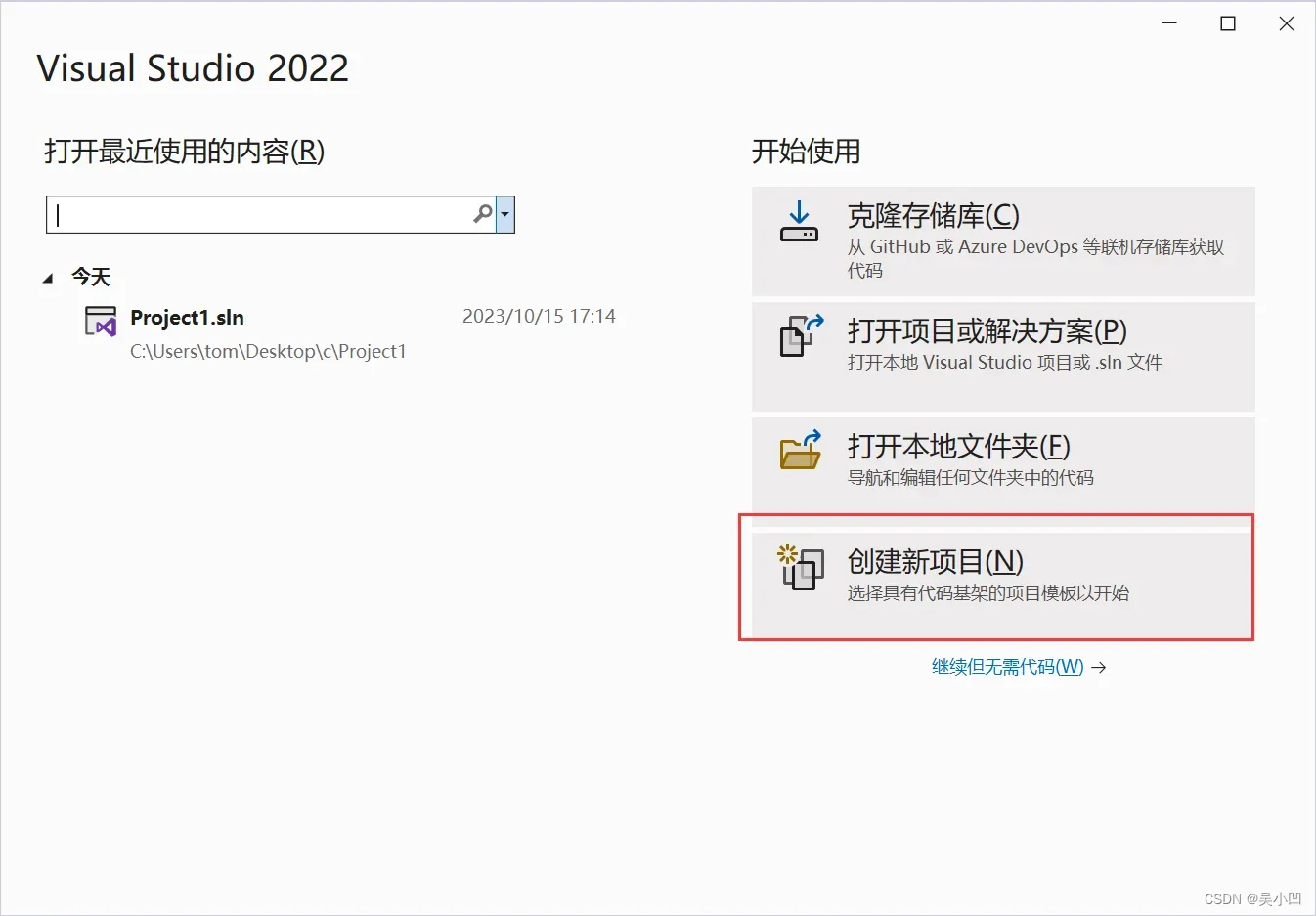
1、点击下拉选项,2、找到python 项目
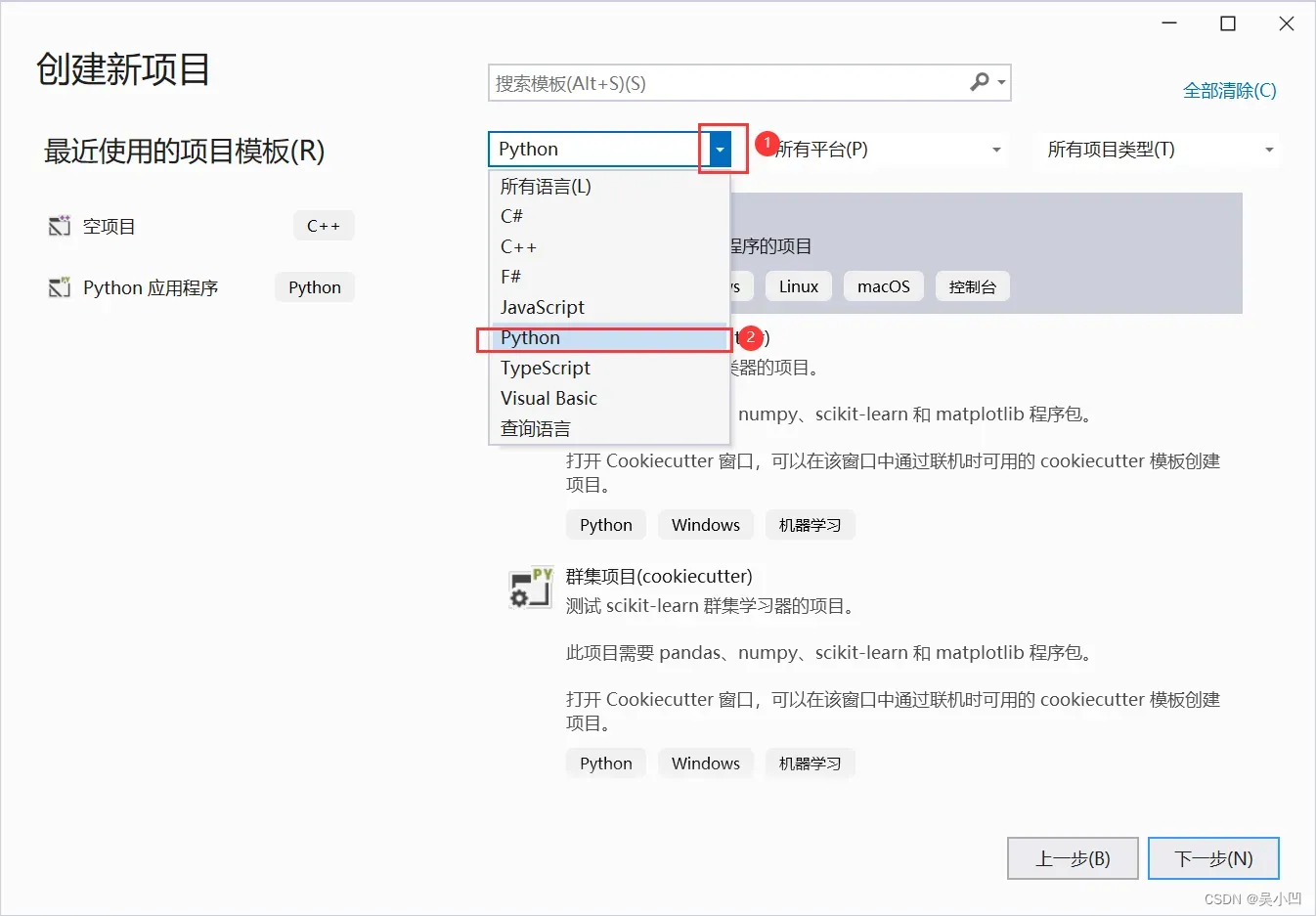
1、选择python应用程序,2、点击确定
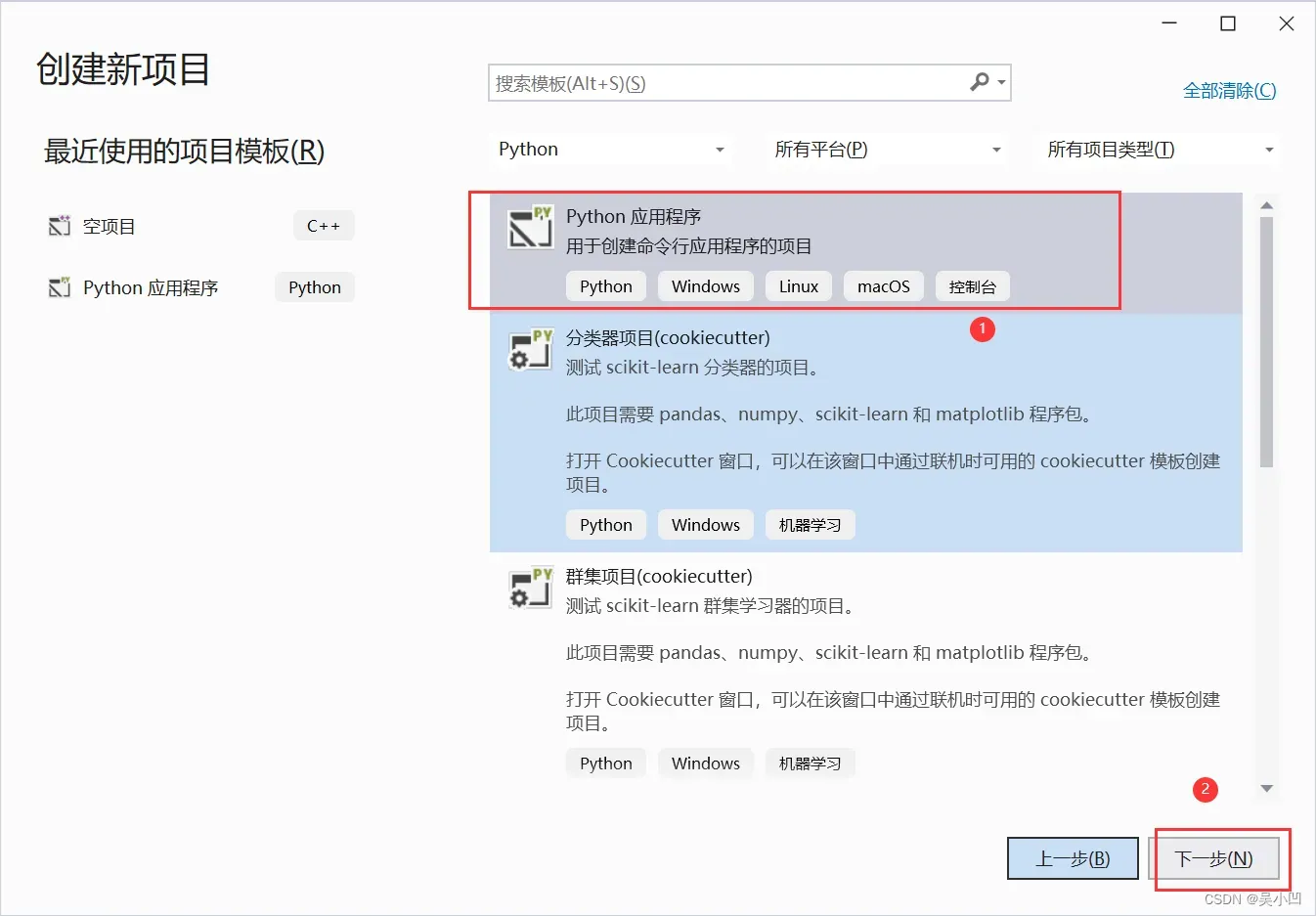
1、程序名称,2、程序存放位置,可自行修改,3、勾选,4、创建
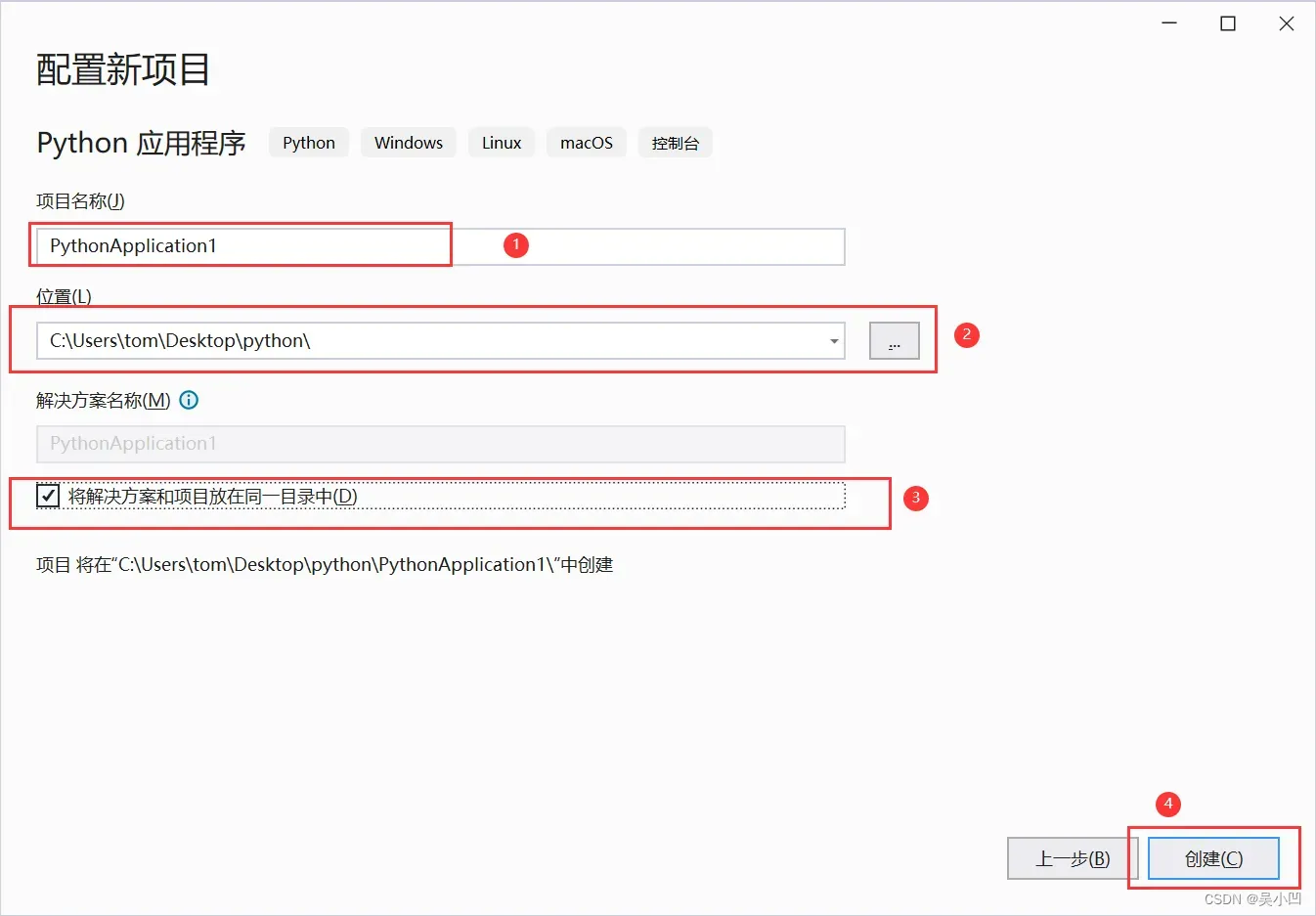
创建后如以下界面:
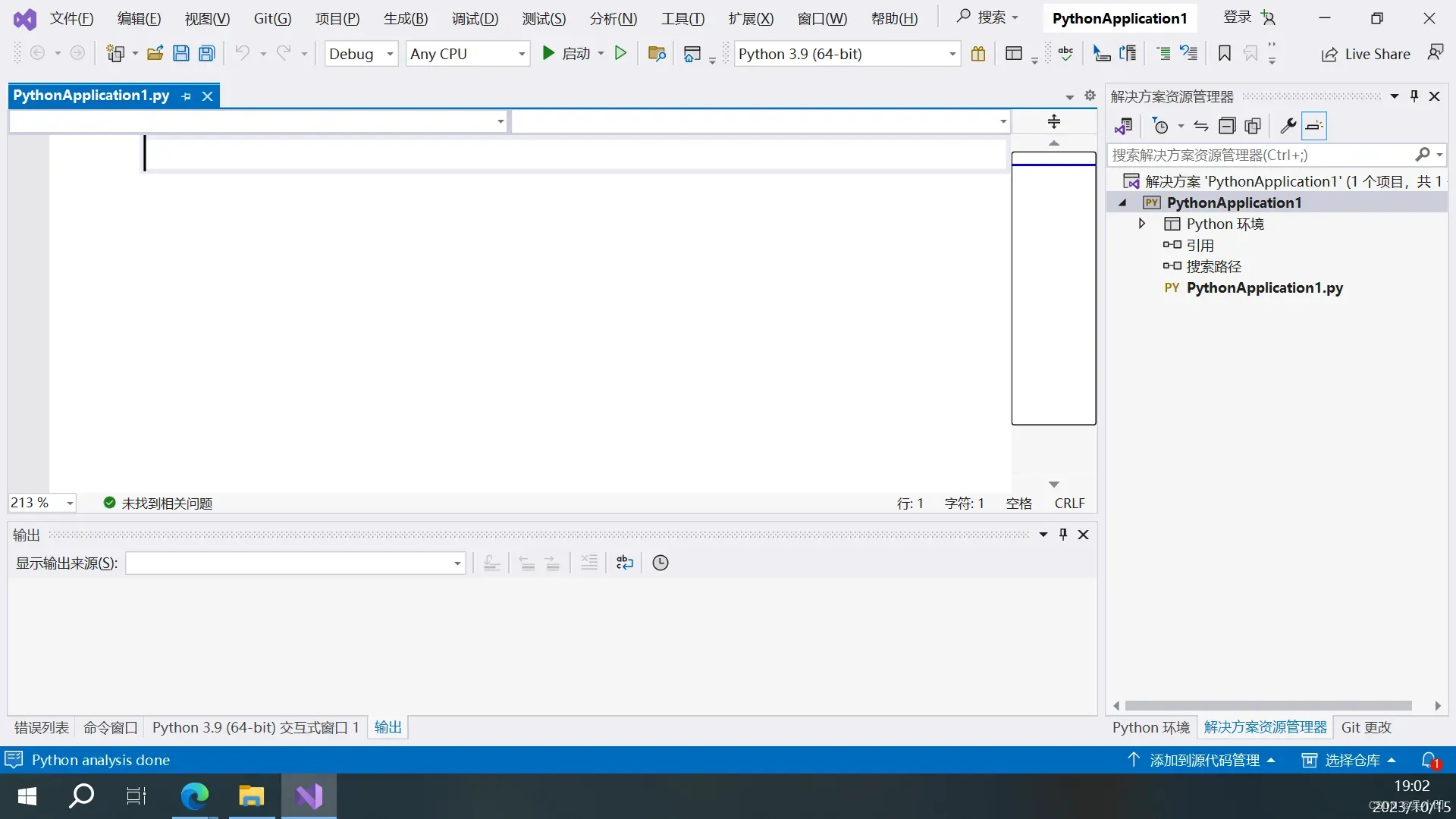
输入测试代码:
print("hello world")点击启动按钮
查看运行结果。
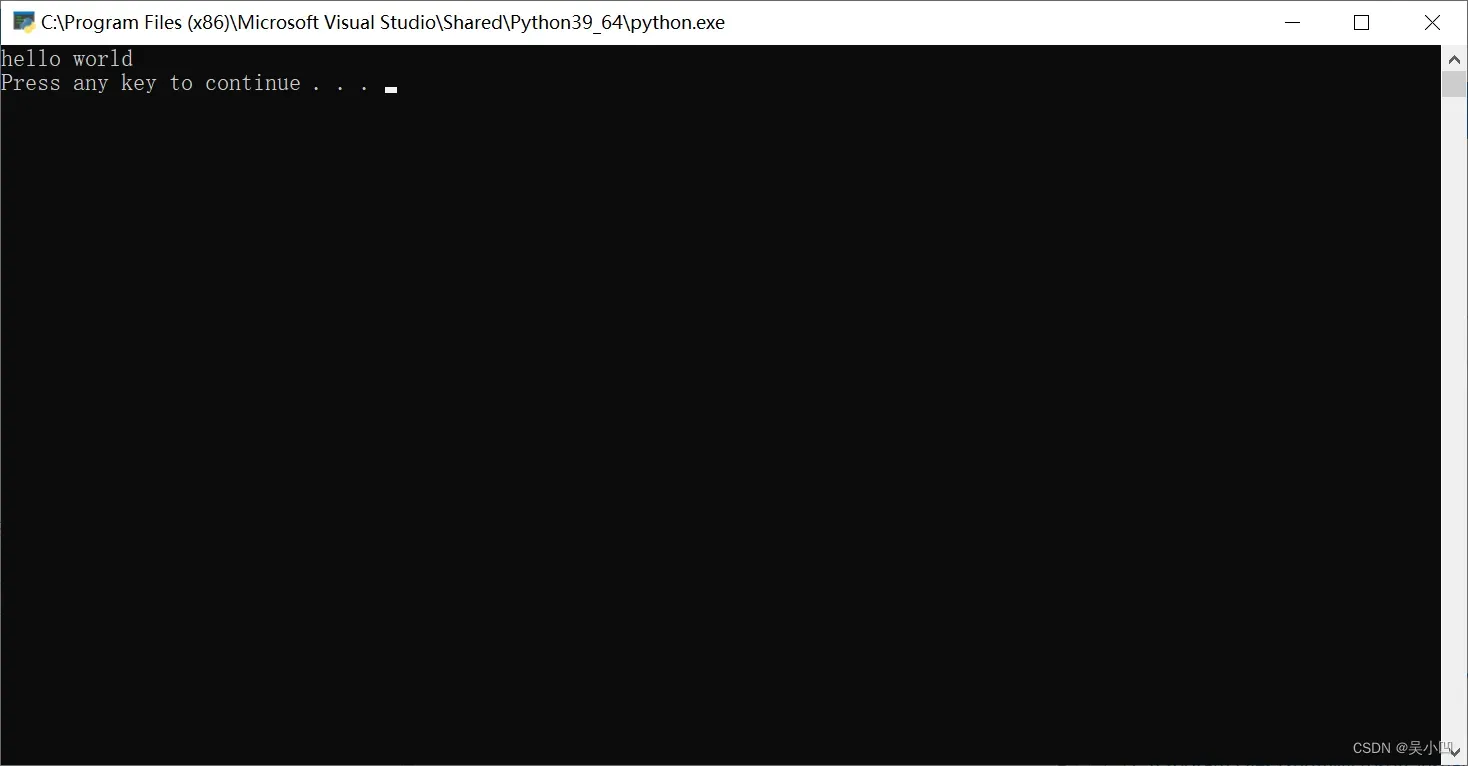
到此我们的新建工程就完毕。
导入python 包:
需要导入的第三方包有两个,是requests和BeautifulSoup,其中一个是用于网页请求的,一个是网页解析的。
import requests
from bs4 import BeautifulSoup直接运行会报以下错误。
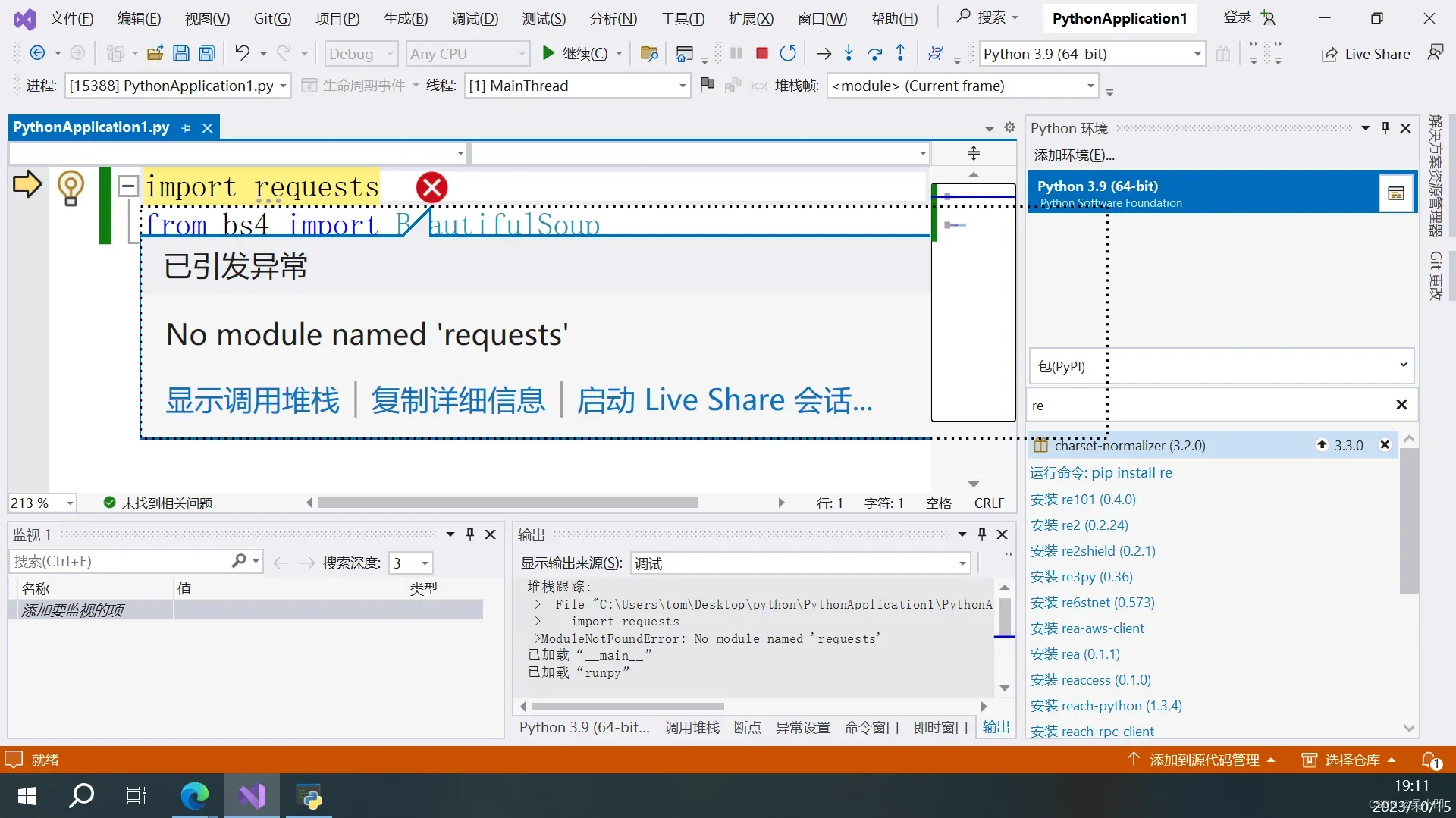 错误的含义是没有找到对应的模块。我们要先下载相关的第三方包。
错误的含义是没有找到对应的模块。我们要先下载相关的第三方包。
首先我们关闭调试模式后,点击工具-》python-》python环境
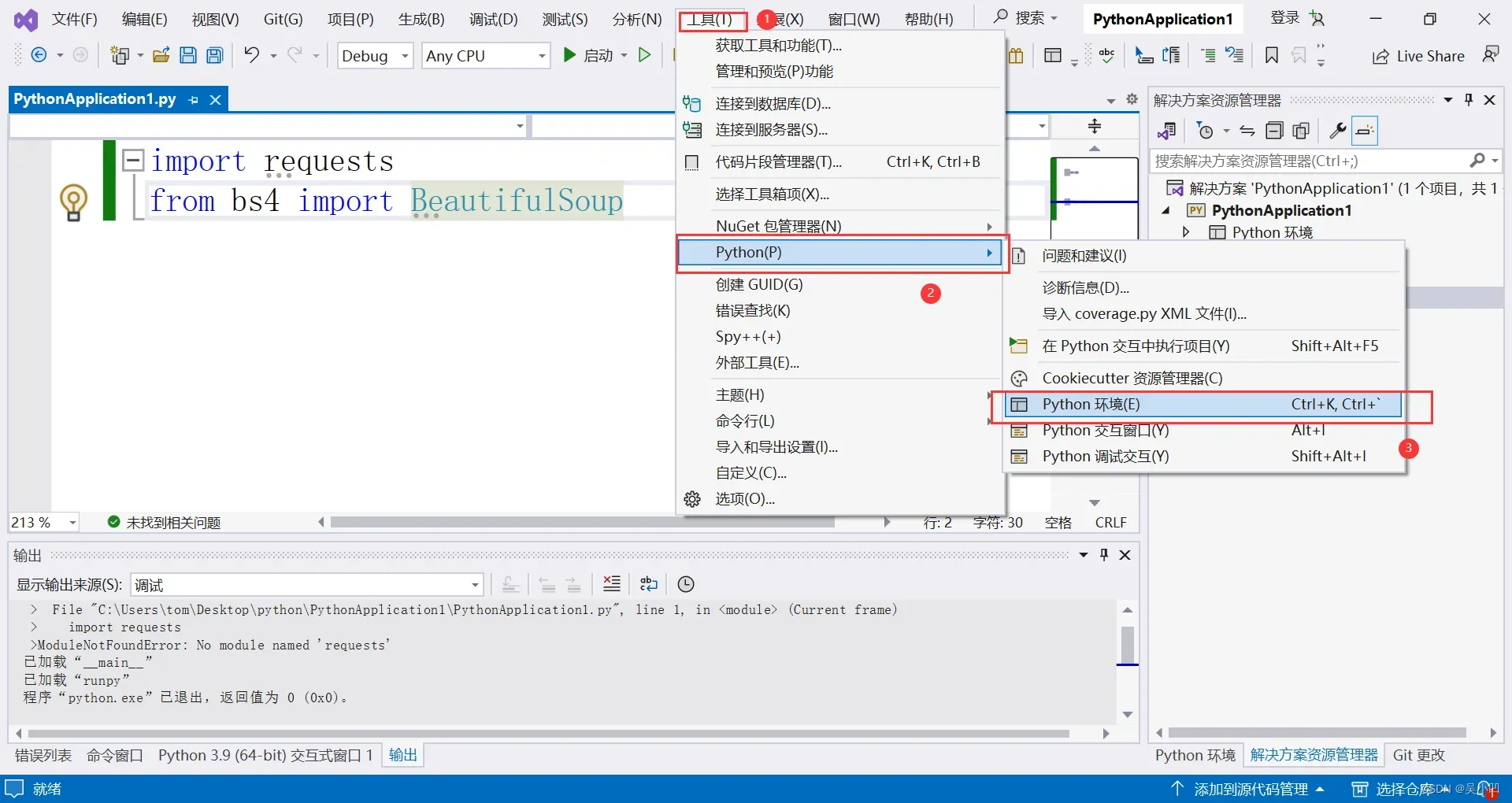
1、右侧输入requests,2、点击安装运行命令 pip install requests
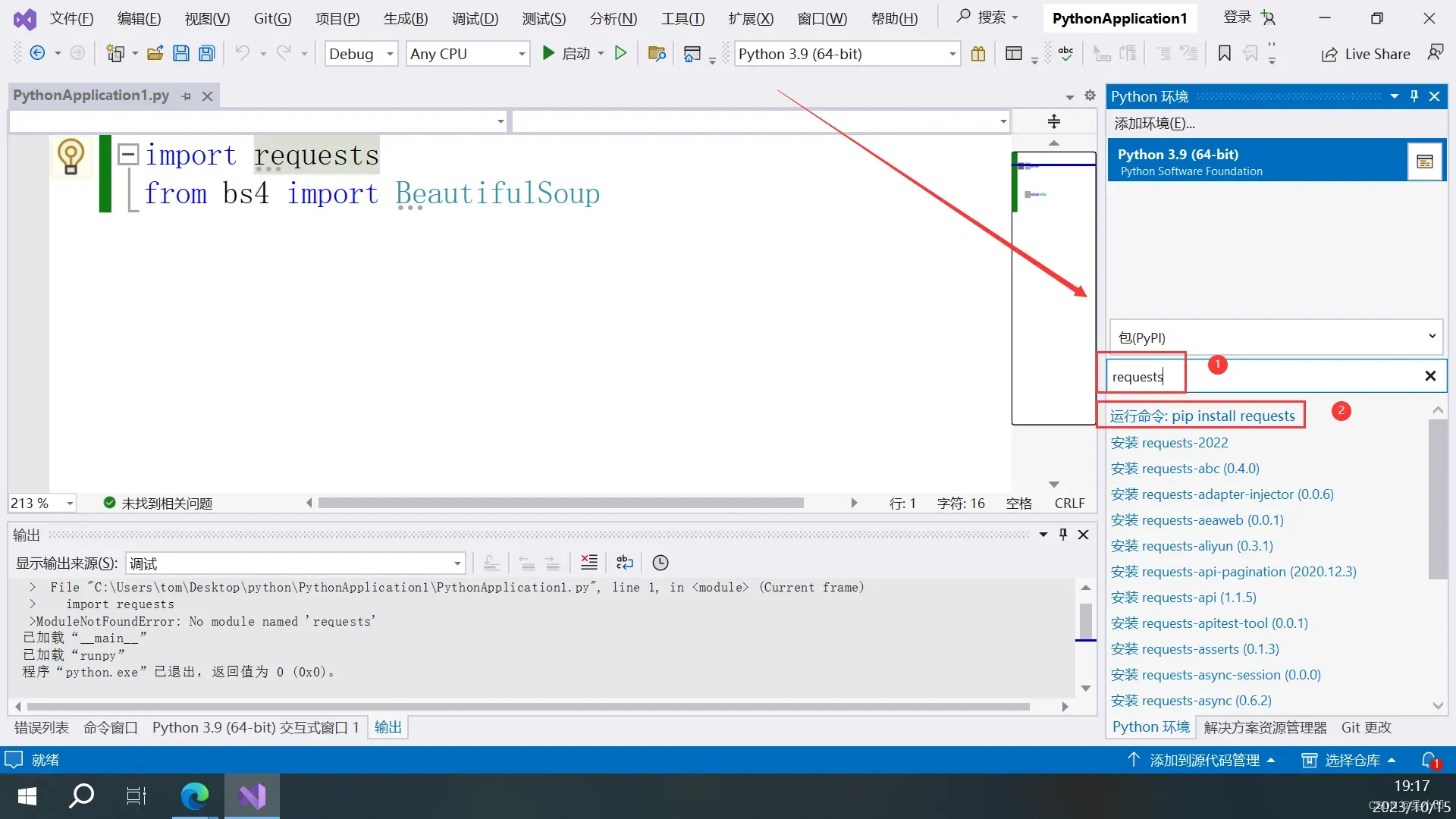
如果弹出提升权限点击立即提升即可
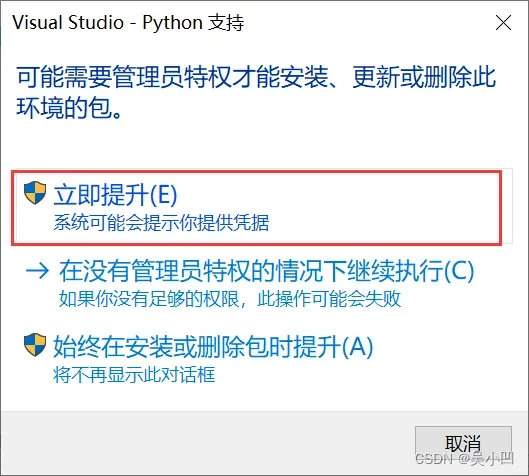
显示此提升表明安装第三方包成功了
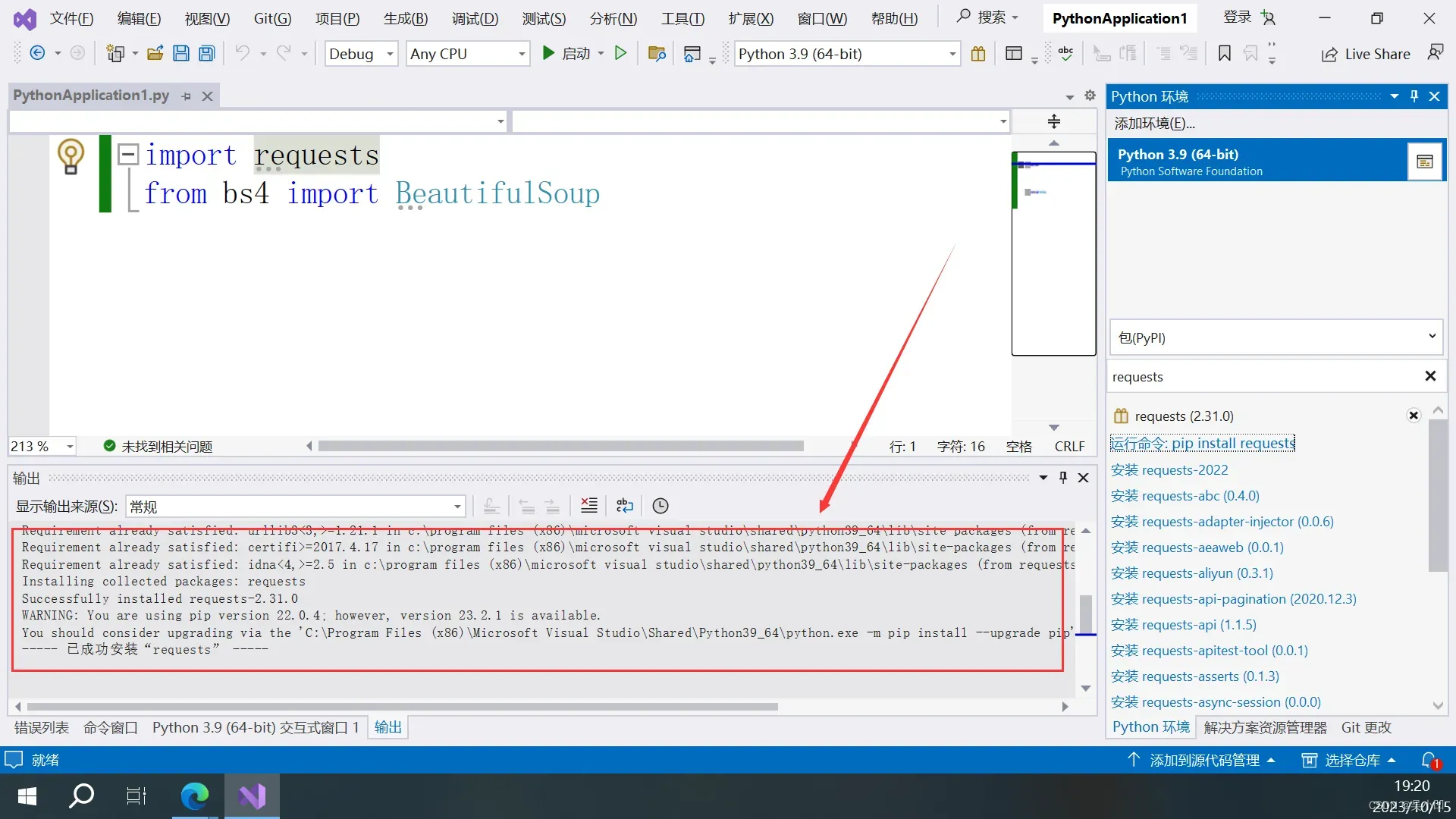
同样的步骤导入bs4
如果是其他编译环境就就采用以下命令即可。
pip install requests
pip install bs4判断爬取网页的编码格式:
定义一个字符串变量内容为需要爬取的小说主页。
# 小说的URL
url = 'https://www.nfxs.com/book/126295/'字符串来源于百度搜索
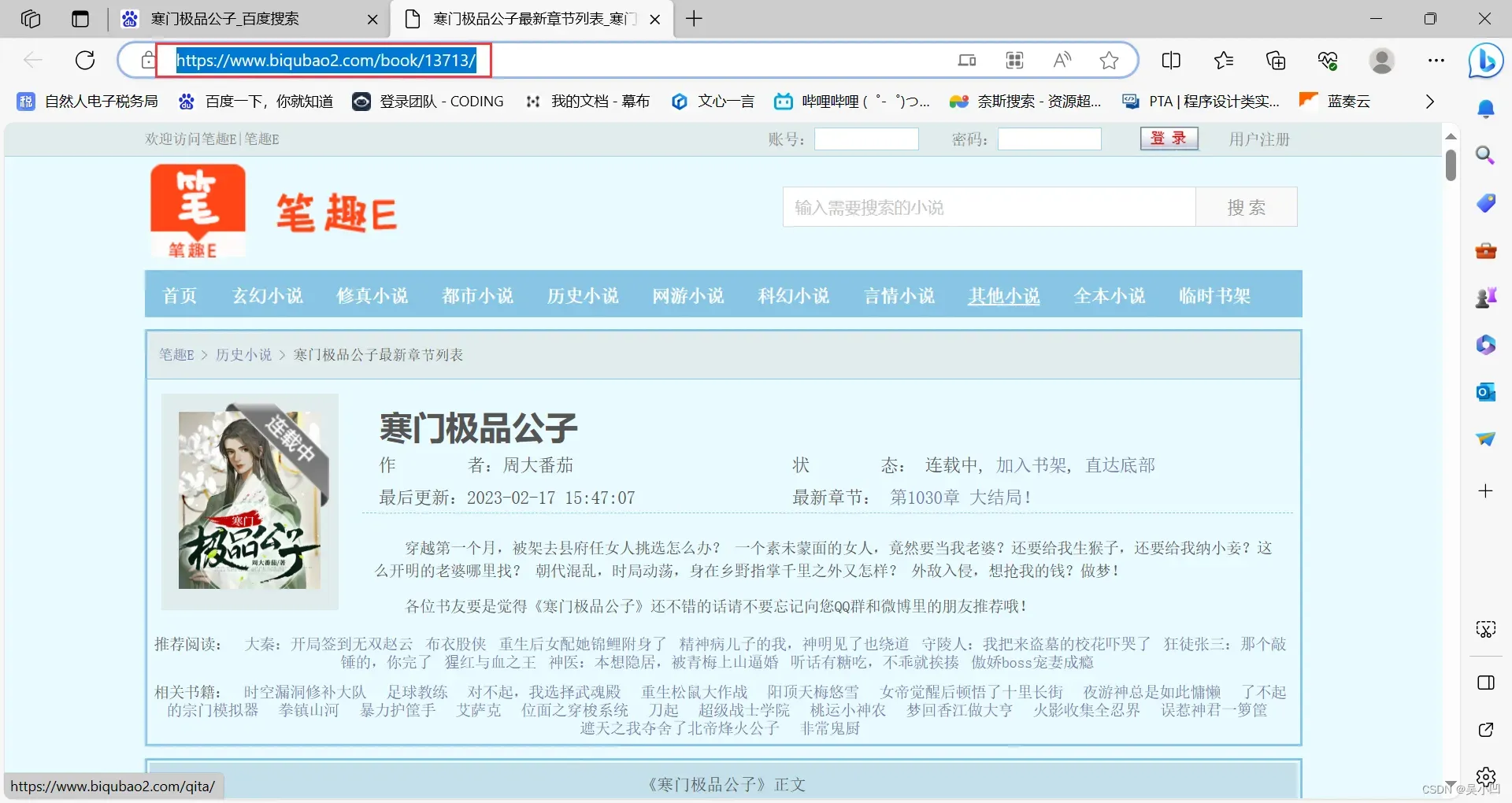 其他小说的话需要更换这个即可。
其他小说的话需要更换这个即可。
首先发起一个请求,并通过BeautifulSoup解析出来。
# 请求的URL是'url',这里的'url'只是一个占位符,你需要把实际的URL替换进去
response = requests.get(url)
# 设置响应的编码为'utf-8',这样获取到的文本内容就会是'utf-8'编码
response.encoding = 'utf-8'
# 导入BeautifulSoup库,这个库是Python中用来解析HTML或XML的库
# 用BeautifulSoup库的'html.parser'解析器来解析从URL获取到的HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
print(soup)运行结果如下这是编码格式正确可以进行下一步了。
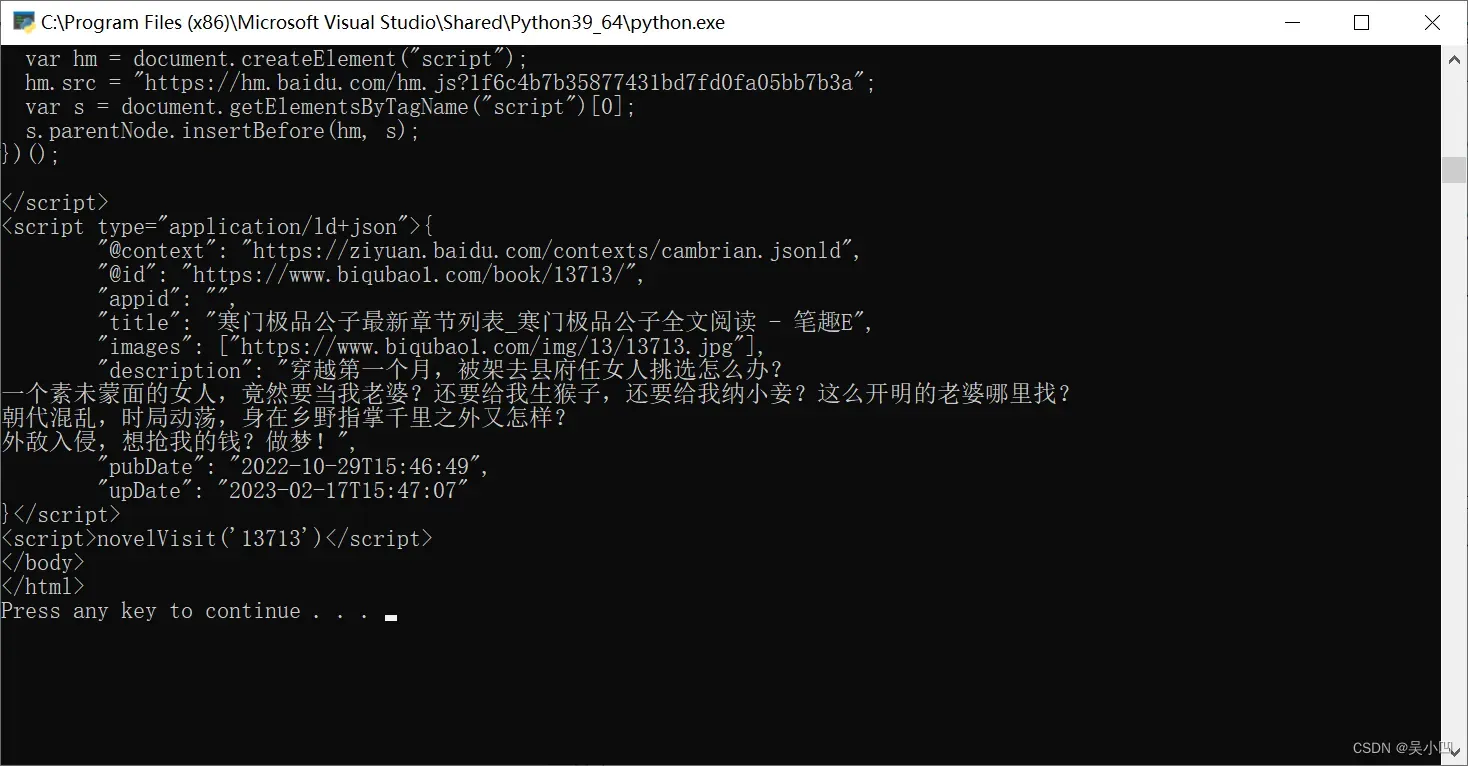
文中没有乱码是一个正常的页面返回。
下面是编码格式错误的,我们需要手动调整。
最常用的两种格式。
response.encoding = 'utf-8'
或者
response.encoding = 'gb2312'到这里我们的编码格式就能确定下来了。
获取小说章节链接及标题:
我们将执行的结果网上拉就可看到每个章节的前面带的有他的链接。
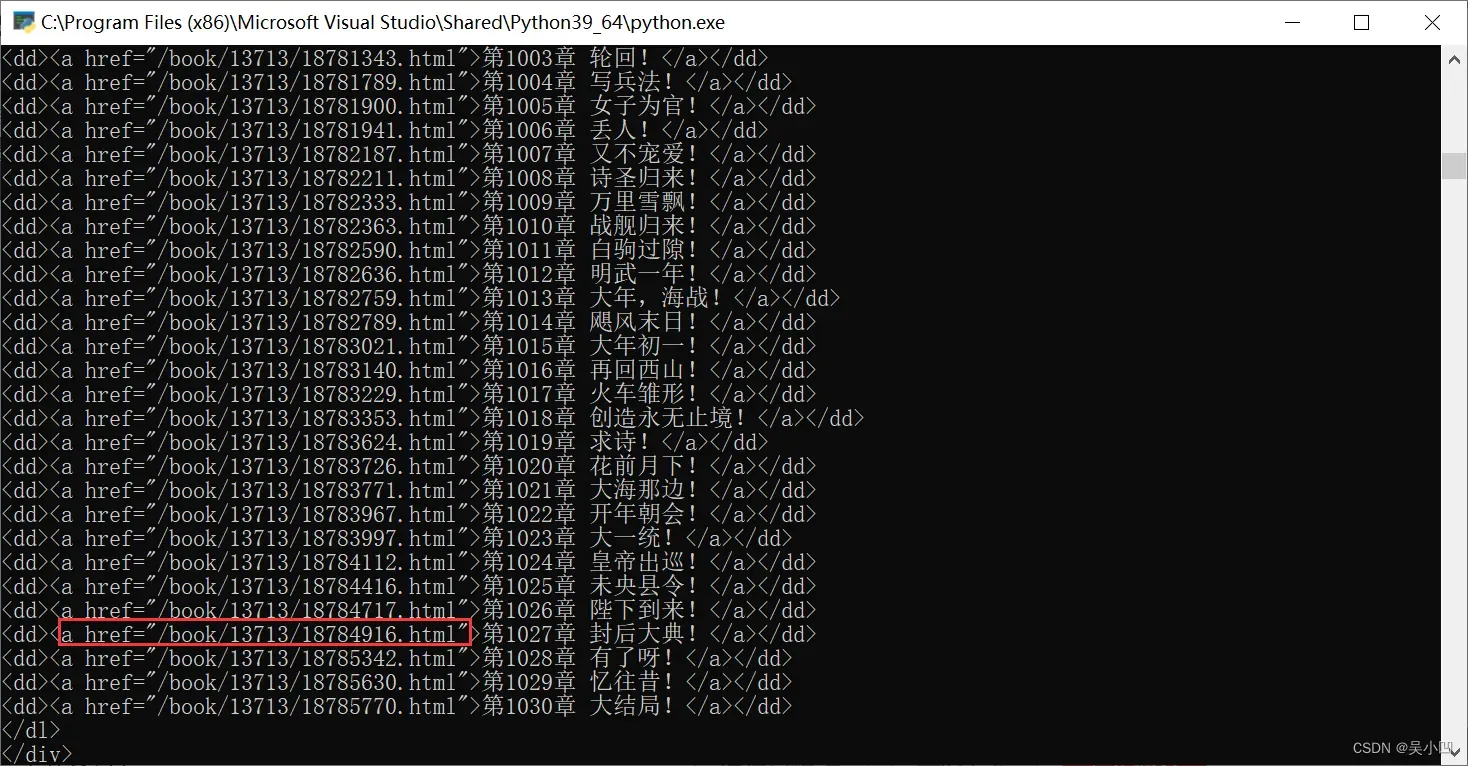
接下来我们要将其取出来,写入以下代码。第一次滤除其他数据
#找到HTML文档中的所有<a>标签(即所有链接)
soup.links = soup.find_all('a')
#遍历所有链接
# 获取小说的章节链接
for a in soup.links:
print(a)加入以上代码后输出,我们发现还有一些其他数据
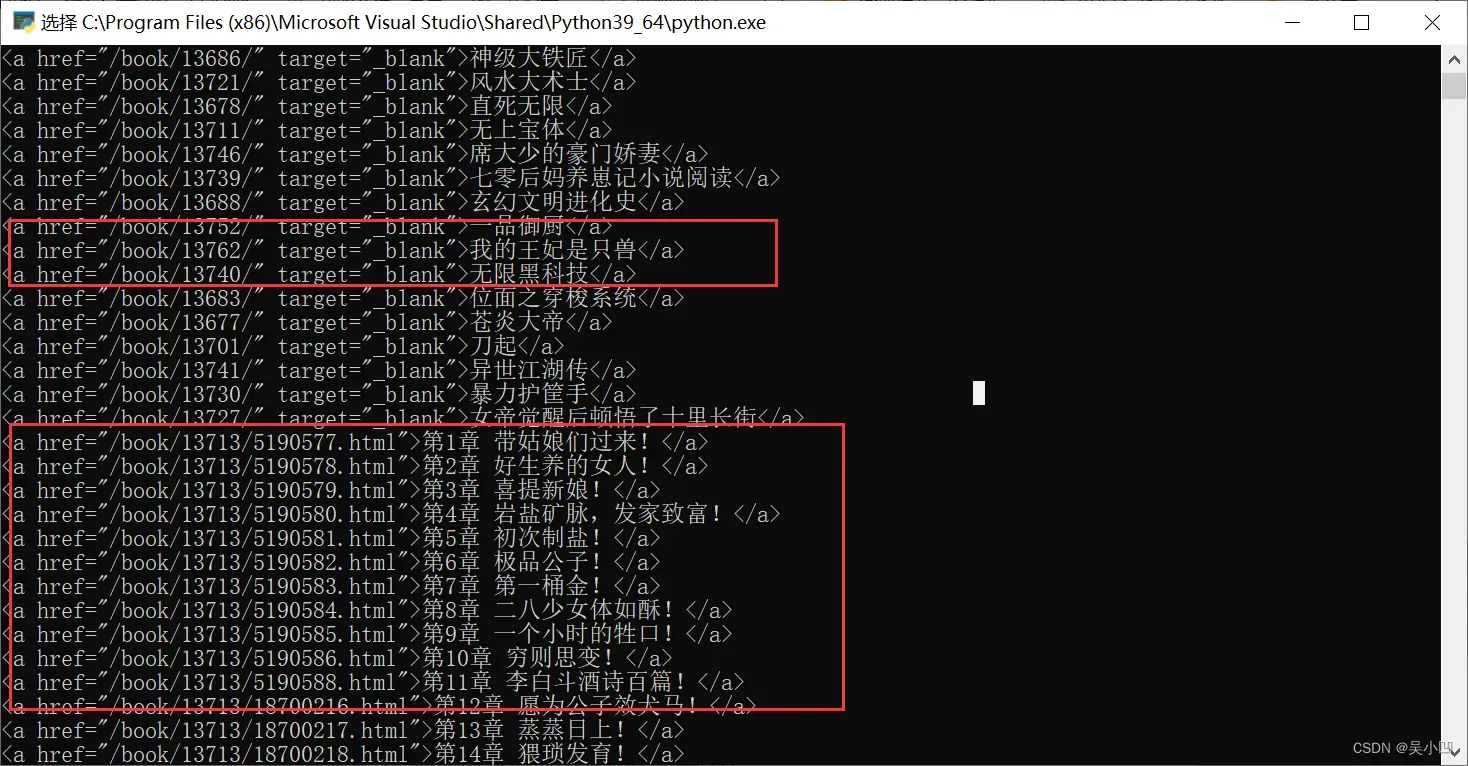
我们通过修改遍历代码将其他的滤除掉.
## 获取小说的章节链接
for a in soup.links:
if '.html' in str(a):
print(a)通过判断其中是否包含’.html’字符,来将其他滤除掉。
我们再次运行。
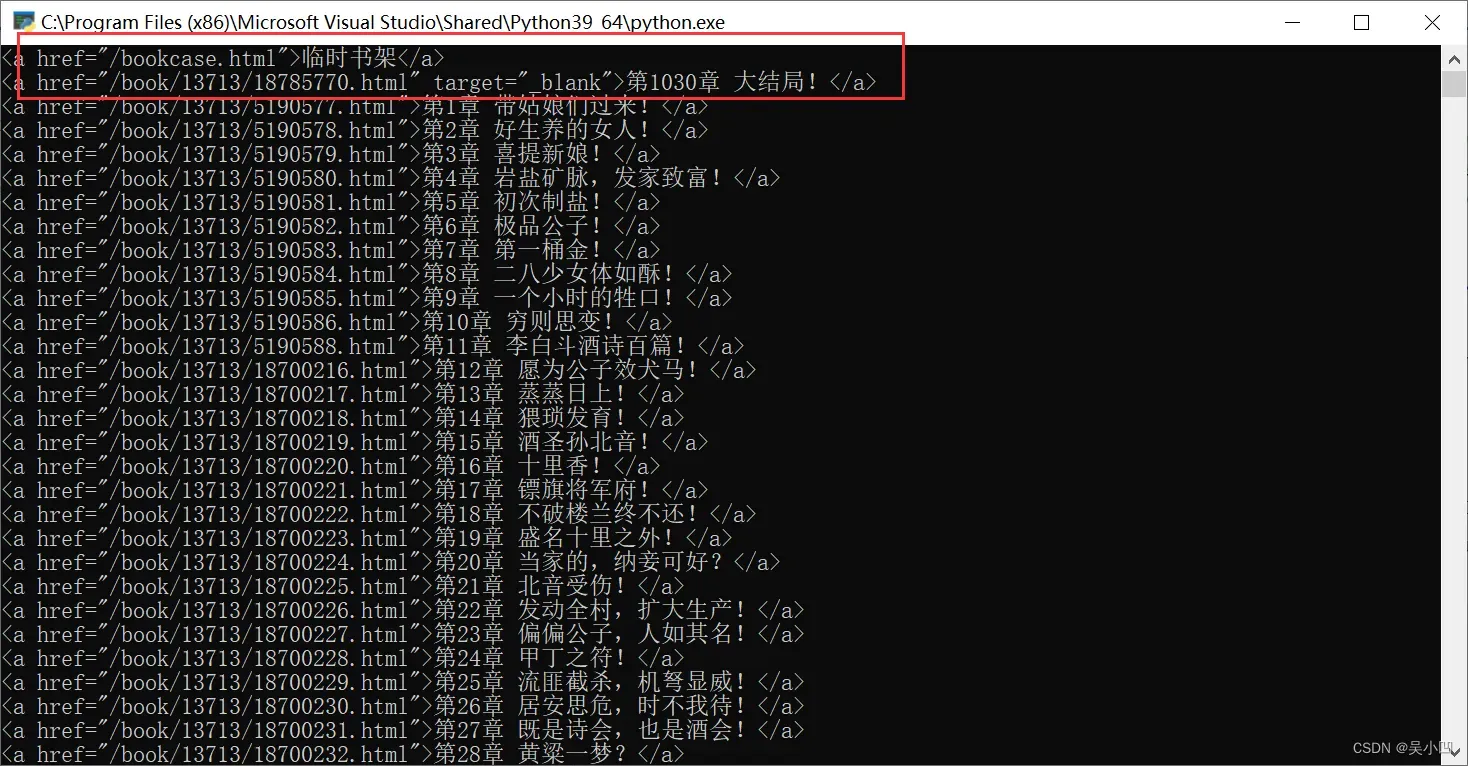
我们发现其中还是有两个我们不想要的数据。再次修改滤波代码。
滤除第一种的时候,我们只需要将章节这个也加入判断即可,滤除第二种错误数据我们就需要强行固定序列了,比如我们强行让它从第一章开始。代码如下:
# 获取小说的章节链接
x=1
for a in soup.links:
if '.html' in str(a) and "第"+str(x)+"章" in str(a):
print(a)
x=x+1再次运行查看结果。
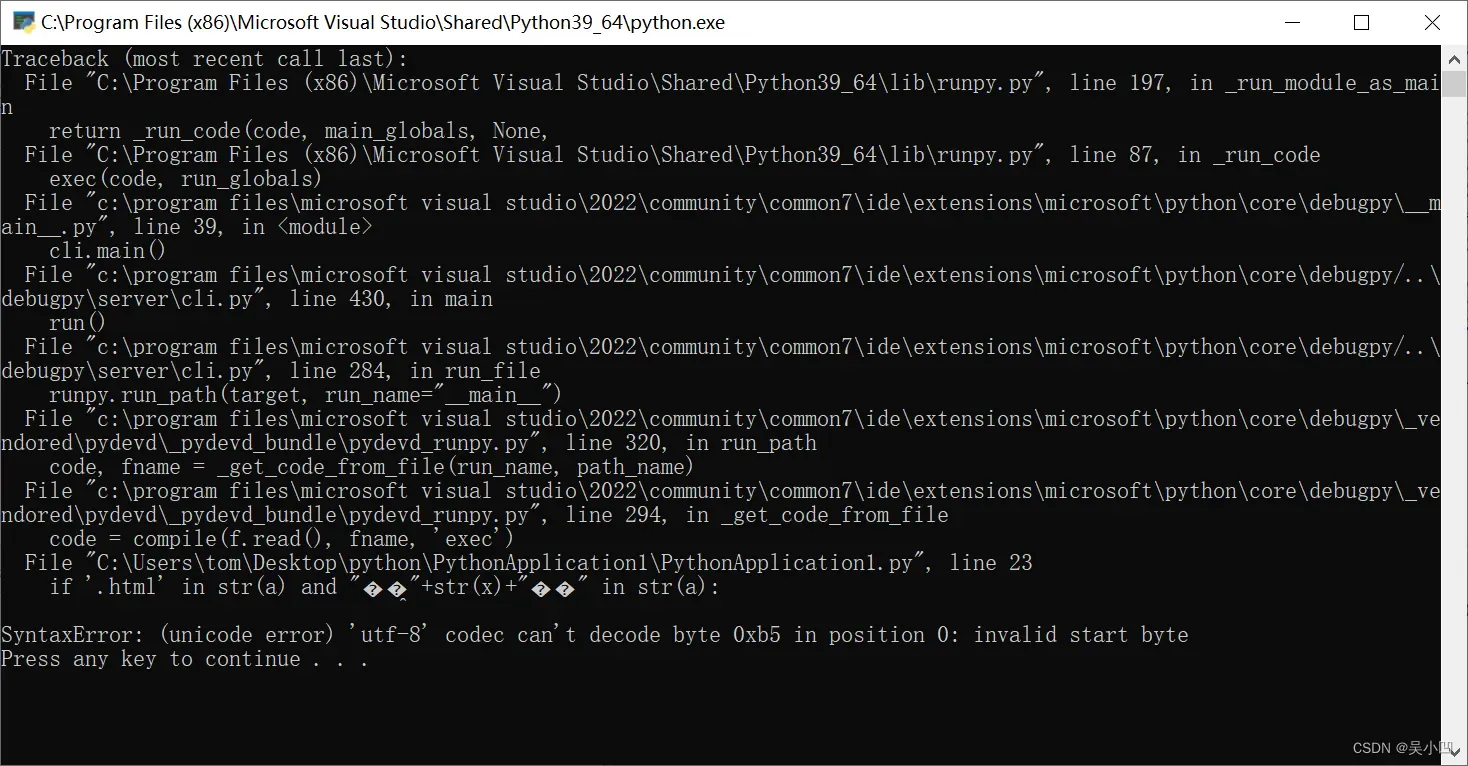 报错咯 ,因为我们用了中文字符,这个是python 编码文件问题。我们在第一行加一行代码:
报错咯 ,因为我们用了中文字符,这个是python 编码文件问题。我们在第一行加一行代码:
# coding: utf-8 再将文件改成utf-8的编码格式即可。
首先找到工具->自定义
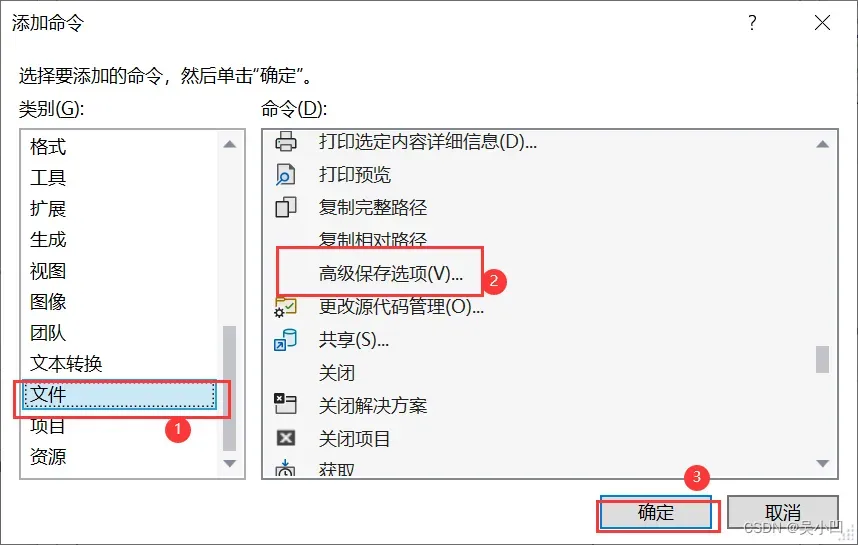
命令-》文件-》添加命令
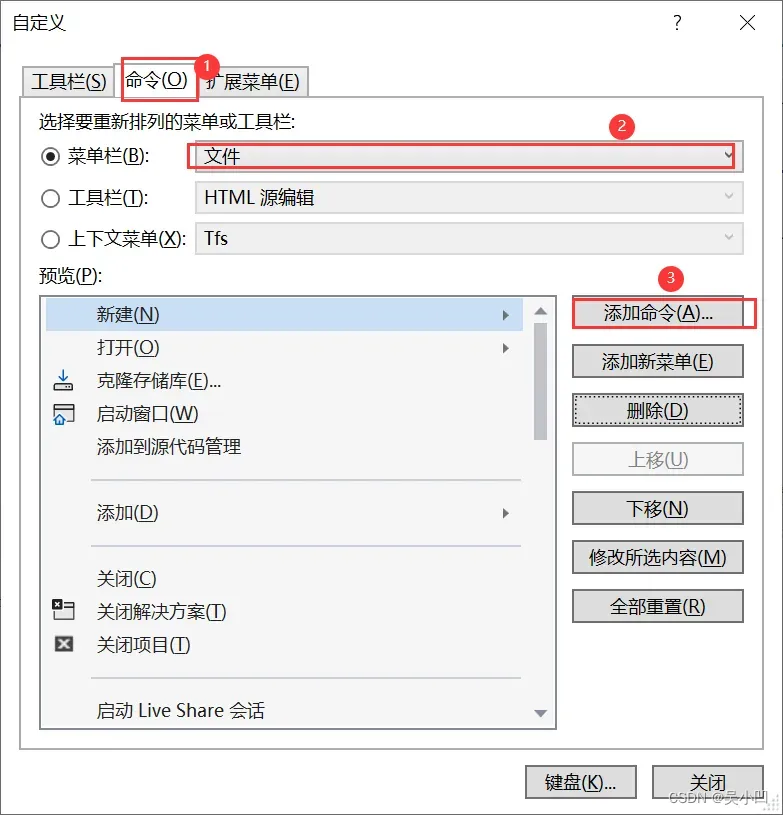
文件-》高级保存选项-》确定
 关闭窗口:
关闭窗口:
我们将文件保存为utf-8模式即可。
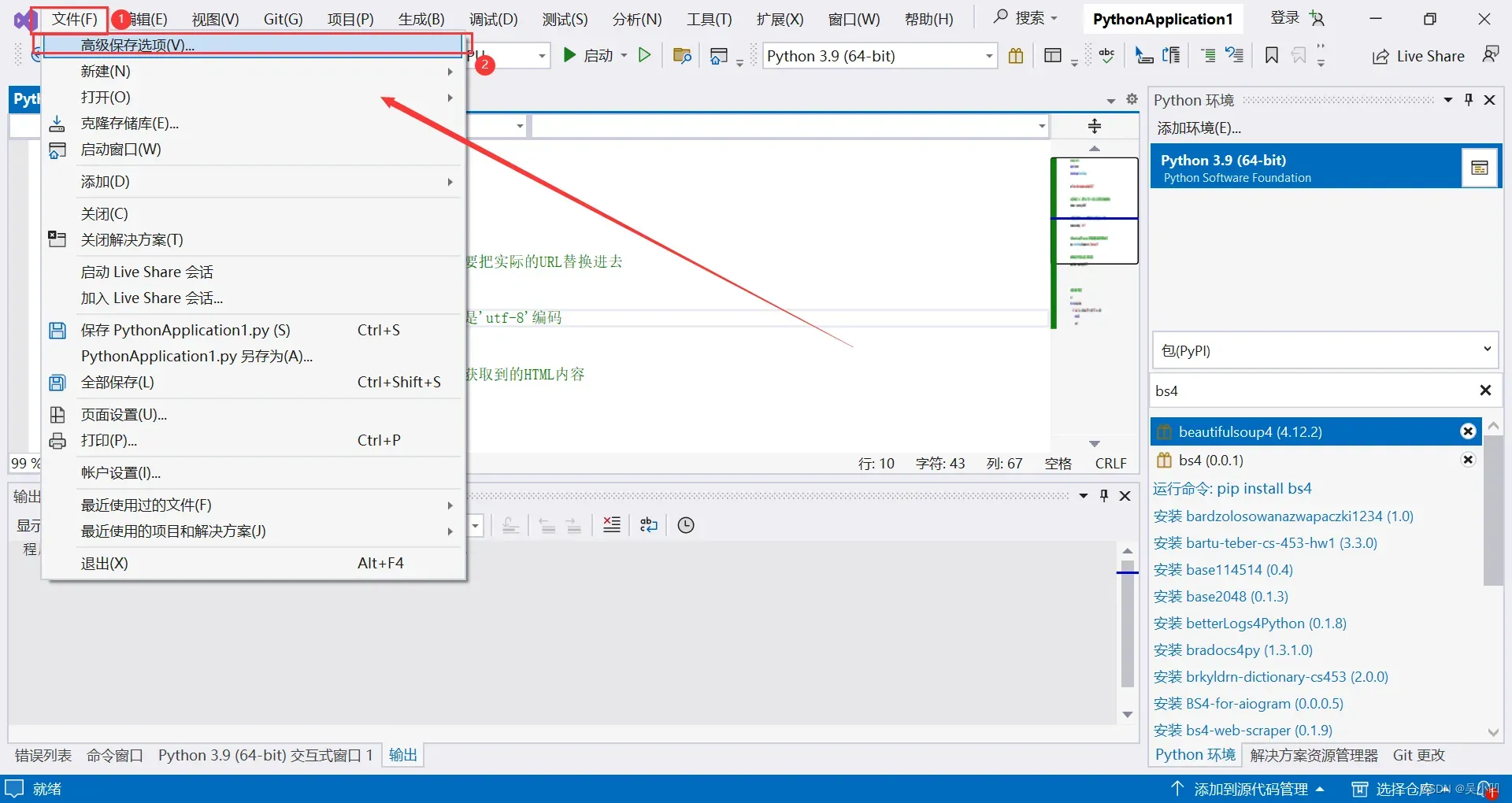
选择编码-》保存
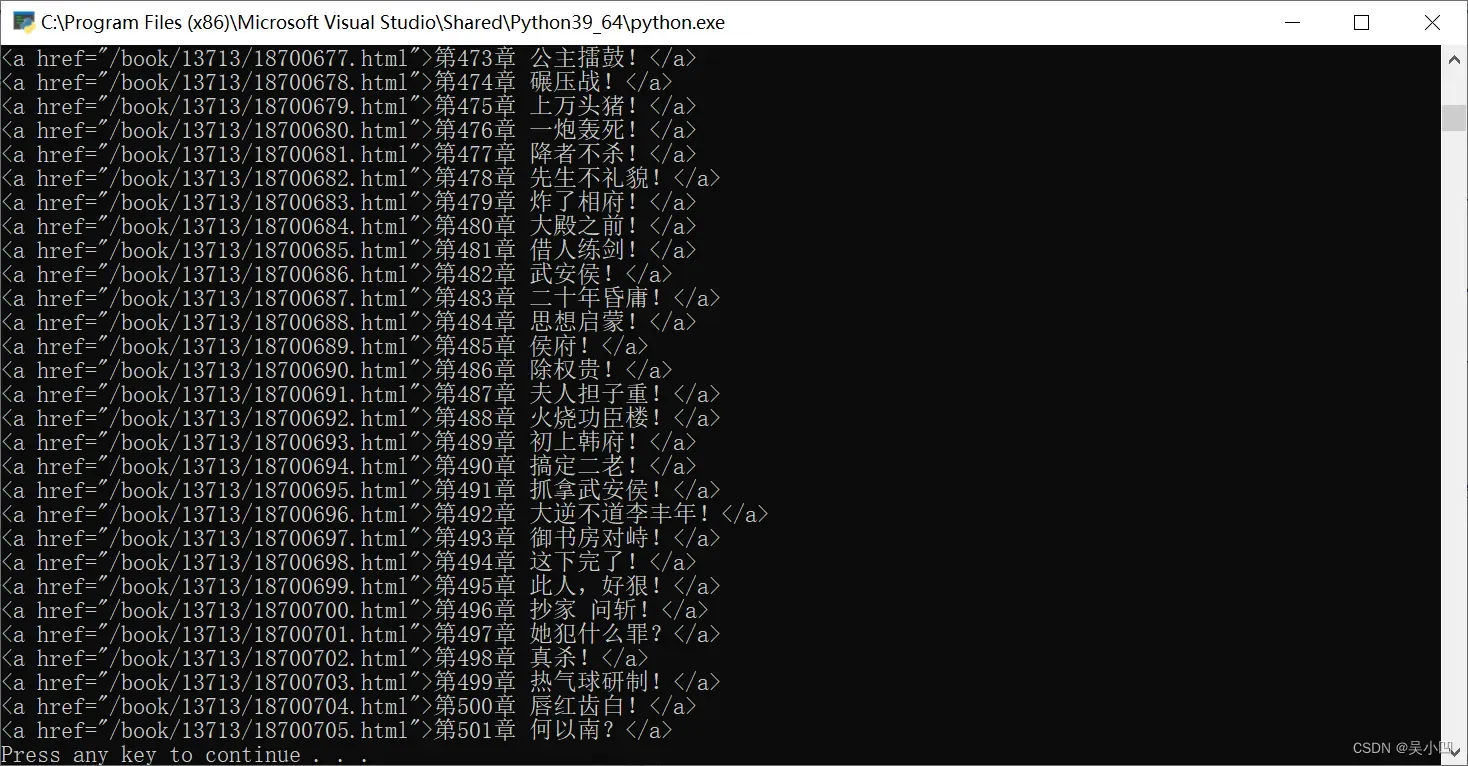
再次运行,我发现此时只有501章了,小说其实有1000多章呢
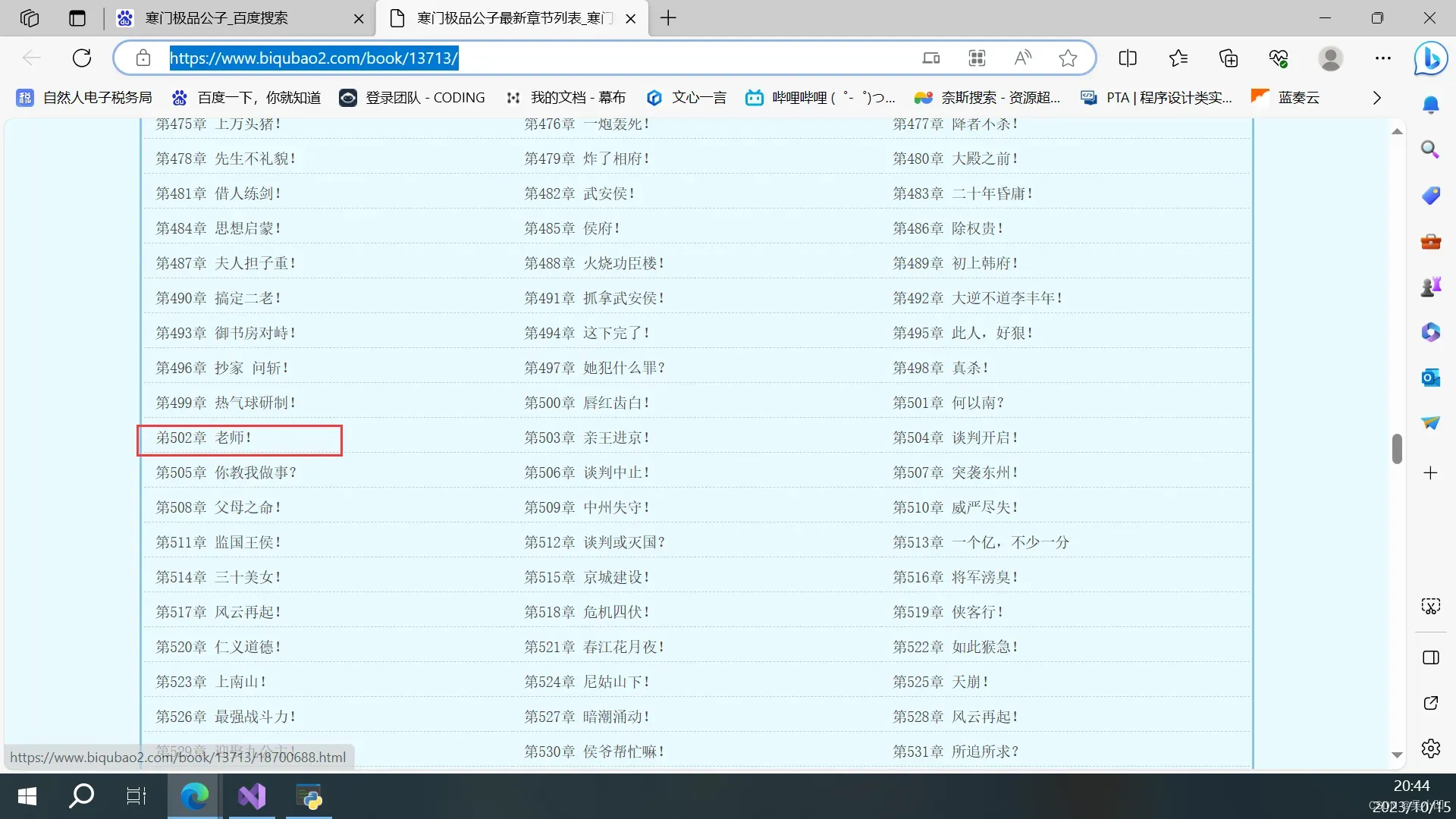
我们可以直接去章节目录查看问题。原来是网站存在错别字。
我们只好再次修改我们将这个错误也加入代码中.
# 获取小说的章节链接
x=1
for a in soup.links:
if '.html' in str(a) and ("第"+str(x)+"章" in str(a) or "弟"+str(x)+"章" in str(a)):
print(a)
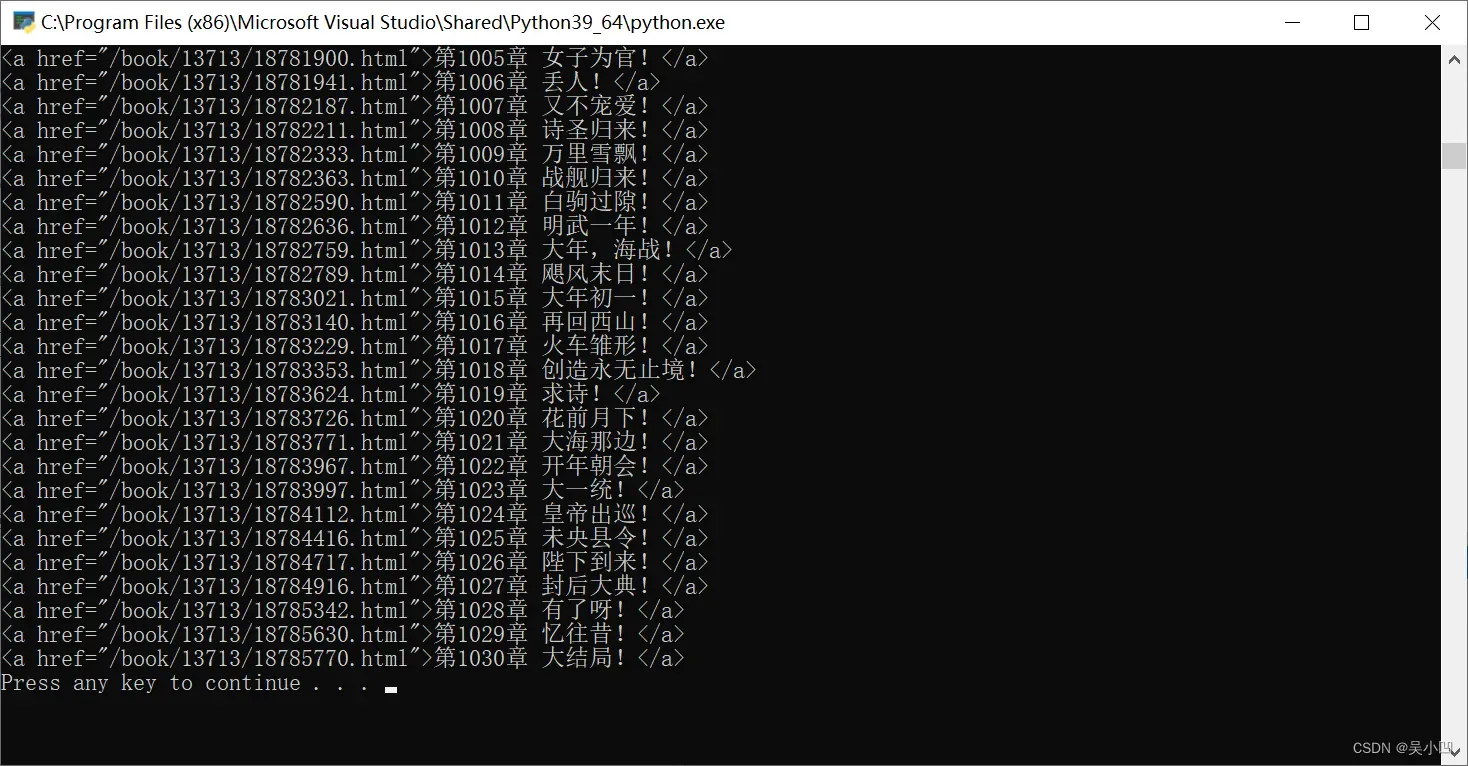
x=x+1再次运行代码。可以发现代码到可以到1000多章了。
首先将链接从标签a中取出来。
# 获取小说的章节链接
x=1
for a in soup.links:
if '.html' in str(a) and ("第"+str(x)+"章" in str(a) or "弟"+str(x)+"章" in str(a)):
print(str(a['href']))
x=x+1运行结果如下。
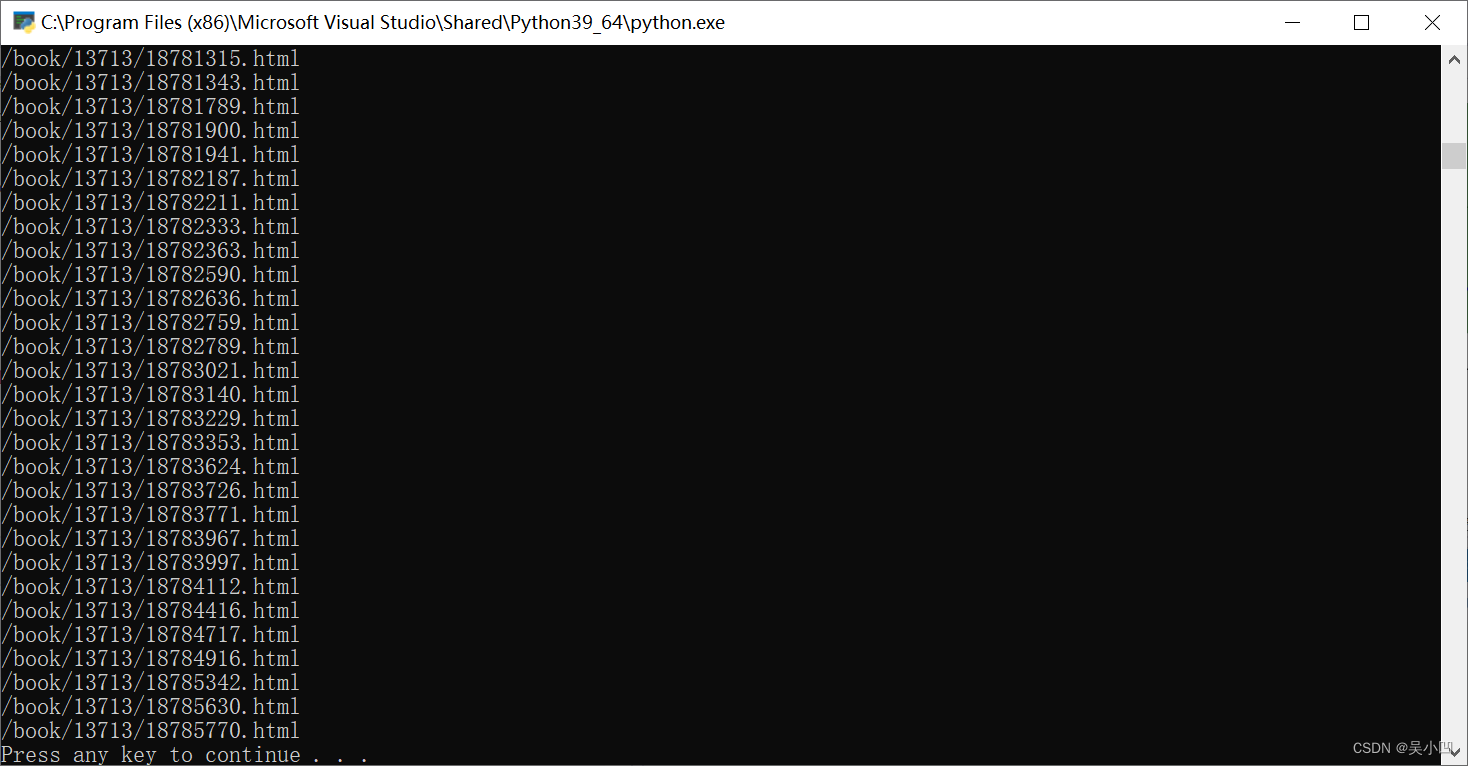
我会发现其中链接不全,我们直接通过这种形式肯定不行。我们查看网站网页的命名格式。
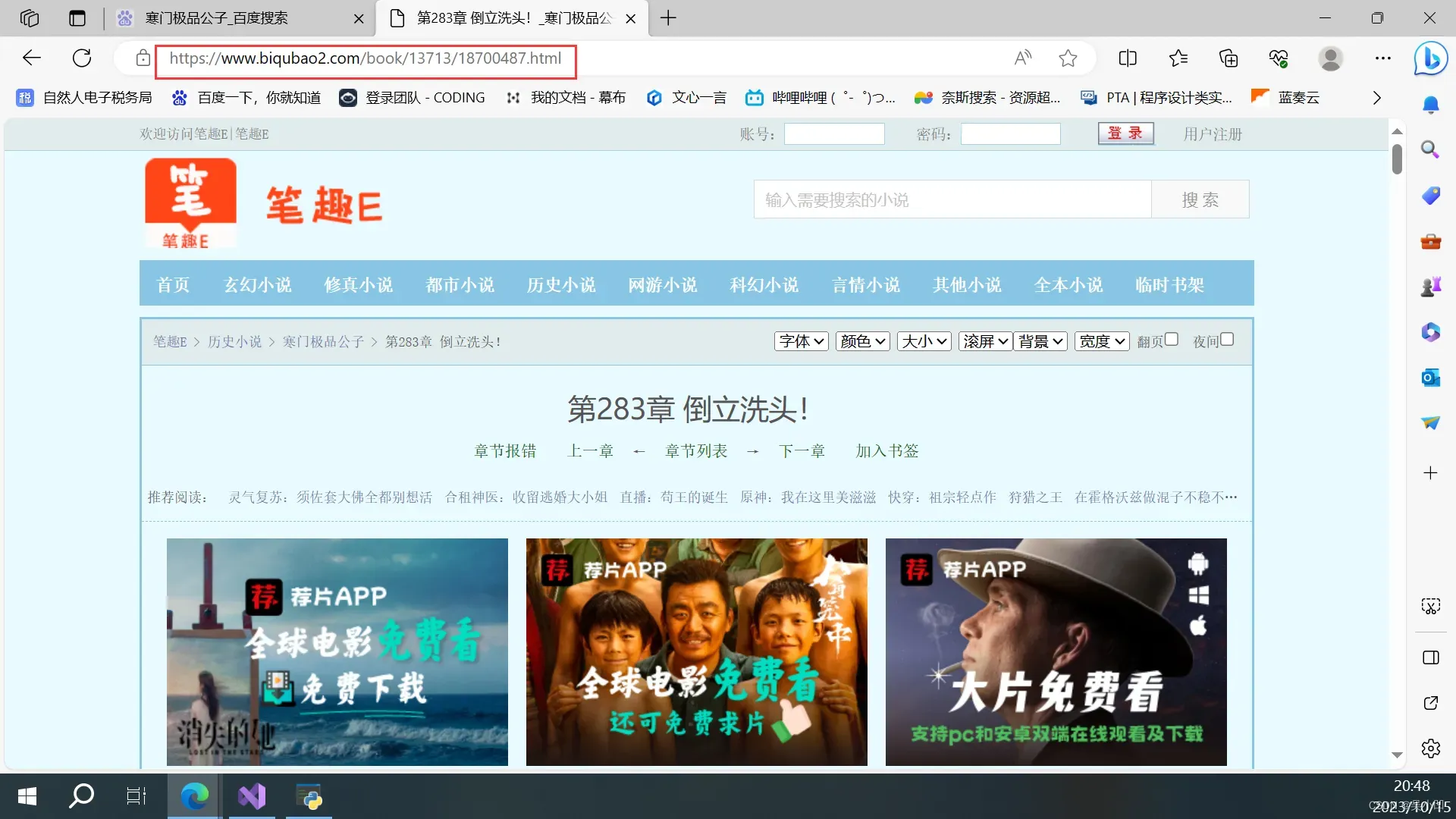
我们每读取一章就要如何通过这个网址来获取,而不是上面那个地方的网页。
我们需要将
/book/13713/18785770.html转化成下面这种模式
https://www.biqubao2.com/book/13713/18785770.html
我们发现前面缺少的其实就是我们刚开始的链接,我们使用字符拼接即可。
修改后代码如下所示。
# 获取小说的章节链接
x=1
for a in soup.links:
if '.html' in str(a) and ("第"+str(x)+"章" in str(a) or "弟"+str(x)+"章" in str(a)):
tp=str(a['href'])
print(url[:-12]+tp)
x=x+1运行代码结果:
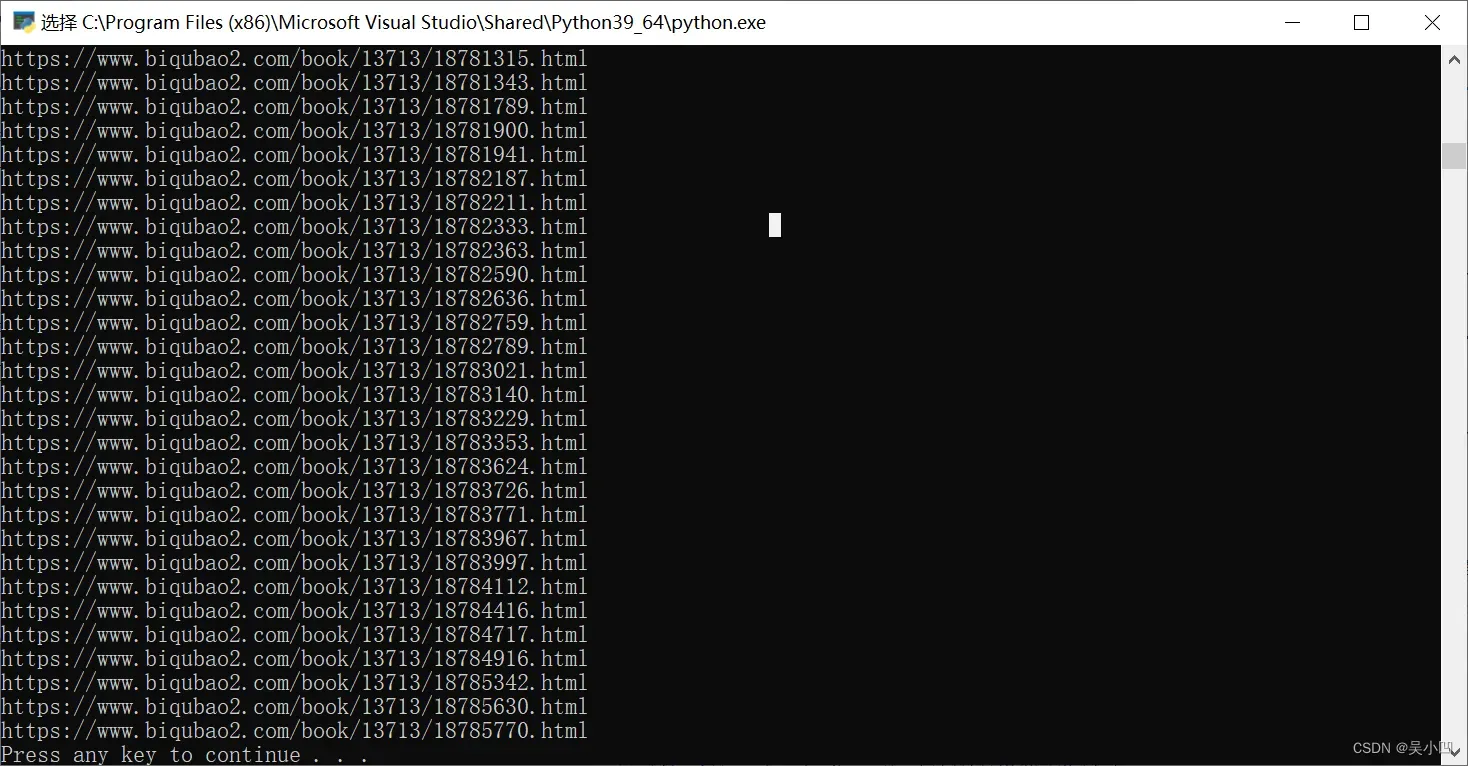
最后修改代码我们将链接和章节名称保存起来。
# 获取小说的章节链接
x=1
#链接
chapter_links=[]
#章节名称
catalogue=[]
for a in soup.links:
if '.html' in str(a) and ("第"+str(x)+"章" in str(a) or "弟"+str(x)+"章" in str(a)):
tp=str(a['href'])
chapter_links.append(url[:-12]+tp)
catalogue.append(a.text)
x=x+1
print(chapter_links)
print(catalogue)运行后发现链接和我们的标题都被保存下来了。
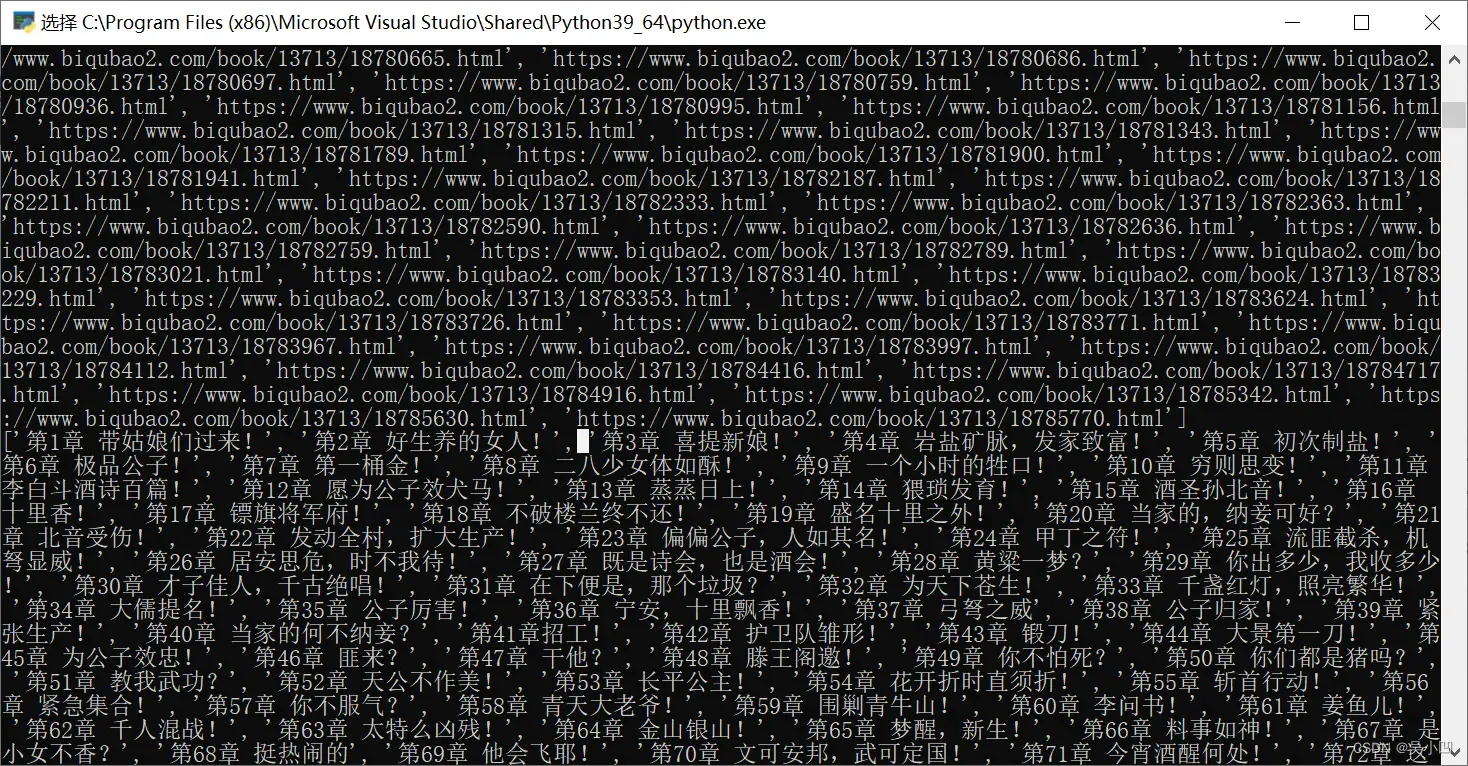
获取小说并保存:
写入以下代码
# 初始化一个计数器,用于跟踪章节的序号
i=0
# 对章节链接进行遍历
for link in chapter_links:
# 获取每一章的内容
chapter_response = requests.get(link)
# 设置响应对象的编码为utf-8,以正确处理获取到的文本数据
chapter_response.encoding = 'utf-8'
# 使用BeautifulSoup库解析获取到的响应文本,将其转化为一个BeautifulSoup对象
# BeautifulSoup是一个用于解析HTML和XML文档的Python库
chapter_soup = BeautifulSoup(chapter_response.text, 'html.parser')
# 在BeautifulSoup对象中寻找id为"myDiv"的div标签
# 这通常用于定位网页中的特定区域,以获取其内容
# 找到 id 为 "myDiv" 的 div 标签
div = chapter_soup.find('div', {'id': 'content'})
# 从找到的div标签中获取文本内容
chapter_text = div.get_text()
# 打开名为'novel.txt'的文件,以追加模式写入数据
# 如果文件不存在,将创建一个新文件
# 将章节内容写入文件
with open('寒门极品公子.txt', 'a', encoding='utf-8') as f:
# 将catalogue[i]的内容与一个换行符'\n'拼接,并写入到文件中
# catalogue可能是一个列表或其他类型的可索引对象,它包含了各章节的标题或其它标识信息
f.write(catalogue[i] + '\n')
# 将获取到的章节文本内容与一个换行符'\n'拼接,并写入到文件中
f.write(chapter_text + '\n')
# 打印出当前处理的章节编号和状态信息
print('第'+str(i)+'章下载完成')
time.sleep(5) # 延时5秒
# 当所有章节都处理完毕后,打印出小说下载完成的信息
print('小说下载完成。')代码的主要内容就是通过单个章节的链接获取到回复,之后找到居中格式的div ,获取其中的文本就是先说内容 这个时候我们将其写入到txt中,知道完成下载,其中延时是必须的,防止影响网站运行,从而导致踩缝纫机的风险。以下是运行结果。
最后等待下载完成即可.
最后贴一下完整源码。
# coding: utf-8
import time
import requests
from bs4 import BeautifulSoup
url='https://www.biqubao2.com/book/13713/'
# 请求的URL是'url',这里的'url'只是一个占位符,你需要把实际的URL替换进去
response = requests.get(url)
# 设置响应的编码为'utf-8',这样获取到的文本内容就会是'utf-8'编码
response.encoding = 'utf-8'
# 用BeautifulSoup库的'html.parser'解析器来解析从URL获取到的HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
#找到HTML文档中的所有<a>标签(即所有链接)
soup.links = soup.find_all('a')
# 获取小说的章节链接
x=1
#链接
chapter_links=[]
#章节名称
catalogue=[]
for a in soup.links:
if '.html' in str(a) and ("第"+str(x)+"章" in str(a) or "弟"+str(x)+"章" in str(a)):
tp=str(a['href'])
chapter_links.append(url[:-12]+tp)
catalogue.append(a.text)
x=x+1
i=0
for link in chapter_links:
# 获取每一章的内容
chapter_response = requests.get(link)
chapter_response.encoding = 'utf-8'
chapter_soup = BeautifulSoup(chapter_response.text, 'html.parser')
# 找到 id 为 "myDiv" 的 div 标签
div = chapter_soup.find('div', {'id': 'content'})
chapter_text = div.get_text()
# 将章节内容写入文件
with open('novel.txt', 'a', encoding='utf-8') as f:
f.write(catalogue[i] + '\n')
f.write(chapter_text + '\n')
i=i+1
print('第'+str(i)+'章下载完成')
time.sleep(5) # 延时5秒
print('小说下载完成。')好了,不多说了,我的小说下载好了,我看小说去了。
文章出处登录后可见!