容错机制
容错:指出错后不影响数据的继续处理,并且恢复到出错前的状态。
检查点:用存档读档的方式,将之前的某个时间点的所有状态保存下来,故障恢复继续处理的结果应该和发送故障前完全一致,这就是所谓的检查点。
检查点的控制节点:jobManager里面的检查点协调器,向source节点的数据插入barrier标记。
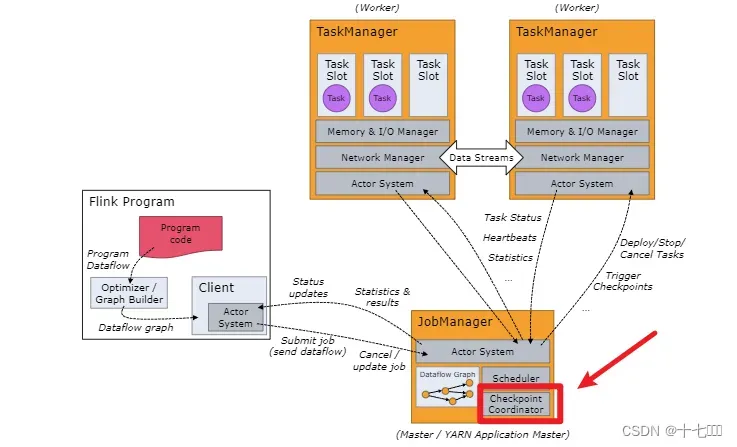
检查点的保存:
– 周期性触发保存
– 保存的时间点:所有算子恰好处理完一个相同的输入数据时(使用Barrier机制)
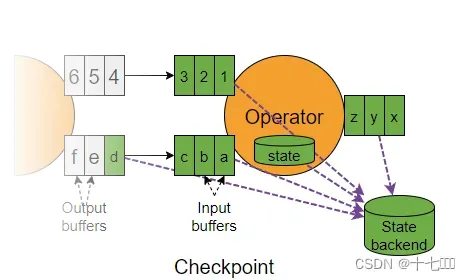
检查点分界线Barrier
barrier标记表示这个标记之前的所有数据已经将状态更改存入当前检查点。后续的算子节点只要遇到它就开始对状态做持久化快照保存。在它之后对数据状态的改变,只能保存到下一个检查点中。
检查点算法:Chandy-Lamport算法的一种变体。
算法两个原则:
- 当上游任务向多个并行下游任务发送barrier时,需要广播出去
- 而当多个上游任务向同一个下游任务传递分界线时,需要在下游任务执行“分界线对齐”操作,也就是需要等到所有并行分区的barrier都到齐,才可以开始状态的保存。
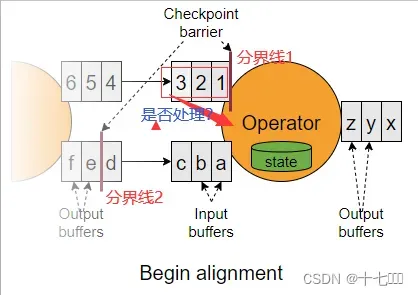
分界线对齐策略
-
精确一次(等待分界线2,先到的数据暂不进行处理):处理多次的结果是一样的
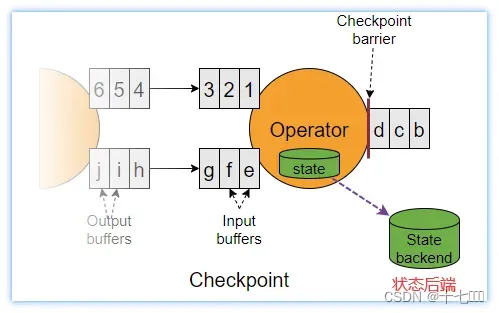
-
至少一次(对先到的数据进行处理):检查点中记录了先到数据对状态的更新信息,但是还未保存到状态后端,如果此时发生故障进行故障恢复,会导致从source重复发送刚刚已经处理过的先到数据。
分界线非对齐策略
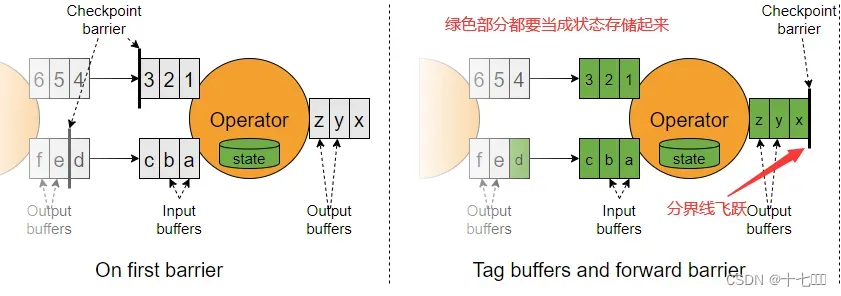
- 非对齐策略只有精准一次
- 缺点是需要将算子左边,分界线右边的所有数据存储起来,增加内存压力。
检查点配置
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
//指定一致性语义
// checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//检查点的存储
//JobManagerCheckpointStorage:将检查点存储到JobManager的内存中
//FileSystemCehckpointSotrage:将检查点存储到指定的文件系统中
checkpointConfig.setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://hadoop102:8020/flink/checkpoint"));
//状态后端
// env.setStateBackend(new EmbeddedRocksDBStateBackend());
//检查点间隔
checkpointConfig.setCheckpointInterval(2000L);
//检查点超时时间
checkpointConfig.setCheckpointTimeout(10000);
//同时存在的检查点个数
checkpointConfig.setMaxConcurrentCheckpoints(1);
//两次检查点之间的间隔
checkpointConfig.setMinPauseBetweenCheckpoints(1000L);
//检查点清理
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION);
//检查点允许的失败次数
checkpointConfig.setTolerableCheckpointFailureNumber(5);
//开启非对齐模式:只有在精准一次时才能开启,且最大同时存在检查点只能为1
checkpointConfig.enableUnalignedCheckpoints();
//对齐超时,自动开启非对齐
checkpointConfig.setAlignedCheckpointTimeout(Duration.ofSeconds(5));
//最终检查点:
//开启changlog
env.enableChangelogStateBackend(true);
通用增量changelog配置:hashmap本身不支持增量存储状态,rockDB是支持的。changeLog可以不论hashmap还是rockDB,都实现增量存储。开启该配置可以减少检查点的持续时间,在创建检查点时,只有changlog中的相关部分需要上传。
– 创建更多的文件
– 残留更多的文件
– 使用更多的IO来上传状态
– 占用更多的CPU资源来序列化状态变更
保存点savepoint
检查点与保存点的区别:
- 检查点
- 检查点是频繁触发的,设计目标就是轻量和尽快恢复
- 检查点的数据在作业终止后是否删除可以配置
- 数据存储格式可能是增量的
- 保存点
- 设计更侧重于可移植和操作灵活性,即运维
- 针对计划中的,手动的运维
- 保存点在作业终止和恢复后都不会删除
- 保存点的数据格式以状态后端独立的(标准的)数据格式存储
保存点的用途:
- 版本管理和归档存储
- 更新Flink版本
- 更新应用程序
- 调整并行度
保存点的使用之切换状态后端
- 开启flink集群
- 提交任务 bin/flink run -d -c -Dstate.backend=hashmap 全类名 jar路径
- 保存点的落盘: bin/flink -yid -type canonical yarn_id job_id hdfs://hadoop102/flink-savepoint
- 切换状态后重启:bin/flink run -d -Dstate.backend=rocksdb -s hdfs保存点路径 全类名 jar包路径
文章出处登录后可见!
已经登录?立即刷新