在进行特征工程、划分数据集的工作中,drop()函数都能派上用场。它可以轻松剔除数据、操作列和操作行等。
drop()详细的语法如下:
删除行是index,删除列是columns:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, inplace=False)参数:
labels:要删除的行或列的标签,可以是单个标签,也可以是标签列表。
axis:要删除的行或列的轴,0表示行,1表示列。
index:要删除的行的索引,可以是单个索引,也可以是索引列表。
columns:要删除的列的列名,可以是单个列名,也可以是列名列表。
inplace:是否在原DataFrame上进行操作,默认为False,即不在原DataFrame上进行操作。
删除列
使用场景1:删除不需要的特征。
例如:有些特征对结果的影响不大,就可以把与因变量不相关的自变量删掉;为了避免多重共线性,要把有强相关关系的自变量删掉。
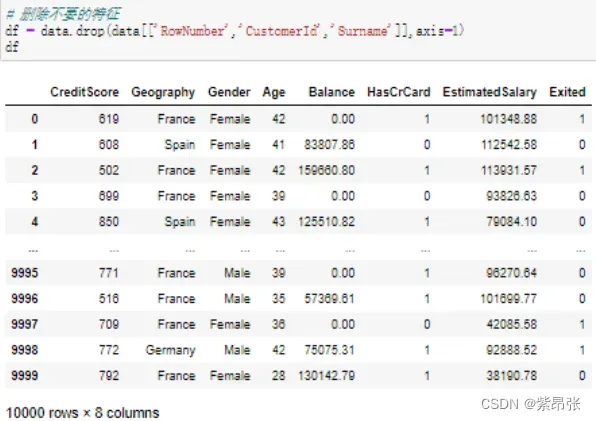
df = data.drop(data[['RowNumber','CustomerId','Surname']],axis=1)
df代码讲解:
data是数据集,两个中括号代表DataFrame格式,里面筛选了3个要删除的字段;
axis=1代表操作列;
运行结果:
使用场景2:把因变量删掉
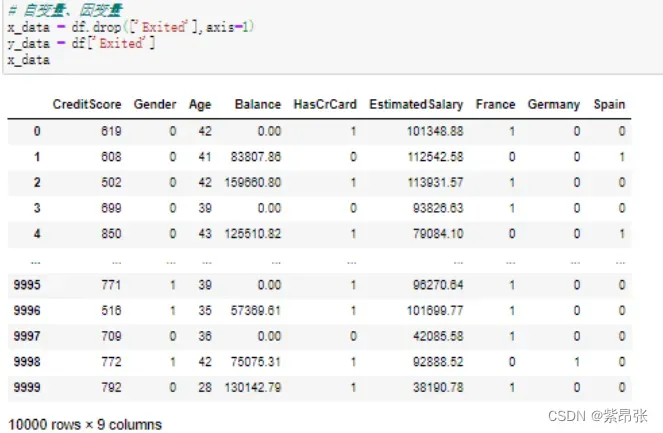
# 自变量、因变量
x_data = df.drop(['Exited'],axis=1)
y_data = df['Exited']
x_data代码讲解:
drop()函数里面填写要删除的字段,表示从df中删除名为“Exited”的列;
[‘Exited’]这一个字段是我们要剔除的因变量,单个字段可以这样表示;
运行结果:
删除行
使用场景3:在划分数据集的时候,生成了训练集,把被分到训练集的样本剔除掉,剩下的就是测试集了。
#划分训练集
train_data = data.sample(frac = 0.8, random_state = 0)
#测试集
test_data = data.drop(train_data.index)
代码讲解:
drop()函数里面填行索引可以删除掉行;
train_data是我们划分好的训练集,train_data.index表示行索引;
axis=0,表示的是删除行,也可以不写,是默认值;
文章出处登录后可见!
已经登录?立即刷新