理解多个预测变量与连续响应变量之间关系通常适用线性回归,但当响应变量为类别变量时需要适用逻辑回归。
逻辑回归是尝试从数据集中把W观测记录分为不同类别的分类算法。
常见的分类回归场景有:
- 通过信用分和账户余额预测客户贷款是否违约
- 通过篮球比赛中平均抢得篮板球次数及平均每场得分预测是否被NBA选中
- 通过特定城市的房屋大小及盥洗室数量预测房价是否为200w以上
相比于线性回归的响应值是连续变量,上述示例的响应变量仅包括两个值中的一个。
逻辑回归方程
逻辑回归使用最大似然估计方法寻找下面方程:
参数说明:
方程右边的公式预测了响应变量取值为1的对数概率。因此,当我们拟合逻辑回归模型时,我们可以使用以下公式来计算给定观测值为1的概率:
然后使用特定概率阈值对观测值进行分类:1或0。举例:观测概率大等于0.5则为1,反之为0。
如何解释逻辑回归响应值
假设我们使用逻辑回归模型来预测一个给定的篮球运动员是否会被NBA选中,基于他们的场均篮板和场均得分。
下面是逻辑回归模型的输出:
| Item | Coefficient | Std. Error | Z-statistic | P-value |
|---|---|---|---|---|
| Intercept | -2.8690 | 0.1485 | -19.3199 | <0.0001 |
| Rebounds | 0.0698 | 0.0161 | 4.3235 | <0.0001 |
| Points | 0.1694 | 0.0299 | 5.6734 | <0.0001 |
使用上述系数,我们可以计算指定运动员被选人NBA的概率:
假设某运动员场均为8个篮板、得15分,则计算结果为0.557,既然大于0.5,则预测结果为被选入NBA;
相比另一个运动员场均3个篮板、得7分,则计算结果为0.186,既然小于0.5,则预测结果不会被选人NBA.
逻辑回归假设前提
逻辑回归需遵循下面一些假设:
- 响应变量为二值,即响应变量只能有两种可能。
- 观测数据集是相互独立的。即观察结果不应该来自于对同一个体的重复测量,也不应该以任何方式相互关联。
- 预测变量之间不存在严重的多重共线性,即假设预测变量之间不存在高度相关。
- 没有极端的异常值。假设在数据集中没有极端的异常值或有影响的观察结果。
- 预测变量与响应变量的logit之间存在线性关系。这个假设可以使用Box-Tidwell测试进行测试。
- 样本量足够大。作为经验法则,每个解释变量应该有至少10个最不常见的结果。例如,如果你有3个解释变量,而最不常见结果的期望概率是0.20,那么你的样本量应该至少为(10*3)/ 0.20 = 150。
示例
载入必要的包
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
import matplotlib.pyplot as plt
加载数据
使用下面代码加载数据:
data = pd.read_csv("data/default.csv")
# view first six rows of dataset
print(data[0:6])
# find total observations in dataset
print(len(data.index))
输出结果:
default student balance income
0 0 0 729.526495 44361.625074
1 0 1 817.180407 12106.134700
2 0 0 1073.549164 31767.138947
3 0 0 529.250605 35704.493935
4 0 0 785.655883 38463.495879
5 0 1 919.588530 7491.558572
10000
数据集包含10000条客户信息,共四列:
default: 响应变量,是否违约.
student: 是否为学生.
balance: 平均余额.
income: 收入情况.
我们将使用其他三个变量预测是否违约:default字段。
创建测试集和训练集
下面把原数据集分为测试集和训练集:
# 定义预测变量和响应变量
x = data[['student', 'balance', 'income']]
y = data['default']
# split the dataset into training (70%) and testing (30%) sets
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=0)
拟合逻辑回归模型
我们使用LogisticRegression()函数拟合模型:
# 实例化模型对象
log_regression = LogisticRegression()
# 使用训练数据拟合模型
log_regression.fit(x_train, y_train)
# 使用测试数据进行预测
y_pred = log_regression.predict(x_test)
# 输出模型参数
print(log_regression.intercept_, log_regression.coef_, log_regression.score(x_train, y_train))
# [-2.86843745] [[-3.79999456e+00 4.03495132e-03 -1.36823955e-04]] 0.9691428571428572
模型诊断
测试完成后,我们需要分析模型表现. 首先创建混淆矩阵:
cnf_matrix = metrics.confusion_matrix(y_test, y_pred)
print(cnf_matrix)
结果如下:
[[2870 17]
[ 93 20]]
- 正确预测不违约: 2870
- 正确预测真违约: 20
- 错误预测不违约: 93
- 错误预测真违约: 17
下面获取模型准确率,它表示模型的正确预测率:
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
# Accuracy: 0.9633333333333334
通过结果可以说明模型可以正确预测客户违约率为96.2% .
最后,我们可以绘制ROC (Receiver Operating Characteristic)曲线,该曲线显示模型预测的真阳性的百分比,随着预测概率的截止点从1降低到0。AUC(曲线下面积)越高,我们的模型预测结果就越准确:
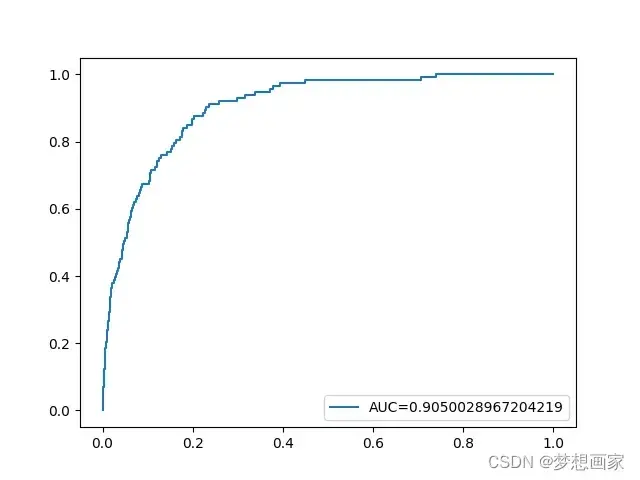
文章出处登录后可见!