目录
涉及知识
按照实验完成顺序:
·自动化测试:selenium
·爬虫:requests
·数据解析:json
·数据清洗
·数据分析:numpy,matpltlib,pandas
自动打开想要获取到数据的页面
(1)注意伪装好,绕过浏览器识别;
(2)反反爬。
绘制统计图
(1)注意即将绘制的图是否有缺失值等;
(2)注意查看数据问题。
初步设计过程
自动化测试
所需数据包
from selenium import webdriver
from time import sleep
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
初步过程分析
(1)确定浏览器版本,下载相应驱动。

(2)防止浏览器自动关闭
option = webdriver.EdgeOptions()
option.add_experimental_option(‘excludeSwitches’, [‘enable-automation’])
option.add_experimental_option(“detach”, True)
driver = webdriver.Edge(executable_path=’./edge driver’, options=option)
(3)进入12306官网,寻找相应标签,定位元素位置(id, name, class, tag, xpath, css, link等)。
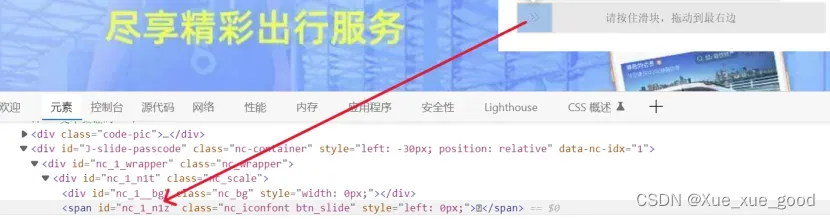
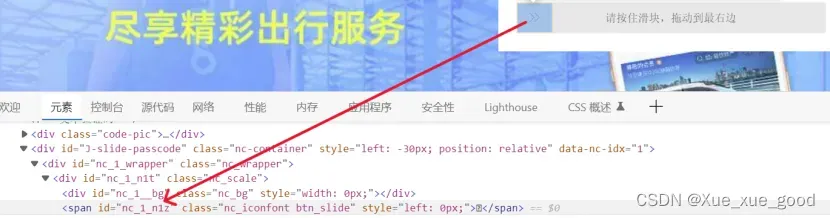
(4)一些网站具有反爬机制,反爬方式多种多样,12306中为验证码滑块,主要用到行为链,让浏览器识别不到爬虫。
具体操作:找到滑块id(‘nc_1_n1z’),创建对象,判断,执行。
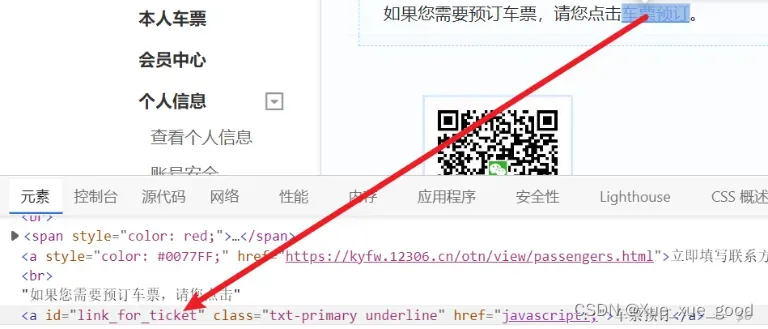
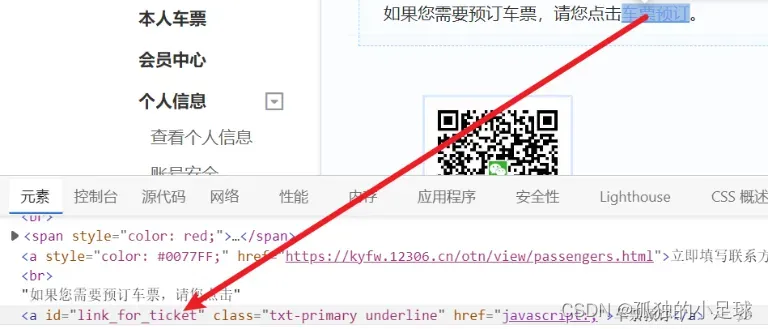
(5) 成功登录后,有目的性地寻找所需标签,模仿鼠标与键盘响应方式。常见的一些方法如下:click(),clear(),send_keys(),perform()等。如下所示:
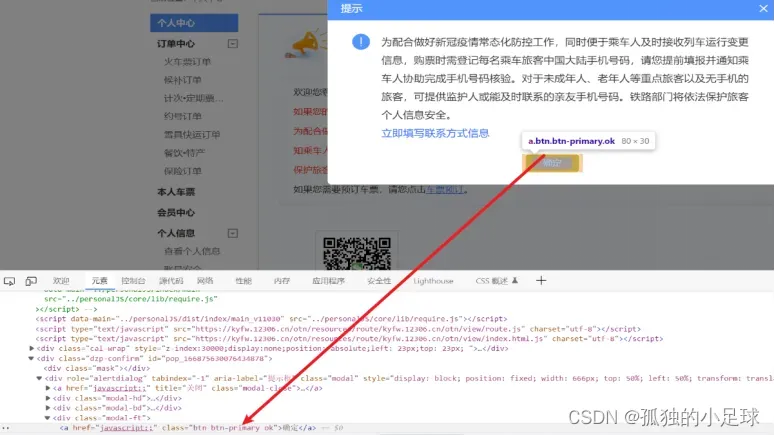
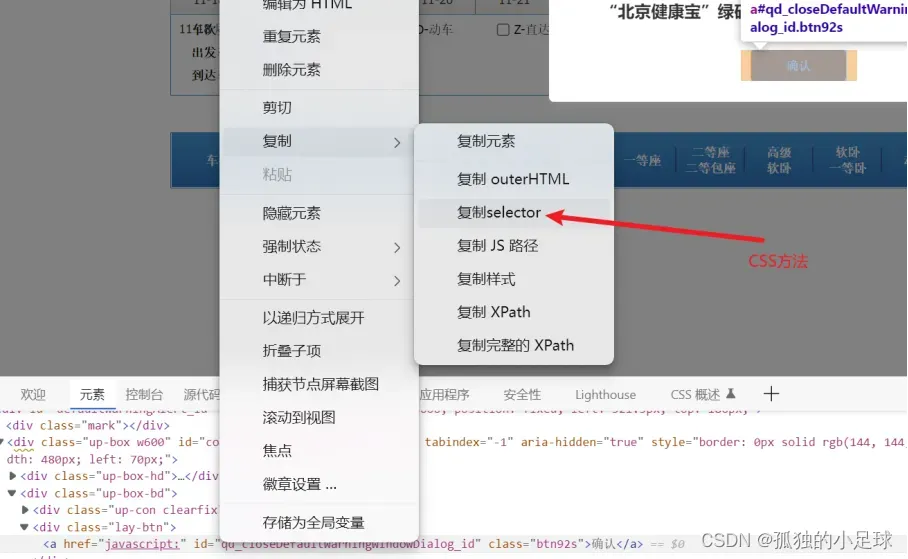
(6)此次实验,我没有完成最后一步,因为12306每天只有三次取消订单机会,而且我最近测试次数比较多,害怕被拉入黑名单。
(7)完成这些之后,开始爬取当前页面我们想要的数据。
爬取数据
所需数据包
import requests
import pandas as pd
import json
from tqdm import tqdm
初步过程分析
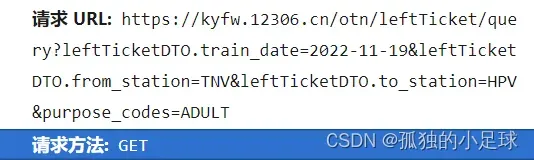
(1)确定目标网址:
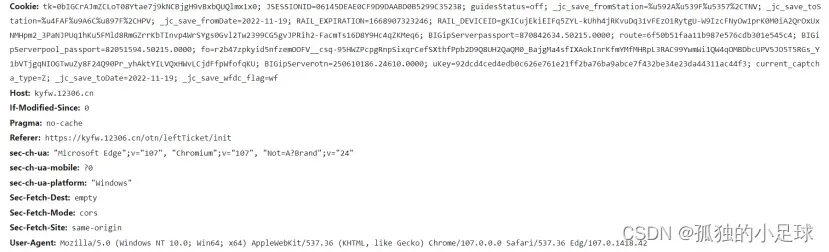
如我要获取12306中从太原南到侯马西,往返,2022-11-19日的所有车票信息,网址如下图所示,除此之外,仍然要做好伪装,如下图 3.11所示,其中User-Agent(用户代理,浏览器基本身份标识),Cookie(用户信息,常用于检测是否登陆账号)都是用来伪装的。
(2)获取网页数据:
获取网页数据,也就是通过网址( URL:Uniform Resource Locator,统一资源 定位符),获得网络的数据,充当搜索引擎。当输入网址,我们就相当于对网址服务器发送了一个请求,网站服务器收到以后,进行处理和解析,进而给我们一个相应的相应。如果网络正确并且网址不错,一般都可以得到网页信息,否则告诉我们一个错误代码,比如404. 整个过程可以称为请求和响应。
版权声明:本文为博主作者:孤独的小足球原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Xue_xue_good/article/details/129825533