python常用的OCR文字识别与图片定位方式
前言
统一版本
如果想一次性调用成功,最好与本教程所用的版本保持一致
python版本:
3.10
PyCharm版本:PyCharm 2022.1.2
更换pip源
平常使用python自带的pip进行安装是比较慢的,该处推荐几个自己用着比较快的源,可以进行替换
百度源:
https://mirror.baidu.com/pypi/simple
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
如果使用的是命令窗口的形式,只需要在安装的包名后面添加个 -i https://mirror.baidu.com/pypi/simple即可,如下所示
pip install paddlepaddle==2.4.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
如果使用的是PyCharm
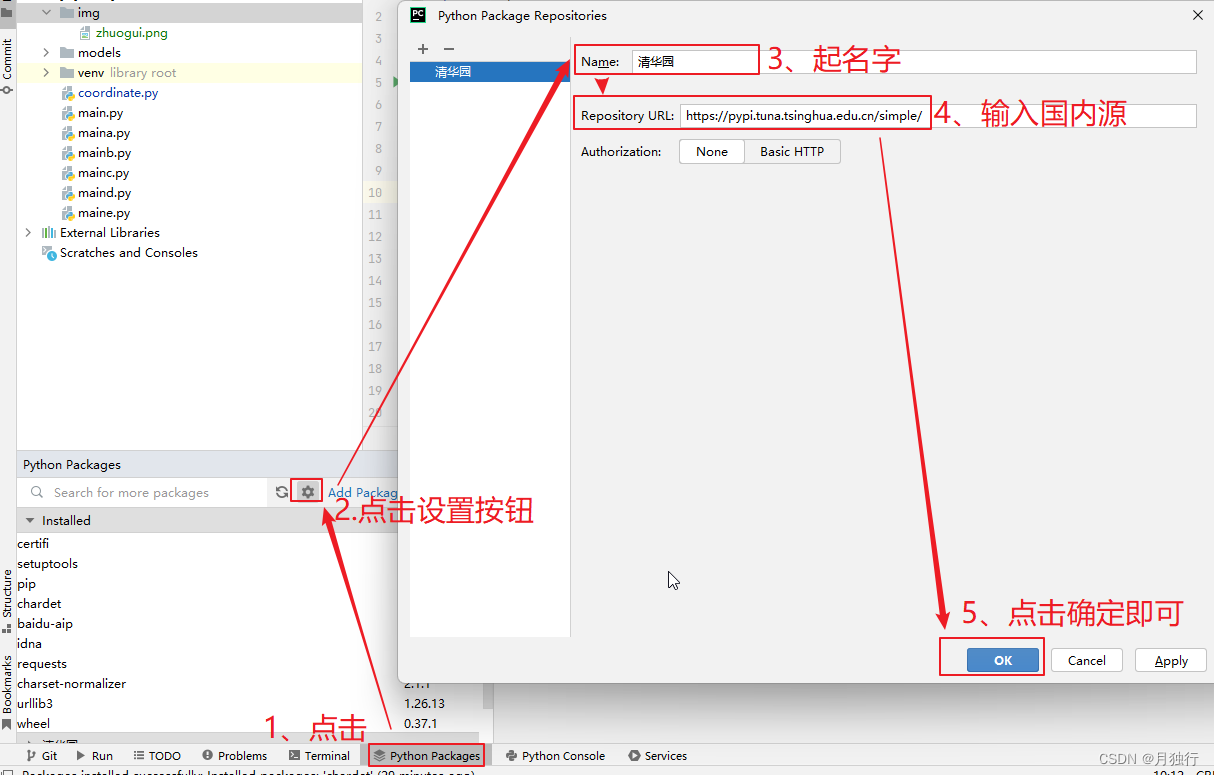
1.在左下角找到
Python Packages
2点击设置按钮
3.起个名字
4.输入源
5.点击确定
6.此时PyCharm中的源添加完毕,在使用Python Interpreter的时候,即可选择对应的源进行下载,提高下载速度
按照如图所示即可
1. Python调用百度文字识别ocr的实现方式
1.1 使用PyCharm安装依赖
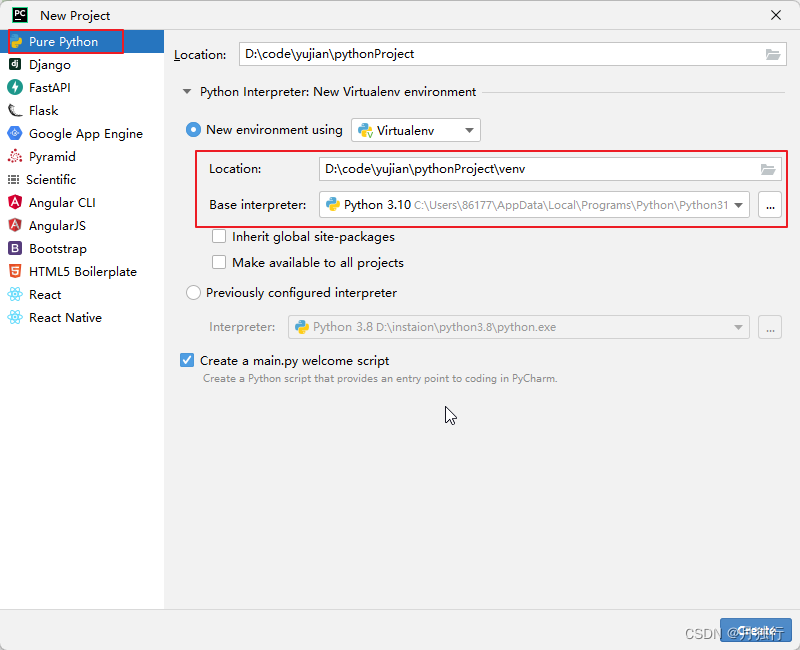
首先,使用PyCharm创建好一个项目,设置如图所示
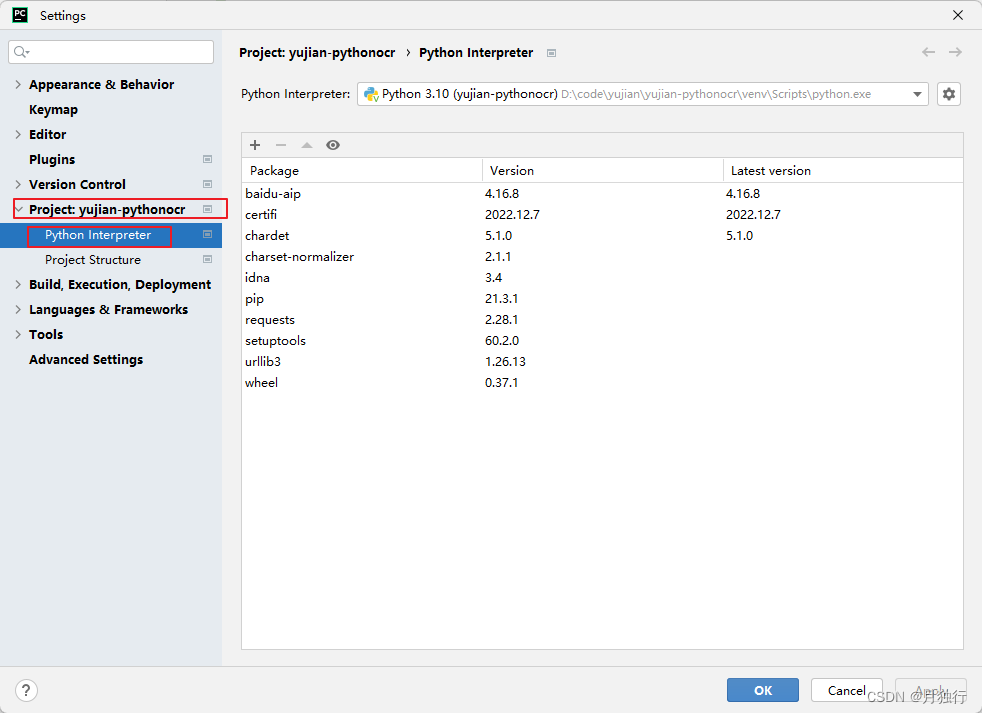
使用PyCharm创建完成一个项目后,开始安装必要的插件,本案例使用的是Python Interpreter。
路径为File–>Settings–>Project:你的项目名称–>Python Interpreter
如下图所示,备注:示例中是已经安装后的,如果是首次创建,则只有三个包
开始安装运行所需要的依赖
baidu-aip
版本为4.16.8
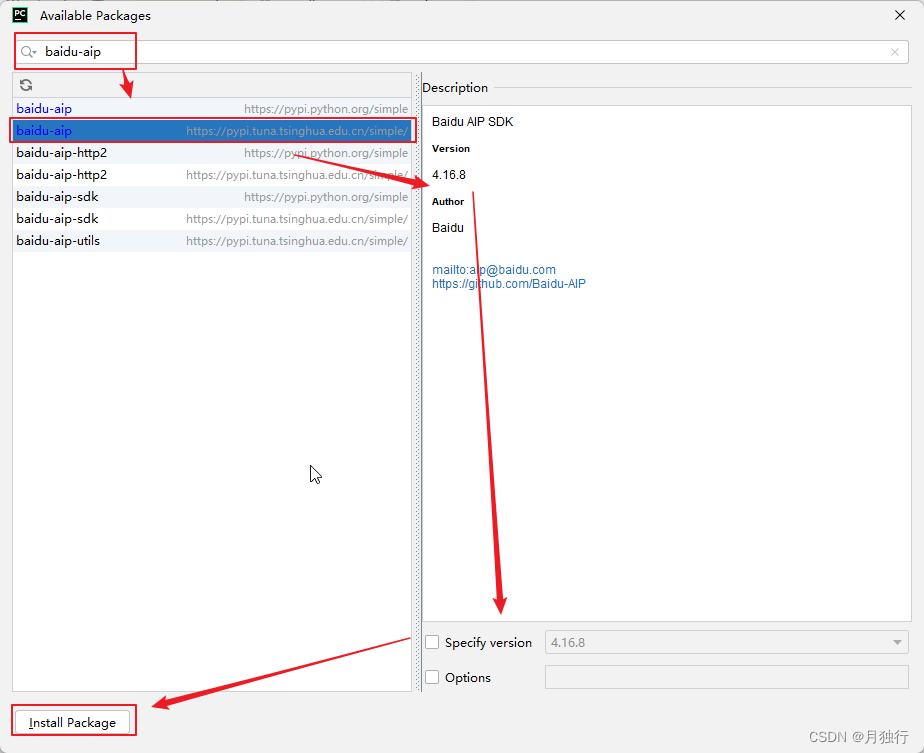
点击图中红框中的 + 号
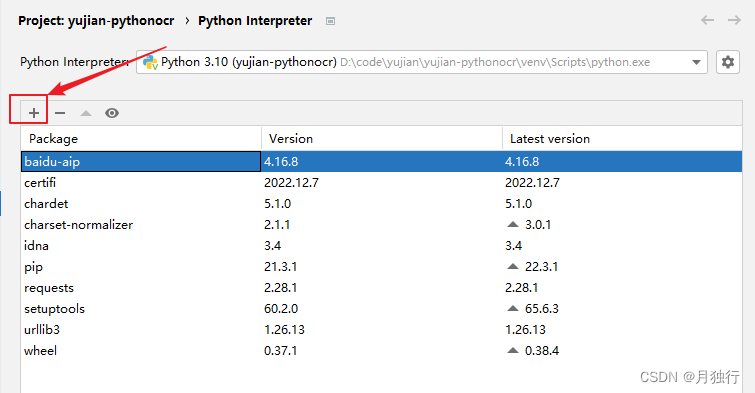
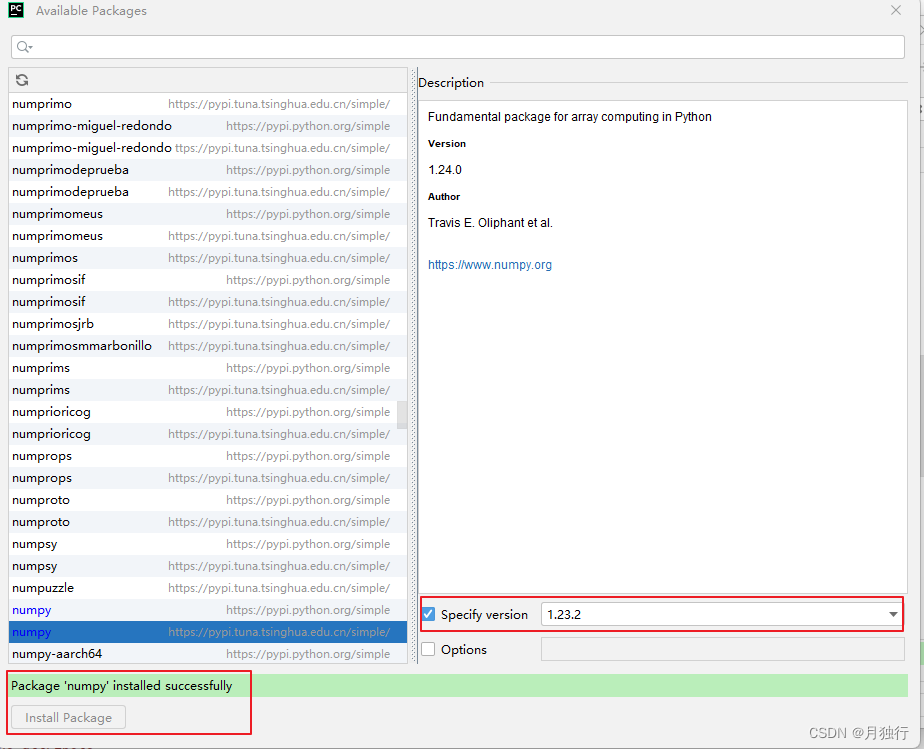
在搜索框中,输入要安装的包名,选择合适的源(此处请参考前言中的更换pip源,如果未添加其他的源,则只显示一个baidu-aip)进行下载,如图所示,可以选择版本,确定好版本后,点击下面的Install Package进行安装即可。接下来的包安装与该方式相同,如果有其他包安装的话,不再进行截图,下载方式参考该处即可
chardet
具体安装详情请参考baidu-api,版本为5.1.0
1.2 代码实现
准备工作
需求自己先在百度工作台上找到对应的APP_ID 、API_KEY 、SECRET_KEY
具体怎么找请自行百度
经过前面的步骤,已经安装了启动代码所需要的依赖,此时,把该代码复制到自己的项目中,稍作修改即可
import os.path
from aip import AipOcr
if __name__ == '__main__':
""" 你的 APPID AK SK """
APP_ID = '你的APP_ID'
API_KEY = '你的API_KEY '
SECRET_KEY = '你的SECRET_KEY '
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
""" 相对路径,在项目跟路径下,创建个img文件夹,然后文件夹中有个zhuogui.png图片,用来进行测试是否可用 """
img_dir_path = r'img'
imagepath = os.path.join(img_dir_path, 'zhuogui.png')
with open(imagepath, 'rb') as fp:
"""识别到信息以字典形式返回"""
dic = client.general(fp.read())
print(dic)
"""遍历字典与想要的文案对比如果对比到就返回坐标"""
exit(0)
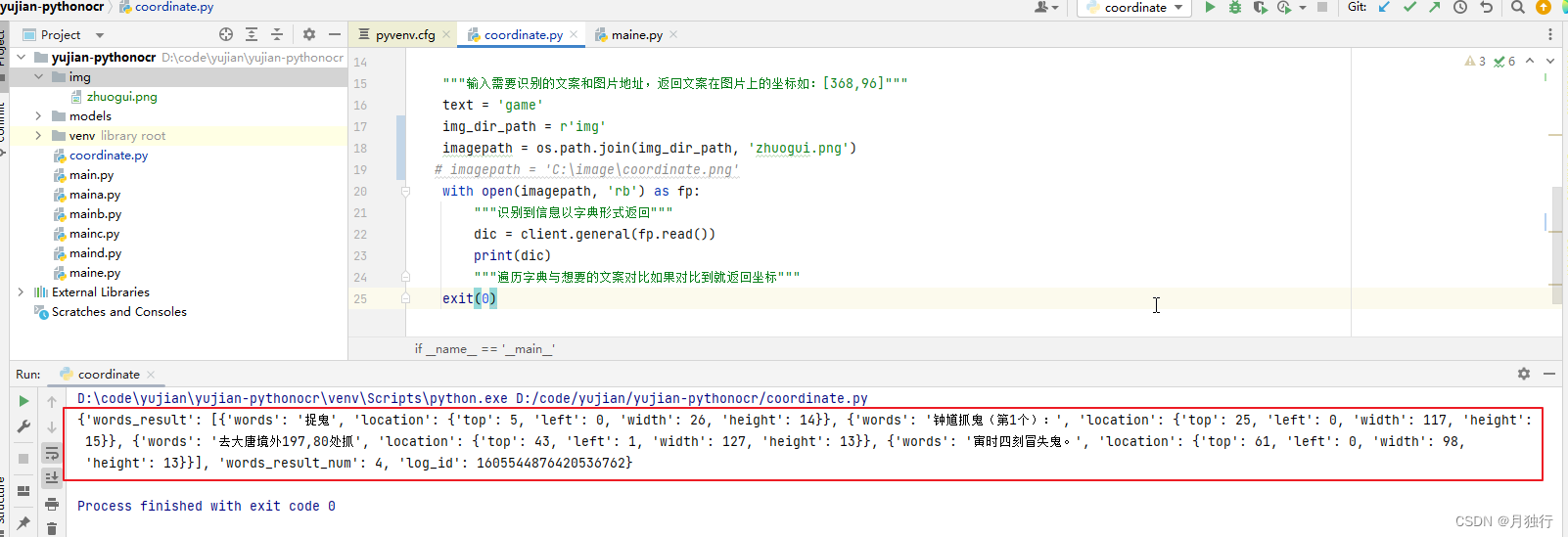
1.3 运行结果展示
效果如下图所示
2. Python实现图片匹配与定位
该实现方式适用于以下场景:
如给定一张小图片,判断该图片是否在另一张图片中;或者在一张大图片中,截出来一小部分图片,然后定位该图片在大图中的位置
2.1 安装依赖
在运行项目前,需要先安装如下依赖,具体安装方式,请参考标题1中的baidu-aip的方式进行安装
aircv
版本为1.4.6
opencv-python
版本为4.6.0.66
2.2 python代码实现
import aircv as ac
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
# 源文件,要在该图片中进行查找,被注释的方式为java传参
# imsrc = ac.imread(sys.argv[1])
imsrc = ac.imread('D:\code\yujian\yujian-admin\src\main\\resources\static\image\coordinate.png')
# 查找的图标,需要查找的图标,被注释的方式为java传参
# imobj = ac.imread(sys.argv[2])
imobj = ac.imread('D:\code\yujian\yujian-admin\src\main\\resources\static\image\c0002.png')
# {'confidence': 0.5435812473297119, 'rectangle': ((394, 384), (394, 416), (450, 384), (450, 416)), 'result': (422.0, 400.0)
# confidence:匹配相似率
# rectangle:匹配图片在原始图像上四边形的坐标
# result:匹配图片在原始图片上的中心坐标点,也就是我们要找的点击点
# similarity = ac.imread(sys.argv[3])
# match_result = ac.find_template(imsrc, imobj, 0.70)
match_result = ac.find_template(imsrc, imobj, 0.70)
if match_result is not None:
match_result['shape'] = (imsrc.shape[1], imsrc.shape[0]) # 0为高,1为宽
print(match_result);
2.3 运行结果展示
如下图所示,返回小图片在大图片中的坐标位置

3.python调用PaddleOCR
详细信息,可去飞桨官网进行查看,本教程只介绍简单的使用与安装
3.1 安装依赖
在运行项目前,需要先安装如下依赖,具体安装方式,请参考标题1中的baidu-aip的方式进行安装
paddlepaddle
版本为2.4.1
paddleocr
版本为2.6.1.2
备注:
1.安装包较大,时间较长,PyCharm导入时间也长,耐心等待即可
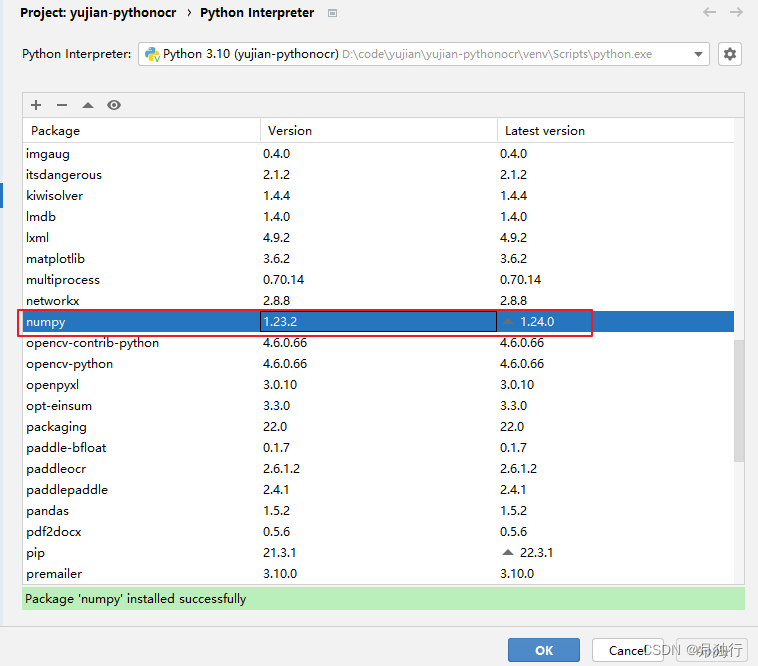
2. 安装完成后,可以先看下numpy包的版本,如果是1.24.0,则更换为1.23.2即可,否则运行时会报错
3.2 python中的代码
import os
from paddleocr import PaddleOCR
import cv2
from math import *
import numpy as np
def img_match(img_address):
ocr = PaddleOCR(use_angle_cls=False, lang="ch", use_gpu=False)
# 该处注释掉了其他的字库,如果需要下面的字库,可在github上自行下载,该教材以上面的简单字库为例,复制即用
#ocr = PaddleOCR(use_angle_cls=True, lang="ch",
# rec_model_dir='../models/ch_PP-OCRv3_rec_slim_infer/',
# cls_model_dir='../models/ch_ppocr_mobile_v2.0_cls_slim_infer/',
# det_model_dir='../models/ch_PP-OCRv3_det_slim_infer/')
src_img = cv2.imread(img_address)
h, w = src_img.shape[:2]
big = int(sqrt(h * h + w * w))
big_img = np.empty((big, big, src_img.ndim), np.uint8)
yoff = round((big - h) / 2)
xoff = round((big - w) / 2)
big_img[yoff:yoff + h, xoff:xoff + w] = src_img
# 文字识别
matRotate = cv2.getRotationMatrix2D((big * 0.5, big * 0.5), 0, 1)
dst = cv2.warpAffine(big_img, matRotate, (big, big))
result = ocr.ocr(dst, cls=True)
results = ""
for text in result:
for value in text:
results = results + str(value[1])
print(results)
if __name__ == '__main__':
img_dir_path = r'img'
imagepath = os.path.join(img_dir_path, 'zhuogui.png')
img_match(imagepath)
# 此处可以更换成字符串的绝对路径,如果更换为绝对路径的话,上面三行需要删除
# img_match("G:\\360MoveData\\Users\\86177\\Desktop\\zhuogui.png")
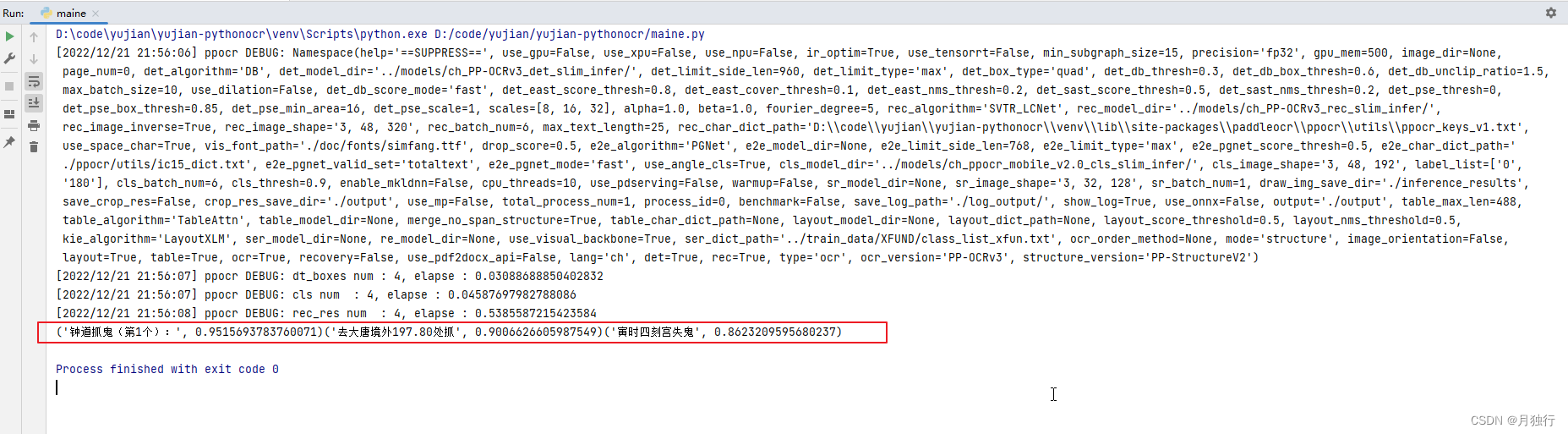
3.3 执行结果
正确执行结果如下(如果执行的时候报错,请看3.4 运行报错(所踩的坑))
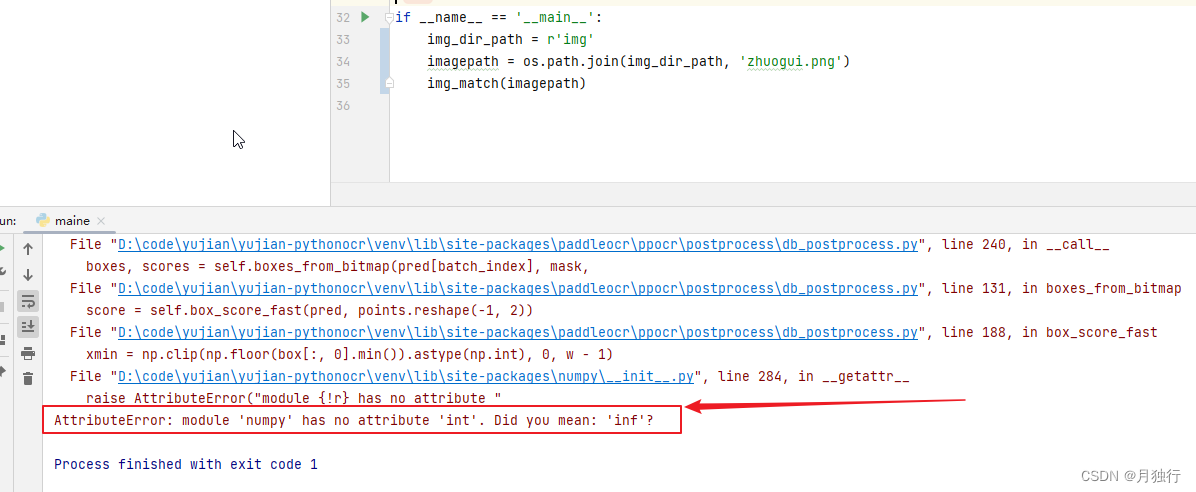
3.4 运行报错(所踩的坑)
如果遇到该报错,请查看安装的依赖的numpy,更换成1.23.2即可
文章出处登录后可见!