《Causal Inference in Python: Applying Causal Inference in the Tech Industry》因果推断啃书系列
第1章 因果推断导论
第2章 随机实验与统计学回顾
第3章 图形化因果模型
第4章 线性回归的不合理有效性
第5章 倾向分
第6章 效果异质性
第7章 元学习器
第8章 双重差分
持续更新中:
第9章 综合控制
第10章 Geo实验与Switchback实验
第11章 不依从性与工具
第12章 后续行动
《Causal Inference in Python》第7章 元学习器
- 第7章 元学习器
- 7.1 离散干预的元学习器
- 7.1.1 T学习器(T-Learner)
- 7.1.2 X学习器(X-Learner)
- 7.2 连续干预的元学习器
- 7.2.1 S学习器(S-Learner)
- 7.2.2 双重/去偏机器学习(Double/Debiased Machine Learning)
- 7.2.2.1 使用双重机器学习获取CATE估算值
- 7.2.2.2 双重ML的直观可视化
- 7.3 要点总结
第7章 元学习器
回顾一下,在第三部分(第6、7章)中,你关注的是干预效果异质性,即识别单元对干预的不同响应。在这个框架下,你想估算的是:
或者在连续干预的场景下需要估算的是:。换句话说,你想知道单元对干预的敏感度。当无法干预每个人并且需要考虑干预优先次序时,这是非常有用的;例如,当你想要提供折扣但预算有限时。或者当干预效果对某些单元是正面的,但对其他单元是负面的。
之前,你已经了解了如何使用带有交互项的回归来获得条件平均干预效果(CATE)估计。现在,是时候将一些机器学习算法混合进来了。
元学习器(Metalearners)是一种利用现成的预测机器学习算法来逼近干预效果的简单方法。它们可用于估算ATE,但通常主要用于CATE估算,因为它们能够很好地处理高维数据。元学习器用于将预测模型循环用于因果推断。所有预测模型,如线性回归、增强决策树、神经网络或高斯过程,都可以按照本章描述的方法用于因果推断。因此,元学习器的成功在很大程度上取决于它内部使用的机器学习技术。通常情况下,你只需要尝试许多不同的方法,看看哪种方法效果最好。
7.1 离散干预的元学习器
假设你在一家网络零售商的营销团队工作,你的目标是找出哪些客户会接受营销邮件。你知道这封邮件有可能使客户消费更多,但你也知道有些客户不太喜欢收到营销邮件。为了解决这个问题,你打算估算邮件对客户未来购买量的条件平均干预效果。这样,你的团队就可以使用这个估算来决定给谁发送邮件。
与大多数商业应用一样,你有一堆历史数据,在这些数据中,你向客户发送了营销邮件。你可以利用这些丰富的数据来拟合你的条件平均干预效果(CATE)模型。除此之外,你还有一些来自实验的数据点,在这些实验中,营销邮件是随机发送的。由于数据量很少,你计划仅使用这些珍贵的数据来评估你的模型:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
import matplotlib
from fklearn.causal.validation.curves import relative_cumulative_gain_curve
from fklearn.causal.validation.auc import area_under_the_relative_cumulative_gain_curve
from cycler import cycler
color=['0.0', '0.4', '0.8']
default_cycler = (cycler(color=color))
linestyle=['-', '--', ':', '-.']
marker=['o', 'v', 'd', 'p']
plt.rc('axes', prop_cycle=default_cycler)
pd.set_option('display.max_columns', 8)
import pandas as pd
import numpy as np
data_biased = pd.read_csv("./data/email_obs_data.csv")
data_rnd = pd.read_csv("./data/email_rnd_data.csv")
print(len(data_biased), len(data_rnd))
data_rnd.head()
300000 10000
| mkt_email | next_mnth_pv | age | tenure | … | jewel | books | music_books_movies | health |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 244.26 | 61 | 1 | 1 | 0 | 0 | 2 |
| 1 | 0 | 29.67 | 36 | 1 | 1 | 0 | 2 | 2 |
| 2 | 0 | 11.73 | 64 | 0 | 0 | 1 | 0 | 1 |
| 3 | 0 | 41.41 | 74 | 0 | 0 | 4 | 1 | 0 |
| 4 | 0 | 447.89 | 59 | 0 | 1 | 1 | 2 | 1 |
随机数据和观测数据具有完全相同的列。干预变量是市场营销邮件(mkt_email),而你关心的结果是在收到邮件后的一个月内的购买量(next_mnth_pv)。除了这些列,数据还包含一系列协变量,如客户的年龄,首次在你的网站上购买的时间(tenure),以及他们在每个类别中购买的数量。这些协变量将决定你计划拟合的干预异质性。
为了简化CATE模型的开发,你可以创建变量来存储干预、结果和协变量,以及训练集和测试集,这样就可以直接构建几乎所有的元学习器:
y = "next_mnth_pv"
T = "mkt_email"
X = list(data_rnd.drop(columns=[y, T]).columns)
train, test = data_biased, data_rnd
准备工作都完成了,让我们看看第一个元学习器。
因果推断库
以下所有的元学习器在大多数因果推断库中都有实现。然而,由于它们的代码非常简单,我将不依赖外部库,而是教你如何从零开始构建它们。此外,在本文撰写之时,所有的因果推断库都处于早期阶段,这使得很难预测哪一个将在行业中占据主导地位。当然,这并不意味着你不应该自己去了解它们。我特别喜欢的两个是微软的econml和Uber的causalml。
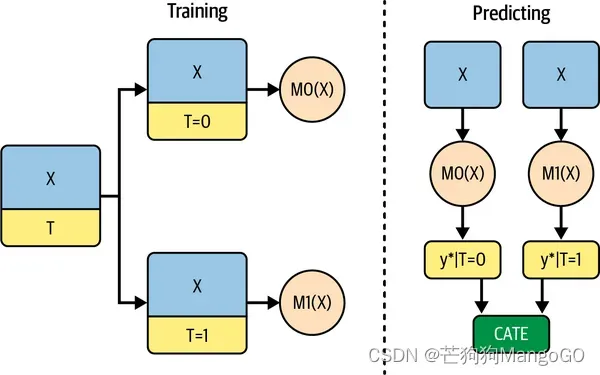
7.1.1 T学习器(T-Learner)
如果干预是类别型,那么你应该尝试的第一个学习器就是T学习器(T-Learner)。它非常直观,对于每种干预都拟合一个结果模型 ,以估算潜在结果
。在二元情况下,你只需要估算两个模型(因此名为T):
一旦有了这些模型,你可以对每种干预进行反事实预测,并得出如下CATE:
下图显示了此学习器的图解。
为了编码它,我将在结果模型中使用提升回归树(Boosted Regression Trees)。具体来说,我将使用LGBMRegressor,这是一种非常流行的回归模型。我也使用了默认参数,但如果你愿意的话,可以随意优化它:
from lightgbm import LGBMRegressor
np.random.seed(123)
m0 = LGBMRegressor()
m1 = LGBMRegressor()
m0.fit(train.query(f"{T}==0")[X], train.query(f"{T}==0")[y])
m1.fit(train.query(f"{T}==1")[X], train.query(f"{T}==1")[y]);
现在我有了两个模型,对测试集进行CATE预测就很容易了:
t_learner_cate_test = test.assign(
cate=m1.predict(test[X]) - m0.predict(test[X])
)
为了评估这个模型,我使用了相对累积增益曲线和该曲线下的面积,这两个概念你都在第6章中学习过。回想一下,这种评估方法只关心你是否正确地对客户进行了排序,从干预效果最好的客户到干预效果最差的客户:
gain_curve_test = relative_cumulative_gain_curve(t_learner_cate_test, T, y, prediction="cate")
auc = area_under_the_relative_cumulative_gain_curve(t_learner_cate_test, T, y, prediction="cate")
plt.figure(figsize=(10,4))
plt.plot(gain_curve_test, color="C0", label=f"AUC: {auc:.2f}")
plt.hlines(0, 0, 100, linestyle="--", color="black", label="Baseline")
plt.legend();
plt.title("T-Learner")
Text(0.5, 1.0, 'T-Learner')
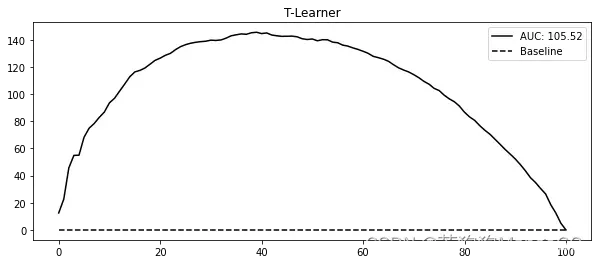
在这个数据集中,T学习器表现得非常好。从累积增益曲线的形状可以看出,它能够根据CATE对客户进行相当好的排序。
一般来说,由于其简单性,T学习器往往是合理的首选。但它存在一个潜在问题,可能会根据具体情况而显现:它容易受到正则化偏差的影响。
考虑这样一种情况,你有大量的未干预数据,而干预数据非常少。这在许多应用中是很常见的,因为干预往往很昂贵。现在假设结果Y中存在一些非线性,但干预效果是恒定的。这在下面的图像的第一个图中有所体现:
np.random.seed(123)
def g_kernel(x, c=0, s=0.05):
return np.exp((-(x-c)**2)/s)
n0 = 500
x0 = np.random.uniform(-1, 1, n0)
y0 = np.random.normal(0.3*g_kernel(x0), 0.1, n0)
n1 = 50
x1 = np.random.uniform(-1, 1, n1)
y1 = np.random.normal(0.3*g_kernel(x1), 0.1, n1)+1
df = pd.concat([pd.DataFrame(dict(x=x0, y=y0, t=0)), pd.DataFrame(dict(x=x1, y=y1, t=1))]).sort_values(by="x")
m0 = LGBMRegressor(min_child_samples=25)
m1 = LGBMRegressor(min_child_samples=25)
m0.fit(x0.reshape(-1, 1), y0)
m1.fit(x1.reshape(-1, 1), y1)
m0_hat = m0.predict(df.query("t==0")[["x"]])
m1_hat = m1.predict(df.query("t==1")[["x"]])
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 10))
ax1.scatter(x0, y0, alpha=0.5, label="T=0", marker=marker[0], color=color[1])
ax1.scatter(x1, y1, alpha=0.7, label="T=1", marker=marker[1], color=color[0])
ax1.plot(df.query("t==0")[["x"]], m0_hat, color="black", linestyle="solid", label="$\hat{\mu}_0$")
ax1.plot(df.query("t==1")[["x"]], m1_hat, color="black", linestyle="--", label="$\hat{\mu}_1$")
ax1.set_ylabel("Y")
ax1.set_xlabel("X")
ax1.legend(fontsize=14);
tau_0 = m1.predict(df.query("t==0")[["x"]]) - df.query("t==0")["y"]
tau_1 = df.query("t==1")["y"] - m0.predict(df.query("t==1")[["x"]])
ax2.scatter(df.query("t==0")[["x"]], tau_0, label="$\hat{\\tau_0}$", alpha=0.5, marker=marker[0], color=color[1])
ax2.scatter(df.query("t==1")[["x"]], tau_1, label="$\hat{\\tau_1}$", alpha=0.7, marker=marker[1], color=color[0])
ax2.plot(df[["x"]], m1.predict(df[["x"]]) - m0.predict(df[["x"]]), label="$\hat{CATE}$", color="black")
ax2.set_ylabel("Estimated Effect")
ax2.set_xlabel("X")
ax2.legend(fontsize=14)
<matplotlib.legend.Legend at 0x7fd8001506d0>
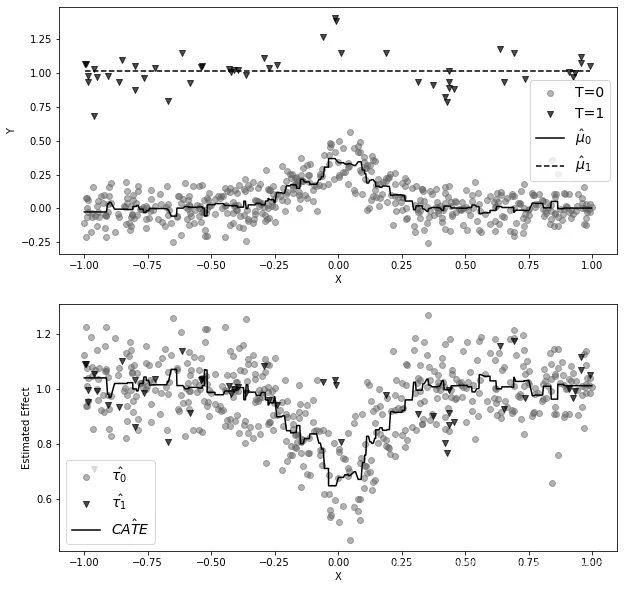
如果数据看起来像这样,与未干预的观测相比,干预的观测非常少,那么 模型最终可能会变得很简单,以避免过拟合。相比之下,
会更复杂一些,但没关系,因为数据的丰富性可以防止过拟合。重要的是,即使你为两个模型使用相同的超参数,这种情况也可能发生。例如,为了生成前面的图形,我使用了一个LGBM回归器,其中min_child_samples=25,其他所有参数都设置为默认。许多机器学习算法在处理较少的数据点时会自动进行正则化,就像min_child_samples的情况一样。它强制LGBM中的树在每个叶节点中至少有25个样本,如果样本量也很小,就会导致树变小。
从机器学习的角度来看,自我正则化是非常有意义的。如果你只有很少的数据,你应该使用更简单的模型。因此,前面图像中的两个模型都具有相当不错的预测性能,因为它们都针对它们所拥有的样本大小进行了优化。然而,如果你使用这些模型来计算CATE ,
的非线性减去
的线性将导致非线性的CATE(虚线减去实线),这是错误的,因为在这种情况下,CATE是恒定的且等于1。你可以在前面图像的第二个图中看到这种情况的发生。
在这里,未干预的模型可以捕捉到非线性关系,但干预的模型却不行,因为它被正则化了以处理小样本。当然,你可以对该模型使用较少的正则化,但这样就有过拟合的风险。左右为难了,那该怎么处理这个问题呢?这时X学习器就派上用场了。
另请参阅
这里概述的问题在Kunzel等人的论文《使用机器学习估计异质处理效应的元学习器》(Meta-learners for Estimating Heterogeneous Treatment Effects using Machine Learning)中得到了进一步探讨。
7.1.2 X学习器(X-Learner)
相比之前的学习器,X学习器(X-Learner)的解释要复杂得多,但其实现非常简单,所以如果你一开始没理解也不用担心。X学习器有两个阶段和一个倾向性评分模型。第一阶段与T学习器相同。首先,你将样本分为干预组和未干预组,并为每个组拟合一个模型:
现在,情况开始发生变化。对于第二阶段,你首先需要使用之前拟合的模型来填补缺失的潜在结果:
然后,你将再拟合两个模型来预测这些估算效果。这个想法是,模型的第二阶段将近似对照组和干预组的CATE:
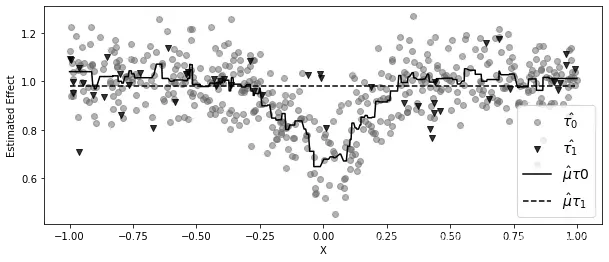
在之前的说明性数据中, 和
是第二张图中的数据点。在下图中,我再现了相同的数据,以及预测模型
和
。请注意,即使你有更多的对照数据,
也是错误的。这是因为它是使用
构建的,而
是在非常小的样本中拟合的。因此,由于
是错误的,
也将具有误导性。相比之下,
可能是正确的,因为
也是正确的,因为它是使用
模型生成的:
from sklearn.linear_model import LogisticRegression
np.random.seed(1)
mu_tau0 = LGBMRegressor(min_child_samples=25)
mu_tau1 = LGBMRegressor(min_child_samples=25)
mu_tau0.fit(df.query("t==0")[["x"]], tau_0)
mu_tau1.fit(df.query("t==1")[["x"]], tau_1)
mu_tau0_hat = mu_tau0.predict(df.query("t==0")[["x"]])
mu_tau1_hat = mu_tau1.predict(df.query("t==1")[["x"]])
plt.figure(figsize=(10, 4))
plt.scatter(df.query("t==0")[["x"]], tau_0, label="$\hat{\\tau_0}$", alpha=0.5, marker=marker[0], color=color[1])
plt.scatter(df.query("t==1")[["x"]], tau_1, label="$\hat{\\tau_1}$", alpha=0.8, marker=marker[1], color=color[0])
plt.plot(df.query("t==0")[["x"]], mu_tau0_hat, color="black", linestyle="solid", label="$\hat{\mu}\\tau 0$")
plt.plot(df.query("t==1")[["x"]], mu_tau1_hat, color="black", linestyle="dashed", label="$\hat{\mu}\\tau_1$")
plt.ylabel("Estimated Effect")
plt.xlabel("X")
plt.legend(fontsize=14)
<matplotlib.legend.Legend at 0x7fd7d05c3110>
总结来说,你有一个模型是错误的,因为你错误地估算了干预效果;而另一个模型是正确的,因为你正确地估算了那些值。现在,你需要一种方法把这两个模型结合起来,同时给予正确模型更大的权重。为此,你可以使用倾向得分模型。有了它,你可以将两个第二阶段模型结合如下:
在这个例子中,由于干预单元非常少, 非常小,这使得错误CATE模型
的权重非常小。相比之下,
接近1,所以你会给正确CATE模型
更多的权重。更一般地说,使用倾向得分的加权平均将有利于使用更多数据训练的
模型得到的干预效果估算。
下图显示了由X学习器给出的CATE估算,以及分配给每个数据点的权重。注意看它是如何在实质上丢弃错误数据的:
plt.figure(figsize=(10, 4))
ps_model = LogisticRegression(penalty="none")
ps_model.fit(df[["x"]], df["t"])
ps = ps_model.predict_proba(df[["x"]])[:, 1]
cate = ((1-ps)*mu_tau1.predict(df[["x"]]) +
ps*mu_tau0.predict(df[["x"]]))
plt.scatter(df.query("t==0")[["x"]], tau_0, label="$\hat{\\tau_0}$", alpha=0.5, s=100*(ps[df["t"]==0]), marker=marker[0], color=color[1])
plt.scatter(df.query("t==1")[["x"]], tau_1, label="$\hat{\\tau_1}$", alpha=0.5, s=100*(1-ps[df["t"]==1]), marker=marker[1], color=color[0])
plt.plot(df[["x"]], cate, label="x-learner", color="black")
plt.ylabel("Estimated Effect")
plt.xlabel("X")
plt.legend(fontsize=14)
<matplotlib.legend.Legend at 0x7fd822807f50>
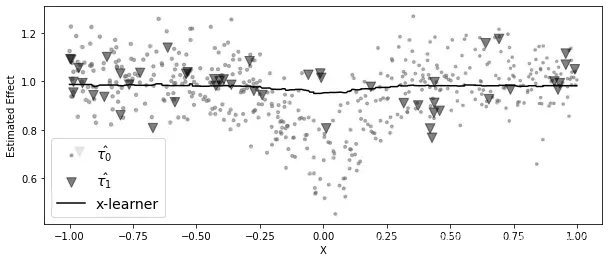
如你所见,与T学习器相比,X学习器在纠正非线性的错误CATE估算方面做得更好。一般来说,当干预组比其他组大得多时,X学习器的性能会更好。
我知道这可能有很多东西需要消化,但希望当你查看代码时,会对其更加清楚。下图总结了这个学习者。
你可以尝试的另一件事是领域适应学习器。它是x学习器的一种,但使用倾向得分模型估算 的权重设置为
。
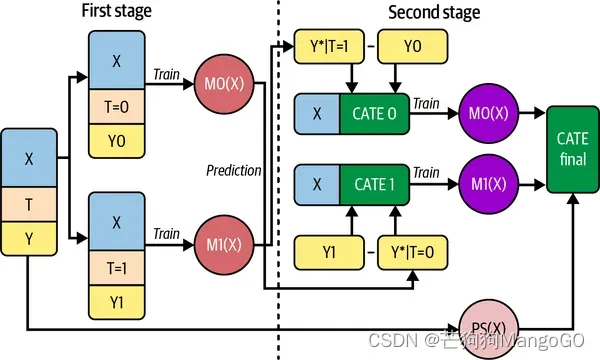
让我们看看如何编写这些代码。第一阶段和T学习器完全一样。如果你计划使用倾向得分进行领域适应,需要使用 重新加权训练样本,因此现在也需要拟合该倾向得分:
from sklearn.linear_model import LogisticRegression
from lightgbm import LGBMRegressor
# propensity score model
ps_model = LogisticRegression(penalty='none')
ps_model.fit(train[X], train[T])
# first stage models
train_t0 = train.query(f"{T}==0")
train_t1 = train.query(f"{T}==1")
m0 = LGBMRegressor()
m1 = LGBMRegressor()
np.random.seed(123)
m0.fit(train_t0[X], train_t0[y],
sample_weight=1/ps_model.predict_proba(train_t0[X])[:, 0])
m1.fit(train_t1[X], train_t1[y],
sample_weight=1/ps_model.predict_proba(train_t1[X])[:, 1]);
接下来,你需要预测干预效果,并在这些预测效果上拟合第二阶段模型:
# second stage
tau_hat_0 = m1.predict(train_t0[X]) - train_t0[y]
tau_hat_1 = train_t1[y] - m0.predict(train_t1[X])
m_tau_0 = LGBMRegressor()
m_tau_1 = LGBMRegressor()
np.random.seed(123)
m_tau_0.fit(train_t0[X], tau_hat_0)
m_tau_1.fit(train_t1[X], tau_hat_1);
最后,您可以使用倾向得分模型将第二阶段模型的预测结合起来,以获得CATE。这些都可以在测试集上进行估算:
# estimate the CATE
ps_test = ps_model.predict_proba(test[X])[:, 1]
x_cate_test = test.assign(
cate=(ps_test*m_tau_0.predict(test[X]) +
(1-ps_test)*m_tau_1.predict(test[X])
)
)
我们来看看X学习器是如何用累积增益来表示的。在这个数据集中,干预组和组几乎是相同的大小,所以不要期望有巨大的差异。X学习器试图纠正的问题可能在这里没有表现出来:
gain_curve_test = relative_cumulative_gain_curve(x_cate_test, T, y, prediction="cate")
auc = area_under_the_relative_cumulative_gain_curve(x_cate_test, T, y, prediction="cate")
plt.figure(figsize=(10, 4))
plt.plot(gain_curve_test, color="C0", label=f"AUC: {auc:.2f}")
plt.hlines(0, 0, 100, linestyle="--", color="black", label="Baseline")
plt.legend();
plt.title("X-Learner")
Text(0.5, 1.0, 'X-Learner')
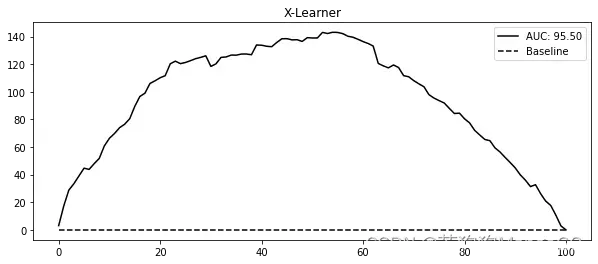
正如预期的那样,X学习器的表现与T学习器的表现没有太大区别。事实上,就曲线下的面积而言,它的表现略逊于T学习器。请记住,这些学习器的性能是取决于情景的。就像我之前说的,在这些具体的数据中,干预组和对照组都有足够大的样本量,这样就不会遇到X学习器试图解决的问题。这可能就是这两个模型性能相似的原因。
7.2 连续干预的元学习器
当干预是连续的,情况会变得有些复杂,对于元学习器来说也是如此。以之前章节的数据为例,其中包含了三家餐馆三年的数据。餐馆连锁店在其六家餐馆中随机提供了折扣,现在想知道哪些日期提供更多折扣最好。要回答这个问题,就需要了解顾客在哪些日期对折扣更敏感(对价格更敏感)。如果餐馆连锁店能够了解这些信息,就能更好地决定何时提供更多或更少的折扣。
可见,这是一个需要估算CATE的问题。如果成功估算出CATE,公司就可以利用CATE预测来决定折扣政策——预测的CATE越高,顾客对折扣就越敏感,因此折扣也应该越高:
data_cont = pd.read_csv("./data/discount_data.csv")
data_cont.head()
| rest_id | day | month | weekday | … | is_nov | competitors_price | discounts | sales | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2016-01-01 | 1 | 4 | … | False | 2.88 | 0 | 79.0 |
| 1 | 0 | 2016-01-02 | 1 | 5 | … | False | 2.64 | 0 | 57.0 |
| 2 | 0 | 2016-01-03 | 1 | 6 | … | False | 2.08 | 5 | 294.0 |
| 3 | 0 | 2016-01-04 | 1 | 0 | … | False | 3.37 | 15 | 676.5 |
| 4 | 0 | 2016-01-05 | 1 | 1 | … | False | 3.79 | 0 | 66.0 |
在这个数据中,折扣是干预,销售是结果。还有一些生成的日期特征,如月份、一周中的哪一天、是否为节假日等等。由于这里的目标是预测CATE,因此最好将数据集分为训练集和测试集。在这里,可以利用时间维度来创建这些集合:
train = data_cont.query("day<'2018-01-01'")
test = data_cont.query("day>='2018-01-01'")
现在你已经熟悉了数据,让我们看看哪些元学习器可以处理这种连续干预。
7.2.1 S学习器(S-Learner)
你应该尝试的第一个学习器是S学习器,是最简单的学习器。你将使用单个(因此是S)机器学习模型 来估算:
为此,你将在模型中包含干预作为特征,该模型试图预测结果 。就是这样:
X = ["month", "weekday", "is_holiday", "competitors_price"]
T = "discounts"
y = "sales"
np.random.seed(123)
s_learner = LGBMRegressor()
s_learner.fit(train[X+[T]], train[y]);
但是这个模型不直接输出干预效果。相反,它输出的是反事实预测。也就是说,它可以在不同的干预方案下做出预测。如果干预是二元的,这个模型仍然有效,并且测试组和对照组之间的预测差异将是CATE估算值:
下图为S学习器的一个图解。
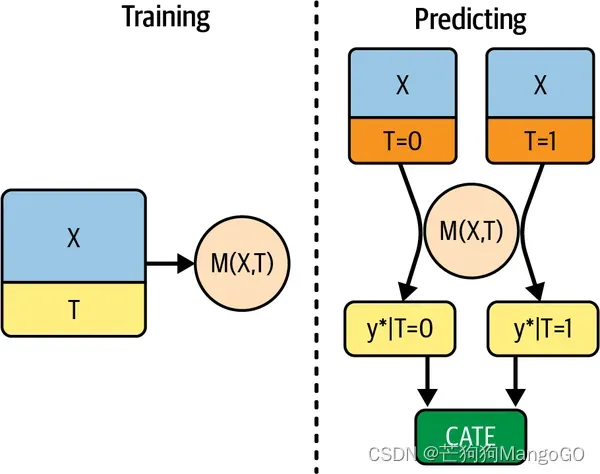
在连续的情况下,你需要做一些额外的工作。首先,你需要定义一个干预网格。例如,折扣从零到大约40%,所以你可以尝试[0,10,20,30,40]的网格。接下来,你需要扩展你想要进行预测的数据,以便在网格中的每个干预值下,每条数据都能得到一份拷贝。我找到的最简单的方法是交叉连接一个数据框和网格值到我想要进行预测的数据中,即测试集。在pandas中,你可以通过一个常量键进行交叉连接。这将复制原始数据中的每一行,只改变干预值。最后,你可以使用你拟合的S学习器在这个扩展数据中进行反事实预测。下面是一段简单的代码来完成所有这些工作:
t_grid = pd.DataFrame(dict(key=1,
discounts=np.array([0, 10, 20, 30, 40])))
test_cf = (test
.drop(columns=["discounts"])
.assign(key=1)
.merge(t_grid)
# make predictions after expansion
.assign(sales_hat = lambda d: s_learner.predict(d[X+[T]])))
test_cf.head(8)
| rest_id | day | month | weekday | sales | key | discounts | sales_hat | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2018-01-01 | 1 | 0 | 251.5 | 1 | 0 | 67.957972 |
| 1 | 0 | 2018-01-01 | 1 | 0 | 251.5 | 1 | 10 | 444.245941 |
| 2 | 0 | 2018-01-01 | 1 | 0 | 251.5 | 1 | 20 | 793.045769 |
| 3 | 0 | 2018-01-01 | 1 | 0 | 251.5 | 1 | 30 | 1279.640793 |
| 4 | 0 | 2018-01-01 | 1 | 0 | 251.5 | 1 | 40 | 1512.630767 |
| 5 | 0 | 2018-01-02 | 1 | 1 | 541.0 | 1 | 0 | 65.672080 |
| 6 | 0 | 2018-01-02 | 1 | 1 | 541.0 | 1 | 10 | 495.669220 |
| 7 | 0 | 2018-01-02 | 1 | 1 | 541.0 | 1 | 20 | 1015.401471 |
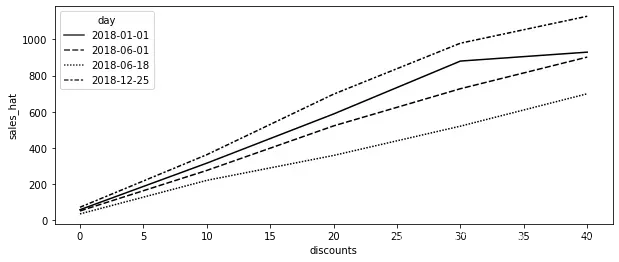
在前一步中,你实质上估算了每个单元的干预响应函数 的粗略版本。你甚至可以为少数单元(在我们的例子中是日期)绘制这条曲线,看看它们是什么样的。在下面的图中可以看到,与2018年6月18日这样的日子相比,2018年12月25日(也就是圣诞节)的估算响应函数更陡峭。这意味着你的模型学习到,与六月的那天相比,顾客在圣诞节对折扣更敏感:
days = ["2018-12-25", "2018-01-01", "2018-06-01", "2018-06-18"]
plt.figure(figsize=(10, 4))
sns.lineplot(data=test_cf.query("day.isin(@days)").query("rest_id==2"),
palette="gray",
y="sales_hat",
x="discounts",
style="day");
这些反事实预测是否正确是另一个问题。要评估这个模型,你首先需要意识到你还没有CATE预测。这意味着你在第6章中学到的评估方法不能在这里使用。为了获得CATE预测,你必须以某种方式将单元级曲线概括为表示干预效果的单个数字。令人惊讶的是(或者不是那么令人惊讶)线性回归是实现这一目标的好方法。简单地说,你可以为每个单元运行一个回归,并提取干预上的斜率参数作为你的CATE估计。
因为你关心的只是斜率参数,所以可以更高效地做到这一点,使用单变量线性回归斜率的公式:
让我们看一下实现这一点的代码。首先,我定义了一个函数,用于将每条个体曲线汇总为一个斜率参数。然后,我通过餐馆ID和日期对扩展后的测试数据进行分组,并对每个单元应用斜率函数。这得到了一个带有索引rest_id和day的pandas序列(pandas series),我将其命名为cate。最后,我将该序列加入到原始测试集(不是扩展后的测试集)中,以获取测试集中每家餐馆每天的CATE预测值:
from toolz import curry
@curry
def linear_effect(df, y, t):
return np.cov(df[y], df[t])[0, 1]/df[t].var()
cate = (test_cf
.groupby(["rest_id", "day"])
.apply(linear_effect(t="discounts", y="sales_hat"))
.rename("cate"))
test_s_learner_pred = test.set_index(["rest_id", "day"]).join(cate)
test_s_learner_pred.head()
| month | weekday | weekend | competitors_price | discounts | sales | cate | ||
|---|---|---|---|---|---|---|---|---|
| rest_id | day | |||||||
| 0 | 2018-01-01 | 1 | 0 | False | 4.92 | 5 | 251.5 | 37.247404 |
| 0 | 2018-01-02 | 1 | 1 | False | 3.06 | 10 | 541.0 | 40.269854 |
| 0 | 2018-01-03 | 1 | 2 | False | 4.61 | 10 | 431.0 | 37.412988 |
| 0 | 2018-01-04 | 1 | 3 | False | 4.84 | 20 | 760.0 | 38.436815 |
| 0 | 2018-01-05 | 1 | 4 | False | 6.29 | 0 | 78.0 | 31.428603 |
现在你已经有了一个CATE预测,你可以使用你从上一章学到的方法来验证你的模型。在这里,让我们坚持使用累积收益:
from fklearn.causal.validation.auc import area_under_the_relative_cumulative_gain_curve
from fklearn.causal.validation.curves import relative_cumulative_gain_curve
gain_curve_test = relative_cumulative_gain_curve(test_s_learner_pred, T, y, prediction="cate")
auc = area_under_the_relative_cumulative_gain_curve(test_s_learner_pred, T, y, prediction="cate")
plt.figure(figsize=(10, 4))
plt.plot(gain_curve_test, color="C0", label=f"AUC: {auc:.2f}")
plt.hlines(0, 0, 100, linestyle="--", color="black", label="Baseline")
plt.legend();
plt.title("S-Learner")
Text(0.5, 1.0, 'S-Learner')
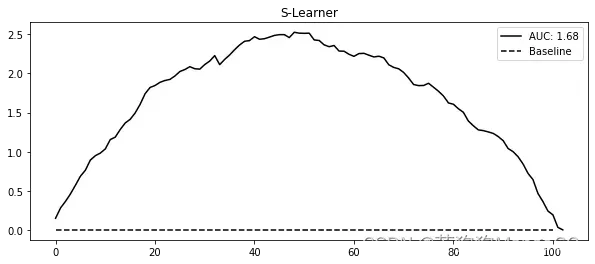
从累积增益可以看出,尽管S学习器简单,但在这个数据集上的表现还可以。再次提醒,这个表现与这个数据集的特殊性有很大关系。这是一个特别简单的数据集,因为你有大量的随机数据,甚至可以用它们来训练你的学习器。在实践中,我发现S学习器是处理任何因果问题的不错的首要选择,这主要是因为它的简单性。即使没有随机数据进行训练,S学习器也能表现得还可以。此外,S学习器支持二元和连续干预,使其成为一个优秀的默认选择。
S学习器的主要缺点是它倾向于将干预效果偏向零。由于S学习器通常采用的是正则化机器学习模型,这种正则化可能会限制干预效果的估算。
下面的图表复制了Chernozhukov等人论文《Double/Debiased/Neyman Machine Learning of Treatment Effects》中的一个结果。为了绘制这张图,我模拟了包含20个协变量和二元干预的数据,真实ATE为1。然后,我试图使用S学习器来估算ATE。我重复了500次模拟和估算步骤,并将估算ATE的分布与真实ATE一起绘制:
np.random.seed(123)
def sim_s_learner_ate():
n = 10000
nx = 20
X = np.random.normal(0, 1, (n, nx))
coefs_y = np.random.uniform(-1, 1, nx)
coefs_t = np.random.uniform(-0.5, 0.5, nx)
ps = 1/(1+np.exp(-(X.dot(coefs_t))))
t = np.random.binomial(1, ps)
te = 1
y = np.random.normal(t*te + X.dot(coefs_y), 1)
s_learner = LGBMRegressor(max_depth=5, n_jobs=4)
s_learner.fit(np.concatenate([X, t.reshape(-1, 1)], axis=1), y);
ate_hat = (s_learner.predict(np.concatenate([X, np.ones((n, 1))], axis=1))
- s_learner.predict(np.concatenate([X, np.zeros((n, 1))], axis=1))).mean()
return ate_hat
ates = [sim_s_learner_ate() for _ in range(500)]
plt.figure(figsize=(10, 4))
plt.hist(ates, alpha=0.5, bins=20, label="Simulations")
plt.vlines(1, 0, 70, label="True ATE")
plt.legend()
plt.xlabel("ATE")
plt.title("500 Simulations")
Text(0.5, 1.0, '500 Simulations')
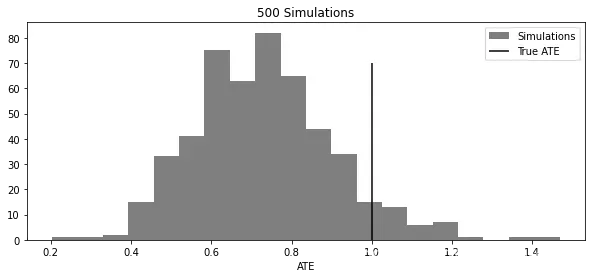
你可以看到,估算ATE的分布集中在真实ATE的左侧,偏向零。换句话说,真实的因果效果经常大于估算的因果效果。
更糟糕的是,如果干预相对于其他协变量在解释结果时的影响非常微弱,S学习器可能会完全丢弃干预变量。请注意,这与你选择的机器学习模型高度相关。正则化越大,问题就越大。切尔诺霍夫等人同一篇论文中提出的一种解决方法是双重/去偏机器学习,或称R学习器。
7.2.2 双重/去偏机器学习(Double/Debiased Machine Learning)
双重/去偏机器学习或直接称为R-学习者可以被视为Frisch-Waugh-Lovell定理的强化版本。这个想法非常简单——在构建结果和干预残差时使用机器学习模型:
其中 用于估算
,
用于估算
。
由于机器学习模型可以超级灵活,它们更适合在估计 和
残差时捕获交互和非线性关系,同时仍然保持FWL风格的正交化。这意味着你不必对协变量
和结果
之间的关系,以及协变量和干预之间的关系做出任何参数假设,以获得正确的干预效果。只要你没有未观察到的混淆因子,你可以通过以下正交化过程来恢复ATE:
- 使用一个柔性ML回归模型
根据特征
估算结果
。
- 使用一个柔性ML回归模型
根据特征
。
- 获取残差
和
。
- 将结果残差在干预残差上进行回归,
,其中
为因果参数ATE,可以用OLS等方法进行估计。
你通过ML获得的力量在于其灵活性。ML功能强大,能够捕捉麻烦的关系中的复杂功能形式。但这种灵活性也是麻烦的根源,因为这意味着你现在必须考虑过拟合的可能性。Chernozhukov等人的论文更深入、严谨地解释了过拟合是如何导致麻烦的,我强烈建议你查阅一下。但在这里,我将继续以更直观的解释来进行阐述。
为了看清问题所在,假设你的 模型过拟合了,其结果是,残差
会比它应有的值小。这也意味着,
在捕获
和
之间的关系之外,还捕获了其他关系。“其他关系”中,有一部分是
和
之间的关系,如果
捕获了其中一部分,那么残差回归就会偏向零。换句话说,
正在捕获因果关系,而没有将其留给最终的残差回归。
现在,为了看清过拟合 的问题,请注意,它得到的
的方差会多于应有的方差。因此,干预的残差将比应有的方差小。如果干预的方差较小,最终估算器的方差就会高。这就好像几乎每个人都接受了相同的干预,或者违反了正值性假设。如果每个人的干预水平几乎相同,就很难估算在不同干预下会发生什么。
以上就是使用机器学习模型时可能遇到的问题。但是,如何解决这些问题呢?答案就在于交叉预测和折外(out-of-fold)残差。而不是获得用于拟合模型的相同数据的残差,你可以将数据划分为K个折,在K-1个折中估算模型,并获得剩余的那个折的残差。重复相同的程序K次,以获得整个数据集的残差。使用这种方法,即使模型确实过拟合,也不会人为地将残差推到零。
这在理论上看起来很复杂,但实际上编写代码非常容易。你可以使用sklearn的cross_val_predict函数从任何机器学习模型中获得折外预测。下面仅使用几行代码获得这些残差:
from sklearn.model_selection import cross_val_predict
X = ["month", "weekday", "is_holiday", "competitors_price"]
T = "discounts"
y = "sales"
debias_m = LGBMRegressor()
denoise_m = LGBMRegressor()
t_res = train[T] - cross_val_predict(debias_m,train[X],train[T],cv=5)
y_res = train[y] - cross_val_predict(denoise_m,train[X],train[y],cv=5)
如果你只关心ATE,你可以简单地在干预的残差上对结果的残差进行回归(不要相信那些标准误差,因为它们不能解释估算残差的方差):
import statsmodels.api as sm
sm.OLS(y_res, t_res).fit().summary().tables[1]
| coef | std err | t | P|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| discounts | 31.4615 | 0.151 | 208.990 | 0.000 | 31.166 | 31.757 |
但在这一章,我们关注的是CATE。那么,如何用双重机器学习来得到它呢?
7.2.2.1 使用双重机器学习获取CATE估算值
要从双重机器学习模型获得CATE预测,需要进行一些适配。本质上,您需要允许因果参数 根据单元的协变量进行变化:
其中, 和
是分别从特征
预测结果和干预的模型。如果你重新排列这些项,就可以分离出误差:
这非常棒,因为现在你可以将其称为因果损失函数(causal loss function)。这意味着,如果使这个损失的平方最小化,你将估算出 的期望值,这就是你想要的CATE:
这种损失也称为R损失(R-Loss),因为它是R学习器最小化时的损失。好的,那么如何最小化这个损失函数呢?实际上有多种方法,但这里你将看到最简单的方法。首先,为了整理技术符号,让我们使用干预和结果的残差版本重写损失函数:
最后,你可以通过一些代数运算将 从括号中取出,并将
在损失函数的平方部分中独立出来:
将前述损失最小化等同于将括号内的内容最小化,但需要使用 对每个项进行加权。任何预测性机器学习模型都可以做到这一点。
但稍等片刻,你之前在第6章中已经看过这个了!这确实是你用来计算均方误差的变换目标。那么,我之前是让你相信我的话,但现在我会告诉你为什么它有效。同样,这个的编码也非常简单:
y_star = y_res/t_res
w = t_res**2
cate_model = LGBMRegressor().fit(train[X], y_star, sample_weight=w)
test_r_learner_pred = test.assign(cate = cate_model.predict(test[X]))
我对这个学习器真正喜欢的地方在于,它直接输出CATE估算值。使用S学习器时,你必须采取所有那些额外的步骤,而现在不用了。此外,正如你在下图中看到的,在按照累积增益来评估CATE的顺序方面,它做得相当不错:
gain_curve_test = relative_cumulative_gain_curve(test_r_learner_pred, T, y, prediction="cate")
auc = area_under_the_relative_cumulative_gain_curve(test_r_learner_pred, T, y, prediction="cate")
plt.figure(figsize=(10, 4))
plt.plot(gain_curve_test, color="C0", label=f"AUC: {auc:.2f}")
plt.hlines(0, 0, 100, linestyle="--", color="black", label="Baseline")
plt.legend();
plt.title("R-Learner")
Text(0.5, 1.0, 'R-Learner')
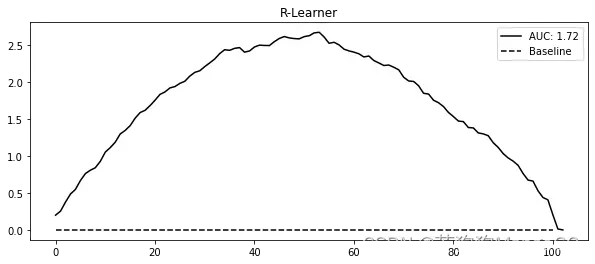
在这个例子中,双重/去偏ML与S学习器的性能相当相似。这可能是因为干预足够强,以至于S学习器中的ML模型为其分配了很高的重要性。此外,干预是随机化的,这意味着双重ML中的 模型并没有真正起作用。因此,为了更好地理解双重ML的真正力量,让我们来看一个更具说明性的例子。
7.2.2.2 双重ML的直观可视化
考虑以下模拟数据。其中,你有两个协变量: 是混淆因子,
不是。而且,
驱动效果异质性。
只有三个值:1、2和3。每个值的CATE分别为2、3和4,因为干预效果由
给出。此外,由于
均匀分布,ATE只是CATE的简单平均值,即3。最后,请注意混淆因子
如何非线性地影响干预和结果:
np.random.seed(123)
n = 5000
x_h = np.random.randint(1, 4, n)
x_c = np.random.uniform(-1, 1, n)
t = np.random.normal(10 + 1*x_c + 3*x_c**2 + x_c**3, 0.3)
y = np.random.normal(t + x_h*t - 5*x_c - x_c**2 - x_c**3, 0.3)
df_sim = pd.DataFrame(dict(x_h=x_h, x_c=x_c, t=t, y=y))
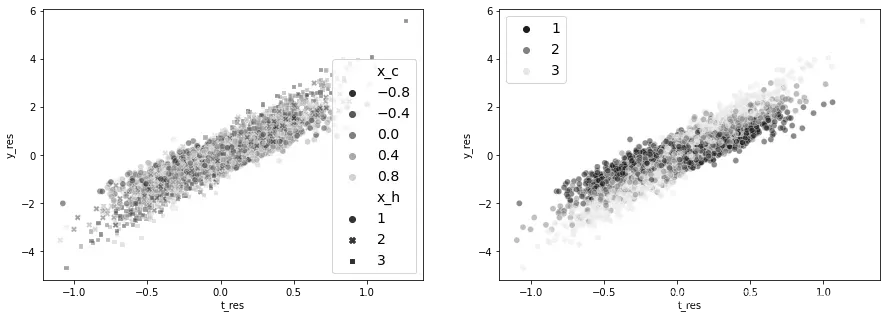
下面是这份数据的可视化图。每一个点集合是由 定义的一个分组。颜色标记代表混淆因子
的值。注意其中的非线性形状:
import matplotlib
plt.figure(figsize=(10, 5))
cmap = matplotlib.colors.LinearSegmentedColormap.from_list("", ["0.1","0.5","0.9"])
sns.scatterplot(data=df_sim, y="y", x="t", hue="x_c", style="x_h", palette=cmap);
plt.legend(fontsize=14)
<matplotlib.legend.Legend at 0x7fd822c9ce90>

好的,现在让我们来看看双重ML如何处理这些数据。首先,我们需要得到残差 和
。由于这里的数据不是很多,我们限制ML模型的树的最大深度为3。在去偏模型中,我只包含
,因为它是唯一的混淆因子。去噪模型则包含两个协变量,因为这两个协变量都会导致结果,包含它们将减少噪音:
debias_m = LGBMRegressor(max_depth=3)
denoise_m = LGBMRegressor(max_depth=3)
t_res = cross_val_predict(debias_m, df_sim[["x_c"]], df_sim["t"],
cv=10)
y_res = cross_val_predict(denoise_m, df_sim[["x_c", "x_h"]],df_sim["y"],
cv=10)
df_res = df_sim.assign(
t_res = df_sim["t"] - t_res,
y_res = df_sim["y"] - y_res
)
当你得到这些残差后,由 引起的混淆偏差应该就消除了。尽管它是非线性的,但我们的ML模型应该能够捕捉这种非线性并消除所有偏差。如此,如果你对
进行简单的
回归,它应该会给出正确的ATE:
import statsmodels.formula.api as smf
smf.ols("y_res~t_res", data=df_res).fit().params["t_res"]
3.045230146006292
接下来,让我们关注CATE的估算。下图中左边展示了残差之间的关系,并通过混淆因子 对每个点进行颜色标记。请注意,这个图的颜色中没有出现任何模式。这表明所有由于
引起的混淆都被消除了。数据看起来就像干预是被随机分配的。
右边的图通过 (驱动干预异质性的特征)对相同的关系进行颜色标记。颜色最深的点(
)似乎对干预不太敏感,如所示的较低的斜率。相比之下,颜色较浅的点(
)似乎对干预更敏感。看着这个图,你能想到一种方法来提取这些敏感性吗?
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
ax1 = sns.scatterplot(data=df_res, y="y_res", x="t_res", hue="x_c", style="x_h", alpha=0.5, ax=ax1, palette=cmap)
h,l = ax1.get_legend_handles_labels()
ax1.legend(fontsize=14)
sns.scatterplot(data=df_res, y="y_res", x="t_res", hue="x_h", ax=ax2, alpha=0.5, palette=cmap)
ax2.legend(fontsize=14)
<matplotlib.legend.Legend at 0x7fd823afbb50>
为了回答这个问题,请注意两个残差都以零为中心。这意味着决定由 定义的所有组的斜率的线应该穿过零点。现在,回忆一下,线的斜率可以用两点确定为
。但是,由于这条线的截距应该为零,这就简化为
。因此,你可以将双重ML的
目标视为通过该点且截距为零的线的斜率。
但有一个问题。 和
的均值都接近零。你知道除以一个接近零的数字时会发生什么吗?没错,它可能非常不稳定,给你带来大量的噪音。这就是权重
发挥作用的地方。通过给予高
值的点更多的重要性,你实际上是在关注方差较低的区间。为了验证这是否有效,你可以计算每个
值的
的平均值,按
加权。对于
,这将使你非常接近真实的CATE值2、3和4:
df_star = df_res.assign(
y_star = df_res["y_res"]/df_res["t_res"],
weight = df_res["t_res"]**2,
)
for x in range(1, 4):
cate = np.average(df_star.query(f"x_h=={x}")["y_star"],
weights=df_star.query(f"x_h=={x}")["weight"])
print(f"CATE x_h={x}", cate)
CATE x_h=1 2.019759619990067
CATE x_h=2 2.974967932350952
CATE x_h=3 3.9962382855476957
你还可以从 对
的图中看到我所描述的内容。在这里,我再次使用
进行颜色标记,但现在我增加了等于
的权重。我还将每个组的平均估算CATE作为水平线包括在内:
plt.figure(figsize=(10, 6))
sns.scatterplot(data=df_star, palette=cmap,
y="y_star", x="t_res", hue="x_h", size="weight", sizes=(1, 100)),
plt.hlines(np.average(df_star.query("x_h==1")["y_star"], weights=df_star.query("x_h==1")["weight"]),
-1, 1, label="x_h=1", color="0.1")
plt.hlines(np.average(df_star.query("x_h==2")["y_star"], weights=df_star.query("x_h==2")["weight"]),
-1, 1, label="x_h=2", color="0.5")
plt.hlines(np.average(df_star.query("x_h==3")["y_star"], weights=df_star.query("x_h==3")["weight"]),
-1, 1, label="x_h=3", color="0.9")
plt.ylim(-1, 8)
plt.legend(fontsize=12)
<matplotlib.legend.Legend at 0x7fd823e00d90>
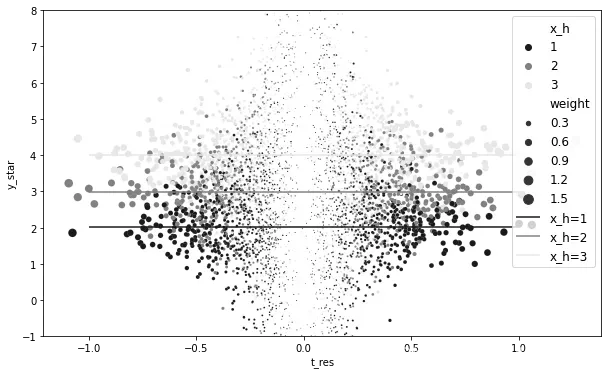
我喜欢这张图,因为它清楚地展示了权重的作用。当你接近图表中心时, 的方差增加了很多。你看不到它,因为我限制了y轴的范围,但实际上有些点一直延伸到了-2000和2000!幸运的是,这些都接近
,所以它们的权重非常小。现在,你在更直观的层面上了解了双重ML的工作原理。
基于树的学习器和神经网络学习器
本章并不打算列出目前所有的元学习器。我只包含了我个人认为最有用的学习器。然而,除了这里介绍的四种学习器外,还有其他的也值得一提。
首先,Susan Athey和Stefan Wager在使用改进决策树对效果异质性方面做了许多开创性的工作。你可以在因果推断库(如econml和causalml)中找到基于树的CATE学习器。我在本章中没有介绍它们,因为在写作之时,我从未成功地使用过它们。主要是因为目前可用的实现是纯Python,这使得它们在大型数据集上的拟合速度相当慢。我预计不久的将来会出现更快的实现,使得基于树的学习器成为值得一试的有趣选项。如果你想了解更多关于基于树的学习器的信息,我建议参阅实现这些学习器的因果推断包的文档。Athey和Wager也在斯坦福商学院(Stanford Business School)制作了一系列非常棒的在线视频,名为《机器学习与因果推理:短课程》(Machine Learning & Causal Inference: A Short Course)。
其次,你可以尝试基于神经网络的算法。然而,我认为这些算法仍处于初级阶段,它们带来潜在的收益并不值得让我们处理它的复杂性。至少目前还不值得。不过,如果你想在这方面的文献中进行探索,我推荐你阅读Curth和Schaar的论文《非参数估计异质处理效应:从理论到学习算法》(Nonparametric Estimation of Heterogeneous Treatment Effects: From Theory to Learning Algorithms),以及Shalit等人的论文《学习用于反事实推理的表示》(Learning Representations for Counterfactual Inference)。
7.3 要点总结
本章详细阐述了学习群组级别的干预效应 的概念。你不仅仅在回归模型中考虑了干预变量与协变量
的交互,还学习了如何将通用机器学习模型用于条件平均干预效果(CATE)的估算:即所谓的元学习器。具体来说,你学习了四种元学习器,其中两种仅适用于类别型干预,另外两种适用于任何类型的干预。
首先,T学习器通过机器学习模型来预测每种干预 的
值。然后,所得的结果模型
可用于估算干预效果。例如,在二元干预的情况下:
如果对于所有的干预分层,你都有大量的观测值,那么T学习器就工作得很好。否则,小数据集中估算的模型可能会受到正则化偏差的影响。你接下来看到的X学习器试图通过使用倾向得分模型来降低任何基于小样本训练的 的重要性,以此来解决这个问题。
为了处理连续的干预,你了解了S学习器,它能简单地估算 。也就是说,它预测了将干预作为特征的结果。这个模型可用于对
进行反事实预测,给定一个干预值的网格。这产生了一个单元特定的粗糙的干预响应函数,稍后需要将其概括为单个斜率参数。
最后但同样重要的是,你了解了双重ML。其理念是使用通用的ML模型和外部预测来获取干预和结果的残差,即 $T-E(T|X) $ 和 。这可以被理解为FWL正交化的加强版。一旦有了这些残差(
和
),你就可以构建一个接近
的目标:
使用任何ML模型预测目标,同时利用权重 ,得到的ML模型可以直接输出CATE预测。
最后,值得记住的是,所有这些方法都依赖于无混淆假设。试图用于CATE估算的算法有多炫酷并不重要;为了消除偏差,你的数据中需要包含所有相关的混淆因子。具体来说,无混淆假设允许你将条件期望的变化率解释为干预响应函数的斜率:
系列文章专栏:
使用Python进行因果推断(Causal Inference in Python)
第1章 因果推断导论
第2章 随机实验与统计学回顾
第3章 图形化因果模型
第4章 线性回归的不合理有效性
第5章 倾向分
第6章 效果异质性
第7章 元学习器
第8章 双重差分
持续更新中:
第9章 综合控制
第10章 Geo实验与Switchback实验
第11章 不依从性与工具
第12章 后续行动
【参考】
原版书籍《Causal Inference in Python: Applying Causal Inference in the Tech Industry》
原链接下载 csdn下载原书github代码
Github
文章出处登录后可见!