- 在最开始,先引入我们的 numpy 和 matplotlib 库。
from matplotlib import pyplot as plt
import numpy as np
- 同时,对基本配置进行设置,将中文字体设置为黑体,不包含中文负号,分辨率为 100,图像显示大小设置为 (5,3)。
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
plt.rcParams['figure.figsize'] = (5,3)
一、散点图
- 散点图也叫 X-Y 图,它将所有的数据以点的形式展现在直角坐标系上,以显示变量之间的相互影响程度,点的位置由变量的数值决定。
- 通过观察散点图上数据点的分布情况,我们可以推断出变量间的相关性。如果变量之间不存在相互 关系,那么在散点图上就会表现为随机分布的离散的点,如果存在某种相关性,那么大部分的数据 点就会相对密集并以某种趋势呈现。
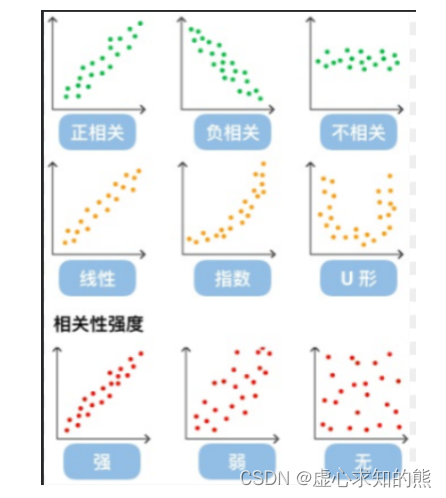
- 数据的相关关系主要分为:正相关(两个变量值同时增长)、负相关(一个变量值增加另一个变量值下降)、 不相关、线性相关、指数相关等,表现在散点图上的大致分布如下图所示。那些离点集群较远的点我们称为离群点或者异常点。
1. scatter() 函数
- scatter() 函数的语法模板如下:
matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, edgecolors=None, plotnonfinite=False, data=None, *kwargs)
- 其参数含义如下:
- x, y 表示散点的坐标。
- s 表示散点的面积。
- c 表示散点的颜色(默认值为蓝色,‘b’,其余颜色同 plt.plot( ))。
- marker 表示散点样式(默认值为实心圆,‘o’,其余样式同 plt.plot( ))。
- alpha 表示散点透明度([0, 1] 之间的数,0 表示完全透明,1 则表示完全不透明)。
- linewidths 表示散点的边缘线宽。
- edgecolors 表示散点的边缘颜色。
- cmap 表示 Colormap,默认 None,标量或者是一个 colormap 的名字,只有 c 是一个浮点数数组的时才使用。
- scatter() 函数接收长度相同的数组参数,一个用于 x 轴的值,另一个用于 y 轴上的值。
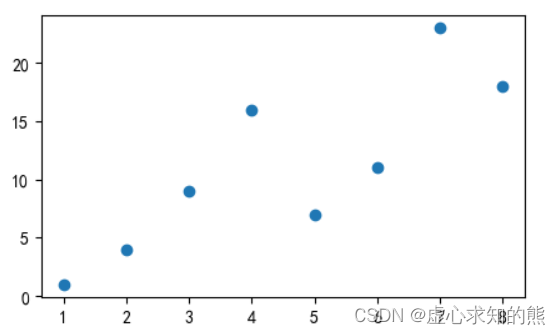
- 其中,x 轴和 y 轴的数据我们直接设定并使用 plt.scatter( ) 函数进行散点图的绘制。
x = np.array([1, 2, 3, 4, 5, 6, 7, 8])
y = np.array([1, 4, 9, 16, 7, 11, 23, 18])
plt.scatter(x, y)
2. 设置图标大小
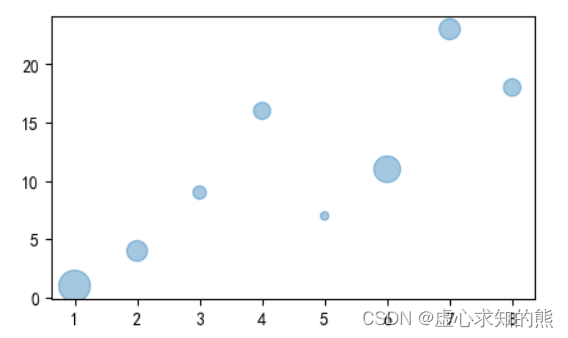
- x 轴和 y 轴仍采用上面的数据,同时,生成一个 [0,1)之间的随机浮点数或N维浮点数组,用以表示散点的大小。
x = np.array([1, 2, 3, 4, 5, 6, 7, 8])
y = np.array([1, 4, 9, 16, 7, 11, 23, 18])
print((20 * np.random.rand(8))** 2)
s = (20 * np.random.rand(8))** 2
plt.scatter(x, y, s,alpha=0.4)
plt.show()
#[131.25378089 364.17758417 253.68756331 172.75394022 296.36009688
# 111.50497604 161.49816335 160.3655232 ]
3. 自定义点的颜色和透明度
- 颜色的设置方式有如下三种:
- (1) 颜色英文。
- (2) 字母 r、b、g。
- (3) 十六进制 #123ab1。
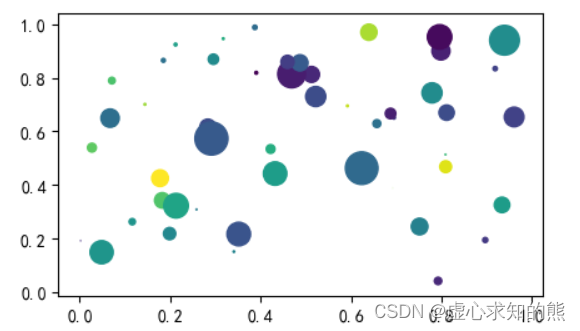
- 此时,我们通过随机种子生成函数 np.random.rand() 在 x 轴和 y 轴生成一个 [0,1) 之间的随机浮点数或 N 维浮点数组,取数范围为正态分布的随机样本数。
- 其中,颜色可以使用一组数字序列,如只需要 3 种颜色,这里我们直接使用 np.random.rand() 对颜色进行随机生成。
x = np.random.rand(50)
y = np.random.rand(50)
s = (10 * np.random.randn(50))** 2
colors = np.random.rand(50)
plt.scatter(x, y, s,c=colors)
4. 可以选择不同的颜色条,配合 cmap 参数
- Matplotlib 模块提供了很多可用的颜色条。
- 颜色条就像一个颜色列表,其中每种颜色都有一个范围从 0 到 100 的值。
- 下面是一个颜色条的例子: viridis。
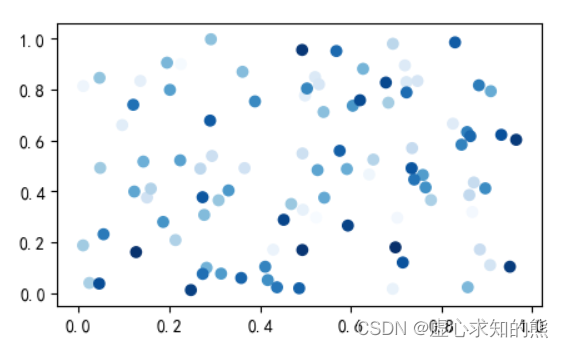
- 对于,x 轴和 y 轴的数据,我们通过 np.random.rand() 生成 100 个随机数据。
- 在此要演示 cmap 参数,因此,我们使用 np.arange() 直接生成 [1,100] 的颜色数据。
- 然后,将 cmap 参数设置为蓝色(其他颜色同理),就会生成各种蓝色的散点图。
x = np.random.rand(100)
y = np.random.rand(100)
colors = np.arange(1,101)
plt.scatter(x, y, c=colors, cmap='Blues')
5. cmap 的分类
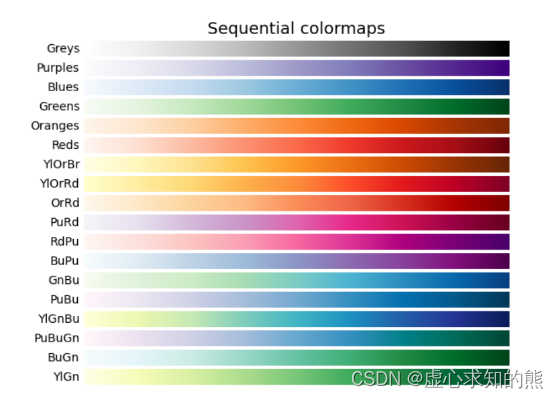
5.1 Sequential colormaps:连续化色图
- 特点:在两种色调之间近似平滑变化,通常是从低饱和度(例如白色)到高饱和度(例如明亮的蓝色)。
- 应用:适用于大多数科学数据,可直观地看出数据从低到高的变化。
- (1) 以中间值颜色命名(eg:viridis 松石绿):[‘viridis’, ‘plasma’, ‘inferno’, ‘magma’, ‘cividis’]。

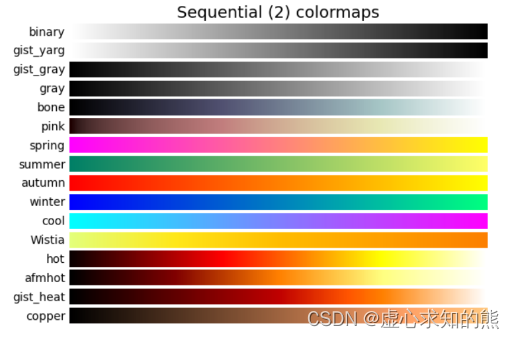
- (2) 以色系名称命名,由低饱和度到高饱和度过渡(eg:YlOrRd = yellow-orange-red,其它同理): [‘Greys’, ‘Purples’, ‘Blues’, ‘Greens’, ‘Oranges’, ‘Reds’,‘YlOrBr’, ‘YlOrRd’, ‘OrRd’, ‘PuRd’, ‘RdPu’, ‘BuPu’,‘GnBu’, ‘PuBu’, ‘YlGnBu’, ‘PuBuGn’, ‘BuGn’, ‘YlGn’,‘binary’, ‘gist_yarg’, ‘gist_gray’, ‘gray’, ‘bone’, ‘pink’,‘spring’, ‘summer’, ‘autumn’, ‘winter’, ‘cool’, ‘Wistia’,‘hot’, ‘afmhot’, ‘gist_heat’, ‘copper’]。
5.2 Diverging colormaps:两端发散的色图 .
- 特点:具有中间值(通常是浅色),并在高值和低值处平滑变化为两种不同的色调。
- 应用:适用于数据的中间值很大的情况(例如0,因此正值和负值分别表示为颜色图的不同颜色)。
- 例如:[‘PiYG’, ‘PRGn’, ‘BrBG’, ‘PuOr’, ‘RdGy’, ‘RdBu’,‘RdYlBu’, ‘RdYlGn’, ‘Spectral’, ‘coolwarm’, ‘bwr’, ‘seismic’]。
5.3 Qualitative colormaps:离散化色图
- 特点:离散的颜色组合。
- 应用:在深色背景上绘制一系列线条时,可以在定性色图中选择一组离散的颜色,例如:color_list = plt.cm.Set3(np.linspace(0, 1, 12))。
5.4 Miscellaneous colormaps:其它色图
二、保存图片 pyplot.savefig()
- 保存图片的语法模板 pyplot.savefig() 如下:
savefig(fname, dpi=None, facecolor=’w’, edgecolor=’w’, orientation=’portrait’, papertype=None, format=None, transparent=False, bbox_inches=None, pad_inches=0.1, frameon=None, metadata=None)
- 其参数含义如下:
- fname 表示(字符串或者仿路径或仿文件)如果格式已经设置,这将决定输出的格式并将文件按 fname 来保存。如果格式没有设置,在 fname 有扩展名的情况下推断按此保存,没有扩展名将按照默认格式存储为 png 格式,并将适当的扩展名添加在 fname 后面。
- dpi 表示分辨率,每英寸的点数。
- facecolor(颜色或 auto,默认值是 auto)表示图形表面颜色。如果是 auto,使用当前图形的表面颜色。
- edgecolor(颜色或 auto,默认值:auto)表示图形边缘颜色。如果是 auto,使用当前图形的边缘颜色。
- format(字符串)表示文件格式,比如 png,jpg,pdf,svg 等,未设置的行为将被记录在 fname 中。
- transparent 表示用于将图片背景设置为透明。图形也会是透明,除非通过关键字参数指定了表面颜色和/或边缘
- 其中,需要注意的是:
- (1) 第一个参数就是保存的路径.
- (2) 如果路径中包含未创建的文件夹,会报错,需要手动或者使用 os 模块创建。
- (3) 必须在调用 plt.show() 之前保存,否则将保存的是空白图形.
- (4) 如果保存到指定文件夹中,一定确保文件夹存在。
- 例如,我们对 x 轴和 y 轴的数据进行指定,然后使用 os 模块判断目录是否存在,如果不存在的话,使用 os 模块进行文件夹的创建。
import os
x_axis =[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
y_axis =[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
plt.hist(x_axis, y_axis)
plt.xlabel("X")
plt.ylabel("Y")
if not os.path.exists("my"):
os.mkdir("my")
plt.savefig("my/my_show.png")
plt.show()

三、箱线图绘制 boxplot()
- 箱线图(Boxplot)是一种用作显示一组数据分散情况资料的统计图表。
1. 箱线图基本介绍
- 箱线图,又称箱形图(boxplot)或盒式图,不同于一般的折线图、柱状图或饼图等图表, 其包含一些统计学的均值、分位数、极值等统计量,该图信息量较大,不仅能够分析不同类别数据平均水平差异, 还能揭示数据间离散程度、异常值、分布差异等。
- 具体含义可通过如下图表进行说明:
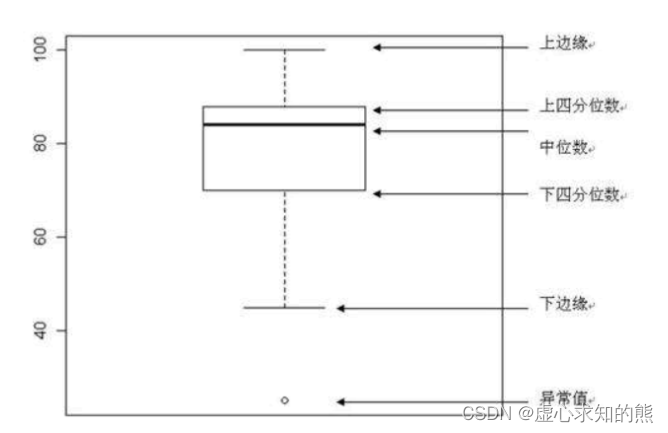
- 在箱型图中,我们从上四分位数到下四分位数绘制一个盒子,然后用一条垂直触须(形象地称为“盒须”)穿过盒子的中间。上垂线延伸至上边缘(最大值),下垂线延伸至下边缘(最小值)
- 箱型图一般应用在如下场景:
- (1) 箱型图由于能显示一组数据分散情况,常用于品质管理。
- (2) 箱型图有利于数据的清洗,能快速知道数据分别情况。
- (3) 箱型图有助于分析一直数据的偏向如分析公司员工收入水平。
2. 函数的使用 pyplot.boxplot()
- 其语法模板如下:
matplotlib.pyplot.boxplot(x, notch=None, sym=None, vert=None, whis=None, positions=None, widths=None, patch_artist=None, bootstrap=None, usermedians=None, conf_intervals=None, meanline=None, showmeans=None, showcaps=None, showbox=None, showfliers=None, boxprops=None, labels=None, flierprops=None, medianprops=None, meanprops=None, capprops=None, whiskerprops=None, manage_ticks=True, autorange=False, zorder=None, *, data=None)
- x 表示输入数据。类型为数组或向量序列。是一个必备参数。
- notch 表示控制箱体中央是否有 V 型凹槽。当取值为 True 时,箱体中央有 V 型凹槽,凹槽表示中位数的置信区间;取值为 False 时,箱体为矩形。数据类型为布尔值,默认值为 False,是一个可选参数。
- vert 表示箱体的方向,当取值为 True 时,绘制垂直箱体,当取值为 False 时,绘制水平箱体。数据类型为布尔值,默认值为 True。是一个可选参数。
- positions 表示指定箱体的位置。刻度和极值会自动匹配箱体位置。数据类型为类数组结构,是一个可选参数。默认值为 range(1, N+1) ,N 为箱线图的个数。
- widths 表示箱体的宽度。类数据型为浮点数或类数组结构。默认值为 0.5 或 0.15 * 极值间的距离。
- labels 表示每个数据集的标签,默认值为 None。数据类型为序列,是一个可选参数。
- autorange 表示当取值为 True 且数据分布满足上四分位数(75%)和下四分位数(25%)相等。数据类型为布尔值,默认值为 False,是一个可选参数。
- showmeans 表示是否显示算术平均值。数据类型为布尔值,默认值为 False,是一个可选参数。
- meanline 表示均值显示为线还是点,当取值为 True,且 showmeans、shownotches 参数均为 True 时显示为线。数据类型为布尔值,默认值为 False,是一个可选参数。
- capprops 表示箱须横杠的样式。数据类型为字典,默认值为 None,是一个可选参数。
- boxprops 表示箱体的样式。数据类型为字典,默认值为 None,是一个可选参数。
- whiskerprops 表示箱须的样式。数据类型为字典,默认值为 None,是一个可选参数。
- flierprops 表示离群点的样式。数据类型为字典,默认值为 None,是一个可选参数。
- medianprops 表示中位数的样式。数据类型为字典,默认值为 None,是一个可选参数。
- meanprops 表示算术平均值的样式。数据类型为字典,默认值为 None,是一个可选参数。
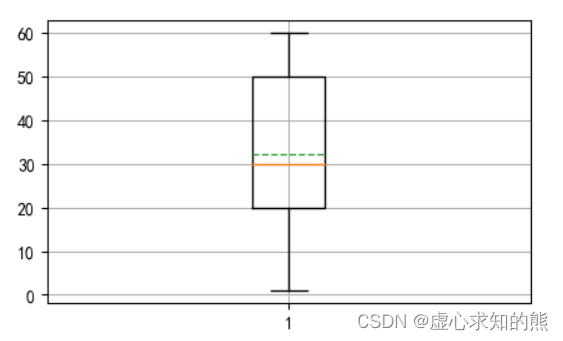
- 例如,我们可以生成如下的简单箱线图。
- 使用 showmeans 和 meanline 参数。
x = np.array([1,20,30,50,60])
print(np.mean(x))
plt.boxplot(x,showmeans=True,meanline=True)
plt.grid()
plt.show()
#32.2
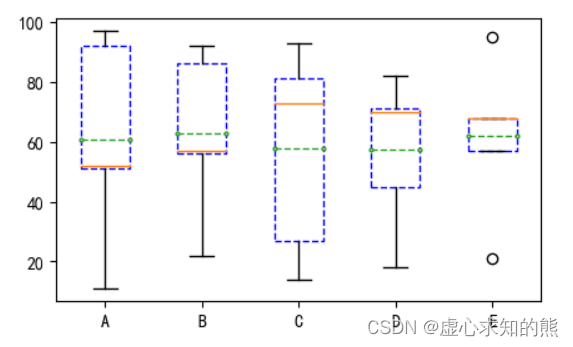
- 通过创建 5 行 5 列的数据,使用 boxprops 和 meanprops 参数。
x = np.random.randint(10,100,size=(5,5))
box = {"linestyle":'--',"linewidth":1,"color":'blue'}
mean = {"marker":'o','markerfacecolor':'pink','markersize':2}
plt.boxplot(x,meanline=True,showmeans=True,labels=["A","B","C","D","E"], boxprops=box,meanprops=mean)
plt.show()
四、词云图
- 词云图,也叫文字云,是对文本中出现频率较高的关键词予以视觉化的展现, 词云图过滤掉大量的低频低质的文本信息,使得浏览者只要一眼扫过文本就可领略文本的主旨。

- WordCloud 是一款 python 环境下的词云图工具包,同时支持 python2 和 python3,能通过代码的形式把关键词数据转换成直观且有趣的图文模式。
- pip 的默认安装方式:
pip install wordcloud。 - 如果是使用 conda 的方式安装,则使用以下命令安装:
conda install -c conda-forge wordcloud。
1. WordCloud 参数查看
| 属性 | 数据类型|默认值 | 解析 |
|---|---|---|
font_path | string | 字体路径 windows:C:/Windows/Fonts/ Linux: /usr/share/fonts |
width | int (default=400) | 输出的画布宽度,默认为400像素 |
height | int (default=200) | 输出的画布高度,默认为200像素 |
prefer_horizontal | float (default=0.90) | 词语水平方向排版出现的频率,默认 0.9 所以词语垂直方向排版出现频率为0.1 |
mask | nd-array or None (default=None) | 如果参数为空,则使用二维遮罩绘制词云 如果mask非空,设置的宽高值将被忽略 遮罩形状被 mask 取代 |
scale | float (default=1) | 按照比例进行放大画布,如设置为1.5, 则长和宽都是原来画布的1.5倍 |
min_font_size | int (default=4) | 显示的最小的字体大小 |
font_step | int (default=1) | 字体步长,如果步长大于1,会加快运算 但是可能导致结果出现较大的误差 |
max_words | number (default=200) | 要显示的词的最大个数 |
stopwords | set of strings or None | 设置需要屏蔽的词,如果为空, 则使用内置的STOPWORDS |
background_color | color value default=”black” | 背景颜色 |
max_font_size | int or None default=None | 显示的最大的字体大小 |
mode | string (default=”RGB”) | 当参数为“RGBA”并且background_color 不为空时,背景为透明 |
relative_scaling | float (default=.5) | 词频和字体大小的关联性 |
color_func | callable, default=None | 生成新颜色的函数,如果为空, 则使用 self.color_func |
regexp | string or None (optional) | 使用正则表达式分隔输入的文本 |
collocations | bool, default=True | 是否包括两个词的搭配 |
colormap | string or matplotlib colormap default=”viridis” | 给每个单词随机分配颜色, 若指定color_func,则忽略该方法 |
random_state | int or None | 为每个单词返回一个PIL颜色 |
2. 中文使用词云图,需要使用 jieba 分词模块
- 他支持如下几种分词模式:
- (1) 精确模式,试图将句子最精确地切开,适合文本分析。
- (2) 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义。
- (3) 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- (4) 支持繁体分词。
- (5) 支持自定义词典。
- 他的代码对 Python 2/3 均兼容,有如下几种安装方式:
- (1) 全自动安装:
easy_install jieba或者pip install jieba / pip3 install jieba。 - (2) 半自动安装:先下载
http://pypi.python.org/pypi/jieba/,解压后运行python setup.py install。 - (3) 手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录,通过
import jieba来引用。 - 知识点补充:
- jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型。
- jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细 待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8。
- jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用 =jieba.lcut 以及 jieba.lcut_for_search 直接返回 list。
3. jieba.analyse的使用:提取关键字
- 第一个参数 表示待提取关键词的文本。
- 第二个参数 topK 表示返回关键词的数量,重要性从高到低排序。
- 第三个参数 withWeight 表示是否同时返回每个关键词的权重。
- 第四个参数allowPOS=() 表示词性过滤,为空表示不过滤,若提供则仅返回符合词性要求的关键词 ,查看:jieba 词性表.txt。
文章出处登录后可见!
已经登录?立即刷新