文章目录
聊DeeplabV3+网络前,先看空洞卷积。
1 常规卷积与空洞卷积的对比
1.1 空洞卷积简介
空洞卷积(Dilated convolution)如下图所示,其中 r 表示两列之间的距离(r=1就是常规卷积了)。
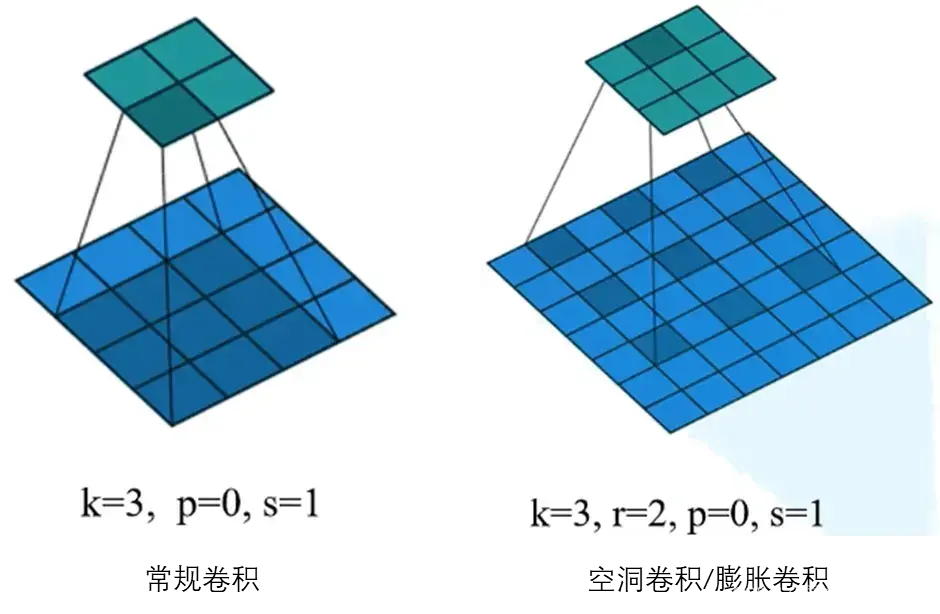
池化可以扩大感受野,降低数据维度,减少计算量,但是会损失信息,对于语义分割来说,这造成了发展瓶颈。
空洞卷积可以在扩大感受野的情况下不损失信息,但其实,空洞卷积的确没有损失信息,但是却没有用到所有的信息。
1.2 空洞卷积的优点
- 扩大感受野:神经网络加深,单个像素感受野扩大,但特征图尺寸缩小,空间分辨率降低,为此,空洞卷积出现了,一方面感受野大了可以检测分割大目标,另一方面分辨率高了可以精确定位目标。
- 捕获多尺度上下文信息:两列之间填充 (r-1) 个0,这个 r 可自己设置,不同 r 可得到不同尺度信息。
2 DeeplabV3+模型简介
DeeplabV3+是语义分割领域超nice的方法,模型效果非常好。
DeeplabV3+主要在模型的架构上作文章,引入了可任意控制编码器提取特征的分辨率,通过空洞卷积平衡精度和耗时。
DeeplabV3+在Encoder部分引入了大量的空洞卷积(见第2节),在不损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。
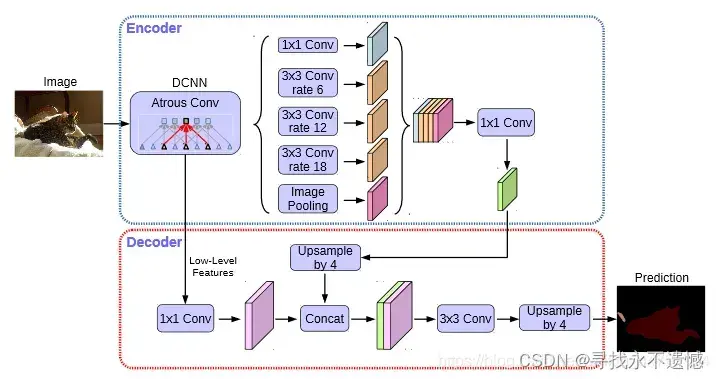
此图详细介绍,请看大佬的b站视频Pytorch 搭建自己的DeeplabV3+语义分割平台,强推此人!
在Encoder中,对压缩四次的初步有效特征层(也可以是三次,看需求)利用并行的空洞卷积(Atrous Convolution),分别用不同rate(也就是第1节中的 r )的Atrous Convolution进行特征提取,再进行concat合并,然后进行1×1卷积压缩特征。 —-Encoder得到绿色特征图,称之为ASPP加强特征提取网络的构建
在Decoder中,对压缩两次的初步有效特征层利用1×1卷积调整通道数,再和**空洞卷积后的有效特征层(Encoder部分的输出)**上采样的结果进行堆叠,在完成堆叠后,进行两次深度可分离卷积,这个时候,我们就获得了一个最终的有效特征层,它是整张图片的特征浓缩。
得到最终的有效特征层后,利用一个1×1卷积进行通道调整,调整到Num_Classes;然后利用resize进行上采样使得最终输出层,宽高和输入图片一样。
3 DeeplabV3+网络代码
结合上图及代码注释理解即可,代码可运行。
import torch
import torch.nn as nn
import torch.nn.functional as F
# mobilenetv2网络下方已给出
from nets.mobilenetv2 import mobilenetv2
class MobileNetV2(nn.Module):
def __init__(self, downsample_factor=8, pretrained=True):
super(MobileNetV2, self).__init__()
from functools import partial
model = mobilenetv2(pretrained)
# ---------------------------------------------------------#
# 把最后一层卷积剔除,也就是
# 17 InvertedResidual后跟着的 18 常规1x1卷积 剔除
# ---------------------------------------------------------#
self.features = model.features[:-1]
# ----------------------------------------------------------------------#
# 18 = 开始的常规conv + 17 个InvertedResidual,即features.0到features.17
# ----------------------------------------------------------------------#
self.total_idx = len(self.features)
# ---------------------------------------------------------#
# 每个 下采样block 所处的索引位置
# 即Output Shape h、w尺寸变为原来的1/2
# ---------------------------------------------------------#
self.down_idx = [2, 4, 7, 14]
# -------------------------------------------------------------------------------------------------#
# 若下采样倍数为8,则网络会进行3次下采样(features.0,features.2,features.4),尺寸 512->64
# 需要对后两处下采样block(步长s为2的InInvertedResidual)的参数进行修改,使其变为空洞卷积,尺寸不再下降
# 再解释一下,下采样倍数为8,表示输入尺寸缩小为原来的1/8,也就是经历3次步长为2的卷积
#
# 若下采样倍数为16,则会进行4次下采样(features.0,features.2,features.4,features.7),尺寸 512-> 32
# 只需要对最后一处 下采样block 的参数进行修改
# -------------------------------------------------------------------------------------------------#
if downsample_factor == 8:
# ----------------------------------------------#
# 从第features.7到features.13
# ----------------------------------------------#
for i in range(self.down_idx[-2], self.down_idx[-1]):
# ----------------------------------------------#
# apply(func,...):func参数是函数,相当于C/C++的函数指针。
# partial函数用于携带部分参数生成一个新函数
# ----------------------------------------------#
self.features[i].apply(
partial(self._nostride_dilate, dilate=2)
)
# ----------------------------------------------#
# 从第features.14到features.17
# ----------------------------------------------#
for i in range(self.down_idx[-1], self.total_idx):
self.features[i].apply(
partial(self._nostride_dilate, dilate=4)
)
elif downsample_factor == 16:
for i in range(self.down_idx[-1], self.total_idx):
self.features[i].apply(
partial(self._nostride_dilate, dilate=2)
)
# ----------------------------------------------------------------------#
# _nostride_dilate函数目的:通过修改卷积参数实现 self.features[i] 尺寸不变
# ----------------------------------------------------------------------#
def _nostride_dilate(self, m, dilate):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
if m.stride == (2, 2): # 原本步长为2的
m.stride = (1, 1) # 步长变为1
if m.kernel_size == (3, 3): # kernel_size为3的
m.dilation = (dilate//2, dilate//2) # 膨胀系数变为dilate参数的一半
m.padding = (dilate//2, dilate//2) # 填充系数变为dilate参数的一半
else:
if m.kernel_size == (3, 3):
m.dilation = (dilate, dilate)
m.padding = (dilate, dilate)
def forward(self, x):
# ------------------------------------------------------------------------------#
# low_level_features表示低(浅)层语义特征,只进行了features.0和features.2两次下采样,
# features.3的输出尺寸和features.2一样
# 输入为512x512,下采样倍数为16时,CHW:[24, 128, 128]
# ------------------------------------------------------------------------------#
low_level_features = self.features[:4](x)
# ------------------------------------------------------#
# x表示高(深)层语义特征,其h、w尺寸更小些
# 输入为512x512,下采样倍数为16时,CHW:[320, 32, 32]
# ------------------------------------------------------#
x = self.features[4:](low_level_features)
return low_level_features, x
#-----------------------------------------#
# ASPP特征提取模块
# 得到深层特征后,进行加强特征提取
# 利用 不同膨胀率rate 的膨胀卷积进行特征提取
#-----------------------------------------#
class ASPP(nn.Module):
def __init__(self, dim_in, dim_out, rate=1, bn_mom=0.1):
super(ASPP, self).__init__()
self.branch1 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 1, 1, padding=0, dilation=rate,bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=6*rate, dilation=6*rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch3 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=12*rate, dilation=12*rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch4 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=18*rate, dilation=18*rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
#-----------------------------------------#
# 结合forward中第五个分支去看
#-----------------------------------------#
self.branch5_conv = nn.Conv2d(dim_in, dim_out, 1, 1, 0,bias=True)
self.branch5_bn = nn.BatchNorm2d(dim_out, momentum=bn_mom)
self.branch5_relu = nn.ReLU(inplace=True)
#-----------------------------------------#
# 五个分支堆叠后的特征,经1x1卷积去整合特征
#-----------------------------------------#
self.conv_cat = nn.Sequential(
nn.Conv2d(dim_out*5, dim_out, 1, 1, padding=0,bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
def forward(self, x):
[b, c, row, col] = x.size()
#-----------------------------------------#
# 一共五个分支
#-----------------------------------------#
conv1x1 = self.branch1(x)
conv3x3_1 = self.branch2(x)
conv3x3_2 = self.branch3(x)
conv3x3_3 = self.branch4(x)
#-----------------------------------------#
# 第五个分支,全局平均池化+卷积
#-----------------------------------------#
global_feature = torch.mean(x,2,True)
global_feature = torch.mean(global_feature,3,True)
global_feature = self.branch5_conv(global_feature)
global_feature = self.branch5_bn(global_feature)
global_feature = self.branch5_relu(global_feature)
#---------------------------------------------#
# 利用插值方法,对输入的张量数组进行上\下采样操作
# 这样才能去和上面四个特征图进行堆叠
# (row, col):输出空间的大小
#---------------------------------------------#
global_feature = F.interpolate(global_feature, (row, col), None, 'bilinear', True)
#-----------------------------------------#
# 将五个分支的内容堆叠起来
# 然后1x1卷积整合特征。
#-----------------------------------------#
feature_cat = torch.cat([conv1x1, conv3x3_1, conv3x3_2, conv3x3_3, global_feature], dim=1)
result = self.conv_cat(feature_cat)
return result # 图中Encoder部分,1x1 Conv后的绿色特征图
class DeepLab(nn.Module):
def __init__(self, num_classes, backbone="mobilenet", pretrained=True, downsample_factor=16):
super(DeepLab, self).__init__()
if backbone=="mobilenet":
#----------------------------------#
# 获得两个特征层
# 浅层特征 [128,128,24]
# 主干部分 [32,32,320]
#----------------------------------#
self.backbone = MobileNetV2(downsample_factor=downsample_factor, pretrained=pretrained)
in_channels = 320 # backbone深层特征引出来的通道数
low_level_channels = 24 # backbone浅层特征引出来的通道数
else:
raise ValueError('Unsupported backbone - `{}`, Use mobilenet, xception.'.format(backbone))
#-----------------------------------------#
# ASPP特征提取模块(加强特征提取)
# 利用不同膨胀率的膨胀卷积进行特征提取
# 得到Encoder部分,1x1 Conv后的绿色特征图
#-----------------------------------------#
self.aspp = ASPP(dim_in=in_channels, dim_out=256, rate=16//downsample_factor)
#----------------------------------#
# 浅层特征边
# Decoder部分1x1卷积进行通道数调整
#----------------------------------#
self.shortcut_conv = nn.Sequential(
nn.Conv2d(low_level_channels, 48, 1),
nn.BatchNorm2d(48),
nn.ReLU(inplace=True)
)
#----------------------------------#
# Decoder部分,对堆叠后的特征图进行
# 两次3x3的特征提取
#----------------------------------#
self.cat_conv = nn.Sequential(
nn.Conv2d(48+256, 256, 3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Conv2d(256, 256, 3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
)
self.cls_conv = nn.Conv2d(256, num_classes, 1, stride=1)
def forward(self, x):
#--------------------------------------------------#
# 输入图片的高和宽,最后上采样得到的输出层和此保持一致
#--------------------------------------------------#
H, W = x.size(2), x.size(3)
#-----------------------------------------#
# 获得两个特征层
# low_level_features: 浅层特征-进行卷积处理
# x : 主干部分-利用ASPP结构进行加强特征提取
#-----------------------------------------#
low_level_features, x = self.backbone(x)
x = self.aspp(x)
low_level_features = self.shortcut_conv(low_level_features)
#-----------------------------------------#
# 将加强特征边上采样
# 与浅层特征堆叠后利用卷积进行特征提取
#-----------------------------------------#
x = F.interpolate(x, size=(low_level_features.size(2), low_level_features.size(3)), mode='bilinear', align_corners=True)
x = self.cat_conv(torch.cat((x, low_level_features), dim=1)) # 堆叠 + 3x3卷积特征提取
#-----------------------------------------#
# 对获取到的特征进行分类,获取每个像素点的种类
# 对于VOC数据集,输出尺寸CHW为[21, 128, 128]
# 21个类别,这儿就输出21个channel,
# 然后经过softmax以及argmax等操作完成像素级分类任务
#-----------------------------------------#
x = self.cls_conv(x)
#-----------------------------------------#
# 通过上采样使得最终输出层,高宽和输入图片一样。
#-----------------------------------------#
x = F.interpolate(x, size=(H, W), mode='bilinear', align_corners=True)
return x
if __name__ == "__main__":
num_classes = 21 # 语义分割,VOC数据集,21个类别
model = DeepLab(num_classes, backbone="mobilenet", pretrained=False, downsample_factor=16)
model.eval()
print(model)
# --------------------------------------------------#
# 用来测试网络能否跑通,同时可查看FLOPs和params
# --------------------------------------------------#
from torchsummaryX import summary
summary(model, torch.randn(1, 3, 512, 512))
输出:
DeepLab(
(backbone): MobileNetV2(
(features): Sequential(
(0): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(1): InvertedResidual(
(conv): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
...
164_cat_conv.Dropout_7 -
165_cls_conv 88.080384M
----------------------------------------------------------------------------------------------------------
Totals
Total params 5.818149M
Trainable params 5.818149M
Non-trainable params 0.0
Mult-Adds 4.836132304G
4 mobilenetv2网络代码
第3节中导入backbone为mobilenetv2,下方给出代码,其详细解读可见MobileNetV2详解及获取网络计算量与参数量。
import math
import os
import torch
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
BatchNorm2d = nn.BatchNorm2d
def conv_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
BatchNorm2d(oup),
nn.ReLU6(inplace=True)
)
def conv_1x1_bn(inp, oup):
return nn.Sequential(
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
BatchNorm2d(oup),
nn.ReLU6(inplace=True)
)
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = round(inp * expand_ratio)
self.use_res_connect = self.stride == 1 and inp == oup
if expand_ratio == 1:
self.conv = nn.Sequential(
#--------------------------------------------#
# 进行3x3的逐层卷积,进行跨特征点的特征提取
#--------------------------------------------#
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
#-----------------------------------#
# 利用1x1卷积进行通道数的调整
#-----------------------------------#
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
#-----------------------------------#
# 利用1x1卷积进行通道数的上升
#-----------------------------------#
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
#--------------------------------------------#
# 进行3x3的逐层卷积,进行跨特征点的特征提取
#--------------------------------------------#
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
#-----------------------------------#
# 利用1x1卷积进行通道数的下降
#-----------------------------------#
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
BatchNorm2d(oup),
)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, n_class=1000, input_size=224, width_mult=1.):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = 32
last_channel = 1280
interverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1], # 256, 256, 32 -> 256, 256, 16
[6, 24, 2, 2], # 256, 256, 16 -> 128, 128, 24 2
[6, 32, 3, 2], # 128, 128, 24 -> 64, 64, 32 4
[6, 64, 4, 2], # 64, 64, 32 -> 32, 32, 64 7
[6, 96, 3, 1], # 32, 32, 64 -> 32, 32, 96
[6, 160, 3, 2], # 32, 32, 96 -> 16, 16, 160 14
[6, 320, 1, 1], # 16, 16, 160 -> 16, 16, 320
]
assert input_size % 32 == 0
input_channel = int(input_channel * width_mult)
self.last_channel = int(last_channel * width_mult) if width_mult > 1.0 else last_channel
# 512, 512, 3 -> 256, 256, 32
self.features = [conv_bn(3, input_channel, 2)]
for t, c, n, s in interverted_residual_setting:
output_channel = int(c * width_mult)
for i in range(n):
if i == 0:
self.features.append(block(input_channel, output_channel, s, expand_ratio=t))
else:
self.features.append(block(input_channel, output_channel, 1, expand_ratio=t))
input_channel = output_channel
self.features.append(conv_1x1_bn(input_channel, self.last_channel))
self.features = nn.Sequential(*self.features)
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(self.last_channel, n_class),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = x.mean(3).mean(2)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
def load_url(url, model_dir='./model_data', map_location=None):
if not os.path.exists(model_dir):
os.makedirs(model_dir)
filename = url.split('/')[-1]
cached_file = os.path.join(model_dir, filename)
if os.path.exists(cached_file):
return torch.load(cached_file, map_location=map_location)
else:
return model_zoo.load_url(url,model_dir=model_dir)
def mobilenetv2(pretrained=False, **kwargs):
model = MobileNetV2(n_class=1000, **kwargs)
if pretrained:
model.load_state_dict(load_url('https://github.com/bubbliiiing/deeplabv3-plus-pytorch/releases/download/v1.0/mobilenet_v2.pth.tar'), strict=False)
return model
if __name__ == "__main__":
model = mobilenetv2()
for i, layer in enumerate(model.features):
print(i, layer)
# --------------------------------------------------#
# 用来测试网络能否跑通,同时可查看FLOPs和params
# --------------------------------------------------#
from torchsummaryX import summary
summary(model, torch.randn(1, 3, 512, 512))
5 感谢链接
https://blog.csdn.net/qq_41076797/article/details/114593840
https://blog.csdn.net/weixin_44791964/article/details/120113686
https://www.bilibili.com/video/BV173411q7xF?p=4
文章出处登录后可见!