python抓取上海某二手房交易网站数据
基本思路
1.使用mysql创建lianjiaershoufang的数据库
2.创建chengjiao table,属性如下:
+---------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------------+--------------+------+-----+---------+-------+
| id | char(60) | NO | PRI | NULL | |
| qu | varchar(20) | YES | | NULL | |
| zhen | varchar(30) | YES | | NULL | |
| xiaoquName | varchar(100) | YES | | NULL | |
| xiaoquYear | varchar(60) | YES | | NULL | |
| title | varchar(200) | YES | | NULL | |
| houseInfo | varchar(200) | YES | | NULL | |
| dealDate | varchar(60) | YES | | NULL | |
| totalPrice | varchar(20) | YES | | NULL | |
| positionInfo | varchar(60) | YES | | NULL | |
| unitPrice | varchar(20) | YES | | NULL | |
| dealHouseInfo | varchar(60) | YES | | NULL | |
| postPrice | varchar(20) | YES | | NULL | |
| dealCycle | varchar(10) | YES | | NULL | |
+---------------+--------------+------+-----+---------+-------+
3.爬取数据将数据一条一条导入数据库
获取数据示例代码
import asyncio
import aiohttp
from lxml import etree
import logging
import datetime
import openpyxl
import nest_asyncio
nest_asyncio.apply()
from bs4 import BeautifulSoup
import re
import pymysql
import time
import random
class Spider(object):
def __init__(self):
self.semaphore = asyncio.Semaphore(1) # 信号量,控制协程数,防止爬的过快被反爬
self.header = {
"Cookie": "填写自己的浏览器cookie",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
}
self.flag = 0
# 请求指定url数据, 返回 HTML 字符串
async def request_data(self, url):
async with self.semaphore:
try:
session = aiohttp.ClientSession(headers=self.header)
response = await session.get(url)
result = await response.text()
await session.close()
except Exception as e:
print("请求地址%s failed" % url)
result = None
return result
# 根据镇名字,获取所有小区
async def get_all_xiaoqu_from_zhen(self, qu, zhen):
url = f'https://sh.lianjia.com/xiaoqu/%s/' % zhen
html_content = await self.request_data(url)
# 使用BeautifulSoup解析HTML
if html_content == None:
return
soup = BeautifulSoup(html_content, 'lxml')
# 找到所有class为'info'的<div>元素
info_divs = soup.find_all('h2', class_='total fl')
#print(info_divs)
span_tag = soup.find('h2', class_='total fl').find('span')
#获取小区的数量
xiaoqu_number = int(span_tag.text.strip())
page_number = 0 if (xiaoqu_number%30==0) else 1
page_number = page_number + xiaoqu_number // 30
print(">>> 区:%s, %s镇,小区数量:%d, totalPage:%d" % (qu, zhen, xiaoqu_number, page_number))
for pg in range(1, page_number+1):
print(">>>> 访问区:%s, 镇:%s, %d/%d 页" % (qu, zhen, pg, page_number))
await self.get_one_page_xiaoqu(qu, zhen, pg)
# 根据qu和page号码,获取一个page所有小区的数据
async def get_one_page_xiaoqu(self, qu, zhen, pg):
url = f'https://sh.lianjia.com/xiaoqu/%s/' % zhen
if pg > 1:
url += "pg%s/" % pg
try:
print(">>>> 访问一页小区:%s" % url)
html_text = await self.request_data(url)
except Exception as e:
print(">>>> request Data fail!")
return
if (html_text) == None:
return
soup = BeautifulSoup(html_text, 'lxml')
info_divs = soup.find_all('li', class_='clear xiaoquListItem')
for xiqoqu in info_divs:
xiaoqu_id = xiqoqu['data-id']
xiaoqu_name = xiqoqu.find('div', class_='title').get_text(strip=True)
xiaoqu_year = xiqoqu.find('div', class_='positionInfo').get_text(strip=True).split('/')[-1].strip()
if await self.get_one_xiaoqu(qu, zhen, xiaoqu_id, xiaoqu_name, xiaoqu_year) == False:
return False
async def get_all_qu(self):
Qu = ['pudong', 'minhang', 'baoshan', 'xuhui', 'putuo', 'yangpu', 'changning', 'songjiang', 'jiading', 'huangpu', 'jingan', 'hongkou', 'qingpu', 'fengxian', 'jinshan', 'chongming']
while True:
for qu in Qu:
print("> 开始获取 %s 区数据" % qu)
await self.get_all_zhen_from_qu(qu)
print("> 结束获取 %s 区数据>" % qu)
async def get_one_xiaoqu(self, qu, zhen, xiaoqu_id, xiaoqu_name, xiaoqu_year):
url = f'https://sh.lianjia.com/chengjiao/c%s/' % xiaoqu_id
html_text = await self.request_data(url)
if html_text == None:
return
soup = BeautifulSoup(html_text, 'lxml')
info_divs = soup.find_all('div', class_='total fl')
span_tag = soup.find('div', class_='total fl').find('span')
fangyuan_number = int(span_tag.text.strip())
page_number = 0 if (fangyuan_number%30==0) else 1
page_number = page_number + fangyuan_number // 30
print(">>>>> 小区:%s,成交数量:%d, page数量:%d" % (xiaoqu_name, fangyuan_number, page_number))
for pg in range(1, page_number+1):
print(">>>>>> 小区:%s, 第%d页/总%d页" % (xiaoqu_name, pg, page_number))
if await self.get_xiaoqu_one_page_fangyuan(qu, zhen, xiaoqu_id, xiaoqu_name, xiaoqu_year, pg) == False:
return False
async def get_xiaoqu_one_page_fangyuan(self, qu, zhen, xiaoqu_id, xiaoqu_name, xiaoqu_year, pg):
url = f'https://sh.lianjia.com/chengjiao/c%s/' % xiaoqu_id
if pg > 1:
url += "pg%s/" % pg
print(">>>>>> 区:%s, 小区:%s, url:%s" % (qu, xiaoqu_name, url))
html_text = await self.request_data(url)
if html_text == None:
return
soup = BeautifulSoup(html_text, 'lxml')
info_divs = soup.find_all('div', class_='info')
result_list = []
conn = pymysql.connect(host='localhost', user='root', password='123456', db='lianjiaershoufang')
cursor = conn.cursor()
index = 0
delay = random.uniform(0.01, 0.2)
time.sleep(delay)
for info_div in info_divs:
try:
# 创建一个字典来存储子元素的内容
info_dict = {}
info_dict['qu'] = qu
info_dict['xiaoquName'] = xiaoqu_name
info_dict['xiaoquYear'] = xiaoqu_year
# 提取子元素<div class="title">
title_div = info_div.find('div', class_='title')
info_dict['title'] = title_div.text.strip() if title_div else None
# 提取子元素<div class="address">
address_div = info_div.find('div', class_='address')
houseInfo = address_div.find('div', class_='houseInfo')
info_dict['houseInfo'] = houseInfo.text.strip() if houseInfo else None
dealDate = address_div.find('div', class_='dealDate')
info_dict['dealDate'] = dealDate.text.strip() if houseInfo else None
totalPrice = address_div.find('div', class_='totalPrice')
number = totalPrice.find('span', class_='number')
info_dict['totalPrice'] = number.text.strip() if number else None
flood_div = info_div.find('div', class_='flood')
positionInfo = flood_div.find('div', class_='positionInfo')
info_dict['positionInfo'] = positionInfo.text.strip() if positionInfo else None
unitPrice = flood_div.find('div', class_='unitPrice')
number = unitPrice.find('span', class_='number')
info_dict['unitPrice'] = number.text.strip() if unitPrice else None
# 提取子元素<div class="dealHouseInfo">
deal_house_info_div = info_div.find('div', class_='dealHouseInfo')
info_dict['dealHouseInfo'] = deal_house_info_div.text.strip() if deal_house_info_div else None
# 提取子元素<div class="dealCycleeInfo">
deal_cycle_info_div = info_div.find('div', class_='dealCycleeInfo')
deal_cycle_str = deal_cycle_info_div.text.strip() if deal_cycle_info_div else None
# 提取挂牌价
listing_price = re.search(r'挂牌(\d+)万', deal_cycle_str)
if listing_price:
listing_price = listing_price.group(1)
info_dict['postPrice'] = listing_price
# 提取成交周期
transaction_period = re.search(r'成交周期(\d+)天', deal_cycle_str)
if transaction_period:
transaction_period = transaction_period.group(1)
info_dict['dealCycle'] = transaction_period
info_dict['id'] = xiaoqu_id + "-" + info_dict['dealDate'] + "-" +info_dict['unitPrice'] + "-" + info_dict['totalPrice']
info_dict['zhen'] = zhen
result_list.append(info_dict)
sql = "INSERT INTO chengjiao (id, qu, zhen, xiaoquName, xiaoquYear, title, houseInfo, dealDate, totalPrice, positionInfo, unitPrice, dealHouseInfo, postPrice, dealCycle) VALUES "
sql += "('%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s');" % (info_dict['id'], info_dict['qu'], info_dict['zhen'], info_dict['xiaoquName'], info_dict['xiaoquYear'], info_dict['title'], info_dict['houseInfo'], info_dict['dealDate'], info_dict['totalPrice'], info_dict['positionInfo'], info_dict['unitPrice'], info_dict['dealHouseInfo'], info_dict['postPrice'], info_dict['dealCycle'])
except Exception as e:
print(">>>>>> 解析错误!")
continue
try:
cursor.execute(sql)
except Exception as e:
print(">>>>>> 小区:%s 已存在!!" % xiaoqu_name)
conn.commit()
cursor.close()
conn.close()
return False
index = index + 1
print("小区:%s, 插入:%d 条数据"%(xiaoqu_name, index))
conn.commit()
cursor.close()
conn.close()
# 根据区名,获取所有的镇,
async def get_all_zhen_from_qu(self, qu):
url = f'https://sh.lianjia.com/xiaoqu/%s/' % qu
html_content = await self.request_data(url)
if html_content == None:
return
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html_content, 'lxml')
div_ershoufang = soup.find('div', {'data-role': 'ershoufang'})
if div_ershoufang:
div_list = div_ershoufang.find_all('div')
# 如果至少有两个<div>标签,提取第二个<div>标签内的<a href>标签内容
if len(div_list) >= 2:
second_div = div_list[1]
a_tags = second_div.find_all('a', href=True)
# 提取第二个<div>标签内每个<a href>标签下的内容
for a_tag in a_tags:
zhen_name = a_tag.get_text()
href = a_tag['href']
# 从href属性中提取所需字符串
one_zhen = href.split('/')[-2]
print(">> 获取:%s%s 镇的小区" % (one_zhen, zhen_name))
# 开始时候的镇名字
if one_zhen == 'xinchenglu1':
self.flag = 1
if self.flag == 0:
continue
await self.get_all_xiaoqu_from_zhen(qu, one_zhen)
if __name__ == '__main__':
spider = Spider()
asyncio.run(spider.get_all_qu())
分析数据实例代码
获取月均价和月成交量,并作图
import pymysql
import matplotlib.pyplot as plt
from datetime import datetime
# 数据库连接配置
host = 'localhost'
user = 'root'
password = '123456'
db = 'lianjiaershoufang'
tableName = 'chengjiao'
showGap = 2
# 连接到数据库
connection = pymysql.connect(host=host, user=user, password=password, db=db)
try:
with connection.cursor() as cursor:
# SQL查询语句
sql = """
SELECT
LEFT(dealDate, 7) AS Month,
SUM(CAST(unitPrice AS DECIMAL(10, 2)) * CAST(SUBSTRING_INDEX(SUBSTRING_INDEX(title, ' ', -1), '平米', 1) AS DECIMAL(10, 2))) AS TotalPrice,
SUM(CAST(SUBSTRING_INDEX(SUBSTRING_INDEX(title, ' ', -1), '平米', 1) AS DECIMAL(10, 2))) AS TotalArea,
COUNT(*) AS Count
FROM
{}
WHERE title NOT LIKE '%车位%' and totalPrice<20000 and totalPrice > 10
GROUP BY
LEFT(dealDate, 7)
ORDER BY
Month
""".format(tableName)
cursor.execute(sql)
result = cursor.fetchall()
# 处理结果
dates = []
avg_prices = []
counts = []
for row in result:
month, total_price, total_area, count = row
avg_price = total_price / total_area
dates.append(datetime.strptime(month, "%Y.%m"))
avg_prices.append(avg_price)
counts.append(count)
except Exception as e:
print("Error: ", e)
finally:
connection.close()
# 绘制散点图
plt.figure(figsize=(16, 20))
plt.subplot(2, 1, 1)
plt.scatter(dates, avg_prices, color='blue')
plt.title('Average Price per Square Meter Over Time')
plt.xlabel('Date')
plt.ylabel('Average Price (RMB)')
# 设置横坐标为日期,垂直显示
plt.xticks(rotation=60)
plt.xticks(dates[::showGap])
plt.subplot(2, 1, 2)
plt.scatter(dates, counts, color='red')
plt.title('Number of Transactions Over Time')
plt.xlabel('Date')
plt.ylabel('Number of Transactions')
# 设置横坐标为日期,垂直显示
plt.xticks(rotation=60)
plt.xticks(dates[::showGap])
plt.tight_layout()
plt.show()
分析结果实例
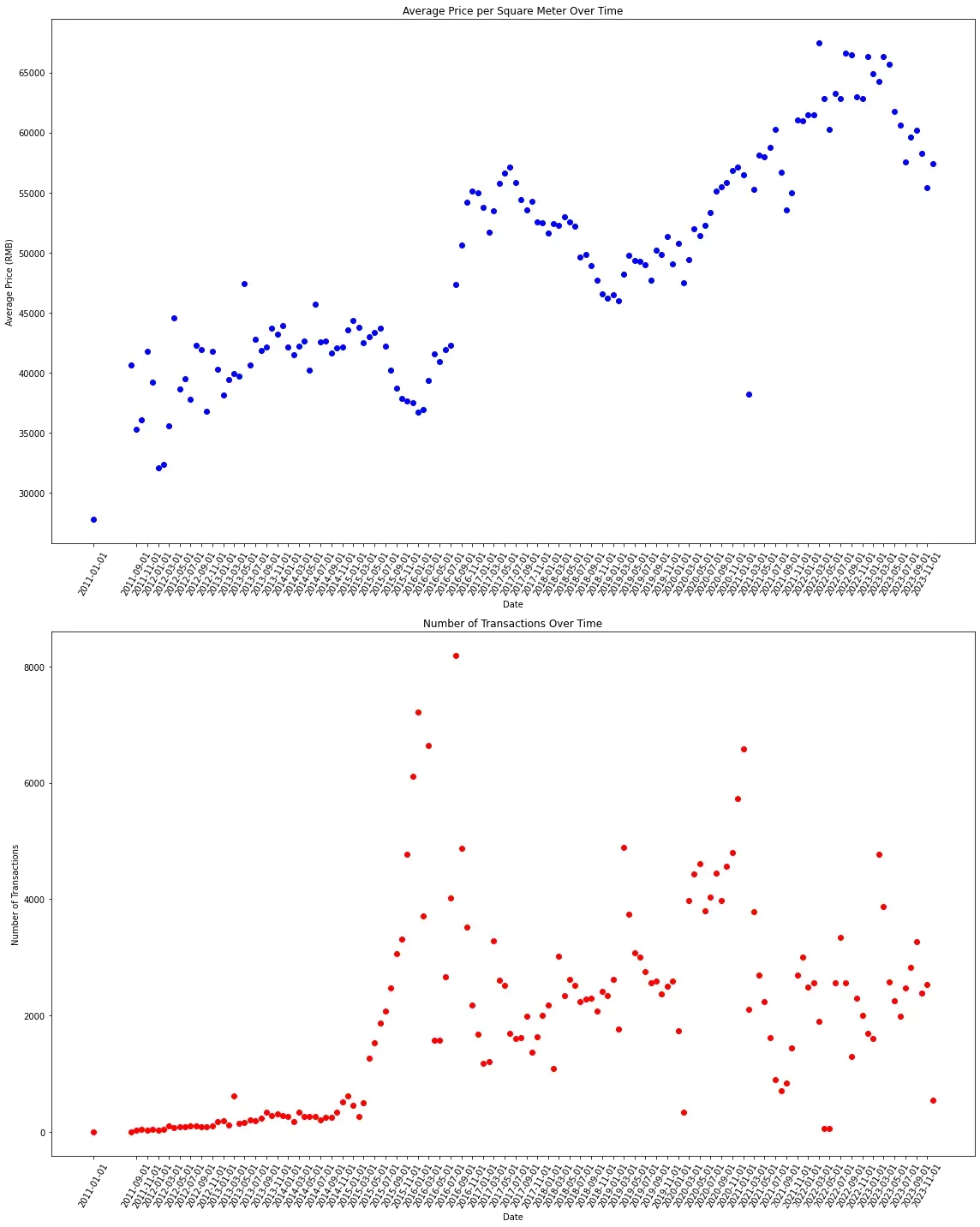
文章出处登录后可见!
已经登录?立即刷新