该文章实验了如何利用Python进行爬取网络视频,看完该文章基本是可以下载出视频的,如有不足请多多包涵
1、爬虫需要使用到的Python库。
I、requests库
II、re库
III、 json
VI、subprocess
第一个库是用来进行网络请求的,通俗点理解就是拿来模拟你去上网的工具。
第二个库是re正则表达,该库是进行信息匹配的,可以在茫茫数据中迅速匹配到我们想要的数据段。
第三个库是将爬取到的字符串信息转换为json格式,便于后续的信息匹配。
第四个库是进行命令行执行命令为后续通过命令行执行命令准备。
2、代码实现。
I. 导入需要用的库。
import requests
import re
import json
import subprocess
II.进行网络发送请求,获取网络数据。
url = 'https://api.bilibili.com/x/player/playurl?qn=32&fnver=0&fnval=4048&fourk=1&voice_balance=1&avid=474270699&bvid=BV1SK411S7K9&cid=869586483'
headers={
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url=url, headers=headers)
json_data = json.loads(response.text)
III. 对获取到的网络数据进行解析,下载需要的网络视频和音频(这里简单说下,该网站的视频和音频是分开的,所以需要分别爬取视频和音频)。
audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0]
video_url = json_data['data']['dash']['video'][0]['backupUrl'][0]
file_name = "demo"
works_name = "requests_video.mp4"
video_name = file_name+".mp4"
audio_name = file_name+".mp3"
audio_url_response = requests.get(url=audio_url, headers=headers)
audio_data = audio_url_response.content
with open(audio_name, mode='wb') as f:
f.write(audio_data)
video_url_response = requests.get(url=video_url, headers=headers)
video_data = video_url_response.content
with open(video_name, mode='wb') as f:
f.write(video_data)
audio_url_response.close()
video_url_response.close()
IV. 最后将获取到的视频和音频进行合拼成一个完整视频即可,最后就是有画面和音频的视频。
cmd = f'ffmpeg -i {video_name} -i {audio_name} -acodec copy -vcodec copy {works_name}'
subprocess.call(cmd,shell=True)
print('完成')
3、总结
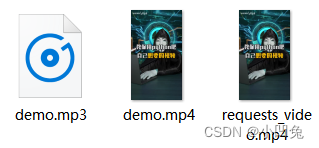
经过上述一番操作就会看到以下图片所示的三个文件,前两个文件分别是音频和无声视频,第三个是合成后有声视频。
希望该文章对你有所帮助,如果可以的话点个免费的赞吧。
文章出处登录后可见!
已经登录?立即刷新