上一节主要介绍了PointNet分类,本节将进一步介绍PointNet++点云分类。本节仍然参考Github上的源码进行介绍,PointNet采用全局最大值池化的方式对全体点云进行了特征抽取,这导致了对局部特征的考虑不足。PointNet++通过分组采用PointNet的方式对局部特征进行了提取。GitHub地址为GitHub – yanx27/Pointnet_Pointnet2_pytorch: PointNet and PointNet++ implemented by pytorch (pure python) and on ModelNet, ShapeNet and S3DIS.。 PointNet文章作者关于三维物体检测的讲解请参考3D物体检测的发展与未来 – 深蓝学院 – 专注人工智能与自动驾驶的学习平台。
文中涉及到PointNet的地方请参考上一篇文章的详细介绍三维目标检测 — PointNet详解(一)_Coding的叶子的博客-CSDN博客。
1 代码环境部署
conda create -n torch16cu101 python=3.7
conda activate torch16cu101
pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
pip install tqdm
git clone https://github.com/yehx1/Pointnet_Pointnet2_pytorch.git
cd Pointnet_Pointnet2_pytorch
python train_classification.py --model pointnet2_cls_ssg --log_dir pointnet2_cls_ssg2 数据介绍
以Pointnet的modelnet40为例,其点云文件中含有x、y、z、normal_x、normal_y、normal_z,前三个为坐标,后三个为法向量。关于txt存储的点云文件格式请参考点云格式介绍(三)_Coding的叶子的博客-CSDN博客。样例文件下载地址:modelnet40点云样例数据-深度学习文档类资源-CSDN下载。
解压后文件主要包含:
(1)各个类别的点云,每个点云文件共有10000个点。分别存储在以类别名称命名的为文件夹中,共40个类别的文件夹。
(2)filelist.txt中列举了全部点云文件的文件名,共12311个点云文件。
(3)modelnet40_train.txt中列举了用于训练的点云文件名,共9843个点云文件,占比80%。
(4)modelnet40_test.txt中列举了用于测试的点云文件名,共2468个点云文件,占比20%。
PointNet模型的输入为点云points和标签targets。其中,points的维度为Bx3xN,B为batch_size,3为点云坐标,N为点云个数。如果使用法向量(use normls),则points的维度维Bx6xN。模型会通过截断或者最远点采样截取1024个点,即N=1024。points还会经过中心归一化和随机增强等操作。标签targets维度为Nx1,即各个类别对应的标签序号。
3 SA(Set Abstraction)模块
SA(Set Abstraction)模块使PointNet++中的核心模块,主要包含随机采样、分组和PointNet特征提取三个步骤。首先,SA模块会利用最远点采样在原始点云中随机采样npoint个点,以采样到的点为中心点在指定半径内球体内选择nsample个点。以这nsample个点为一组,对每一组按照PointNet的方式提取特征,并用最大池化得到每一组点的全局特征。假设特征数量为nfeature,那么SA模块返回的特征维度为nfeature X npoint,同时SA模块会返回最远点采样的坐标,以便于进一步连续进行SA操作。
可以看到,SA模块会对点云进行随机采样,一般采样会降低点云中点的数量。连续的SA操作会使点的数量逐渐下降,这类似与图像当中连续卷积操作降低特征图的尺寸。既然点的数量下降了,那么特征通道的数量需要增加以保持足够的维度去表达原始的点云信息。因此,在模型中SA输出的点云数量下降,同时通道数逐步增加。
另一方面,点数量的下降会导致点和点之间的平均距离越来越大,也就是点会更加稀疏。那么分组过程中的球体半径在连续SA过程中需要设置越来越大。由于点数的下降,分组过程也将更多的点分到一组,这样上面的nsample也会增加。
通过SA操作,PointNet++充分提取了分组的点云特征,也就是局部点云特征。
4 模型简介
PointNet++模型结构如下图所示。
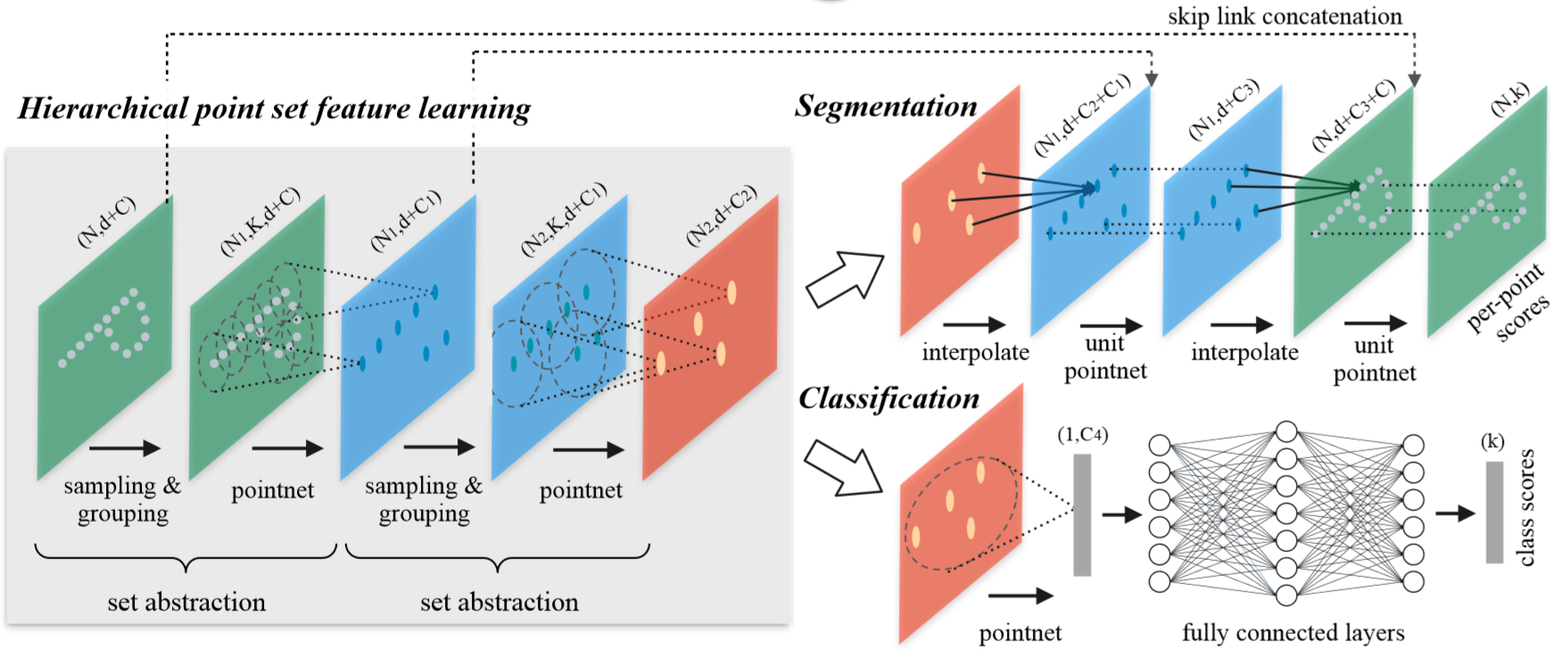
PointNet++网络提取特征的各个步骤如下:
(1)SA1:输入为xyz坐标值和法向量,以法向量作为原始特征,也可以设置不输入法向量。这里假设不输入法向量,那么输入维度为3×1024(N=1024)。随机最远点采样的点数为512,分组半径为0.2,分组内点数为32个,那么采样分组后的特征维度为512x32x(3+0),其中分组内每个点的坐标都已减去中心点坐标,0表示原有特征维度,对应上图中的C,若用法向量作为输入特征,则会将坐标与法向量拼接作为新的特征。经过PointNet卷积Conv1d(3, 64)、Conv1d(64, 64)、Conv1d(64, 128)和最大池化后。每个分组点云的特征维度为128,共512个分组。这相当于512个采样点的特征维度为128,即128×512,128对应上图中的C1。
(2)SA2:输入为(1)中采样得到的512个点坐标和128×512维度特征。随机最远点采样的点数为128,分组半径为0.4,分组内点数为64个,那么采样分组后的特征维度为128x64x131,其中分组内每个点的坐标都已减去中心点坐标,并将坐标与原特征拼接作为新的特征(3+128=131)。经过PointNet卷积Conv1d(131, 128)、Conv1d(128, 128)、Conv1d(128, 256)和最大池化后。每个分组点云的特征维度为256,共128个分组。这相当于128个采样点的特征维度为256,即256×128,256对应上图中的C2。
(3)SA3:输入为(2)中采样得到的128个点坐标和256×128维度特征。将全部128个点分为1组,采样中心设置为为坐标原点。那么采样分组后的特征维度为1x128x259,将坐标与原特征拼接作为新的特征(3+256=259)。经过PointNet卷积Conv1d(259, 256)、Conv1d(256, 512)、Conv1d(512, 1024)和最大池化后。每个分组点云的特征维度为1024,共1个分组。这相当于1个采样点的特征维度为1024,即1024×1,1024对应上图中的C4。
(4)(3)中输出1024维度特征经过FC(1024, 512)、FC(512, 256)、FC(256, 40)、log_softmaxt得到40维度的输出,即40个类别log softmax,即图中的class scores。
5 损失函数
与PointNet不一样的地方在于,PointNet++不含特征变换矩阵。因此。损失函数仅由交叉熵损失函数组成,不再包括64维特征的变换矩阵的损失。这里考虑到类别的均衡性,交叉熵损失函数会为每个类别分配一个权重。在全部原始点云中,同一类别的空间点数量最多的权重最小,取值为1。其他,类别的权重是最大点数量与该类别数量的比值的三分之一次方,显然其他类别的权重大于1。
6 训练评估程序
将2中的数据集解压到1中工程目录下data文件夹中,data文件夹需要新建,默认是没有的。将model参数设置为pointnet2_cls_ssg(ssg,Single-Scale Group,单一尺度分类,下节会介绍多尺度分类),然后直接运行train_classification.py和test_classdification.py即可完成训练和测试,通过将use_normals设置为True将在输入中引入法向量。
文章出处登录后可见!