本文用于学习记录
前言
YOLO v5 实现目标检测
一、YOLO v5 环境配置
1.1 安装 anaconda 与 pycharm
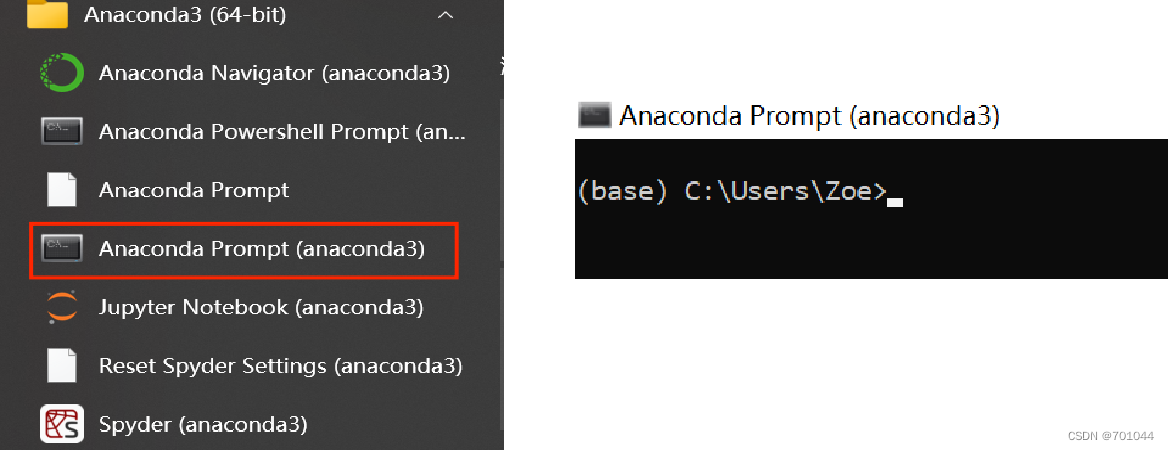
安装完成以后,按下开始键( win 键)在左边就会出现 anaconda3 这个文件夹,可以发现 anaconda 已经安装好了。点击左下图中标红的图标,就可打开 anaconda 的终端如右下图:
2. 创建虚拟环境
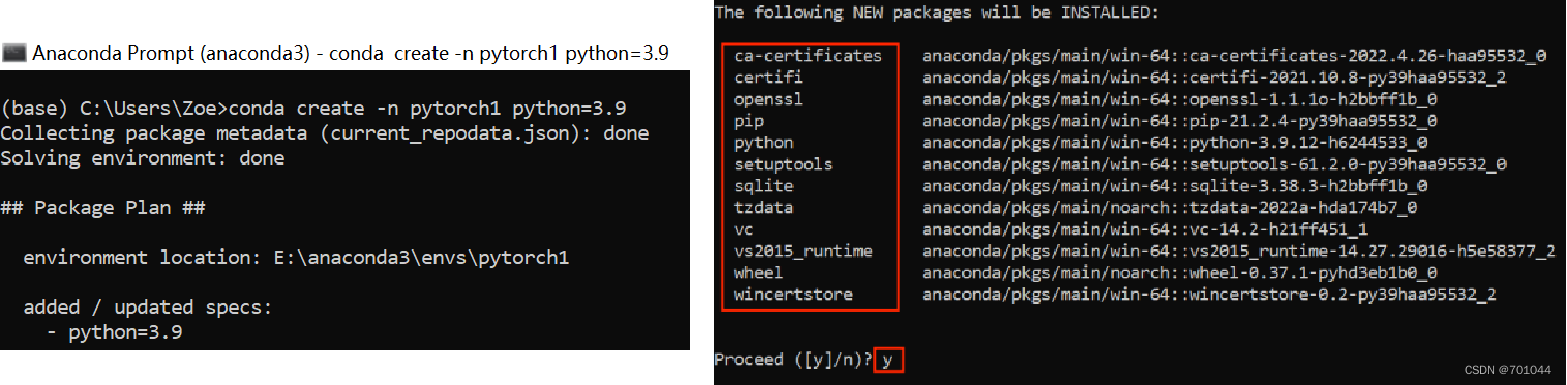
conda create -n 环境名字(英文) python=x.x(python版本)
# 输入 conda create -n pytorch1 python=3.9,在 base 环境中这条命令,就会创建一个新的虚拟环境,这个虚拟环境会安装一些基础的包,如下图所示。询问是否安装的时候,输入 y 就可以创建环境了。
3. 进入 pytorch 环境
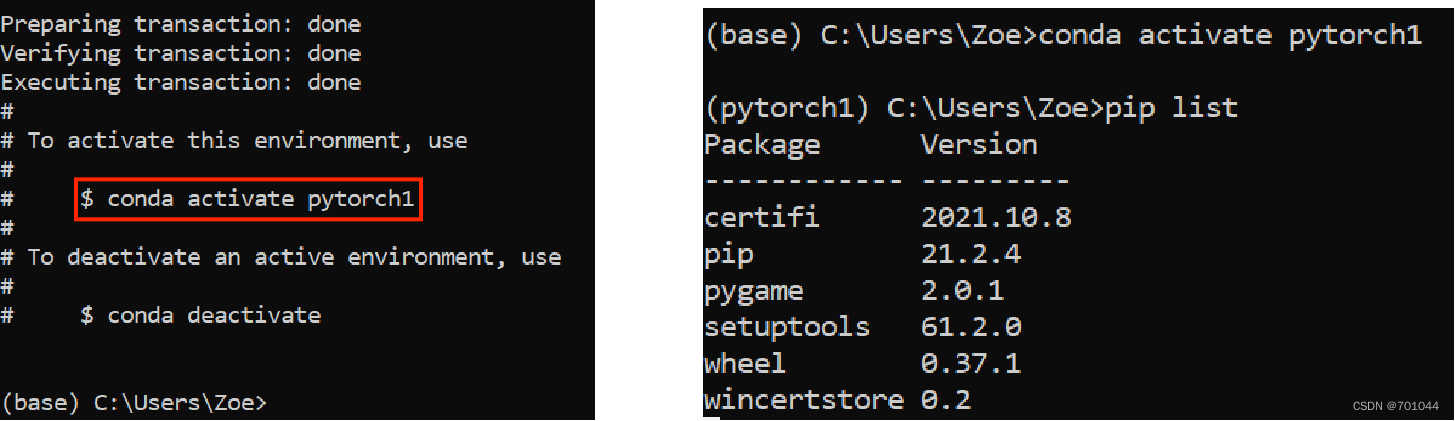
安装完成后显示如下,输入 conda activate pytorch1 进入 pytorch 环境,输入 pip list 查看已经安装的包
4. 安装 pytorch
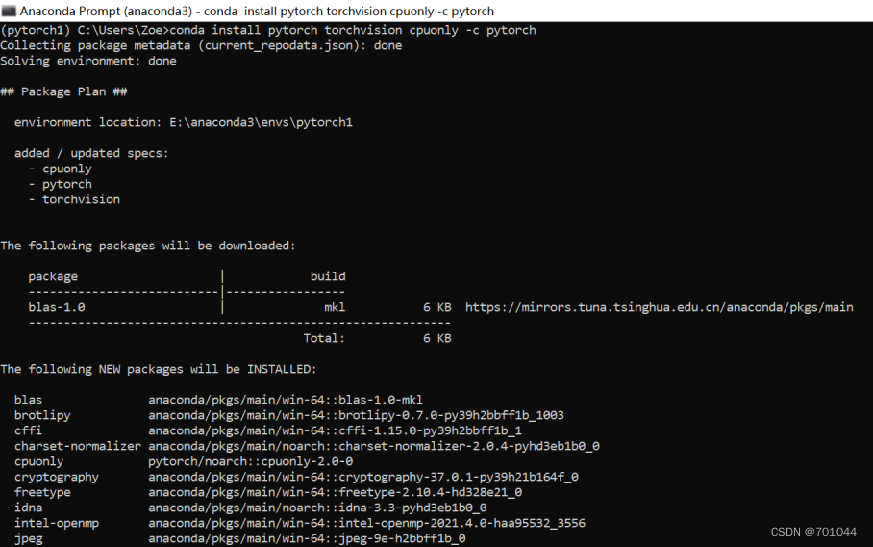
#如果电脑没有英伟达的显卡输入:(在 pytorch 环境下输入)
conda install pytorch torchvision cpuonly -c pytorch
二、YOLO v5 项目下载实现
1. YOLO v5 项目下载
下载地址:https://github.com/ultralytics/yolov5 ,并保存至本地
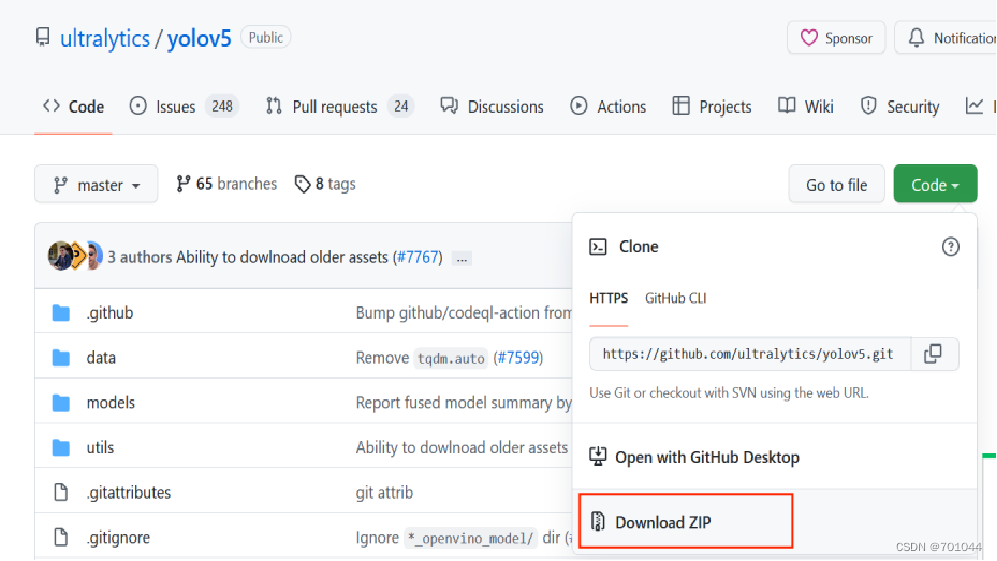
2. 解压 yolo v5 项目并导入 Pycharm
将本地的 yolov5 项目解压至 Pycharm 特定的 Project 项目中,Pycharm 将会自动识别,并完成加载。如图所示,已完成 yolov5 项目的导入,进入 File 下的 Settings 进行 python 解释器设置;
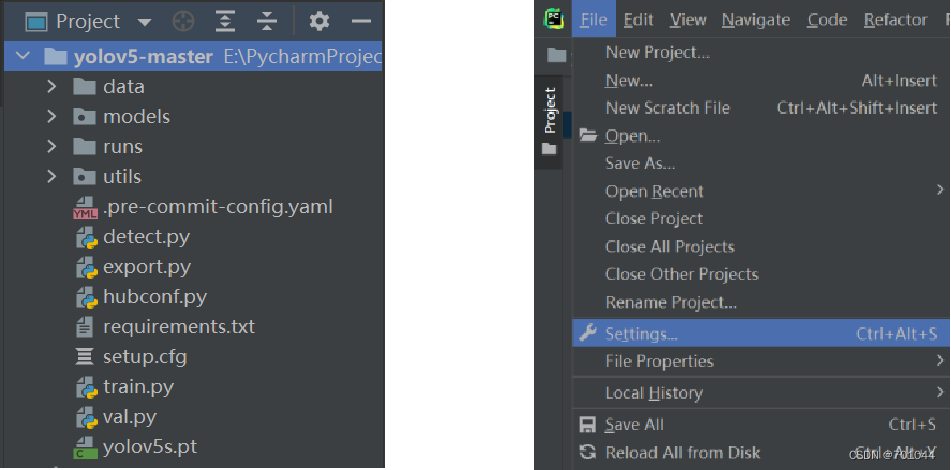
3. 添加 Python interpreter
选择 Settings 中的 Project yolov5-master 下的 Python interpreter,点击右上角标红的设置选择 add 添加;
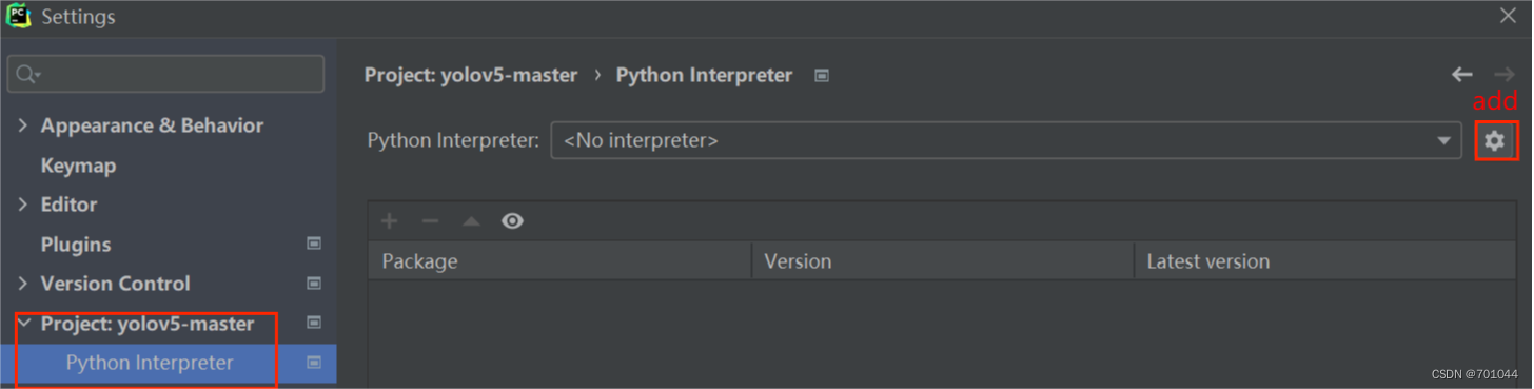
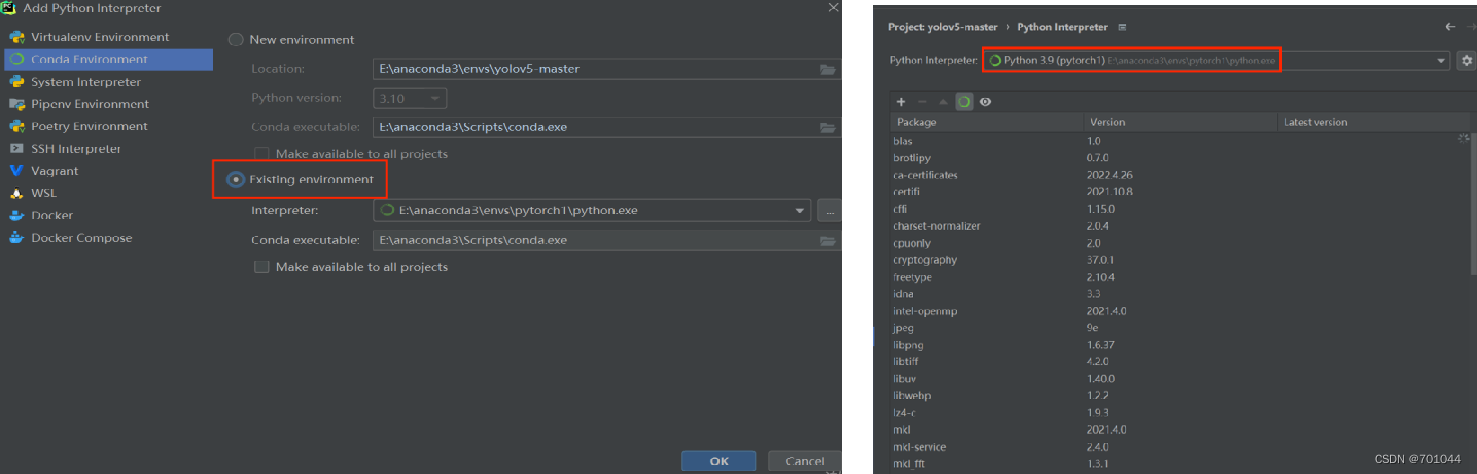
4. 选择 Existing environment
进入 Add Python interpreter 选择 Conda Environment 下标红的 Existing environment,点击 OK 之后 python 解释器设置就配置好了;
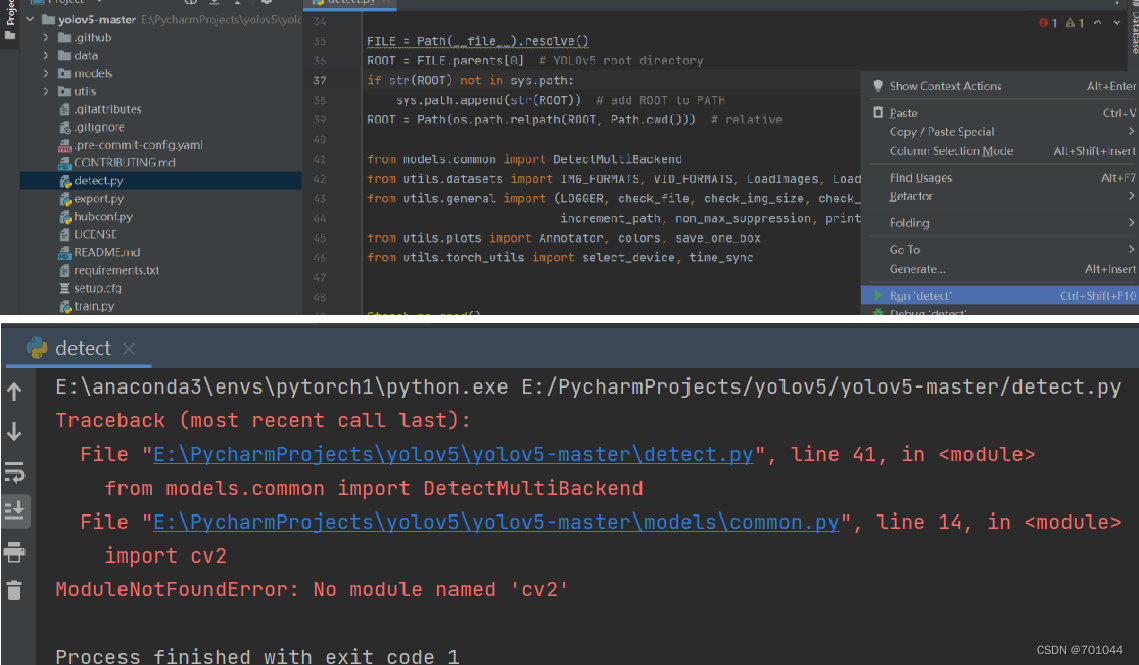
5. 直接运行 detect.py
直接运行 detect.py,会出现以下问题,即缺少依赖包;
6. 配置 requirements.txt
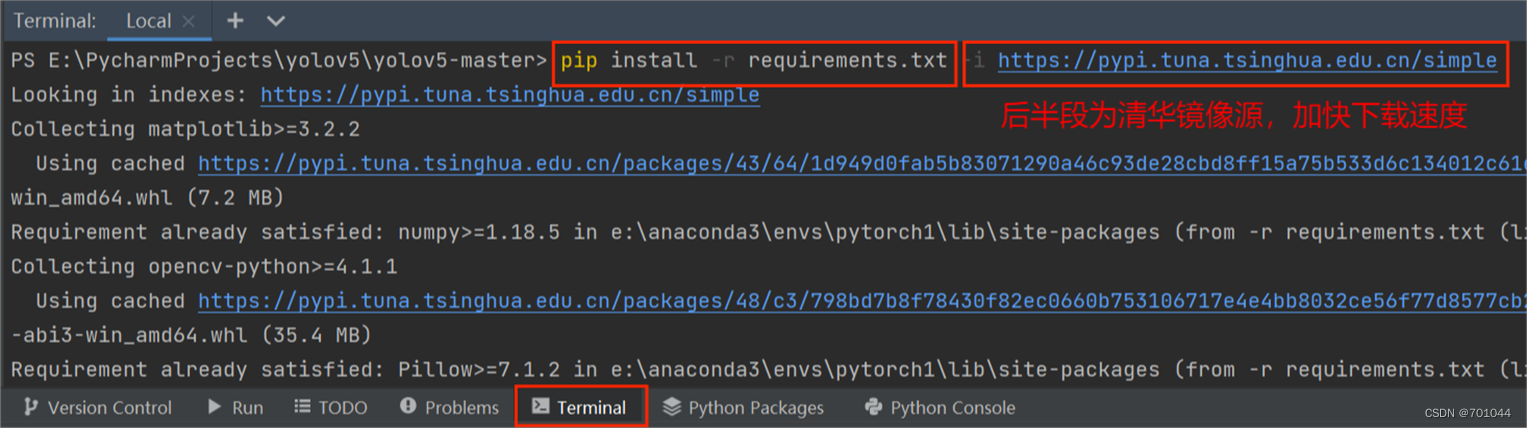
#需要导入的 requirements.txt 文件配置,里面包含 yolo5 运行所需依赖,在 PYcharm 的 Terminal 终端输入:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
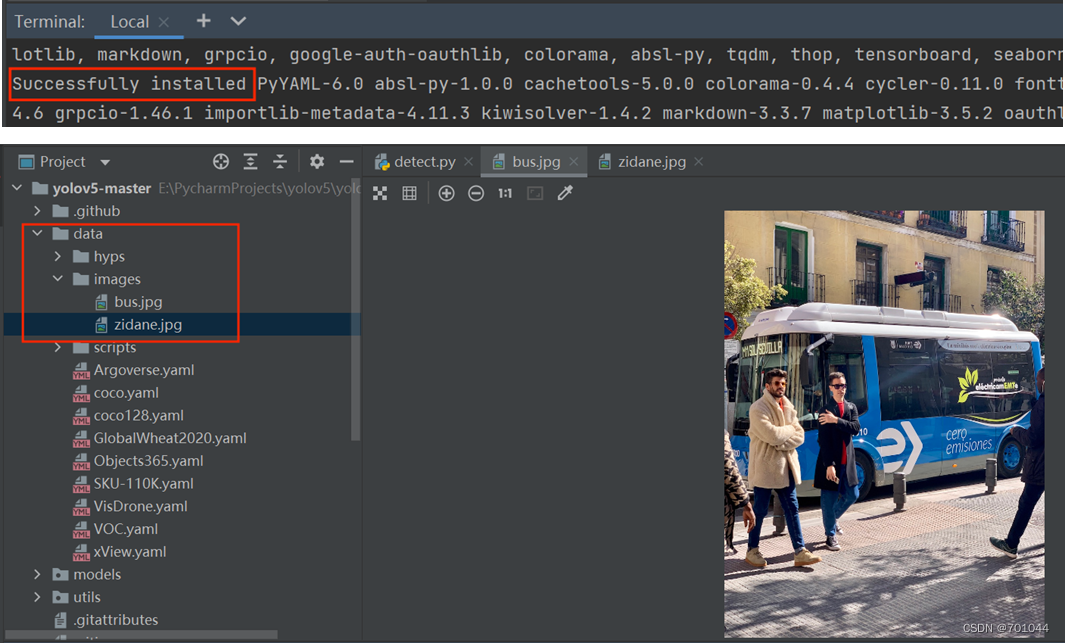
7. 重新运行 detect.py
安装成功后,再次运行 detect.py,将会检测 data/images 中的图片;
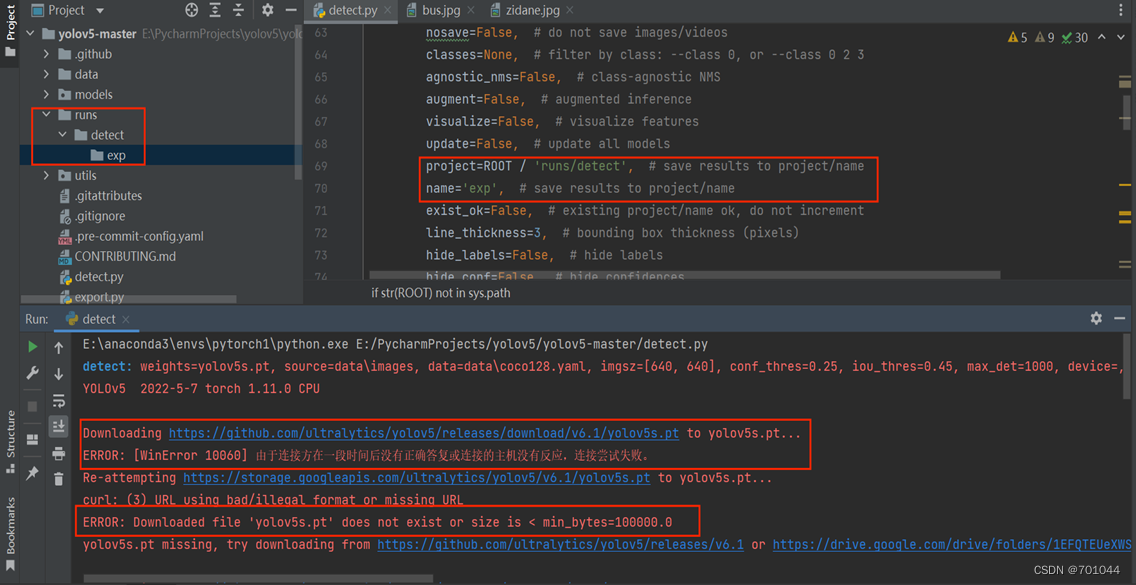
8. yolov5s.pt 权重文件下载超时
运行结果会在 runs 目录下,但这里没有看到所预测的图片,原因是 yolov5s.pt 权重文件下载超时;
9. 下载 yolov5s.pt 权重文件
yolov5s.pt 权重文件下载超时后,可重新运行 detec.py,
如果下载太慢,也可进入https://github.com/ultralytics/yolov5/releases 下载 yolov5s.pt;
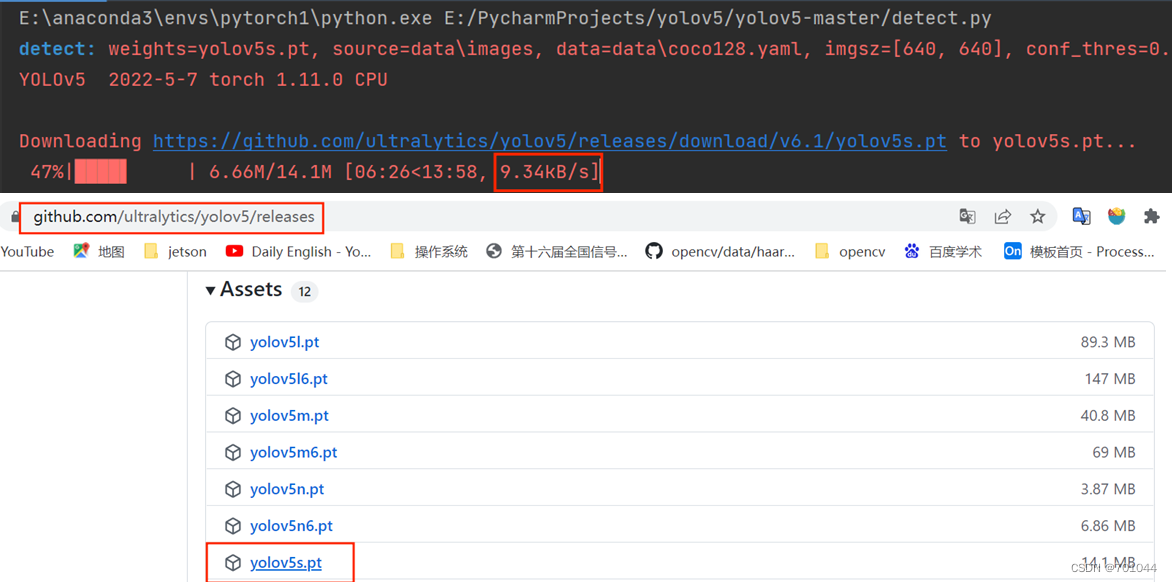
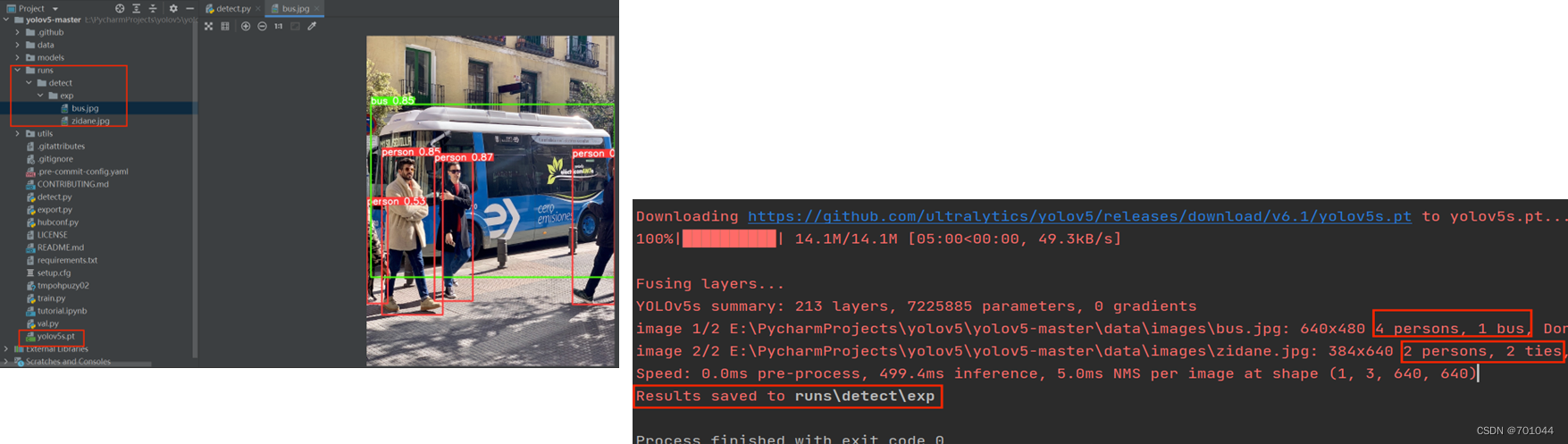
10. detect.py 运行成功
detect.py 运行结果保存到runs\detect\exp 中,
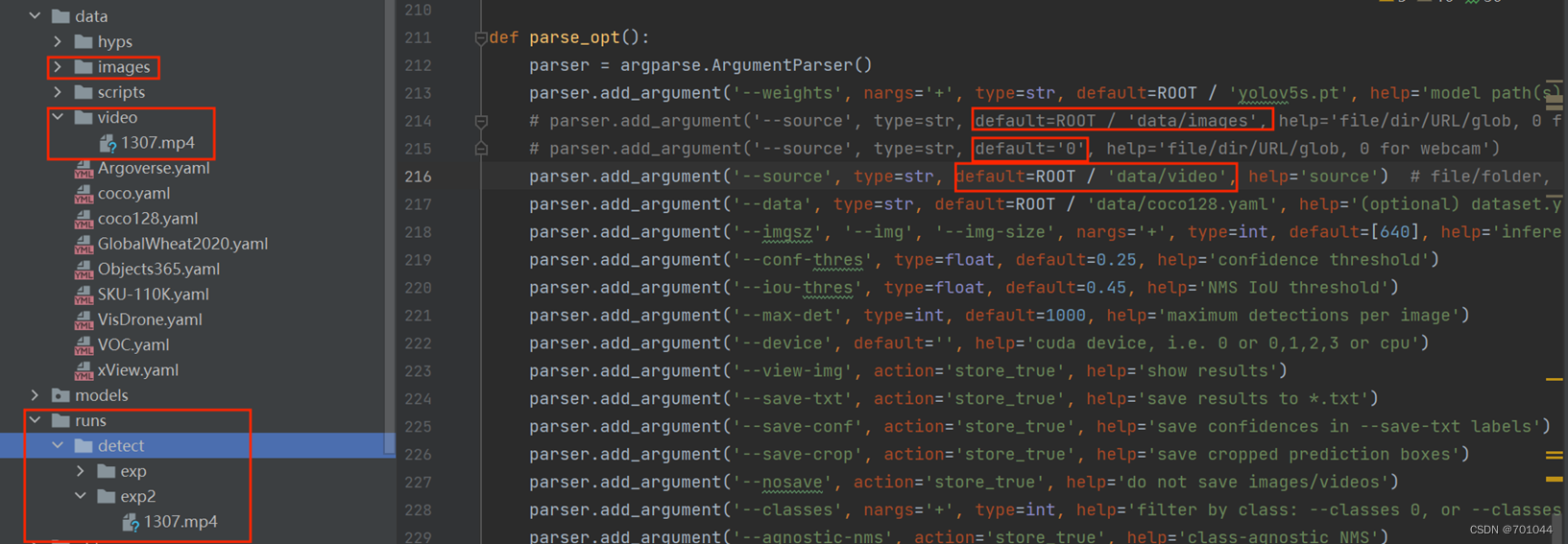
11. 检测视频
前面是检测图片,可以把想检测的视频放入新建的 data/video 的文件夹中,将代码改成 default=ROOT / 'data/video' 即可;
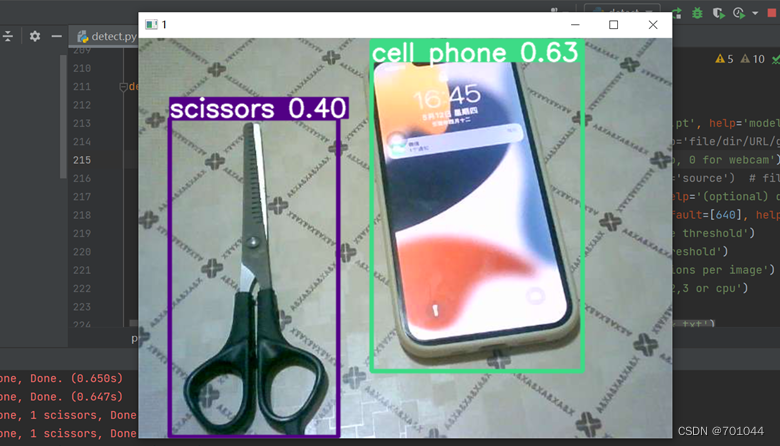
12. 检测摄像头
开启摄像头检测,将代码改成 default='0',便可开启自带摄像头;将代码改成 default='1',便可开启 USB 摄像头,进行动态的实时检测。
三、自制数据集训练自己的模型
1. 新建文件夹存储数据集图片和标签
新建文件夹 train_data,在该文件夹下新建 images、labels两个文件夹,分别在这里两个文件夹下新建 train 文件夹,将采集的图片(采用手机拍照或者走网上搜索你所需要的数据集)放入 train_data/images/train 文件夹,此时 train_dat/labels/train 文件夹是空的。
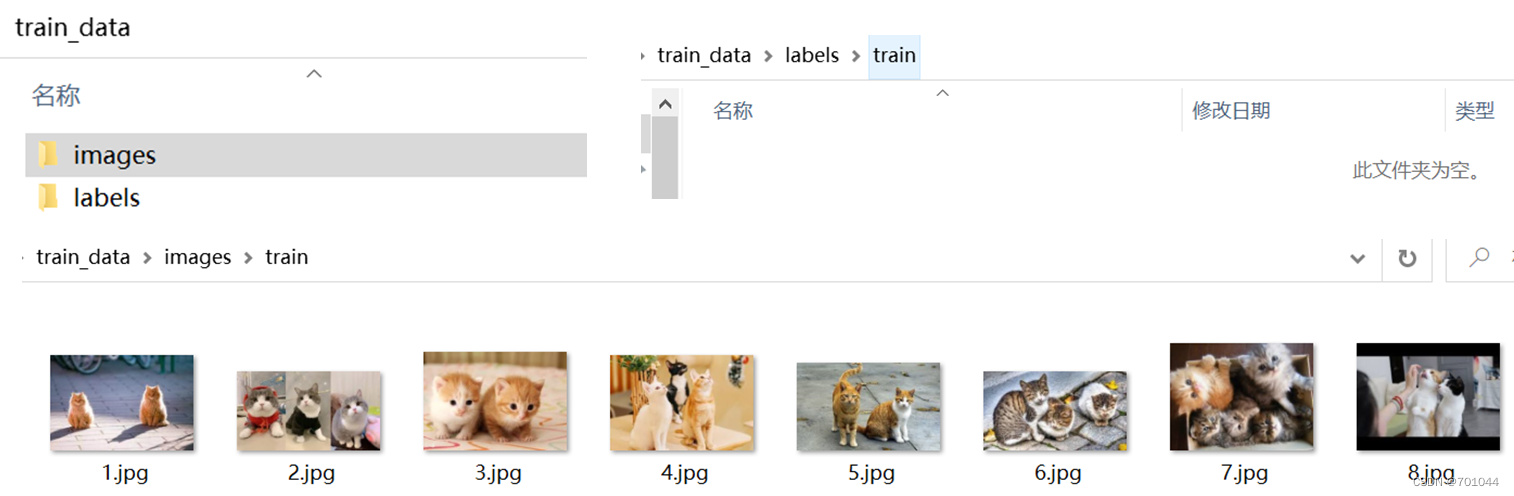
2. 图片标注
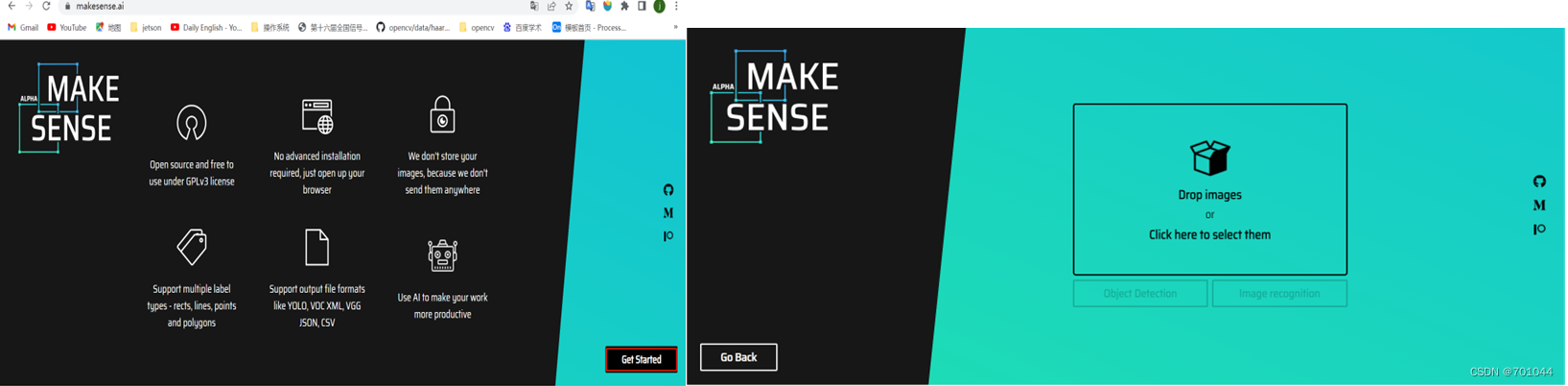
这是一个在线标注工具:https://www.makesense.ai/,点击 Get Started 进入右图;
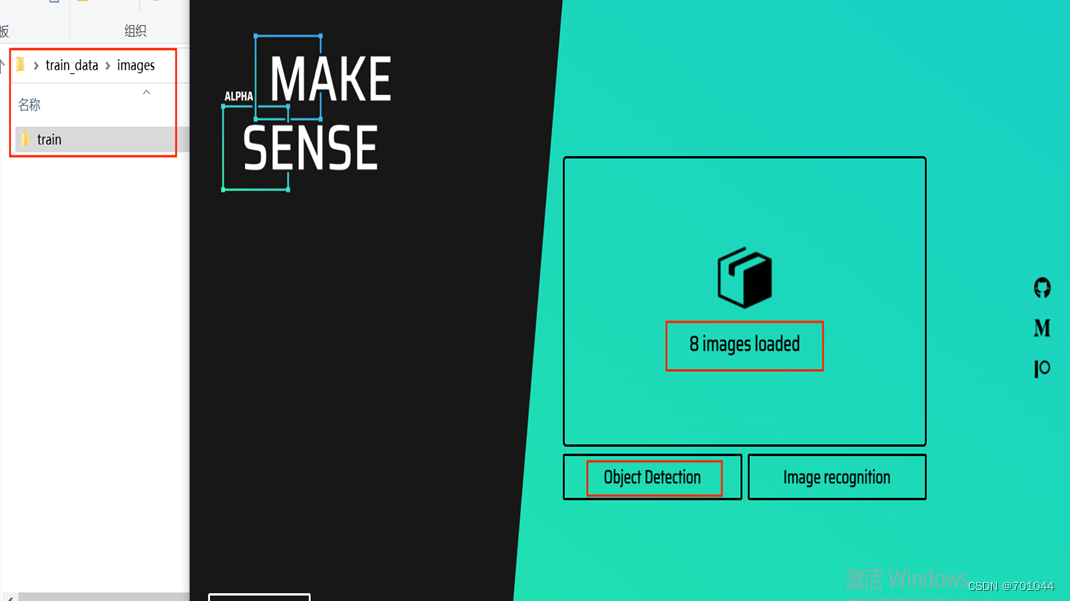
选择自己前面采集的8张要训练的图片,点击 Object Detection ;
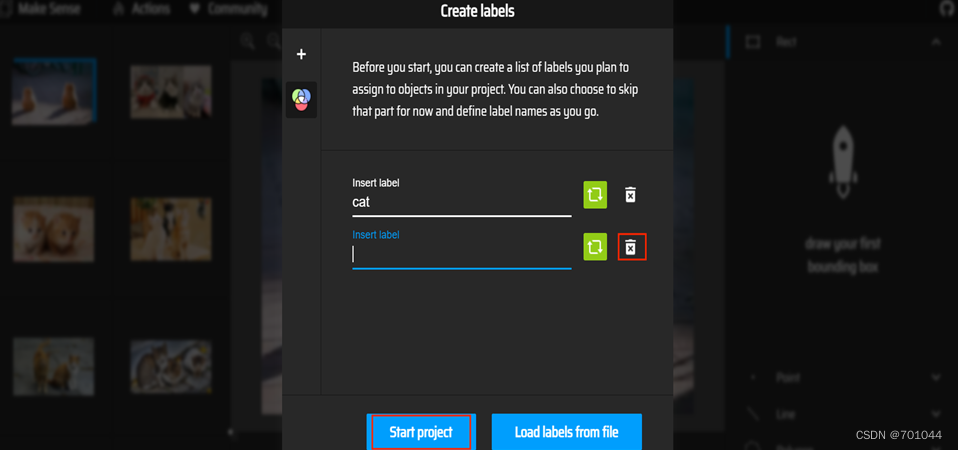
输入你所需要的标签,在这都是猫的图片,如果种类多样,按 Enter 继续添加输入即可,不需要则点击删除;
画框打上标签,给所有图片都打完标签后,选择导出模型标签,如下图所示:
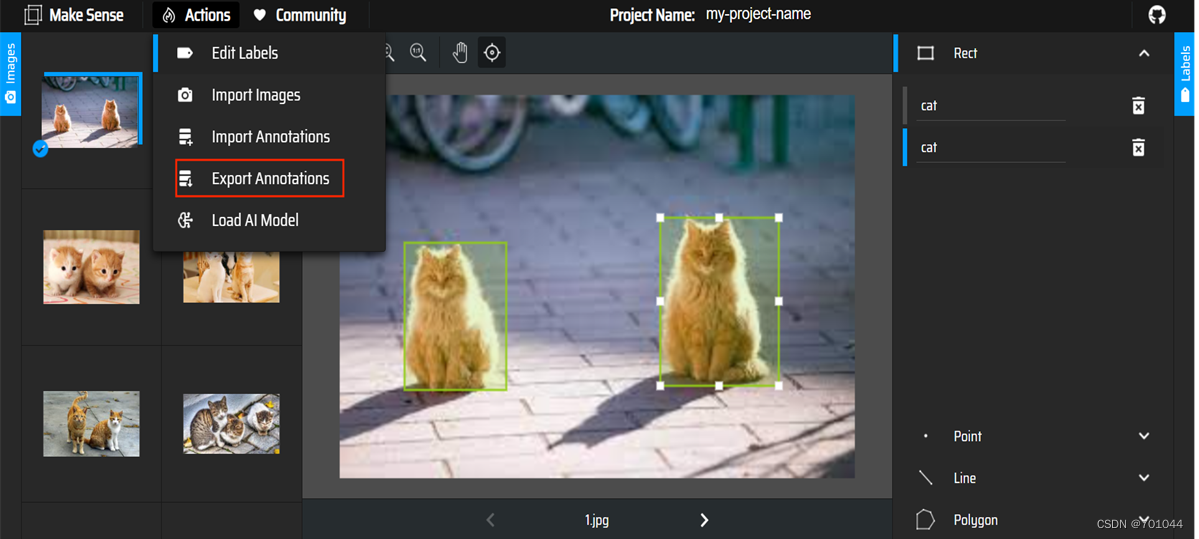
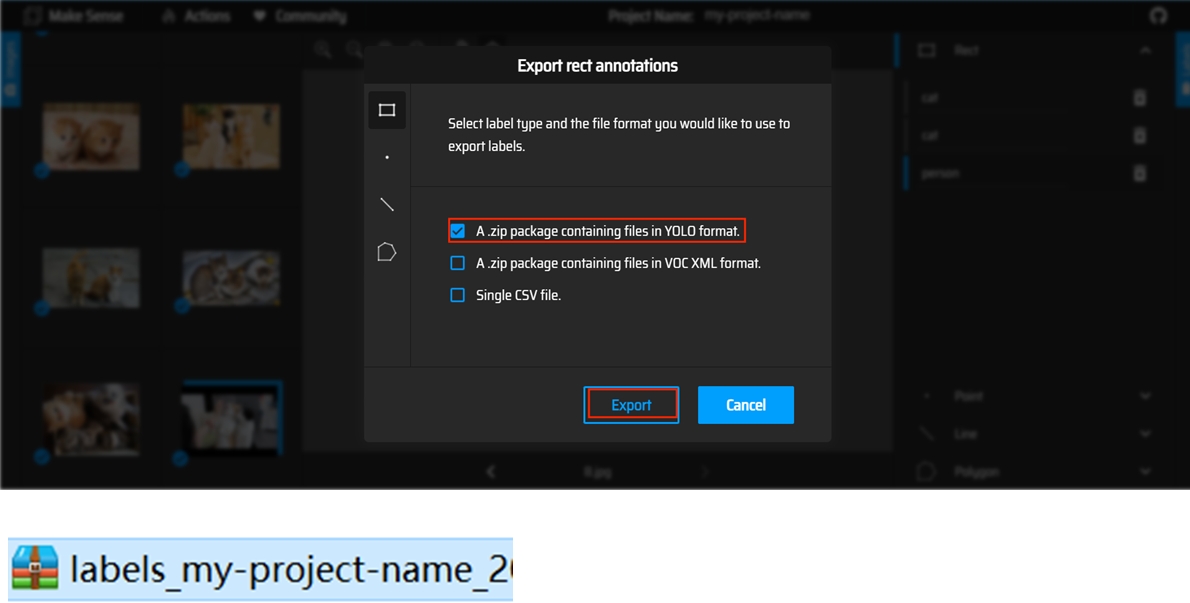
选择第一个 yolo 模型,然年导出,你可以看到你需要的标签已经下载下来了;
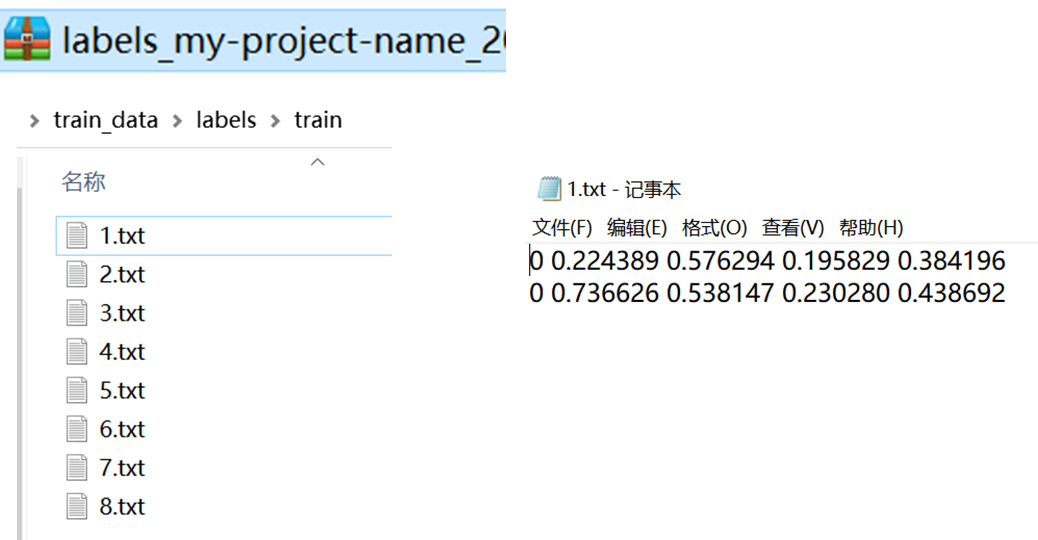
导出后,你可以看到该标签文件夹下有8个已经标注好的 txt 文件,把它们复制到之前空的 train_data/labels/train 文件夹中
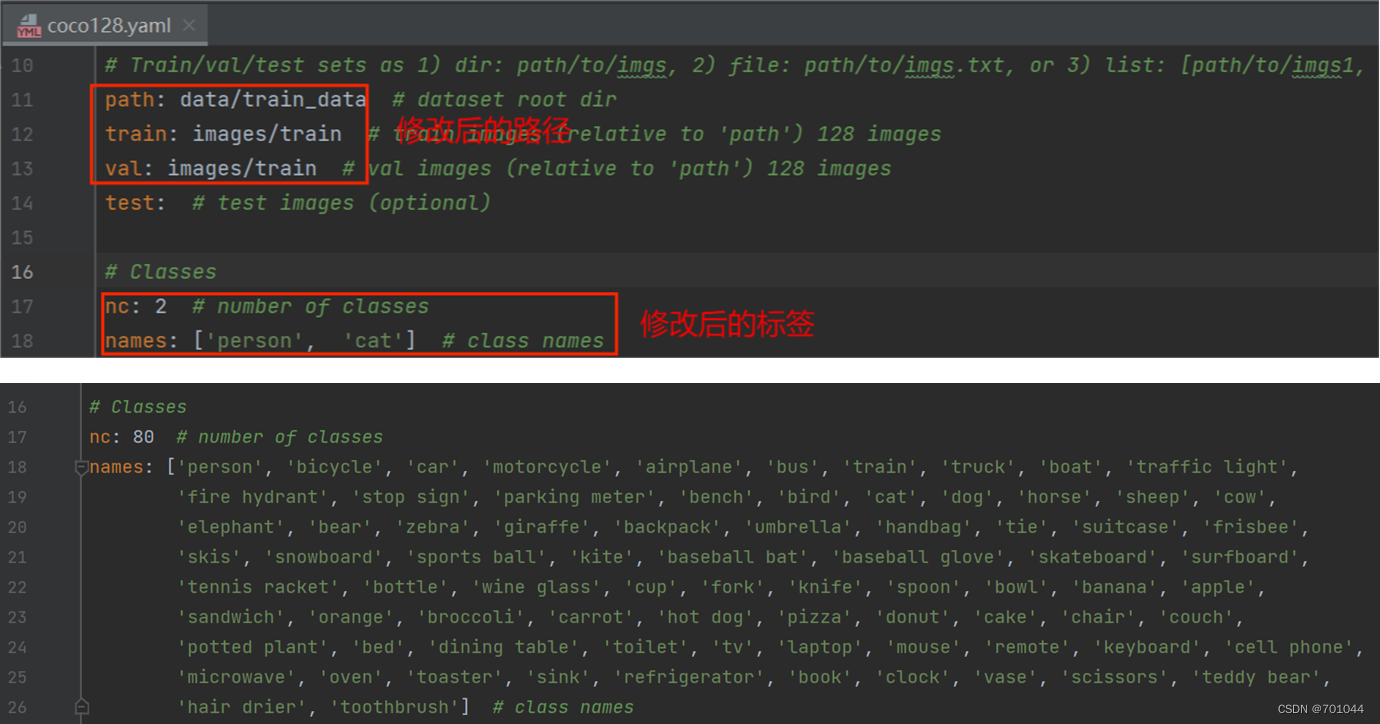
3. yaml 文件修改
复制 coco128.yaml 修改为 cat.yaml ,并对其内容进行修改;
4. 修改并运行 train.py
(这里是由于内存不足报错,)1个 epoch 表示过了1遍训练集中的所有样本;batch-size:1次迭代所使用的样本量;例如定义10000次迭代为1个 epoch,若每次迭代的 batch-size 设为256,那么1个 epoch 相当于过了2560000个训练样本。
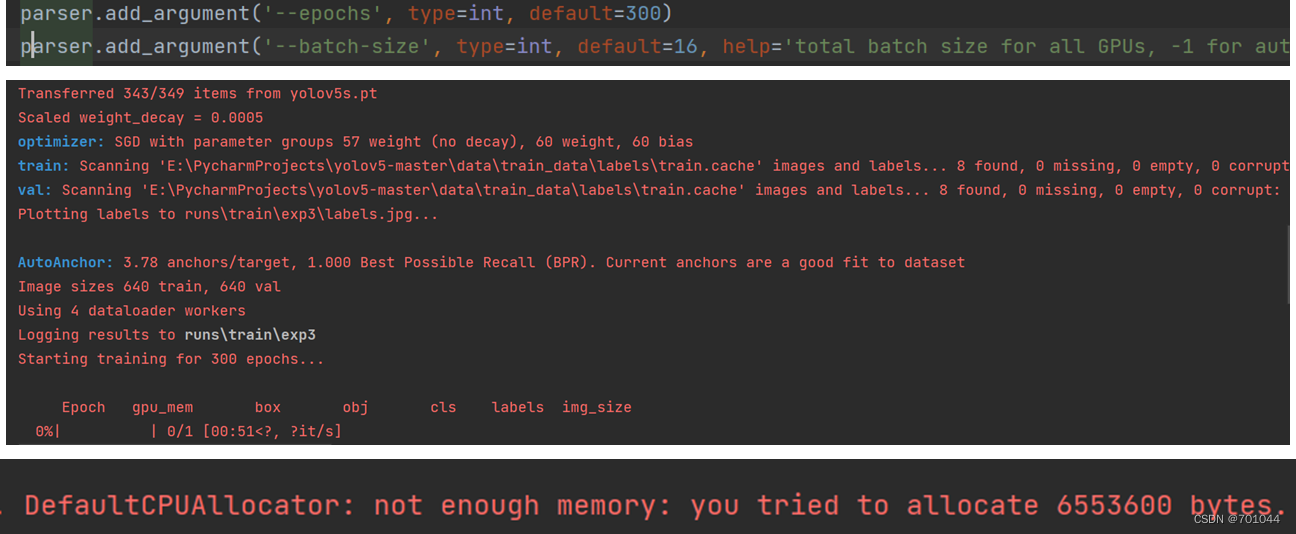
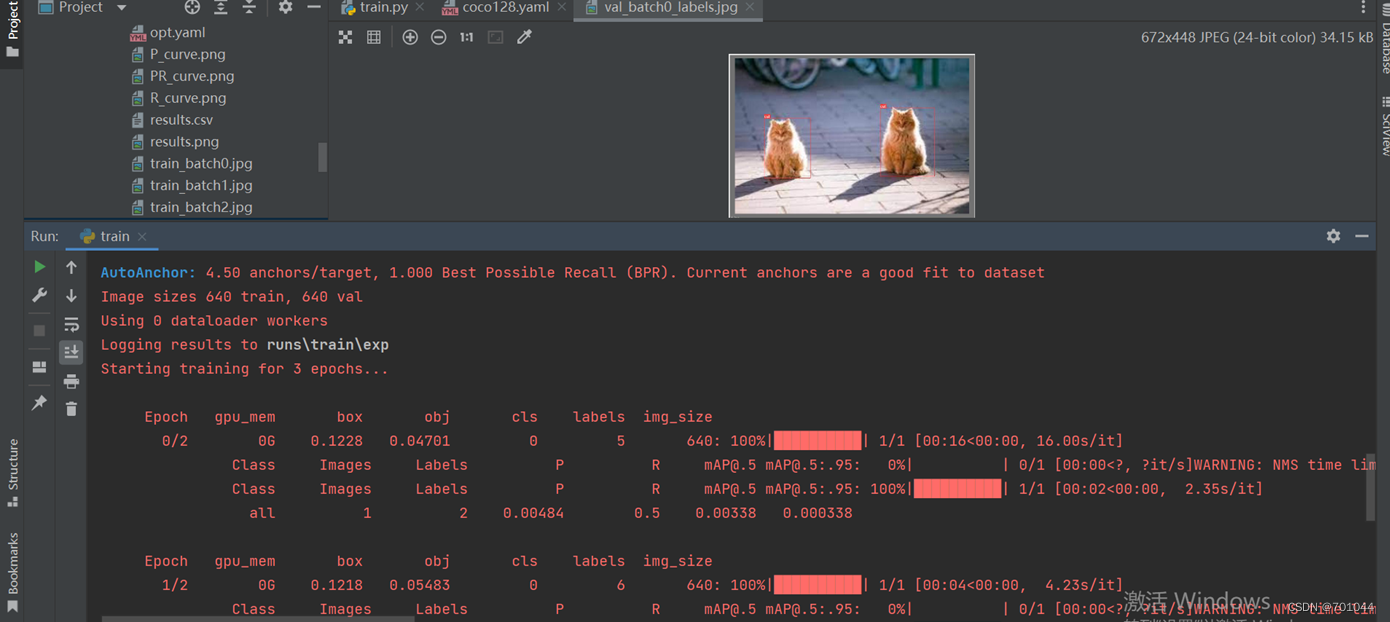
于是把 epoch 设置为3,能成功训练,但这样训练出来的模型就没啥效果,所以还得将 epoch 设置的高点,比较不同值训练后的结果,看哪个效果更好。
总结
以上就是 yolov5 的环境配置、运行与训练过程及其中可能出现的问题与解决办法。
文章出处登录后可见!
已经登录?立即刷新