创作不易,如果以下内容对你有帮助,记得三连呀,让更多的小伙伴能看到吧~~
1. 研究内容
- 本课题研究的是基于Python的微博舆情热点分析与研究。在PyCharm、Jupiter Notebook开发环境下,首先利使用python的requests库对微博进行分时段多进程爬取,并利用lxml解析库对爬取到的数据解析并做简单的数据清洗且保存到数据库;然后,使用numpy、pandas等库对原始数据进行数据预处理;接着,对各特征做灰色关联分析,筛选对传播热度影响较大的特征;最后,利用python的matplotlib库可视化两官方媒体和自媒体在不同的时段、不同人群传播力度的变化等各种变化指标,并对微博的内容利用基于情感词典的方法进行文本情感分析,从而挖掘正面和负面信息。
2. 数据获取
- 主要采用的是requests+lxml库进行数据爬取和数据解析,以下附上爬取的部分代码:
# 统一时间
def parse_time(datetime):
if datetime is None:
return datetime
if re.match('\d+年\d+月\d+日.+', datetime):
# time模块
datetime = datetime
datetime.replace("年","-")
datetime.replace("月","-")
datetime.replace("日","")
if re.match('\d+月\d+日.+', datetime):
# time模块
datetime = datetime.replace("月","-").replace("日","")
datetime = time.strftime('%Y-', time.localtime(time.time())) + datetime
if re.match('\d+分钟前', datetime):
minute = re.match('(\d+)', datetime).group(1)
# time.localtime()为当前的时间戳,用time.time()当前的时间戳-已过的时间来获取发布时的时间戳(1970纪元后经过的浮点秒数)
datetime = time.strftime('%Y-%m-%d %H:%M', time.localtime(time.time() - float(minute)*60))
if re.match('\d+秒前', datetime):
second = re.match('(\d+)', datetime).group(1)
# time.localtime()为当前的时间戳,用time.time()当前的时间戳-已过的时间来获取发布时的时间戳(1970纪元后经过的浮点秒数)
datetime = time.strftime('%Y-%m-%d %H:%M', time.localtime(time.time() - float(second)))
if re.match('今天.*', datetime):
temp = re.match("今天(\d+:\d+)",datetime).group(1)
datetime = time.strftime('%Y-%m-%d ', time.localtime()) + temp
return datetime
# 开启爬虫
def start_crawl(base_url,pages):
headers = request_header_article()
# 遍历搜索时间
years = [2021,2022]
for year in years:
months = [*range(1,13)] if year != 2022 else list(1)
days = [31,28,31,30,31,30,31,31,30,31,30,31]
for num, month in enumerate(months):
for day in range(1,days[num],7):
day_end = day + 6 if day + 6 < 31 else 30
print("Spider正在爬取{}-{}-{}至{}-{}-{}时间段!".format(year,month,day,year,month,day_end))
time.sleep(1)
for page in range(1, pages + 1):
url = base_url.format(year_start=year, month_start=month, day_start=day, year_end=year, month_end=month, day_end=day_end, page=page)
response = requests.get(url=url, headers=headers,timeout=(3,7))
if response.status_code == 200:
res = et.HTML(response.text)
print("Spider已完成第{}页爬取任务!".format(page))
yield res
else:
continue
# 将数据存入MongoDB
def save_mongoDB(base_url,pages):
client = pymongo.MongoClient(host='localhost', port=27017)
db = client.HotSpotBD
table = db['HotSpotInfo']
for insert_list in data_clean(base_url,pages):
table.insert_many(insert_list)
print("完成一页数据插入任务!")
client.close()
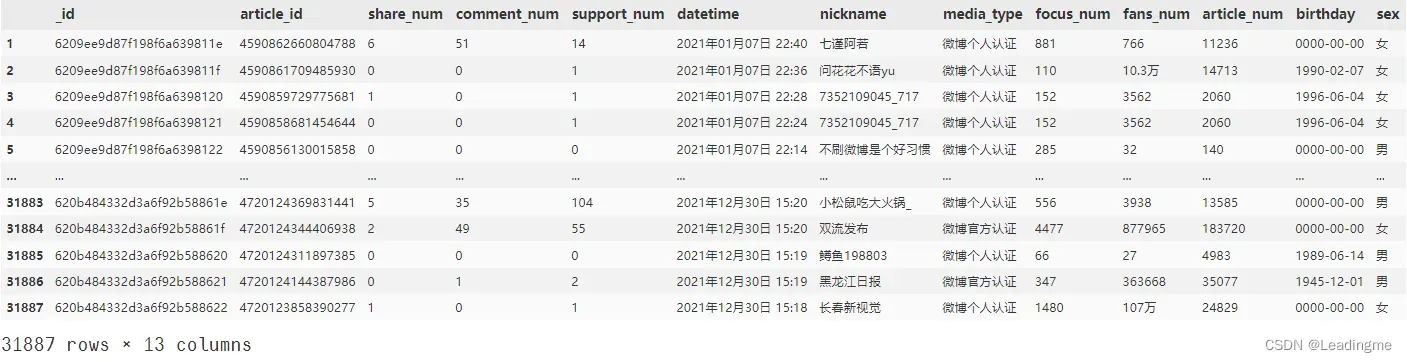
- 本项目主要采用MongoDB数据库作为存储介质,主要包括的字段有点赞数、评论数、转发数、媒体类型、发布时间、作者总获赞数、作者总发布文章数、作者年龄、作者性别等,以下为数据表的部分数据:
该部分数据用于数据分析
该部分数据用于文本情感分析

3. 数据预处理
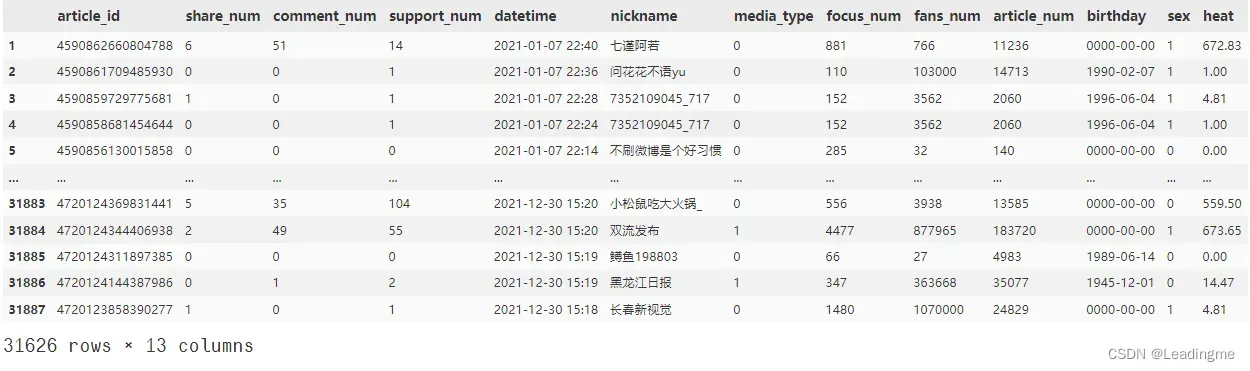
- 在这一部分主要是对原始数据进行数据缺失值填充、重复值去重、非法值替换等处理,以及特征编码,对某些特征进行数据类型转换,各特征间的相关性分析,最重要的是在这一部分通过文章的点赞,评论,转发数的权重定义出了文章的热度特征,以下是数据预处理后的部分数据:
4. 数据分析及可视化
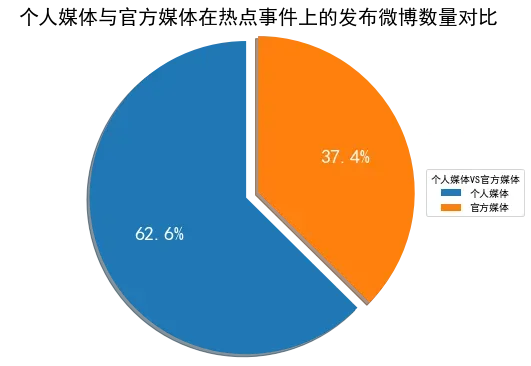
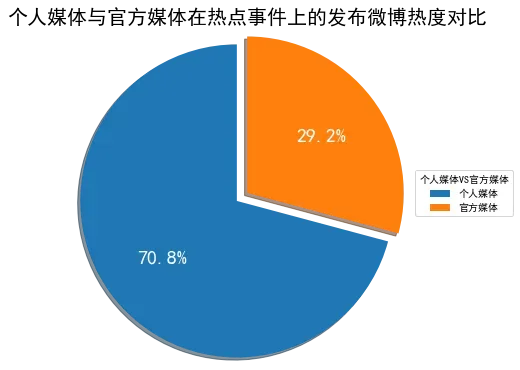
- 在这一部分主要是研究官方媒体和自媒体在不同的时段、不同人群传播力度的变化等各种变化指标,以下是数据分析后作可视化后的图形:
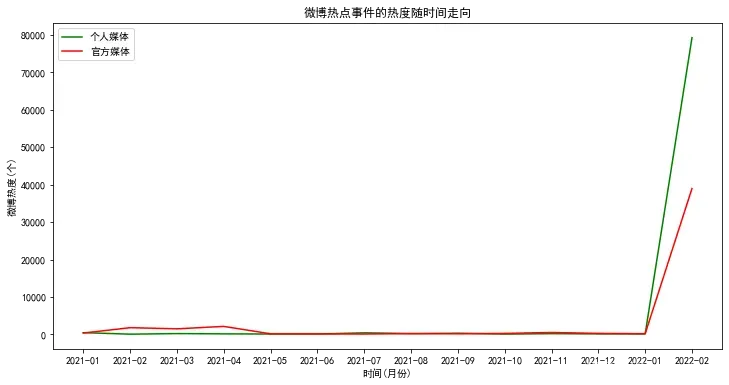
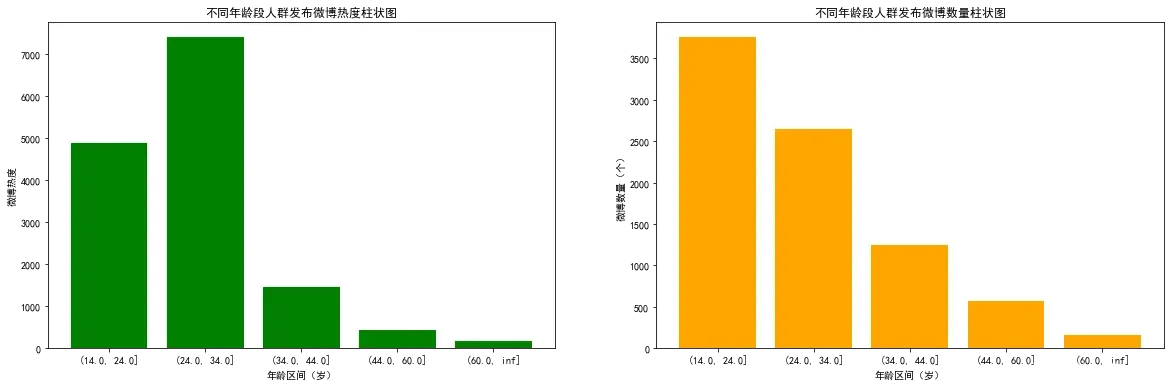
5. 文本情感分析
文本预处理
-
在做情感分析之前,需要对文本进行去除非中文字符、中文分词、去除停用词、词频统计等预处理,以下是对文本预处理后的部分数据:

词频统计后作出的词云图

情感分析
- 用于没有标记标签的训练集数据,所有没有采用贝叶斯分类模型进行分类,这里直接调用用百度已经训练好的模型接口进行情感分析的,以下是特定时间段内的情感趋势走向的分析:

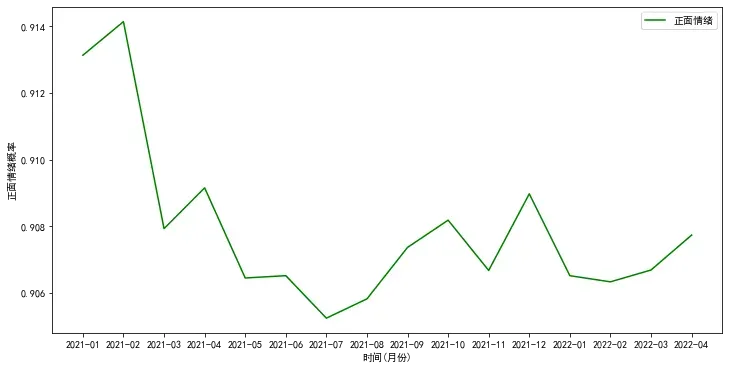
源码分享
文章出处登录后可见!
已经登录?立即刷新