文章目录
数据可视化第二版-03部分-06章-比较与排序
总结
本系列博客为基于《数据可视化第二版》一书的教学资源博客。本文主要是第6章,比较与排序可视化的案例相关。
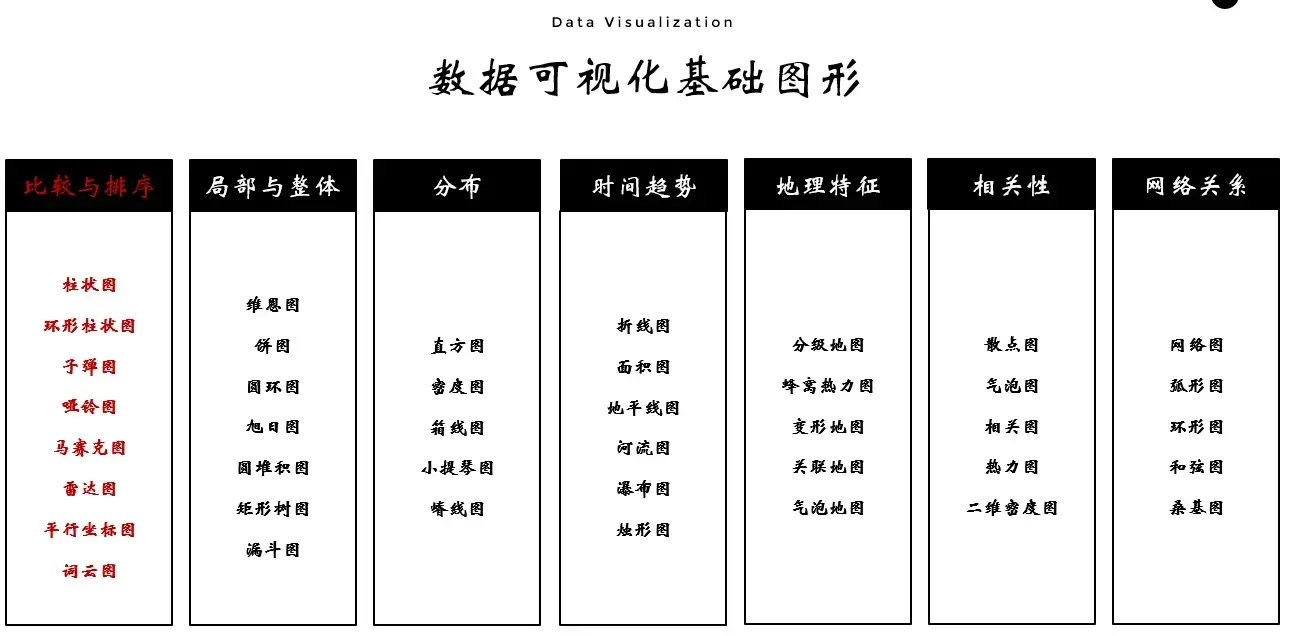
可视化视角-比较与排序
代码实现
创建虚拟环境
我的conda下有多个python环境。
1. python版本管理
创建python版本的命令为
conda create -n name python=3.10(python版本自己指定)
如:
conda create -n py10 python=3.10
查看当前的python版本
conda env list

2.切换到指定版本后安装虚拟环境
切换到指定的python版本
conda activate py10
激活虚拟环境后,安装python虚拟环境
python -m venv venv202302

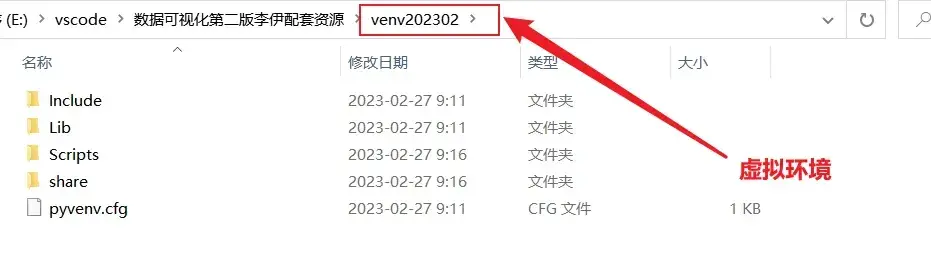
然后把数据和代码拖拽到
E:\vscode\数据可视化第二版李伊配套资源
切换路径到文件当前路径
目录下即可,但很多代码拖拽后,无法执行,因为python工程中的默认路径为工程目录的根路径,如果python文件中的路径为相对于当前文件,需要切换默认路径为文件当前路径
import os
print(os.getcwd(),"-----------------")
# os.chdir("./")
os.chdir(os.path.dirname(os.path.realpath(__file__)))
print(os.getcwd(),"-----------------")
输出为:
(venv202302) E:\vscode\数据可视化第二版李伊配套资源>e:/vscode/数据可视化第二版李伊配套
资源/venv202302/Scripts/python.exe e:/vscode/数据可视化第二版李伊配套资源/各类图形示例
代码/比较类/哑铃图.py
E:\vscode\数据可视化第二版李伊配套资源 —————–
E:\vscode\数据可视化第二版李伊配套资源\各类图形示例代码\比较类 —————–
柱形图
plt.bar(x, height, width=0.8, bottom=None, *, align='center', data=None, **kwargs)
x:表示x坐标,数据类型为int或float类型,刻度自适应调整;也可传dataframe的object,x轴上等间距排列;
height:表示柱状图的高度,也就是y坐标值,数据类型为int或float类型;
width:表示柱状图的宽度,取值在0~1之间,默认为0.8;
bottom:柱状图的起始位置,也就是y轴的起始坐标;
align:柱状图的中心位置,默认”center”居中,可设置为”lege”边缘;
color:柱状图颜色;
edgecolor:边框颜色;
linewidth:边框宽度;
tick_label:下标标签;
log:柱状图y周使用科学计算方法,bool类型;
orientation:柱状图是竖直还是水平,竖直:“vertical”,水平条:“horizontal”;
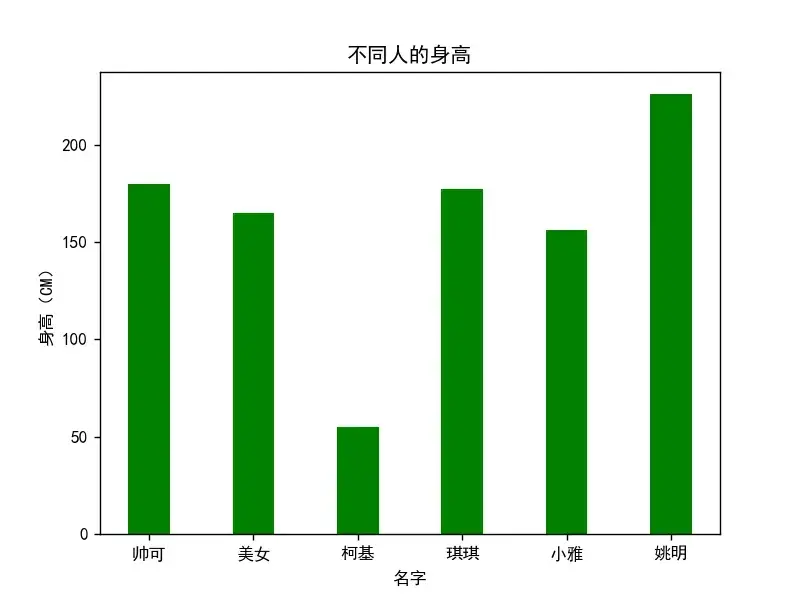
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] # 设置支持中文
plt.rcParams['axes.unicode_minus']=False # 设置支持坐标轴数值为复数
X = ["帅可", "美女", "柯基", "琪琪", "小雅", "姚明"]
Y = [180, 165, 55, 177, 156, 226]
fig = plt.figure()
plt.bar(X, Y, 0.4, color="green")
plt.xlabel("名字")
plt.ylabel("身高(CM)")
plt.title("不同人的身高")
plt.show()
输出为:
环形柱状图
plt.axes解释参考:https://www.zhihu.com/question/51745620
axes的用法和subplot是差不多的,四个参数的话,前两个指的是相对于坐标原点的位置,后两个指的是坐标轴的长/宽度,
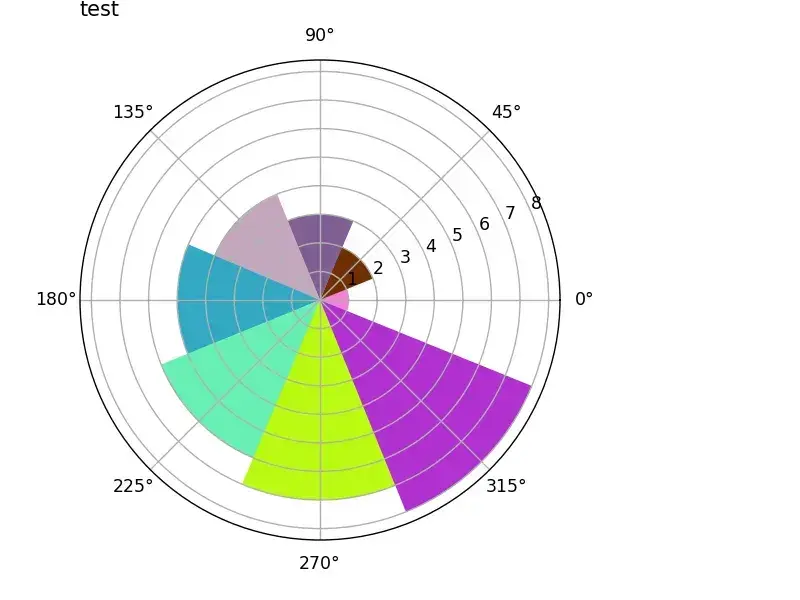
import numpy as np
from matplotlib import pyplot as plt
def show_rose(values, title):
n = 8
angle = np.arange(0, 2 * np.pi, 2 * np.pi / n)
print("angle--->",angle)
# angle---> [0. 0.78539816 1.57079633 2.35619449 3.14159265 3.92699082 4.71238898 5.49778714]
# 绘制的数据
radius = np.array(values)
print("radius--->",radius)
# radius---> [1 2 3 4 5 6 7 8]
# 极坐标条形图,polar为True
plt.axes([0, 0.1, 0.8, 0.8], polar=True)
color = np.random.random(size=24).reshape((8, 3))
plt.bar(angle, radius, color=color)
plt.title(title, loc='left')
plt.show()
v = [1, 2, 3, 4, 5, 6, 7, 8]
show_rose(v, 'test')
输出为:
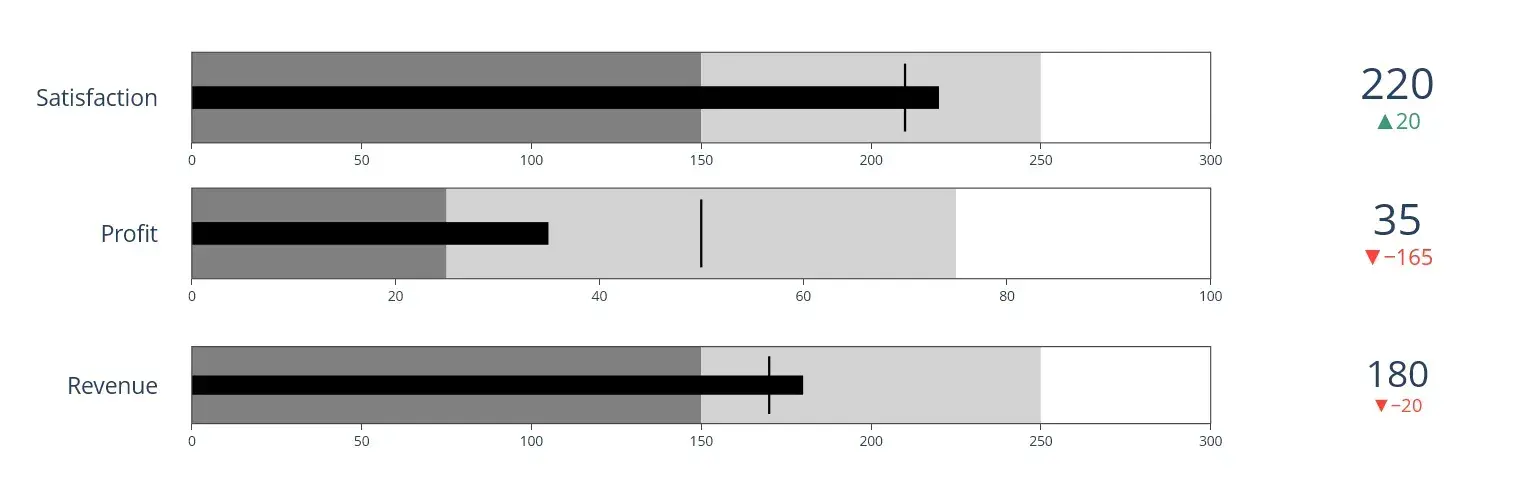
子弹图
import plotly.graph_objects as go
fig = go.Figure()#每一个制作一条子弹图轨道
fig.add_trace(go.Indicator(
mode = "number+gauge+delta", value = 180,#调整的是显示的内容,number是最右端数字。gauge表示图表,delta表示与标准的差值,值为细条形的值
delta = {"reference": 200},#设定标准
domain = {"x": [0.25, 1], "y": [0.08, 0.25]},#这一条子弹图的位置
title = {"text": "Revenue"},
gauge = {
"shape": "bullet",
"axis": {"range": [None, 300]},
"threshold": {#细线属性
"line": {"color": "black", "width": 2},
"thickness": 0.75,
"value": 170},
"steps": [#分段填充颜色
{"range": [0, 150], "color": "gray"},
{"range": [150, 250], "color": "lightgray"}],
"bar": {"color": "black"}}))
fig.add_trace(go.Indicator(
mode = "number+gauge+delta", value = 35,
delta = {"reference": 200},
domain = {"x": [0.25, 1], "y": [0.4, 0.6]},
title = {"text": "Profit"},
gauge = {
"shape": "bullet",
"axis": {"range": [None, 100]},
"threshold": {#细线属性
"line": {"color": "black", "width": 2},
#"line": {"color": "black", "width": 2},
"thickness": 0.75,
"value": 50},
"steps": [#分段填充颜色
{"range": [0, 25], "color": "gray"},
{"range": [25, 75], "color": "lightgray"}],
"bar": {"color": "black"}}))
fig.add_trace(go.Indicator(
mode = "number+gauge+delta", value = 220,
delta = {"reference": 200},
domain = {"x": [0.25, 1], "y": [0.7, 0.9]},
title = {"text" :"Satisfaction"},
gauge = {
"shape": "bullet",
"axis": {"range": [None, 300]},
"threshold": {#准线
"line": {"color": "black", "width": 2},
# "line": {"color": "black", "width": 2},
"thickness": 0.75,
"value": 210},
"steps": [
{"range": [0, 150], "color": "gray"},
{"range": [150, 250], "color": "lightgray"}],
"bar": {"color": "black"}}))
fig.update_layout(height = 400 , margin = {"t":0, "b":0, "l":0})
fig.show()
输出为:
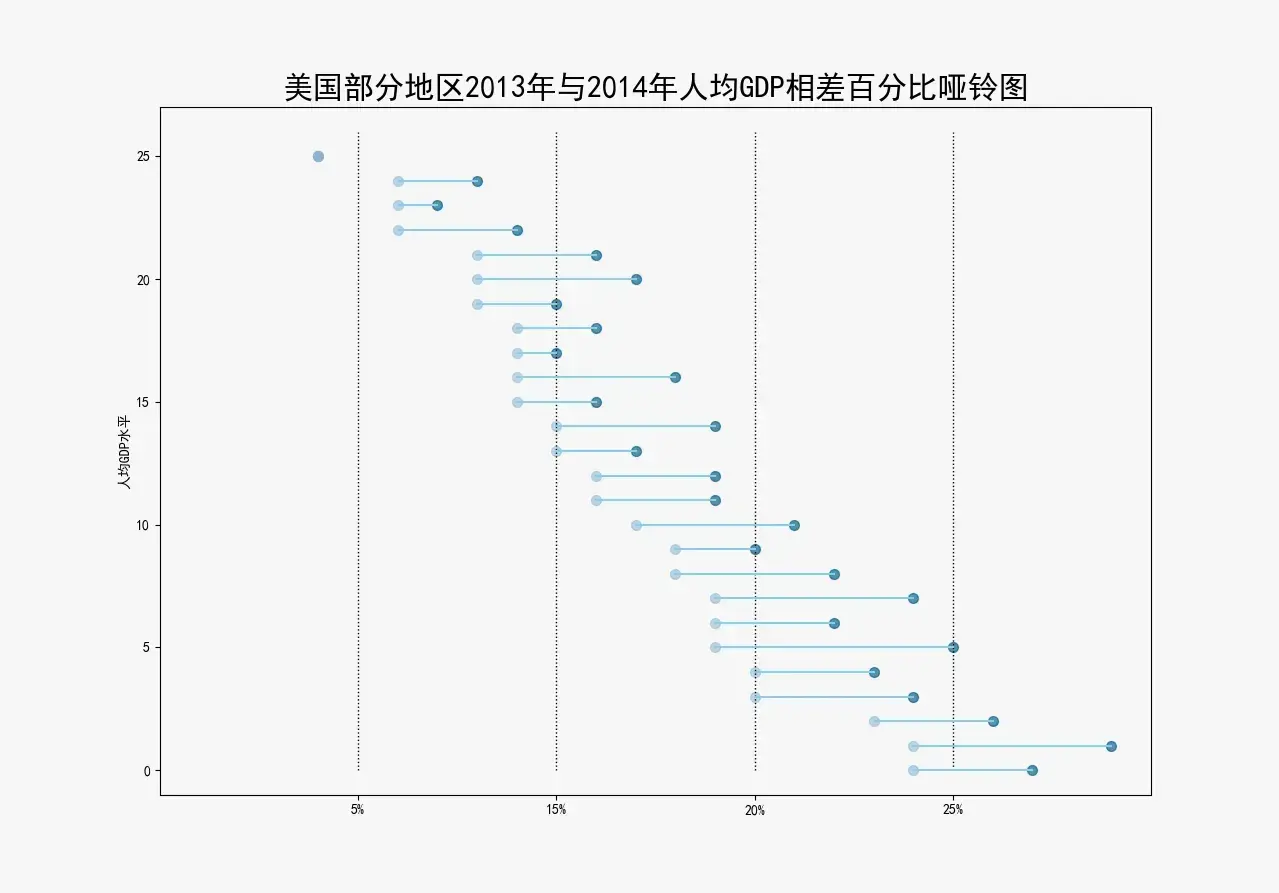
哑铃图
数据:美国部分地图人均GDP.csv
"Area","pct_2014","pct_2013"
"Houston",0.19,0.22
"Miami",0.19,0.24
"Dallas",0.18,0.21
"San Antonio",0.15,0.19
"Atlanta",0.15,0.18
"Los Angeles",0.14,0.2
"Tampa",0.14,0.17
"Riverside, Calif.",0.14,0.19
"Phoenix",0.13,0.17
"Charlotte",0.13,0.15
"San Diego",0.12,0.16
"All Metro Areas",0.11,0.14
"Chicago",0.11,0.14
"New York",0.1,0.12
"Denver",0.1,0.14
"Washington, D.C.",0.09,0.11
"Portland",0.09,0.13
"St. Louis",0.09,0.1
"Detroit",0.09,0.11
"Philadelphia",0.08,0.1
"Seattle",0.08,0.12
"San Francisco",0.08,0.11
"Baltimore",0.06,0.09
"Pittsburgh",0.06,0.07
"Minneapolis",0.06,0.08
"Boston",0.04,0.04
代码:
plt.gca() 参考:https://zhuanlan.zhihu.com/p/110976210
matplotlib库的axiss模块中的Axes.vlines()函数用于在从ymin到ymax的每个x处绘制垂直线。
Axes.vlines(self, x, ymin, ymax, colors=’k’, linestyles=’solid’, label=”, *, data=None, **kwargs)
参数:此方法接受以下描述的参数:
x:该参数是x-indexes绘制线条的顺序。
ymin, ymax:这些参数包含一个数组,它们代表每行的开头和结尾。
colors:此参数是可选参数。它是默认值为k的线条的颜色。
linetsyle:此参数也是可选参数。它用于表示线型{‘实线’,‘虚线’,‘虚线’,‘虚线’}。
label:该参数也是可选参数,它是图形的标签。
返回值:这将返回LineCollection。
# -*- coding:UTF-8 -*-
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.lines as mlines
import os
print(os.getcwd(),"-----------------")
# E:\vscode\数据可视化第二版李伊配套资源 -----------------
# os.chdir("./")
os.chdir(os.path.dirname(os.path.realpath(__file__)))
print(os.getcwd(),"-----------------")
# E:\vscode\数据可视化第二版李伊配套资源\各类图形示例代码\比较类 -----------------
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams["axes.unicode_minus"] = False # 用来正常显示负号
# Import Data
df = pd.read_csv("美国部分地图人均GDP.csv")
df.sort_values('pct_2014', inplace=True)
df.reset_index(inplace=True)
# Func to draw line segment
def newline(p1, p2, color='black'):
ax = plt.gca()
l = mlines.Line2D([p1[0], p2[0]], [p1[1], p2[1]], color='skyblue')
ax.add_line(l)
return l
# Figure and Axes
fig, ax = plt.subplots(1, 1, figsize=(14, 14), facecolor='#f7f7f7', dpi=80)
# Vertical Lines
ax.vlines(x=.05, ymin=0, ymax=26, color='black', alpha=1, linewidth=1, linestyles='dotted')
ax.vlines(x=.10, ymin=0, ymax=26, color='black', alpha=1, linewidth=1, linestyles='dotted')
ax.vlines(x=.15, ymin=0, ymax=26, color='black', alpha=1, linewidth=1, linestyles='dotted')
ax.vlines(x=.20, ymin=0, ymax=26, color='black', alpha=1, linewidth=1, linestyles='dotted')
# Points
ax.scatter(y=df['index'], x=df['pct_2013'], s=50, color='#0e668b', alpha=0.7)
ax.scatter(y=df['index'], x=df['pct_2014'], s=50, color='#a3c4dc', alpha=0.7)
# Line Segments
for i, p1, p2 in zip(df['index'], df['pct_2013'], df['pct_2014']):
newline([p1, i], [p2, i])
# Decoration
ax.set_facecolor('#f7f7f7')
ax.set_title("美国部分地区2013年与2014年人均GDP相差百分比哑铃图", fontdict={'size': 22})
ax.set(xlim=(0, .25), ylim=(-1, 27), ylabel='人均GDP水平')
ax.set_xticks([.05, .1, .15, .20])
ax.set_xticklabels(['5%', '15%', '20%', '25%'])
ax.set_xticklabels(['5%', '15%', '20%', '25%'])
plt.show()
输出为:
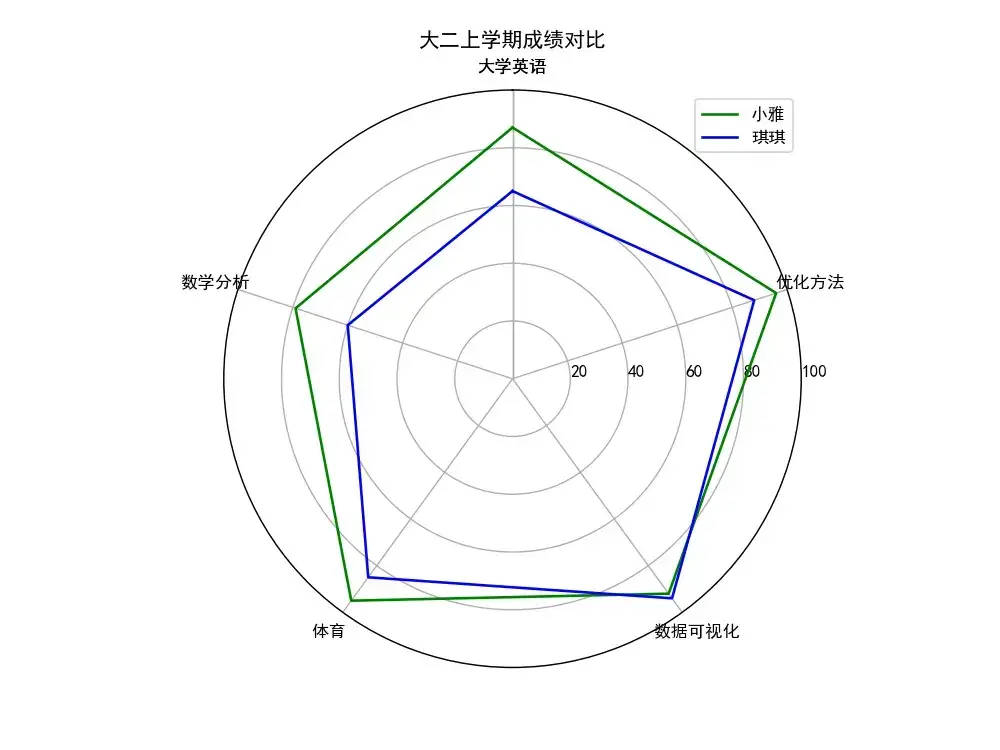
雷达图
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
results = [{"大学英语": 87, "数学分析": 79, "体育": 95, "数据可视化": 92, "优化方法": 96},
{"大学英语": 65, "数学分析": 60, "体育": 85, "数据可视化": 94, "优化方法": 88}]
data_length = len(results[0])
# 将极坐标根据数据长度进行等分
angles = np.linspace(0, 2 * np.pi, data_length, endpoint=False)
print("angles-->",angles)
# angles--> [0. 1.25663706 2.51327412 3.76991118 5.02654825]
labels = [key for key in results[0].keys()]
print("labels-->",labels)
# labels--> ['大学英语', '数学分析', '体育', '数据可视化', '优化方法']
score = [[v for v in result.values()] for result in results]
print("score-->",score)
# score--> [[87, 79, 95, 92, 96], [65, 60, 85, 94, 88]]
# 使雷达图数据封闭
score_a = np.concatenate((score[0], [score[0][0]]))
print("score_a-->",score_a)
# score_a--> [87 79 95 92 96 87]
score_b = np.concatenate((score[1], [score[1][0]]))
print("score_b-->",score_b)
# score_b--> [65 60 85 94 88 65]
angles = np.concatenate((angles, [angles[0]]))
print("angles-->",angles)
# angles--> [0. 1.25663706 2.51327412 3.76991118 5.02654825 0. ]
labels = np.concatenate((labels, [labels[0]]))
print("labels-->",labels)
# labels--> ['大学英语' '数学分析' '体育' '数据可视化' '优化方法' '大学英语']
# 设置图形的大小
fig = plt.figure(figsize=(8, 6), dpi=100)
# 新建一个子图
ax = plt.subplot(111, polar=True)
# 绘制雷达图
ax.plot(angles, score_a, color='g')
ax.plot(angles, score_b, color='b')
# 设置雷达图中每一项的标签显示
ax.set_thetagrids(angles * 180 / np.pi, labels)
# 设置雷达图的0度起始位置
ax.set_theta_zero_location('N')
# 设置雷达图的坐标刻度范围
ax.set_rlim(0, 100)
# 设置雷达图的坐标值显示角度,相对于起始角度的偏移量
ax.set_rlabel_position(270)
ax.set_title("大二上学期成绩对比")
plt.legend(["小雅", "琪琪"], loc='best')
plt.show()
输出为:
词云图
from pyecharts import options as opts
from pyecharts.charts import Page, WordCloud
from pyecharts.faker import Collector
from pyecharts.globals import SymbolType
C = Collector()
words = [
("Sam S Club", 10000),
("Macys", 6181),
("Amy Schumer", 4386),
("Jurassic World", 4055),
("Charter Communications", 2467),
("Chick Fil A", 2244),
("Planet Fitness", 1868),
("Pitch Perfect", 1484),
("Express", 1112),
("Home", 865),
("Johnny Depp", 847),
("Lena Dunham", 582),
("Lewis Hamilton", 555),
("KXAN", 550),
("Mary Ellen Mark", 462),
("Farrah Abraham", 366),
("Rita Ora", 360),
("Serena Williams", 282),
("NCAA baseball tournament", 273),
("Point Break", 265),
]
def wordcloud_diamond() -> WordCloud:
c = (
WordCloud()
.add("", words, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="WordCloud-shape-diamond"))
)
return c
wordcloud_diamond().render()
输出为:

教材截图

文章出处登录后可见!