又快到了写论文的时间了,相信同学对获取数据都十分的头大,而要想能学会使用python或者第三方现成的采集器软件来采集想要的数据,这个学习成本也是不低,那么,拿来主义就是摆在很多同学面前最理想的追求了。
今天,小编就给大家带来一个Python通过移动端接口爬取的案例,同时用pyinstaller打包成exe,可以帮助大家用最简单的方式下载到微博的数据,大家如果有需要的可以免费下载使用。
下面我们来看看这个小工具如何使用?

gif动图 – 富泰科
这是博主:Vsinger_洛天依 的微博:
;
下图就是采集到的内容,导出到表格当中
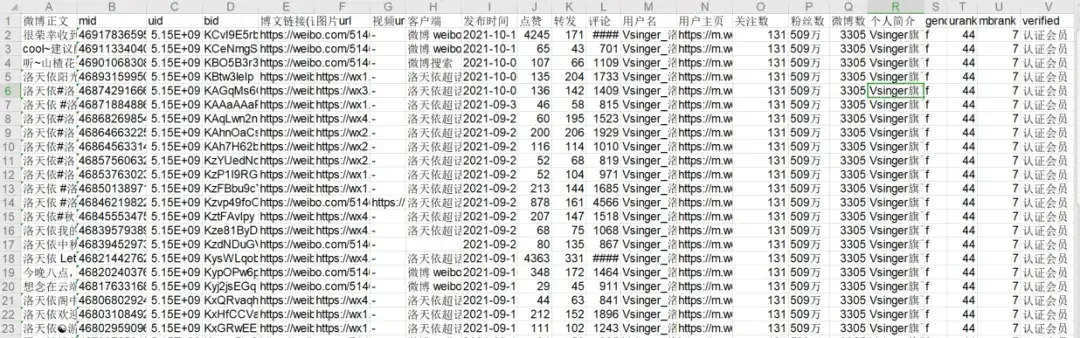
我们可以看到数据字段非常的丰富,无论我们想要进行对这些数据进行什么维度的分析,都可以利用到。那么,这个小工具是如何使用呢?
下面我们看一下这个小工具如何下载:

我们可以看到数据就采集出来了,而且会同步下载到本地的表格当中。
是不是非常傻瓜,那么我们的同学们如果选题要用到微博的数据,有了这款小工具就可以节省很多采集数据的时间了。是不是非常nice?
我们下面详情说一下具体的思路:
首先我们知道:微博有很多不同的终端:如:www.weibo.com/www.weibo.cn/m.weibo.cn,分别对应不同的硬件终端,而我们爬取数据的都知道,获取数据最快的方式是通过网站的接口。这样不用浏览器的加载,那我们就按这个思路来找一下,是否有相应的接口:
我们打开weibo(我们通过https://m.weibo.cn/这个移动端访问),登录后,打开一个大v的首页 – 下拉 – 打开全部微博。按f12打开开发者工具。
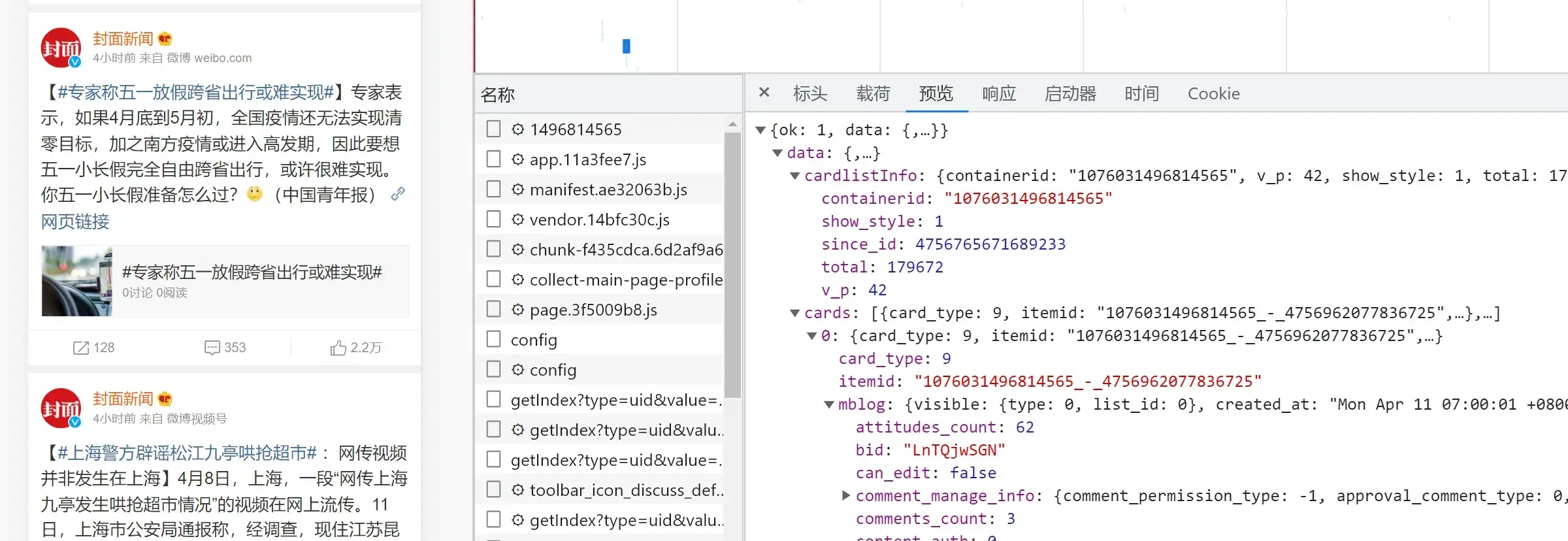
;
然后我们通过网络调试,就可以看到相应的数据接口了。

;
然后我们看到,所有的数据都在这个mblog下,下面我们就可以写代码来获取了。
1、先获取用户的基本信息:
'''用户信息'''
user_name = card['mblog']['user']['screen_name']
profile_url = card['mblog']['user']['profile_url']
post_count = card['mblog']['user']['statuses_count']
desc = card['mblog']['user']['description']
fans = card['mblog']['user']['followers_count']
follow = card['mblog']['user']['follow_count']
gender = card['mblog']['user']['gender']
urank = card['mblog']['user']['urank']
mbrank = card['mblog']['user']['mbrank']
verified = card['mblog']['user']['verified']
if verified:
verified = '认证会员'
else:
verified = '非认证会员'复制
这个container_id 就是用户的ID,相应的字段都是json格式,我们解析一下就可以。
2、再获取每一条微博:
for card in data['cards']:
if card['card_type'] == 9:
mid = card['mblog']['id']
uid = card['mblog']['user']['id']
bid = card['mblog']['bid']
content = card['mblog']['text']
content = re.sub(r'<.*?>', '', content) # 通过正则过滤博文当中的html标签
imageUrl = ''
video_url = '-'
try:
for pic in card['mblog']['pics']:
imageUrl += pic['url'] + ','
imageUrl = imageUrl[:len(imageUrl) - 1]
except KeyError as e:
imageUrl = ''
try:
if card['mblog']['page_info']['type'] == 'video':
video_url = card['mblog']['page_info']['media_info']['stream_url']
except KeyError as e:
video_url = '-'
source = card['mblog']['source']
scheme = 'https://weibo.com/{}/{}?filter=hot&root_comment_id=0&type=comment'.format(
card['mblog']['user']['id'], card['mblog']['bid'])
created_time = card['mblog']['created_at']复制
3、然后我们再加一下翻页:
while True:
url = f'https://m.weibo.cn/api/container/getIndex?containerid={container_id}&page={page_num}'
page_num += 1复制
update:微博好像更新了翻页的方式,新的翻页为一个动态参数,我们如下写一下就好了。
since_id = '' # 翻页参数
while True:
url = f'https://m.weibo.cn/api/container/getIndex?type=uid&value={profile_id}' \
f'&containerid=107603{profile_id}&since_id={since_id}'复制
然后设置一下结束翻页:
total_num = data['cardlistInfo']['total']
if page_num > int(total_num / 10):
print('没有更多页了')
break复制
4、将获取的内容保存:
'''数据导出到表格当中'''
self.excel_save(file_name + '_微博博文.xlsx', items, self.head)复制
5、当然,我们还需要对self.headers设置一下,这里的cookie需要将登录后的值复制过来。
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Mobile Safari/537.36 Edg/93.0.961.47'
}复制
6、然后,就可以运行一下代码了。

导出的数据表格:
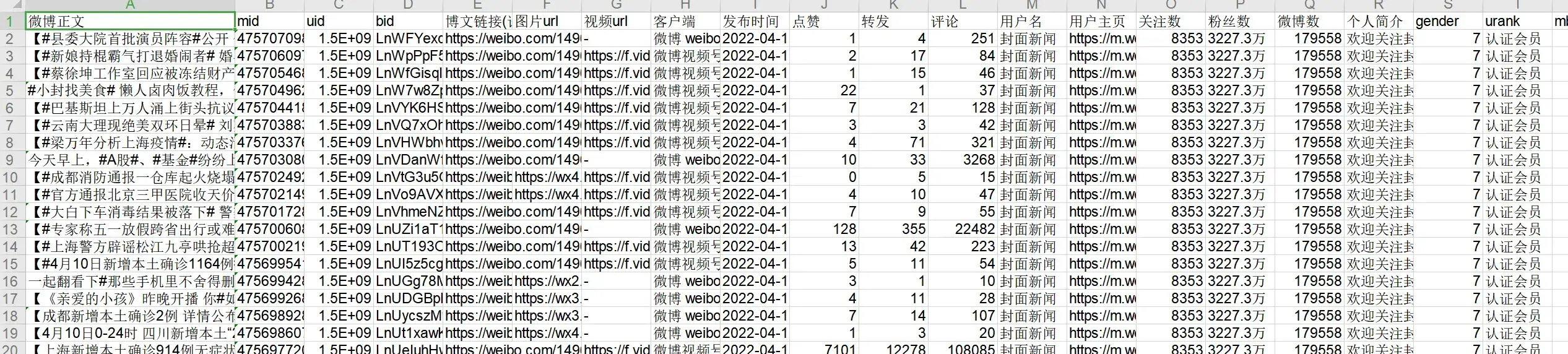
调试好了,我们如果说想方便使用,可以使用pyinstaller打包一下。打包成exe,可以方便发送和携带。下载点这里
当然,这里有义务告知:以上工具下载的数据仅限于用于学习与研究使用,如有需要用于商业用途请取得相应权利人授权。请大家下载时视为同意这个要求,否则请勿下载。如果有超出以上规范或者将获取的数据应用于超过上述范围的,因此产生的后果由下载者负责,造成的可能的纠纷或法律后果与本号无关。
文章出处登录后可见!