介绍:
list 是 Python 中的一种内置数据类型,代表一个可变的有序序列。list 类型的对象可以使用多个方法来操作和修改其中的元素。
list: 列表 Built-in mutable sequence. 内置可变的序列 定义列表的时候使用的是[ ], 也可以包含多个不同类型的元素,多个元素之间也是用逗号分隔
一、创建一个列表
list_data = [1, 2, 3, 4, 5] # 创建一个列表
print(list_data, type(list_data)) # 打印列表并输出它的类型
以上实例输出结果如下:
[1, 2, 3, 4, 5]
<class 'list'>二、 访问列表中的元素

例如,以下是如何获取 list 中的元素:
fruits = ['apple', 'banana', 'cherry']
# 取第一个元素
print(fruits[0]) # 'apple'
# 取第二个元素
print(fruits[1]) # 'banana'
# 从右边获取右边的第一个元素
print(fruits[-1]) # 'cherry'
可以使用切片操作符 : 来获取 list 的一个子序列。切片操作符接受两个参数,第一个参数是子序列的起始索引,第二个参数是子序列的结束索引(不包括该索引对应的元素)。
如果省略第一个参数,则默认从 list 的第一个元素开始。
如果省略第二个参数,则默认到 list 的最后一个元素。
例如,以下是如何获取 list 的子序列
fruits = ['apple', 'banana', 'cherry', 'date', 'elderberry']
print(fruits[1:3]) # ['banana', 'cherry']
print(fruits[:2]) # ['apple', 'banana']
print(fruits[3:]) # ['date', 'elderberry']
如果想获取 list 中的最后一个元素,也可以使用 -1 索引:
# 返回列表的最后一个元素
print(fruits[-1]) # elderberry
# 返回一个列表的一部分,其中包含除最后两个元素之外的所有元素
print(fruits[:-2]) # ['apple', 'banana', 'cherry']
# 返回包含列表最后三个元素的列表切片
print(fruits[-3:]) # ['cherry', 'date', 'elderberry']
三、append 方法:
append() 方法用于在列表的末尾追加元素,该方法的标准语法格式如下:
list.append(obj)- obj — 添加到列表末尾的对象。
- 该方法无返回值,但是会修改原来的列表
示例如下:列表的末尾追加元素
fruits = ['apple', 'banana', 'cherry']
fruits.append('orange')
print(fruits) # ['apple', 'banana', 'cherry', 'orange']
结论:
- 列表可包含任何数据类型的元素,单个列表中的元素无须全为同一类型。
- append() 方法向列表的尾部添加一个新的元素。
- 列表是以类的形式实现的。“创建”列表实际上是将一个类实例化。因此,列表有多种方法可以操作。
extend()方法只接受一个列表作为参数,并将该参数的每个元素都添加到原有的列表中
四、extend 方法:
extend() 函数用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)。
extend()方法语法:
list.extend(seq)- seq — 元素列表。
- 该方法没有返回值,但会在已存在的列表中添加新的列表内容。
示例如下:
fruits = ['apple', 'banana', 'cherry']
more_fruits = ['orange', 'lemon']
fruits.extend(more_fruits)
print(fruits) # ['apple', 'banana', 'cherry', 'orange', 'lemon']
五、insert 方法:
在指定位置插入一个元素,append() 和 extend() 方法只能在列表末尾插入元素,如果希望在列表中间某个位置插入元素,那么可以使用 insert() 方法。
insert() 的语法格式如下:
listname.insert(index , obj)- index 表示指定位置的索引值。
- obj — 要插入列表中的对象。
- insert() 会将 obj 插入到 listname 列表第 index 个元素的位置。
- 该方法没有返回值,但会在列表指定位置插入对象。
示例如下:
fruits = ['apple', 'banana', 'cherry']
fruits.insert(1, 'orange')
print(fruits) # ['apple', 'orange', 'banana', 'cherry']
结论:insert() 主要用来在列表的中间位置插入元素,如果你仅仅希望在列表的末尾追加元素,那我更建议使用 append() 和 extend()。
六、remove 方法:
remove() 函数用于移除列表中某个值的第一个匹配项。
remove()方法语法:
list.remove(obj)- obj — 列表中要移除的对象。
- 该方法没有返回值但是会移除列表中的某个值的第一个匹配项。
示例如下:删除列表中第一个匹配的元素。
fruits = ['apple', 'banana', 'cherry', 'banana']
fruits.remove('banana')
print(fruits) # ['apple', 'cherry', 'banana']
结论: remove() 方法只会删除第一个和指定值相同的元素,而且必须保证该元素是存在的,否则会引发 ValueError 错误
七、pop 方法:
pop() 方法用来删除列表中指定索引处的元素,具体格式如下:
list.pop([index=-1])- list 表示列表名称
- index 表示索引值
- obj — 可选参数,要移除列表元素的索引值,不能超过列表总长度,默认为 index=-1,删除最后一个列表值,类似于数据结构中的“出栈”操作
- 该方法返回从列表中移除的元素对象。
示例如下:删除并返回指定位置的元素,默认为列表末尾的元素
fruits = ['apple', 'banana', 'cherry']
last_fruit = fruits.pop()
print(last_fruit) # 'cherry'
print(fruits) # ['apple', 'banana']
结论:pop() 相对应的方法,就是 push(),该方法用来将元素添加到列表的尾部,类似于数据结构中的“入栈”操作。但是 Python 是个例外,Python 并没有提供 push() 方法,因为完全可以使用 append() 来代替 push() 的功能。
八、del方法:
del 可以删除列表中的单个元素,格式为:
del listname[index]- listname 表示列表名称,index 表示元素的索引值
示例如下:
fruits = ['apple', 'banana', 'cherry']
del fruits[2]
print(fruits) # 'apple', 'banana'del 也可以删除中间一段连续的元素,格式为:
del listname[start : end]- start 表示起始索引
- end 表示结束索引
- del 会删除从索引 start 到 end 之间的元素,不包括 end 位置的元素
示例如下:
fruits = ['apple', 'banana', 'cherry']
del fruits[0:2]
print(fruits) # 'cherry'
九、clear()方法:
clear()方法语法:
list.clear()clear() 用来删除列表的所有元素,也即清空列表
示例如下:
fruits = ['apple', 'banana', 'cherry']
fruits.clear()
print(fruits) # []
十、index( ) 方法:
index() 方法用来查找某个元素在列表中出现的位置(也就是索引),如果该元素不存在,则会导致 ValueError 错误,所以在查找之前最好使用 count() 方法判断一下。
index()方法语法:
list.index(obj, start, end)- lobj– 表示要查找的元素
- start– 可选,查找的起始位置。
- end– 可选,查找的结束位置。
- index() 方法会返回元素所在列表中的索引值。
start 和 end 参数用来指定检索范围:
- start 和 end 可以都不写,此时会检索整个列表;
- 如果只写 start 不写 end,那么表示检索从 start 到末尾的元素;
- 如果 start 和 end 都写,那么表示检索 start 和 end 之间的元素。
示例如下:返回第一个匹配的元素的索引。
fruits = ['apple', 'banana', 'cherry']
banana_index = fruits.index('banana')
print(banana_index) # 1
结论:index() 方法只返回元素在列表中第一次出现的位置索引,如果需要查找所有出现位置的索引,可以使用列表解析或循环等方法实现。
十一、count 方法:
count() 方法用来统计某个元素在列表中出现的次数,基本语法格式为:
list.count(obj)- obj — 列表中统计的对象。
- 如果 count() 返回 0,就表示列表中不存在该元素,所以 count() 也可以用来判断列表中的某个元素是否存在
示例如下::返回列表中指定元素的出现次数
fruits = ['apple', 'banana', 'cherry', 'banana']
banana_count = fruits.count('banana')
print(banana_count) # 2
结论:count() 方法只统计某个元素在列表中出现的次数,而不会返回元素在列表中出现的位置索引。如果需要查找元素在列表中的位置索引,可以使用 index() 方法。
十二、sort 方法:
sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。
sort()方法语法:
list.sort(cmp=None, key=None, reverse=False)- cmp — 可选参数, 如果指定了该参数会使用该参数的方法进行排序。
- key — 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse — 排序规则,reverse = True 降序, reverse = False 升序(默认)。
示例如下:按升序排列列表中的元素。
# 升序排序
a = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
a.sort()
print(a) # [1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
# 降序排序
a = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
a.sort(reverse=True)
print(a) # [9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1]
# 根据字符串长度排序
fruits = ['apple', 'banana', 'cherry', 'durian', 'elderberry']
fruits.sort(key=len)
print(fruits) # ['apple', 'banana', 'cherry', 'durian', 'elderberry']
结论:sort() 方法是 Python 列表中的一个方法,用于原地对列表进行排序,即将列表中的元素按一定的规则重新排列。默认情况下,sort() 方法按升序对列表进行排序,也可以通过传递 reverse=True 参数来按降序排序。
sort() 方法是原地排序,即会修改原始列表。如果需要对列表进行排序但又不想修改原始列表,可以使用 sorted() 内置函数。
十三、reverse 方法:
reverse() 函数用于反向列表中元素。reverse()方法语法:
list.reverse()示例如下:将列表中的元素倒序排列
fruits = ['apple', 'banana', 'cherry']
fruits.reverse()
print(fruits) # ['cherry', 'banana', 'apple']
结论:reverse() 方法是原地反转,即会修改原始列表。如果需要对列表进行反转但又不想修改原始列表,可以使用切片操作来创建一个反转后的新列表,例如 fruits[::-1]。
十四、copy方法:
copy() 是 list 类的一个方法,用于创建一个列表的副本。copy() 方法不带参数,它返回一个新列表,该列表包含原始列表中所有元素的副本。
例如,以下是如何使用 copy() 方法创建一个列表的副本:
fruits = ['apple', 'banana', 'cherry']
fruits_copy = fruits.copy()
print(fruits_copy) # ['apple', 'banana', 'cherry']
上面的例子中,
copy()方法创建了一个新的list对象fruits_copy,其中包含与原始列表fruits相同的元素。修改fruits_copy不会影响原始列表fruits。需要注意的是,
copy()方法只复制列表中元素的值,而不是元素本身。如果列表中包含可变对象(如列表或字典),则副本列表中的元素将包含与原始列表相同的可变对象的引用。这意味着如果修改了原始列表中的可变对象,副本列表中相应的元素也会受到影响。在 Python 中,可以使用
=运算符来复制列表。但是,使用=运算符复制列表只会创建原始列表的一个引用,而不是创建一个副本。这意味着修改一个列表会同时修改另一个列表。因此,如果需要复制列表并保留其独立性,请使用copy()方法。
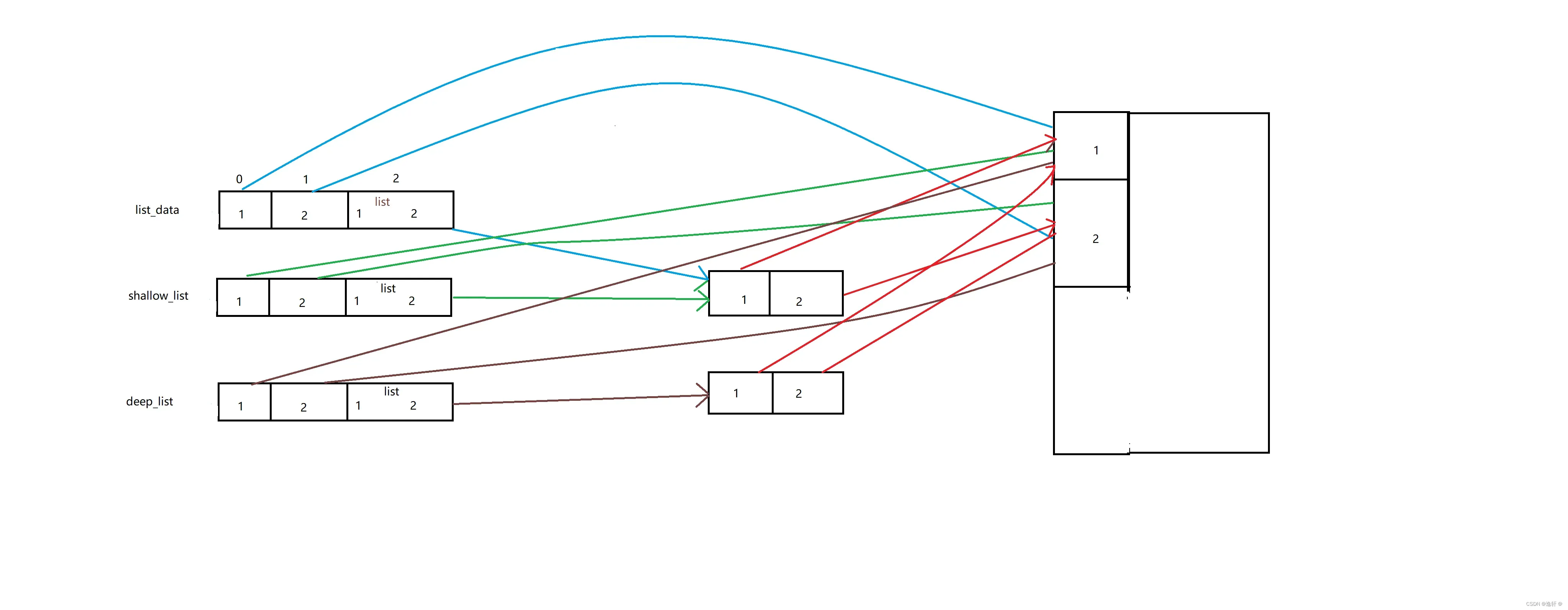
浅拷贝:copy() 方法进行浅拷贝的示例:
a = [1, 2, [1, 2]]
b = a.copy()
# 修改原始列表的第三个元素
a[2][0] = 5
print(a) # [1, 2, [5, 2]]
print(b) # [1, 2, [5, 2]]
在上面的例子中,a 是一个包含整数和嵌套列表的列表。使用 copy() 方法将 a 复制到 b 中,然后修改了 a 中的嵌套列表中的第一个元素。在浅拷贝后的 b 中,嵌套列表中的第一个元素也发生了变化。
深拷贝:copy 模块中的 deepcopy() 函数进行深拷贝的示例:
深拷贝是指创建一个新的列表对象,并递归地复制原始列表中的所有元素和嵌套的可变对象。这意味着如果修改原始列表中的嵌套对象,这些对象在深拷贝后的新列表中不会发生变化
import copy
a = [1, 2, [1, 2]]
b = copy.deepcopy(a)
# 修改原始列表的第三个元素
a[2][0] = 5
print(a) # [1, 2, [5, 2]]
print(b) # [1, 2, [1, 2]]
使用 copy 模块中的 deepcopy() 函数将 a 深拷贝到 b 中,然后修改了 a 中的嵌套列表中的第一个元素。在深拷贝后的 b 中,嵌套列表中的第一个元素没有发生变化。
需要注意的是,深拷贝比浅拷贝更慢并且更消耗内存,因为它需要递归地复制所有嵌套的对象。通常,只有在需要保留原始列表和新列表之间的独立性,并且原始列表包含嵌套的可变。
结论:
浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
深拷贝(deepcopy): copy 模块的deepcopy 方法,完全拷贝了父对象及其子对象。
十五、总结:
list 对象是可变的,即对 list 对象的操作会直接修改原列表,而不是返回一个新列表,Python 中的列表(list)是一种有序、可变的数据类型,可以容纳任何类型的元素,包括整数、浮点数、字符串、甚至其他列表。列表通过方括号 [ ] 来定义,可以使用索引来访问或修改列表中的元素。需要注意的是列表是可变的,即可以修改它们的内容。如果需要在不修改原始列表的情况下进行操作,可以使用切片操作来创建一个新的列表,或者使用 copy() 方法来创建一个原始列表的副本。
文章出处登录后可见!