目录~python
个人昵称:lxw-pro
个人主页:欢迎关注 我的主页
个人感悟: “失败乃成功之母”,这是不变的道理,在失败中总结,在失败中成长,才能成为IT界的一代宗师。
现在都已是互联网时代,各个地方各种销售也早已用上了,不仅方便还很快捷,像在超市购物好后,就会有那个消费单之类的,分分钟就弄好。一个字,绝!!!
计算商品总价
# -*- coding = utf-8 -*-
# @Time : 2022/8/13 13:21
# @Author : lxw_pro
# @File : 计算商品总价.py
# @Software : PyCharm
price1 = input("酸菜方便面:")
price2 = input("牛肉干:")
price3 = input("卫生纸:")
price4 = input("篮球:")
pay = float(input("支付金额:"))
price_total = float(price1)+float(price2)+float(price3)+float(price4)
crash = pay - price_total
print("您本次购物实际消费:%d元;收您:%d元, \
退您:%d元。" % (price_total, pay, crash))
print("收银总计为:%d元" % price_total)
print("收银员:")
print('************************************')
print('单号:21124451655524562')
price_total = 0
name = input("商品名:")
count = input("数量:")
price = int(input('支付金额:'))
total = count * price
price_total = price_total + total
print(name, count , price, total, sep='\t\t')
name = '牛肉干'
count = 3
price = 35
total = count * price
price_total = price_total + total
print(name, count, price, total, sep='\t\t')
name = '卫生纸'
count = 2
price = 6
total = count * price
price_total = price_total + total
print(name, count, price, total, sep='\t\t')
name = '篮球'
count = 1
price = 120
total = count * price
price_total = price_total + total
print(name, count, price, total, sep='\t\t')
print('**************************************')
print('收银合计:\t\t\t\t\t', price_total)
print('您共消费:%d元' % price_total)
print('**************************************')
print('感谢您的惠顾, 欢迎下次再来!\n收银员:')
运行效果如下:
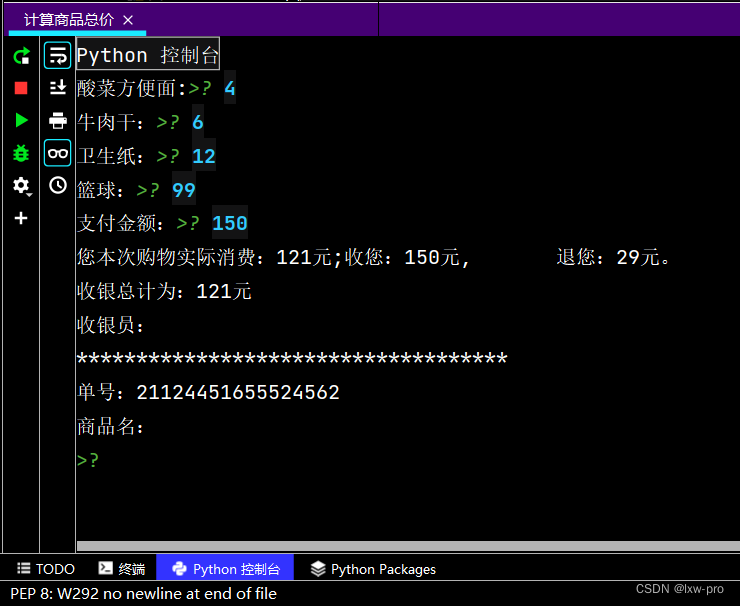
————————————————————————————————————————————
pandas 每日一练:
# -*- coding = utf-8 -*-
# @Time : 2022/8/25 21:10
# @Author : lxw_pro
# @File : pandas-14 练习.py
# @Software : PyCharm
import pandas as pd
import numpy as np
tmp1 = np.random.randint(1, 100, 10)
df1 = pd.DataFrame(tmp1)
tmp2 = np.arange(0, 100, 5)
df2 = pd.DataFrame(tmp2)
tmp3 = np.random.normal(0, 1, 20)
df3 = pd.DataFrame(tmp3)
df = pd.concat([df1, df2, df3], axis=1, ignore_index=True)
df.columns = ['col1', 'col2', 'col3']
print(df[:10])
程序运行结果如下:
col1 col2 col3
0 49.0 0 0.008018
1 40.0 5 1.306242
2 66.0 10 0.456268
3 80.0 15 0.022094
4 84.0 20 -0.645454
5 48.0 25 2.278528
6 77.0 30 -1.172350
7 97.0 35 -0.472123
8 89.0 40 0.527241
9 89.0 45 -0.487878
92、计算第一列数字前一个与后一个的差值
cz = df['col1'].diff().tolist()
for i in cz[:10]:
print(i)
程序运行结果如下:
nan
-9.0
26.0
14.0
4.0
-36.0
29.0
20.0
-8.0
0.0
93、提取第一列位置在1,5,9
tq = df['col1'].take([1, 5, 9])
print(tq)
程序运行结果如下:
1 40.0
5 48.0
9 89.0
Name: col1, dtype: float64
94、查找第一列的局部最大值位置
czz = np.diff(np.sign(np.diff(df['col1'])))
print(np.where(czz == -2)[0]+1)
程序运行结果如下:
[4 7]
95、按行计算df的每一行均值
hjz = df[['col1', 'col2', 'col3']].mean(axis=1)
print(hjz)
程序运行结果如下:
0 16.336006
1 15.435414
2 25.485423
3 31.674031
4 34.451515
5 25.092843
6 35.275883
7 43.842626
8 43.175747
9 44.504041
10 24.885406
11 28.643262
12 30.546387
13 32.927772
14 35.502965
15 38.608620
16 39.676013
17 42.000693
18 44.415029
19 47.931993
dtype: float64
96、对第二列计算移动平均值
ydz = np.convolve(df['col2'], np.ones(3)/3, mode='valid')
print(ydz)
程序运行结果如下:
[ 5. 10. 15. 20. 25. 30. 35. 40. 45. 50. 55. 60. 65. 70. 75. 80. 85. 90.]
97、将数据按照第三列值得大小升序排列
df.sort_values('col3', inplace=True)
print(df)
程序运行结果如下:
col1 col2 col3
6 77.0 30 -1.172350
18 NaN 90 -1.169942
17 NaN 85 -0.998613
16 NaN 80 -0.647974
4 84.0 20 -0.645454
9 89.0 45 -0.487878
7 97.0 35 -0.472123
10 NaN 50 -0.229187
0 49.0 0 0.008018
3 80.0 15 0.022094
2 66.0 10 0.456268
8 89.0 40 0.527241
13 NaN 65 0.855545
19 NaN 95 0.863986
14 NaN 70 1.005930
12 NaN 60 1.092773
1 40.0 5 1.306242
15 NaN 75 2.217240
5 48.0 25 2.278528
11 NaN 55 2.286525
98、将第一列大于20的数字修改为‘高’
df.col1[df['col1'] > 20] = '高'
print(df)
程序运行结果如下:
col1 col2 col3
6 高 30 -1.172350
18 NaN 90 -1.169942
17 NaN 85 -0.998613
16 NaN 80 -0.647974
4 高 20 -0.645454
9 高 45 -0.487878
7 高 35 -0.472123
10 NaN 50 -0.229187
0 高 0 0.008018
3 高 15 0.022094
2 高 10 0.456268
8 高 40 0.527241
13 NaN 65 0.855545
19 NaN 95 0.863986
14 NaN 70 1.005930
12 NaN 60 1.092773
1 高 5 1.306242
15 NaN 75 2.217240
5 高 25 2.278528
11 NaN 55 2.286525
99、计算第二列与第三列之间的欧式距离
print(np.linalg.norm(df['col2'] - df['col3']))
程序运行结果如下:
247.27710730609496
每日一言:
努力的人很多,但不是每个人都会如愿以偿,努力都得不到想要的,那为什么还要努力呢?为了不留遗憾哇!!!
持续更新中…
点赞,你的认可是我创作的
动力!
收藏,你的青睐是我努力的方向!
评论,你的意见是我进步的财富!
关注,你的喜欢是我长久的坚持!

欢迎关注微信公众号【程序人生6】,一起探讨学习哦!!!
文章出处登录后可见!
已经登录?立即刷新